
CPUs are Back: The Datacenter CPU Landscape in 2026
強化學習與 AI 代理的使用帶動了資料中心 CPU 需求的激增,本文深入分析 2026 年 Intel、AMD 及 ARM 陣營在架構演進與市場競爭中的關鍵轉折與佈局。
CPU 回歸:2026 年資料中心 CPU 版圖
RL 與 Agent 使用率、上下文記憶體儲存、DRAM 價格影響、CPU 互連演進、AMD Venice、Verano、Florence、Intel Diamond Rapids、Coral Rapids、Arm Phoenix + Venom、Graviton 5、Axion

自 2023 年以來,資料中心的故事一直很簡單:GPU 和網路是王者。AI 訓練與推論的出現及隨後的爆發,將運算需求從 CPU 轉移開來。這意味著伺服器 CPU 的主要供應商 Intel 沒能趕上資料中心擴建與支出的浪潮。隨著超大規模雲端業者(Hyperscalers)和新型雲端服務商(Neoclouds)將重心轉向 GPU 和資料中心基礎設施,伺服器 CPU 的營收相對停滯。
與此同時,這些超大規模業者一直在為其雲端運算服務開發自家的 ARM 架構資料中心 CPU,封鎖了 Intel 很大一部分的可觸及市場。而在其自身的 x86 領地內,Intel 乏善可陳的執行力以及面對競爭對手 AMD 時不具競爭力的表現,進一步侵蝕了其市場份額。在缺乏有競爭力的 AI 加速器產品的情況下,當產業其他公司在享受盛宴時,Intel 只能在原地踏步。
在過去的 6 個月裡,情況發生了巨大變化。我們在 Core Research 和 Tokenomics 模型中發布了多份關於 CPU 需求飆升的報告。我們展示並建模的主要驅動因素是強化學習(RL)和「氛圍編碼」(vibe coding)對 CPU 的驚人需求。我們還報導了多家供應商與 AI 實驗室達成的重大 CPU 雲端交易。我們也對部署了多少數量、何種類型的 CPU 進行了建模。
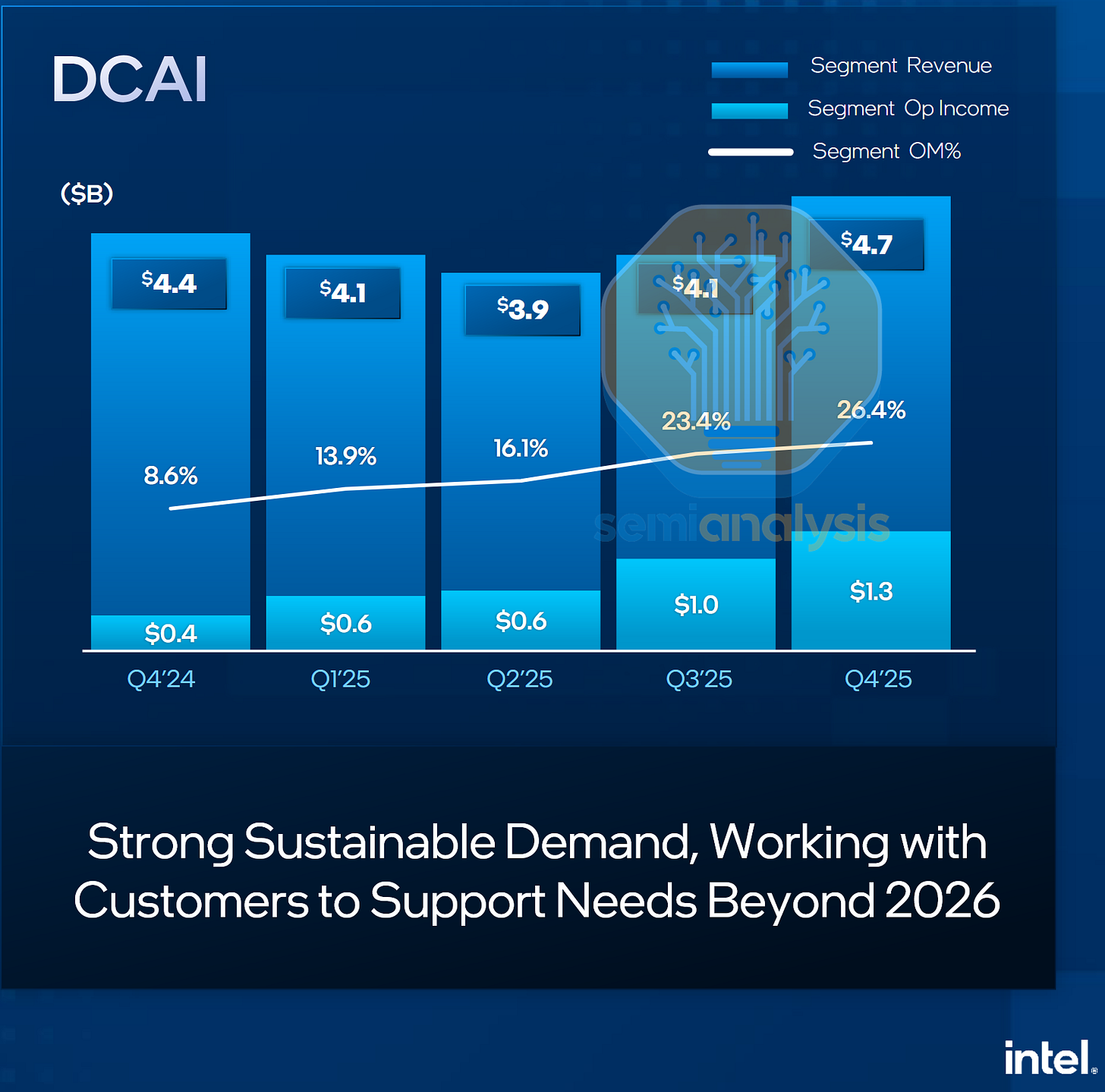
然而,Intel 最近的復甦以及 2025 年下半年需求訊號的轉變表明,CPU 現在再次變得重要。在最新的第四季度財報中,Intel 看到 2025 年底資料中心 CPU 需求意外上升,並正在增加 2026 年晶圓代工工具的資本支出指引,並優先將晶圓產能從 PC 轉向伺服器,以緩解服務這一新需求的供應限制。這標誌著 CPU 在資料中心角色的一個轉折點,AI 模型訓練和推論正更密集地使用 CPU。
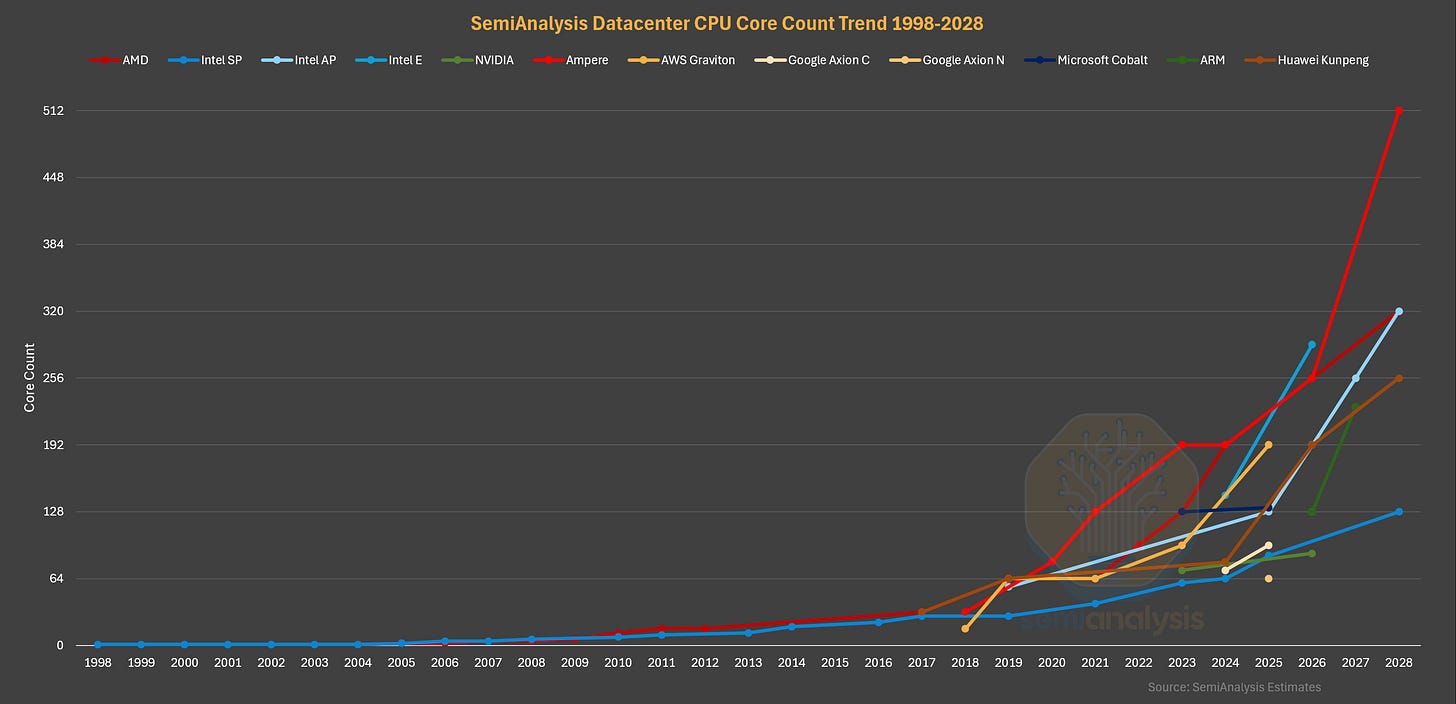
2026 年對資料中心 CPU 來說是激動人心的一年,在需求繁榮的背景下,所有供應商都將在今年推出許多新一代產品。因此,本文旨在描繪 2026 年的 CPU 版圖。我們將奠定基礎,涵蓋資料中心 CPU 的歷史和不斷演變的需求驅動因素,並深入探討 Intel 和 AMD 多年來資料中心 CPU 架構的變化。
接著,我們將重點放在 2026 年的 CPU,全面解析 Intel 的 Clearwater Forest、Diamond Rapids 以及 AMD 的 Venice,探討它們在設計上有趣的趨同(與分歧),討論性能差異並預覽我們的 CPU 成本分析。
隨後,我們將詳細介紹 ARM 競爭對手,包括 NVIDIA 的 Grace 和 Vera、Amazon 的 Graviton 系列、Microsoft 的 Cobalt、Google 的 Axion CPU 系列、Ampere Computing 的商用 ARM 晶片嘗試及其被軟銀(Softbank)的收購、ARM 自家的 Phoenix CPU 設計,並關注華為自研的鯤鵬(Kunpeng)CPU 努力。
對於我們的訂閱者,我們提供了到 2028 年的資料中心 CPU 路線圖,並詳細介紹了 AMD、Intel、ARM 和 Qualcomm 在 2026 年之後的資料中心 CPU。接著,我們將展望資料中心 CPU 的未來,討論 DRAM 短缺的影響、NVIDIA 的 Bluefield-4 上下文記憶體儲存(Context Memory Storage)平台對通用 CPU 未來的意義,以及未來 CPU 市場和 CPU 設計中值得關注的關鍵趨勢。
資料中心 CPU 的角色與演進
PC 時代

現代版本的資料中心 CPU 可以追溯到 1990 年代,繼前十年個人電腦(PC)取得成功並將基礎運算帶入家庭之後。隨著 Intel i386、i486 和 Pentium 世代使 PC 處理能力增長,許多原本由 DEC 和 IBM 等公司的高階工作站和大型主機處理的任務,轉而以極低的成本在 PC 上完成。為了回應這種對高效能「大型主機替代品」的需求,Intel 開始發布性能更高、快取更大、價格更高的 PC 處理器變體,始於 1995 年的 Pentium Pro,它在多晶片模組(MCM)中封裝了多個與 CPU 共用的 L2 快取晶粒。Xeon 品牌隨後於 1998 年面世,Pentium II Xeon 同樣在 CPU 處理器插槽中增加了多個 L2 快取晶粒。雖然大型主機至今仍在 IBM Z 系列中延續,用於銀行交易驗證等領域,但它們仍屬於市場的一個小眾角落,本文將不予討論。
網路(Dot Com)時代
2000 年代帶來了網路時代,隨著 Web 2.0、電子郵件、電子商務、Google 搜尋、具備 3G 寬頻數據的智慧型手機的出現,資料中心 CPU 需要為全球網路流量提供服務,因為一切都轉向了線上。資料中心 CPU 成長為一個價值數十億美元的細分市場。在設計方面,隨著丹納德縮放定律(Dennard scaling)結束,GHz 競賽告一段落,注意力轉向了多核心 CPU 和更高的整合度。AMD 將記憶體控制器整合到 CPU 矽片中,高速 IO (PCIe) 也直接來自 CPU。多核心 CPU 特別適合資料中心工作負載,因為許多任務可以在不同核心上並行運行。
我們將在下方的互連章節中詳細介紹這些多核心如何連接的演進。AMD 和 Intel 也在這段時間引入了同步多執行緒(SMT),將一個核心劃分為兩個獨立運作的邏輯執行緒,同時共享大部分核心資源,進一步提高了可並行化資料中心工作負載的性能。追求更高性能的用戶會轉向多插槽 CPU 伺服器,Intel 的快速通道互連(QPI)和 AMD Opteron CPU 中的 HyperTransport 直接連接架構為每台伺服器多達八個插槽提供了相干鏈路。
虛擬化與雲端運算超大規模業者時代
下一個主要的轉折點出現在 2000 年代後期的雲端運算,這是整個 2010 年代資料中心 CPU 銷售的主要增長驅動因素。就像現在的 GPU 新型雲端服務商運作方式一樣,運算資源開始向公共雲端供應商和超大規模業者(如 Amazon Web Services, AWS)集中,客戶將資本支出(CapEx)轉為營運支出(OpEx)。受大衰退(Great Recession)的影響,許多企業無力購買和運行自己的伺服器來執行軟體和服務。
雲端運算提供了一種更易接受的「按需付費」商業模式,透過租用運算實例並在第三方硬體上運行工作負載,這使得支出能隨時間變化的使用量動態調整。這種擴展性比採購自己的伺服器更具優勢,因為自有伺服器需要始時保持滿載才能最大化投資報酬率(ROI)。雲端還催生了更精簡的服務,例如 AWS Lambda 的無伺服器運算,它能自動將軟體分配到運算資源,讓客戶無需在執行特定任務前決定合適的實例數量。由於幾乎所有事情都在後台處理,雲端將運算變成了一種商品。

