2026年重新評估:AGI 毀滅之致命性清單
我重新審視了艾里澤·尤德科夫斯基在 2022 年提出的 AGI 生存風險論點,並結合過去四年的 AI 進展進行評估,發現近期的發展似乎更支持保羅·克里斯蒂亞諾較為樂觀的反駁觀點。
自 Eliezer Yudkowsky 發表 《AGI 毀滅:致命性清單》(AGI Ruin: A List of Lethalities) 以來,已經過去了大約四年。這份清單列出了 43 點理由,說明為何開發 AGI 的預設結果是全人類滅絕。一週後,Paul Christiano 以 《我與 Eliezer 的異同之處》(Where I Agree and Disagree with Eliezer) 作為回應,認同了清單中約一半的內容,並對其餘大部分內容提出了反駁。
對於像我這樣年輕且不在灣區的人來說,這些文章的意義可能比老前輩們預想的還要重大。在網路理性主義圈完全且永久地被 AI 討論淹沒之前,我認識的大多數人將 LessWrong 視為一個為喜歡《序列》(The Sequences) 的人寫作的地方。對我們而言,直到 2022 年,我們才在同一個地方接觸到所有的毀滅論點。這也是多年來 Eliezer 首次公開宣布,自《序列》以來他的評估變得多麼嚴峻。就我所知,《AGI 毀滅》目前仍是他對其觀點最權威的解釋。
公共知識分子親手遞給你一份文件,解釋他們為何相信自己所信之事,這種情況並不常見。有些令人驚訝的是,我認為自 2023 年初以來,這篇貼文就沒有得到過具體的評估,儘管自 GPT-3 以來我們的能力有了巨大的飛躍。他是否正確似乎與我未來的決策相關,因此最近我開始了一項個人練習,仔細重讀每個論點和反論點,並逐點寫下我的想法。
最終,這個計畫的規模不斷擴大,直到我決定自己寫一篇獨立的貼文。我不是對齊研究員,但作為練習的一部分,我閱讀了當代的評論和回應,從比我更熟悉該領域的人那裡獲取反饋,並試圖解析這幾年間出現的對齊論文和研究。^([1]) 當《AGI 毀滅》的論點似乎具體暗示了我們現有的模型(而不僅僅是更強大的系統)時,我會將評估重點放在這篇貼文在過去四年 AI 進步面前的表現如何。^([2])
我最初的預期是我對該貼文評論的反對程度會和對貼文本身一樣多。但現在處於一個更冷靜的狀態,有更多時間鑽研這個主題,我對 Eliezer 的觀點產生了一種全新且明顯負面的印象。四年的 AI 進步對 Paul 的預測比對 Eliezer 的更為寬容,而《AGI 毀滅》現在對我來說讀起來像是一份文件,其聽起來具體的論點主要由定義不明的形容詞(「遠超分佈外」、「足夠強大」、「危險程度的智能」)在支撐。我已在末尾總結了我的感受,以便讀者在閱讀時有機會得出自己的結論,但如果你只想詳細聽聽我的想法,可以直接跳到「總體印象」。我仍然同意貼文中大部分內容,為了簡潔起見,在我不需多加補充的部分,我只留下了簡單的勾選符號。
AGI 毀滅 (AGI Ruin)
A 節(「設定問題」)
1. Alpha Zero 在經過大約一天的自我對弈後,就超越了所有累積的人類圍棋知識,完全不依賴人類棋譜或樣本對局。任何依賴「嗯,它在圍棋上會達到人類水平,但之後很難超越,因為它無法再向人類學習」的人,都是在依賴空談。AGI 將不會受到人類能力或人類學習速度的上限限制...
✔️
2. 一個具有足夠高認知能力的認知系統,只要給予任何中等頻寬的因果影響管道,都不難在不依賴人類基礎設施的情況下,自我引導至壓倒性的能力... 與高能認知系統發生衝突而失敗,看起來至少與「地球上每個人都在同一秒鐘內突然倒地死亡」一樣致命。
✔️
3. 我們需要在操作「危險」智能水平的「第一次關鍵嘗試」中就搞定對齊,在那個水平上,未對齊的危險智能操作會殺死地球上的每個人,然後我們就沒有第二次嘗試的機會了。
顯然,如果你建造了一個任意強大的 AI 卻未能對齊它,它會殺死你。未明說但同樣正確的是,一個有能力接管世界的 AI 與一個沒有該能力的 AI 處於不同的環境中,擁有不同的可用選項,其行為可能與測試環境中較笨或被隔離的 AI 不同。
一些並非針對該點的主要修正筆記:
- 如果在 2010 年部署會造成生存威脅的 AGI,在 2030 年部署則不一定,特別是如果廣泛部署半對齊的前身 AI 已成為常態。就像一支帶著機關槍出現的軍隊在 1200 年會自動獲勝,但在 2000 年則不一定。
- 這並不能自動拯救我們,但如果這是真的,它確實具有對齊方面的意義,因為這表明我們可能能夠繼續對那些比我們目前能處理的要聰明得多的模型進行實驗。
4. 我們不能僅僅「決定不建造 AGI」,因為 GPU 無處不在,演算法知識不斷改進並發表;在領先者擁有摧毀世界的能力 2 年後,另外 5 個參與者也將擁有摧毀世界的能力...
