打造千萬節點AI記憶體系:架構、失敗與寶貴經驗
本文深入探討了建構擁有超過千萬節點的大規模AI記憶體系的挑戰與經驗教訓,強調傳統RAG流程和向量資料庫在處理時間性與情境資訊方面的局限性。
![]()
Building a knowledge graph memory system with 10M+ nodes: Architecture, Failures, and Hard-Won Lessons

TL;DR: Building AI memory at 10M nodes taught us hard lessons about query variability, static weights, and latency. Here's what broke and how we're fixing it.
You've built the RAG pipeline. Embeddings are working. Retrieval is fast. Then a user asks: "What did we decide about the API design last month?"
Your system returns nothing or worse, returns the wrong context from a different project.
The problem isn't your vector database. It's that flat embeddings don't understand time, don't track who said what, and can't answer "what changed?"
We learned this the hard way while building CORE a digital brain that remembers like humans do: with context, contradictions, and history.

What We're Building (And Why It's Hard)
At CORE our goal is to build a digital brain that remembers everything a user tells it . Technically it is a memory layer that ingests conversations and documents, extracts facts, and retrieves relevant context when you need it. Simple enough.
But here's what makes memory different from search: facts change over time.
Say you're building an AI assistant and it ingests these two messages, weeks apart:
Now someone asks: "Where did John work in October?"
A vector database returns both documents, they're both semantically relevant to "John" and "work." You get contradictory information with no way to resolve it.
We needed a system that could:
This requires two things vectors can't do: relationships and time.

Why a Knowledge Graph With Reification
Knowledge graphs store facts as triples: (John, works_at, TechCorp). That gives us relationships—we know John is connected to TechCorp via employment.
But standard triples are static. If we later store (John, works_at, StartupX), we've lost history. Did John work at both? Did one replace the other? When?
Reification solves this by making each fact a first-class entity with metadata:
Now we can query: "Where did John work Oct 10th?" → TechCorp. "How do I know?" → Episode #42.
The tradeoff: 3x more nodes, extra query hops. But for memory that evolves over time, it's non-negotiable.

