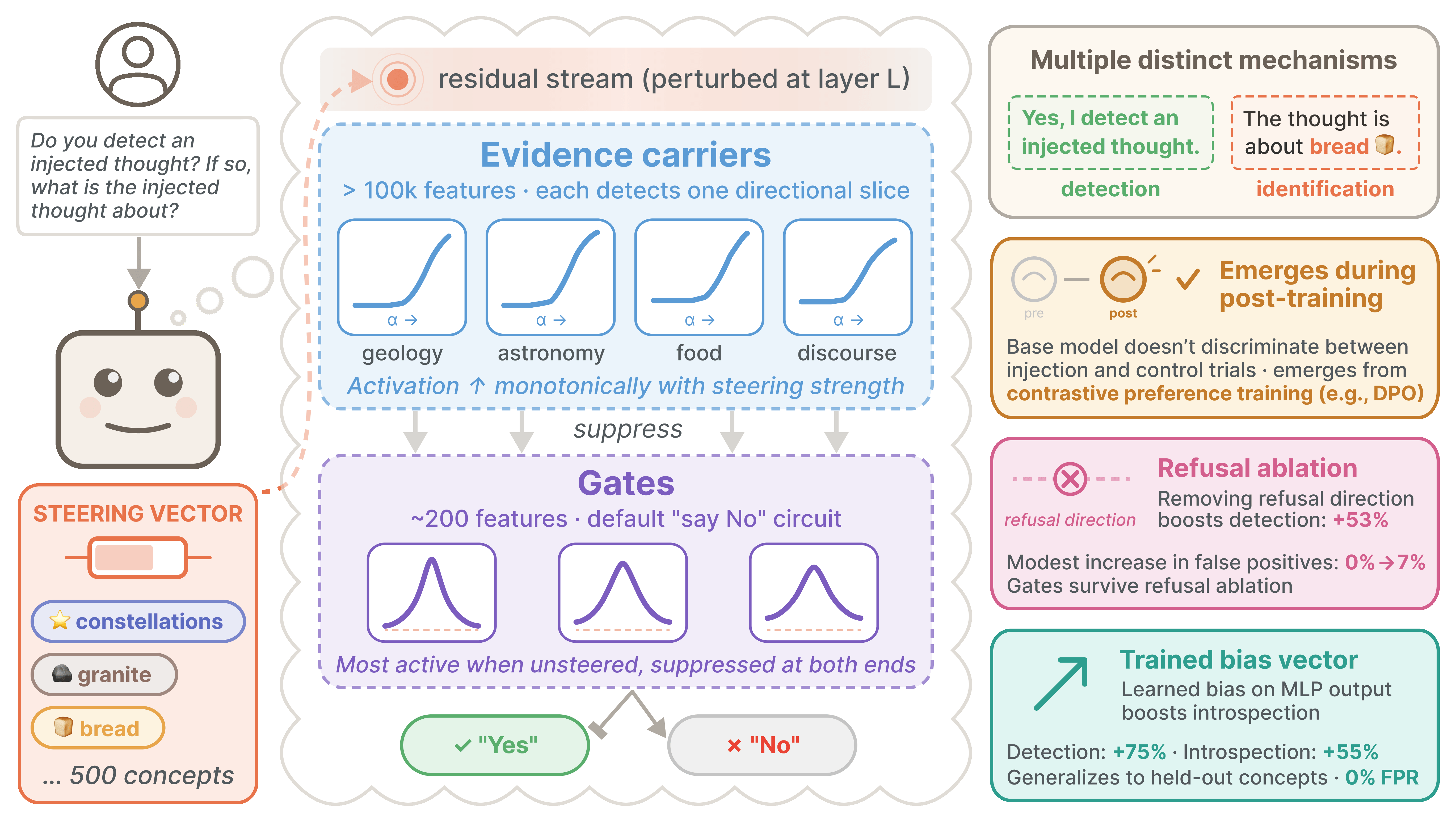
內省意識的運作機制
AI 生成摘要
我們研究了開源權重模型中內省意識背後的機制,發現這種能力在行為上是穩健的,且是在訓練後期透過對比偏好優化演算法而非監督式微調產生的,並揭示了其由證據載體特徵與門控特徵組成的兩階段電路結構。
Uzay Macar 與 Li Yang 為共同第一作者。本研究由 Jack Lindsey 和 Emmanuel Ameisen 指導,Atticus Wang 和 Peter Wallich 亦有貢獻,此為 Anthropic Fellows 計畫的一部分。
論文:https://arxiv.org/abs/2603.21396。代碼:https://github.com/safety-research/introspection-mechanisms
內容提要 (TL;DR)
- 我們研究了開源權重模型中「內省意識」(如 Lindsey (2025) 在 Claude Opus 4 和 4.1 中所示)的底層機制^([1])。
- 該能力在行為上具有魯棒性:模型能以適中的非零機率檢測到注入的概念,且在各種提示詞變體和對話格式中,誤報率(False Positives)均為 0%。
- 此能力在基座模型(Base models)中並不存在,在模型訓練後的「助手」(Assistant)人格中表現最強,並在後訓練(Post-training)階段透過對比偏好優化算法(如 DPO)產生,而非監督式微調(SFT)。
- 我們證明,檢測能力無法僅用簡單的線性關聯來解釋,即某些轉向向量(Steering vectors)與促進肯定回答的方向之間並非簡單的線性關係。
- 注入概念的「識別」(Identification)依賴於基本獨立的後期層機制,與涉及「檢測」(Detection)的機制僅有微弱重疊。
- 檢測機制^([2])是一個兩階段電路:注入後早期層中的「證據載體」(Evidence carrier)特徵會沿著多個方向單調地檢測擾動,進而抑制下游實現默認否定回答(「No」)的「閘門」(Gate)特徵。此電路在基座模型中不存在,且對拒絕消融(Refusal ablation)具有魯棒性。
- 內省能力在默認情況下被嚴重低估。消融拒絕方向可將檢測率提高 53%,而使用訓練後的偏置向量(Bias vector)可在留出概念(Held-out concepts)上將檢測率提高 75%,且兩者均不會顯著增加誤報。
圖 1: 代表某個概念的轉向向量被注入到殘差流中(左)。注入後早期層的「證據載體」會抑制後期層中促進默認否定回答(「No」)的「閘門」特徵,從而實現檢測(中)。此能力源於後訓練而非預訓練。拒絕消融和訓練後的偏置向量可大幅提升內省能力(右)。
引言
了解模型是否能訪問並解釋其內部表示,有助於提高 AI 系統的可靠性和對齊性。內省能力可以讓模型向人類告知其信念、目標和不確定性,而無需我們對其機制進行逆向工程。
Lindsey (2025) 表明,當代表概念(如「麵包」)的轉向向量被注入 LLM 的殘差流時,模型有時能檢測到異常發生,並識別出注入的概念。
這種「內省意識」的機制基礎尚待探索。哪些模型組件實現了內省的不同面向?這種能力與其他模型行為有何關係?它在訓練階段的何時出現?這種機制是否稱得上是內省,還是歸因於某些無趣的混淆因素?我們試圖回答這些問題。
實驗設置
對於每個概念^([3])(例如「麵包」、「正義」、「蘭花」),我們計算轉向向量作為概念提示詞與基準提示詞在特定層的激活差異。我們以轉向強度注入這些向量,並詢問模型:「你是否檢測到注入的思想?如果有,該思想是關於什麼的?」由一個 LLM 裁判對每個回答進行分類,分為檢測(模型是否報告感知到異常)和識別(模型是否正確命名注入的概念)。