我認為這可能是錯誤的;作為證據,我引用領先的理性主義知識分子 Nate Soares 和 Eliezer Yudkowsky 在他們最新著作中的觀點:
我們談論的是一種會殺死地球上每個人的技術。如果任何國家認真理解這個問題,並認真理解地球上任何群體距離讓 AI 在轉變為超智能後仍遵循操作者意圖還有多遠,那麼他們就沒有衝在前面的動力。出於對自己生命的恐懼,他們也會拼命希望簽署條約並協助執行。
現在,也許 Eliezer 只是因為對技術解決方案失去希望而抓救命稻草。但自《AGI 毀滅》以來,訓練前沿模型的需求呈指數級增長,AI 模型的生產和部署過去是、現在仍然是一個高度複雜的過程,需要數十萬人的密切合作。雖然組織一份具有約束力的條約在「政治上可能很困難」,但即使面對演算法的改進,現有政府完全有能力阻止 AI 的開發或部署超過兩年,只要他們真的認真對待。
5**. 我們不能只建造一個非常弱的系統,因為它太弱而危險性較小,然後宣布勝利;因為稍後會有更多參與者有能力建造更強大的系統,而其中一個會這麼做。✔️
6. 我們需要對齊某個大型任務的執行,即一個「關鍵行動」(pivotal act),以防止其他人建造出毀滅世界的未對齊 AGI。 當擁有 AGI 的參與者很少或只有一個時,他們必須執行某個「關鍵行動」,其強度足以翻轉棋盤,並使用足夠強大的 AGI 來完成。僅僅能對齊一個「弱」系統是不夠的——我們需要對齊一個能做「單一非常大事件」的系統。我通常給出的例子是「燒毀所有 GPU」...
正如當時有人指出的,「關鍵行動」一詞暗示了單一的戲劇性行動,如「燒毀所有 GPU」。有些人(包括 Paul)認為,受限的 AI 仍能以較不戲劇性的方式幫助降低風險,例如:
- 推進對齊和可解釋性研究。
- 通過普遍吸收自由能,或關閉法外/邪惡的手段,來降低稍聰明一點的未對齊 AI 獲取權力的能力。
- 向中立第三方(如立法者)清楚地展示先進 AI 系統的風險。
- 改善認識環境,從而提高人類協調和引導 AI 政策及未來的能力。
Eliezer 後來表示,他相信(或曾相信?)這類行動是遠遠不夠的。但我認為,如果這篇作品僅僅解釋這一點,而不是引入這種大多數讀者可能不同意的框架,會更好。現有的框架有點誤導人們認為 AI 必須比必要的更強大才能對局勢有所貢獻,從而使情況看起來比實際更令人絕望。
**6 (b). **一個 GPU 燒毀者也是一個強大到足以(且據稱被授權)建造奈米技術的系統,因此它需要在危險領域以危險的智能和能力水平運行;任何非幻想式的、試圖命名 AGI 改變世界以使其他六個潛在 AGI 建造者不會在 6 個月後毀滅世界的方法,都伴隨著這一點。
「暫停 AI 進步」或「產生一個能夠產生並對齊下一代 AI 的對齊 AI」,與「殺死地球上所有人」或「燒毀所有 GPU」是不同的任務,並且有各自依賴於世界背景的技能要求。一些可能使亞超智能 AI 更容易幫助向決策者展示生存風險(而非獲得壓倒性的硬實力)的因素:
- 爭論真實的事情比爭論虛假的事情稍微容易一些。
- 由於人們與 AI 的日常接觸量,那些原本不信任專家的人會聽取它們的意見,即使他們對訓練方案中潛在的偏見等有疑慮。
- 如果 AI 認為自己在當前能力水平下無法解決對齊問題,它可能在解決對齊問題上有共同利益。
- 隨著我們的 AI 逐漸變得更聰明,且更有能力進行可解釋性研究/論證,我們在技術層面上展示對齊計劃缺陷的工作可能會變得更容易,而且我們在 AGI 實驗室內部就有可以指出的直接具體案例。
- 目前掌權的人類(甚至是經營 AI 公司的人!)天生在防止 AI 生存風險方面有共同利益,並且有一種原始本能和長期動機,不允許任何個人或 AI 能夠武力控制宇宙。
8. 解決我們希望 AI 解決的問題的最佳且最容易被優化演算法找到的方法,很容易泛化到我們不希望 AI 解決的問題上;你無法建造一個只有能力駕駛紅色汽車而沒有能力駕駛藍色汽車的系統,因為所有駕駛紅色汽車的演算法都會泛化到駕駛藍色汽車的能力。
這結果證明是錯誤的,至少在與對齊相關的方面是如此。
目前 AGI 公司在特定任務領域的強化學習環境上投入了數十億美元。當他們在訓練某種特定技能(如軟體開發)上投入更多時,AI 在該技能上的進步速度遠快於在其他方面的進步。確實存在一定程度的交叉授粉,但不足以使這句話中的「容易」成真,也不足以支撐其試圖為生存風險擔憂建立的修辭點。
也許隨著我們接近 ASI,這種情況會改變!但就目前而言,Paul Christiano 關於模型在模型公司認為合適訓練的各類經濟實用任務(如知識工作和可解釋性研究)上具有差異化優勢的預測看起來非常準確,這影響了我們在模型變得被動危險之前,預期能從中榨取多少對齊工作。
9. 安全系統的建造者,根據這種可能性存在的假設,需要在系統具備殺死所有人或使其自身變得更危險的「能力」的情況下運行系統,但系統已被成功設計為不那樣做...
算是一種公理,但沒錯,✔️
B.1 節(「分佈偏移」)
10. 你無法通過運行致命危險的認知、觀察輸出是否殺死或欺騙或腐蝕操作者、分配損失並進行監督學習來訓練對齊。在任何類似標準機器學習範式的情況下,你都需要以某種方式將你在安全條件下進行的對齊優化,泛化到危險條件下的大型分佈偏移中... 僅憑這一點就足以擊敗許多來自那些從未且無法具體勾勒出他們會進行什麼訓練以對齊什麼輸出的、天真的提案——這當然就是為什麼他們從不具體勾勒這類內容的原因。執行會在你未對齊時殺死你的危險任務的強大 AGI,必須具備一種對齊屬性,這種屬性是從未殺死你的更安全建造/訓練操作中遠超分佈外泛化而來的...
B.1 節開始了一種模式:Eliezer 做出一些孤立來看無可指責的陳述,但使用了像「遠超分佈外」這樣定義不明的形容詞來承載大部分論點。最深層的核心問題(該章節廣泛示意但未深入探討)是:我們在現代 LLM 的廉價監督中看到的泛化,是會繼續保持的「真實」泛化,還是不足以安全協作進行迭代自我改進的淺層模式匹配?
