用於從肌電訊號連續估計手部運動學的平行高效Transformer深度學習網路
本研究提出PET,一個輕量級的平行高效Transformer模型,以解決現有基於表面肌電訊號的手部運動學估計方法的高延遲、高記憶體和高功耗問題。PET能夠即時分解肌電訊號並輸出手指關節角度,同時降低資源需求,並在多種資料集上取得了最先進的效能。
Subjects
Abstract
Surface electromyography (EMG) provides a non-invasive human-machine interaction interface that can promote the coherence of human-machine interaction operations. Decomposing surface electromyographic signals into hand joint angles in real time can be applied to prosthetic control, rehabilitation engineering and other fields. However, existing methods of using surface electromyography signals suffer from high end-to-end latency, high memory consumption, and high power consumption, which hinder their dissemination in clinical edge devices and public wearable devices. After a thorough analysis of the state-of-the-art surface EMG based architecture, we observed that the time complexity of the attention mechanism in using Transformer for continuous motion estimation results in longer inference time. The attention mechanism requires a large number of parameters to achieve good results, leading to higher model power consumption. This will reduce its performance in continuous motion statistics. To tackle the existing Surface EMGs challenges, PET, a lightweight parallel efficient transformer model, is proposed. We elaborately develop a thorough bottom-up architecture of PET, from model structure and power mechanism. The PET’s parallel and lightweight architecture can decompose the surface electromyography in real time and output the hand joint angles while compacting memory consumption and affordable power expenditure without sacrificing the accuracy of extracting motion statistics. Compared to the state-of-the-art surface EMG architectures, the experimental results demonstrate that PET outperforms SVR, TCN, LSTM, GRU, LE-LSTM, LE-ConvMN, Transformer, Bert, MAFN and Conformer by Correlation Coefficient, RMSE, NRMSE, AME, End-to-end latency in variety of challenging Surface EMG programs, including Ninapro DB2, Ninapro DB7, FMHD, and SEEDS. The PET correlation coefficient for all 60 subjects in the Ninapro dataset was 0.85 ± 0.01, the root mean square error was 7.26 ± 0.32, the normalized RMSE was 0.11 ± 0.01, and the AME was 6.183. The PET correlation coefficient in the test of the Finger Movement HD was 0.81 ± 0.01, and the root mean square error was 10.15 ± 0.52 with a normalized RMSE of 0.11 ± 0.01. The PET correlation coefficient in the test of the SEEDS was 0.82 ± 0.01, and the root mean square error was 10.09 ± 0.01 with a normalized RMSE of 0.10 ± 0.01. Our method achieved state-of-the-art performance in the above tests. The results of the above tests were based on the same subjects.
Similar content being viewed by others
Classification of hand and wrist movements via surface electromyogram using the random convolutional kernels transform
Hand gesture recognition using sEMG signals with a multi-stream time-varying feature enhancement approach
High-density Surface and Intramuscular EMG Data from the Tibialis Anterior During Dynamic Contractions
Introduction
Electromyography (EMG) is a technique used to record and analyze the signals produced by the electrical activity of skeletal muscles. Surface EMG signals are muscle electrical signals extracted from the surface of human skin using electrodes, which can be smoothly collected through non-invasive implanted dry electrodes. Surface EMG signals are generated by active muscles that occur approximately 200 to 300ms prior to actual muscle alterations, thus can be used as confident clues of real-time human movement prediction. Decoding human movement intention from surface EMG signals exhibits promising potential in a variety of domains, including prosthetic control, intelligent human-computer interaction, rehabilitation training, and artificial limbs movement qualification.
Surface EMG inspired human motion intention prediction is a category and regression tasks. Compared to discrete motion classification, contemporary experimental results demonstrate that continuous motion regression estimation is more direct, natural, and flexible to reflect human motion intention. Current continuous motion estimation methodologies can be assorted into two groups1 : model-based and model-free. Model-based methodologies facilitate human mechanical knowledge to construct competent estimation models, such as kinematic models2, and musculoskeletal models3. Model-free methodologies directly employs artificial intelligence techniques without exploiting existing human mechanical knowledge. Deep learning models have the ability to automatically extract features. Taking CNN as an example, by sliding the convolution kernels in the convolutional layer over the sEMG signal data, local features in the signal can be automatically learned, such as the initial stage features of muscle contraction and local patterns of different frequency components. These convolution kernels are like automatically adjusted filters that can adapt to signal changes of different individuals and motion tasks. This automatic feature extraction capability greatly reduces the workload of manual feature engineering and can mine more complex and representative features, thereby improving the accuracy of motion intention prediction. Deep learning models can easily integrate information from multiple modalities. For example, a multi input deep learning architecture can be constructed, using sEMG signals and joint angle information as different input channels, and integrating and jointly learning these information within the model through structures such as convolutional layers and fully connected layers.
Beneficial to the powerful capabilities of artificial intelligence techniques, model-free methodologies outperform significantly to the model-based methodologies in terms of motion predication accuracy. Unfortunately, our observations indicate that current state-of-the-art model-free methodologies are extensively computing-intensive, making them challenging to be deployed on computing-resource constrained edge devices. Furthermore, the inferior memory maneuver severely deteriorates the battery life of edge devices. These deficiencies remarkably hinders the model-free techniques dissemination in human motion predication region.
To tackle the existing model-free methodologies challenges, we present PET, a lightweight model-free architecture designed with the Parallel Efficient Transformer (PET) network. In the attention mechanism of Transformer, when calculating the attention score, each query vector needs to be dot product with all key vectors. For a sequence of length n, n * n operations are required, with a complexity of (O(n^2)). The computational complexity increases dramatically when processing long sequences. In order to reduce computational complexity, we advocate the use of external attention mechanisms to reduce the computational complexity of state-of-the-art Transformer model free methods. In addition, we designed and used a parallel Transformer structure to improve the stability of the model without reducing training efficiency. Finally, in order to significantly improve the stability of our proposed architecture, we explored and practiced various methods for initializing model parameters. The purpose is to guide the model to learn in a more optimal direction during the training process, and through reasonable parameter initialization, enable the model to converge more stably. These enhancements render PET’s high efficiency in surface EMG signals’ processing, leading to a significant improvement in computing performance and power expenditure on resource-constraint edge devices, such as raspberry pi.
To summarize, the contributions of this work are as follows:
We advocate an external attention mechanism to scale down the computing complexity of state-of-the-art model-free methodologies. Unlike traditional self-attention with O(n²) complexity, our external attention uses fixed learnable tokens to model global dependencies, cutting complexity to O(n).
