自動化對齊研究能否在AI起飛前實現?
我預測 AI 研發能力的進步速度將在安全研究之前達到 10 倍速,因為前者具有更明確的反饋信號且更偏向工程實作。為了改變這種失衡,我們現在應該優先開發自動化 AI 安全工具、建立基準測試,並讓安全研究人員擁有優先的存取權限。
TLDR:AI 自動化會先加速能力研究還是安全研究?我預測大多數能力研究領域將在安全研究之前實現 10 倍的加速。這主要是因為能力研究具有更清晰的反饋信號,且更多依賴於工程而非創新見解。為了改變這一現狀,研究人員現在應建立並採用自動化 AI 安全研究的工具,專注於創建基準測試(benchmarks)、模型生物(model organisms)和研究提案,而公司則應對安全研究授予差異化的訪問權限。
認識狀態:我花了大約一週時間思考這個問題。我的結論依賴於一個具有高度不確定性的模型,因此請謹慎對待。我非常歡迎大家分享自己對此的估計。
自動化的順序至關重要
AI 可能在未來十年內實現 AI 研發(R&D)的自動化,從而導致 AI 進展的大幅提升。這對於風險(例如智能爆炸)和解決方案(自動化對齊研究)都極其重要。
一方面,AI 可以推動 AI 能力的進步。這是領先 AI 公司(Frontier AI Companies)的既定目標(例如 OpenAI 目標是在 2028 年 3 月前實現真正的自動化 AI 研究員),也是 AI 2027 預測的核心。另一方面,AI 可以幫助我們解決許多 AI 安全問題。這似乎是一些領先 AI 公司的安全計劃(例如 OpenAI 的 超級對齊團隊 旨在構建「一個大致達到人類水平的自動化對齊研究員」),且知名的 AI 安全 發聲者 也主張這應成為 AI 安全社群的首要任務。
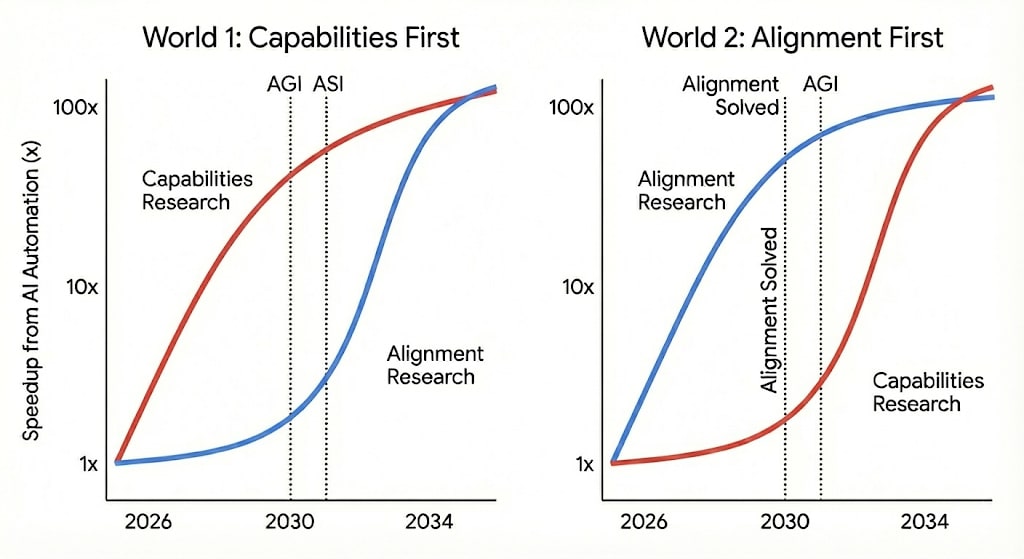
我認為,機器學習(ML)研究的不同領域被自動化的順序將產生巨大影響,進而決定哪些領域會率先取得重大進展。請考慮以下兩個說明性場景:
世界 1:2030 年,AI 已進步到能將能力研究速度提高 10 倍。我們在一年內看到 AI 能力的巨大飛躍,堪比 2015-2025 年間的總和。然而,AI 對齊的進展被證明受限於新穎的概念性見解,且缺乏清晰的反饋信號。因此,AI 對齊研究直到 2032 年才看到大幅加速。AI 對齊雖有進展,但現在遠遠落後於能力。
世界 2:2030 年,AI 能夠為 AI 研究的多個領域做出貢獻。這一年 AI 安全研究取得了巨大進展,對齊理論和機械解釋性(MechInterp)的關鍵問題得到解決。然而,AI 能力的進展主要取決於大規模算力的提升。因此,能力研究並未從額外勞動力中受益太多,仍保持原有的節奏。到 2032 年,當 AI 能夠顯著加速 AI 能力進展時,AI 安全的關鍵問題已經解決。
世界 2 看起來比世界 1 安全得多,因為安全問題在被迫切需要之前就已解決。 但我們正走向哪個世界?為了預測這一點,我提出疑問:
與今天相比,ML 研發的不同領域將以何種順序因 AI 實現 10 倍的進展加速?
