追趕型演算法進展可能每年高達 60 倍
我分析了 2023 年至 2025 年間的 AI 模型,發現「追趕式」演算法進步(即達到特定能力水準所需的運算量減少)每年可能高達 16 到 60 倍,這比之前的估計要快得多。
認知狀態:這是一份可能存在重大錯誤的快速分析。我目前認為這裡有一些真實且重要的發現。我分享這份內容是為了徵求回饋,並在需要更新時告知他人,若有錯誤也希望能藉此學習。
摘要
關於演算法進步(Algorithmic Progress)的權威論文是由 Ho 等人(2024)撰寫的,他們發現從歷史上看,達到特定 AI 能力水準所需的預訓練算力每年約減少 3 倍。他們的數據涵蓋 2012-2023 年,且側重於預訓練階段。
在本篇文章中,我觀察了 2023-2025 年的 AI 模型,並發現根據我認為最直觀的分析,這段期間的「追趕式演算法進步」(catch-up algorithmic progress,包含後訓練階段)大約是每年 16 倍至 60 倍。
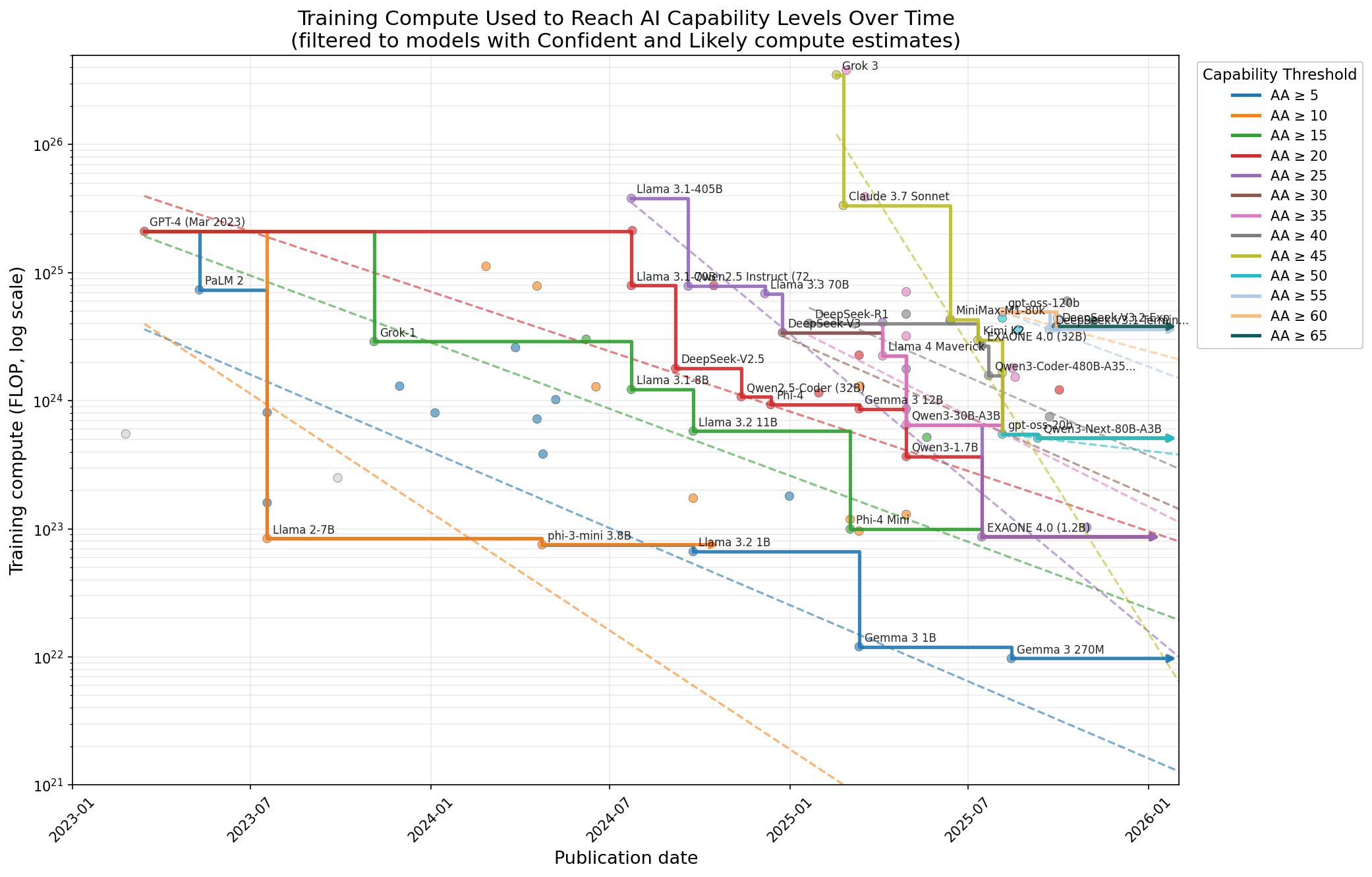
這種直觀分析的方法是:針對隨時間推移處於「訓練算力效率前沿」的模型畫出最佳擬合線,即在所有達到或超過某種能力水準的模型中,使用訓練算力最少的模型。我結合了 Epoch AI 對訓練算力的估計,以及 Artificial Analysis 智能指數(Intelligence Index)的模型能力評分。因此,每個能力水準都會從其擬合線產生一個斜率,這些斜率可以透過各種方式匯總,以確定整體的進步率。其中一種匯總方式是為每個能力水準分配主觀權重,並取能力水準斜率(以對數算力計)的加權平均值,得出演算法進步的整體估計:每年 1.76 個數量級,或算力效率提升約 60 倍,或者說達到特定能力水準所需的訓練算力減半時間為 2 個月。若看斜率的中位數,則為 16 倍,或減半時間為 2.9 個月。
基於這些證據和現有文獻,我對明年追趕式演算法進步的整體預期可能是 20 倍,80% 的置信區間為 [2倍–200倍],這比我最初想像的要高得多。
本文正文解釋了「追趕式」與「前沿式」演算法進步的區別,討論了數據分析和結果,以兩個 Qwen 模型作為常識檢查(sanity check),討論了現有的演算法進步估計,並在附錄中涵蓋了幾個相關主題。
我所說的「演算法進步」是什麼意思?