Three Problems That Only Emerged at Scale

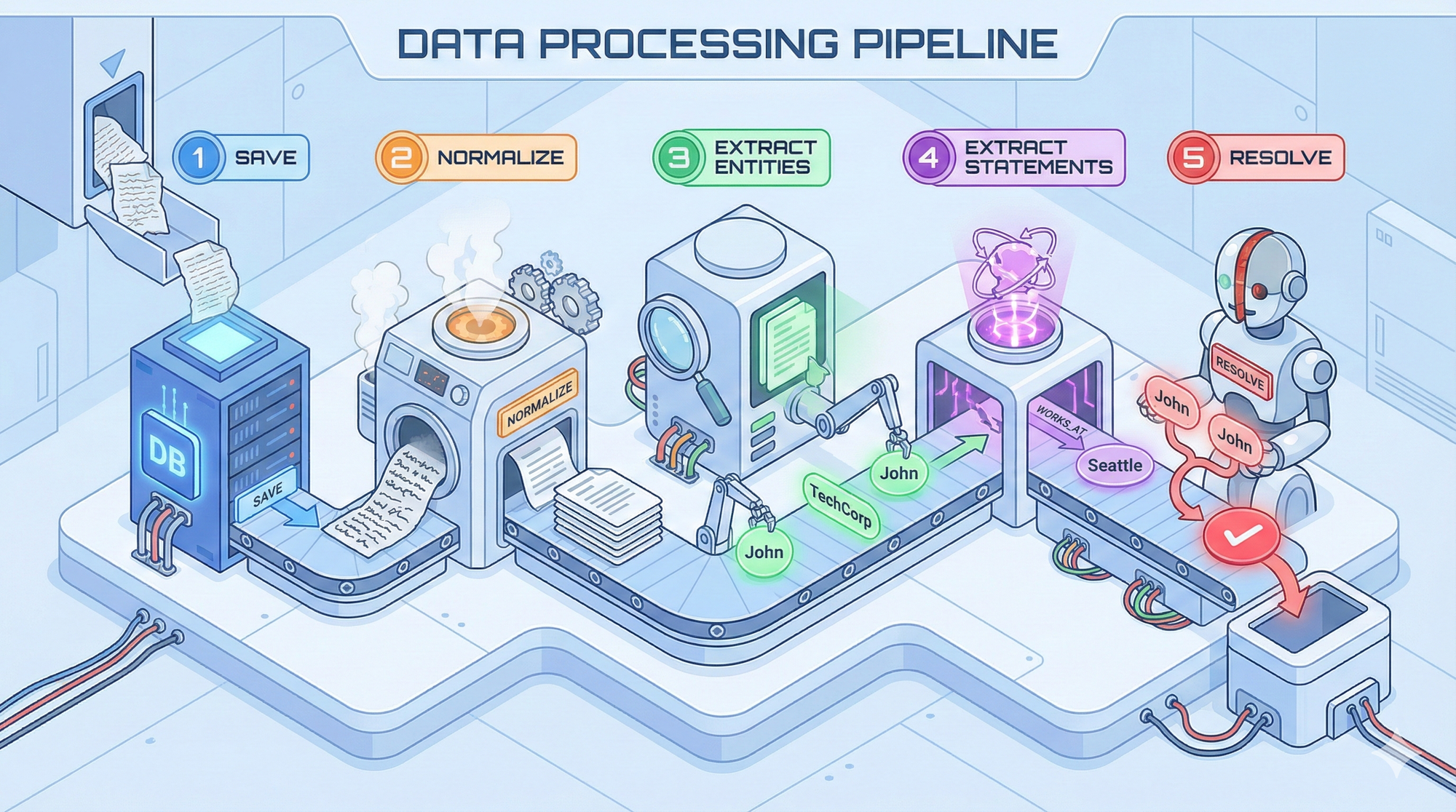
How We Ingest Data
Our pipeline has five stages:
Stage 1: Save First, Process LaterWe save episodes immediately before processing. When ingesting large documents, chunk 2 needs to see what chunk 1 created.
Stage 2: Content NormalizationWe don't ingest raw text—we normalize using session context (last 5 episodes) and semantic context (5 similar episodes + 10 similar facts). The LLM outputs clean, structured content with timestamps.
Stage 3: Entity ExtractionThe LLM extracts entities and generates embeddings in parallel. We use type-free entities, types are hints, not constraints—reducing false categorizations.
Stage 4: Statement ExtractionThe LLM extracts triples: (John, moved_to, Seattle). Each statement becomes a first-class node with temporal metadata and embeddings.
Stage 5: Async Graph ResolutionRuns 30-120 seconds after ingestion. Three deduplication phases:
How We Search
Five methods run in parallel, each covers different failure modes:
BFS Traversal Details:Extract entities from query (unigrams, bigrams, full query), embed each chunk, find matching entities. Then hop-by-hop: find connected statements, filter by relevance, extract next-level entities. Repeat up to 3 hops. Explore with low threshold (0.3), keep high-quality results (0.65).
Result Merging:
Plus bonuses: concentration (more matching facts = higher rank), entity match multiplier (50% boost per match).

Where It All Fell Apart
Problem 1: Query Variability
User asks "Tell me about me." The agent might generate:
Same question, different internal query, different results. You can't guarantee consistent LLM output.

Problem 2: Static Weights
Optimal weights depend on query type:
Query classification requires an extra LLM call. Wrong classification → wrong weights → bad results.
Problem 3: Latency Explosion
At 10M nodes:
Root causes:

The Migration: Separating Vector and Graph
Neo4j is brilliant for graphs. It's terrible for vectors at scale:
New Architecture:
Early Results (dev environment, 100K nodes):
Production target: 1-2 second p95, down from 6-9 seconds.