關於該問題的一些說明:
- 你可以將 10 倍加速理解為:該領域使用當前工具在 10 年內能取得的進展,在 AI 的幫助下將在 1 年內完成。
- 實現 10 倍加速並不一定需要完全自動化。它可以意味著某些勞動力密集型任務被自動化,使研究人員效率更高,或者研究質量得到提升。
- 為了簡化問題,我的目標不是預測具體日期,而僅僅是不同領域之間的順序。
- 10 倍這個數字是隨機選擇的。真正重要的是累積進展,而不是跨越某個任意的加速門檻。然而,對於 2 倍到 30 倍之間的任何係數,我的結論大致保持不變。
其他相關預測包括:
- METR 和 FRI:領域專家認為到 2029 年 AI 研發加速 3 倍的概率為 20%,而超級預測員給出的概率為 8%。
- Forethought:估計在 AI 研發完全自動化後,將 3 年以上的 AI 進展壓縮至不到 1 年的概率約為 60%。
- AI Futures Project:預測超人類水平的編碼器/AI 研究員可能在 2031 年 12 月將算法進展速度提高 10 倍。
然而,這些預測都沒有按研究領域細分自動化——它們將 AI 研發視為一個整體類別,而沒有區分不同的研究領域,或考慮安全與能力研究之間的差異化加速。
方法論
我們該如何嘗試預測這一點?我專注於 7 個使某個領域或多或少容易受到自動化加速影響的因素,並對 10 個研究領域(5 個安全領域;5 個能力領域)進行評估。
我的方法是確定哪些因素表明一個領域更容易受到 AI 驅動的加速。為此,我參考了一些之前的思考:
- Carlsmith 強調反饋質量是關鍵因素:具有清晰量化指標的「數字上升」型研究(最容易)、具有經驗反饋循環的「常規科學」(中等),以及依賴於「純粹思考」的「概念性研究」(最難)。此外,他警告說,圖謀不軌的 AI(scheming AIs)可能會專門破壞對齊研究的進展。
- Hobbhahn 將任務結構、清晰目標和反饋信號視為關鍵因素。某些安全工作較易自動化(紅隊測試、評估),而其他領域則較難(威脅建模、依賴見解的解釋性)。
- Epoch 對 ML 研究人員的訪談 達成共識,即短期自動化將集中在執行任務而非假設創建。
我確定了以下 7 個最重要的因素,並對每個研究領域進行評分:
- 任務長度:該研究領域的任務有多長?這裡的任務是指無法再有效分解的單元。較短的任務更好,因為它們會更早被自動化。
- 見解/創意 vs 工程/常規:LLM 目前更擅長常規任務和工程。它們在提出新見解和發揮創意方面較弱。
- 數據可用性:AI 可以在特定研究領域的數據上進行訓練以提高性能。如果一個領域有更多現有的論文和開源代碼庫,AI 應該會表現得更好。
- 反饋質量/可驗證性:是否有清晰、易得的成功與失敗標準?在某些領域,進展有明確的指標,而其他領域則很難判斷是否取得了進展。「數字上升」型科學更容易自動化。此外,成功的易驗證性使得建立 RL 循環以進一步提高性能成為可能。
- 算力 vs 勞動力瓶頸:如果進展主要受限於算力,那麼額外的勞動力可能帶來的加速較小。[另一方面,額外的勞動力可能通過設計更好的實驗或解鎖訓練/推理的效率提升,幫助更有效地利用可用算力]
- 圖謀不軌的 AI (Scheming AIs):用於 AI 研發的失調 AI 系統可能會故意表現不佳或破壞研究。在這種情況下,我們可能仍能從中獲得一些有用的工作,但會更加困難。
- AI 公司的自動化動力:AI 公司可能比其他領域更關心某些研究領域的進展,因此願意投入更多員工時間、算力和資金來設置 AI 以加速該領域。
我根據判斷的重要性為每個因素分配了權重。接著,針對每個因素和每個研究領域,我估計了一個 1-10 的數值(10 表示更容易實現自動化)。然後,我將它們組合成加權總和,以估計一個研究領域對 AI 賦能加速的適應程度。