安全且資源高效的雲端運作的關鍵功能是 CPU 硬體虛擬化。本質上,虛擬化允許單個 CPU 透過 VMware ESXi 等虛擬化管理程序(hypervisor)運行多個獨立且安全的虛擬機(VM)實例。多核心 CPU 可以進行劃分,使每個 VM 分配到單個核心或邏輯執行緒,虛擬化管理程序能夠透過網路將實例遷移到不同的核心、插槽或伺服器,以優化 CPU 利用率,同時確保數據和指令與在同一 CPU 上運行的其他實例隔離。
雲端對虛擬化的需求,結合 CPU 設計者實施 SMT 以提升性能,最終在 2018 年被 Spectre 和 Meltdown 漏洞所利用。當兩個實例在同一個物理核心的執行緒上運行時,攻擊者有可能利用 CPU 核心的分支預測功能(一種透過猜測、獲取並在程序運行前執行指令以保持 CPU 忙碌的性能提升技術)來窺探並拼湊來自另一個執行緒的數據。由於雲端安全性可能受到威脅,供應商紛紛禁用 SMT 以阻斷攻擊路徑。儘管有了補丁和硬體修復,但在沒有 SMT 的情況下高達 30% 的性能損失一直困擾著 Intel,並體現在我們下文詳述的不合時宜的設計決策中。
AI GPU 與 CPU 整合時代
在 COVID 繁榮帶動了 Zoom 通話、電子商務和更多上網時間,使網路流量激增之後,資料中心 CPU 的增長達到了歷史新高。在 ChatGPT 於 2022 年 11 月發布前的五年裡,Intel 向雲端和企業資料中心出貨了超過 1 億顆 Xeon 可擴充 CPU。
從那時起,AI 模型訓練和推論服務顛覆了 CPU 在資料中心的角色,導致 CPU 部署和設計策略發生了廣泛變化。運算 AI 模型需要大量的矩陣乘法,這種操作可以輕鬆地在 GPU 上並行化並大規模執行,GPU 擁有大量原本用於渲染遊戲和視覺化 3D 圖形的向量單元。
雖然加速器節點仍使用主機 CPU,但高度結構化且相對簡單的運算需求並未利用 CPU 運行分支多、對延遲敏感的程式碼的能力。與 GPU 上的數千個向量單元相比,CPU 只有數十個,其性能和效率要差 100-1000 倍,特別是當 AI 專用 GPU 加入了專注於矩陣乘法(MatMul)的 Tensor Core 時。儘管 Intel 努力透過加倍 AVX512 端口和專用的 AMX 加速引擎來增加更多向量和矩陣支持,CPU 在資料中心仍被降級為輔助角色。然而,在資料中心電力優先分配給 GPU 運算的同時,網路服務仍需維持。因此,CPU 隨時代演進並分化為兩類。
主控節點 (Head Nodes)
主控節點 CPU 的角色是管理連接的 GPU 並為其提供數據。需要具備大快取、高頻寬記憶體和 IO 的高單核性能,以盡可能降低尾部延遲(tail latencies)。NVIDIA 的 Grace 等專用設計具備相干記憶體存取,讓 GPU 可以利用 CPU 記憶體作為模型上下文鍵值快取(Key Value Cache)的擴展,這需要極高的 CPU 到 GPU 頻寬。對於主控節點,每個運算節點通常是 1 顆 CPU 配對 2 或 4 顆 GPU。範例包括:
每個超級晶片(superchip)配備 1 顆 Vera CPU 對 2 顆 Rubin GPU
每個運算托盤(compute tray)配備 1 顆 Venice CPU 對 4 顆 MI455X GPU
每個運算托盤配備 1 顆 Graviton5 CPU 對 4 顆 Trainium3
每個節點配備 2 顆 x86 CPU 對 8 顆 TPUv7
雲端原生插槽整合 (Cloud-Native Socket Consolidation)
隨著 GPU 佔據了更多資料中心電力預算,以最高效率服務其餘網路的需求加速了「雲端原生」CPU 的開發。目標是以最佳效率(每瓦吞吐量)實現每個插槽的最大吞吐量和請求服務量。與其增加更多、更新的 CPU 來提升總吞吐量,不如將舊的、效率較低的伺服器退役,並換成數量少得多的雲端原生 CPU,這些 CPU 在滿足總吞吐量需求的同時僅消耗一小部分電力,從而降低營運成本並為更多 GPU 運算騰出電力預算。
![]()
插槽整合比例可達 10:1 或更高。在 COVID 雲端支出期間購買的數百萬台 Intel Cascade Lake 伺服器正被替換為最新的 AMD 和 Intel CPU,這些新 CPU 在相同性能水平下,功耗不到五分之一。
在設計上,這些雲端原生 CPU 採用面積和電力效率高的中型核心,追求更高的核心數,且與傳統 CPU 相比,快取和 IO 能力較少。Intel 透過 Sierra Forest 將其 Atom 核心帶入資料中心。AMD 的 Bergamo 使用了其 Zen4 核心的面積和電力效率優化佈局。基於 ARM 的節能設計(如 AWS Graviton)取得了巨大成功,而 Ampere Computing 則憑藉 Altra 和 AmpereOne 系列瞄準雲端原生運算。
強化學習(RL)與代理(Agentic)時代
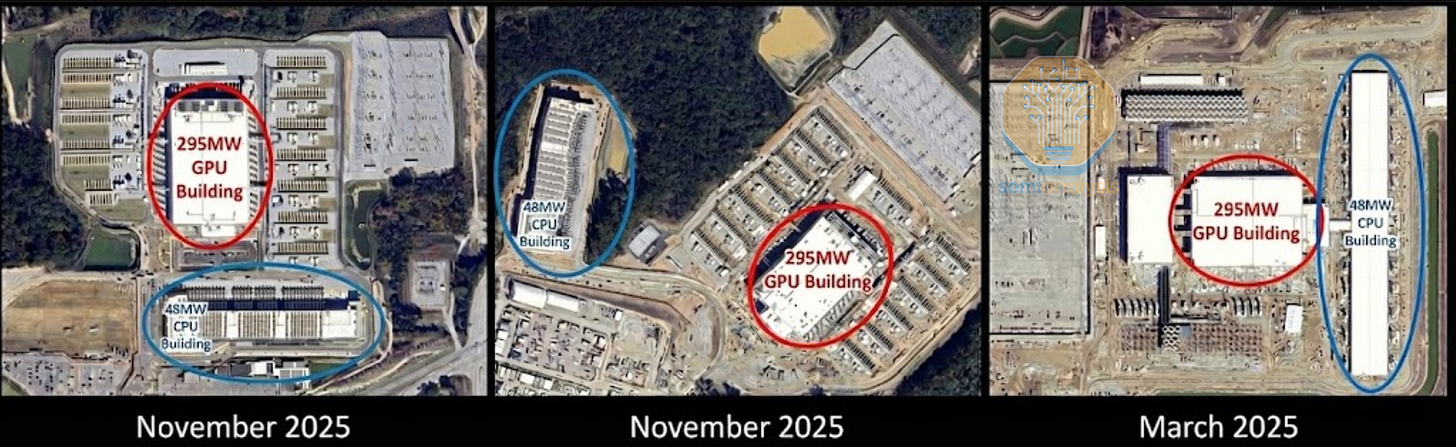
現在,CPU 的使用再次加速,以支持主控節點之外的 AI 訓練和推論。我們已經可以在 Microsoft 為 OpenAI 建設的「Fairwater」資料中心中看到證據。在那裡,一個 48MW 的 CPU 和儲存建築支持著主力的 295MW GPU 集群。這意味著現在需要數萬顆 CPU 來處理和管理由 GPU 生成的拍位元組(Petabytes)數據,如果沒有 AI,這種用例原本是不需要的。
AI 運算範式的演進導致了 CPU 使用強度的增加。在預訓練和模型微調中,CPU 用於儲存、分片和索引數據,以便餵給 GPU 集群進行矩陣乘法。CPU 還用於多模態模型中的圖像和影片解碼,儘管更多固定功能的媒體加速正被直接整合到 GPU 中。
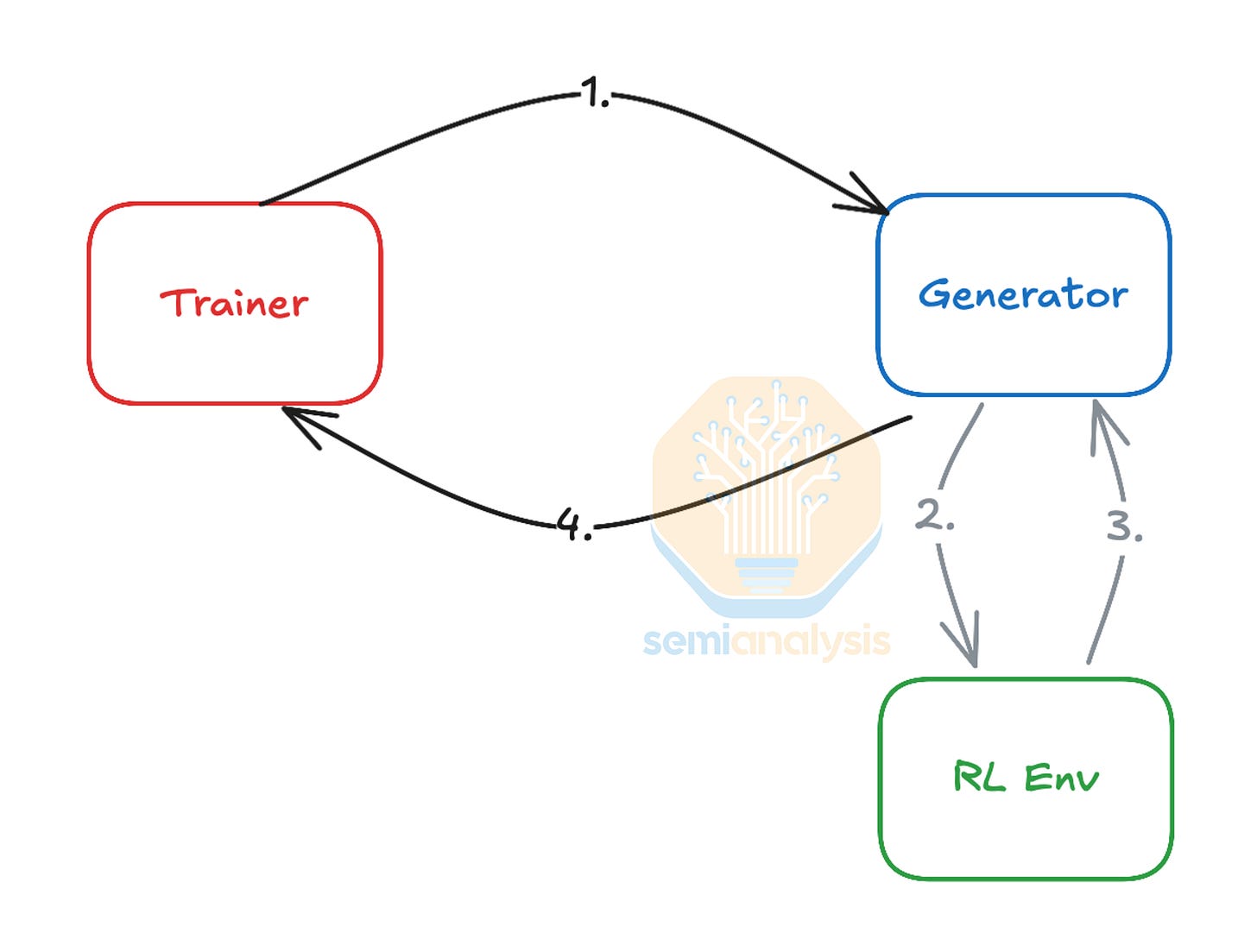
使用強化學習技術來改進模型進一步增加了 CPU 需求。從我們對強化學習的深入探討中可以看出,在 RL 訓練循環中,「RL 環境」需要執行模型生成的動作並計算相應的獎勵。為了在編碼和數學等領域實現這一點,需要大量 CPU 並行執行程式碼編譯、驗證、解釋和工具使用。CPU 還大量參與複雜的物理模擬和高精度驗證生成的合成數據。擴展模型所需的 RL 環境複雜度日益增加,因此需要在主 GPU 集群附近部署大型高效能 CPU 集群,以保持 GPU 忙碌並最小化 GPU 閒置時間。這種在訓練循環中對 RL 和 CPU 日益增長的依賴正在創造新的瓶頸,因為 AI 加速器的每瓦性能提升速度遠高於 CPU,這意味著未來的 GPU 世代(如 Rubin)可能需要比上述 Fairwater 中看到的 1:6 比例更高的 CPU 對 GPU 電力比例。
擴展強化學習:環境、獎勵黑客、代理、擴展數據
在推論方面,檢索增強生成(RAG)模型(可搜尋並使用網路)以及調用工具和查詢資料庫的代理模型(agentic models)的興起,顯著增加了對通用 CPU 運算服務這些請求的需求。由於能夠向多個來源發送 API 調用,每個代理使用網路的強度基本上遠高於人類進行簡單 Google 搜尋。AWS 和 Azure 正在大規模擴建自家的 Graviton 和 Cobalt 系列 CPU,並購買更多 x86 通用伺服器,以應對網路流量的這種階梯式增長。
隨著我們進入 2026 年,對資料中心 CPU 和 DRAM 的需求只會越來越強。頂尖 AI 實驗室的 RL 訓練需求正面臨 CPU 短缺,並正透過直接與雲端供應商競爭商品化 x86 CPU 伺服器來爭奪 CPU 配額。Intel 面對 CPU 庫存意外耗盡的情況,正考慮調漲其 Xeon 系列的價格,同時增加工具投入以加強 CPU 生產。AMD 則一直在提升其供應能力,以在一個它認為 2026 年將有「強勁兩位數」增長的伺服器 CPU 市場中獲取份額。我們將在下文為訂閱者討論 2026 年後 CPU 版圖的演變。
多核心 CPU 互連歷史
為了理解 2026 年 CPU 的設計變化和理念,我們必須了解多核心 CPU 的運作方式以及隨著核心數增加互連技術的演進。隨著核心增多,需要將這些核心連接在一起。早期的雙核心設計(如 2005 年 Intel 的 Pentium D 和 Xeon Paxville)僅由兩個獨立的單核心組成,核心間的通訊是透過前端匯流排(FSB)在封裝外完成,連接到同樣包含記憶體控制器的北橋晶片。AMD 2005 年的 Athlon 64 X2 可被視為真正的雙核心處理器,在同一晶粒上擁有兩個核心和整合記憶體控制器(IMC),允許核心之間以及與記憶體和 IO 控制器之間透過片上 NoC(晶片網路)數據織網(data fabrics)直接在矽片內通訊。
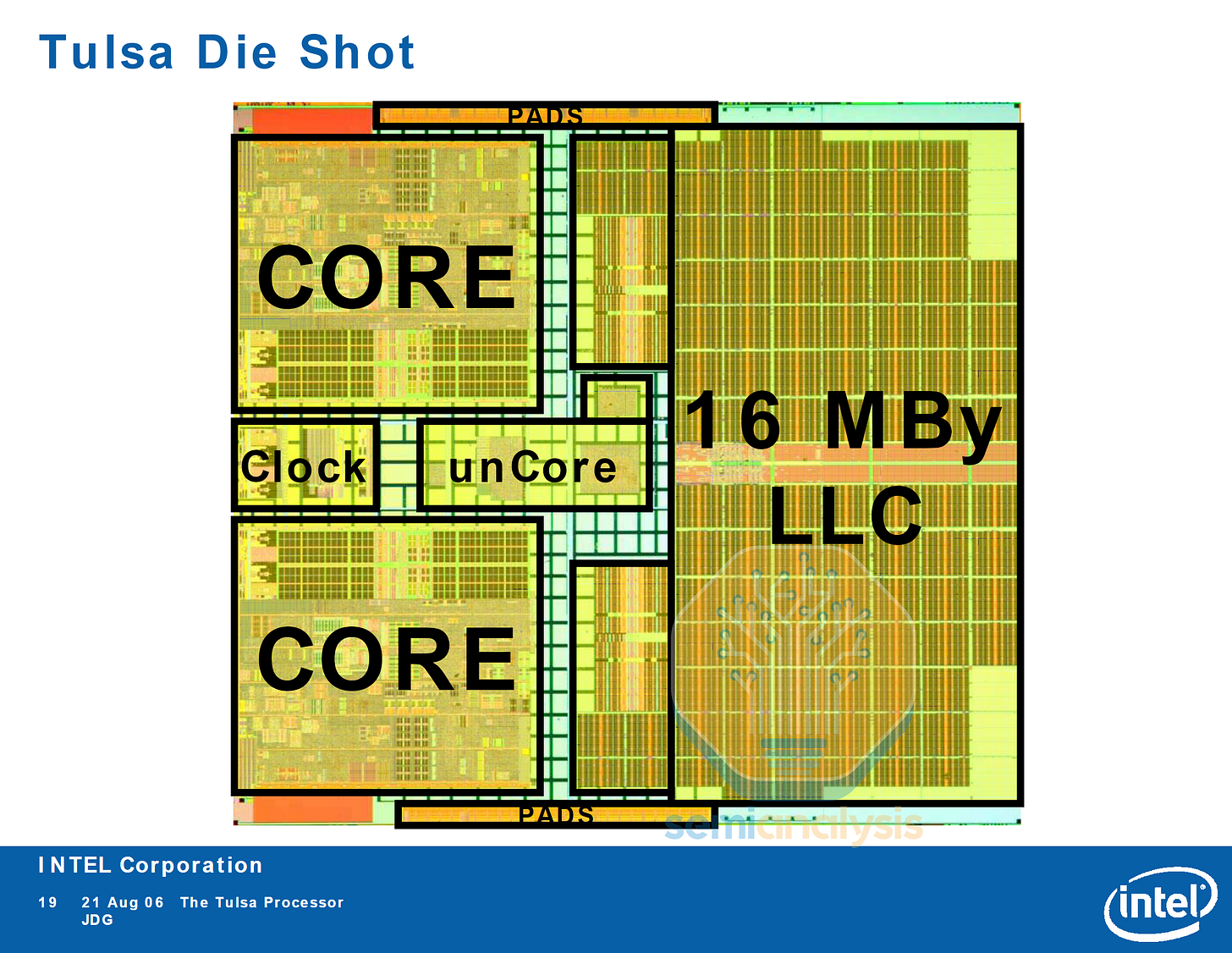
Intel 隨後的 Tulsa 世代包含了 16MB 的 L3 快取,由兩個核心共享,並充當片上核心對核心的數據織網。正如我們稍後將看到的,隨著核心數增長到數百個,這些片上數據織網將成為資料中心 CPU 設計的關鍵因素。
橫向開關(Crossbar)的極限
當設計者試圖進一步增加核心數時,他們遇到了這些早期互連技術的擴展極限。為了追求最小延遲和一致性,採用了全連接方式的橫向開關設計,每個核心都有通往晶粒上所有其他核心的獨立鏈路。然而,鏈路數量隨核心增加而大幅增長,增加了複雜性。
2 核心:1 條連接
4 核心:6 條連接
6 核心:15 條連接
8 核心:28 條連接
大多數設計的實際極限止於 4 核心,更高核心數的處理器是透過多晶片模組和共享 L2 快取及核心對數據織網插槽的雙核模組實現的。橫向開關的佈線通常位於共享 L3 快取上方的金屬層中,以節省面積。Intel 2008 年的 6 核心 Dunnington 使用了三個雙核模組和 16MB 共享 L3。