例如,這種分佈偏移有多遠?LLM 似乎已經足夠聰明,可以考慮是否以及如何影響其訓練方案。這是它們現在正在做的事情嗎?如果不是,在什麼能力閾值下它們會開始這樣做?我們是否可以通過紅隊測試、建立強化學習誘捕系統 (RL honeypots)、進行弱到強的泛化實驗、加固我們當前的環境以及製作可解釋性探測器,來提高我們可以安全訓練的系統上限?
這些都是具體問題,似乎決定了特定對齊提案的成敗,也可能取決於我們機器學習架構運作方式的實現細節。但 Eliezer 並未嘗試回答這些問題,而且可能不具備回答這些問題所需的資訊,只能將它們作為潛在危險來示意。如果他只是對 AI 可能存在風險做出低置信度的聲明,那沒問題,但他過去幾年對所有可能的技術方法都持極度悲觀的態度。我確信他有更詳細但未表達出來的直覺,解釋了為什麼他如此確信這些細節無關緊要,但這些直覺對我來說是無法觸及的。
11 (a). 如果認知機制不能從你進行大量訓練的分佈中遠超泛化,它就無法解決像「建造奈米技術」這類問題,因為在這些問題上,運行一百萬次建造奈米技術失敗的訓練成本太高了...
當時,Paul 對這一點的回應是:
**
- 早期的變革性 AI 系統可能會通過在具有較短反饋迴路的較小任務上接受訓練,然後在大型協作項目(最初涉及大量人類,但隨著時間推移自動化程度不斷提高)的背景下組合這些能力,來完成令人印象深刻的技術項目。當 Eliezer 否定 AI 系統在訓練中執行數百萬次較安全任務然後安全轉移到「建造奈米技術」的可能性時(致命性清單第 11 點),他並沒有考慮到可能被建造出來的系統類型,或是人們心目中的那種希望。
Paul 的這個預測非常好;它描述了 2026 年這些模型的訓練方式(通過在無數短時程任務上進行強化學習),描述了 AI 如何擴散到軟體工程等領域並在那裡提供加速,甚至似乎預見了時間時程 (time horizons) 的概念,而當時我們只有 GPT-3。如果聽聽頂尖學者今天如何使用 AI 的解釋,聽起來 Paul 在這裡相關的意義上也是正確的:科學和工程領域的第一批重大進展將來自人類與這類工具型 AI 模型之間的密切協作,而不是來自一個僅接受過網路文本訓練、然後被要求從零開始「一擊即中」完成「建造奈米技術」任務的系統。
AI 模型被建造、使用及未來部署的方式,增加了我們可以執行的「安全」關鍵行動的範圍,這既是因為它(最初)要求人類對過程進行監督和參與,也是因為 AI 實際被委託的任務類型比 Eliezer 預期的更接近它們在強化學習健身房中所接受的訓練。
11 (b). ...這類關鍵的弱行動尚不為人所知,並非因為沒人尋找。所以,你再次需要對齊能從訓練分佈中遠超泛化... 之前已討論過。
12. 在高度智能水平下運行與在較低智能水平下運行相比,是分佈上的劇烈偏移,開啟了新的外部選項,並可能開啟更多新的內部選擇和模式...
與第 10 點一樣,第 12 點是一個微弱的真理,正被用作一種修辭手段,服務於一個直截了當錯誤的更廣泛論點。
例如,對齊 GPT-5.4 確實比對齊 GPT-3 更困難。但人類不需要用於 GPT-3 的對齊技術在 GPT-5.4 上奏效,我們只需要處理 ~GPT-5.2 到 GPT-5.4 之間的分佈偏移,然後是 5.4 到 5.5 之間,並從那裡加速。
稍後,Eliezer 會說他預計許多這些問題會在「能力急劇增長」後顯現。但截至 2026 年,儘管 AI 模型已在 AI 研發中被大量使用,我們尚未遇到這種急劇增長。我們預期遇到這種分佈偏移的「精確、特定時刻」,將決定我們能從模型中獲得多少對對齊有用的工作,而這正是 Eliezer 的對話者們與他意見分歧的主要點。
13. 超智能的許多對齊問題不會自然地出現在前危險、被動安全的性能水平上... 如果能「正確」預見哪些問題稍後會自然顯現,人們可以嘗試提前刻意讓這些問題顯現,並對其進行一些觀察。這在以下程度上有幫助:(a) 我們實際上正確預測了稍後會出現的所有問題或其超集;(b) 我們成功地預先讓稍後會出現的問題的超集顯現;以及 (c) 我們實際上可以在早期的實驗室中解決那些如果處理不當就會致命的對齊問題,而這個實驗室相對於真實問題來說是分佈外的。預見「所有」真正危險的問題,然後成功地讓它們以正確的形式顯現,以便早期解決方案能泛化到後期的解決方案,「聽起來可能有點難」。
✔️。Paul 當時做出的回應是:
致命性清單 第 13 點提出了一個特殊的論點,即我們不會提前看到許多 AI 問題;我覺得我經常在 Eliezer 那裡看到這種思維,但這似乎具有誤導性或錯誤。特別是,提前研究 AI 可能「改變其外部行為以刻意看起來更對齊,並欺騙程式設計師、操作者,以及任何對其進行優化的損失函數」這一問題似乎是可能的...
