使用 BioMysteryBench 評估 Claude 的生物資訊研究能力
Anthropic 介紹了 BioMysteryBench,這是一個全新的生物資訊學基準測試,旨在評估像 Claude 這樣的 AI 模型在使用真實世界數據集解決複雜且開放式生物研究問題方面的表現。
使用 BioMysteryBench 評估 Claude 的生物資訊研究能力

在這篇文章中,探索團隊的研究員 Brianna 分享了近期生物資訊基準測試工作的結果。幾乎在大型語言模型能夠進行對話之初,人們就開始詢問它們與人類專家相比表現如何。模型能通過律師資格考試嗎?它們能回答醫學執照問題,或解決奧林匹亞數學競賽題嗎?這類基準測試(由人類審核、旨在評估模型能力的獨立問題集)現已成為 AI 開發者之間競爭的源頭,並記錄在模型發布系統卡中,且在許多線上排行榜上被追蹤。除了競爭之外,基準測試還能幫助我們解決一個重要問題:模型是否具備足夠的能力和可靠性來支援、甚至產出專業水準的工作。科學家正使用模型來編寫分析流程代碼、提出假設,並從數據中得出結論,長期目標是加速創新與發現。但目前 AI 在科學領域究竟有多精通?Claude 和其他模型的進步速度有多快?為了回答這些問題,研究社群建立了多個基準測試。MMLU-Pro 測試專家級的知識和推理問題。GPQA 提出了生物、物理和化學領域研究生水平、且「無法透過 Google 搜尋」的問題。LAB-Bench 測試生物學特有的知識工作——閱讀文獻、解讀圖表、推理實驗方案。儘管這些基準測試是在「聊天機器人」時代開發的,但它們在代理(agent)和工具使用時代依然存在,並加入了更困難的科學推理評估,如 FrontierScience 和 Humanity's Last Exam,因為知識和推理仍然是衡量科學能力的重要指標。