We reduce model-free methodologies’ end-to-end latency by replacing the existing attention mechanism and feedforward network’s serial structure with a specifically designed parallel transformer framework.
We conduct a comprehensive evaluation that includes the enhancement effect of each innovation features. Compared to the state-of-the-art surface EMG architectures, the experimental results demonstrate that PET outperforms TCN, LSTM, GRU, LE-LSTM, LE-ConvMN, Transformer, Bert, MAFN and Conformer in inference delay and AME in various challenging surface electromyography programs, including Ninapro DB2/DB7, SEEDS and finger motion HD, with similar correlation coefficients and NRMSE.
Related works
Model-free surface EMG methodologies: Mobarak et al.4,5 utilized time-domain and wavelet features from thigh muscle surface electromyography signals, combined with traditional machine learning models, to achieve ankle joint angle estimation using only proximal lower limb information. They further introduced an LSTM model, comparing and validating that the combination of time-domain features with a shallow LSTM yields high accuracy and efficiency in ankle joint angle estimation. Atzori et al.6 proposed a deep CNN-based neural network with raw EMG data as input, whose performance is comparable to that of machine learning-based methods. Cote-Allard et al.7 attempted to aggregate signals from multiple users through deep migration learning, thus generating a large amount of data to learn common informative features and reduce the calibration time for new users. Zanghieri et al. proposed a novel EMG algorithm based on a temporal convolutional network (TCN) for sEMG-based robust gesture recognition and grip recognition methods8,9. Wu et al.10 proposed a robust dilated convolutional neural network (DCNN)–based EMG control method that can mitigate the disturbance of electrode offset. Compared with ordinary convolutional neural networks, DCNN always contains a larger receptive field, which is more adept at mining a wider range of spatial contextual information in an image. Xiong et al.11 proposed a method for electromyographic pattern recognition by learning non Euclidean representations from electromyographic signals using symmetric positive definite (SPD) manifolds.
However, migration learning adds extra structures that take up memory, the output model can only be migrated from one subject to another, and it is still difficult to generate a model to be applied to two or more subjects at the same time.
The current methods used have many problems. On the one hand, some methods perform poorly in terms of prediction accuracy, and their results often have significant deviations from the actual situation. On the other hand, there are also some methods that are computationally intensive and require a significant amount of computing resources to complete tasks. This makes it impossible to deploy these methods on edge devices, as the computing power of edge devices themselves is very limited.
Emerging transformer architecture: The Transformer architecture, along with the attention mechanism, can be considered to be the mainstay behind many of the recent successes in the field of deep learning. Self-attention-based Transformer architectures, which can capture long-range features and have high training efficiency, have been widely used in sequence modeling12,13. Lin et al.14 proposed a method based on the transformer bi-directional encoder representation (BERT) structure, which, based on the root-mean-square (RMS) of the sEMG signals normalized by the (\mu)-law features to predict hand motion, a hard sample mining strategy is employed to stabilize the estimation from sEMG. Self-attentive learning excels at global interactions, and convolution effectively captures spatial-based local correlations. Gulati15 et al. proposed a novel self-attention combined with convolution for automatic speech recognition (ASR), and Rahimian et al. proposed a small number of learning gesture recognition frameworks combining temporal convolution with an attention mechanism and a visual Transformer-based (VIT) model for upper limb gesture classification and recognition16,17. The Transformer model has the problems of computation time and high complexity when processing data. In its core attention mechanism computation, the computational complexity is quadratic with the length of the input sequence. Both the training and inference stages are affected by this high complexity, especially in the case of limited hardware resources, which may result in extremely slow processing speed and seriously affect the practical application efficiency of the model.
Understanding model-free surface EMG methodologies
Background, challenges and motivations
The typical structure of the current model free architecture is to use recurrent neural networks and Transformers to estimate the joint angles of fingers through surface electromyography signals.
The computational complexity of recurrent neural networks is relatively high. Due to the need for recursive computation at each time step, recurrent neural networks18,19,20,21 consume a significant amount of computational resources and time when processing long sequences. This may be a challenge for real-time continuous estimation of hand movements, especially when running on devices with limited resources. In addition, when processing long sequences, recurrent neural networks gradually weaken their memory of early information over time, making it difficult to effectively capture long-term dependencies. If the recurrent neural network cannot capture the changes in electromyographic signals over a long period of time well, inaccurate estimation may occur during the continuous process of prosthetic movement, resulting in disjointed movements of the prosthetic. Especially when performing complex and continuous hand movements, it is necessary to rely on electromyographic signal information from a long period of time in the past. If the recurrent neural network cannot effectively process it, it will cause the prosthetic to experience stuttering or unnatural transitions during the movement transition process.
Due to the effective capture of global dependencies by Transformers, there may be complex global correlations between electromyographic signals of different muscles in hand motion estimation, and Transformers can better integrate this information. Therefore, some people hope to use Transformer to address the shortcomings of recurrent neural networks. However, Transformers typically require a large amount of data for effective training. It is relatively difficult to obtain sufficient high-quality samples of surface electromyographic signal data for hand movements, especially for various hand movements and individual differences. If the amount of data is insufficient, it may lead to overfitting of the model or insufficient learning of effective hand motion patterns, thereby affecting the accuracy of estimation. Transformer models22 typically have a large number of parameters, which require powerful computing resources for training and inference. In practical applications, especially for scenarios that may require real-time hand motion estimation to control prostheses, it may be difficult to meet the requirements of computing resources, resulting in high latency or inability to provide accurate estimation results within a limited time.
We hope to solve the problem of high computational complexity in Transformers by improving the attention mechanism. Inspired by external attention23 and parallel structures24, we have independently designed an attention computing mechanism and a parallel module, and paid attention to the impact of parameter initialization and model stability on accuracy during the training process, thus achieving a combination of fast inference and high accuracy.
Characterization methodology
Platform setups
In terms of hardware configuration in this study, the training model used NVIDIA GeForce RTX 4060 GPU. In order to perform performance testing on the model on edge devices, we chose Raspberry Pie as the simulation platform. Raspberry pie, as a device widely used in edge computing scene simulation, has the characteristics of small size, strong flexibility, low power consumption, and is consistent with the device characteristics in the actual edge computing scene. Through testing on Raspberry Pie, we can effectively evaluate the performance of the model in the resource constrained real-time edge computing environment, including key performance indicators such as model response speed, resource occupancy and stability in complex environments. At the software level, model development work is done using the PyTorch framework25. In addition, we used Matlab during the data preprocessing stage. Meanwhile, during the optimization process of the model, we chose the Adam optimizer.
Evaluation datasets
We select Ninapro DB216, Ninapro DB726, FMHD27, and SEEDS28 as our evaluation datasets.