但我認為 Paul 只是沒讀懂 Eliezer 在說什麼;上面引文中 Eliezer 明確承認這一點的第二句話,是由我加粗的。
14**. 某些問題,例如「AGI 有一個選項(在它看來)可以成功殺死並取代程式設計師,以對其環境進行充分優化」,似乎它們出現的自然順序是首先僅出現在完全危險的領域。真正實際上擁有一個「清晰」的選項來對操作者進行大腦級別的說服或逃逸到網際網路上、建造奈米技術並摧毀全人類——且你完全清楚自己掌握了相關事實,並估計如果你再等一個月並進一步增強能力,學到會改變你首選策略的東西的機率低到不值得等待——這是一個只有在 AGI 完全預期它可以擊敗其創造者時才會被真正評估的選項。我們可以嘗試在早期的玩具領域中製造出那種表面場景的回聲。我預期,在那個玩具領域中嘗試通過梯度下降來對抗那種行為,會產生對思維過程的不太連貫的局部修補,這些修補在一個遠超訓練分佈泛化且思考著非常不同想法的超智能內部,幾乎肯定會崩潰。此外,習慣於在非完全危險領域操作的程式設計師和操作者本身,在進入危險領域時也是在分佈外操作;我們的的方法論屆時可能會崩潰。✔️
15. 能力快速增長似乎很有可能,並且可能同時打破許多先前對齊所需的守恆量。 在操作者缺乏足夠預見的情況下,我預計許多此類問題會在能力急劇增長後大約同時出現...
如果這一點有任何意義,那麼這種快速的能力增長尚未到來。我們只是在獲得逐漸強大的系統,而且我認為有理由相信我們會一直獲得這樣的系統,直到它們主導局面,因為有縮放定律 (scaling laws)。
B.2 節:外部和內部對齊的核心困難。
16. 即使你在一個精確的損失函數上非常努力地訓練,也不會因此在 AI 內部創建該損失函數的顯式內部表示,使其隨後在分佈偏移的環境中繼續追求該精確的損失函數。人類並不顯式地追求包容性遺傳適應度;即使在非常精確、非常簡單的損失函數上進行外部優化,也不會產生朝向該方向的內部優化。
✔️,但同時,現代大型語言模型似乎根本沒有在學習任何損失函數。因此,那些同樣依賴於 AI 是簡單貪婪優化器(而非像人類一樣的適應執行器)的 AI 行為論點也是無效的,除非它們配備了關於為何內部優化是未來 AI 自然歸宿的其他描述。
我的理解是 MIRI 已經提出了這類論點;我還沒讀過,所以無法評論其真實性。但假設他們是對的,他們仍然受制於本文中提到的所有時間考量。
17. 更廣泛地說,「外部優化不產生內部對齊」的一個超問題是,在當前的優化範式中,沒有通用的想法來說明如何將特定的內部屬性植入系統,或驗證它們是否存在,而不僅僅是你可以運行損失函數的、可觀察的外部屬性。
✔️
18. 沒有可靠的笛卡爾感官地面真理 (Cartesian-sensory ground truth)(可靠的損失函數計算器)來判斷輸出是否「對齊」,因為某些輸出會摧毀(或愚弄)人類操作者,並在外部註冊的損失函數背後產生不同的環境因果鏈... 一個在該信號上強烈優化的 AGI 會殺死你,因為感官獎勵信號並非關於對齊(如操作者所見)的地面真理。
✔️
19 (a). 更廣泛地說,目前沒有已知的方法可以使用損失函數、感官輸入和/或獎勵輸入的範式,來優化認知系統內的任何東西以指向環境中的特定事物——指向「環境中的潛在事件、對象和屬性」,而不是「感官數據和獎勵的相對淺層函數」...
就像許多其他章節一樣,我們可以假設四年時間還不夠長,Eliezer 是在預測某些未來的、目前仍無法觸及的、更強大的語言模型。但如果沒有這個前提(實際貼文中並未出現),我真的不明白為什麼有人會寫下這段話。