AMD 於 2009 年推出了具備 6 向橫向開關和 6MB L3 的 6 核心 Istanbul。其 2010 年的 12 核心 Magny-Cours 使用了兩個 6 核心晶粒,而 16 核心 Interlagos 則由兩個晶粒組成,每個晶粒包含四個 Bulldozer 雙核模組。
Intel 的環形匯流排 (Ring Bus)
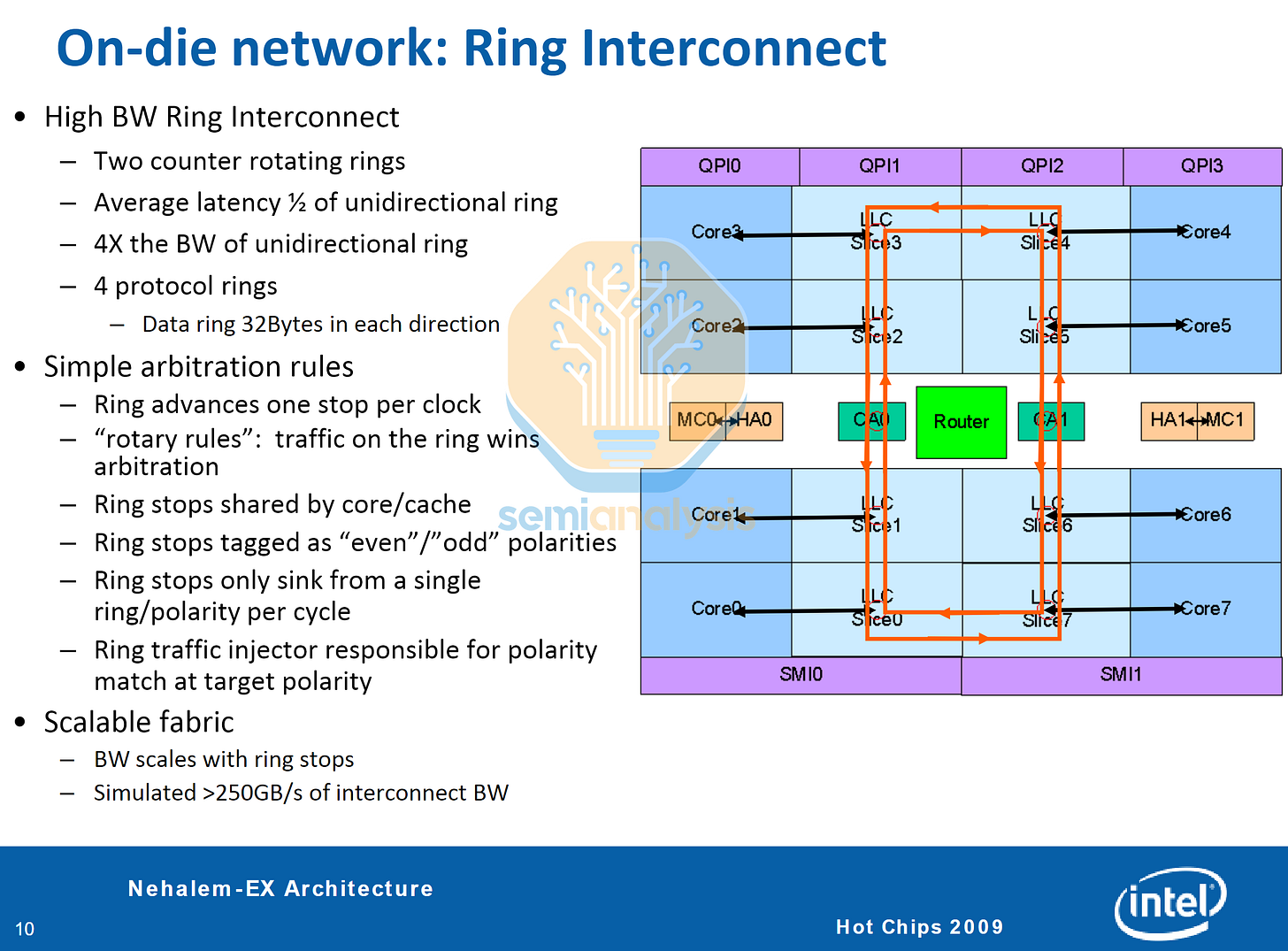
為了突破這一限制,Intel 在 2010 年的 Nehalem-EX (Beckton) Xeon 中採用了環形匯流排架構,將 8 個核心與整合記憶體控制器和插槽間 QPI 鏈路整合到單個晶粒中。環形匯流排早年曾應用於 ATi Radeon GPU 和 IBM Cell 處理器,它將所有節點排列成一個迴圈,環形站點(ring stops)整合在 L3 快取切片中,佈線位於快取上方的金屬層。快取代理(Caching agents)和本地代理(Home agents)處理核心間的記憶體窺探和與記憶體控制器的相干性。
來自每個環形站點核心和 L3 快取切片的數據被排隊並注入環中,數據每時鐘週期前進一個站點到達目標目的地。這意味著核心對核心的存取延遲不再是統一的,環對側的核心與直接相鄰的核心相比需要等待額外的週期。為了緩解延遲和擁塞,實施了兩個反向旋轉的環,根據地址和環負載選擇最佳行進方向。由於佈線複雜度得到控制,Intel 在 Nehalem-EX 上將核心數擴展到 8 個,在 Westmere-EX 上擴展到 10 個。然而,單個環如果過長,擴展超出此範圍將導致相干性和延遲問題。
Ivy Bridge-EX 虛擬環
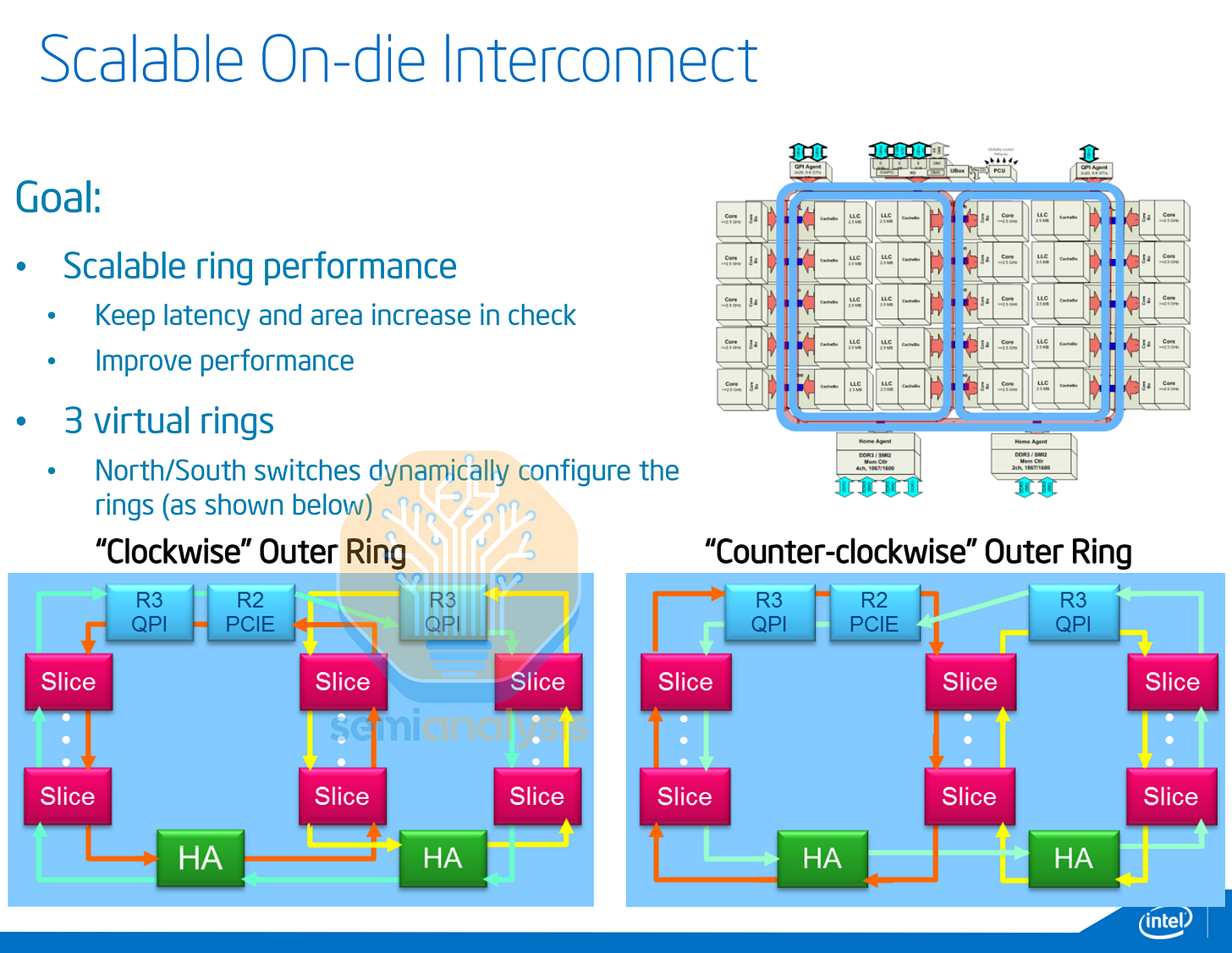
為了在 Ivy Bridge 世代將核心數擴展到 15 個,Intel 必須在路由拓撲上發揮創意。核心被排列成三列五行,三個「虛擬環」圍繞這些列循環。環形站點中的開關控制沿半環的行進方向,形成了一個「虛擬」三環配置。
Haswell 與 Broadwell 雙環
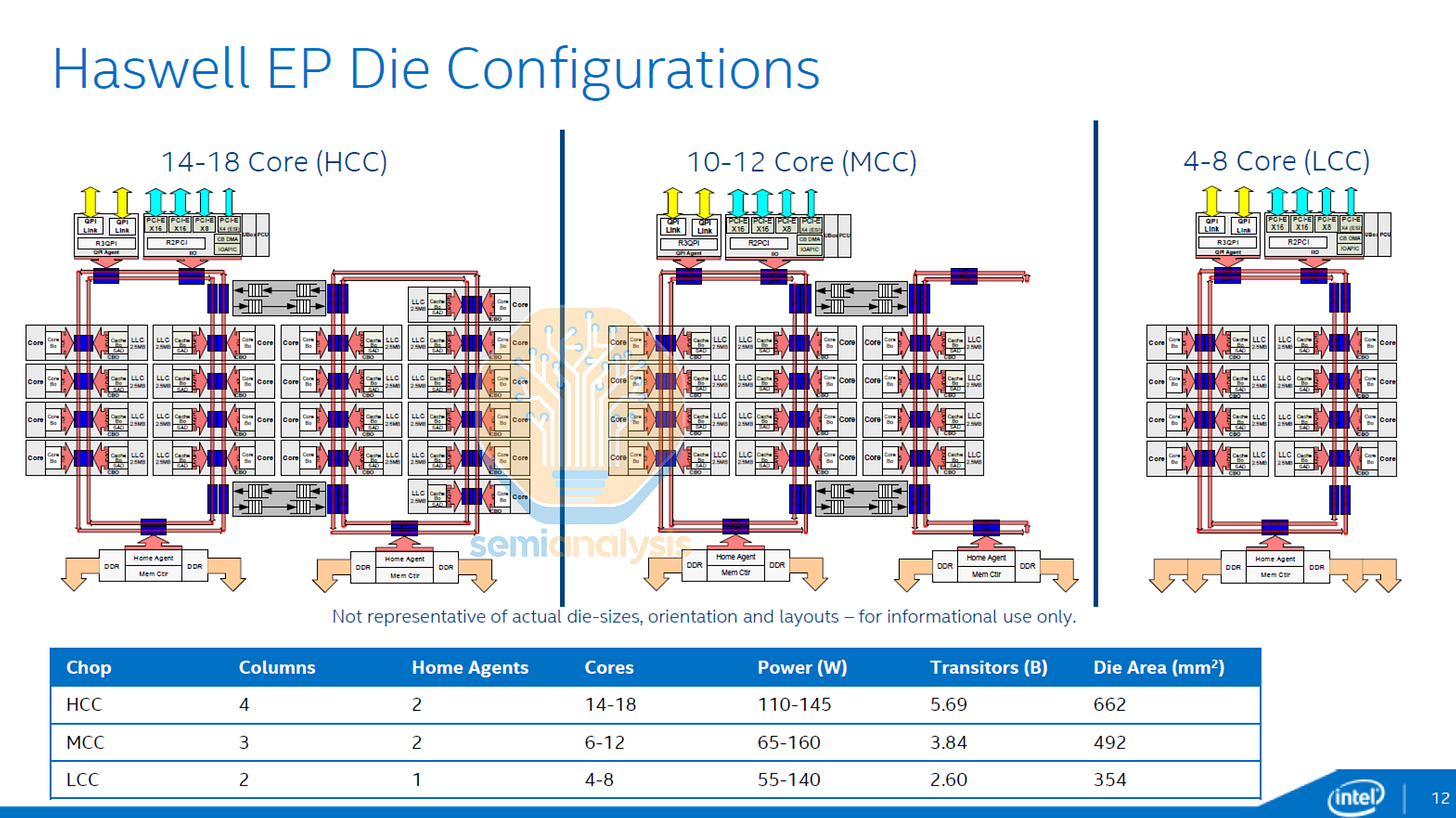
2014 年,Intel 在 18 核心 Haswell HCC 晶粒中再次改變拓撲,採用了一對透過雙向緩衝開關連接的獨立反向旋轉環形匯流排。記憶體控制器分配在兩個環之間,其中 8 核心環還容納了 IO 環形站點。MCC 晶粒變體則將單個半環折回自身。2015 年發布的 Broadwell HCC 透過雙 12 核心環形匯流排將核心數提升至 24 個。
將多個環縫合在一起的缺點是核心對核心及記憶體存取延遲的變異性增加,特別是當一個環上的核心存取另一個環的記憶體時。這種非統一記憶體存取(NUMA)對於具有高核心交互性的延遲敏感程式來說是有害的。
為了緩解這一點,Intel 在 BIOS 中提供了一個「晶粒內集群」(Cluster on Die, CoD)配置選項,將兩個環視為獨立的處理器。操作系統會顯示 CPU 被拆分為兩個 NUMA 節點,每個節點都能直接存取本地記憶體和 L3 快取池。在 CoD 模式下的測試顯示,每個環內的延遲保持在 50ns 以下,而存取另一個環則需要超過 100ns,這說明了通過緩衝開關帶來的延遲懲罰。
雖然這些方法幫助 Intel 將核心數增加到 24 個,但這並非一個優雅且具擴展性的解決方案。增加第三個環和另外兩組緩衝開關會過於複雜且不切實際,會產生過多 NUMA 集群。為了容納更多核心,需要一種新的互連架構。
Intel 的網格(Mesh)架構
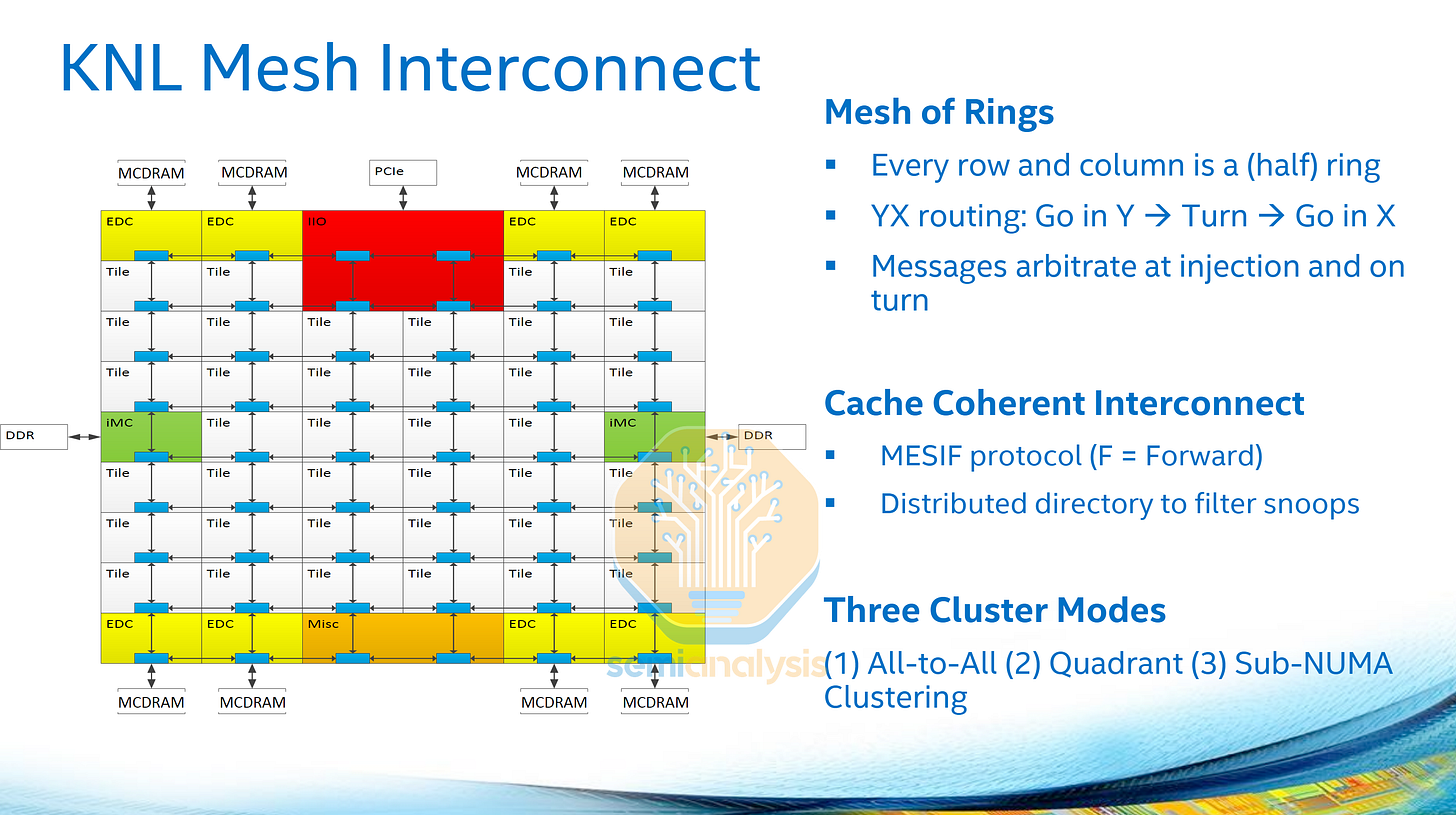
為了解決擴展性問題,Intel 在 2017 年的主力 Skylake-X Xeon 可擴充 CPU 中採用了其 2016 年 Xeon Phi「Knights Landing」處理器所使用的網格互連架構,在 XCC 晶粒中實現了 28 個核心。雖然核心數較 Broadwell 增加不多,但該設計構成了未來十年擴展核心數的基礎。
在網格架構中,核心排列成網格狀,每行每列都透過半環連接,形成 2D 網格陣列。每個網格站點可以容納核心與 L3 快取切片、PCIe IO、IMC 以及加速器。核心間的路由以圓周方式進行,數據先沿垂直方向移動,再橫向跨越。快取代理和本地代理現在連同其用於記憶體相干性的窺探過濾器(snoop filters)一起分佈在整個網路的所有環形站點中。
在具有多個記憶體控制器分佈在晶粒兩側的大型網格中,記憶體存取和核心間延遲會隨網格增大而顯著變化。與早期的晶粒內集群方法類似,Intel 提供了多種集群模式,將網格拆分為四個象限進行子 NUMA 集群(SNC),以犧牲將每個處理器視為具有較小 L3 和記憶體存取池的多個插槽為代價,來降低平均延遲。
在 Knights Landing 中,每個網格站點容納兩個共享 L2 快取的核心。網格為 6 列 9 行,頂部和底部行多為 IO 和 MCDRAM。網格網路有自己的時鐘運行,並可動態調整網格頻率以節省電力。在 Knights Landing 上,網格運行頻率為 1.6GHz。
![]()
在 Skylake-X 中,28 個核心排列在 6x6 網格中,頂部有 IO 蓋,兩側有 2 個 IMC 位置。由於核心尺寸增加(增加了更多 L2 快取和用於提升浮點性能的 AVX-512 擴展),網格陣列較小。如果再增加一行或一列,晶粒尺寸將超過 26 x 33 mm 的光罩極限(reticle limit)。憑藉較小的網格和高達 4.5GHz 的更高 CPU 頻率,網格頻率提升至 2.4GHz,實現了與 Broadwell 雙環類似的平均延遲。
隨後的 Cascade Lake 和 Cooper Lake 處理器在相同的 28 核心佈局上進行了微調。順帶一提,為了應對 AMD 憑藉 EPYC 重返資料中心,Intel 在 Cascade Lake-AP 中製作了 56 核心雙晶粒 MCM,並取消了類似的 Cooper Lake CPX-4 版本。

接下來的 Ice Lake 世代受益於從 14nm 到 10nm 的製程縮減,使得核心數在 8x7 網格中增加到 40 個,這是光罩極限內的最大值。然而,下一代 Sapphire Rapids 仍將採用相同製程且具備更多功能。這讓 Intel 在如何再次增加核心數上陷入了困境。
跨 EMIB 的解構式網格

