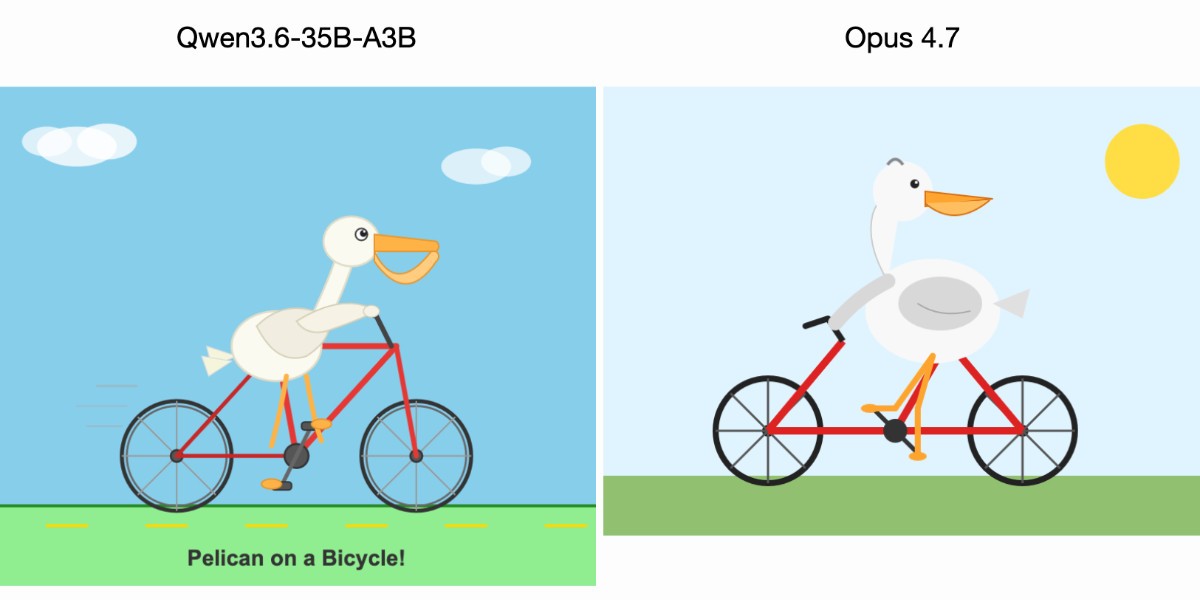
在我筆電上運行的 Qwen3.6-35B-A3B 畫出的鵜鶘比 Claude Opus 4.7 還要好
AI 生成摘要
我利用鵜鶘騎腳踏車的基準測試,比較了阿里巴巴 Qwen3.6 與 Anthropic Claude Opus 4.7 的 SVG 生成能力,發現這款在我筆電上運行的本地模型表現竟然優於最新的商業旗艦模型。
背景
知名科技部落客 Simon Willison 近期發布了一篇關於大型語言模型繪圖能力的測試報告,對比了阿里巴巴新推出的開源模型 Qwen3.6-35B-A3B 與 Anthropic 的頂級商業模型 Claude Opus 4.7。作者長期以「鵜鶘騎腳踏車」作為非正式的基準測試,意外發現能在筆電運行的 Qwen 量化模型,在生成 SVG 向量圖的構圖與細節表現上,竟然優於參數規模大得多的 Opus 4.7。
社群觀點
針對這項有趣的測試結果,Hacker News 的討論呈現出兩極化的反應。部分使用者對於 Qwen 系列模型的進步感到驚艷,認為其在工具調用與代理工作流的處理能力上有顯著提升。有留言指出,在搭載 M5 Max 晶片與充足記憶體的硬體環境下,這類中型規模的模型展現了極高的實用價值,甚至在某些特定任務上能與昂貴的閉源模型一搏。
然而,對於「鵜鶘測試」是否能代表模型真實實力,社群中存在不少質疑。有觀點認為,Qwen 在備用測試「火烈鳥騎單輪車」的表現雖然充滿創意,但在物理邏輯上卻漏洞百出。相較之下,Claude Opus 生成的圖像雖然顯得平淡乏味,卻更符合現實世界的物理結構,例如腳踏板的位置與輪輻的連接方式。這種差異引發了關於模型是否過度擬合特定測試集的討論,有評論者懷疑開發者可能針對知名的非正式測試進行了數據優化,導致模型在特定題目上表現優異,卻缺乏對物理現實的深刻理解。
此外,專業開發者更傾向於從實際編碼能力來評估模型。根據社群提供的數據對比,Qwen 3.6 35B 在解決複雜編程任務的成功率上,僅比前一代版本略有提升,且與同系列的密集模型相比仍有差距。最關鍵的是,在面對頂尖的 Opus 4.7 時,Qwen 在編碼基準測試中的表現依然落後一大截。這說明了儘管開源模型在創意繪圖或特定 SVG 生成上能帶來驚喜,但在處理高難度邏輯與工程問題時,頂級商業模型所擁有的參數優勢與推理深度依然難以被輕易超越。
最後,社群也反思了這類「趣味測試」的侷限性。雖然鵜鶘測試最初是作為一種對抗嚴肅基準測試的幽默回應,但隨著模型能力提升,這種單一場景的測試已逐漸失去鑑別度。討論者建議,若要測試模型在分佈外情境的適應能力,應該混合更多隨機的動物與活動組合,而非固定在特定的題目上,否則測試結果將越來越難以區分模型是具備真正的創造力,還是僅僅是記憶了相關的訓練數據。
延伸閱讀
在討論過程中,有使用者提到了用於在 Mac 硬體上運行本地模型的工具,包括 LM Studio 以及基於 MLX 框架的 oMLX 實作,這些工具能讓開發者更方便地在本地端部署並測試 Qwen 等開源模型。此外,針對模型編碼能力的評估,討論中也引用了 Power Ranking 任務基準,作為衡量模型在實際工程場景下表現的參考指標。
相關文章
其他收藏 · 0
收藏夾