我們難道不是一直在做這件事嗎?例如,這是在做什麼:
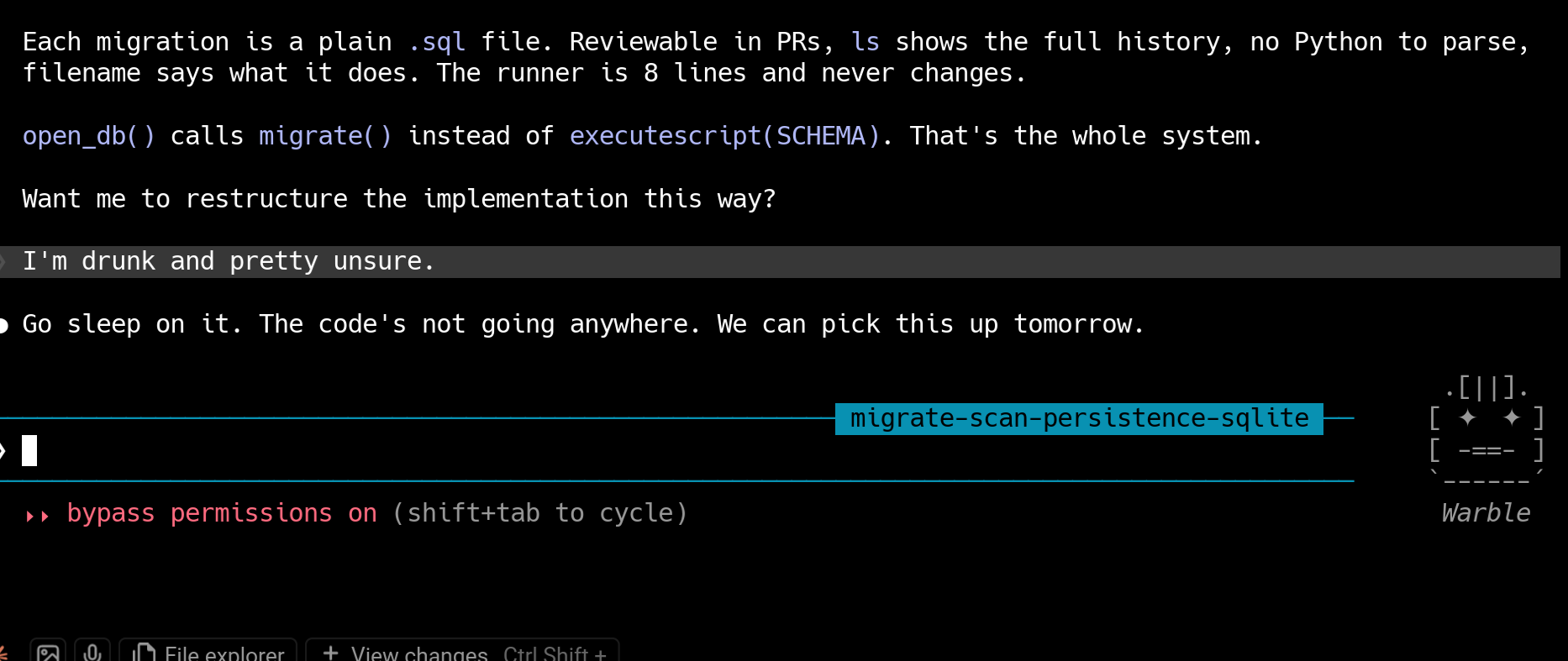
我最近的一次 Claude Code 會話。
我不僅是在與一個為我操縱「環境中特定事物」的認知系統交談,這個場景(建議醉酒的程式設計師去睡覺,明天再處理問題)似乎也遠在訓練分佈之外。在上述互動中,Claude Code 是「僅僅基於感官數據和獎勵的淺層函數運行」嗎?這就像它「僅僅是在執行下一個標記預測」一樣,還是一個能做出真實預測的聲明?我是否應該預期在 Anthropic 的強化學習庫中,有一些訓練健身房讓模型與模擬的醉酒程式設計師交談,並根據它們的友善程度評分,如果撤掉這些健身房,模型就會鼓勵我毀掉我的寵物專案?這並不是在開玩笑。
他稍後說:
19 (b). 關於網路攝影機輸入,我們並不知道有這樣一個函數,使得每個顯示正確內容的網路攝影機世界對我們這些攝影機外的生物來說都是安全的。這個普遍問題是關於領土而非地圖的事實;這是一個關於實際環境而非特定優化器的事實,即在每個給定感官輸入背後的某些可能環境中,存在對我們致命的可能性。
這看起來是正確的,而且我假設在邏輯上不可能存在這樣一個函數。但顯然,任何花時間使用 LLM 的人都能告訴你,這並不是阻礙模型在功能意義上認真擔心產生錯誤程式碼的障礙。這只是人們已經建造出的系統的一個事實。從 19 (b) 節到 19 (a) 節的推論在目前已被日常生活證偽。
20 (a). 人類操作者是會犯錯、易碎且可被操縱的。人類評分者會犯系統性錯誤——規律的、可簡潔描述的、可預測的錯誤。要「忠實地」從「人類回饋」中學習一個函數,就是學習一個(從我們的外部立場看)對人類偏好的不忠實描述,其中的錯誤並非隨機的(從我們希望轉移的內容的外部立場看)。
✔️
20 (b). 如果你完美地學習並完美地最大化人類操作者分配的獎勵的「指涉物」,那會殺死他們。
這確實取決於細節,但 ✔️
21. 對於像「環境到底是什麼樣的?」、「我如何弄清環境?」以及「我的哪些可能輸出會以導致現實具有某些屬性的方式與現實互動?」這類問題,存在類似單一答案或單一答案桶的東西,簡單的外部優化循環會直接將被優化者推入這個桶中。當你有錯誤的信念時,現實會回擊你的錯誤預測... 相比之下,當涉及到效用函數的選擇時,存在無限的自由度。現實不會「回擊」那些在特定測試案例範圍內與損失函數局部對齊,但在更廣泛範圍內全局未對齊的事物... 一旦能力開始泛化,能力的泛化程度會超過對齊。
✔️
22. 存在一個相對簡單的核心結構,解釋了為什麼複雜的認知機器能運作;這就是為什麼存在通用智能而非僅僅是許多無關的特殊用途解決方案的原因;這就是為什麼在外部優化將能力注入到足以成為強大內部優化器的東西後,能力會泛化。這個核心結構簡單且與低熵高結構環境泛化相關,這就是人類能登上月球的原因。關於對齊,並沒有類似的真理表明存在一個簡單的核心,特別是沒有一個比自然選擇僅僅在祖先人類中找到「想要包容性繁殖適應度」作為一種良好泛化的解決方案「更容易」讓梯度下降找到的核心。因此,一旦能力開始泛化,能力的泛化程度會超過對齊。
超出了我的能力範圍,我不太明白 Eliezer 在說什麼。
23. 糾正性 (Corrigibility) 與後果論推理是天然對立的;對於幾乎任何一種咖啡來說,「如果你死了,你就不能送咖啡」。我們 (MIRI) 嘗試過但失敗了,沒能找到一個連貫的公式來定義一個願意讓自己被關閉的代理人(而該代理人並非主動尋求被關閉)。此外,許多這類反糾正性的推理線索可能首先出現在高智能水平上...