We chose these datasets because of their significant advantages. From the perspective of source and quality, the data is collected by high-precision sensors in a professional environment, including high-density and sparse surface electromyography signals, which are accurate and reliable, and can reflect muscle movement information. It covers a wide range of hand and arm movement categories, providing comprehensive materials for motion intention prediction models. The data contains different individual information, and individual differences result in different signals for the same movement. In addition, these datasets are commonly used in this field for model validation comparison, which facilitates the evaluation of method effectiveness and provides reference for future research and improvement.
Ninapro DB2: Ninapro DB2 is a state-of-the-art dataset widely used in the surface EMG estimation qualification. We utilize Ninapro DB2’s gesture movements data from all subjects. The gesture movements are repeated six times in the experiment. The first four times are used as our training dataset and the rest two times are used as our test dataset.
Ninapro DB7: Compared to Ninapro DB2, Ninapro DB7 collects extra electromyographic signals to expedite motion intention decoding analysis. We utilize data from 20 healthy subjects in Ninapro DB7 dataset. To alignment the data initialization with Ninapro DB2, the gesture movements are also repeated six times in the experiment. The first four times are used as our training dataset and the rest two times are used as our test dataset. In this paper, Ninapro DB2 and DB7 datasets are uniformly referred as Ninapro. We select 6 widely used gestures as our experimental database from the overall Ninapro datasets.
FMHD: FMHD is an open-source dataset that conduct the experiments in three phases. Each experiment consists of three stages, in which participants are required to complete three fast and three slow experiments in different arm postures in sequence.Each phase contains six repetitions: three fast and three slow respectively. We use two of the fast and slow repetitions as our training set and one as our test set.
SEEDS: SEEDS is an open-source dataset that is designed to enhance proportional control algorithms for robotic prosthetic hands. SEEDS contains experimental data from 25 subjects. The experimental procedure is divided into three sessions, with six repetitions of each subjects’ 13 fixed movements. We randomly select 20 subjects from SEEDS as our experimental samples and utilize 6 hand movements as our test bench. We use first four times as our training dataset and the last two times as our testing dataset. To ensure data consistency, we restore the hand kinematics data from normalized values to their original values. The sampling frequency of EMG data stream is reduced to 2048 Hz, and the data glove rate is reduced to 256 Hz.
Datasets’ Gesture Selection: We select ten finger joints in Ninapro DB2, Ninapro DB7 and SEEDS datasets for evaluation, which are thumb-roll, thumb-inner, ti-abduction, index-inner, index-middle, middle-inner, mi-abduction, ring-inner, rm-abduction, and pinky-inner. These joint angles are crucial for hand movements, as they are key elements for achieving various fine movements and complex postures of the hand. The changes in joint angles during hand movements such as grasping, pinching, and stretching directly reflect the state and intention of the movement. Moreover, it is worth mentioning that there is a close intrinsic relationship between the other joint angles and these ten joint angles. Through specific calculation methods, the remaining joint angles can be roughly derived based on these ten joint angles, thus ensuring the comprehensiveness of the evaluation while also reflecting the core representativeness of these joint angles in the evaluation system. Since the FMHD dataset has no thumb kinematics, we select eight joint angles, including ti-abduction, index-inner, index-middle, middle-inner, mi-abduction, ring-inner, rm-abduction, and pinky-inner to compensate the experimental evaluation.
Data normalization and evaluation metrics
In the data preprocessing process, a series of key operations such as data cleaning, normalization, and feature extraction were completed, effectively removing noise and outliers from the original data, and improving the consistency and reliability of the data. When inputting data into the model, use a sliding window to read the data, with a uniform window size of 100ms and a step size of 50ms. This setting method can ensure that the model has sufficient information capture capability for data, while avoiding problems such as data information loss or computational resource waste caused by unreasonable window size or step size.
In this study, we selected logarithmic normalization (LN) as the data normalization algorithm, while using Pearson correlation coefficient (PCC), root mean square error (RMSE), and normalized root mean square error (NRMSE) as evaluation metrics. Logarithmic normalization can compress the dynamic range of surface electromyographic signals by 2 to 3 orders of magnitude to avoid numerical overflow and suppress the interference of outliers in surface electromyographic signals on model training. Pearson correlation coefficient (PCC) plays an important role in this study, mainly used to quantify the degree of correlation between actual joint angles and predicted joint angles. Our evaluation is also based on PCC as the most important criterion. Through the calculation of PCC, we can clearly understand the degree of correlation between the predicted results of the model and the actual situation, which provides a key basis for evaluating the predictive ability of the model. Root Mean Square Error (RMSE) is also an important indicator in the evaluation process, which can effectively measure the size of the error between the actual joint angle and the joint angle predicted by the deep learning model. However, it should be noted that due to the specificity of each individual’s finger movement range, this individualized characteristic makes RMSE limited in uniformly evaluating algorithm advantages. That is to say, the value of RMSE will fluctuate due to individual differences and cannot form a universally comparable standard among different individuals. In view of this, we introduced Normalized Root Mean Square Error (NRMSE) as an evaluation metric. NRMSE effectively eliminates the impact caused by individual differences in finger movement range by normalizing RMSE. This enables us to have a more objective and unified standard for evaluating the performance of algorithms on different individuals, thereby more accurately assessing the strengths and weaknesses of algorithms in different individual contexts, and providing more convincing data support for model performance evaluation. In order to accurately evaluate the computational power consumed by the model, we used real ARM devices. In this evaluation process, we used the evaluation metric - ARM model efficiency, which is determined by the ratio of model inference time to model power consumption. This approach can effectively quantify the utilization of computing resources by the model when running on ARM devices, providing a strong basis for evaluating the performance of the model in practical application scenarios:
where (Infer_Time) is the inference time of the model, and Power is the power consumption of the model running on ARM devices
Design
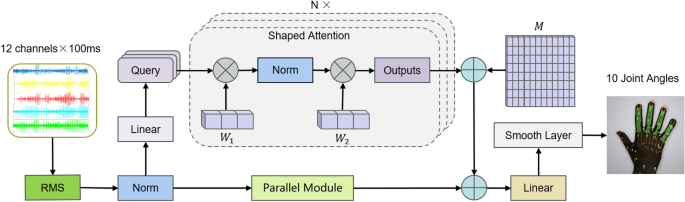
The current continuous estimation model exposes shortcomings in end-to-end latency, memory consumption, and power consumption, which seriously hinders the deployment of sEMG models on modern resource constrained edge devices. To address existing challenges, we have introduced PET, a continuous estimation architecture designed using parallel efficient transformers (PET). Specifically, PET consists of a lightweight external attention mechanism, novel feature extraction features, and a compact smoothing layer. The overview of the proposed continuous estimation architecture is shown in Fig. 1.
