我理解大型語言模型架構的工作流程
Sebastian Raschka'S Blog·
我分享了自己理解新發佈的開放權重模型架構的工作流程。我通常從官方技術報告開始,並透過檢查 Hugging Face 上的設定檔與參考實作程式碼,來獲取更準確的架構細節。
我理解 LLM 架構的工作流程
一套以學習為導向的工作流程,用於理解新發佈的開放權重模型
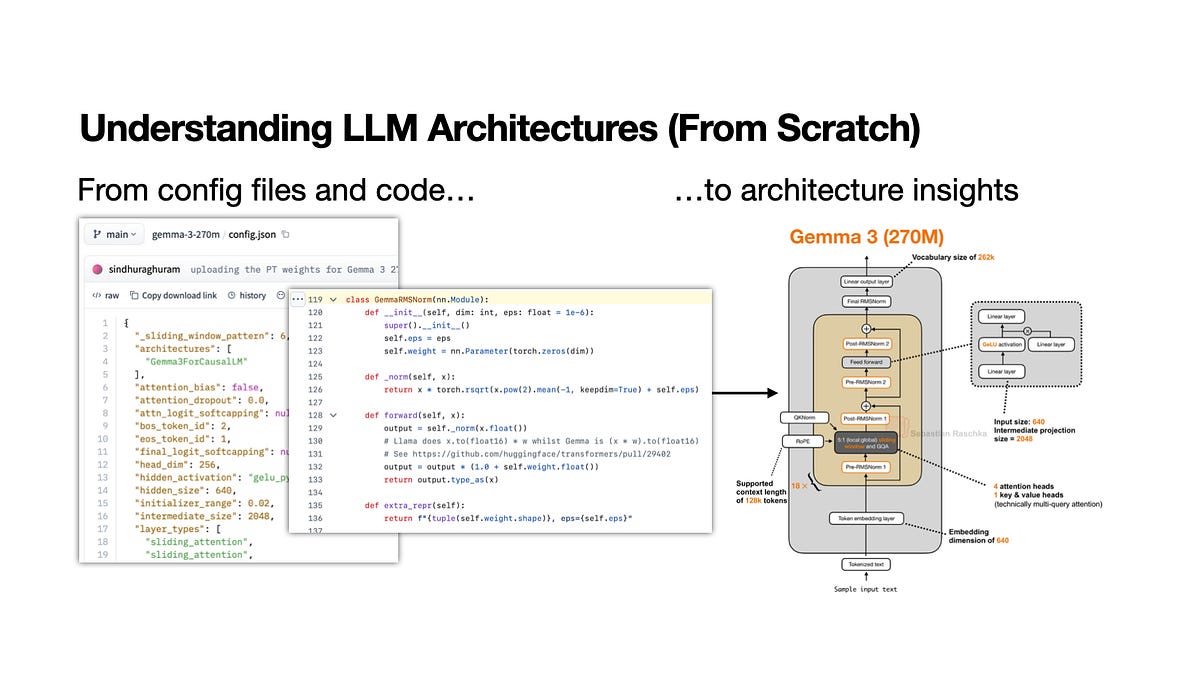
過去幾個月,許多人要求我分享我的工作流程,即我是如何構思文章、演講以及 LLM-Gallery 中那些 LLM 架構草圖和圖表的。因此,我認為記錄下我通常遵循的過程會很有用。
簡短的版本是,我通常從官方技術報告開始,但近來論文的詳細程度往往不如以往,特別是對於大多數來自業界實驗室的開放權重模型。
好消息是,如果權重已分享在 Hugging Face Model Hub 上,且該模型受 Python transformers 函式庫支援,我們通常可以直接檢查設定檔(config file)和參考實作,以獲取更多關於架構細節的資訊。而且,「能運行的」程式碼是不會說謊的。

我也應該說明,這主要是一套針對開放權重模型的工作流程。它並不適用於像 ChatGPT、Claude 或 Gemini 這樣權重和細節均為私有的模型。
此外,這刻意設計成一個相當手動的過程。你可以自動化其中的部分環節。但如果目標是學習這些架構是如何運作的,那麼在我看來,親手完成幾次這樣的分析仍然是最好的練習之一。

本篇文章僅限付費訂閱者閱讀
相關文章
其他收藏 · 0