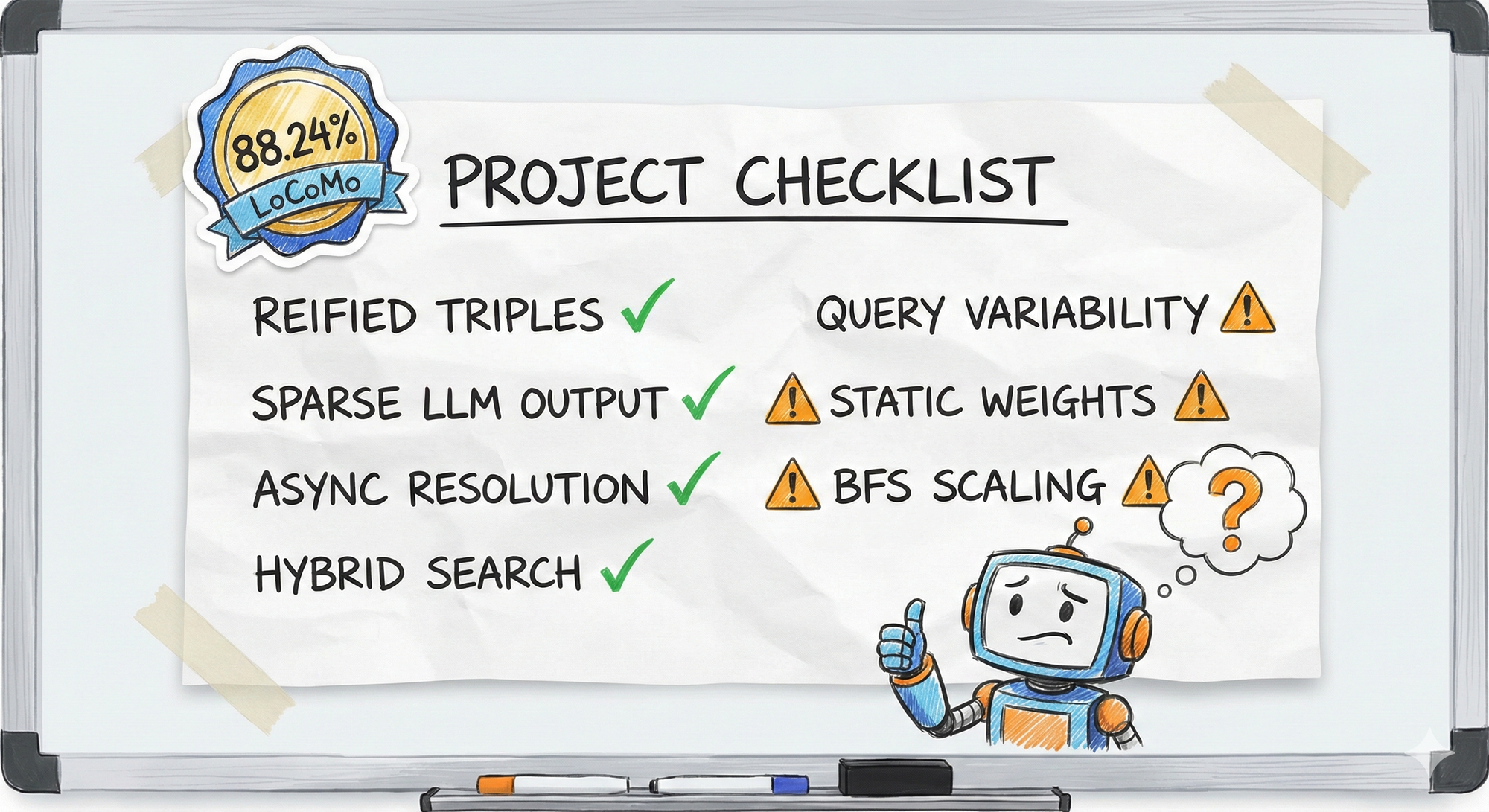
Key Takeaways
What Worked:
What's Still Hard:
Validation: 88.24% accuracy on LoCoMo benchmark (long-context memory retrieval) state of the art for AI memory systems.
The Big Lesson
You can't just throw a vector database at memory. You can't just throw a graph database at it either.
Human-like memory requires temporal intelligence, provenance tracking, and hybrid search, each with its own scaling challenges. The promise is simple: remember everything, deduplicate intelligently, retrieve what's relevant. The reality at scale is subtle problems in every layer.

Get Started
⭐ Star the repo if this was useful, helps us reach more developers.

Read more

How I Automated GitHub Community Management and Saved 10 Hours/Week (Claude + CORE Memory)
Learn how I automated GitHub community management with Claude + CORE Memory. This workflow cut my daily GitHub time from 2 hours to 15 minutes with a 15-minute setup.
TLDR: Managing GitHub issues, PRs, and comments used to eat 1–2 hours every morning. I connected Claude to CORE Memory (persistent

Why AI Forgets Everything You Tell It (And How to Fix It in 2025)
I was 20 minutes into debugging with claude, explained my (architecture, database schema, 3 different approaches) and just when the AI finally understood my problem, the session timed out and it forgot everything
This happens 5-10 times a week to every developer using AI tools, and it's not

We built memory for individuals and achieved SOTA (88.24%) on LoCoMo benchmark
CORE became SOTA on the LoCoMo benchmark with overall 88.24% accuracy.
LoCoMo tests how well AI systems remember and reason across long conversations (300+ turns). Think of it as the SAT for AI memory - it evaluates whether systems can maintain context, resolve contradictions, and surface relevant information as

Why claude.md Fails and How CORE Fixes Memory in Claude Code
The Pain Every Claude Code User Knows
You’re in the middle of a tricky refactor. After 20 minutes of explaining architecture and trade-offs, Claude Code helps you land the perfect solution.
Then the session times out, Claude Code forgets everything and you’re back to square one.
To fix
![]()
Become a pioneer
Welcome to CORE blog!
相關文章