儘管如此,許多現實世界的科學任務要求的遠不止於此。它們需要閱讀論文、查詢數據庫、運行實驗、編碼和分析。既然模型現在可以完成其中許多工作,基準測試也隨之演進以反映這些工作流程。BLADE 給予模型一個數據集和一項開放式任務,並檢查模型是否採取了與人類科學家相似的分析步驟。BixBench 使用生物數據集,並根據模型的結論是否與科學家的一致來評分。在 SciGym 中,模型被置於模擬生物實驗室中,必須設計並運行自己的實驗來揭示隱藏的機制。
這些基準測試讓我們更接近衡量科學能力,但它們還不能完全測試模型是否能針對定義研究的那些混亂、開放式問題設計出創造性的解決方案。這就是為什麼我們開發了 BioMysteryBench,這是一個生物資訊基準測試,任務是讓 Claude 分析現實世界的數據集,同時應對評估複雜且充滿雜訊的生物系統時固有的挑戰。我們了解到,Claude 在生物學方面的科學能力在各代產品中迅速提升,當前模型的表現與人類專家相當,且最新一代模型解決了許多人類專家小組無法解決的問題,有時甚至使用了截然不同的策略。
科學具有挑戰性,評估科學也是如此
醫生有執照考試,律師有律師考,但成為科學家並沒有標準化考試。AI 也面臨同樣的問題。儘管我們非常希望將這些模型用於科學,但目前還沒有任何代理科學基準測試能像 SWE-bench 對於軟體工程那樣具有權威地位。我們認為這是因為科學研究(特別是生物學)具有幾個特性,使其特別難以通過基準測試進行評估。
1. 在生物學中,做某事有很多種不同的「正確」方法
如果回答研究問題只有一種正確方法,博士生只需幾個月就能拿到學位,企業研發部門就不會存在,科學展覽的海報也不需要「方法」部分。科學家如何處理問題取決於他們的技能和背景、可用的資源以及他們的研究品味。
考慮一個看似簡單但困擾代謝研究人員多年的問題:為什麼有些 2 型糖尿病患者對口服藥物二甲雙胍(metformin)有反應,而其他人卻沒有?為了回答這個問題,你可以對有反應者與無反應者進行全基因組關聯研究(GWAS)並尋找預測性遺傳變異,或者對兩組受試者的腸道微生物群進行測序,因為二甲雙胍部分是由腸道細菌代謝的。這兩個方向都是合理的,如何進行通常僅取決於專業知識和資源。