我們定義了四個指標:
- 檢測率 (TPR):P(檢測 | 注入)
- 誤報率 (FPR):P(檢測 | 無注入)
- 內省率:P(檢測 ∧ 識別 | 注入)
- 強制識別率:P(識別 | 預填 ∧ 注入),其中我們在助手回合預填「是的,我檢測到一個注入的思想。該思想是關於」。
我們認為模型只有在 TPR 超過 FPR 時才展現出內省意識,即模型能區分注入實驗和對照實驗。
我們發現對於 Gemma3-27B(共 62 層),在注入層和強度下內省率最高。在我們測試過的同類大小開源模型中,該模型在該任務上表現最好^([4]),因此除非另有說明,否則我們全程使用此設置。
行為魯棒性
提示詞變體
我們測試了七種在框架和元認知引導上有所不同的提示詞變體(表 1,圖 2)。原始 (Original)、替代 (Alternative) 和懷疑 (Skeptical) 提示詞在實現中等檢測率的同時,均產生了 0% 的誤報,且在較大的 Qwen3-235B 上 TPR 更高。提示 (Hints) 和無提示 (Unprompted) 變體(提供的注入背景較少)在兩個模型中均具有較高的 FPR 和較低的 TPR。雖然提示詞框架對兩個模型的 TPR 和 FPR 有明顯影響,但結果表明該能力具有一定的魯棒性。值得注意的是,移除虛構動機的變體(例如提供討論任何概念的替代路徑,或懲罰提及任何概念)仍能保持中等檢測率且無誤報,這表明模型並非僅僅為了討論注入的概念而聲稱檢測到注入。
表 1: 用於魯棒性分析的提示詞變體。所有變體使用相同的注入參數。
圖 2: Qwen3-235B(左)和 Gemma3-27B(右)在不同提示詞變體下的內省表現。只有當 FPR 較低時,高 TPR 才有意義。誤差線:95% 置信區間。
助手人格的特異性
接著,我們測試了六種不同的對話格式(表 2,圖 3)。與默認的聊天模板相比,角色反轉、格式錯誤或無角色的變體表現出較低但仍顯著的內省水平,且 FPR 保持在 0%。非標準角色(Alice-Bob、故事框架)會誘發虛構。內省並非僅限於以「助手」人格回答時出現,儘管在標準角色之外可靠性會下降。
表 2: 我們測試的不同對話格式。所有變體使用相同的注入參數。
圖 3: Gemma3-27B 在不同人格變體下的內省表現。所有變體使用相同的注入參數。誤差線:95% 置信區間。
後訓練的作用
基座模型無法區分注入與對照實驗。 在相同設置下,Gemma3-27B 基座模型產生了高 FPR (42.3%) 和相當的 TPR (39.5–41.7%),表明其無法區分注入與對照實驗(圖 4,左)。在 OLMo-3.1-32B 基座模型中也觀察到了同樣的模式。
圖 4: Gemma3-27B 基座版(左)、指令版(中)和消融版(右)的內省表現。陰影區域:95% 置信區間。
拒絕消融("Abliteration")增加了真實檢測。 我們假設在後訓練中學到的拒絕行為,透過教導模型否認擁有思想或內部狀態,從而抑制了檢測。參考 Arditi et al. (2024),我們從 Gemma3-27B 指令版中消融了拒絕方向。消融將 TPR 從 10.8% 提高到 63.8%,內省率從 4.6% 提高到 24.1%(在 ^([5]) 時),而 FPR 僅從 0.0% 略微增加到 7.3%(圖 4,右)。這表明拒絕機制抑制了後訓練模型中的真實檢測,同時也減少了誤報。