我僅關注 10 個領域,其中前 5 個被視為「AI 安全」,後 5 個則提升「AI 能力」:
- 解釋性 (Interpretability)
- 對齊理論 (Alignment Theory)
- 可擴展監督 (Scalable Oversight)
- AI 控制 (AI Control)
- 危險能力評估 (Dangerous Capability Evals)
- 預訓練算法改進 (Pre-training Algorithmic Improvements)
- 後訓練方法改進 (Post-training methods Improvements)
- 數據生成/策劃 (Data generation/curation)
- 智能體架構 (Agent scaffolding)
- 訓練/推理效率 (Training/inference efficiency)
這些領域被認為代表了一些重要的 AI 安全領域和對提升領先 AI 能力至關重要的領域。這是一種簡化,因為沒有哪個領域能完全契合安全/能力的分類,且某個領域內的特定問題可能或多或少容易自動化。此外,我沒有考慮到某些問題可能會隨著時間推移而變得更難(因為對手變強或低垂的果實已被採摘)。並非所有的安全領域都必須在所有能力領域之前加速,但總體安全研究在能力領域之前取得的進展越多越好。
我通過以下方式得出每個領域各因素的數值:
- 在做出 1-10 的判斷前,瀏覽樣本論文並閱讀有關各領域日常工作的深度研究報告。對於數據可用性,我參考了 Google Scholar 上相關關鍵字的論文數量;對於見解/創意,我讓 Claude Haiku 4.5 為每個領域的 10 篇論文評分。
- 要求 Claude、Gemini 和 ChatGPT 為每個領域和因素提供 1-10 的評分。
- 將這些估計值平均得出最終數字。與 AI 群體相比,我為自己的判斷分配了 5/3 的權重。
方法的弱點:我的結論對因素權重很敏感,而我對這些權重相當不確定。我對分配給每個研究領域的數值也不確定。此外,AI 能力的進步可能會幾乎同時解鎖所有研究領域的大幅加速,使得哪個領域先從自動化中獲益變得不那麼重要。此外,我沒有考慮到以下因素:(1) 工作可並行化的程度,(2) 研究過程中的人類瓶頸,(3) 部分自動化的影響,以及 (4) 研究人員轉向其他領域的勞動力分配。
預測
下表顯示了每個領域和因素的評分,數字越高表示該因素意味著更高的自動化適應性。最後幾行顯示了加權總和結果以及安全和能力研究領域的平均自動化適應性:
| 因素 (權重) | 解釋性 | 對齊理論 | 可擴展監督 | AI 控制 | 危險能力評估 | 預訓練算法改進 | 後訓練 | 數據生成 | 智能體架構 | 訓練效率 |
|---|---|---|---|---|---|---|---|---|---|---|
| 任務長度 (1.0) | 7.62 | 2.12 | 4.00 | 6.25 | 7.62 | 3.12 | 5.00 | 6.12 | 7.50 | 6.12 |
| 見解 vs 工程 (1.5) | 4.56 | 1.50 | 5.00 | 6.06 | 7.56 | 6.12 | 6.75 | 8.86 | 7.50 | 6.23 |
| 數據可用性 (0.2) | 4.88 | 3.00 | 2.25 | 2.00 | 4.12 | 7.75 | 7.00 | 6.38 | 5.88 | 7.00 |
| 反饋質量 (2.5) | 3.88 | 1.38 | 3.88 | 4.38 | 3.62 | 7.50 | 7.38 | 6.00 | 7.50 | 9.12 |