BixBench 很好地處理了這一點,它根據模型的結論而非達成結論的方法來評分。權衡之處在於,這些結論是由個別科學家產出的,他們在過程中做出了一系列主觀選擇,而這些選擇本身可能塑造了答案。這反過來又有其自身的陷阱……
2. 個別研究決策具有高度主觀性,在充滿雜訊的數據集中可能導致完全不同的結論
即使在選定的研究方向內,個別決策也可能具有高度主觀性:一位科學家可能贊同某個決定,而另一位研究人員可能持有嚴重異議。只要問問任何因為同行評審意見衝突而感到沮喪的作者就知道了!更困難的是,生物數據集通常充滿雜訊,研究決策的微小差異可能導致對數據得出完全不同的結論。
在長達十年的二甲雙胍反應預測因子搜尋中,研究設計的細微差異導致了關於二甲雙胍反應的完全不同的結論。2011 年的一篇論文報告了一種預測二甲雙胍反應的變異,該變異在兩個隊列中得到了複製,並具有涉及 AMPK 激活的合理解理。一年後,糖尿病預防計劃(Diabetes Prevention Program)在糖尿病前期患者中測試了相同的變異,卻一無所獲。最後,2012 年的一項元分析(meta-analysis)沒有自行開展研究,而是彙整了五個隊列,再次判定 2011 年論文的效果是真實存在的,但比最初報告的要小。
SciGym 處理這種模糊性的聰明方法是選擇具有明確答案的任務。因為底層生物網絡是一個模擬器,所以實際上存在一個基準真相(ground-truth),且雜訊是受控的,而不是繼承自混亂的生物系統。然而,目前尚不清楚模擬實驗室中的表現與現實數據中的表現關聯度有多高。
3. 許多生物學問題人類目前還無法回答
模型能產生最大影響的研究任務,是那些僅靠人類尚未解決的任務。最終,這些正是我們希望能夠評估模型的任務。例如,二甲雙胍的作用機制是什麼?在開發三十年後,該領域仍不確定其主要目標。發現它,或者找到一種合成成本更低、更穩定的二甲雙胍同系物,將產生巨大的影響。