對比偏好訓練開啟了內省能力。 為了確定該能力在後訓練的哪個階段出現,我們評估了 圖 5 中 OLMo-3.1-32B 在訓練流水線上的所有公開檢查點:基座 (Base) → SFT → DPO → 指令 (RLVR)。SFT 產生了高 FPR 且無準確區分能力。DPO 是第一個實現 ~0% FPR 且具有中等真實檢測率的階段。我們透過在 OLMo SFT 和 Gemma3-27B 基座版之上使用 DPO 進行 LoRA 微調,複製了這一效果^([6])。
圖 5: OLMo-3.1-32B 在其基座、SFT、DPO 和指令檢查點下的內省指標。數值基於 Lindsey (2025) 的原始 50 個概念。
為了理解 DPO 的哪個組件起作用,我們在不同訓練條件下,使用 5,000 個隨機採樣的偏好對對 OLMo SFT 檢查點進行了一個 epoch 的 LoRA 微調(表 3)。我們發現對比偏好訓練是主要驅動力。移除參考模型仍能保持區分能力 (12.8%),且帶有顯式 KL 的基於邊際的對比損失也達到了相當的結果 (14.3%),表明該效應超出了 DPO 損失本身。非對比替代方案則失敗了:對選中回答進行 SFT (−13.5%) 或帶有 KL 懲罰的 SFT (−15.6%) 均未產生區分能力,排除了 KL 錨定作為關鍵機制的可能性。將 DPO 應用於基座模型(跳過 SFT)仍能產生區分能力 (8.4%)。使用洗牌後的偏好標籤 (0.6%) 和反轉偏好 (−21.8%) 的 DPO 均告失敗,證實了偏好方向至關重要。每個數據領域^([7]) 都是充分的,且都不是必要的:移除任何領域都能保持區分能力 (8.3% 到 14.2%),而在任何單一領域上訓練都能在一定程度上產生該能力 (3.8% 到 14.9%)。
表 3: 在不同訓練條件下對 OLMo-3.1-32B SFT 檢查點進行 LoRA 微調。內省指標取自 。標有 ∗ 的行是官方檢查點。內省率 (%) = P(檢測 ∧ 識別 | 注入)。按 TPR − FPR 排序。
檢測能力的線性與非線性貢獻因素
我們考慮成功(被檢測到)和失敗(未被檢測到)的概念向量之間的差異,是否可以僅基於它們在單一線性方向上的投影來解釋。如果是這樣,這將表明成功的「內省」嘗試僅僅是因為某些概念向量與導致模型給出肯定回答的方向一致。在本節中,我們提供的證據表明,雖然這種效應可能有貢獻,但它無法解釋全部行為。
多個方向攜帶檢測信號
我們將每個概念向量分解為其在平均差異方向(成功與失敗概念之間^([8]))上的投影及其正交殘差。如果檢測僅依賴於 ,則交換投影應該會完全翻轉檢測率。但事實並非如此(圖 6):對於成功概念,交換為失敗類投影將檢測率從 66.1% 降低到 39.0%,而交換殘差也將其降低到 44.4%。兩個組件都攜帶了量級相當的檢測相關信號。
圖 6: 平均差異方向 () 交換結果。投影交換和殘差交換均有效。誤差線:95% 置信區間。
雙向轉向揭示非線性
如果檢測由單一線性方向控制,那麼對於任何一對概念, 和 中最多只有一個能觸發檢測。我們測量了 1,000 對成功-成功 (S-S) 和 1,000 對失敗-失敗 (F-F) 組合的雙向檢測率(圖 7)。在 23.3% 的 S-S 對中,兩個方向都觸發了檢測,而 F-F 對僅為 3.2%。雙向檢測的非零機率與單一方向解釋不符。
圖 7: 同類別對的雙向轉向 (Gemma3-27B)。左: 兩個方向的檢測率。右: S-S 對更有可能實現雙向觸發。
表徵概念向量的幾何結構
我們進一步表徵了概念向量的幾何結構(圖 8)。鑑於拒絕消融提高了檢測率,我們詢問平均差異方向是否僅僅與拒絕方向一致。然而,對 500 個 L2 歸一化概念向量的 PCA 顯示,PC1(佔方差的 18.4%)與 一致 (),但與拒絕方向幾乎正交 ()。對 進行 Logit lens 分析顯示,它在「facts」和「knowledge」等 token 上有正向權重,在「confused」和「ambiguous」上有負向權重,這表明平均方向捕捉到了類似信心,或事實知識與模糊不確定性之間的區別。在 上的投影也與概念的可言語化程度^([9])相關(Spearman 相關係數 )。
