
加州大學聖地牙哥分校實驗室藉由NVIDIA DGX B200系統推進生成式AI研究
加州大學聖地牙哥分校的Hao AI Lab實驗室獲得了NVIDIA DGX B200系統,以加速其在大型語言模型推論方面的研究,包括FastVideo和Lmgame benchmark等專案。
Hao AI Lab 研究團隊,位於加州大學聖地牙哥分校,是開創性 AI 模型創新的前沿,最近獲得了 NVIDIA DGX B200 系統,以提升他們在大語言模型 推論 方面的關鍵工作。
如今許多生產環境中的 LLM 推論平台,例如 NVIDIA Dynamo,都使用了源自 Hao AI Lab 的研究概念,包括 DistServe。
Hao AI Lab 如何使用 DGX B200?

Hao AI Lab 成員與 NVIDIA DGX B200 系統合影。
隨著 DGX B200 現已全面開放給 Hao AI Lab 以及加州大學聖地牙哥分校計算、資訊與數據科學學院 聖地牙哥超級計算中心 的更廣泛社群使用,研究機會無限。
加州大學聖地牙哥分校 Halıcıoğlu 數據科學研究所和計算機科學與工程系的助理教授 Hao Zhang 表示:「DGX B200 是 NVIDIA 迄今為止最強大的 AI 系統之一,這意味著它的性能位居世界前列。」「它使我們能夠比使用上一代硬體更快地進行原型設計和實驗。」
DGX B200 加速的兩個 Hao AI Lab 專案是 FastVideo 和 Lmgame benchmark。
FastVideo 專注於訓練一系列影片生成模型,以在五秒鐘內根據給定的文字提示生成五秒鐘的影片。
FastVideo 的研究階段除了 DGX B200 系統外,還利用了 NVIDIA H200 GPU。
Lmgame-bench 是一個基準測試套件,它使用流行的線上遊戲,包括俄羅斯方塊和超級瑪利歐兄弟,來測試 LLM。使用者可以一次測試一個模型,或者讓兩個模型相互對抗來衡量其性能。
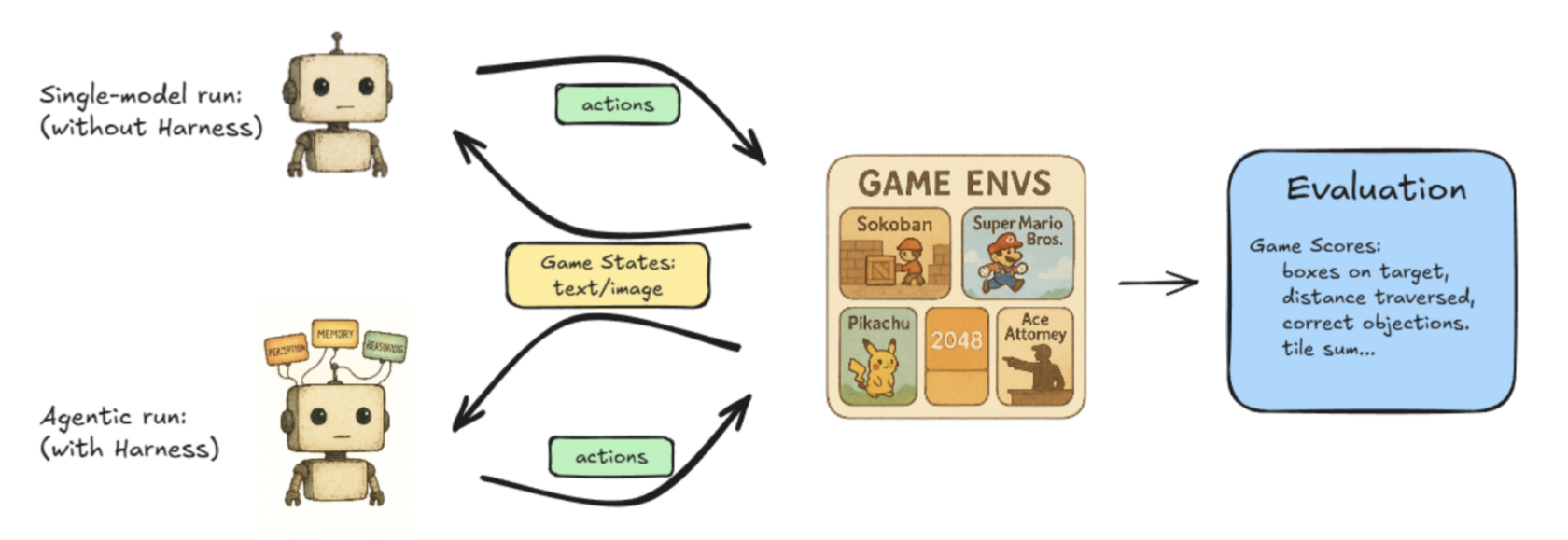
Hao AI Lab 的 Lmgame-Bench 專案的插畫工作流程。
Hao AI Labs 其他正在進行的專案正在探索實現低延遲 LLM 服務的新方法,推動大型語言模型實現即時響應。
加州大學聖地牙哥分校計算機科學博士候選人 Junda Chen 表示:「我們目前的研究利用 DGX B200,在系統提供的出色硬體規格上探索低延遲 LLM 服務的下一個前沿。」
DistServe 如何影響分散式服務