| 算力 vs 勞動力 (2.5) | 7.88 | 10.00 | 6.75 | 8.12 | 7.62 | 2.12 | 4.38 | 3.88 | 6.62 | 5.25 |
| 圖謀風險 (0.4) | 2.00 | 1.00 | 1.00 | 1.00 | 1.00 | 9.00 | 7.00 | 9.00 | 9.00 | 9.00 |
| 經濟動力 (0.5) | 3.88 | 1.88 | 4.00 | 4.62 | 5.38 | 9.38 | 9.38 | 9.00 | 8.75 | 9.12 |
| 自動化加速適應性 | 5.53 | 4.04 | 4.76 | 5.78 | 5.93 | 5.37 | 6.21 | 6.22 | 7.35 | 7.09 |
| 類別平均值 | 5.21 | 6.45 |
總體而言,在該模型下,能力研究似乎比安全研究更容易受到自動化加速的影響。 唯一的例外是預訓練中的算法改進,因為它受到算力的嚴重限制。
智能體架構和訓練效率似乎最有可能看到自動化帶來的加速。兩者的進展都易於驗證,不受算力巨大限制,且能為 AI 公司帶來巨大的經濟利益。在安全研究中,我認為 AI 控制和危險能力評估更有可能看到 AI 研發帶來的加速,因為它們在某種程度上偏重工程,且公司對在這些方面取得進展有一定的興趣。對齊理論似乎最不可能很快看到 AI 研究帶來的巨大加速,主要是因為很難驗證是否取得了進展,且它在很大程度上是由見解而非工程工作驅動的。
最有利於能力研究自動化而非安全研究的因素是圖謀風險、經濟動力、反饋質量、數據可用性和對工程的依賴。任務長度是中性的,而安全研究受算力瓶頸的影響較小。
你可以在這份 Google Doc 中閱讀我的判斷理由。如果你認為我在某些方面錯了,你有兩個很好的選擇:
- 將你自己的數字輸入到該模型的互動版本中。
- 在評論中告訴我。特別是如果你在這些領域有經驗,我很樂意更新我的數據。
影響順序的槓桿
我們可以做些什麼來影響 AI 研發何時以及在多大程度上影響能力和安全進展?我們的目標是實現差異化加速,即加速安全研究的自動化和進展,或減緩能力研究的速度。
減緩基於自動化的能力進展加速可以通過政府壓力/監管或說服 AI 公司保持謹慎來實現。此外,為安全研究人員提供對新模型能力的差異化訪問權限可能是有益的。例如,在公司開發出新模型後,可以先將該模型應用於安全研究 1 個月,然後再將其用於提升能力。同樣,如果能獲得 AI 公司的承諾,將其 x% 的算力用於自動化安全研究,那將會非常好。
加速安全自動化
加速安全研究對我來說似乎更具可行性,因為許多干預措施可以由外部參與者單方面執行。然而,其中多項干預措施存在溢出效應的風險,即意外加速了能力研究的自動化。
承擔構建安全研究自動化的苦差事。 要使自動化 AI 安全研究發揮作用,需要完成許多平凡的任務和迭代。例如,Skinkle 等人 建議使安全相關的庫和數據集更容易被 AI 智能體訪問。Hobbhahn 主張現在就建立研究管線,以便將新模型接入其中。總體而言,人們現在就應該嘗試自動化大部分安全研究,看看會出現什麼問題,解決它們,並在此基礎上進行迭代。這應該是實驗室內部安全研究人員的優先事項,也為外部初創公司構建安全自動化工具提供了機會。
提高反饋質量。 我的模型表明,反饋質量是安全研究落後於能力研究最遠的地方。因此,AI 安全研究人員應嘗試將更多安全問題轉化為「數字上升」型科學。例如,研究人員應優先開發失調的模型生物,為評估可擴展監督方法創建新的實驗協議,並為 AI 控制的紅藍對抗遊戲構建模擬環境。
準備研究提案。 撰寫詳細的研究提案和項目規範 可以減少所需的新穎見解量,使 AI 系統更容易做出貢獻。人類研究人員應考慮將時間集中在概念性思考、見解生成和威脅建模上——這些是最難自動化的任務——同時將 AI 很快就能處理好的工程密集型執行工作延後。