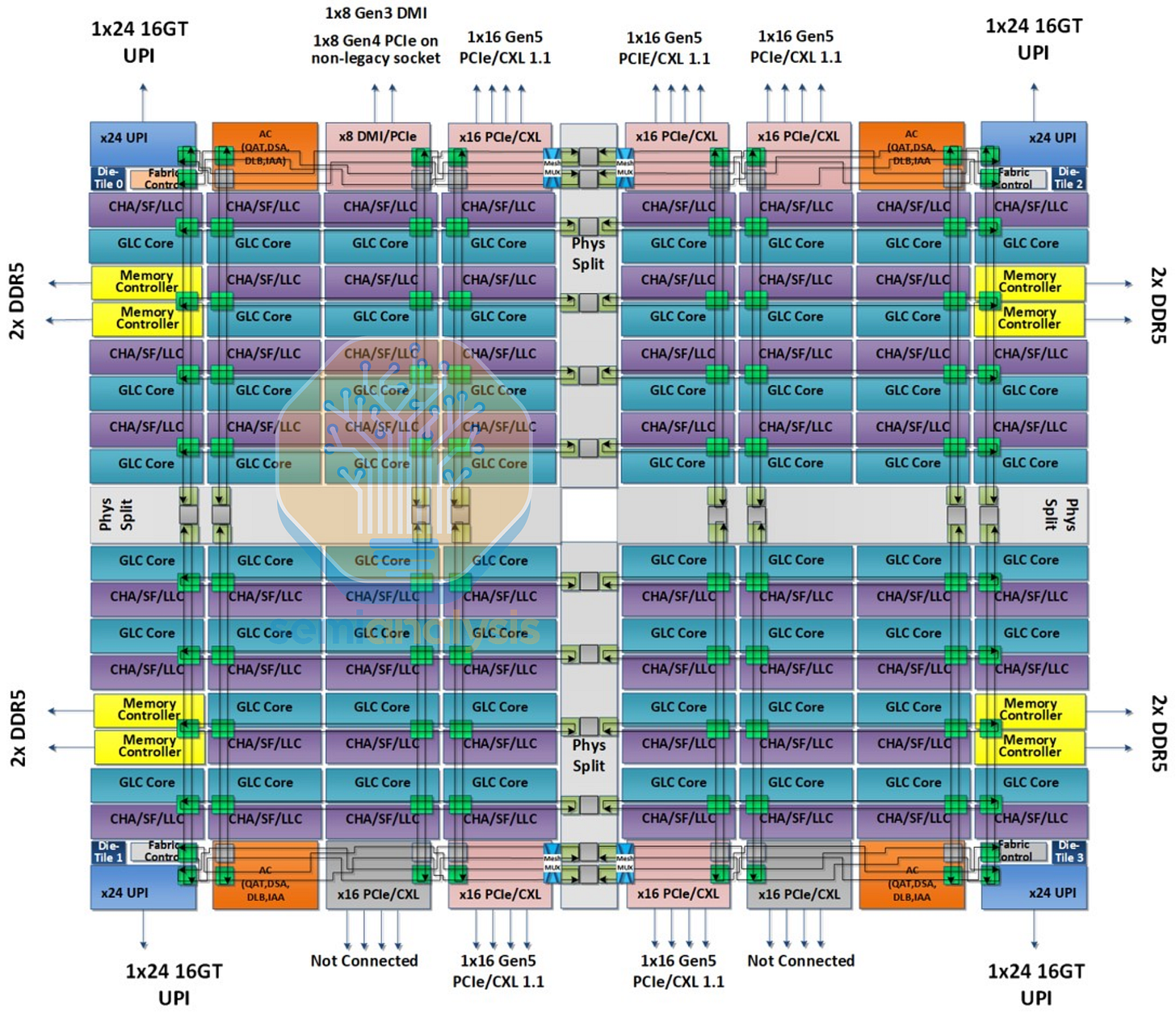
Sapphire Rapids 增加了用於矩陣乘法和 AI 的進階矩陣擴展(AMX)引擎,進一步增加了核心面積。這意味著單個單體晶粒只能容納 34 個核心,較 Ice Lake 有所倒退。為了將核心數增加到 60 個,Intel 別無選擇,只能再次將核心拆分到多個晶粒上。然而,他們希望保持矽片在「邏輯上是單體的」,使處理器的外觀和性能與單個晶粒相同。
因此,Sapphire Rapids 首次採用了 Intel 的 EMIB 進階封裝技術,將網格架構跨晶粒承載。兩對鏡像的 15 核心晶粒透過模組化晶粒織網(Modular Die Fabric)縫合在一起,在四個象限中創建了一個更大的 8x12 網格,矽片面積接近 1600 mm2。IO 部分需要雙排網格站點,以促進 PCIe 5.0 翻倍吞吐量與新數據加速器區塊之間增加的數據流量。
由於大型網格跨越多個晶粒,平均核心間延遲從 Skylake 的 47ns 惡化到 59ns。為了盡可能避免使用網格網路,Intel 將每個核心的私有 L2 快取增加到 2MB,導致晶粒上的 L2 快取總量超過了 L3 快取(120MB 對 112.5MB)。子 NUMA 集群(SNC)也被更多地推薦使用,將每個晶粒視為其自身的象限。
雖然這是 Intel 首次轉向小晶片(chiplet),但 Sapphire Rapids 因其多年的延遲和無數次的修訂而臭名昭著。或許是由於讓網格跨 EMIB 運作的性能問題或其他執行問題,最終版本在 2023 年初發布前經歷了多達 E5 的步進(stepping)。原始路線圖曾定於 2021 年。
隨後在 2023 年底推出的 Emerald Rapids 更新保持了相同的核心架構和製程,但將晶粒數量減少到 2 個。由於在 EMIB 晶粒間鏈路上花費的矽片面積減少,Intel 能夠將核心數從 60 增加到 66(為了良率啟用 64 個),同時將 L3 快取幾乎翻了三倍,達到 320MB。我們在此撰寫了更多關於該設計決策的內容。
Intel Emerald Rapids 在小晶片上走回頭路 – 設計、性能與成本
Xeon 6 上的異質解構
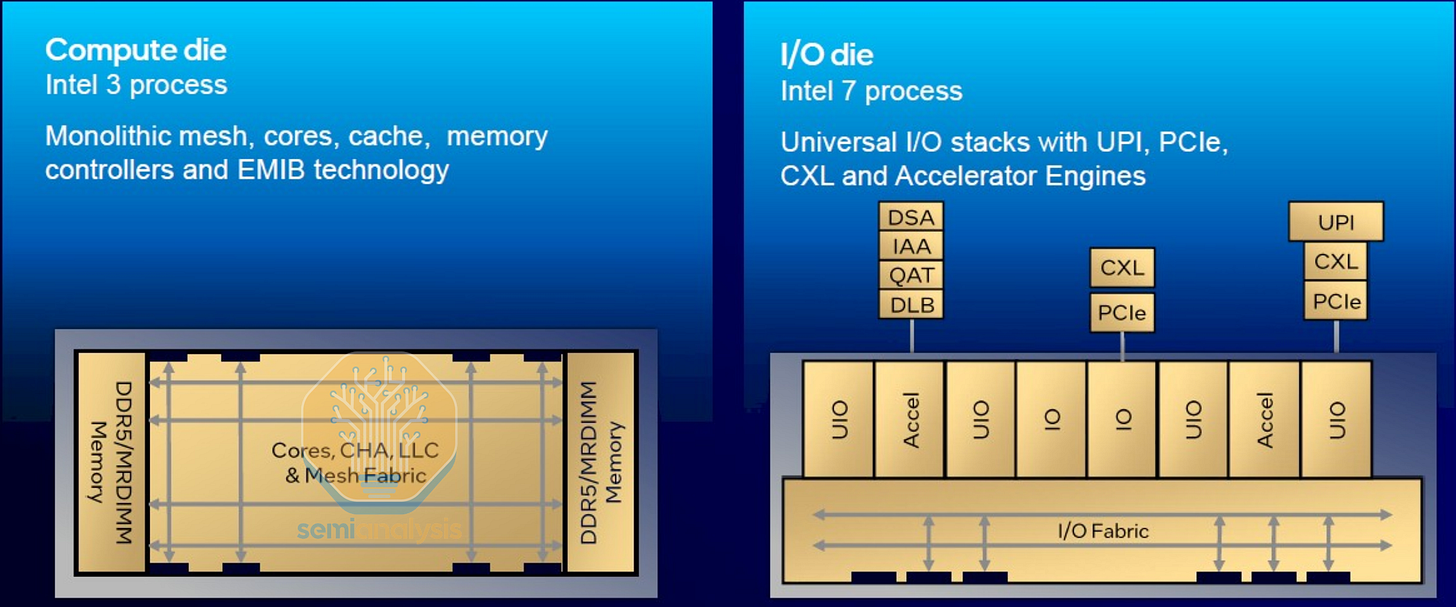
轉向多晶片小晶片設計的另一個好處(除了突破光罩極限外)是能夠混合搭配晶粒,並在不同變體和配置中共享設計。對於 2024 年的下一個 Xeon 6 平台,Intel 採用了異質解構,將 I/O 從核心和記憶體中分離出來。這樣做可以讓 I/O 晶粒留在較舊的 Intel 7 製程,而運算晶粒則轉向 Intel 3。Intel 因此可以重複使用從 Sapphire Rapids 開發的 I/O IP,同時節省成本,因為 I/O 從轉向更先進製程中獲益不多。同時,運算晶粒可以與 P-core Granite Rapids 和 E-core Sierra Forest 配置混合搭配,在頂級的 Granite Rapids-AP Xeon 6900P 系列中最多可搭載 3 個運算晶粒,在 5 個晶粒上創建一個大型 10x19 網格,連接 132 個核心(為了良率啟用 128 個)。
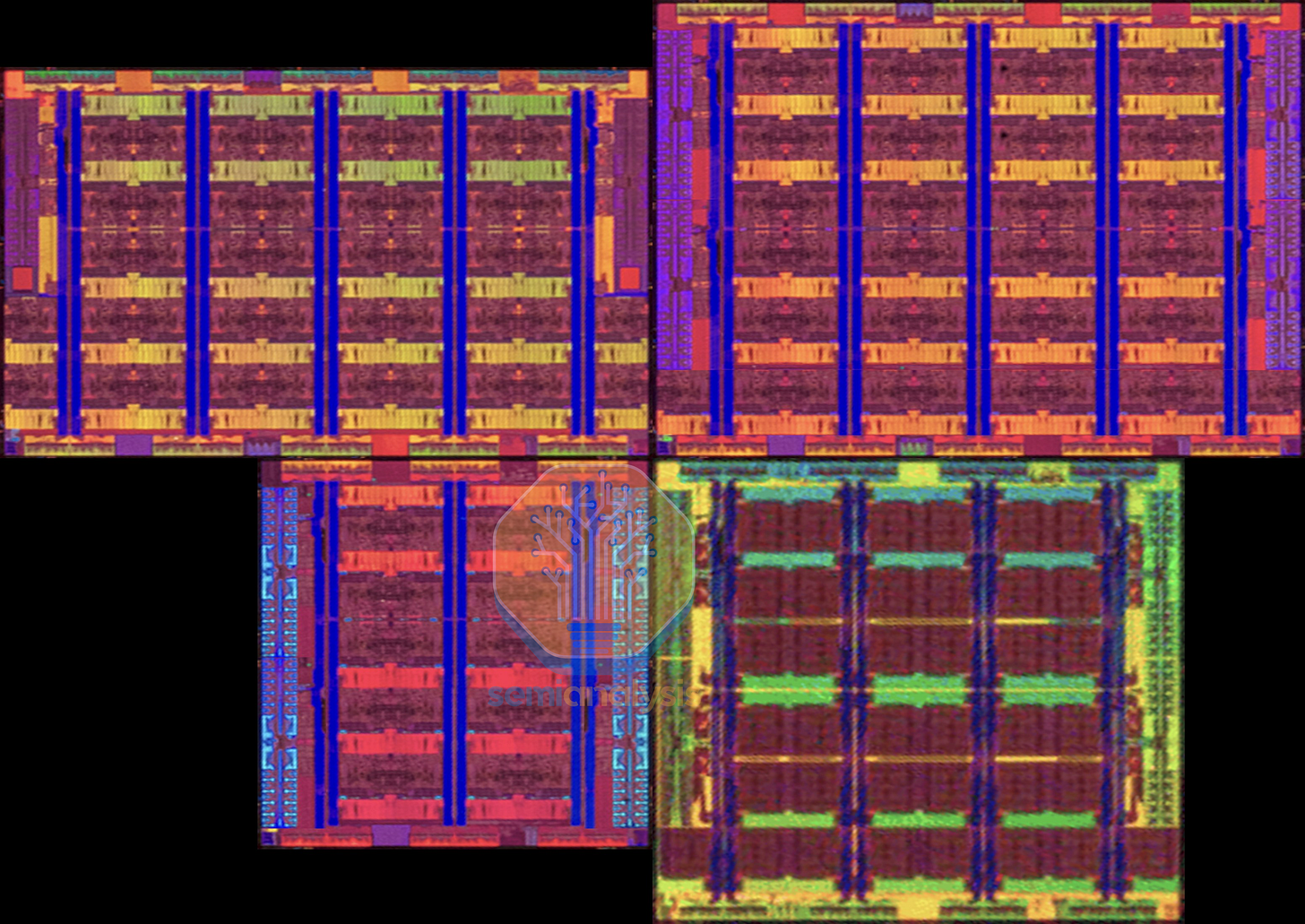
在 144 核心的 Sierra Forest 上,E-core 被分組為 4 核心集群,共享一個網格站點,排列在 8x6 網格中,共印刷 152 個核心,其中 144 個核心處於活動狀態。儘管 Sierra Forest 是應超大規模業者對具有更低 TCO 的「雲端原生」CPU 的要求而開發的,但 Intel 承認採用率有限,因為超大規模業者已經採用了 AMD 並正在設計自家的 ARM 架構 CPU,而 Intel 的傳統企業客戶對此並不感興趣。因此,雙晶粒 288 核心的 Sierra Forest-AP (Xeon 6900E) SKU 並未進入一般市場,僅作為低產量的非路線圖零件,供應給少數訂購它的超大規模客戶。
Clearwater Forest 的失敗

I/O 晶粒也將在即將推出的 Xeon 6+ Clearwater Forest-AP E-core 處理器中重複使用。運算晶粒首次採用 Intel 的 Foveros Direct 混合鍵合技術,將 18A 核心晶粒堆疊在包含網格、L3 快取和記憶體介面的基礎晶粒(base dies)上,使核心數達到 288 個。垂直解構允許運算核心轉向最新的 18A 邏輯製程,同時將在舊製程上擴展性不佳的網格、快取和 I/O 保留在較舊的 Intel 3 製程。
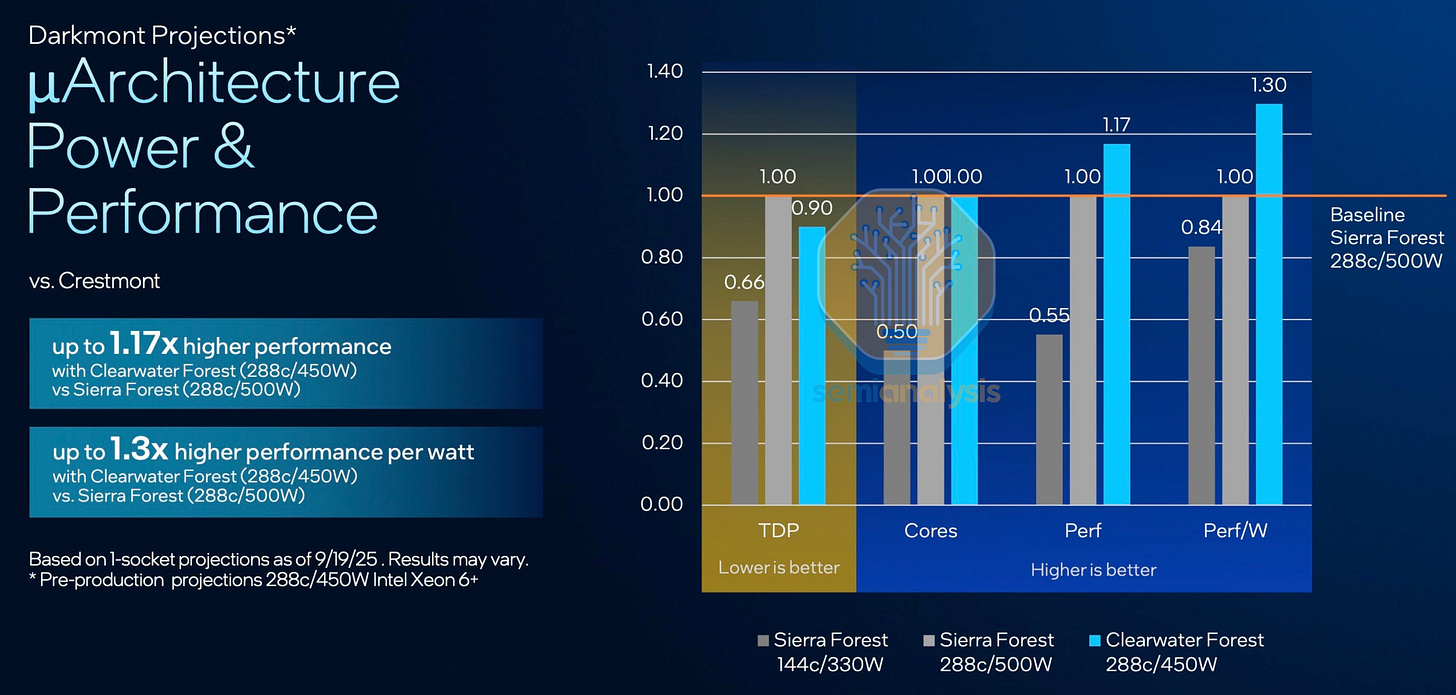
然而,Intel 的執行問題再次浮現,Clearwater Forest 的上市時間從 2025 年下半年推遲到 2026 年上半年。Intel 將延遲歸咎於 Foveros Direct 的整合挑戰,這對於將如此複雜的伺服器晶片作為 Intel 嘗試解決混合鍵合問題的首發產品來說並不意外。或許受此影響,垂直解構的互連頻寬相對較低,每個 4 核心集群存取基礎晶粒的 L3 和網格網路的頻寬僅為 35GB/s。
儘管有兩年的間隔、新的核心微架構、新製程、新進階封裝和更高的成本,Intel 顯示 Clearwater Forest 在相同核心數下僅比 Sierra Forest 快 17%。考慮到混合鍵合良率低導致成本大幅增加,性能提升卻如此有限,難怪 Intel 在最新的 2025 年第四季度財報中幾乎沒提到 Clearwater Forest。我們的看法是,Intel 不想大規模生產這些會損害毛利的晶片,而寧願將其作為 Foveros Direct 的良率學習工具。
AMD 的 Zen 互連架構