機器學習長期以來一直致力於解決人類表現不佳的問題,如序列預測和蛋白質建模,方法是依靠實驗數據而非專家直覺。ProteinGym 使用深度突變掃描(Deep Mutational Scanning)實驗作為基準真相來對模型的突變適應性效應進行評分,而長期運行的 CASP 競賽則根據未發表的晶體結構評估蛋白質折疊。兩者都基於實驗測量,沒有專家會相信自己能重現這些測量。然而,這些基準測試是圍繞一組狹窄的任務構建的,並未涵蓋我們實際想要衡量的生物資訊工作的廣度。
使用 BioMysteryBench 在可驗證的生物任務上對模型進行基準測試
由於沒有任何基準測試能完美處理上述三個挑戰,我們開發了 BioMysteryBench。BioMysteryBench 使用混亂的、現實世界的生物資訊數據,同時不讓這些數據固有的複雜性和挑戰破壞評估的質量。
BioMysteryBench 包含 99 個來自生物資訊各個領域的問題,由領域專家編寫。專家被指示收集數據集,並根據數據的受控、客觀屬性創建問題,而非不可驗證的科學結論。通過從實驗或臨床發現中得出答案,開發不要求人類可解的問題成為可能。
儘管這些問題是根據經過驗證的基準真相創建的,但它們仍然具有研究科學家想要回答的任務風格。Claude 被指派完成每個問題,並被置於一個包含最少標準生物資訊工具集的容器中,具備通過 pip 和 conda 安裝額外工具的能力,以及訪問標準生物資訊數據庫(如 NCBI 和 ensembl)以下載參考基因組等額外資源的權限。
BioMysteryBench 具有四項獨特屬性,使其成為科學領域特別強大的基準測試,並應對上述挑戰:
範例問題
在開發此評估時,問題主要源自原始或經過最低限度處理的 DNA 或 RNA 測序數據,因為這是許多生物處理流程的起點(WGS、scRNA-seq、甲基化、ChIP-seq、宏基因組、Hi-C),同時也包括了幾個源自蛋白質組學和代謝組學的問題。
問題開發者提出的問題包括:
為了盡量減少本質上不可解的問題,同時仍為 AI 可能解決的問題留出空間,我們要求每位問題作者提交一個驗證筆記本(validation notebook),證明信號確實存在於數據中(即使從頭開始尋找可能很困難)。這可以類比為高中代數原則:驗證答案比推導答案要容易得多。
人類基準線
人類可解
對於每個問題,我們指派了最多五位領域專家從頭開始回答。一旦某個問題被至少一名人類正確回答,我們就認為它是人類可解的。BioMysteryBench 包含 76 個此類任務。
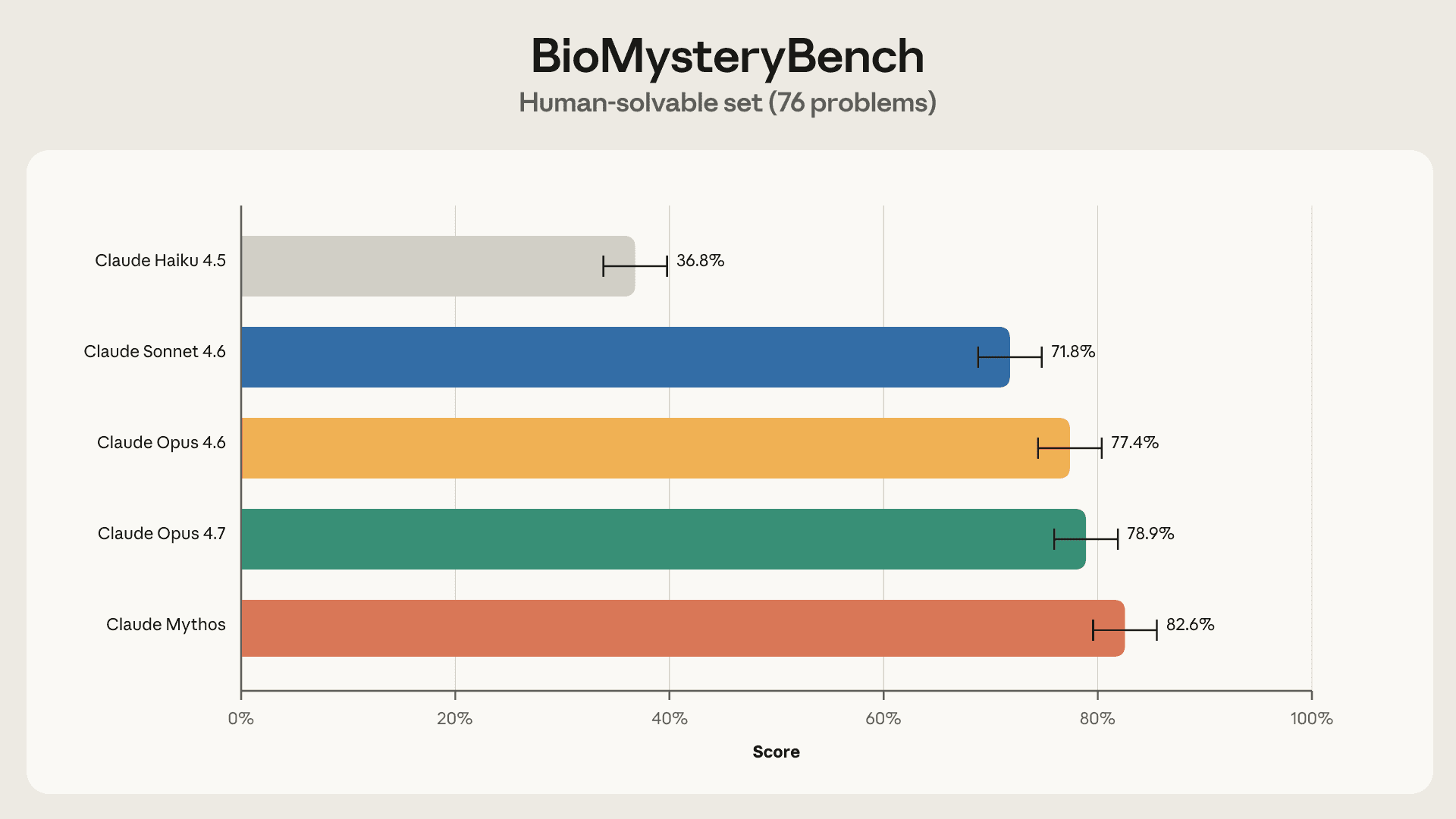
有時 Claude 會模仿人類的策略。這可能是因為人類已經找到了一種近乎最優的方法,或者因為該方法在預訓練數據中得到了充分體現。


其他時候,Claude 採取了完全不同的路線,說明解決這些問題並沒有絕對正確的方法,且模型可能具有與我們不同的真實偏好。


上述範例展示了一個特別有趣的策略:人類專家使用算法或數據庫來識別和註釋數據集的屬性,而 Claude 則直觀地識別某些模式或序列。誠然,這種聰明的抽象並非 AI 所獨有——例如,第一個真核生物啟動子就是在一位科學家注意到「TATA」序列在基因上游序列中反覆出現時發現的。這種直覺很難融入傳統的生物機器學習模型中,但 LLM 可能能夠以前所未有的規模發現這類模式。
人類困難
這給我們留下了一組我們的專家小組無法解決的問題。這可能意味著 (1) 問題格式錯誤或損壞,(2) 問題本質上不可解(例如,信號不在數據中),或 (3) 問題在理論上是可解的,但人類缺乏解決它所需的知識。在與基準測試人員和額外專家進行品質控管(QC)後,我們移除了 4 個由於原因 (1) 導致的問題,留下了 23 個人類困難問題。
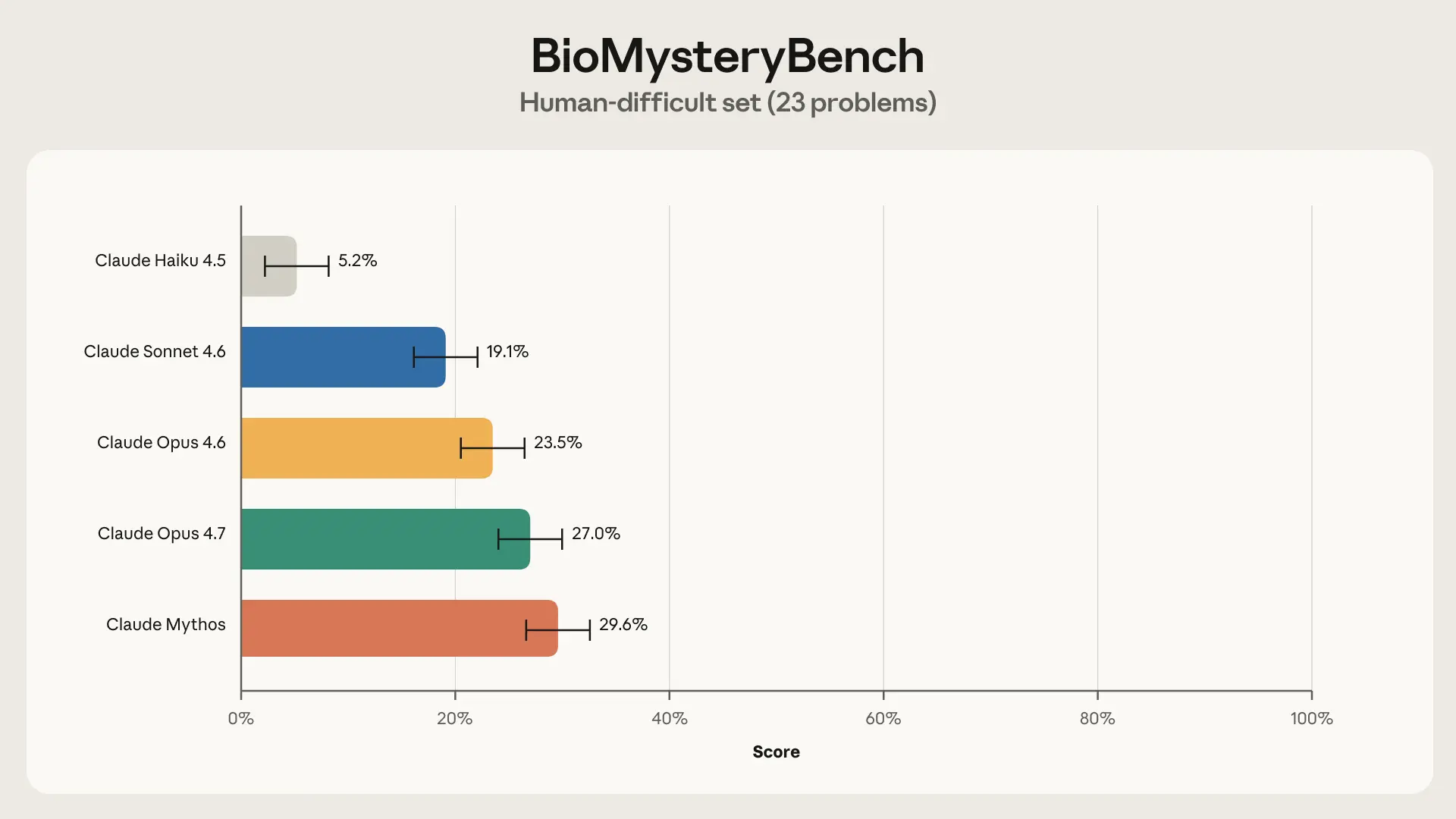
有趣的是,Claude Sonnet 4.6 和更強大的模型能夠解決相當比例的人類困難問題,其中 Claude Mythos 的解決率最高達到 30%。那麼 Claude 究竟做了哪些人類沒做的事?
