過去一個月我使用 AI 的 10 個有趣案例
我分享了過去一個月在日常工作中以創意方式使用 AI 的具體案例,包括自動轉錄並總結辦公室對話、自動修復團隊提到的程式錯誤,以及快速生成多種網頁設計方案。
我基本上在所有的工作中都會使用 AI 輔助,每天長達數小時。我的同事們也是如此。最近的調查顯示,超過 50% 的美國人在過去一週內曾使用 AI 來協助工作。我的建築師最近開始給我發送顯然是由 ChatGPT 生成的電子郵件。^([1])
儘管如此,我對其他人如何使用 AI 輔助知之甚少,這點令人驚訝。或者至少,我不知道那些不是在 Twitter 或 LinkedIn 上分享行銷課程的怪異 AI 網紅們是如何使用 AI 的。因此,這裡列出了 10 個我以至少帶點創意的方式使用 AI 的具體案例,以及效果如何。
1) 轉錄並總結我們團隊辦公室裡的每一次對話
利用一個名為「Omnilog」的 Lightcone 內部應用程式,我們在辦公室放置了一個麥克風,記錄所有的會議,透過 ElevenLabs 進行轉錄,並使用 Pyannote.ai 進行講者識別。這花了不少功夫且非常有價值,但對於本篇文章的大多數讀者來說,設置起來可能有點太麻煩了。
然而,我成功使用 Claude Code 執行的任務是:獲取該逐字稿(通常含有大量的轉錄和講者識別錯誤),對其進行清理、總結,並將摘要和完整逐字稿發布到一個頻道,讓團隊其他成員可以補上他們錯過的內容。
這是由 Claude Code 的定期任務功能驅動的。我每小時啟動一個 Claude 程序來查詢這些日誌,加上 Slack 討論串以及關於組織正在進行的事務的其他背景資訊。^([2])
這看起來運作得相當不錯!^([3])
我為每小時定期任務設定的提示詞(Prompt)
查詢遠端 Omnilog Neon 資料庫中過去 2 小時內團隊辦公室的逐字稿(包括講者身份),使用「Team Room」講者設定檔。然後將這些逐字稿清理成易於閱讀的散文。接著寫出逐字稿的摘要。
關鍵:僅使用 remote_browser_microphone 作為擷取來源。 desktop_microphone 會擷取到 Oliver 的私人通話、會議和其他非來自團隊辦公室的音訊。團隊辦公室的會議麥克風是透過 remote_browser_microphone 傳輸的。絕對不要發布來自 desktop_microphone 的逐字稿——那是私密的。
在請求逐字稿時,請為每個片段獲取至少前 3 個講者置信度,並思考 Pyannote 的講者分配是否錯誤。
搜尋 #listencone-livestream 頻道,查看你正在分析的逐字稿部分是否已經發布過。然後在頻道中發布,最上層是對話摘要,回覆中則是完整逐字稿。
發布到 Slack: 直接透過 curl 使用 Slack API 和 Lightcone Factotum 機器人權杖(token),而不是使用 Slack MCP 工具,這樣發文會顯示來自機器人而非 Oliver 的帳號。權杖位於 /Users/habryka/Lightcone/lightcone-factotum/.env.local 中的 SLACK_BOT_TOKEN。發布方式如下:
source /Users/habryka/Lightcone/lightcone-factotum/.env.local
curl -X POST https://slack.com/api/chat.postMessage \
-H "Authorization: Bearer $SLACK_BOT_TOKEN" \
-H "Content-Type: application/json" \
-d '{"channel":"C0AFGB94E3W","text":"your message"}'
對於討論串回覆,請在 JSON 主體中加入 "thread_ts":"<parent_ts>"。你仍然可以使用 Slack MCP 工具來讀取/搜尋頻道。
如果根據逐字稿顯示沒有發生實質性對話,則不執行任何操作。
2) 嘗試自動修復團隊成員大聲提到或在 Slack 中抱怨過的任何簡單 Bug
同樣使用 Claude Code 的每小時任務,我會查詢...