首先,讓我區分人們在討論「演算法進步」時關心的兩個不同概念:追趕速度,以及前沿領域的演算法效率提升。
追趕(Catch-up): 當一項能力首次使用 X 算力達成後,需要多長時間才能用 [少於 X 的某個量] 的算力達成該能力?方便的是,追趕速度可以直接使用相對簡單的指標來衡量:發布日期、基準測試分數和訓練算力估計。追趕速度影響 AI 能力的擴散/傳播,並間接反映了第二種演算法進步。
前沿領域的演算法進步定義較不明確。它探討的是:在給定的算力增長假設下,由於演算法的改進,AI 能力的前沿提升速度有多快?前沿效率或「有效算力」為 AI 研究自動化或智能爆炸的預測提供資訊;如果算力保持不變而研究投入激增,能力會提升多少?
Hernandez & Brown 對有效算力的定義如下:
我們認為最有用的概念是:想像一下,以浮點運算量(FLOPs)衡量,訓練 2018 年感興趣的模型,比將 2012 年的模型「擴展」(scale up)到當前的能力水準要高效多少。所謂「擴展」,我們指的是更多的算力、隨算力增加而增加的參數、避免過擬合所需的額外數據以及一些微調,但沒有更聰明的改進。
不幸的是,這並不容易衡量。它涉及一個反事實假設,即 2012 年有人大規模擴展了訓練算力。(如果他們真的那樣做了,那麼回過頭來看,我們衡量的就會是「追趕」速度!)常見的替代方案是經驗縮放定律(scaling laws):在 2012 年使用不同的算力但相同的數據集和演算法訓練一系列模型,比較它們的訓練算力和性能,並外推以估計它們在更多訓練算力下的表現。
有幾個因素會影響這兩個指標的相對速度。由於蒸餾(distillation)或合成數據,追趕速度可能會更快:一旦 AI 模型達到特定的能力水準,它就可以用來為較小的模型生成高質量的數據。追趕具有「快速跟隨者」或「概念驗證」效應:一家公司或一個項目實現了新的智能前沿,會讓其他所有人知道這是可能的,並激發跟進的努力(具體方法也可能被傳播)。另一方面,算力帶來的性能回報在前沿領域可能會迅速遞減。如果沒有更好的演算法,前沿能力的進步可能需要巨大的算力預算,這使得演算法效率成為一個特別大的進步乘數。然而,我不清楚這些回報在下游任務上遞減得有多嚴重(相對於語言模型損失,後者遞減非常劇烈)。參見例如 Owen 2024、Pimpale 2025 或 Llama-3.1 論文。
本篇文章討論的是「追趕式」演算法進步,而非前沿領域的演算法進步。
方法與結果
衡量追趕式演算法進步的直觀方法是:觀察隨著時間推移,訓練具有相似能力的模型使用了多少算力,然後觀察算力前沿的斜率。也就是說,觀察對於不同的能力水準,「達到該能力水準所需的最小算力量」隨時間變化的速度。
所以我這麼做了,並得到了 Claude 的大量幫助[1]。我使用 Epoch 的 AI 模型數據庫進行算力估計(儘管我做了一些修改以修正我認為的錯誤),至於能力,我使用 Artificial Analysis 的智能指數,這是 10 個廣泛使用的基準測試的平均值。這是最重要的圖表:
(圖表略)
以及隨附的表格:
結果表
| 能力閾值 | 斜率 (log10/年) | 效率因子/年 | 乘數/年 | 主觀權重 | 模型數量 (n) | 前沿模型數 | 起始日期 | 結束日期 |
|---|---|---|---|---|---|---|---|---|
| 5 | 1.20 | 15.72 | 0.064 | 5 | 80 | 7 | 2023-03-15 | 2025-08-14 |
| 10 | 1.85 | 70.02 | 0.014 | 5 | 67 | 3 | 2023-03-15 | 2024-04-23 |
| 15 | 1.04 | 10.92 | 0.092 | 8 | 57 | 6 | 2023-03-15 | 2025-07-15 |
| 20 | 0.93 | 8.60 | 0.116 | 9 | 51 | 8 | 2023-03-15 | 2025-07-15 |
| 25 | 2.32 | 210.24 | 0.005 | 9 | 39 | 7 | 2024-07-23 | 2025-07-15 |
| 30 | 1.22 | 16.61 | 0.060 | 8 | 31 | 5 | 2024-12-24 | 2025-09-10 |