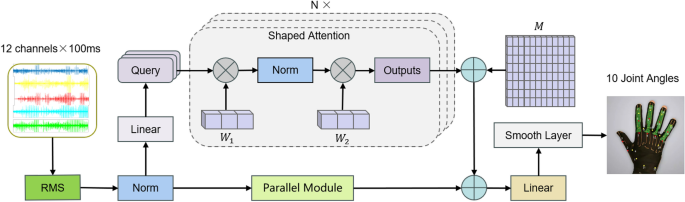
The model structure of our proposed continuous hand joint angle estimation method. The original sEMG signal is extracted as long exposure RMS features, which can be seen as a method of enhancing data. Therefore, these features are divided into slices with a length of 100ms. After normalization, they enter a parallel structure and are processed by parallel network modules and deformable attention, respectively. Finally, all estimated values are smoothed by a smoothing layer. Among them, (W_1) and (W_2) refer to convolutional kernels, and M is a learnable tensor.
External attention
Self-attention is a special attention mechanism that allows models to consider the relationship between each element in a sequence and all other elements when processing a sequence. The original self attention mechanism only considers the relationships between elements in the data sample, while ignoring the potential relationships between elements in different samples. This makes the model only focus on the relationship between the current input surface electromyography signal and the given hand joint angle, while ignoring the connection between the current hand action and the previous action. Guo et al. proposed a novel attention module called external attention. We attempted to use this external attention directly to replace the original attention mechanism, but the results were not satisfactory. The inference effect is relatively poor in movements with large joint angle movements. We consider that convolution operations can effectively extract local data features, so we attempt to use convolution operations instead of external memory modules. In this way, the data is processed through the first one-dimensional convolution operation to obtain a complete feature map, normalized, and then processed through the second convolution to finally obtain the output of the attention mechanism. In this way, the parameters of two convolutions are used as external memory, which are independent of individual samples and can be shared throughout the entire dataset, improving the generalization ability of the attention mechanism. Meanwhile, due to the high efficiency of convolution operations, the computational complexity of the original attention mechanism is also solved, further improving the running speed of the model.
External memory aims to learn the most discriminative features of the entire dataset, capture the most informative parts, and eliminate interference from other samples. The formula can be expressed as:
where ‘(*)’ denotes the convolution operator and ‘(\circ)’, denotes the Hadamard product. (W_q) and (W_v) are learnable matrices, while (W_c) and (W_d) are convolutional kernels
In practical use, we have found that when the model is stacked in multiple layers, the effect of the model is often unsatisfactory once the number of layers exceeds 3. We considered that the instability of the model structure may result in poor performance when the number of layers increases, so we added two additional learnable matrices. Set the initial value of matrix I to 0, and set the initial value of matrix C to be the same as the initial value of external attention. Then set alpha to 1, with beta and gamma values being the same. Alpha, beta, and gamma are all learnable variables, which makes the model relatively stable during initial training. The formula can be expressed as follows:
where (\alpha), (\beta), and (\gamma) are learnable variables, (W_I) and (W_C) are learnable matrices, and EA is the output of external attention
Parallel SOTA transformer architecture
Using external attention calculation directly and abandoning Feed Forward can speed up the model operation. However, since the control of model parameters has reached the extreme, removing this module will damage the performance of the model to a certain extent. So we try to process it in parallel with the attention module and modify its content mainly through convolution. Finally, a module similar to skip connections was obtained in parallel with the attention mechanism. After adding this module, the computational speed is almost the same as using only the attention module, and the performance of the model will not weaken. This parallel module can be expressed using the formula:
where ‘(*)’ denotes the convolution operator and ‘(\circ)’, as before, denotes the Hadamard product. (W_u), (W_v), and (W_t) are convolution kernels, (W_m) and (W_n) are learnable matrices, and IP is a linear interpolation operation.
Experiments
We evaluate the performance of the proposed PET compared to contemporary SOTA sEMG architectures in standard continuous hand movement estimation tasks. We verify the CC, RMSE, and NRMSE to demonstrate the accuracy if the proposed architecture. We also calculated the average training time for each epoch and estimated the convergence time for each training operation. The shorter the average training time, the less time and equipment consumption it takes to initialize the model for an individual.The inference time is used to estimate the architecture’s end-to-end latency performance. We deploy PET on edge devices with various hardware settings to extensively evaluate the robustness of PET. PET and various models were deployed on edge devices to measure power consumption.
Accuracy advantage of PET
We compare our proposed PET architecture’s motion prediction accuracy to contemporary SOTA models in hand joint angle estimation tasks. PCC, RMSE, and NRMSE are utilized to evaluate the joint angles’ predication accuracy of all sEMG architectures. However, it should be noted that the purpose of our research is to apply it to human-computer interaction, rehabilitation robot control and other fields, and it is necessary to give priority to understanding the user’s movement trends. A high PCC value proves that the model can stably capture the temporal logic of the movement, and RMSE and NRMSE can prove the accuracy of the numerical value. Therefore, we will use PCC as the main evaluation criterion, and RMSE and NRMSE can be at a relatively reasonable level. Concerning the Transformer model, we use a hyperparameter of 64 and set the number of heads for its multi-head attention to 4.
Table 1 demonstrates the experimental results in Ninapro. We observe that the best accuracy in Table 1 is PET (CC=0.8472; RMSE=7.2645; NRMSE=0.1128). This was followed by Bert from the Transformer series (CC=0.8122; RMSE=2.9725; NRMSE=0.1333). GRU from the RNN series (CC=0.8102; RMSE=7.9289; NRMSE=0.1246) and TCN from the CNN series (CC=0.7505; RMSE=0.8927; NRMSE=0.1376) also perform well. It is worth noting that sBERT-OHEM and MAFN also used the NINAPRO DB2 dataset for experiments. However, the difference is that in their experiments they selected a part of the subjects in DB2 for the experiments, while we included all the subjects in DB2 and DB7 in the experimental scope. We also repeat their experimental method to compare it with our proposed method. Only in the RMSE evaluation method, PET’s performance was slightly lower than sBERT-OHEM. In other evaluation methods, PET outperformed sBERT-OHEM and MAFN.