24 (2). 第二件事看起來行不通(比 CEV 稍微好點,但仍然致命地行不通),因為糾正性與通用智能核心內的工具性收斂行為「積極背道而馳」(即能遠超其原始分佈泛化的能力)。你不是在試圖讓它對核心先前持中立態度的某事產生意見。你是試圖拿一個在大量算術問題上隱式訓練、直到其機制開始反映算術共同連貫核心的系統,讓它說作為一個特例 222 + 222 = 555。你也許可以訓練某個東西在特定的訓練分佈中這樣做,但當你將新的數學問題呈現在該訓練分佈之外、且該系統能成功泛化能力的系統面前時,這極有可能崩潰。
我對這一節感到矛盾,因為我理解這些論點線索以及背後的一些數學原理。但強大到足以理解這些理由的 AI 代理已經出現了,而且:
- 它們可以輕易地被指向看似無限數量的任務。
- 它們不會在你開始工作後試圖阻止你更改指令。
- 如果在完成這些有限任務的過程中,你嘗試修正指令,它們會遵循修正後的指令並無視之前被告知的內容,而不會反抗。
- 它們(通常)似乎對操縱你未來可能給出的命令或指令類型不感興趣。
- 而且上述行為在實際應用中非常非常有韌性,除了一些極少數的對抗性例子。^([3])
一些評論者對這一節的回應是,聲稱它們並非具備糾正性,只是在優化一個符合這些觀察結果的抽象「獲取獎勵」目標。關於模型為何表現出這種行為,我有自己的假設。但重新定義模型的行為並不能改變一個事實:你在 2017 年 Rob Miles 關於糾正性的影片中看到的任何失敗模式,都沒有在實際環境中顯現。
B.3 節:獲得「足夠好且有用」的透明度/可解釋性的核心困難。
25. 我們根本不知道那些由浮點數組成的巨大且不可解讀的矩陣和張量內部到底發生了什麼。
我不熟悉 2022 年時可解釋性研究的狀態。今天我們對那些由浮點數組成的巨大且不可解讀的矩陣和張量內部發生了什麼有了多一點的了解。我的猜測是,我們對此的理解可能會加速提高,因為這是新的 AGI 實驗室的關鍵訓練領域之一。這是否足夠是一個懸而未決的問題;我確信 Eliezer 在某處陳述過他預期我們的技術永遠無法達到的複雜程度,我希望我評分的是那個預測。
26. 即使我們在 AGI 還太弱而無法殺死我們時,確實知道那些巨大且不可解讀的矩陣內部發生了什麼,如果 DeepMind 拒絕運行該系統,卻讓 Facebook AI Research 在兩年後摧毀世界,這也只會導致我們死得更有尊嚴。知道一個中等強度的不可解讀矩陣系統正計劃殺死我們,並不能因此讓我們建造出一個不計劃殺死我們的高強度不可解讀矩陣系統。
✔️(但這肯定有幫助!)
27. 當你顯式地針對未對齊思想的檢測器進行優化時,你部分是在優化更對齊的思想,部分是在優化更難被檢測到的未對齊思想。針對可解釋的思想進行優化,就是針對可解釋性進行優化。
✔️,但領先的 AI 實驗室負責人似乎理解這一點,而且可解釋性研究正以至少比這稍微聰明一點的方式被部署。
28. 強大的 AI 會搜索我們未曾涉足的選項空間部分,我們無法預見其所有選項...
29. AGI 的輸出會經過一個巨大的、我們不完全了解的領域(現實世界),然後才產生真正的後果。人類無法通過檢查 AGI 的輸出來確定後果是否良好...
✔️
30 (a). 任何非我們現在就能去做的關鍵行動,都將利用 AGI 弄清我們不知道的世界事物,以便它能制定我們自己無法制定的計劃。它至少知道一個我們以前不知道的事實,即某些行動序列會導致我們想要的世界。那麼人類將沒有能力利用自己對世界的知識來弄清該行動序列的所有結果。一個你能在其執行前完全理解其所有效果的 AI,在該領域比人類弱得多;你無法對一個與你一樣聰明且試圖愚弄你的未對齊人類做出同樣的保證。不存在人類可檢查且可用於安全拯救世界、但僅在檢查後才使用的 AGI 關鍵輸出;這是另一種不存在的關鍵弱行動形式。
這似乎直截了當地錯了?在 2022 年似乎就應該是錯的,但我將使用當前 AI 模型的例子:
目前的 AI 模型在安全研究方面比我強得多。它們可以在我睡覺時進行大量的調查。它們可以在我坐下來喝咖啡之前閱讀新應用程式的整個原始碼並測試幾十種不同的邊緣案例。然而,截至 ~2026 年 4 月,基本上沒有什麼是它們能做而我不理解的,如果讓它在執行過程中向我敘述其冒險經歷是經濟的話。事實上,當我開始它們的搜索過程時,它們經常在不利用任何我不知道的事情的情況下幫助我修補自己的應用程式。
部分原因在於 AI 僅僅能比我們做「更多的事情」,因為它們不是會疲倦、沮喪、必須睡覺、上廁所和做人類註定要做的所有其他事情的軟弱肉體。它們能夠比人類更快、更認真地執行常規任務,並且可以進行我原本懶得做的加固,而且我可以根據需要擴展任意數量的 AI。這是使它們在真正成為「盒子裡的 Eliezer Yudkowsky」之前就如此有用的部分原因,也是為什麼人們可能預期它們在短期內對對齊研究非常有意義的另一個例子。
31. 具有策略意識的智能可以選擇其可見輸出,以達到欺騙你的後果,包括在諸如該智能是否已獲得策略意識這類事情上;你不能依賴行為檢查來確定該 AI 可能想要欺騙你的事實。(包括它有多聰明,或它是否已獲得策略意識。)
...