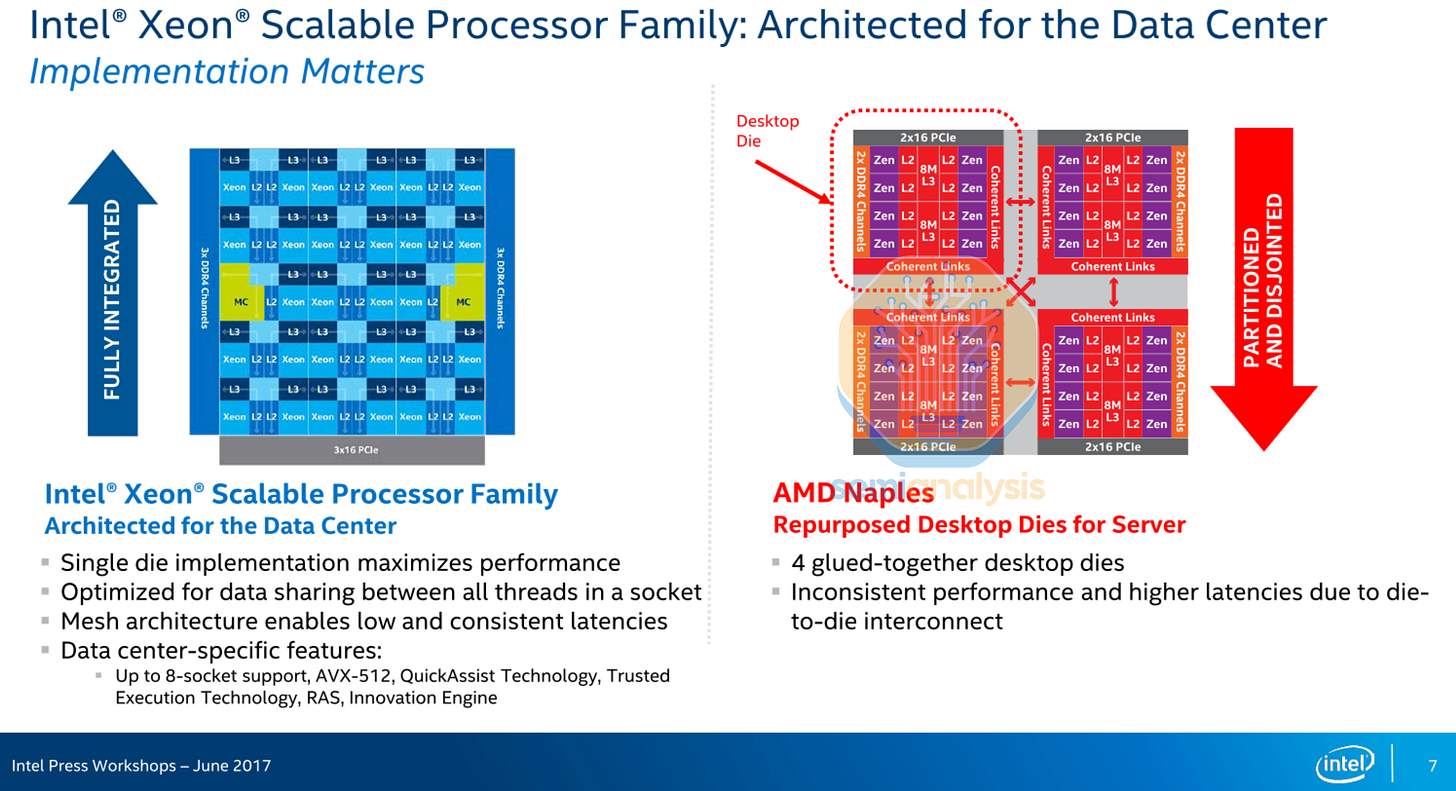
AMD 於 2017 年憑藉 EPYC Naples 7001 系列重返資料中心 CPU 市場引起了不小的轟動,Intel 當時嘲笑該設計是「四個膠合在一起的桌上型晶粒」,性能不穩定。實際上,AMD 的小型設計團隊必須足智多謀,只能負擔得起開發單個晶粒,該晶粒必須同時用於桌上型 PC、伺服器,甚至是在同一晶粒上整合了 10Gbit 乙太網路的嵌入式系統。
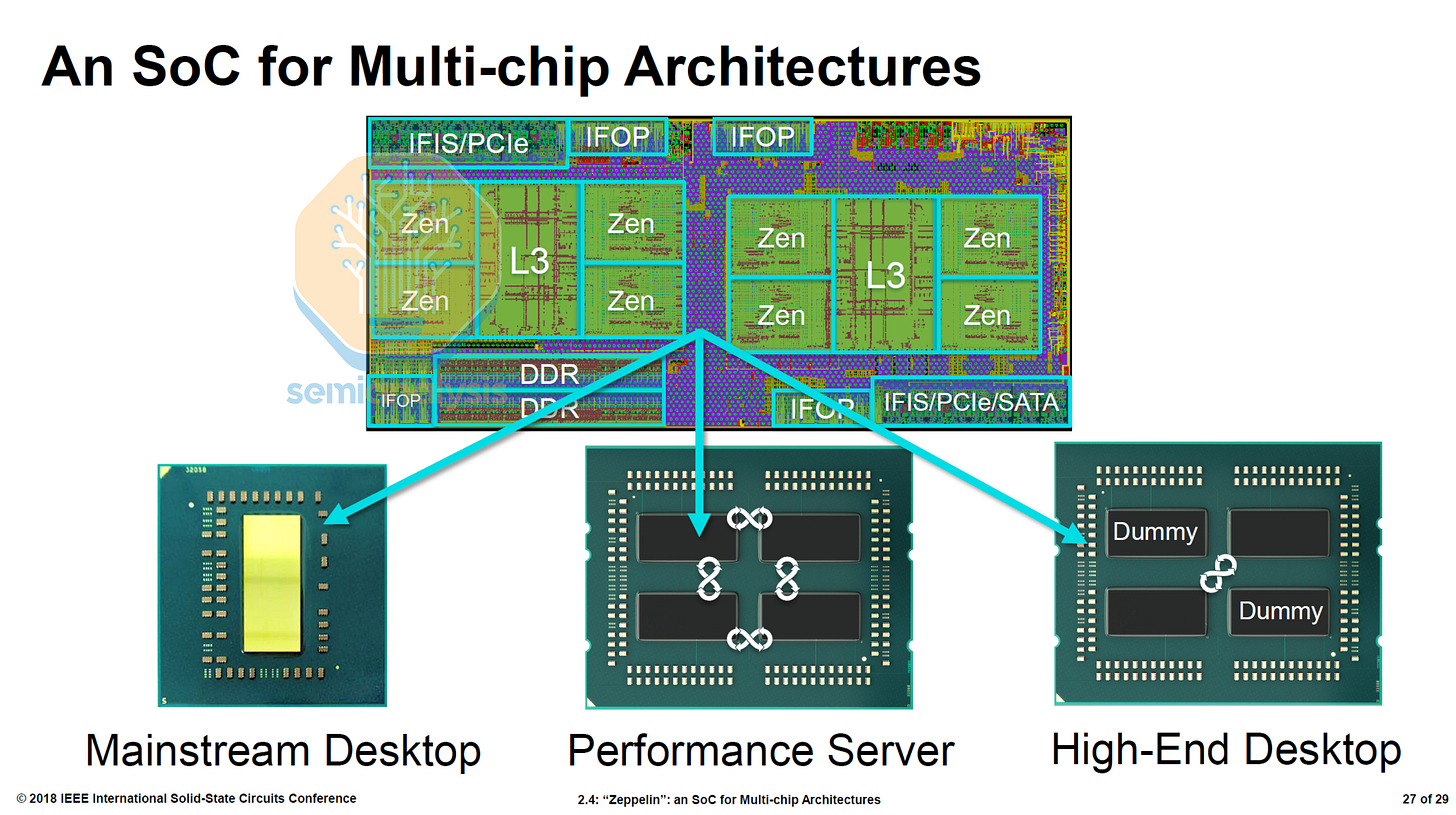
Naples 採用了 4 晶粒 MCM,每個「Zeppelin」晶粒包含 8 個核心,使 AMD 能夠以 32 個核心超越 Intel 的 28 個。每個晶粒包含 2 個核心複合物(CCX),每個 CCX 有 4 個核心和 8MB L3,透過橫向開關連接。片上可擴充數據織網(Scalable Data Fabric)實現了 CCX 間的通訊。封裝上的 Infinity Fabric (IFOP) 鏈路將每個晶粒與封裝內的另外 3 個晶粒連接,而插槽間 Infinity Fabric (IFIS) 鏈路則支持雙插槽設計。Infinity Fabric 實現了晶粒間的相干記憶體共享,源自其舊有的 HyperTransport 技術。
這種架構意味著沒有統一的 L3 快取,且核心間延遲差異巨大,從一個晶粒上 CCX 的核心到另一個晶粒上的核心需要多次跳轉。典型的雙插槽伺服器最終擁有四個 NUMA 域:CCX 內、CCX 間、晶粒間 MCM、插槽間。性能反映了這一點,核心間通訊和記憶體存取極少的可高度並行化任務(如渲染)表現良好,而依賴核心間通訊的記憶體和延遲敏感任務表現較差。由於當時大多數軟體也不具備 NUMA 感知能力,這讓 Intel 對其「性能不穩定」的批評有了一定道理。
EPYC Rome 的集中式 IO
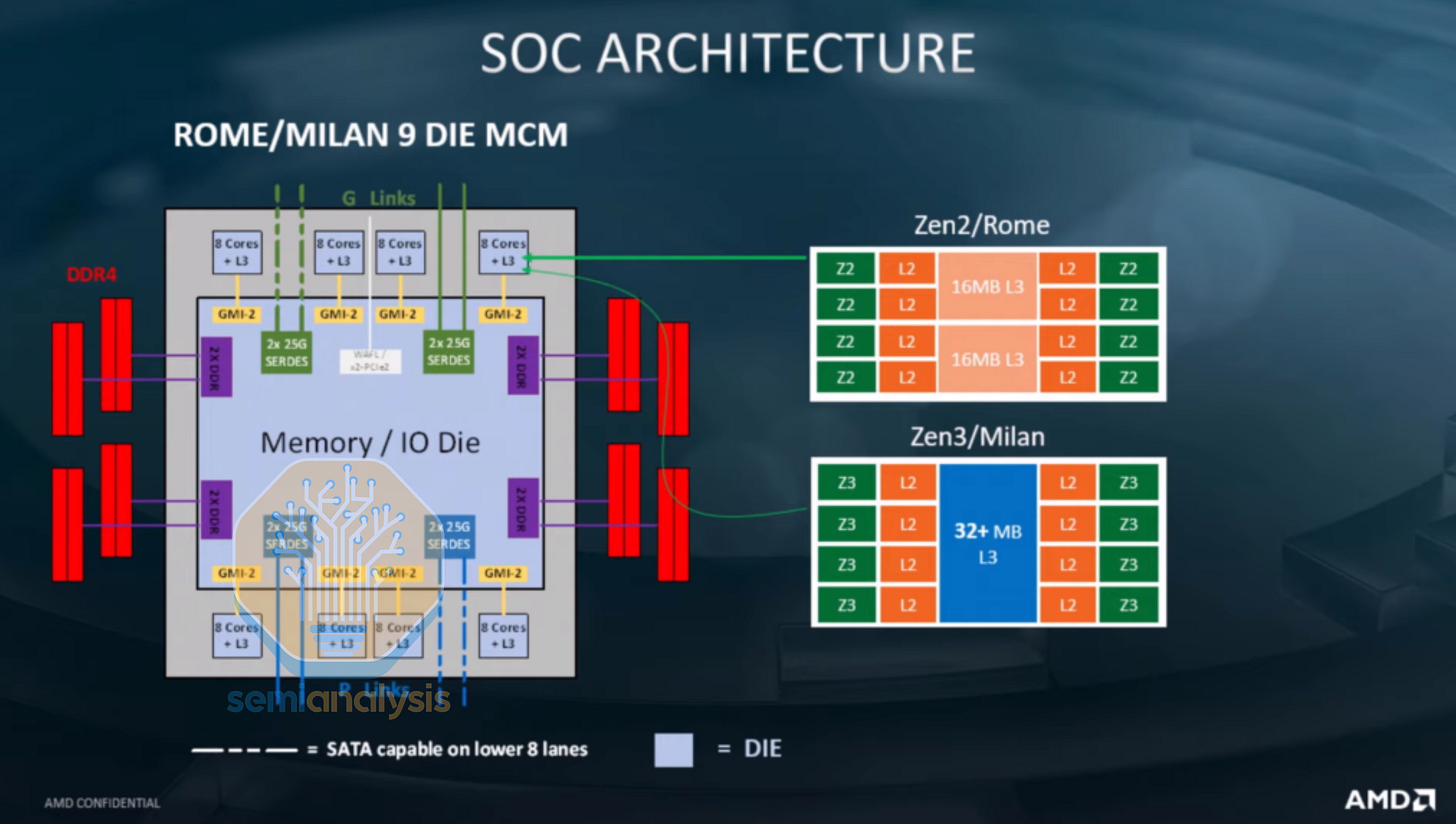
2019 年的 Rome 世代對晶粒佈局進行了徹底的反思,利用異質解構創建了一個 64 核心產品,遠遠超過當時仍停留在 28 核心的 Intel。八個 8 核心運算晶粒(CCD)圍繞著一個包含記憶體和 PCIe 介面的中央 I/O 晶粒,CCD 轉向最新的 TSMC N7 製程,而 I/O 晶粒則留在 GlobalFoundries 的 12nm。CCD 仍由兩個 4 核心 CCX 組成,但現在它們之間沒有直接通訊。相反,所有 CCX 間的流量都透過 I/O 晶粒路由,訊號透過全球記憶體互連(GMI)鏈路跨越基板。這意味著 Rome 在功能上表現為十六個 4 核心 NUMA 節點,但只有 2 個 NUMA 域。
在 Rome 上運行的 VM 必須限制在 4 核心以內,以避免跨晶粒通訊帶來的性能損失,這與之前的 Naples 類似。這一點在 2021 年的 Milan 世代得到解決,透過轉向環形匯流排架構將 CCX 規模增加到 8 核心,同時重複使用與 Rome 相同的 I/O 晶粒。