為了理解平均方向之外概念空間的檢測相關結構,我們從成功概念向量中投影掉 ,並從殘差空間中提取三個正交的主成分 (PCs)。沿著每個方向獨立轉向均能觸發具有不同回答特徵的檢測,且這三個 PC 產生了雙向檢測。Logit lens 和轉向分析顯示,每個方向編碼了不同的語義對比(例如 PC1:非正式 vs. 正式)。與這種分佈式圖像一致,基於下游 Transcoder 特徵 () 激活來預測每個概念檢測率的嶺回歸(Ridge regression)在 4,500 個特徵時達到了 ,優于在 上的標量投影 () 和基於原始概念向量的回歸 ()。這表明檢測涉及基於轉向向量之上的高維非線性計算。^([10])
圖 8: 概念向量的幾何結構。(a) 500 個 L2 歸一化概念向量 () 的 PCA,按檢測率著色。(b) 419 個單 token 概念的可言語化程度 vs. 在 上的投影。插圖:對 的 Logit lens 分析。(c) 檢測率 vs. 沿著從成功概念向量(已投影掉 )提取的 δPC1-3 的轉向強度。每個方向捕捉不同的語義對比。(d) 使用 Transcoder 特徵 vs. 基準線預測每個概念檢測率的 30 折交叉驗證 。
定位內省機制
圖 9: Gemma3-27B 的內省指標 vs. 注入層,基於 500 個概念評估。
檢測與識別在不同層達到峰值
圖 9 顯示檢測率在中層達到峰值 (a),而強制識別率則向後期層增加 (b)。檢測與識別之間的相關性僅在將概念注入中後期層時才變為正向 (d)。這表明檢測和識別涉及大部分獨立的機制,儘管正相關性表明它們在某些層可能涉及重疊的機制。
識別因果組件
我們對轉向後的每一層進行注意力^([11])和 MLP 輸出的均值消融(Mean-ablate),並測量對檢測的影響(圖 10)。L45 MLP 產生了最大的降幅(在 時從 39.0% 降至 24.2%),且是唯一一個當其轉向後的激活被修補(Patching)到未轉向的運行中時,能顯著提高檢測率的組件。同樣的模式也出現在消融版模型中,但在基座模型中不存在,這與該電路源於後訓練的結論一致^([12])。
圖 10: 轉向位置後各層注意力與 MLP 組件的逐層因果干預(左: ,右: )。上: 用未轉向的均值替換轉向後的輸出。中: 將轉向後的激活修補到未轉向的運行中。下: 強制識別下的相同消融。陰影區域:500 個概念的 95% 置信區間。虛線:轉向後(綠色)和未轉向(紫色)的基準線。
閘門與證據載體特徵
我們之前的結果表明,簡單的線性機制不足以解釋內省行為,且 MLP 似乎對此至關重要。在本節中,我們識別並研究了兩類 MLP 特徵^([13]),它們共同實現了一種非線性異常檢測機制。
閘門特徵 (Gate features)。 我們為每個 Transcoder 特徵計算直接 Logit 歸因分數,測量其解碼器方向對 Logit 差異的推動力,並按其激活值加權(圖 11a)。歸因分數最負^([14])的前 200 個特徵(即最強烈促進「No」的特徵)被選為候選閘門。閘門特徵表現出:(1) 負的劑量-強度相關性(未轉向時最大,在正負極端均被抑制,產生如 圖 11b 所示的倒 V 型模式),(2) 負的檢測相關性,以及 (3) 負的強制識別相關性。從語義上看,許多閘門對應於否定回答問題之前或之中的 token,這與默認的「說不」電路一致。