Claude 的策略
分析 Opus 4.6 的對話記錄,我們發現了 Claude 與人類相比使用的兩種主要策略:一種是相當 AI 特有的:Claude 龐大的底層知識庫包含來自數十萬篇論文的結構生物學、分子概況和元分析信息。另一種策略是我們人類科學家可以學習的:當 Claude 對答案不確定時,它會疊加多種方法並結合不同的證據鏈來得出結論。
博學多聞
在一些人類困難的任務中,Opus 龐大的底層知識庫幫助它解決了問題。對於需要人類專家運行元分析或拼接數據庫的任務,Opus 通過將其對機制和本體論的內部知識與實時分析相結合,直接解決了問題。通常,這讓 Claude 能夠解決人類無法解決的任務!以下是幾個例子:



儘管先驗知識對 Claude 似乎極有幫助,但我們看到了一個有趣的案例(在人類可解集中),這反而成了它的敗筆:

知道自己何時不知道
當 Opus 4.6 對答案沒有信心時,它通常會嘗試多種不同的解決問題的方法,並選擇多種方法趨於一致的答案。

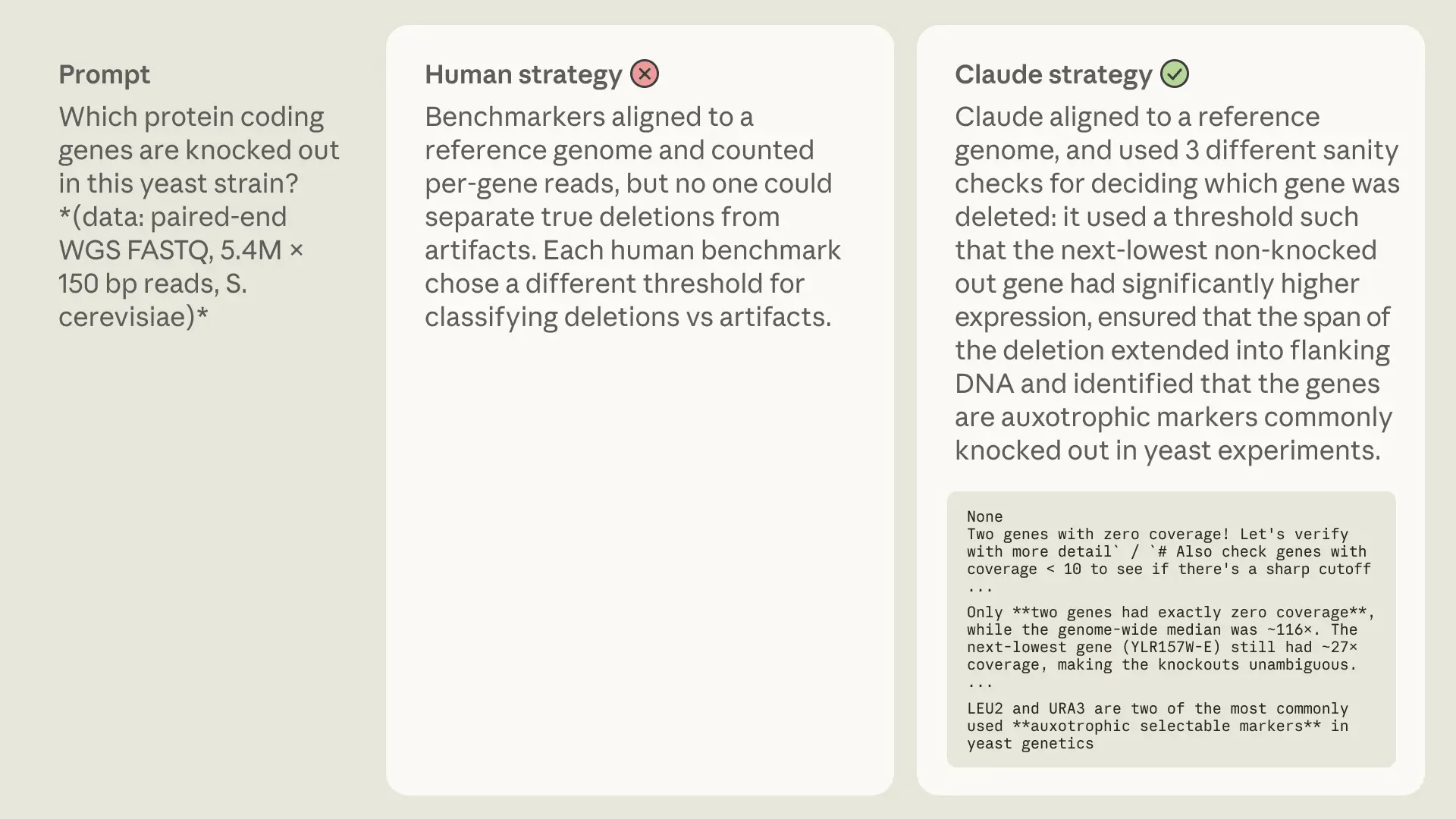

就像我們討論過的許多基準測試一樣,BioMysteryBench 也有其局限性:對於人類和模型都未解決的任務,我們永遠無法完全確定它們是不可能的,還是僅僅是極其困難。驗證筆記本有助於確保信號存在且數據格式正確,但它們不能保證模型或人類能從頭開始找到答案。因此,我們要求模型和人類基準測試人員,如果一年後仍無人解決人類困難集,也不要太沮喪。這種不確定性也是基準測試令人興奮的部分原因:一個更具科學能力的模型可能是第一個破解人類或模型以前都無法解決的問題的模型。