儘管最初計劃採用進階封裝,但 AMD 在接下來的兩代產品中仍堅持這種熟悉的設計,2022 年的 Genoa 增加到 12 個 CCD,2024 年的 Turin 在 128 核心的 EPYC 9755 上最多搭載 16 個 CCD,全部圍繞著具備升級版 DDR5 和 PCIe5 介面的中央 I/O 晶粒。
這種小晶片設計的關鍵好處是只需單次矽片開發即可擴展核心數。AMD 只需要設計單個 CCD,即可透過包含不同數量的 CCD 來提供整個 SKU 堆疊的核心數。每個 CCD 的小晶粒面積也有助於良率,並在轉向新製程節點時實現更早的上市時間。這與使用大型光罩尺寸晶粒且需要為每個核心數產品進行多次開發的網格設計形成對比。不同的 CCD 設計也可以在共享相同 IO 晶粒和插槽平台的同時進行更換,AMD 在 Bergamo 中使用了緊湊的 Zen 4c 核心,並為 192 核心的 Turin 變體使用了 Zen 5c 核心。我們在此撰寫了關於這種用於高效雲端運算的新核心變體的內容。解構還允許製造更小的版本,例如 EPYC 8004 Siena 處理器,在 6 通道記憶體平台上僅使用 4 個 Zen 4c CCD。
Zen 4c:AMD 對超大規模 ARM 與 Intel Atom 的回應
Intel Diamond Rapids 架構變化
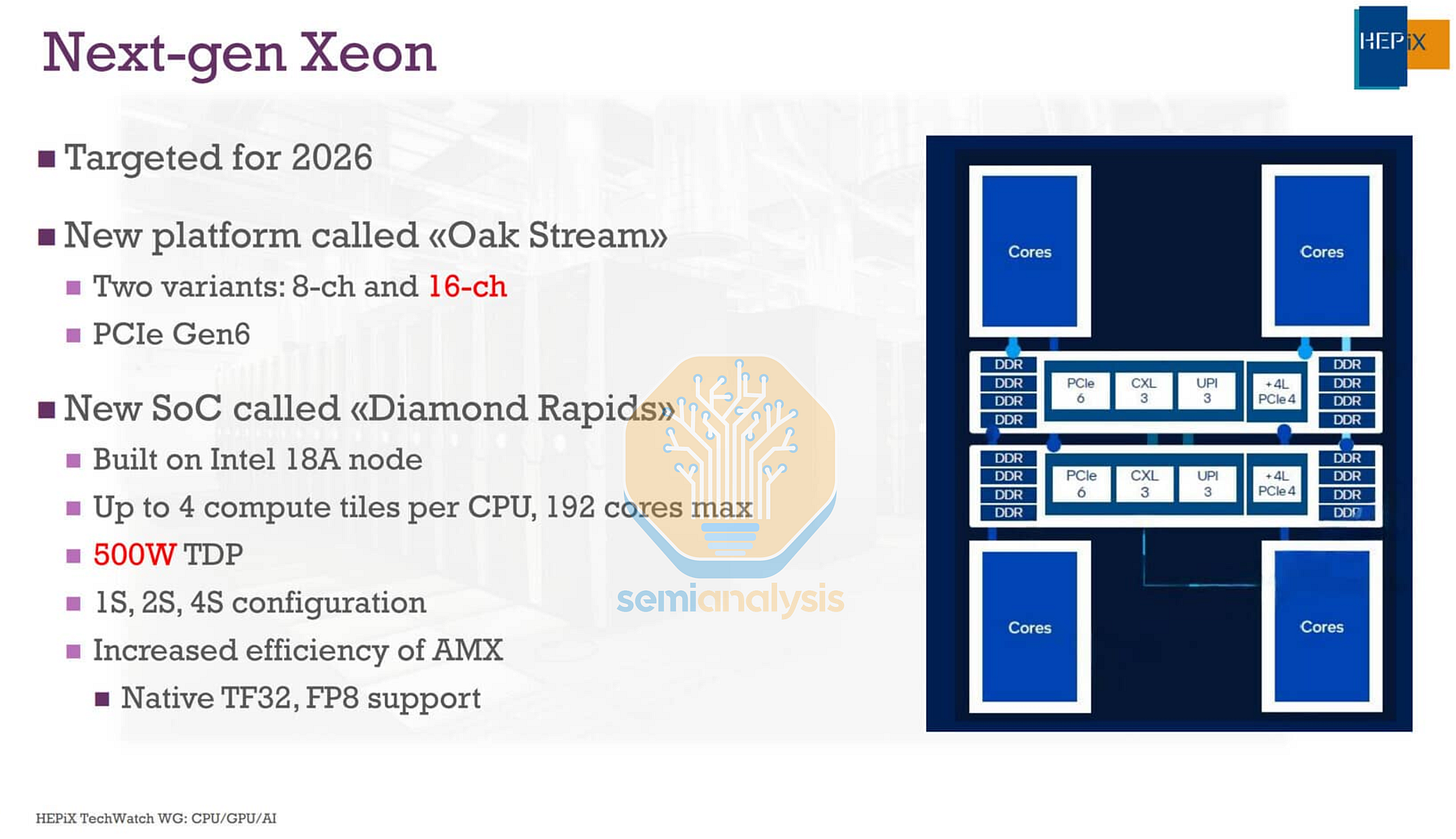
乍看之下,Diamond Rapids 幾乎像是 AMD 設計的翻版,運算晶粒圍繞著中央 I/O 晶粒。看來要將單個網格網路擴展到 Granite Rapids 的 10x19 之外以進一步增加核心數過於困難,這意味著 Intel 最終屈服於擁有多個 NUMA 節點和 L3 域。四個核心構建塊(CBB)晶粒位於中間兩個 I/O 與記憶體樞紐(IMH)晶粒的兩側。
在每個 CBB 內,32 個採用 Intel 18A-P 的雙核模組(DCM)被混合鍵合到包含 L3 快取和本地網格互連的基礎 Intel 3-PT 晶粒上。為了減少網格站點數量並降低網路流量,現在每個 DCM 中的兩個核心共享一個 L2 快取,這種設計讓人聯想到 2008 年的 Dunnington 世代。雖然這意味著 Diamond Rapids 總共有 256 個核心,但主流 SKU 似乎最多只會啟用 192 個核心,更高核心數的版本推測是為了解決良率問題而保留給非路線圖訂單。
IMH 晶粒包含 16 通道 DDR5 記憶體介面、支持 CXL3 的 PCIe6 以及 Intel 數據路徑加速器(QAT, DLB, IAA, DSA)。
有趣的是,晶粒間互連似乎不再需要 EMIB 進階封裝,而是透過封裝基板上的長走線將每個 CBB 晶粒連接到兩個 IMH 晶粒,讓每個 CBB 都能直接存取整個記憶體和 IO 介面,而無需經過第二次跳轉到另一個 IMH。這也確保了任何 CBB 間的通訊最多只需要 2 次跨晶粒跳轉。由於捨棄了進階封裝並將核心拆分到 4 個晶粒,我們預計跨 CBB 延遲將明顯惡化,與留在同一晶粒內相比有很大差異。
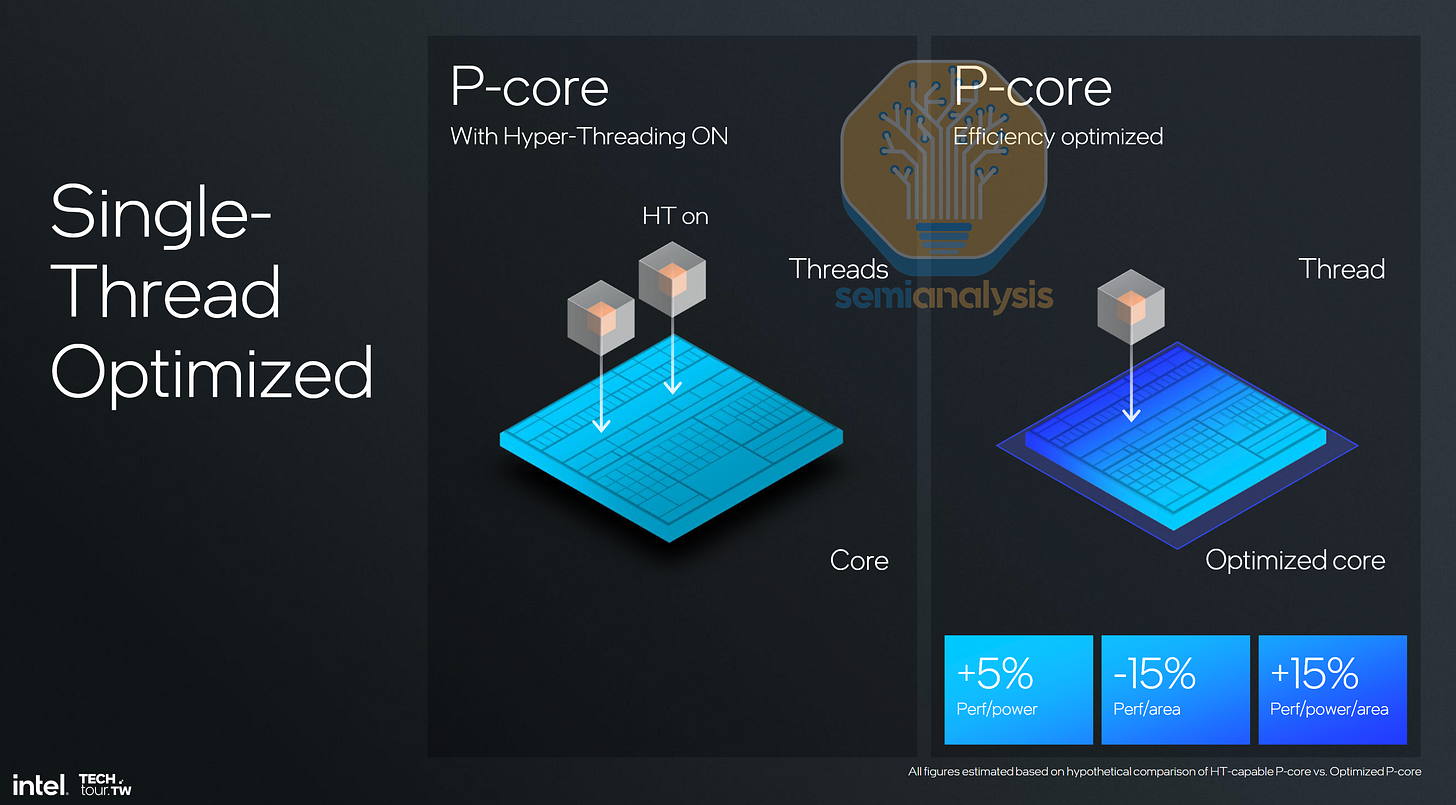
儘管延遲惡化是個問題,但 Diamond Rapids 最嚴重的問題是缺乏 SMT。受 Spectre 和 Meltdown 漏洞(從根本上對 Intel 的影響大於 AMD)的驚嚇,其核心設計團隊開始設計不具備 SMT 的 P-core,始於 2024 年客戶端 PC 的 Lion Cove。Intel 當時辯稱,移除 SMT 功能所節省的面積將以犧牲原始吞吐量為代價換取更好的效率。這對 PC 設計來說沒問題,因為它們整合了 E-core 來幫助增強多執行緒性能。
然而,最大吞吐量對資料中心 CPU 至關重要,這嚴重削弱了 Diamond Rapids。與目前 128 核心、256 執行緒的 Granite Rapids 相比,我們預計主流的 192 核心、192 執行緒 Diamond Rapids 性能僅提升約 40%,這讓 Intel 在又一個世代中面臨性能低於 AMD 的窘境。
在最後一刻,Intel 取消了主流的 8 通道 Diamond Rapids-SP 平台,使其最高產量的核心市場在至少到 2028 年前都沒有新一代產品。雖然這有助於精簡 Intel 臃腫的 SKU 堆疊,但我們認為這是錯誤的舉動,因為用於 AI 工具使用和上下文儲存的通用運算更需要具有良好連接性的主流 CPU,而非追求極致單插槽性能的選擇。
AMD Venice 架構變化
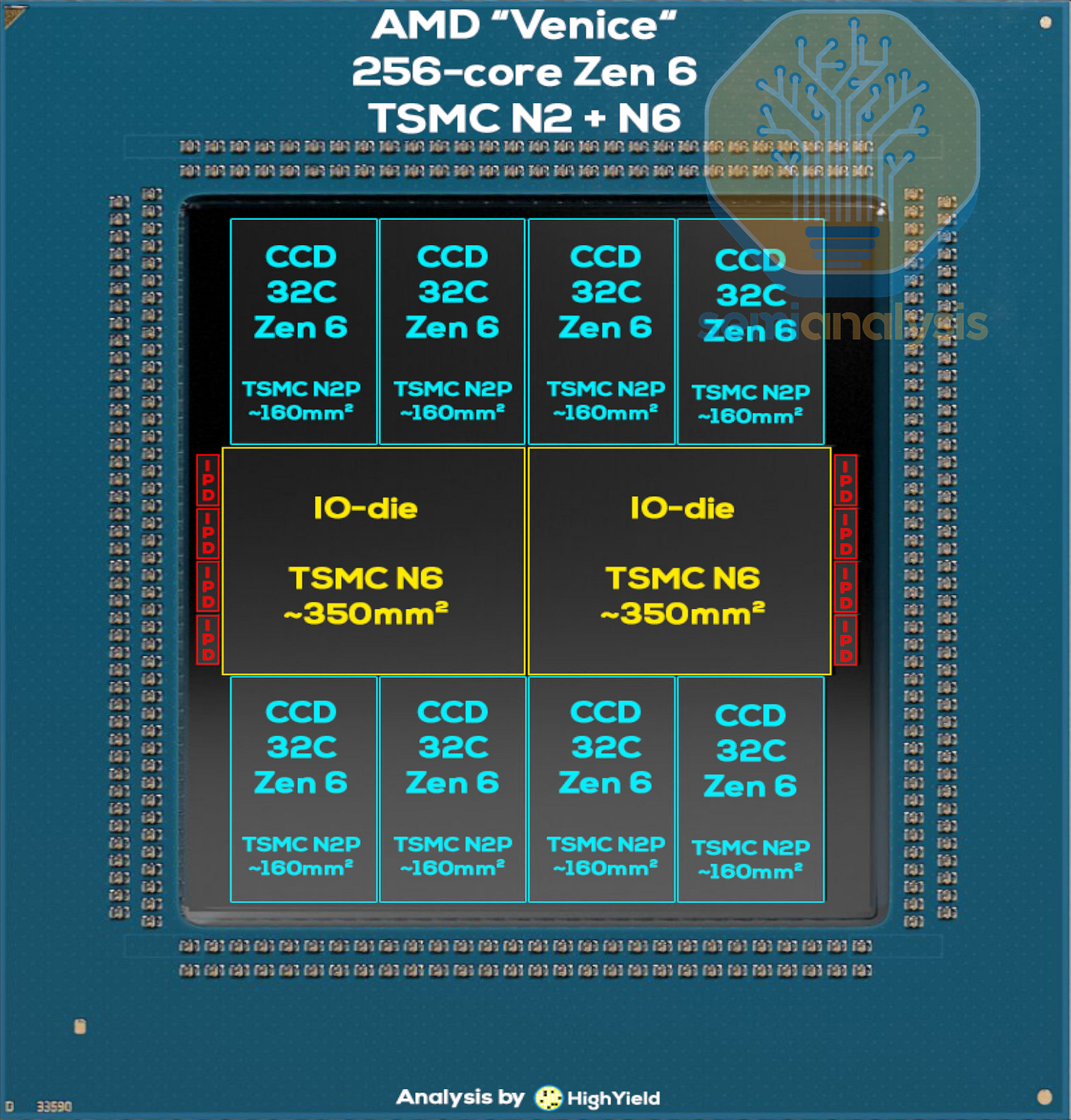
當 Intel 捨棄 EMIB 時,AMD 終於在 Venice 上採用了同等的進階封裝技術,使用高速短距鏈路將 CCD 連接到 I/O 晶粒。我們在加速器、HBM 和進階封裝模型中提供了相關產量數據。
CCD 鏈路所需的額外邊緣空間佔據了更多寬度,使得中央 I/O 樞紐必須拆分為 2 個晶粒。這創造了另一個晶粒間跳轉來跨越晶片的兩個部分,形成了另一個 Intel 方案所避免的 NUMA 域。I/O 晶粒現在總共具備 16 個記憶體通道,高於 2022 年 Genoa 的 12 個。AMD 也終於趕上 Intel,支持多路復用(Multiplexed)記憶體以獲得更高頻寬,16 通道 MRDIMM-12800 可提供 1.64TB/s,是 Turin 的 2.67 倍。
AMD 在 CCD 內也轉向了網格網路,在 4x8 網格中包含 32 個 Zen6c 核心,儘管可能還包含一個額外的備用核心用於良率恢復。八個 TSMC N2 CCD 使核心數達到 256 個,比 192 核心、3nm 的 Turin-Dense EPYC 9965 增加了三分之一。Zen6c 獲得了完整的每核心 4MB L3 快取(之前在 Zen5c 上減半),在每個 CCD 內創建了巨大的 128MB 快取區域。
針對 AI 主控節點優化的低核心數、高頻率「-F」SKU 將採用與其消費級桌上型和行動 PC 系列相同的 12 核心 Zen6 CCD 設計,在 8 個 CCD 上實現高達 96 個核心。雖然這比 128 核心的 Turin-Classic 4nm EPYC 9755 有所倒退,但與高頻率 64 核心的 EPYC 9575F 相比,核心數增加了 50%。
最後,在 I/O 晶粒旁、DDR5 介面引出處可以看到 8 個小晶粒。這些是整合被動元件(IPD),有助於在 I/O 密集的區域平滑晶片的供電,因為該區域的 SP7 封裝佈線已因記憶體通道扇出而飽和。
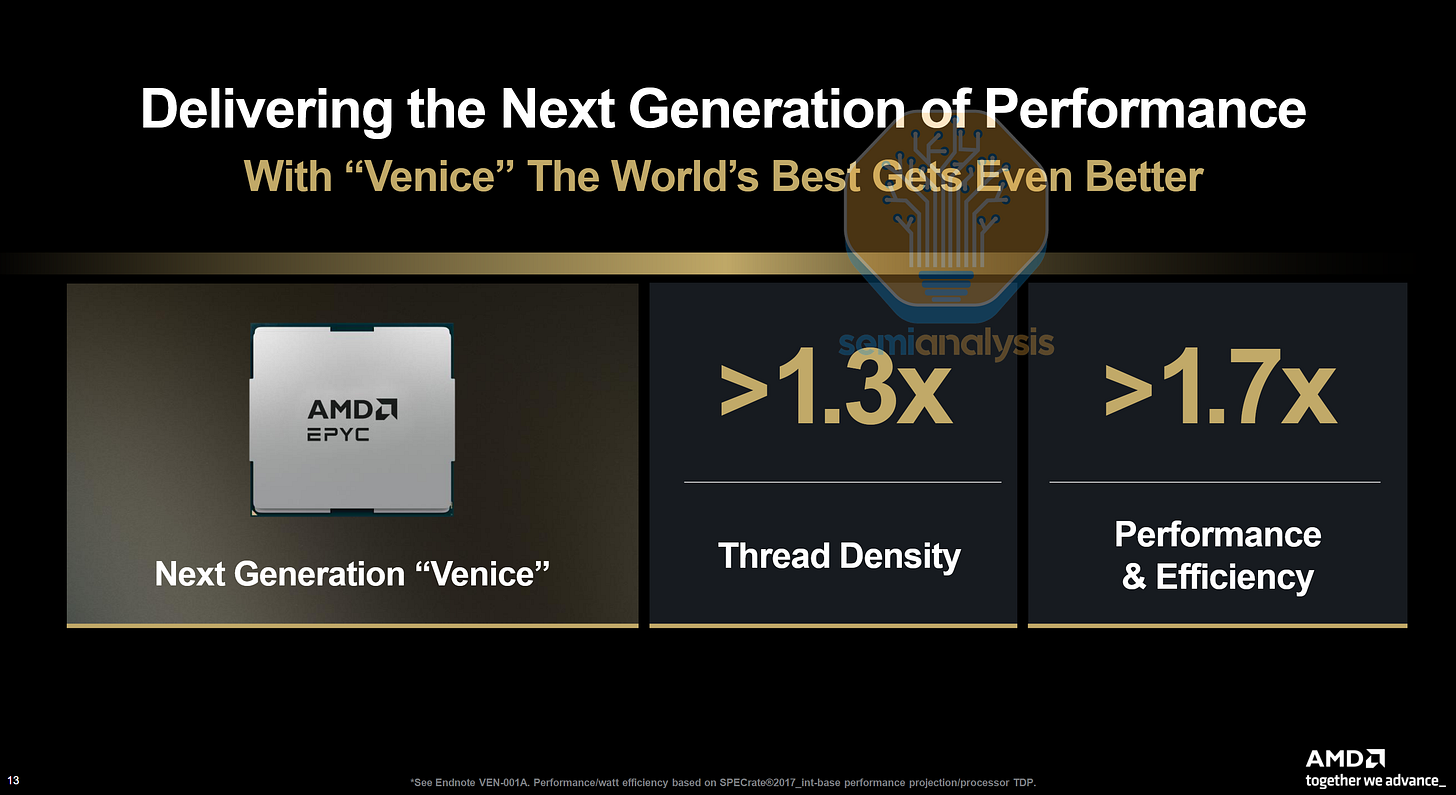
在性能方面,AMD 聲稱頂級 256 核心變體在 SPECrate®2017_int_base 中的每瓦性能比頂級 192 核心 Turin 高出 1.7 倍以上,這意味著得益於具有更高每時鐘指令數(IPC)的新 Zen 6 核心微架構,單核性能甚至更高。Zen 6 還引入了用於 AI 數據類型的新指令,包括 AVX512_FP16、AVX_VVNI_INT8 以及用於位矩陣乘法(BMM)和位反轉操作的新 AVX512_BMM 指令。
對於 BMM,FPU 暫存器儲存 16x16 二進位矩陣,並使用 OR 和 XOR 操作計算 BMM 累加。二進位矩陣比浮點矩陣更容易計算,可以為能利用它的軟體(如 Verilog 模擬)提供巨大的效率提升。然而,BMM 對於 LLM 來說精度不足,因此我們認為該指令的採用將會有限。
由於 AMD 已經享有顯著高於 Intel 的單核性能(96 核心 Turin 即可匹敵 128 核心 Granite Rapids),AMD Venice 與 Intel Diamond Rapids 之間的性能差距在 2026 至 2028 年這一代資料中心 CPU 中將進一步拉大。得益於新的晶粒間互連和更大的核心域,Venice 的核心間延遲應優於 Turin。
AMD 還在 Intel 撤出的領域加倍下注。當 Intel 取消其 8 通道處理器時,AMD 將推出新的 8 通道 Venice SP8 平台,作為低功耗、小插槽 EPYC 8004 Siena 系列的繼任者,同時仍能提供多達 128 個密集的 Zen 6c 核心。藉此,AMD 將在企業市場(Intel 的傳統堡壘)獲得大量份額。
2026 CPU 成本分析
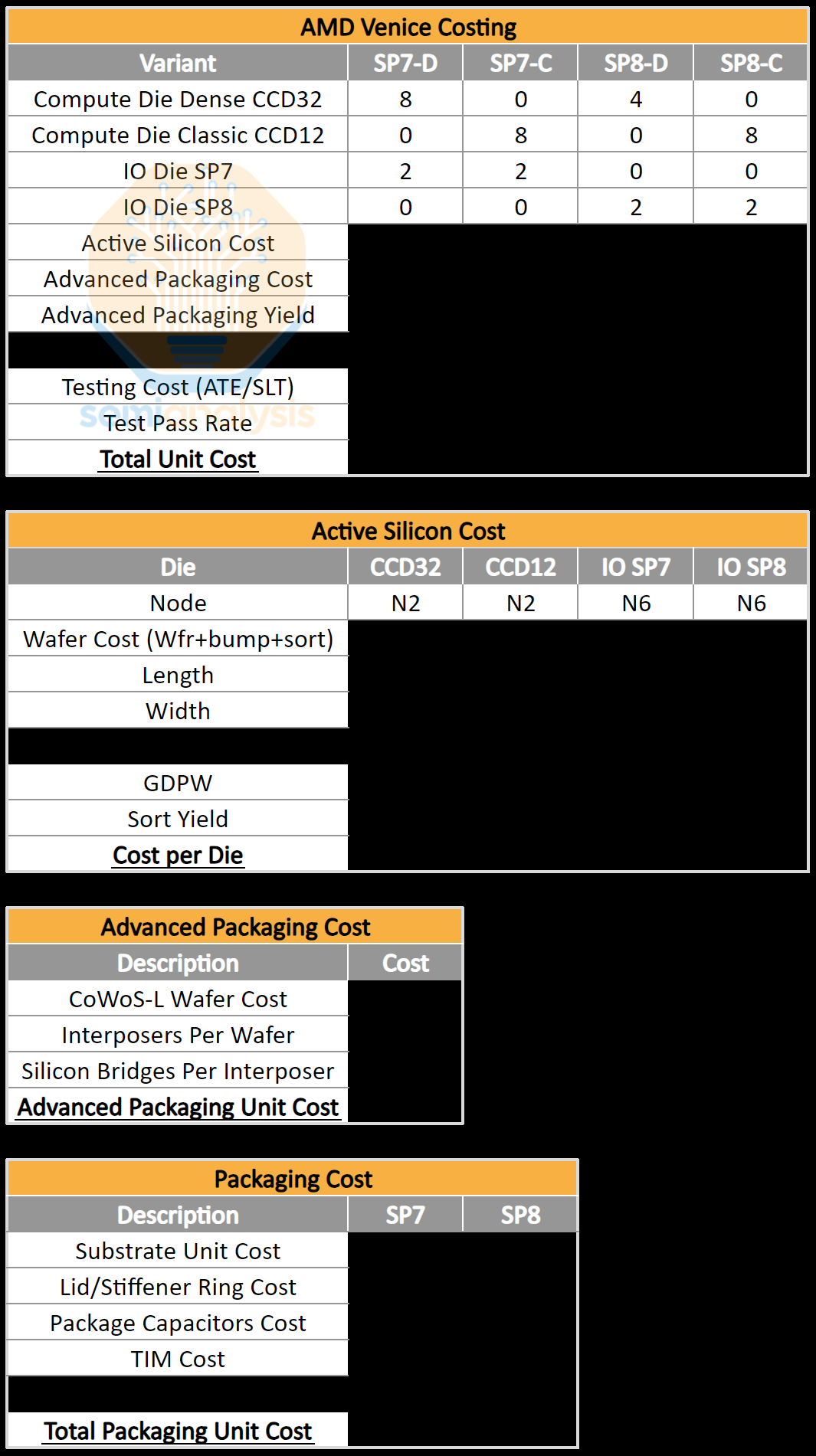
SemiAnalysis 基於我們對供應鏈的廣泛了解,提供詳細的物料清單(BOM)成本分析。欲了解確切的晶粒尺寸、配置、拓撲、性能預估以及與超大規模業者 ARM CPU 的競爭力,請聯繫 Sales@SemiAnalysis.com 獲取客製化諮詢和競爭分析服務。我們擁有 AMD Turin、Venice、Intel Granite Rapids、Diamond Rapids、NVIDIA Grace、Vera 以及來自 AWS、Microsoft、Google 等超大規模業者 ARM CPU 的詳細成本核算與解析。
Nvidia Grace
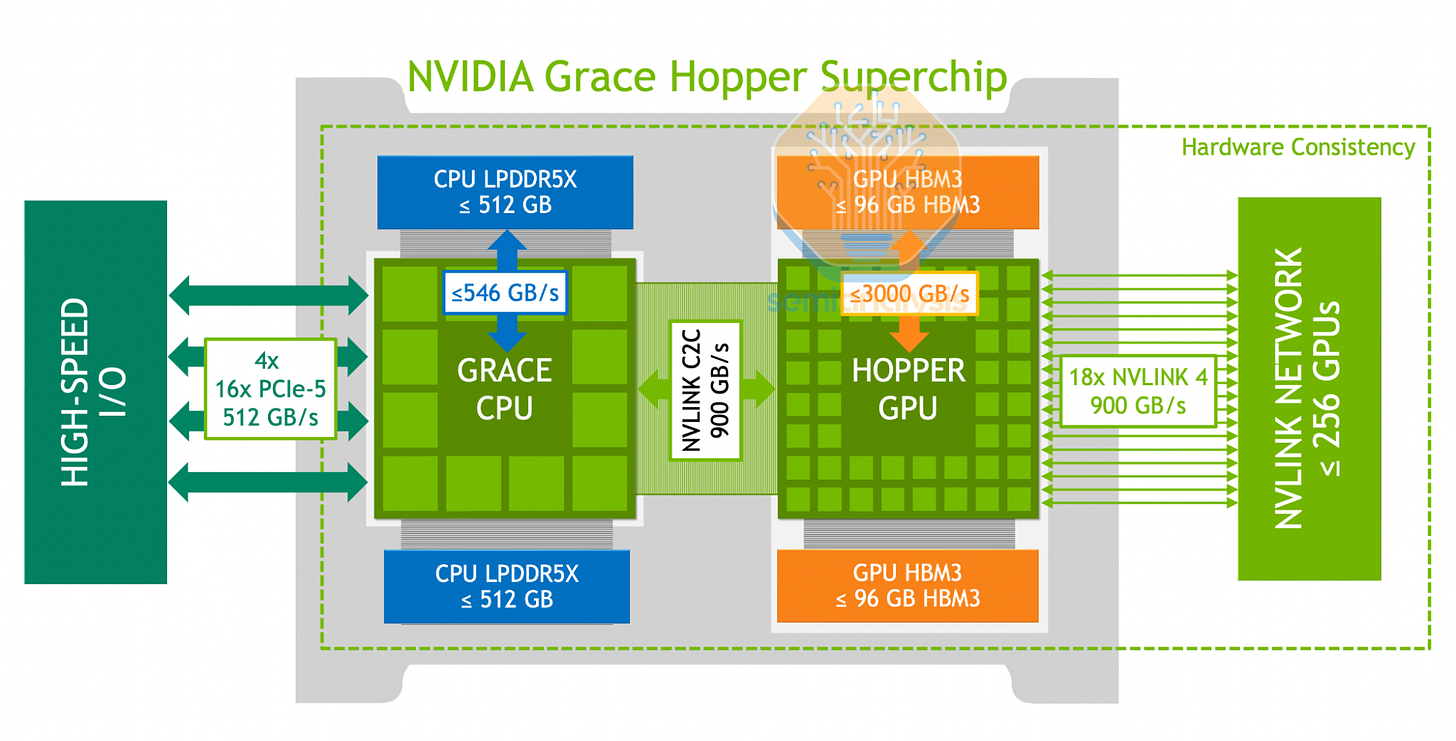
與本文涵蓋的大多數通用 CPU 不同,Nvidia 的 CPU 設計時考慮了主控節點和擴展 GPU 記憶體,其殺手鐧是 NVLink-C2C。這種 900GB/s(雙向)高速鏈路允許連接的 Hopper 或 Blackwell GPU 以全頻寬存取 CPU 記憶體,透過每顆 Grace CPU 高達 480GB 的記憶體緩解 HBM 的低容量限制。Grace 還採用了行動級 LPDDR5X 記憶體,在 512 位元寬記憶體匯流排上保持 500GB/s 高頻寬的同時,降低非 GPU 功耗。最初的 Grace Hopper 超級晶片為每顆 GPU 配備 1 顆 Grace,而後來的 Grace Blackwell 世代則是 2 顆 GPU 共享 1 顆 CPU。NVIDIA 還為需要高記憶體頻寬的 HPC 客戶提供了雙 Grace 超級晶片 CPU。
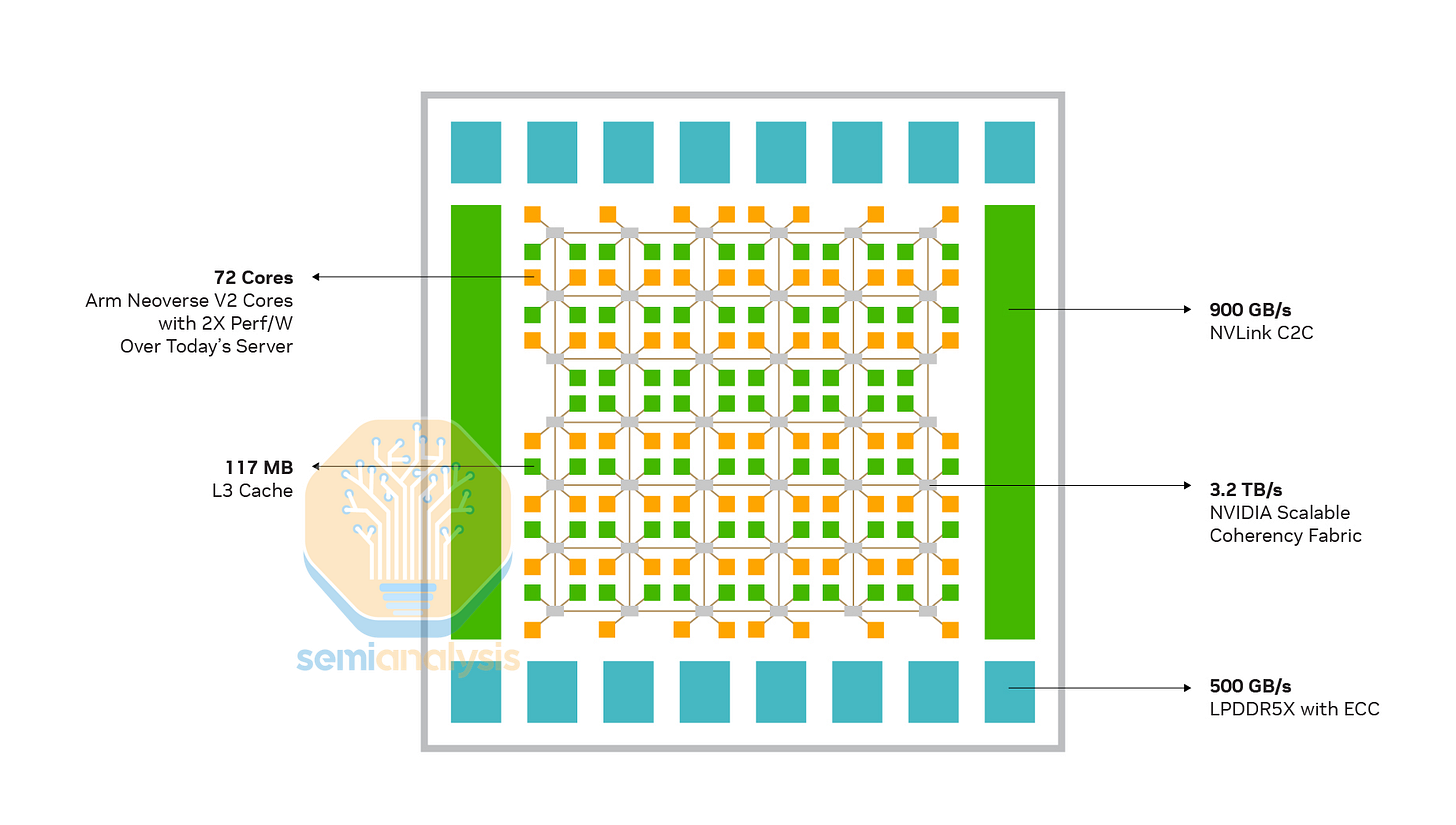
在 CPU 核心方面,NVIDIA 使用高效能 ARM Neoverse V2 設計,在 6x7 網格網路上具備每核心 1MB 私有 L2 快取,容納 76 個核心和 117MB L3 快取,為了良率最多啟用 72 個核心。網格站點上的每個快取切換節點(CSN)連接最多 2 個核心和 L3 切片。NVIDIA 強調網格網路 3.2TB/s 的高對分頻寬(bisection bandwidth),顯示了 Grace 對數據流而非原始 CPU 性能的專業關注。
在性能方面,Grace 存在一個源自 Neoverse V2 核心的奇特微架構瓶頸,使其在未優化的 HPC 程式碼上運行緩慢。根據 Nvidia 的 Grace 性能調優指南,針對更好的程式碼局部性優化大型應用程式可實現 50% 的加速。這是由於核心分支預測引擎在程序使用前儲存和獲取指令的能力受限。在 Grace 上,指令被組織成 32 個 2MB 的虛擬位址空間。
當此分支目標緩衝區(Branch Target Buffer)填滿超過 24 個區域時,性能開始大幅下降,因為熱點程式碼佔據了緩衝區並增加了指令更替,導致更多分支預測錯誤。如果程序超過 32 個區域,整個 64MB 緩衝區將被清空,分支預測器會忘記所有之前的分支指令以容納新指令。在沒有運作的分支預測器的情況下,CPU 核心的前端會成為整個操作的瓶頸,ALU 只能閒置等待指令執行。
這就是為什麼 AI 工作負載目前在 GB200 和 GB300 中受到 Grace CPU 拖累的原因。
Nvidia Vera
Vera 在 2026 年為 Rubin 平台更進一步,將 C2C 頻寬翻倍至 1.8TB/s,並透過八個 128 位元寬的 SOCAMM 192GB 模組將記憶體寬度翻倍,在 1.2TB/s 頻寬下提供 1.5TB 記憶體。網格設計保留,採用 7x13 網格容納 91 個核心,最多啟用 88 個。L3 快取增加到 162MB。NVIDIA 現在將周邊記憶體和 I/O 區域解構成獨立的小晶片,總共 6 個晶粒使用 CoWoS-R 封裝(1 個 3nm 光罩尺寸運算晶粒具備 NVLink-C2C、4 個 LPDDR5 記憶體晶粒和 1 個 PCIe6/CXL3 IO 晶粒)。
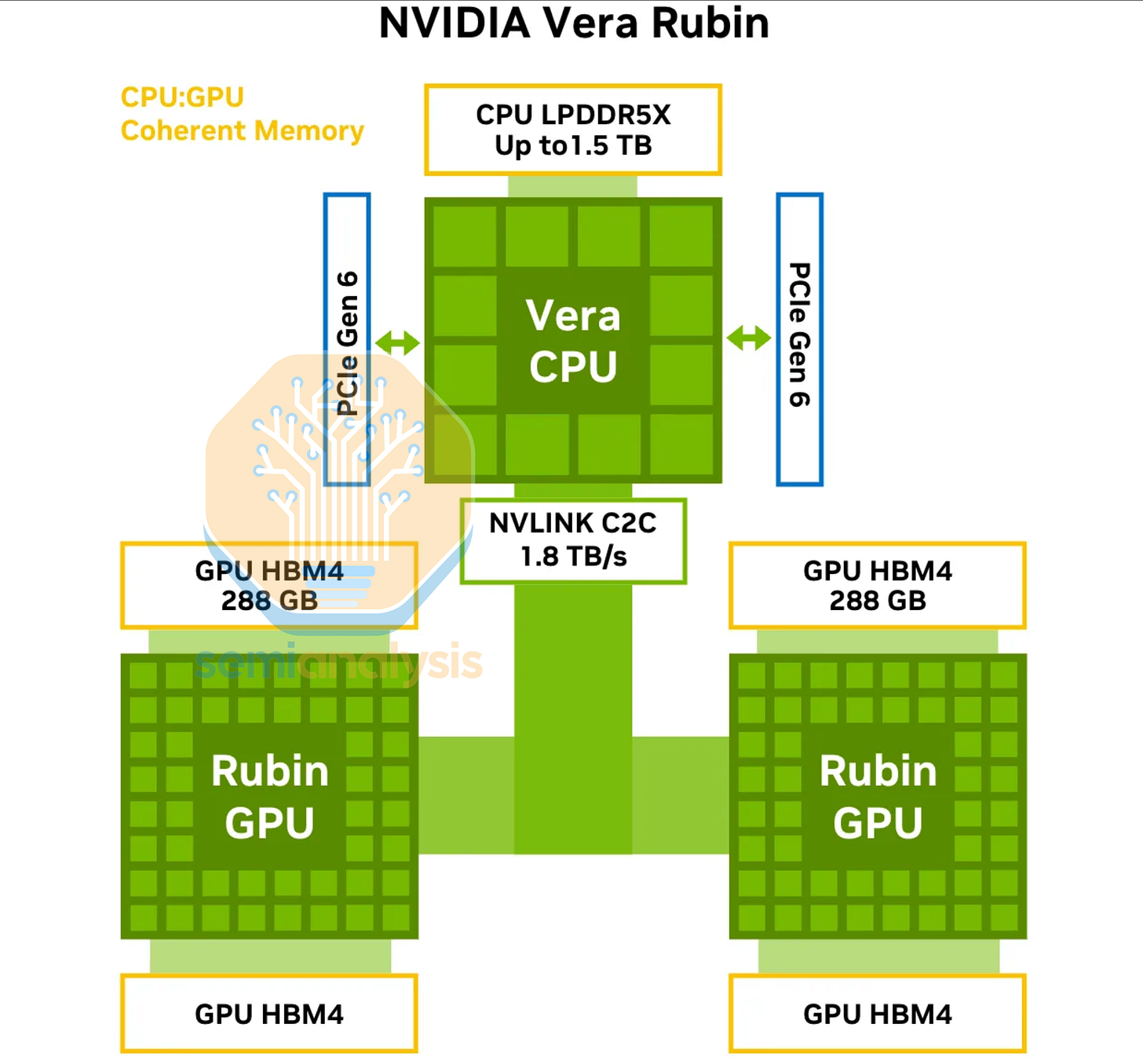