In the model system we have constructed, innovative improvements have been made to the external attention module, specifically by carefully introducing the key element of convolution operation. From the perspective of information processing mechanisms, convolution operation has excellent performance in data feature extraction, and its mathematical principles endow it with high sensitivity to local information and precise feature capture ability. When integrating convolution operations into the external attention module, it brings a new dimension of information perception to the entire model. The direct impact of this improvement is that the model exhibits stronger learning ability when processing data, especially for the details hidden in the data. In complex data environments, these detailed information do not exist in isolation and have significant value in accurately understanding the underlying mechanisms of the research object and constructing accurate models. Traditional models or methods often only capture macro level information due to the lack of sufficient fine information processing capabilities, and are unable to deeply explore these micro level details. However, introducing convolution operations in the external attention module greatly enriches the information content mastered by the model.
This ability to learn detailed information further plays a crucial role in the model fitting process. Due to the enhanced ability of the external attention module to obtain detailed information through convolution operations, the matching degree between the model output and the actual data is significantly improved. In addition, compared with traditional attention mechanisms, our proposed external attention mechanism exhibits significant advantages in two aspects. On the one hand, it has the ability to learn cross action features. In many cases, the behavior of research subjects often presents diverse action patterns, and these different actions are not completely independent of each other, but have complex internal connections. Traditional attention mechanisms often only focus on the internal information of each action when dealing with data with complex action correlations, making it difficult to effectively capture potential correlation features between actions. Our proposed external attention mechanism, with its unique design, external learnable memory, and convolutional operation assistance, can break through this limitation and deeply explore the shared feature information between different actions, thus establishing a more comprehensive and in-depth model understanding.
On the other hand, in the learning process for each individual action, due to the addition of convolution operations, our external attention mechanism can keenly perceive more subtle changes. These subtle changes may be caused by various factors such as changes in the internal state of the research object and external environmental disturbances. Due to the limitations of its own information processing, traditional attention mechanisms may overlook these subtle changes, resulting in incomplete and inaccurate understanding of actions. However, our proposed external attention mechanism relies on the fine information capture ability brought by convolution operations to more accurately grasp the essential features of each action, providing the model with stronger capabilities when processing complex action data. The advantages of these two aspects together constitute the core competitiveness of our proposed external attention mechanism in processing complex data, providing a more effective model design approach for research in related fields.
Tables 2 and 3 present in detail the performance of each model on high-density datasets. In the context of the FMHD dataset, the PET model demonstrated excellent performance in terms of CC (correlation coefficient) metric, with a CC value of 0.8145, RMSE (root mean square error) of 10.1578, and NRMSE (normalized root mean square error) of 0.1185, standing out among all models evaluated. In addition, the MAFN model also showed a high level, with a CC value of 0.7467, RMSE of 8.3389, and NRMSE of 0.1354. It is worth noting that the MAFN model utilizes unique methods in the data preprocessing stage, successfully extracting multiple types of features, and fusing these diverse features in the subsequent model calculation process. This series of operations may be one of the reasons for its excellent performance. Further observation of Table 3 shows that our proposed PET model performs excellently in high-density surface electromyography datasets, with a CC value of 0.8224, RMSE of 10.0918, and NRMSE of 0.1035. After the PET model, the GRU model in the recurrent neural network series also achieved good results, with a CC value of 0.8104, RMSE of 10.3656, and NRMSE of 0.1066. These results strongly demonstrate the excellent performance of our proposed PET model, which not only exhibits excellent characteristics in processing sparse electromyographic signals, but also maintains outstanding performance when facing high-density surface electromyographic signals.
This excellent performance can be attributed to two key factors. On the one hand, our carefully designed external attention mechanism has unique advantages, as it can efficiently store various data using streamlined storage modules. This storage method ensures the integrity and accessibility of data without consuming too many resources, providing a solid foundation for the model to process data. On the other hand, the parallel module we designed played an important role in the entire model system. This module can accurately extract detailed information from a large amount of data and use it to modify the results obtained by the attention mechanism. Through this correction, the model’s ability to understand and process data can be further optimized, thereby improving its performance in high-density surface electromyography data environments and ensuring the accuracy and reliability of the model output.
In Fig. 2, we clearly show the real data curves of several representative models outputting hand joint angles. From the curve shape, it can be seen that in the initial few waveform stages, most models can achieve good fitting results. This phenomenon can be attributed to the fact that the first few actions in the test data have a relatively small range of motion and a simple action pattern for the joint, making it relatively easy for the model to predict at this stage.
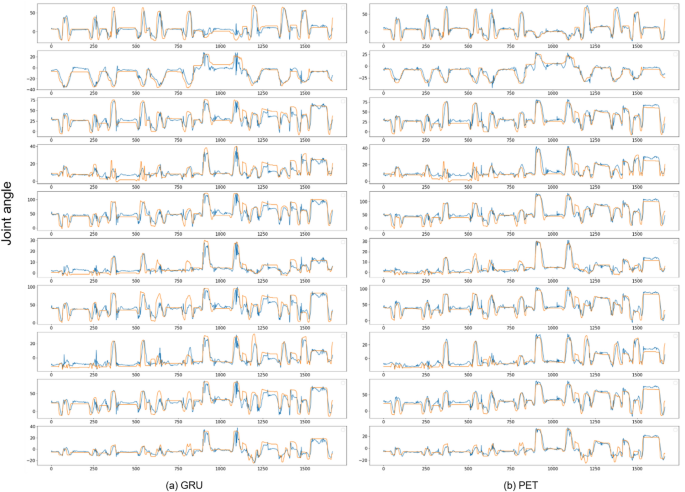
The proposed parallel efficient Transformer and GRU joint angle continuous motion estimation. The red curve represents the actual joint angle, and the blue curve represents the estimated result. Data from Ninapro DB2 is used here, and a schematic diagram of ten joint angles is shown in the figure.
However, when the data curve develops to the seventh and eighth fluctuations, most models show a significant decline in performance and the fitting effect deteriorates. Further analysis reveals that this is due to the fact that the subsequent two actions mainly rely on the thumb to complete, resulting in a significant increase in their amplitude and complexity. This complex action pattern places higher demands on the predictive ability of the model, exceeding the processing capacity of most models, leading to difficulties in fitting.
It is worth noting that in this case, our proposed PET model still demonstrates excellent fitting ability and maintains good adaptability to complex changes in hand joint angles. This advantage mainly stems from the strong cross action learning ability of the external attention mechanism we designed. During the operation of the model, when the thumb joint angle is constantly increasing, this mechanism can efficiently retrieve and obtain similar action information learned previously from external memory. This effective utilization of past similar action information enables the PET model to better understand and process current complex actions, thus accurately fitting data even when facing situations with large action amplitudes and complex action patterns, reflecting the unique advantages of this model in processing complex hand action data.