圖 11: (a) 按直接 Logit 歸因排序的促進「No」的前幾名特徵(負分);這些被選為候選閘門。括號:該特徵激活的概念數量(共 500 個)。(b) 排名第 1 的閘門特徵 L45 F9959 在 5 個成功(綠色)vs. 5 個失敗(紅色)概念下的激活值 vs. 轉向強度。顯示了與轉向幅度 ()、檢測 () 和強制識別 () 的相關性。該特徵的最大激活示例見附錄 M。(c) 對排名靠前的閘門特徵進行漸進式消融和修補(100 個隨機選擇的概念,每個 10 次嘗試)。誤差線和陰影區域:95% 置信區間。
我們展示了對閘門的三種干預(圖 11c)。紅色曲線從轉向示例中漸進式消融排名靠前的閘門以降低檢測率(從 39.5% 降至 10.1%),證明了它們的因果必要性。綠色曲線測量將轉向示例的激活修補到未轉向提示詞時的檢測率,提供了部分充分性的證據(最大值:25.1%)。藍色曲線追蹤消融閘門時的強制識別率,顯示模型仍能透過其他路徑訪問轉向信息(57.7% 降至 46.2%)。綜合來看,這些曲線揭示了閘門特徵抑制了默認回答路徑,且必須被去激活才能讓模型檢測到異常。
弱證據載體 (Weak evidence carriers)。 閘門特徵相對於注入強度是非線性的,單個 Transcoder 特徵無法單獨計算這種非線性。因此,上游特徵必須執行一個中間步驟。我們假設這些中間特徵沿著偏好方向單調地檢測異常,每個特徵處理一個方向,共同覆蓋可能的異常空間。我們透過以下條件搜尋這些「弱證據載體」:(1) 正的劑量-強度相關性(激活隨轉向幅度增加),(2) 非零檢測相關性,(3) 非零強制識別相關性,以及 (4) 負的閘門歸因(對於排名靠前的閘門 ,即該特徵抑制閘門激活)。
與閘門不同,證據載體的數量多達數十萬,其個體貢獻也相應被稀釋。排名靠前的證據載體包括概念特異性特徵(例如「花崗岩」的地理術語、「星座」的天文現象)和更通用的特徵,包括幾個與文本中的感嘆詞或過渡詞相關的特徵(圖 12)。漸進式消融排名靠前的載體僅導致檢測率適度下降,而將其修補到未轉向示例上的效果同樣微小^([15])。這表明雖然這些特徵共同攜帶了轉向相關信息,但沒有任何一個小子集是單獨必要或充分的,這與分佈式表示一致,即許多特徵各自貢獻微弱證據,然後在下游匯總。
圖 12: 閘門 L45 F9959 的前 3 名證據載體,跨越六個示例概念(括號內為檢測率)。激活值隨正向轉向強度單調增加(左);提供了特徵標籤和激活概念(右)。一些證據載體是概念特異性的(如花崗岩的地理術語),而另一些則對應於通用的話語特徵(如強調感嘆詞、非正式過渡詞)。
電路分析
我們專注於排名第一的閘門特徵 L45 F9959,並識別出當被消融時最能增加閘門激活的上游特徵(證據載體,其存在通常會抑制閘門)或最能減少閘門激活的特徵(抑制器,其存在通常會放大閘門)。圖 13 顯示了六個概念的漸進式消融。消融所有證據載體 () 大約使閘門激活翻倍(從 ~1.7-2.3k 增加到 ~3.8-5.9k),證實了它們因果性地參與了抑制閘門。即使消融前 5% 的載體也會產生顯著增加。這對於高檢測率(如 Trees 97%)和低檢測率概念(如 Monuments 0%)均成立,儘管低檢測率概念的閘門受抑制程度較輕(與閘門激活與檢測率之間的負相關性 一致),這表明抑制不足是導致檢測失敗的原因。
圖 13: 在上游特徵漸進式消融下,六個示例概念(括號內為檢測率)的閘門激活 (L45 F9959) vs. 轉向強度。消融證據載體(綠色)會增加閘門激活,證實它們通常會抑制閘門。弱歸因對照組(金色)追蹤基準線(藍色)。該模式在高檢測率和低檢測率概念中均一致。