分散式推論 是一種確保大規模 LLM 服務引擎能夠實現最佳總體系統吞吐量,同時為使用者請求保持可接受的低延遲的方法。
分散式推論的好處在於優化 DistServe 所謂的「有效吞吐量」(goodput),而不是 LLM 服務引擎中的「吞吐量」(throughput)。
兩者之間的區別如下:
吞吐量以系統每秒產生的 token 數量來衡量。更高的吞吐量意味著為服務使用者生成每個 token 的成本更低。長期以來,吞吐量一直是 LLM 服務引擎用來衡量彼此性能的唯一指標。
雖然吞吐量衡量系統的總體性能,但它與使用者感知到的延遲沒有直接關聯。如果使用者要求更低的 token 生成延遲,系統就必須犧牲吞吐量。
吞吐量和延遲之間的這種自然權衡促使 DistServe 團隊提出了一個新指標,「有效吞吐量」(goodput):衡量在滿足使用者指定的延遲目標(通常稱為服務等級目標)情況下的吞吐量。換句話說,有效吞吐量代表了系統在滿足使用者體驗情況下的整體健康狀況。
DistServe 表明,有效吞吐量是 LLM 服務系統的更好指標,因為它同時考慮了成本和服務品質。有效吞吐量能夠實現最佳效率和模型的理想輸出。
開發者如何實現最佳有效吞吐量?
當使用者在 LLM 系統中發出請求時,系統會接收使用者輸入並生成第一個 token,稱為預填(prefill)。然後,系統會一個接一個地生成大量輸出 token,根據過去請求的結果預測每個 token 的未來行為。這個過程稱為解碼(decode)。
過去,預填和解碼都在同一 GPU 上運行,但 DistServe 的研究人員發現,將它們分割到不同的 GPU 上可以最大化有效吞吐量。
Chen 表示:「以前,如果你將這兩項任務放在一個 GPU 上,它們會爭奪資源,這可能會從使用者角度來看很慢。」「現在,如果我將任務分割到兩組不同的 GPU 上——一個執行計算密集型的預填,另一個執行記憶體密集型的解碼——我們可以從根本上消除兩項任務之間的干擾,使兩項任務都運行得更快。」
這個過程稱為預填/解碼分散,或將預填與解碼分離以獲得更高的有效吞吐量。
提高有效吞吐量並使用分散式推論方法,可以在不損害低延遲或高品質模型響應的情況下,持續擴展工作負載。
NVIDIA Dynamo — 一個旨在以最高效率和最低成本加速和擴展生成式 AI 模型開源框架 — 使分散式推論的擴展成為可能。
除了這些專案外,加州大學聖地牙哥分校還在進行跨部門合作,例如在醫療保健和生物學領域,以進一步優化一系列使用 NVIDIA DGX B200 的研究專案,因為研究人員將繼續探索 AI 平台如何加速創新。
深入了解 NVIDIA DGX B200 系統。
相關文章