End-to-end latency advantage of PET
To evaluate the end-to-end performance of PET architecture, we deployed the model on NVIDIA GeForce RTX 4060, Intel I9-13900HX, and Raspberry Pi, where GeForce RTX 4060 is a high-performance GPU chip used in professional laptops with a maximum power consumption of 115 W, and the I9-13900HX is a processor used in high-performance computers with a chip with a maximum power consumption of 55W. The Raspberry Pi is an ARM device that consumes a maximum of only 6.25W and requires only a 5 V power supply. Based on the comparison of inference time and power consumption, we can get an idea of whether a model can be used for portable devices or not. In calculating the inference time, we take the average of 30 inference runs using the corresponding model on different devices respectively.
In the evaluation of inference time, we observed a series of significant phenomena. Among many models, due to the inability of the three models in the RNN sequence to perform parallel computing and the extremely large number of parameters, these two factors work together, resulting in a significant increase in their inference time compared to other models. In terms of comparison of inference time, RNN sequence models are at a significant disadvantage.
For the Transformer series models, although their self attention mechanism can perform parallel computing during the training phase, this feature improves training efficiency to some extent. However, during the execution of reasoning tasks, the limitations of self attention mechanisms begin to become apparent. This limitation seriously hinders the Transformer model from achieving efficient computation during inference, resulting in relatively long inference time.
By analyzing the data in Table 4, it can be seen that in the specific environment of ARM devices, the inference time of RNN series models has reached an unacceptable level. In contrast, other models were not significantly affected on this device. By delving deeper into the reasons, we found that the structural characteristics of the RNN model family itself determine that it cannot perform parallel operations. In sharp contrast, the CNN model family and Transformer model family can effectively reduce inference time through parallel operations, thereby exhibiting better performance on ARM devices.
Further observation of the data in Table 2 reveals that our proposed PET model exhibits unique advantages on ARM devices, with inference time not only lower than other Transformer series models, but also lower than the TCN model. This result is of great significance as it fully demonstrates the potential of our designed PET model for application in portable devices. The length of inference time has a direct impact on the practical application effect of the model. A shorter inference time means that the model can output more joint angle information per unit time. This efficient information output capability ensures the continuity and timeliness of hand joint activity information, resulting in smoother and smoother hand joint activity in simulated or practical application scenarios, greatly enhancing user experience and the practical value of the model.
In addition, it is worth mentioning that the external attention mechanism we adopted in the model design has unique computational characteristics. Unlike the computation process in the original attention mechanism, the computational complexity of external attention does not increase exponentially with the increase of input data. This feature enables the calculation time of the model to be controlled within an acceptable range regardless of how the feature dimension of the input surface electromyography signal changes. Moreover, the parallel module we designed is mainly composed of convolution operations, and this parallel module is in parallel execution with attention computation. This design architecture ensures that parallel modules do not have a negative impact on the model’s computation time during operation, further ensuring the model’s advantage in computational efficiency.
Power expenditure advantage of PET
In the comparative analysis of the models, our proposed PET model exhibits unique advantages compared to Transformer, with the smallest model size. This feature endows the PET model with the ability to perform tasks with higher accuracy under limited parameter conditions. The high-precision implementation mechanism lies in the external attention mechanism adopted by the PET model, which can more efficiently extract the most critical and useful parts from the entire dataset. In this way, the PET model can still maintain excellent performance even with parameter simplification, avoiding problems such as overfitting that may occur due to too many parameters, while improving the efficiency of the model in capturing and utilizing core features of the data.
Further observation of the power consumption and inference time related data of the model in Table 5 indicates that although the RNN series models exhibit relatively low power consumption levels, their inference time is relatively long. This phenomenon indicates that when using RNN series models to output a set of joint angles, their overall energy consumption is actually at a relatively high level. From the perspective of energy consumption rate, the RNN series models are much lower than other models. In contrast, although the CNN and Transformer series models have relatively high power consumption, their shorter inference time results in lower energy consumption when completing the same inference task. That is to say, in the same inference task scenario, Transformer and CNN series models have significant advantages in power consumption compared to RNN series models.
Specifically, in the CNN and Transformer series models, our proposed PET model is at the forefront in terms of energy consumption ratio. This advantage is mainly attributed to our careful optimization of the calculation process in the model design process. Specifically, we have eliminated unnecessary computational processes in traditional Transformer models, reducing the waste of computing resources and unnecessary energy consumption. At the same time, we also optimized the slow attention computation process to improve computational efficiency, enabling the model to utilize computing resources more efficiently during operation, thereby effectively reducing energy consumption. This outstanding performance in terms of energy consumption further enhances the advantages of PET models in practical applications, making them more competitive in energy sensitive application scenarios.
Online experiment
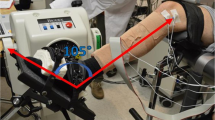
We utilized three electrodes (ELSCH064NM3, 8(\times)8 channels, OT Bioelettronica, Italy) to acquire 192 channels of high-density surface electromyographic (sEMG) signals from forearm muscles, which were connected to a multi-channel amplifier (QUATTROCENTO, OT Bioelettronica, Italy). The sEMG signals were sampled at a rate of 2048 Hz. Post-acquisition, the signals underwent band-pass filtering with cutoff frequencies set between 10 and 500 Hz. Hand joint angle data were recorded using a data glove (5DT Inc., USA), which measures the angles of 14 finger joints at a sampling rate of 16 Hz. Our model was deployed on a Raspberry Pi 4B; with an inference time of approximately 25 ms and an additional time overhead of around 120 ms for data filtering and RMS calculation, the step size was set to 150 ms. Six actions were selected for the experiments: finger pinching, cylindrical grasping, disc grasping, key holding, pinch-and-grasp, and fisting, each performed for 30 seconds. The joint angle prediction of online experiment is shown in Fig. 3. In the online experiment, the average values of PCC, RMSE, and NRMSE for PET were 0.8605, 0.1016, and 1415, respectively. Meets our expectations in terms of evaluation results and inference speed. In online experiments, fast model inference speed ensures real-time motion control, enabling the output of joint angle signals at a higher frequency to prevent the loss of motion details and facilitating more accurate tracking of rapid transient movements. When sEMG signals are disturbed, high-frequency updates allow for quick correction of prediction results, thereby enhancing the system’s robustness to a certain extent.