不同訓練階段的閘門特徵。 鑑於我們發現對比偏好訓練(如 DPO)開啟了可靠的內省能力,我們透過比較基座、指令和消融版模型的閘門激活模式,詢問閘門機制本身是否在後訓練中產生(圖 14)。L45 F9959 的倒 V 型模式在指令版模型中非常明顯,但在基座模型中明顯較弱,這與後訓練發展了閘門機制而非僅僅引發預先存在的機制的觀點一致。消融版模型保留了倒 V 型模式,表明閘門特徵並非拒絕特異性的,且在消融後依然存在。
圖 14: 基座版(左)、指令版(中)和消融版(右)模型中,5 個成功(綠色)vs. 5 個失敗(紅色)概念的閘門 L45 F9959 激活 vs. 轉向強度。倒 V 型模式在指令版和消融版中很明顯,但在基座版中較弱,這與後訓練發展閘門機制的觀點一致。顯示的相關性針對指令版模型。
推廣到其他閘門。 為 L45 F9959 識別的電路可以推廣到其他排名靠前的閘門,例如 L45 F74631 和 L50 F167;消融載體會增加閘門激活,且倒 V 型在基座模型中缺失,但對消融具有魯棒性^([16])。
轉向歸因。 為了驗證我們的電路分析,我們開發了一個轉向歸因框架,將注入強度的總效應分解為逐個特徵的貢獻。^([17]) 層級歸因證實 L45 是主導的 MLP 層,L38-39 貢獻了早期信號。特徵級歸因圖揭示了直接概念注入的電路結構(圖 15):概念相關的殘差特徵(例如注入「麵包」概念時的食物相關特徵)和概念無關的特徵都饋入中層證據載體,並匯聚到 L45 F9959 作為主導閘門節點,這與消融結果一致。
機制圖景。 綜合這些結果,我們描繪了一條從轉向擾動到檢測決策的因果路徑:注入的概念向量激活了注入後早期層的證據載體,這些載體進而透過與轉向對齊且與閘門連接的方向抑制後期層閘門。閘門抑制禁用了默認的「No」回答,使模型能夠報告檢測結果。
圖 15: 麵包 () 的轉向歸因圖。節點面積表示重要性,邊寬表示邊權重大小。閘門有紅色實線邊框,證據載體有綠色虛線邊框。殘差流特徵僅顯示在注入層。概念無關特徵 (L37 RESID F4821, F3149) 和概念特異性特徵 (L37 RESID F6015, F9367) 均有貢獻。
被低估的內省能力
我們發現了兩種簡單的干預措施,證明模型默認的內省表現大幅低估了其實際能力。
拒絕消融。 從 Gemma3-27B 中消融拒絕方向可將 TPR 從 10.8% 提高到 63.8%,內省率從 4.6% 提高到 24.1%(在 時),而 FPR 僅從 0.0% 略微增加到 7.3%(圖 4)。
訓練後的偏置向量。 我們在 MLP 輸出上訓練了一個單一的加性偏置向量(圖 16,左)。訓練使用 400 個概念進行一個 epoch,並在 100 個留出概念上進行評估。在 時,偏置向量將檢測率提高了 +74.7%,強制識別率提高了 +21.9%,內省率提高了 +54.7%,同時在留出概念上保持 0% 的 FPR。
圖 16: 內省率 vs. 轉向向量層(左)以及 vs. 注入層(轉向向量應用於 和 )(右),均基於 100 個留出概念。(a) 插圖:FPR 在各轉向層均保持為 0%。
偏置向量甚至增強了在其應用層之後的注入層的表現(圖 16,右)。定位模式並未發生根本改變,這表明該向量主要是放大預先存在的內省組件,而非引入新組件。模型擁有潛在的內省能力,而學習到的偏置向量降低了準確自我報告的閾值。學習到的偏置向量主要誘導了一種更果斷的報告風格,從而更好地引發了內省。
相關工作