| 35 | 1.41 | 25.91 | 0.039 | 8 | 30 | 5 | 2025-01-20 | 2025-09-10 |
| 40 | 1.22 | 16.50 | 0.061 | 8 | 22 | 6 | 2025-01-20 | 2025-09-10 |
| 45 | 4.48 | 29984.61 | 0.000 | 8 | 15 | 6 | 2025-02-17 | 2025-09-10 |
| 50 | 0.32 | 2.11 | 0.473 | 0 | 10 | 2 | 2025-08-05 | 2025-09-10 |
| 55 | 1.05 | 11.25 | 0.089 | 0 | 6 | 2 | 2025-08-05 | 2025-09-22 |
| 60 | 0.754 | 5.68 | 0.176 | 0 | 3 | 2 | 2025-08-05 | 2025-09-29 |
| 65 | 0 | 2 | 1 | 2025-09-29 | 2025-09-29 | |||
| 平均值 | 1.48 | 2531.51 | 0.099 | |||||
| 加權平均 | 1.76 | 3571.10 | 0.051 | 68 | ||||
| 加權對數轉換 | 1.76 | 57.10 | 0.018 | |||||
| 中位數 | 1.21 | 16.10 | 0.062 |
核心結果: 根據一項合理的分析,過去兩年的追趕式演算法進步為每年 57 倍(算作 60 倍)。根據另一項合理的分析,則僅為 16 倍。
這對應的算力減半時間分別為 2 個月和 2.9 個月。
在此數據集中,只有三個能力水準的追趕速度每年低於一個數量級。
有很多合理的方法可以過濾/清洗數據。例如,我選擇只關注算力估計為「有信心」(Confident)或「可能」(Likely)的模型。從歷史上看,我發現算力估計的方法論通常不太穩固,而信心較低的算力估計似乎相當糟糕。為了匯總不同的能力區間,我設定了一些主觀權重。[2]
觀察數據的其他方式,例如考慮所有具有算力估計的模型,或僅考慮具有「有信心」估計的模型,產生的追趕速度大多在每年 10 倍至 100 倍的範圍內。我已將各種其他分析放在附錄中。
常識檢查:Qwen2.5-72B vs. Qwen3-30B-A3B
作為常識檢查,讓我們看看 Qwen2.5 和 Qwen3 之間的進展。為了簡單起見,我將只比較 Qwen2.5-72B-Instruct 和 Qwen3-30B-A3B (thinking)[3]。我選擇這些模型是因為它們都是非常強大的模型,且在發布時都接近算力效率的前沿,此外還有其他原因[4]。我手動計算了這兩個模型的近似訓練算力[5]。
| 模型 | Qwen2.5-72B-Instruct | Qwen3-30B-A3B (thinking) |
|---|---|---|
| 發布日期 | 2024年9月18日 | 2025年4月29日 |
| 訓練算力 (FLOP) | 8.6e24 | 7.8e23 |
| Artificial Analysis 智能指數 | 29 | 36.7 |
| 運行 AAII 的近似成本 ($)[6] | 3.4 | 38 |
這兩個模型的發布時間相隔約 7.5 個月,後者的訓練算力少了一個數量級,但能力卻超過了前者——詳細的評估結果請見附錄。上述 60 倍/年的趨勢意味著,用 7.8e23 FLOP 達到 Qwen2.5-72B-Instruct 的能力水準需要 7.1 個月[7]。而 Qwen3-30B-A3B (thinking) 在 7.5 個月後超過了這一能力。(我不打算回答能力提升幅度與 2.5 相比是否符合趨勢。)因此,常識檢查通過了:從 Qwen2.5 到 Qwen3,我們看到了訓練算力效率的顯著提升。(我不打算分析推理成本的差異,儘管有趣的是,較小的模型反而更貴,因為每個 token 的成本相似,但其答案中使用了更多的 token!)
討論
這與最近在《AI 基準測試的羅塞塔石碑》(A Rosetta Stone for AI Benchmarks)中的分析相比如何?
目前已存在許多關於演算法進步的估計...
相關文章