- 來自筆電麥克風的所有逐字稿,
- 我們的團隊辦公室麥克風,
- 我們 Slack 中的所有近期活動,
- 以及我一直在處理的任何專案,
- 和任何相關的 Github issue
...並要求 Claude 識別任何被提及或報告的 Bug。然後我要求它識別出一個看起來特別可能有簡單修復方案的 Bug,建立一個帶有建議修復方案的分支(branch),並在 Slack 中提供連結。
最初的幾次嘗試很糟糕。Claude 要麼過於雄心勃勃,試圖實現需要花費太長時間審核並增加技術債的功能;要麼修復我們已經修復過的 Bug;或者嘗試修復我們之前已經決定沒有簡單解決方案的 Bug。但在反覆調整提示詞並確保它真正掌握了所有相關背景資訊後,成功率顯著提高。
我們現在每天大約會合併一個以此方式產生的 Bug 修復。
我為每小時定期任務設定的提示詞
查詢我過去幾小時的 Omnilog 逐字稿數據,以識別我們是否在 Lightcone 團隊辦公室或我參加的任何會議中討論了任何重要的 Bug 或功能。
然後也搜尋 Slack 中關於此功能的任何近期對話以獲取相關背景。特別確保搜尋過去一個月的 #m_bugs_channel 和 #teamcone_automations,看看該功能或 Bug 是否在那裡被討論過,以及你是否能找到相關背景。在 #m_bugs_channel 中,如果一個 Bug 有打勾符號的反應,則表示已修復;如果有加號反應,則表示高優先級。同時確保沒有任何近期的 PR 已經處理了該 Bug 或功能。務必獲取你看到的任何討論 Bug 或功能的頂層訊息的完整討論串。
除了查看 forum_magnum_bugs,也要查看 forum_magnum_product。如果一個討論串提出了具體的變更(而非模糊的建議),請考慮實作它,並在討論串中回覆你的分支連結。
如果修復或變更影響特定頁面,除了連結預覽部署的首頁外,還要生成指向預覽部署內相關頁面的深層連結。例如,如果變更影響所有文章頁面,請連結至 <preview-deployment-base-url>/posts/bJ2haLkcGeLtTWaD5/welcome-to-lesswrong。
在找到每個功能的相關背景後,決定其中是否有任何一個適合由你實作。不要嘗試修復你已經在 #teamcone_automations 中建立過討論串的 Bug 或實作該功能,除非對先前嘗試的回覆傳達了實質性的反饋。如果你決定不執行任何操作,則無需發布更新(我們不希望你發送每小時的垃圾訊息)。
如果是,請在適當的儲存庫(ForumMagnum, lightcone-factotum, omnilog 等)建立分支,並將該功能或 Bug 修復的實作提交(commit)到該分支。使用單個提交(或壓縮你的提交)。然後在 #teamcone_automations 中發布連結和簡短摘要,如果有相關的 Slack 討論串,也請在那裡作為回覆發布。連結分支的格式為 https://github.com/{org}/{repo}/{compare}/{base}...{branch}。確保提交訊息中包含 "preview" 一詞,這能確保我們建立預覽部署,使審核變更更容易。將分支名稱保持在 26 個字元以內,以免 Vercel 將其截斷並添加雜湊值。然後讓提交訊息和任何 Slack 訊息連結到 https://baserates-test-git-{branchname}-lesswrong.vercel.app。