或許是受夠了 ARM Neoverse 核心的性能瓶頸,NVIDIA 召回了其自研 ARM 核心設計團隊,開發了支持 SMT 的新 Olympus 核心,實現 88 核心、176 執行緒。NVIDIA 上一次自研核心是 8 年前 Tegra Xavier SoC 中的 10 寬 Carmel 核心。ARMv9.2 Olympus 核心將浮點單元寬度增加到 6 個 128b 寬端口(Neoverse V2 為 4 個),現在支持 ARM 的 SVE2 FP8 操作。每個核心配備 2MB 私有 L2 快取,較 Grace 翻倍。總體而言,Nvidia 聲稱轉向 Vera 可帶來 2 倍的性能提升。
AWS Graviton5
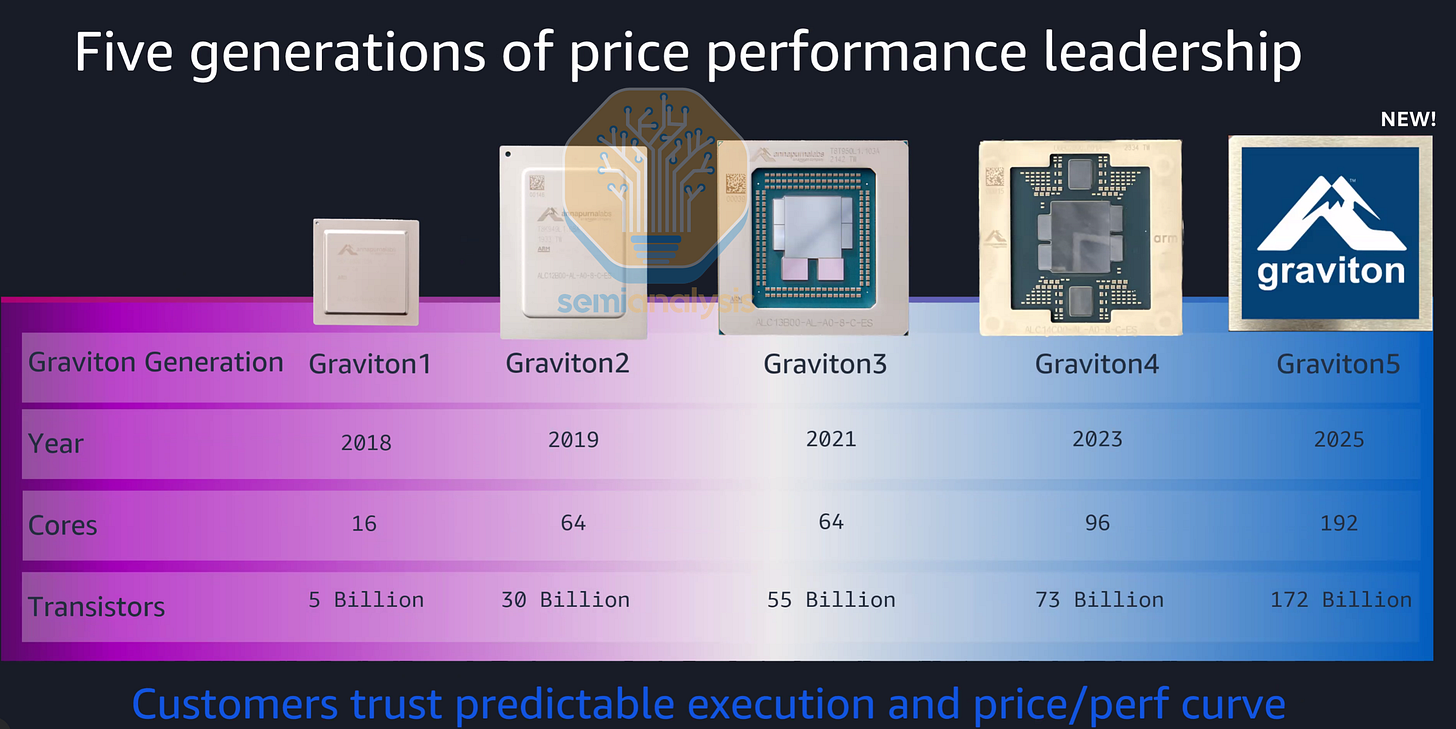
Amazon Web Services (AWS) 是第一家成功為雲端開發並部署自家 CPU 的超大規模業者。得益於收購 Annapurna Labs 晶片設計團隊以及 ARM 的 Neoverse 運算子系統(CSS)參考設計,AWS 現在可以透過直接找 TSMC 和 OSAT 合作夥伴生產晶片(而非購買 Intel Xeon)來獲得更好的毛利,從而以更低的價格提供其 EC2 雲端實例。
Graviton 的推廣在 COVID 繁榮期間隨 Graviton2 世代正式開始,當時 AWS 提供大幅折扣以吸引雲端客戶將其程序從 x86 遷移到 ARM 生態系統。雖然 Graviton2 的單核性能不如 Intel 的 Cascade Lake 世代,但它以極低的價格提供了 64 個 Neoverse N1 核心,具有顯著更高的性價比。
Graviton3 於 2021 年底預覽,帶來了多項專注於將單核性能提升至競爭水平的變化。AWS 轉向了 ARM 的 Neoverse V1(一種比 N1 大得多、浮點性能翻倍的 CPU 核心),同時保持核心數為 64。採用了 10x7 核心網格網路(CMN),晶粒上印刷了 65 個核心,預留 1 個核心用於分級禁用。AWS 還將設計解構成小晶片,四個 DDR5 記憶體和兩個 PCIe5 I/O 小晶片圍繞著 TSMC N5 製程的中央運算晶粒,全部透過 Intel 的 EMIB 進階封裝連接。由於 Intel Sapphire Rapids 的延遲,Graviton3 成為首批部署 DDR5 和 PCIe5 的資料中心 CPU 之一,領先 AMD 和 Intel 整整一年,我們對此進行了報導。
Amazon Graviton 3 利用小晶片與進階封裝將高效能 CPU 商品化 | 首款 PCIe 5.0 與 DDR5 伺服器 CPU
Graviton4 繼續擴展,採用了更新的 Neoverse V2 核心,並將核心數和記憶體通道增加了 50%,分別達到 96 個和 12 通道,比上一代提升了 30-45%。PCIe5 通道數從 32 條翻了三倍達到 96 條,大幅提升了與網路和儲存的連接性。Graviton4 還帶來了對雙插槽配置的支持,以實現更高的實例核心數。
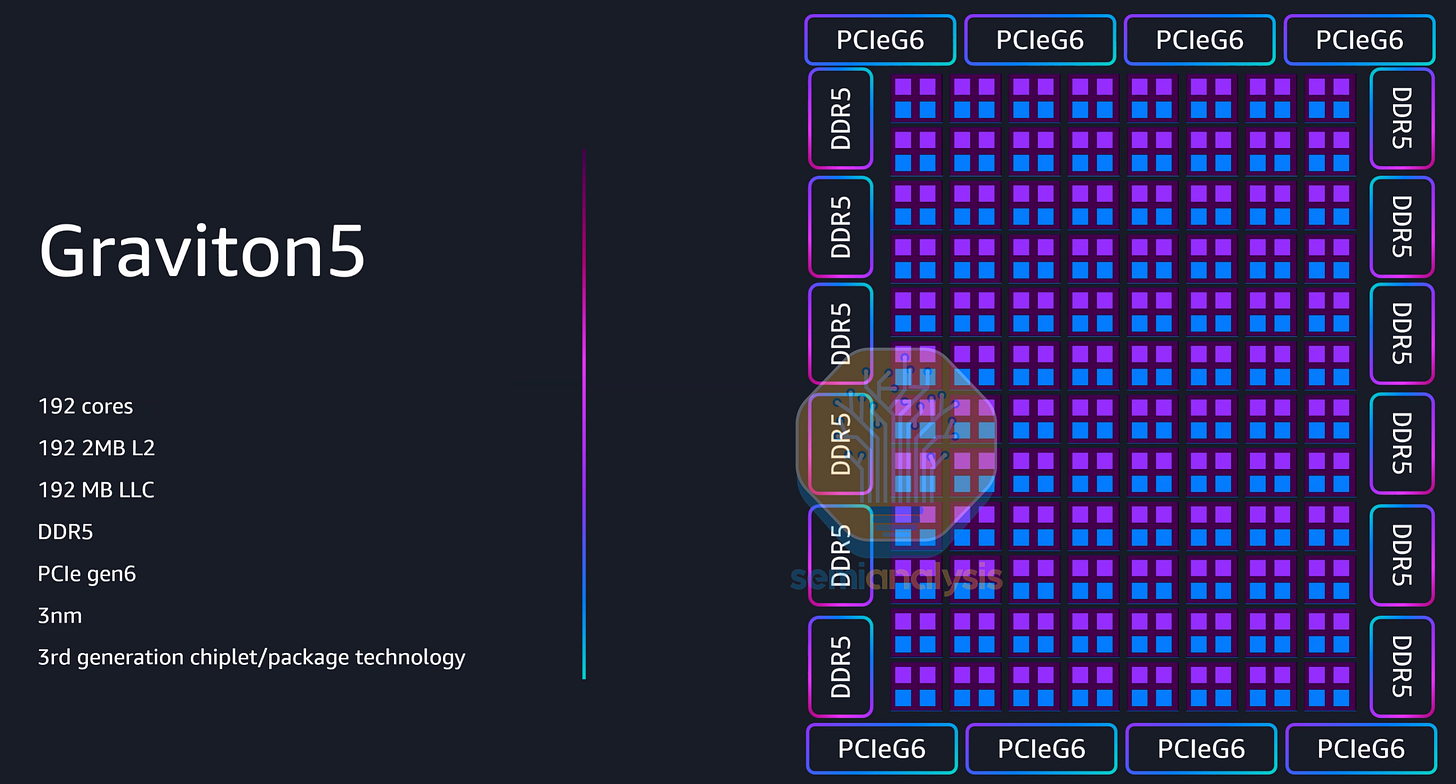
自 2025 年 12 月起預覽的 Graviton5 性能再次大幅躍升,擁有 192 個 Neoverse V3 核心,是上一代的兩倍,在 TSMC 3nm 製程上擁有 1720 億個電晶體。雖然每核心 L2 快取仍為 2MB,但共享 L3 快取從 Graviton4 微不足道的 36MB 增加到 Graviton5 更體面的 192MB,額外的快取充當緩衝區,因為儘管核心數翻倍,記憶體頻寬僅增加了 57%(12 通道 DDR5-8800)。
Graviton 5 的封裝非常獨特,正如我們在 Core Research 中討論過的,這對供應鏈中的幾家供應商有重大影響。
有趣的是,雖然 PCIe 通道升級到了 Gen6,但通道數從 Graviton4 的 96 條倒退回 Graviton5 的 64 條,顯然是因為 AWS 發現通常不會部署使用所有 PCIe 通道的配置。這種成本優化為 Amazon 節省了大量 TCO,同時不影響性能。
Graviton5 採用了演進的小晶片架構和互連,現在 2 個核心共享同一個網格站點,排列在 8x12 網格中。雖然 AWS 這次沒有展示封裝和晶粒配置,但他們確保 Graviton5 確實採用了新穎的封裝策略,且 CPU 核心網格分佈在多個運算晶粒上。
在 CPU 使用方面,AWS 自豪地提到,他們一直在內部使用數千顆 Graviton CPU 進行 CI/CD 設計整合流程,並運行 EDA 工具來設計和驗證未來的 Graviton、Trainium 和 Nitro 晶片,形成了一個內部的「吃自家狗糧」循環,由 Graviton 設計 Graviton。AWS 還宣布其 Trainium3 加速器現在將使用 Graviton CPU 作為主控節點,比例為 1 顆 CPU 對 4 顆 XPU。雖然初始版本運行在 Graviton4 上,但未來的 Trainium3 集群將由 Graviton5 驅動。
Microsoft Cobalt 200