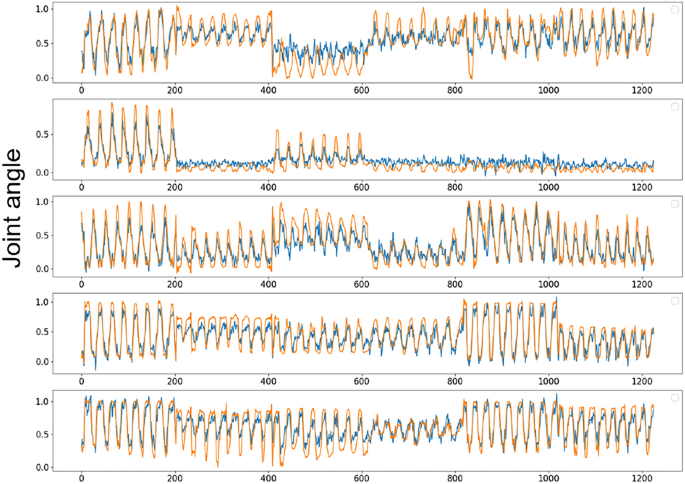
A Parallel and Efficient Transformer for online experiments is proposed. The red curve represents the actual joint angle, and the blue curve represents the estimated result. We selected five joints that have a significant impact on hand function for display, and the fitting of other joint angles is similar.
Discussions
Our research can achieve real-time and accurate motion estimation, which can be applied to rehabilitation assistance, human-computer interaction and other fields. Experiments were conducted using TCN, LSTM, GRU, Transformer, BERT and PET. PET has advantages in terms of PCC, RMSE, NRMSE, AME, training time and inference time. It is also proved that models with small parameters can also perform well in continuous motion estimation of hand joint angles based on surface electromyography signals. In addition, although our research has achieved certain results, it is undeniable that there are still some limitations. In the current study, the PET we proposed showed significant advantages of high precision and high speed in the application scenarios for individual subjects. However, there are also some problems behind this advantage. Specifically, it is precisely because the original intention of PET is to adapt to the specific patterns of individual subjects that its number of parameters is relatively small. Such a parameter scale exposes obvious deficiencies in cross-subject application scenarios. When facing different subjects, due to complex factors such as physiological differences and diverse behavioral patterns between individuals, the PET model is difficult to effectively process and adapt to these differentiated information, resulting in its unsatisfactory performance in cross-subject application scenarios. In addition, we are also concerned that non-ideal factors such as electrode displacement, limb position changes, and muscle fatigue30,31,32 will also affect the performance of actual applications. To address these problems, we plan to use transfer learning and combine physiological feature modeling to improve the PET model.
Conclusions
In this paper, we propose efficient parallel structure-based models that provide both high accuracy and high efficiency to estimate finger joint angles from sEMG signals. We change the Transformer structure to parallel based on the Transformer and apply external attention to continuous motion estimation in sEMG to extract the most discriminative features of the whole dataset. The proposed model is compared with the CNN family and the Transformer family of models. The extensive experimental results demonstrate PET significantly outperforms the contemporary models in all aspects of accuracy, end-to-end latency and power expenditure.
Data availability
The datasets used during the current study are available from the corresponding author on reasonable request.
References
Bi, L. et al. A review on EMG-based motor intention prediction of continuous human upper limb motion for human-robot collaboration. Biomedical Signal Processing and Control 51, 113–127 (2019).
Article
Google Scholar
Borbély, B. J. & Szolgay, P. Real-time inverse kinematics for the upper limb: a model-based algorithm using segment orientations. Biomedical engineering online 16, 1–29 (2017).
Article
Google Scholar
Crouch, D. L. & Huang, H. Lumped-parameter electromyogram-driven musculoskeletal hand model: A potential platform for real-time prosthesis control. Journal of biomechanics 49(16), 3901–3907 (2016).
Article
PubMed
Google Scholar
Mobarak, R. et al. A Minimal and Multi-Source Recording Setup for Ankle Joint Kinematics Estimation During Walking Using Only Proximal Information From Lower Limb. IEEE Trans. Neural Syst. Rehabil. Eng. 32, 812–821 (2024).
Article
PubMed
Google Scholar
R. Mobarak et al., “Neuromechanical-Driven Ankle Angular Position Control During Gait Using Minimal Setup and LSTM Model,” in 2024 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Eindhoven, Netherlands: IEEE, June (2024) pp. 1–6.
Atzori, M., Cognolato, M. & Müller, H. Deep learning with convolutional neural networks applied to electromyography data: A resource for the classification of movements for prosthetic hands. Frontiers in neurorobotics 10, 9 (2016).
Article
PubMed
PubMed Central
Google Scholar
Côté-Allard, U. et al. Deep learning for electromyographic hand gesture signal classification using transfer learning. IEEE transactions on neural systems and rehabilitation engineering 27(4), 760–771 (2019).
Article
PubMed
Google Scholar
Zanghieri, M. et al. Robust real-time embedded EMG recognition framework using temporal convolutional networks on a multicore IoT processor. IEEE transactions on biomedical circuits and systems 14(2), 244–256 (2019).
Article
PubMed
Google Scholar
Zanghieri, M., Benatti, S., Conti, F., Burrello, A., & Benini, L. ‘Temporal variability analysis in sEMG hand grasp recognition using temporal convolutional networks’, in 2020 2nd IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), IEEE, 2020, pp. 228–232.
Wu, L., Zhang, X., Wang, K., Chen, X. & Chen, X. Improved high-density myoelectric pattern recognition control against electrode shift using data augmentation and dilated convolutional neural network. IEEE Transactions on Neural Systems and Rehabilitation Engineering 28(12), 2637–2646 (2020).
Article
PubMed
Google Scholar
Xiong, D., Zhang, D., Zhao, X., Chu, Y. & Zhao, Y. Learning Non-Euclidean Representations With SPD Manifold for Myoelectric Pattern Recognition. IEEE Trans. Neural Syst. Rehabil. Eng. 30, 1514–1524 (2022).
Article
PubMed
Google Scholar
Tay, Y., Dehghani, M., Bahri, D. & Metzler, D. Efficient transformers: A survey. ACM Computing Surveys 55(6), 1–28 (2022).
Article
Google Scholar
Josephs, D., Drake, C., Heroy, A. & Santerre, J. sEMG gesture recognition with a simple model of attention. Machine Learning for Health, PMLR 126–138 (2020).
Lin, C. et al. A BERT based method for continuous estimation of cross-subject hand kinematics from surface electromyographic signals. IEEE Transactions on Neural Systems and Rehabilitation Engineering 31, 87–96 (2022).
Article
Google Scholar
Gulati, A. et al., ‘Conformer: Convolution-augmented transformer for speech recognition’, arXiv preprint arXiv:2005.08100, (2020).
Atzori, M. et al. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Scientific data 1(1), 1–13 (2014).