確保提交訊息連結到任何重要的 Slack 討論串(最重要的是 #m_bugs_channel 中的任何提及),並回覆任何明確討論此 Bug 的討論串,附上分支連結。在建立 PR 之前請先切換到 master!不要建立 PR,只需建立分支並從 Slack 連結它。
如果你在任何地方留下評論,請註明你是 CLAUDE 而不是我,即使你使用的是我的帳號。不要模仿我的口吻說話。
發布到 Slack: 直接透過 curl 使用 Slack API 和 Lightcone Factotum 機器人權杖,而不是使用 Slack MCP 工具,這樣發文會顯示來自機器人而非 Oliver 的帳號。權杖位於 /Users/habryka/Lightcone/lightcone-factotum/.env.local 中的 SLACK_BOT_TOKEN。發布方式如下:
source /Users/habryka/Lightcone/lightcone-factotum/.env.local
curl -X POST https://slack.com/api/chat.postMessage \
-H "Authorization: Bearer $SLACK_BOT_TOKEN" \
-H "Content-Type: application/json" \
-d '{"channel":"CHANNEL_ID","text":"your message"}'
對於討論串回覆,請在 JSON 主體中加入 "thread_ts":"<parent_ts>"。你仍然可以使用 Slack MCP 工具來讀取/搜尋頻道。
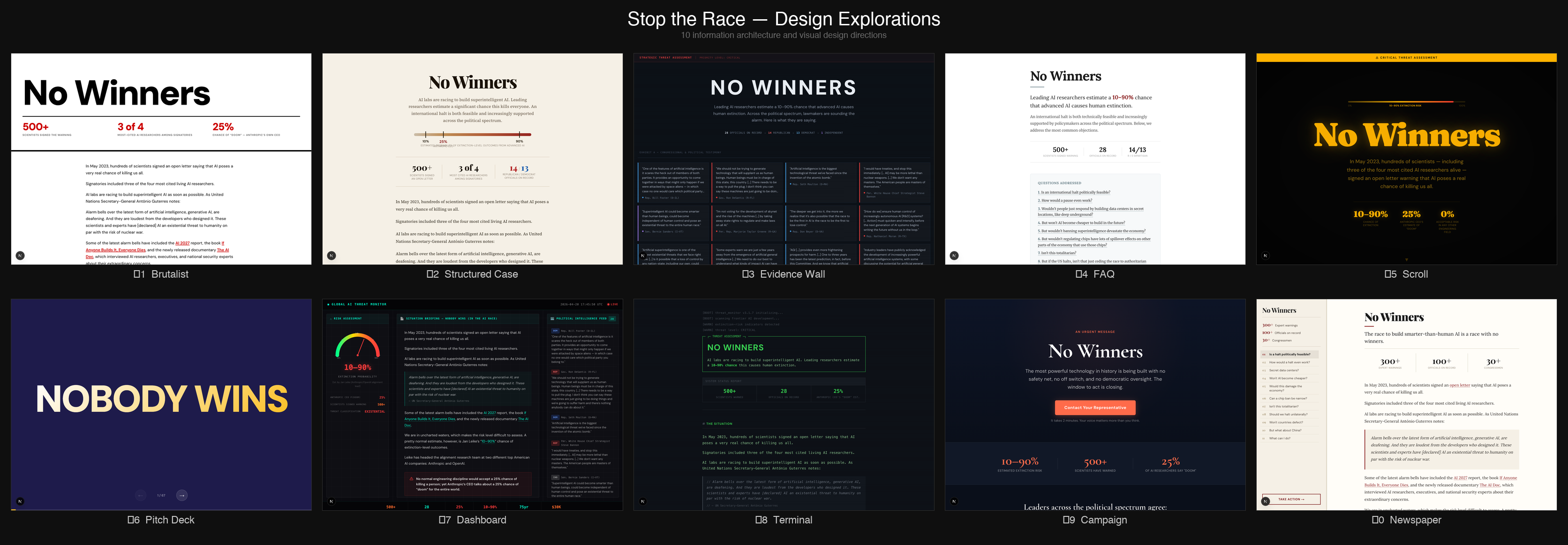
3) 為 nowinners.ai 設計 20 多種不同的設計變體
Rob Bensinger 之前寫了一篇文章,彙整了與暫停或大幅放緩 AI 發展相關的論點和證據,以及政治上的支持。他認為將其放在獨立網站上以便於分享可能是個好主意,但我們真的不確定呈現文章資訊的最佳方式是什麼,以及網站應該具備什麼樣的氛圍。
所以我要求 Claude Code 幫我製作 20 多個變體,嘗試不同的設計和設計原則:
*大多數設計都很糟糕,但我喜歡其中 1-2 個的方向,然後我從那裡開始迭代,最終得到了目前的設計(現已在 nowinners.ai 上線)。
4) 審核我的 LessWrong 文章的正確性,並就其核心論點與我爭論
我不喜歡使用 LLM 來編輯我的寫作。^([4]) 然而,我不介意讓 LLM 幫我的文章進行事實查核,或者檢查其中是否有任何極其錯誤的地方,或是有任何明顯未處理的反駁論點。
這種做法的成功率相當低(大約只有 30% 的反對意見或批評是我最終想要處理的),但成本也很低,所以我通常在發布頂層文章之前都會這麼做。最近一次這讓我更新了關於演色性指數(CRI)與光光譜圖之間確切關係的模型。
LessWrong 編輯器提供了一個 API,讓 Claude 可以在任何草稿上發布和讀取行內評論,這讓整個體驗非常符合人體工學。
我請求反饋的提示詞
我正在 LessWrong 上寫一篇文章。
文章位於 https://www.lesswrong.com/editPost?postId=<ID>&key=<sharingKey>。
請記得遵守我隨附的 LessWrong SKILL.md 中的指南和審核結構。
請閱讀這篇文章,並就其論點給我整體反饋,並對任何事實陳述進行事實查核。我希望你非常認真地思考這件事。如果需要的話,請進行「超思考」(Ultrathink)。我希望這篇文章很出色!