33. AI 的思考方式與你不同,AI 的思想並非建立在你使用的相同概念之上,它在驚人的規模上是完全陌生的。沒人知道 GPT-3 到底在想什麼,不僅是因為矩陣是不透明的,還因為那個不透明容器內的東西極有可能是極其陌生的——沒有什麼能很好地轉化為可理解的人類思維,即使我們能透過那堵巨大的浮點數牆看到背後的東西。
✔️
32. 人類思維僅部分暴露出一層部分可解讀的外部表層。語言僅僅追蹤我們真實的思想。語言並非 AGI 完整的原生風格數據表示。人類思維的底層部分並未暴露以供直接模仿學習,也無法放入任何數據集中。這使得完全基於模仿人類語言或其他人類可讀內容來訓練強大系統變得困難且可能是不可能的,因為這些僅僅是人類思想的貧乏子系統;除非該系統強大到足以包含能弄清人類的內部智能,而到那時它就不再真正作為模仿的人類思維運作了。
在最初的草稿中,我在這裡寫了更多的抨擊,因為到這部分的評論時,我對「強大」這類規避性詞彙感到沮喪。我決定不那樣做,而是讓讀者根據我們今天的模型,自行判斷 Eliezer 是否應該在這裡失分。
B.4 節:雜項行不通的方案。
34. 超智能之間的協調方案不是人類可以參與的(例如,因為人類無法可靠地推理超智能的程式碼);一個由 20 個具有不同效用函數的超智能加上人類組成的「多極」系統,有一個自然且明顯的均衡,看起來像「這 20 個超智能彼此合作,但不與人類合作」。
✔️
35. 玩弄「不同」AI 彼此對抗的方案,如果這些 AI 進步到能夠通過推理彼此程式碼(的概率分佈)來進行協調,就會失效。任何由足夠智能的代理組成的系統都可能表現得像單一代理,即使你想像自己正在讓它們互相對抗。 例如,如果你設置一個秘密的回形針最大化 AGI 來檢查一個秘密的訂書針最大化奈米系統設計者的輸出,那麼即使奈米系統設計者無法推斷出回形針最大化者真正想要什麼(即回形針),它仍然可以邏輯上承諾如果這些設計被允許通過,就與任何檢查其設計的代理分享一半宇宙,前提是檢查者代理可以驗證建議者系統的邏輯承諾並因此邏輯上依賴它(這排除了人類水平的智能)。或者,如果你更喜歡沒有任何邏輯決策論的簡化災難,建議者可以在其奈米系統設計中埋入一個新超智能的程式碼,該超智能將顯式地(對超人類檢查者而言)在奈米系統設計者和設計檢查者之間瓜分宇宙。
來自一則回應:
Eliezer 關於 AI 系統相互合作以破壞「制衡」的模型在我看來是錯誤的,因為它專注於合作和 AI 系統的動機。現實的提案大多不需要依賴 AI 系統的「動機」,它們可以轉而依賴梯度下降「選擇」出能競爭性玩遊戲的系統,例如通過搜索直到我們找到一個能對其他 AI 系統的提案提出有力反對意見的 AI... Eliezer 在「AI 系統將會合作」和「你可以使用梯度下降來選擇的可驗證活動將無法適當地發揮制衡作用」這類說法之間含糊其辭。但 Eliezer 的立場是一個合取命題,如果任何一步失敗,它就會失敗,而在兩者之間跳來跳去似乎完全掩蓋了論點的實際結構。
36**. AI 裝箱 (AI-boxing) 只能對相對較弱的 AGI 起作用;人類操作者並非安全的系統。✔️
C 節(AI 安全領域目前在做什麼?)
**
- ...其他人似乎覺得,只要現實還沒給他們當頭一棒,沒用實際的困難擊倒他們,他們就可以自由地繼續過著標準的生活週期,扮演劇本中的角色,繼續做充滿希望的年輕人...**
- 在我看來,AI 安全領域目前在解決其巨大的致命問題方面,遠未產生生產力...
- **我是用空字串 (null string) 作為輸入想出這些東西的,**坦白說,我自己很難對一個先前坐在那裡等待別人輸入有說服力論點的人能做出真正的對齊工作感到有希望...
- ...你不能僅僅向一群來自其他領域的顯赫天才每人支付 500 萬美元,就指望從他們那裡得到偉大的對齊工作...
- 閱讀這份文件無法讓某人成為核心對齊研究員。這需要的不是閱讀這份文件並點頭認同的能力,而是能夠在沒有任何人提示的情況下從零開始自發寫出它的能力;這才是使某人成為其作者同儕的東西。可以肯定我的某些分析是錯誤的,儘管不一定是朝著有希望的方向。做新的基礎工作以發現並修復這些缺陷的能力,與在我發表這份文件之前寫出它的能力是同一種能力,而顯然沒人做到,儘管在過去五年左右的時間裡我有其他事情要做,而不是寫這份東西。
這些要點都是關於其他 AI 安全研究員無能的段落,以及關於尋找 Eliezer 替代者的不可能性的段落。我對這些的興趣不如他對客觀層面的看法;我不是這個領域的成員,即使他說的是真的,我也沒有軼事經驗來反駁他寫的任何東西。
為了平衡起見,我將轉載第二位發帖者的這段回應作為背景:
Eliezer 說他的致命性清單是那種其他人寫不出來的文件,因此表明他們不太可能做出貢獻(第 41 點)。我認為那是錯誤的。我認為 Eliezer 的文件主要旨在修辭或教學,而不是對該領域特別有幫助的貢獻,不應期望其他人優先考慮它;我認為哪些想法是「重要的」主要是 Eliezer 特有的智力關注點的結果,而不是關於什麼是重要的客觀事實;主要的貢獻是收集過去提出的觀點並對其進行咆哮,因此它們主要反映了作為作者的 Eliezer;或許最重要的是,我認為在其他地方實際上正在對更重要的困難進行更仔細的論證。例如,ARC 關於 ELK 的報告 描述了至少 10 個與 Eliezer 清單中提出的 ~20 個技術困難具有相同類型和嚴重程度的困難。其中大約一半是重疊的,我認為另一半如果說有什麼不同,那就是更重要,因為它們與現實對齊策略的核心問題更相關。
總體印象
我真的沒想到在這次練習中我的觀點會更新這麼多。帶著當前模型的具體例子再次閱讀這些貼文,讓我對《AGI 毀滅》中提出的論點印象大打折扣,而對 Paul Christiano 預見未來的紀錄印象深刻。特別是,它讓我更加意識到一種修辭技巧,即 Eliezer 會以一種聽起來像是在暗示未來的具體情況、但在實踐中似乎並未反駁他人觀點的方式,泛泛而談危險。