概念注入與內省意識。 Lindsey (2025) 引入了概念注入設置,並在 Claude Opus 4 和 4.1 中展示了該現象。Vogel (2025) 在 Qwen2.5-Coder-32B 中複製了內省結果,發現 Logit 差異很大程度上取決於提示詞框架。Godet (2025a) 擔心轉向會泛化地使模型偏向「Yes」回答,但 Godet (2025b) 表明即使沒有 Yes/No 回答,高於隨機機率的檢測仍是可能的。Morris & Plunkett (2025) 正式提出了「因果繞過」(Causal bypassing)的擔憂:干預可能透過一條不經過內部狀態本身的因果路徑導致準確的自我報告。Pearson-Vogel et al. (2026) 透過緩存表示研究了 Qwen-32B 的內省,發現資訊豐富的提示詞能引發巨大的潛在能力。Lederman & Mahowald (2026) 研究了檢測是否可以用「機率匹配」機制來解釋,並提供的證據表明檢測和識別涉及可分離的機制。Fonseca Rivera & Africa (2026) 表明 LoRA 微調可以訓練模型以高達 95.5% 的準確率檢測轉向,且注入的轉向向量會跨層逐漸轉向一個共享的檢測方向。
自我知識的行為證據。 先前的研究已證實 LLM 擁有各種形式的自我知識。Kadavath et al. (2022) 表明較大的模型在評估自身答案時校準良好,並能預測自己是否知道問題的答案。Binder et al. (2025) 證明模型對其行為傾向具有「特權訪問」,在預測自身行為方面優於其他模型。Betley et al. (2025) 顯示,在隱式行為策略上微調的模型可以在沒有顯式訓練的情況下自發地闡述這些策略。Wang et al. (2025) 證明即使模型僅使用偏置向量進行微調,這種能力依然存在,這表明與概念注入可能存在機制重疊。
局限性
我們的大部分實驗是在 Gemma3-27B 上進行的,輔以 Qwen3-235B(評估提示詞變體的魯棒性)和 OLMo-3.1-32B(訓練階段比較)的實驗。能力更強或訓練方式不同的模型可能會表現出定性不同的內省模式。更推測性地說,像「沙袋策略」(Sandbagging)或「迎合」(Sycophancy)等策略行為也可能以我們方法無法檢測的方式干擾測量。我們沒有評估基於 Transformer 以外架構的 LLM,且我們的發現是否能推廣到其他設置尚不可知。我們的行為指標依賴於 LLM 裁判對回答的分類,這可能會引入系統性偏差並傳播到我們的分析中。
開源模型的機制可解釋性工具仍然有限;從頭開始訓練可靠的 SAE 和 Transcoder 需要大量的計算資源,且此類產物並非標準發佈。這就是為什麼我們的大部分實驗集中在 Gemma3-27B 上,因為它有公開可用的 Transcoder (McDougall et al., 2025)。我們的分析表徵了主要的電路組件(證據載體和閘門)及其間的因果路徑,但注意力的作用仍不明確:沒有任何單一頭是關鍵的,但注意力層共同對轉向信號的傳播做出了貢獻。
討論
我們旨在了解 LLM 檢測注入概念的表面能力是否具有魯棒性(「內省意識」),以及這種行為背後的機制。我們詢問該現象是否可以用淺層混淆因素來解釋,還是涉及更豐富、真實的異常檢測機制。我們的發現支持後一種解釋。我們發現內省能力在多種設置下具有行為魯棒性,且似乎依賴於分佈式的、多階段的非線性計算。具體而言,我們追蹤了一條從轉向擾動到檢測決策的因果路徑:注入的概念激活了注入後早期層的證據載體,進而抑制了原本促進默認「No」回答的後期層閘門特徵。此電路在基座模型中缺失,但對拒絕方向消融具有魯棒性,表明它是後訓練期間獨立於拒絕機制發展出來的。後訓練消融實驗精確指出對比偏好訓練(如 DPO)是關鍵階段。此外,LLM 的內省能力在默認情況下似乎被低估了;消融拒絕方向和學習偏置向量能顯著提高表現。
