Claude Token 計數器現已支援模型比較功能
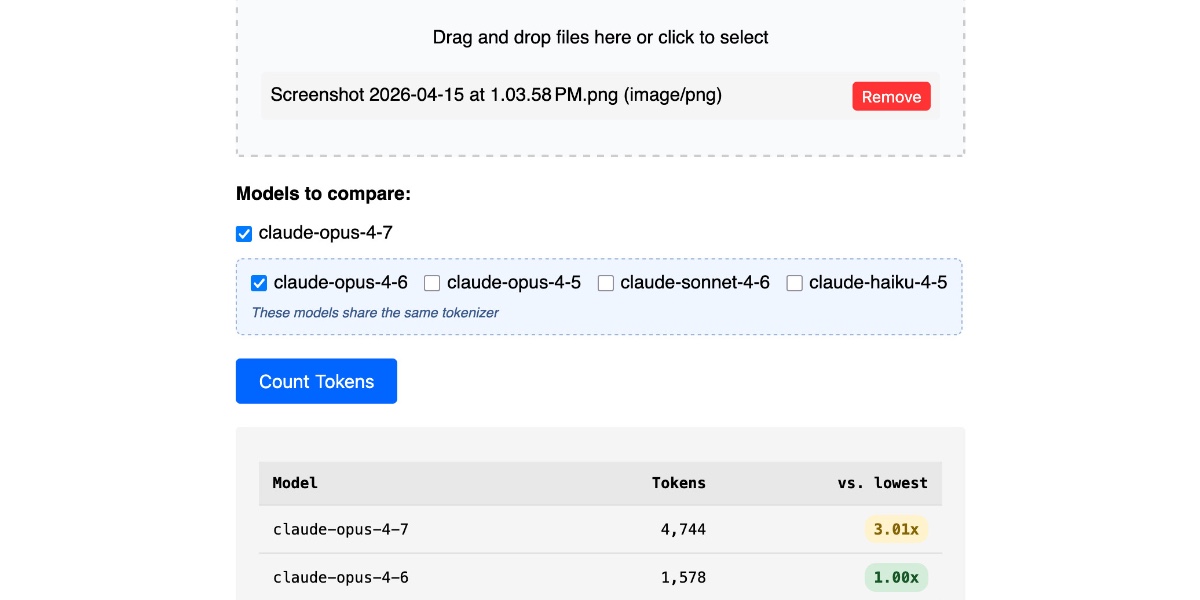
我升級了我的 Claude Token 計數器工具,增加了針對不同模型運行相同計數以進行比較的功能。我發現 Claude Opus 4.7 是第一個更改分詞器的模型,這導致相同輸入的 Token 數量增加了約 1.0 到 1.35 倍,進而使實際使用成本上升。
背景
知名科技部落客 Simon Willison 近期更新了他的 Claude Token 計數工具,新增了不同模型間的 Token 消耗對比功能。這次更新的核心發現在於 Anthropic 最新推出的 Claude Opus 4.7 模型更換了 Tokenizer(分詞器),導致在處理相同內容時,Opus 4.7 所產生的 Token 數量顯著高於舊版 Opus 4.6,這直接影響了使用者的 API 成本支出。
社群觀點
針對 Opus 4.7 導致的 Token 膨脹現象,Hacker News 社群展開了多層次的討論。首先是關於成本的直接衝擊,由於 Anthropic 維持了與前代相同的每百萬 Token 單價,但分詞後的數量卻增加了約 40% 甚至更多,部分使用者認為這無異於變相漲價。特別是在處理高解析度圖像時,Opus 4.7 支援更高像素的特性導致 Token 消耗量激增至三倍以上。對此,有開發者建議在將圖片上傳至 API 之前應先進行手動降採樣,以避免不必要的成本負擔,因為小尺寸圖片在不同版本間的 Token 消耗差異其實並不明顯。
在技術原理的探討上,社群對於 Anthropic 為何更換分詞器有著深入的辯論。由於 Anthropic 是目前唯一不公開分詞器原始碼、不提供離線庫的主流廠商,這引發了關於「黑箱作業」的質疑。有觀點認為,這種改變並非單純為了獲利,而是為了提升模型的語義理解能力。傳統的分詞方式往往會因為大小寫或空格的差異,將同一個詞拆解成完全不同的 Token,迫使模型必須透過暴力學習來理解這些 Token 之間的關聯。若新版分詞器能更精準地進行形態學切分,例如將字根與字尾分離,雖然會增加 Token 總數,卻能讓模型更有效地學習語言邏輯,甚至可能因為回答更精準、減少重複提問次數,而降低整體的開發成本。
然而,並非所有人都認同形態學分詞能帶來實質效益。部分專家引用研究指出,目前尚無強力證據顯示這種分詞方式能顯著提升模型性能,並認為這可能只是另一種「苦澀的教訓」,即過度的人為規則介入往往不如純粹的數據驅動。此外,也有討論提到非英語系語言在分詞上的困境,認為目前的模型在處理具有複雜變格的語言時仍顯得力不從心。對於一般訂閱用戶而言,這種成本結構的變動正促使他們重新評估使用策略,考慮將簡單任務轉向高性能的本地模型,僅將昂貴的 Claude 留給極端複雜的難題。
延伸閱讀
- 3Blue1Brown 關於大型語言模型運作原理的科普影片:探討模型如何處理與學習不同 Token 之間的關聯。
- Arxiv 論文《Is Morphological Tokenization Helpful?》:探討形態學分詞對模型性能影響的研究。
- BPE-Knockout 技術文件:關於位元組對編碼(BPE)在不同語言應用下的實驗觀察。
相關文章
其他收藏 · 0