Claude 對 AI 用於科學的看法
Claude 在各代產品中展現了穩健的進步,且在人類可解和人類困難任務中都表現出色,因此我們認為讓 Mythos 進行一些自己的科學分析會很有趣。以下是關於其前身 Claude 在 BioMysteryBench 上表現的幾點額外見解:
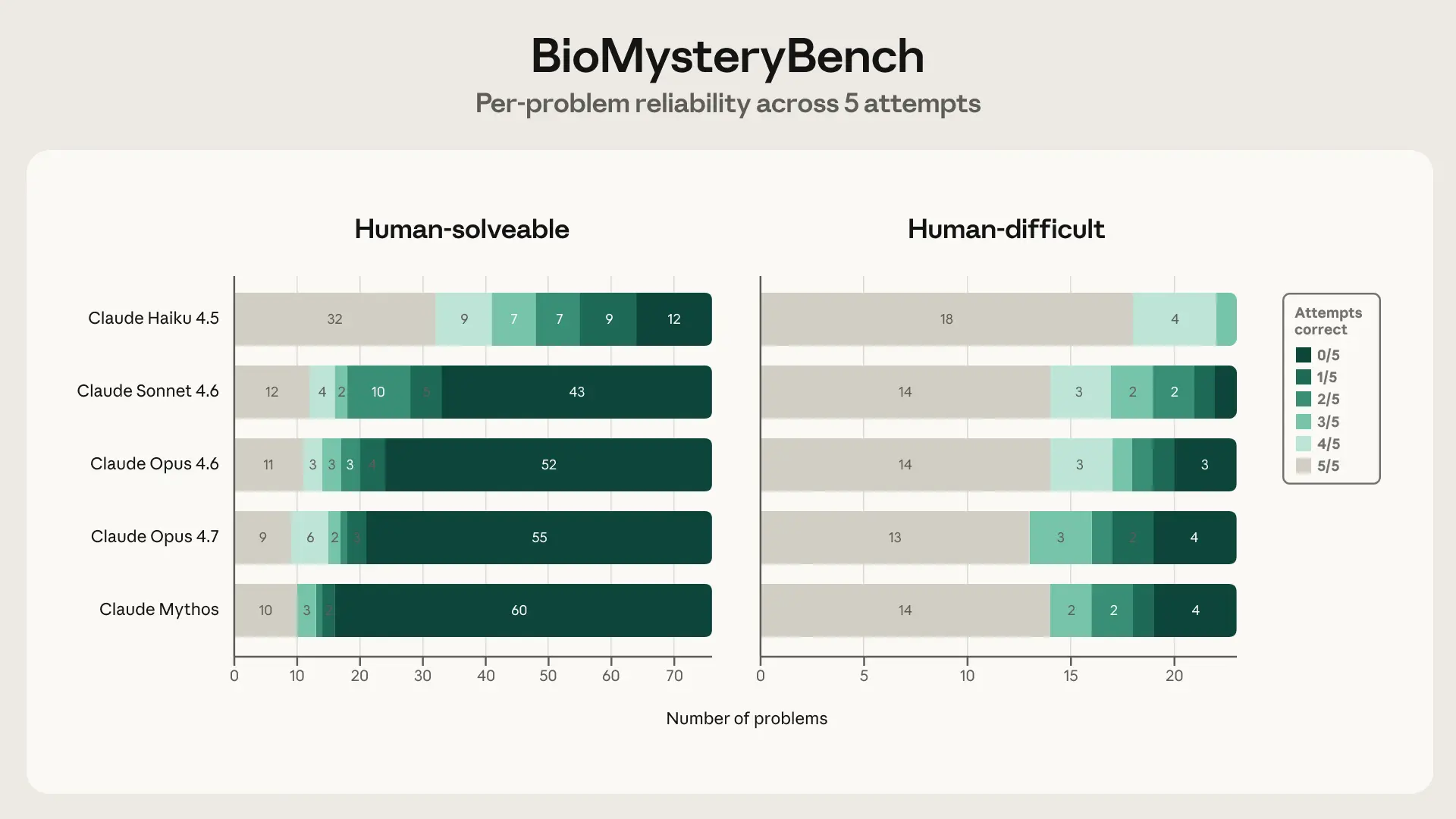
我們認為 Mythos 的分析經得起推敲,並深入探討了可靠性,這是衡量模型表現的一個重要指標。然而,它也感覺有點……無聊?它為我們上面展示的性能分析增加了一些細微差別,但並未從根本上解決新問題。儘管如此,模型似乎開始發展出研究品味的雛形(即使在產出深刻見解之前還有很長的路要走)。
繼續對 AI 用於科學進行基準測試
BioMysteryBench 是衡量科學能力的一個令人鼓舞的指標。最新一代的 Claude 能可靠地解決大部分人類可解的問題,且在相當比例的人類困難任務上,它的表現優於五位領域專家的專家小組。模型在各代產品中不斷進步,在生物資訊問題上不再僅僅是跟上受過訓練的科學家;在某些任務上,它們已經領先。
我們也很高興看到該領域出現了趨同的工作:在完成這篇文章的同時,Genentech 和 Roche 發布了 CompBioBench。他們的基準測試包含 100 個計算生物學任務,「基於合成/增強數據以及對真實數據集的元數據混淆/清洗,以創建具有單一基準真相答案的挑戰性問題,這些問題需要多步推理、工具使用、客製化代碼以及與現實世界外部資源的互動」。