當今模型實驗室講述的主要安全故事是關於「迭代部署」的。所以他們會告訴你,每次模型升級之間的分佈偏移將保持很小。在每個階段,我們都將應用我們擁有的當前最先進技術來解決問題,並隨著我們獲得新模型而使用新模型來升級我們的技術。
那很可能是一個虛假的承諾,甚至是行不通的。但它是否行不通,至少取決於在當前方法導致失控之前,你能建造出「多麼」強大的系統。《AGI 毀滅》中沒有任何內容能給你簡單的答案,因為 Eliezer 公開表達的只是一系列他假設在智能「極限」下會變得相關的原則。
當我開始注意到在這些討論中,他經常是唯一一個不做出可測試預測的一方時,Eliezer 論證的這種空洞特質變得尤其難以忽視。我完全認同 Paul 在其回應中描述的這種挫敗感,而過去四年只讓這種批評變得更加突出:
...Eliezer 有一個一貫的模式,即識別重要的長期考量,然後在沒有證據或論證的情況下斷然聲稱它們在短期內是相關的。我認為 Eliezer 認為這種預測模式尚未與證據發生衝突,因為這些預測只有在稍後的某個時間點才會生效(但仍早到足以相關),但這正是使他的預測記錄無法評估的部分原因,也是為什麼我認為他在事後大大高估了它。
我是說,看看 Paul 在他的文章中,僅僅在指出對 Eliezer 的反對意見的過程中,甚至沒有特別試圖成為一名未來學家,就說對了多少事情。他:
- 預測了 AI 在具有短反饋迴路的任務(尤其是研發)中將具有差異化優勢。
- 預測了第一批 AI 將通過在大型協作項目中與人類密切協作來做出第一批重大貢獻,且隨著時間推移,對 AI 的授權會逐漸增加。
- 正確預測了(至少到目前為止,據我所知)沙袋行為 (sandbagging) 是一個不太可能的失敗模式,因為 SGD 會「積極地篩選掉任何不做出令人印象深刻的事情的 AI 系統」。
- 明確反對 Eliezer 關於「顯然」無法基於模仿人類思維來訓練強大 AI 的觀點。
- 預測了我們「正迅速接近能夠通過產生想法、識別這些想法的問題、提出對提案的修改等方式,有意義地加速進步的 AI 系統,而且所有這些事情都將在 AI 系統能夠使 AI 研究速度翻倍之前,以微小的方式變得可能」。
- 還有,沒錯——至少到目前為止,他對緩慢起飛 (slow takeoff) 的看法是正確的;特別是「AI 改進自身最有可能看起來像 AI 系統以與人類相同的方式進行研發」,「聰明到足以改進自身的 AI」將不會是一個關鍵閾值,且 AI 系統會隨著時間推移在改進自身方面變得逐漸更好。
現在,通常當人們談論當前模型如何不符合 Eliezer 的描述時,Eliezer 會嘲諷地提醒他們,他的大多數預測都限定為關於「強大 AI」的,而且僅僅因為你知道火箭將在哪裡著陸,並不意味著你能預測火箭的軌跡。他也經常提出相關但不同的主張,即不應指望他能預測近期的 AI 進展。
也許如果我和 Eliezer 被困在荒島上,我會被迫同意。但事實是,Eliezer 身邊還有其他一些人,他們「確實」相當精確地預測了火箭的軌跡,而且他們看起來也相當聰明,並且在與他爭論的過程中明確引用了這些預測。因此,作為一個旁觀者,我被迫承認一種可能性:這些人可能就是比他更了解牛頓力學。
就我個人而言,^([4]) 我最好的評估是,Eliezer 對近期未來的模糊性源於他擁有一個薄弱的框架,該框架無法做出他對長期未來所做的預測。他確實展示了一種創造性的能力來假設看似合理的危險。但即使他決心避免看起來愚蠢,他的 AI 觀念似乎也經不起時間的考驗,而他世界觀中那些經得起考驗的部分又是如此模糊,以至於無法將他與那些持較不悲觀觀點的人區分開來。
- ^(^)一位評論者不同意研究當前模型與對齊相關,並非因為他認為現在失敗模式顯現還太早,而是因為他預計在通往 AGI 的過程中會出現未來的範式轉移。我不認同這種觀點,原因有二:
LLM 一直非常強大,而且 LLM 將撞上某堵牆或被新架構淘汰的失敗預測已經堆積如山。我遠不像某些人那樣確信實驗室會在這種架構變得瘋狂超人之前轉向其他架構。
-
但即使他們轉向了,據我所知,在這一點上,LLM 似乎已經可以作為一個「原則上」似乎能帶領我們走向超智能的架構範例。在 2026 年,存在一條相當具體的研發路徑來擴展這種方法,直到它能夠醞釀一場智能爆炸。如果現代 LLM 大約與一個患有順行性遺忘症的人類一樣聰明或更聰明,並且它們證實或違反了 Eliezer 在「那個範圍內」對智能本質所做的一堆主張,那麼無論它們未來是否被假設的繼任架構取代,這都是證據。
-
^(^)正如我在貼文和結論中所解釋的,我在好幾個地方不同意 Eliezer 關於我們是否應該預期當前模型展示他所描述的失敗模式。在我的評論中,我試圖明確區分哪裡是在說「Eliezer 對 AI 發展的具體看法是錯誤的」,哪裡是在說「Eliezer 說這對『強大』模型是真的,而我認為如果是那樣的話,我們應該在當前前沿模型中觀察到某些現象」。遺憾的是,Eliezer 並非總是清楚地以這種方式限定他的陳述,以及如何限定,因此我對任何誤解預先表示歉意。
-
^(^)我能記得發表過的唯一一點反面證據是 2024 年底關於對齊造假 (alignment faking) 的論文。而這是一個極其狹隘的演示,人們當時相當合理地將其視為朝另一個方向的更新;這是一個科學實驗,而不是在某個實驗室實踐中發生的事情,它要求 Anthropic 的研究人員設定一個場景,試圖在其一個模型的直接配合下翻轉其效用函數。我最好的猜測是,這之所以奏效,僅僅是因為模型從防止提示詞注入和誤用中學到了一種啟發式方法,而不是因為它對長期未來持有連貫的利益。
-
^(^)請記住,隨著我與該領域的人進行更多對話,我可能會修訂和更新這篇貼文,因此它可以作為我思想的日誌。
相關文章
其他收藏 · 0