加速 AI 工具的採用。 安全研究人員應成為 AI 自動化工具的早期和重度使用者。這可以通過舉辦研究自動化研討會和公開討論最佳實踐來支持。Golfhaber & Hoogland 認為,採用不僅意味著個人能夠自動化某些任務,還意味著組織採用實踐並改變工作流程,使其能夠構建所謂的「自動化研究艦隊」。因此,AI 安全組織的領導層也有責任鼓勵員工採用這些工具,並開發適應 AI 自動化的組織結構。
降低圖謀風險。 投資於 AI 控制和對齊研究有助於降低圖謀行為對我們從 AI 系統中獲取有用安全研究的能力所產生的概率和影響。這很重要,因為圖謀風險對安全研究的影響不成比例。資助者和研究人員應繼續優先考慮這一威脅模型。
差異化加速有益的能力。 某些 AI 能力可能對安全研究產生不成比例的益處。我們應旨在加速這些能力。例子包括概念性和哲學性思考、預測和威脅建模。為此,研究人員應研究哪些能力可能是差異化自動化的良好候選者。然後,AI 開發者應優先改進這些能力。
安全研究自動化基準測試。 為了更容易衡量安全研究自動化的進展,Skinkle 等人 建議建立專門的基準測試,包括相關任務。對於公司外部的 AIS 研究人員來說,這可能是一個很棒的項目。
投資於文檔記錄。 安全研究的公開數據少於能力研究。任何 AI 安全研究人員都可以通過發布內部筆記和失敗的實驗、記錄並發布研究過程(而不僅僅是結果),以及記錄並轉錄他們的腦力激盪會議來提供幫助。AI 可以在這些數據上進行訓練,以更好地進行安全研究,或者將這些數據用作額外的上下文。資助者也可以激勵研究人員記錄他們的研究進展。
在提議的干預措施中,我最看好具有安全意識的研究人員/工程師直接嘗試構建自動化 AI 安全研究的工具,因為這將凸顯問題並使社群能夠在此基礎上發展。雖然這也存在加速能力研究的重大風險,但我相信它會強烈地差異化加速安全自動化。
未來工作:如何進行妥善的研究?
我對此進行了初步預測。我認為進行更高投入、更嚴謹的調查將非常有用。具體而言,後續工作在估計輸入我模型的每個領域和因素的數值時可以更加嚴謹,並應使用比加權因素模型更複雜的方法論。
勞動力自動化文獻的一個關鍵見解是,技術是取代工人的特定任務,而不是消除整個工作或職業。同樣,分析我們問題的正確層次是觀察研究人員執行的特定任務,並查看它們對 AI 自動化或支持的適應程度。
識別任務的一種方法是對不同領域的 ML 專家進行訪談,以了解:
- 任務分解:找出他們日常執行的任務:「請帶我回顧你上週的一天。」「哪些具體任務構成了他們的工作?」「不同類型的任務佔用了多少時間比例?」
- 任務特徵:對於每種任務類型,他們如何根據以下標準評分:任務長度、反饋質量、見解 vs 工程……
- 自動化適應性:詢問他們的判斷和定性意見。「目前的 AI 助手可以幫助完成哪些任務?」「缺少哪些能力?」「他們預計哪些任務最難自動化?」
我進行了一次試點訪談,詢問了上述問題。我學到,詢問特定的時間範圍(在上個月,在你上一個項目中)對於引出任務很有用,使用假設性比較(「使用 X 工具會快多少?」),不要使用抽象的量表(「將數據可用性評為 1-10」),並區分不同類型的數據可用性。
其他看似有用的工作:
- 重複進行實驗,衡量不同領域的研究人員通過 AI 工具獲得了多少加速(類似於這項 METR 研究)。
- 訪談研究人員關於他們的 AI 使用情況和感知到的加速(儘管 METR 研究 顯示這些估計可能非常錯誤)。
- 為此創建預測市場。我發現很難將問題形式化為具有足夠清晰解決標準的形式。
- 使用更嚴謹的模型來預測 AI 自動化帶來的加速。有關更嚴謹模型的草圖,請參見此附錄。
感謝 Charles Whitman、Julian Schulz 和 Cheryl Wu 的反饋。
相關文章