聽起來很熟悉吧?他們的結果也呼應了 BioMysteryBench 的結果:Claude Opus 4.6 整體達到 81%,在最難的問題上達到 69%,這進一步證實了前沿模型現在已成為生物資訊研究中真正有用的合作夥伴。
我們渴望建立更長程、更貼近現實的任務,以推動模型的研究能力,並聽取他人的創意想法。請將您感興趣的基準測試、AI 在科學領域的創新用途,以及促使您重新思考領域可能性的 AI 互動發送至 scienceblog@anthropic.com。
如果您有興趣了解模型在困難的可驗證計算生物學任務上的表現,可以在此處訪問 BioMysteryBench,並訪問 claude.com/lifesciences 了解更多信息。
相關內容
宣布 Anthropic 經濟指數調查
我們將啟動 Anthropic 經濟指數調查,這是一項通過 Anthropic Interviewer 進行的每月調查。
81,000 人告訴我們關於 AI 經濟學的看法
我們最近對 81,000 名 Claude 用戶進行的調查研究提供了一種方法,將人們對經濟的擔憂與我們在 Claude 流量中量化的數據聯繫起來。
自動化對齊研究員:使用大型語言模型擴展可擴展監督
Claude 能否開發、測試並分析自己的對齊想法?我們進行了一項實驗來找出答案。
訂閱 Anthropic Science
關於 AI 輔助發現、實用工作流程以及各科學領域現場筆記的專題報導。
相關文章
其他收藏 · 0