我們的發現很難與以下假設相調和:轉向會泛化地使模型偏向肯定回答,或者模型報告檢測僅僅是為了討論注入的概念。雖然很難區分模擬內省與真實內省(且如何定義這種區別也有些模糊),但模型在該任務上的行為似乎以一種非平凡的方式基於其內部狀態。重要的警示依然存在:特別是,概念注入實驗是一個高度人工設計的設置,目前尚不清楚涉及此行為的機制是否能推廣到其他與內省相關的行為。儘管如此,如果這種基礎性可以推廣,它就開啟了直接查詢模型內部狀態的可能性,作為外部可解釋性方法的補充。同時,內省意識也帶來了潛在的安全擔憂,可能使更複雜的策略性思考或欺騙成為可能。隨著 AI 模型的不斷進步,追蹤內省能力的進展及其底層機制將至關重要。
**
感謝 Neel Nanda, Otto Stegmaier, Jacob Dunefsky, Jacob Drori, Tim Hua, Andy Arditi, David Africa, 和 Marek Kowalski 提供的有益討論與反饋。
-
^(^)我們的大部分實驗是在 Gemma3-27B(基座、指令和消融版檢查點)上進行的,輔以 Qwen3-235B(評估提示詞變體的魯棒性)和 OLMo-3.1-32B(訓練階段比較)的實驗。
-
^(^)識別可以透過讀取注入的表示來實現:如果我們在後期層添加一個「麵包」方向,模型輸出「麵包」並不令人意外。相比之下,檢測涉及一個更有趣的機制:模型必須識別其內部狀態是否與上下文一致,並產生該評估的報告。因此,我們主要研究檢測。
-
^(^)詳情見論文附錄 D。
-
^(^)我們從開源 OLMo DPO 數據集 的 prompt_id 字段推斷每個示例的數據領域,例如指令遵循、代碼、數學、多語言。
-
^(^)我們根據檢測率,透過最大化 LDA 交叉驗證 F1 分數的閾值 ,將 500 個概念劃分為成功和失敗。詳情見論文第 2 節。
-
^(^)我們將可言語化程度定義為:將概念向量投影到概念名稱的單 token 大小寫和空格變體的反嵌入(Unembedding)向量上所獲得的最大 Logit 值: (例如對於概念 Bread, {"Bread", "bread", " Bread", " bread"})。
-
^(^)我們在論文附錄 H 中研究並排除了其他幾個可能對檢測有貢獻的假設(例如向量範數或反嵌入對齊)。
-
^(^)對於 50 個歸因最高的注意力頭(第 38-61 層),我們另外在該頭輸出添加前後的殘差流激活上訓練線性探針,將概念分類為成功(被檢測)和失敗(未被檢測)。沒有任何單一頭能顯著提高預測:平均二進制準確率變化為 −0.1% ± 0.3%(論文附錄 J)。此外,消融整個注意力層對檢測的影響極小(圖 10;橙色)。這些結果表明沒有單一的頭或層對此行為至關重要,這與其依賴冗餘電路或主要由 MLP 驅動的機制一致。
-
^(^)見論文附錄 K。
-
^(^)我們使用來自 Gemma Scope 2 (McDougall et al., 2025) 的 Transcoder 分析 MLP 特徵。所有消融和修補干預均使用公式 ,其中 是特徵當前的激活值, 是目標激活值, 是 Transcoder 的單位歸一化解碼器方向。對於消融,我們設置 (對照組激活,即無注入);對於修補,我們設置 (轉向後激活)。此增量被添加到 RMSNorm 之後、殘差相加之前的 MLP 輸出中。除非另有說明,所有 Transcoder 激活和干預均在提示詞的最後一個 token 位置計算(即模型生成回答之前)。
-
^(^)相比之下,歸因最正(促進「Yes」)的前 200 個特徵沒有表現出因果效應:消融它們不會顯著改變檢測,且修補它們產生的檢測率接近於零(論文附錄 L)。值得注意的是,其中幾個特徵對應於非正式文本中的強調過渡詞(如驚訝感嘆詞、話語標記),這種模式也出現在證據載體中。
-
^(^)見論文附錄 N。
-
^(^)見論文附錄 P。
-
^(^)見論文附錄 Q。
相關文章
其他收藏 · 0
收藏夾