Article
Google Scholar
Rahimian, E., Zabihi, S., Asif, A., Farina, D., Atashzar, SF., & Mohammadi, A. ‘Temgnet: Deep transformer-based decoding of upperlimb semg for hand gestures recognition’, arXiv preprint arXiv:2109.12379, (2021).
Quivira, F., Koike-Akino, T., Wang, Y., & Erdogmus, D. ‘Translating sEMG signals to continuous hand poses using recurrent neural networks’, in 2018 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), IEEE, (2018) 166–169.
Ma, C. et al. A bi-directional LSTM network for estimating continuous upper limb movement from surface electromyography. IEEE Robotics and Automation Letters 6(4), 7217–7224 (2021).
Article
Google Scholar
Wen, L., Xu, J., Li, D., Pei, X. & Wang, J. Continuous estimation of upper limb joint angle from sEMG based on multiple decomposition feature and BiLSTM network. Biomedical Signal Processing and Control 80, 104303 (2023).
Article
Google Scholar
Peng, Y., Tao, H., Li, W., Yuan, H. & Li, T. Dynamic gesture recognition based on feature fusion network and variant ConvLSTM. IET Image Processing 14(11), 2480–2486 (2020).
Article
Google Scholar
Rahimian, E., Zabihi, S., Atashzar, SF., Asif, A., & Mohammadi, A. ‘Xceptiontime: independent time-window xceptiontime architecture for hand gesture classification’, in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, (2020) 1304–1308.
Guo, M.-H., Liu, Z.-N., Mu, T.-J. & Hu, S.-M. Beyond self-attention: External attention using two linear layers for visual tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence 45(5), 5436–5447 (2022).
ADS
Google Scholar
He, B., Hofmann, T. ‘Simplifying transformer blocks’, arXiv preprint arXiv:2311.01906, (2023).
Ketkar, N., Moolayil, J., Ketkar, N. & Moolayil, J. Introduction to pytorch. Deep learning with python: learn best practices of deep learning models with PyTorch 27–91 (2021).
Krasoulis, A., Kyranou, I., Erden, M. S., Nazarpour, K. & Vijayakumar, S. Improved prosthetic hand control with concurrent use of myoelectric and inertial measurements. Journal of neuroengineering and rehabilitation 14, 1–14 (2017).
Article
Google Scholar
Hu, X., Song, A., Wang, J., Zeng, H. & Wei, W. Finger movement recognition via high-density electromyography of intrinsic and extrinsic hand muscles. Scientific Data 9(1), 373 (2022).
Article
PubMed
PubMed Central
Google Scholar
Matran-Fernandez, A., Rodríguez Martínez, I. J., Poli, R., Cipriani, C. & Citi, L. SEEDS, simultaneous recordings of high-density EMG and finger joint angles during multiple hand movements. Scientific data 6(1), 186 (2019).
Article
PubMed
PubMed Central
Google Scholar
Guo, W. et al. Multi-Attention Feature Fusion Network for Accurate Estimation of Finger Kinematics From Surface Electromyographic Signals. IEEE Trans. Human-Mach. Syst. 53(3), 512–519. https://doi.org/10.1109/THMS.2023.3252817 (2023).
Article
Google Scholar
Xiong, D., Zhang, D., Zhao, X. & Zhao, Y. Deep Learning for EMG-based Human-Machine Interaction: A Review. IEEE/CAA J. Autom. Sinica 8(3), 512–533. https://doi.org/10.1109/jas.2021.1003865 (2021).
Article
Google Scholar
Xiong, D., Zhang, D., Chu, Y., Zhao, Y. & Zhao, X. Intuitive Human-Robot-Environment Interaction with EMG Signals: A Review. IEEE/CAA J. Autom. Sinica 11(5), 1075–1091. https://doi.org/10.1109/jas.2024.124329 (2024).
Article
Google Scholar
Bao, T., Xie, S. Q., Yang, P., Zhou, P. & Zhang, Z. Q. Toward Robust, Adaptiveand Reliable Upper-Limb Motion Estimation Using Machine Learning and Deep Learning–A Survey in Myoelectric Control. IEEE J. Biomed. Health Inform. 26(8), 3822–3835. https://doi.org/10.1109/jbhi.2022.3159792 (2022).
Article
PubMed
Google Scholar
Download references
Funding
This work was supported by the Leading Talent Project of Dalian Maritime University 00253020.
Author information
Authors and Affiliations
Dalian Maritime University, Dalian, 116026, China
Chuang Lin, Xifeng Zhang & Chunxiao Zhao
Search author on:PubMed Google Scholar
Search author on:PubMed Google Scholar
Search author on:PubMed Google Scholar
Contributions
C. L. and X. Z. proposed an experimental approach and designed a research plan. C. Z. denoises and processes data, and extracts features from the data. X. Z. and C. Z. transformed their ideas into practical deep learning models and trained and adjusted the parameters of the models. C. L. and X. Z. analyzed the experimental results and created charts based on them. C. L. provides guidance on the writing approach of the article and checks the rigor of its expression. The three authors worked closely together, each showcasing their own strengths, and all authors reviewed the manuscript.
Corresponding author
Correspondence to
Chuang Lin.
Ethics declarations
Ethics approval and consent to participate
The datasets we used in the experiment are all open-source. Each dataset obtained the consent of the subjects before collection began, and all four datasets were approved by the ethics committee. Ninapro DB2 has been approved by the Ethics Commission of the Canton Valais (Switzerland), https://ninapro.hevs.ch/instructions/DB2.html. Ninapro DB7 has been approved by the local Ethics Committees of the School of Informatics, University of Edinburgh and School of Electrical and Electronic Engineering, Newcastle University, https://ninapro.hevs.ch/instructions/DB7.html. FMHD has been approved by the Ethics Committee of Jiangsu Province Hospital (2020-SR-362), https://doi.org/10.6084/m9.figshare.c.5670433.v1. SEEDS has been approved by the Ethics Committee of the University of Essex (United Kingdom) in October 2016, https://doi.org/10.17605/OSF.IO/WA3QK(2018).
Consent for publication
Written informed consent was obtained from the participants for the publication of this report and any accompanying images.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
Reprints and permissions
About this article
Cite this article
Lin, C., Zhang, X. & Zhao, C. A parallel and efficient transformer deep learning network for continuous estimation of hand kinematics from electromyographic signals.
Sci Rep 15, 36150 (2025). https://doi.org/10.1038/s41598-025-16268-y
Download citation
Received: 30 April 2025
Accepted: 13 August 2025
Published: 16 October 2025
Version of record: 16 October 2025
DOI: https://doi.org/10.1038/s41598-025-16268-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
Keywords
— Nature
相關文章