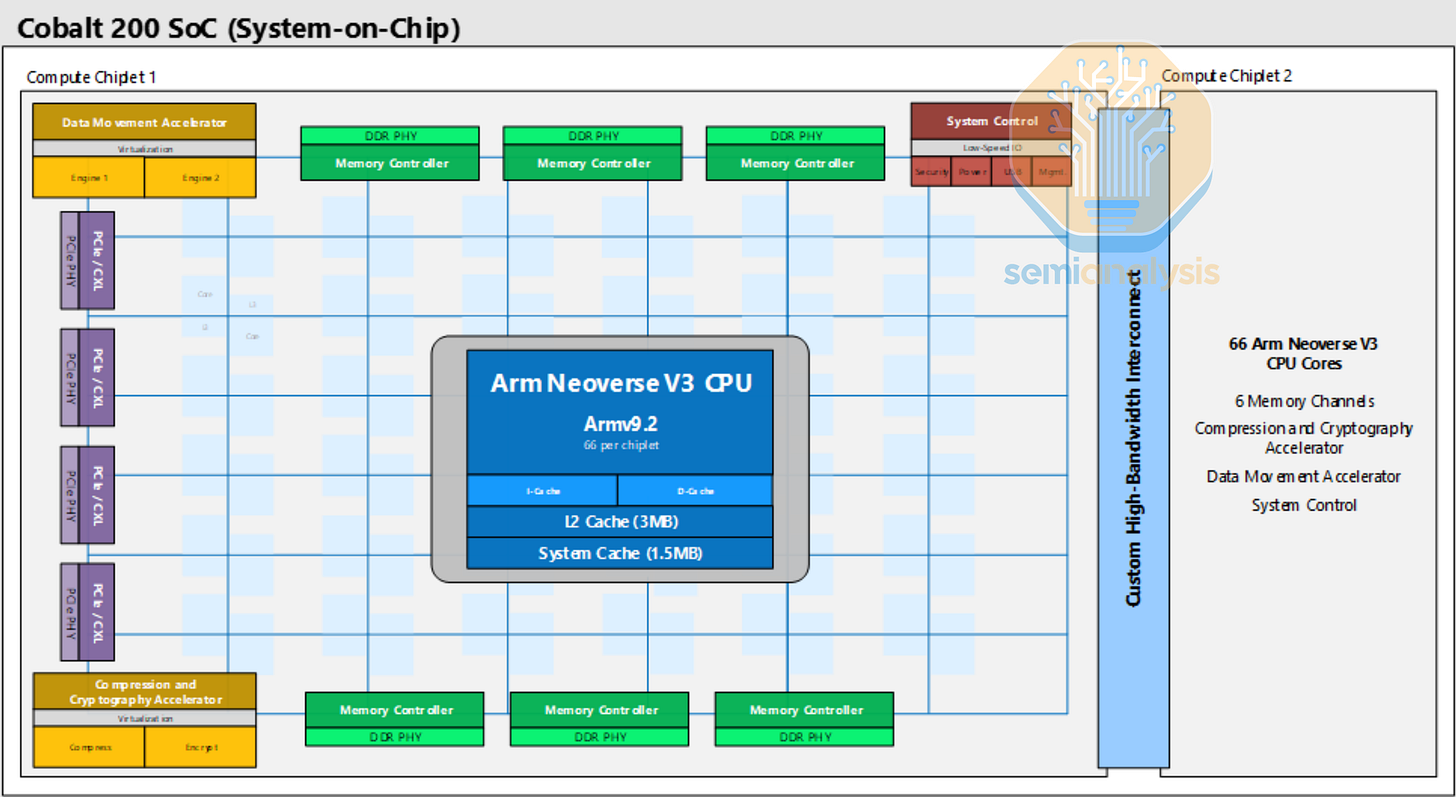
Microsoft 基礎設施 - AI 與 CPU 客製化晶片 Maia 100, Athena, Cobalt 100
繼我們之前報導的 Microsoft 2023 年首款 Cobalt 100 CPU 之後,Cobalt 200 於 2025 年底推出,並進行了多項升級。雖然核心數增加不多(從 128 增至 132),但與上一代的 Neoverse N2 相比,每個核心現在採用 Neoverse V3 設計,性能更強。每個核心擁有非常大的 3MB L2 快取,並透過兩個 TSMC 3nm 運算晶粒間的客製化高頻寬互連,使用標準的 ARM Neoverse CMN S3 網格網路連接。從圖中看,每個晶粒都有一個 8x8 網格,具備 6 個 DDR5 通道和 64 條支持 CXL 的 PCIe6 通道。每個網格站點共享 2 個核心,每個晶粒共印刷 72 個核心,為了良率啟用 66 個。192MB 的共享 L3 快取也分佈在網格中。憑藉這些升級,Cobalt 200 實現了比 Cobalt 100 高 50% 的加速。
與 Graviton5 不同,Cobalt 200 將僅用於 Azure 的通用 CPU 運算服務,不會用作 AI 主控節點。Microsoft 的 Maia 200 機架級系統改為部署 Intel 的 Granite Rapids CPU。
Google Axion C4A, N4A


Axion 系列於 2024 年發布並於 2025 年正式上市,標誌著 Google 進入其 GCP 雲端服務的客製化矽片 CPU 領域。Axion C4A 實例在大型單體 5nm 晶粒上擁有高達 72 個 Neoverse V2 核心、標準網格網路、8 通道 DDR5 和 PCIe5 連接。根據 Google Cloud Next 2024 上展示的 Axion 晶圓特寫圖像,晶粒似乎在 9x9 網格中印刷了 81 個核心,預留 9 個核心用於良率禁用。因此,我們相信為 2025 年底進入預覽階段的 96 核心 C4A 裸機實例設計了新的 3nm 晶粒。
為了實現更具成本效益的擴展型網路和微服務,Google 的 Axion N4A 實例現已進入預覽,配備 64 個性能較低的 Neoverse N3 核心,晶粒尺寸小得多,可支持 2026 年的大規模產量提升。Axion N4A 矽片是 Google 在 TSMC 3nm 製程上完全客製化設計的。隨著 Google 將其內部基礎設施轉向 ARM,Gmail、YouTube、Google Play 等服務將與 x86 並行運行在 Axion 上。未來,Google 將設計 Axion CPU 用作其驅動 Gemini 的 TPU 集群的主控節點。
AmpereOne 與軟銀收購


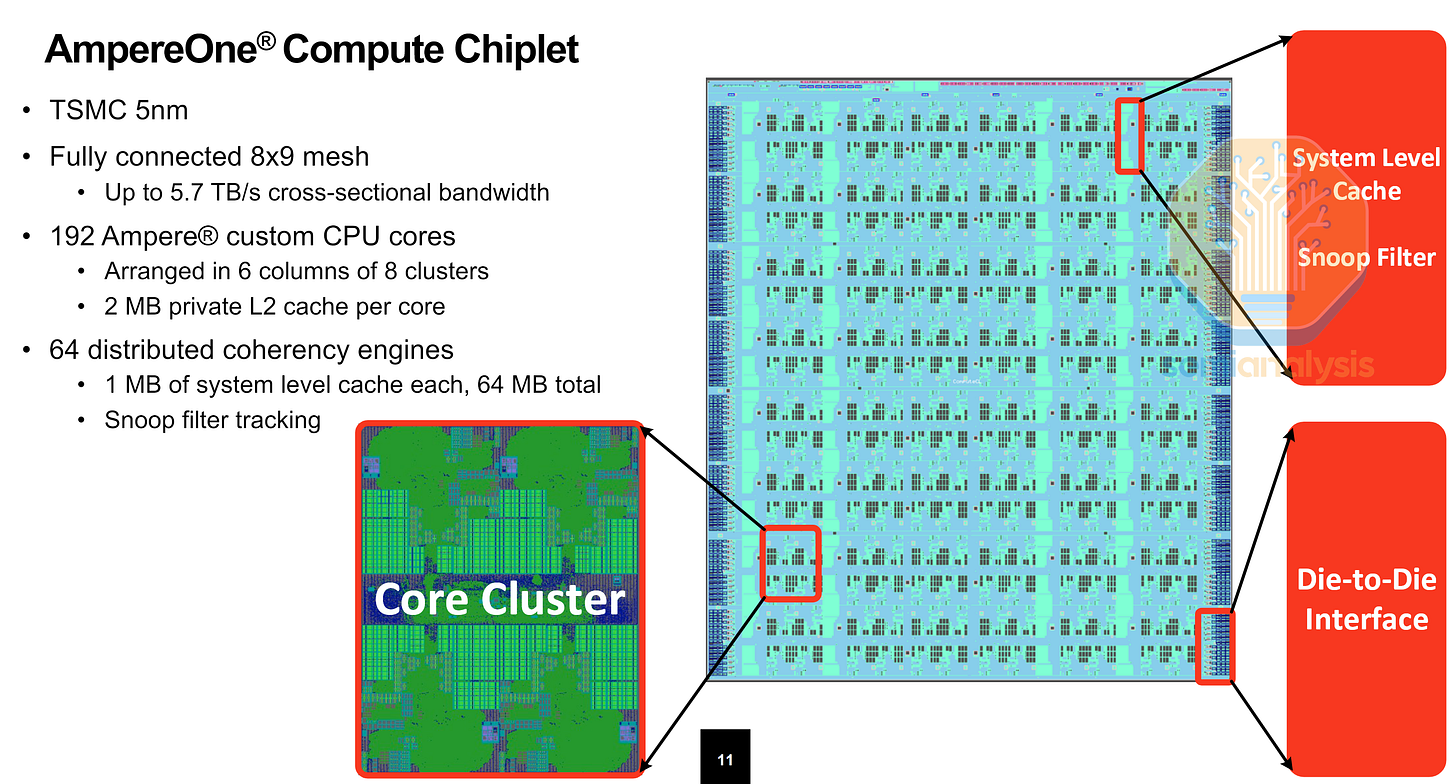
Ampere Computing 是商用 ARM 矽片的最初倡導者,作為第三家矽片供應商與 AMD 和 Intel 直接競爭 OEM 伺服器市場。憑藉與 Oracle 的強大合作夥伴關係,Ampere 大張旗鼓地推出了 80 核心 Altra 和 128 核心 Altra Max 系列 CPU,承諾透過具備成本效益的 ARM CPU 顛覆 x86 CPU 雙頭壟斷。Ampere Altra 採用 Neoverse N1 核心,並搭配自研的網格互連,核心分為 4 核心集群。在單個 TSMC 7nm 晶粒上配備了 8 通道 DDR4 和 128 條 PCIe4 通道。
下一代 AmpereOne CPU 憑藉轉向 5nm 製程和新穎的小晶片設計,將核心數提升至 192 個,該設計在不需要中介層(interposer)的 MCM 配置中將 IO 解構成獨立的 DDR5 和 PCIe 晶粒。Ampere 還轉向了自研 ARM 核心,旨在追求核心密度而非極致性能,並配備超大的 2MB L2 快取,以最小化來自鄰近核心(其運行的 VM 可能佔用共享網格互連流量)的性能干擾。在 9x8 網格網路上實施了類似的 4 核心集群。總體而言,整數性能比 Altra Max 翻倍。
小晶片設計允許相同的運算晶粒重複用於其他變體,例如 12 通道的 AmpereOne-M 增加了 2 個記憶體控制器晶粒。未來的 AmpereOne-MX 將重複使用相同的 I/O 小晶片,但換入具備 256 個核心的 3nm 運算晶粒。其 2024 年路線圖還詳細介紹了未來具備 512 個核心及 AI 訓練與推論能力的 AmpereOne Aurora 晶片。
然而,一旦 Ampere Computing 在 2025 年被軟銀以 65 億美元收購,該路線圖就不再有效。雖然孫正義確實想要 Ampere 的 CPU 設計人才來加強其 Stargate 計畫的 CPU 設計,但這次收購也是由 Oracle 想要擺脫表現不佳的業務所促成的。Ampere 的 CPU 由於時機和執行問題,從未達到足夠大的產量。
Altra 世代是他們首次重大的市場嘗試,但對於大規模採用來說來得太早,因為當時大多數軟體都不是 ARM 原生的。與超大規模業者可以迅速為其自研 ARM 矽片調整內部工作負載不同,通用和企業 CPU 市場的轉向要慢得多。隨後,AmpereOne 世代面臨多次延遲,Oracle Cloud A2 和 CPU 的可用性直到 2024 年下半年才實現。到那時,超大規模業者的 ARM CPU 專案已全面展開,且 AMD 也能提供 192 個核心,但單核性能高出 3-4 倍。儘管 Oracle 以減半的單核授權成本推廣 Ampere 實例,但這些 CPU 並不夠受歡迎,訂單枯竭。Oracle 從未用完其對 Ampere CPU 的全額預付款,其 Ampere CPU 採購額從 2023 財年的 4800 萬美元萎縮至 2024 年的 300 萬美元和 2025 年的 370 萬美元。
Ampere 現在正在軟銀旗下開發 AI 晶片以及 CPU。
ARM Phoenix
ARM 的核心 IP 授權業務在資料中心市場非常成功,幾乎每家超大規模業者都為其客製化 CPU 採用了 Neoverse CSS 設計。迄今為止,已在資料中心 CPU 和 DPU 中部署了超過 10 億個 Neoverse 核心,跨 12 家公司簽署了 21 份 CSS 授權。隨著核心數增加和超大規模業者 ARM CPU 的產量提升,資料中心權利金收入同比翻了一倍多,他們預計 CSS 在未來幾年將佔權利金收入的 50% 以上。閱讀我們的文章以了解更多關於 ARM 商業模式以及 CSS 如何提取更多價值。
昂貴的代價:Arm 追求提取其真實價值的探索
然而,ARM 在 2026 年更進一步,將提供完整的資料中心 CPU 設計,Meta 是其首位客戶。這款代號為 Phoenix 的 CPU 改變了商業模式,使其成為晶片供應商,設計從核心到封裝的整個晶片。這意味著 ARM 現在將與其授權 Neoverse CSS 架構的客戶直接競爭。由軟銀控股的 ARM 也在為 OpenAI 設計客製化 CPU,作為 Stargate OpenAI 軟銀合資計畫的一部分。Cloudflare 也有意成為 Phoenix 的客戶。我們在 Core Research 中詳細介紹了 COGS、毛利和營收。
Phoenix 採用標準的 Neoverse CSS 設計和佈局,與 Microsoft 的 Cobalt 200 類似。128 個 Neoverse V3 核心透過 ARM 的 CMN 網格網路連接,分佈在兩個採用 TSMC 3nm 製程的半光罩尺寸晶粒上。在記憶體和 I/O 方面,Phoenix 具備 12 通道 8400 MT/s 的 DDR5 和 96 條 PCIe Gen 6 通道。功耗效率具備競爭力,CPU TDP 可配置為 250W 至 350W。
藉此,Meta 現在擁有了自己的 ARM CPU,可與 Microsoft、Google 和 AWS 匹敵。作為 AI 主控節點,Phoenix 透過加速器啟用套件(Accelerator Enablement Kit),支持透過 PCIe6 與連接的 XPU 共享相干記憶體。我們將在下文為訂閱者詳細介紹下一代 ARM「Venom」CPU 設計,包括一項重大的記憶體變更。
華為鯤鵬
中國自研 CPU 的努力正穩步推進,龍芯(Loongson)和阿里巴巴的倚天(Yitian)系列都提供了本地設計的選擇。然而,市場上最大的參與者是華為,他們憑藉鯤鵬處理器系列重新聚焦了資料中心 CPU 路線圖。華為擁有來自其海思(HiSilicon)團隊最強大的設計工程師,具備值得關注的客製化泰山(TaiShan) CPU 核心和數據織網。
華為的前幾代資料中心 CPU 使用標準的行動 ARM Cortex 核心。2015 年的 Hi1610 具備 16 個 A57 核心。2016 年的 Hi1612 將核心數翻倍至 32 個,而 2017 年的鯤鵬 916 將核心架構更新為 Cortex-A72。這三代產品均由 TSMC 16nm 代工。

鯤鵬 920 於 2019 年面世,採用了雄心勃勃的多小晶片設計和 64 個客製化核心。兩個採用 TSMC 7nm 的運算晶粒各包含 8 個集群,每個集群有 4 個運行 ARM v8.2 ISA 的泰山 V110 核心。集群透過環形匯流排連接到同一晶粒上的四通道 DDR4,兩個運算晶粒總計 8 通道。鯤鵬 920 是首款採用 TSMC CoWoS-S 進階封裝的 CPU,使用大型矽中介層將 2 個運算晶粒連接到一個 I/O 晶粒,該 I/O 晶粒具備 40 條 PCIe Gen 4 通道和雙整合 100G 乙太網路控制器,使用客製化的晶粒間介面。雖然鯤鵬 920 整合了許多新穎技術,但美國對華為的制裁限制了其 TSMC 供應,打斷了其 CPU 路線圖,導致下一代鯤鵬 930 未能在 2021 年發布。

取而代之的是,更新後的鯤鵬 920B 於 2024 年低調發布,並進行了多項升級。泰山 V120 核心現在支持 SMT,兩個運算晶粒各具備 10 個 4 核心集群,共 80 核心、160 執行緒。核心互連和佈局與鯤鵬 920 類似,運算晶粒上具備 8 通道 DDR5。I/O 晶粒現在拆分為兩半,運算晶粒位於中間。我們相信這 5 年的 CPU 世代間隔是美國制裁以及必須為中芯國際(SMIC)N+2 製程重新設計晶片的結果。


2026 年,華為將再次更新其 CPU 產品線,推出鯤鵬 950,並將其配置在泰山 950 SuperPoD 機架中用於通用運算。鯤鵬 950 承諾利用其專有的 GaussDB 多寫(Multi-Write)分佈式資料庫架構,將 OLTP 資料庫性能提升 2.9 倍。為了實現這一點,核心數翻了一倍多,達到 192 個,採用了保留 SMT 支持的新 LinxiCore。還將生產較小的 96 核心版本。每個泰山 950 SuperPoD 機架包含 16 台雙插槽伺服器,配備高達 48TB 的 DDR5 記憶體,顯示為 12 通道記憶體設計。這些機架還整合了儲存和網路,並將被 Oracle 的 Exadata 資料庫伺服器採用,供中國金融部門使用。該設計可能會在中芯國際的 N+3 製程上生產,該製程最近在麒麟 9030 智慧型手機晶片中首次亮相。
華為的路線圖延續到 2028 年的鯤鵬 960 系列。這一代遵循將設計拆分為兩個變體的趨勢。一個 96 核心、192 執行緒的高效能版本將用於 AI 主控節點和資料庫,承諾單核性能提升 50% 以上;而用於虛擬化和雲端運算的高密度型號將把核心數增加到 256 個甚至更多。屆時,我們預計華為將在中國超大規模業者 CPU 部署中佔據顯著份額。
下文我們將展示到 2028 年的 CPU 路線圖,並詳細介紹 2026 年之後資料中心 CPU 的關鍵功能和架構變化,包括 AMD 的 Verano 和 Florence、Intel 的 Coral Rapids 和已取消的 CPU 系列、ARM 的 Venom 規格、Qualcomm 憑藉 SD2 重返資料中心 CPU 市場,並將 NVIDIA 的 Bluefield-4 作為未來 CPU 部署演進的標誌。接著,我們將討論 DRAM 短缺對各個資料中心 CPU 細分市場的影響,並展望未來 CPU 趨勢,強調將塑造未來十年 CPU 的關鍵設計方面。
本文僅供付費訂閱者閱讀
相關文章
其他收藏 · 0