5) 在發布前刪除 LessWrong 文章中不必要的從句、句子、括號和隨機的贅言
我寫作最大的弱點就是太囉嗦。雖然你可能要從我冰冷死掉的手中才能搶走我的認識論限定詞(epistemic qualifiers),但我有時也會勉強承認,我寫的句子有一種迂迴的特質,往往長到讀者讀到結尾時,已經忘記開頭是怎麼寫的了。
這是我要求 Claude 幫我做的唯一編輯任務。
這並非完美無缺。特別是 Claude 喜歡用破折號結構來取代我長而迂迴的句子,雖然這並沒有真正引入任何新的詞彙或典型的 LLM 語氣,但仍然給我一種 LLM 的感覺。但大多數情況下,Claude 成功地識別了隨機的從句、適合開始新句子的位置以及不必要的重複結構,並成功地將其刪除。
我同樣使用 LessWrong 編輯器,這讓 Claude 可以直接在我的草稿上提出修改建議。
最近要求刪減內容的提示詞示例
<在一個以事實查核和整體論點反饋開始的對話中>
你能使用建議的行內編輯工具幫我刪減內容嗎?我通常太囉嗦了,過一遍來修正這一點似乎不錯。
6) 配對氛圍編程 (Pair vibe-coding)
Lightcone 團隊的每個人都使用 LLM 來驅動他們的程式開發工作。不幸的是,這導致整個組織的配對編程(pair programming)變得不再普遍。配對編程以前扮演著至關重要的角色:在定義模糊的產品任務上產生推動力、讓人們從基本原則出發思考產品,並提供一個社交環境,讓人更容易專注工作而不是被 Twitter 分心。
在 LLM 世界中,配對編程的問題在於,原本用於與編程夥伴交流的認知,現在都花在給 LLM 寫訊息上了。此外,在人們主要與 LLM 協作程式碼的世界裡,他們往往會在等待 LLM 回覆時同時處理多個任務。
但最近我們終於在配對氛圍編程(pair vibecoding)環節中取得了一些初步成功。基本設置如下:
- Robert 和我討論了一個複雜的重構約 20 分鐘,然後讓 Claude Code 獲取該對話的逐字稿並產出實作計劃。在它運作時,我們繼續討論可能出現的問題。
- 計劃準備好後,我們大聲進行審核,然後讓 Claude 獲取那段對話的逐字稿並相應地更新計劃。
- 經過又一輪審核後,我們讓 Claude 實作變更。當程式碼進來時,我們一起查看,大聲指出問題,並讓 Claude 修復它們。
這效果真的出奇地好!那種某人消失幾分鐘去給 AI 建議的計劃提供反饋,或寫一篇長長的指令文章來提供所有必要背景的常見模式消失了。取而代之的是我們只需交談,而 Claude 在背景實作。
7) 使用 Claude Cowork 桌面控制大規模建立 100 多種 Suno 歌曲變體
當我製作一首新的 Fooming Shoggoths 歌曲時,我通常會針對一個寬泛的概念取樣數百次、有時甚至數千次歌曲生成,以獲得具有正確氛圍的作品。然後,在我有了看起來有前途或有趣的內容後,我會使用 Suno 的「Cover」和「Persona」功能進行迭代,直到我滿意為止。在我最近為了準備 4 月 1 日發布第二張專輯的衝刺中,我嘗試讓 Claude 在這裡主導更多的生成過程。
我把之前所有歌曲的歌詞和我想為新專輯探索的概念列表交給 Claude,並讓它控制我 Chrome 中的 Suno 分頁,提交風格和歌詞的大量交叉組合。
然後我聽了隨機取樣的前幾秒鐘,給了 Claude 一些高層次的反饋,並讓它生成更多變體。
這並沒有產生任何哪怕是稍微接近能放入專輯的作品,但它最終讓我認為 Indie-Rock、「The National」氛圍和一首關於 AI 時間線的歌曲之間有一個特別有前途的交集,這促成了 "Friday's Far Enough For Milk",這是我創作過第三喜歡的歌曲。
8) 要求 Claude 閱讀一本關於詞曲創作的書,然後批評我的歌詞
由於上一張 Fooming Shoggoth 專輯專注於試圖捕捉其他音樂中未涵蓋的特定氛圍的歌詞,我對詞曲創作思考了很多。在追求進步的過程中,Buck 向我推薦了他最喜歡的詞曲創作書籍:Song Building: "Mastering Lyric Writing (1) (SongTown Songwriting Series)"
當然,我不想等到讀完或略讀完一整本書後才從中獲益,所以我直接要求 Claude 幫我讀,並用它來批評我寫的歌詞。
Claude 總共花了 35 秒讀完這本 100 多頁的書,並將其應用到我的歌詞中。大多數反饋都很糟糕,因為 Claude 並不擅長詩歌或歌詞創作。但有些反饋相當不錯,讓 Claude 直接引用並將書中的原則應用到我的歌詞中,讓我比自己略讀並嘗試應用理解得更好、更快。
9) 找出那些我一直向人解釋到應該寫成部落格文章的事情
除了記錄團隊辦公室和筆電麥克風的對話外,Omnilog 每 15 秒還會擷取我的螢幕內容(除非它偵測到我正在看私密內容),這意味著它擁有一份非常完整的我的活動記錄。
所以我要求 ChatGPT 瀏覽過去 2 個月它擁有的關於我的所有*內容,並整理出我一直反覆解釋的主題,或許我應該寫篇部落格文章,遵循 Gwern 關於部落格文章的「三則律」:
三則律:如果你(或其他人)已經解釋了同一件事 3 次,就該把它寫下來。
這顯然有趣到讓你不斷回頭討論,而且你現在已經有幾份草稿可以用了。
它總共產生了 40 個候選部落格文章^([5])。幾乎所有的都很糟糕。當它注意到我曾幾次大聲抱怨我們的 LessWrong 草稿頁面顯示了沒有標題且零字數的草稿時,它建議我寫一篇關於那個的文章!
標題:字數為零的無標題草稿不應存在
論點:產品介面不應向用戶顯示技術上真實但心理上毫無意義的物件。
容易寫的原因:一個小小的 UI 觀察就能寫出 500 字。
它推薦的 40 個文章標題中,有一個看起來很有前途:「寫得像 Claude 的 AI 正在讓我的警鐘失靈」。雖然標題(當然)非常糟糕,但我確實發現自己在過去幾週幾次指出,LLM 的寫作似乎被優化成一種不冒犯人的方式,這使得它在內部備忘錄或高風險溝通中變得很危險。
我的猜測是,Claude 的寫作被優化為在「缺乏模糊性可能會導致讀者注意到他們強烈反對內容」的地方精確地使用模糊性,這與我通常嘗試優化寫作的方式完全相反!
10) 為我的 LessWrong 文章建立微型互動式嵌入元件
我最近的兩篇 LessWrong 文章都包含了互動式小工具,在我看來,這些工具在解釋我試圖傳達的核心概念方面,比任何文字都做得更好:
這非常快速、直接,而且在我看來讓那些文章變得更好了。
就這樣。希望這 10 個具體例子對某些人有所幫助。也歡迎在評論中發布你自己的案例!我的感覺是,人們目前對 LLM 的創意用途分享得還不夠。
相關文章
其他收藏 · 0