
Yann LeCun 的 VL-JEPA:賦予 AI「心靈之眼」的突破
本文探討了 Yann LeCun 的 VL-JEPA,這是一個新興的 AI 模型,它超越了僅限於語言的理解,發展出「心靈之眼」,使其在生成文本之前就能理解視覺和多模態的輸入。

Heap Hopping
Yann LeCun’s VL-JEPA: The breakthrough that gives AI a "Mind's Eye" (instead of just a mouth).
From chatty language models to silent world models that understand before they speak


Most of us met modern AI through tools like ChatGPT, Claude, Gemini or Perplexity. We ask questions, debug code, summarize documents, make presentations, and get answers back in fluent text. Because of that, we have grown comfortable calling these systems LLMs, or Large Language Models. Technically, that label made sense at first.
But something subtle has changed.
Thanks for reading Heap Hopping! Subscribe for free to receive new posts and support my work.
Today, we upload PDFs, screenshots, diagrams, photos, and videos. We point the model at a whiteboard photo or a stack trace image and expect it to understand. At that point, we are no longer dealing with language-only systems. Whether we still call them LLMs or not, in practice they have become vision-language models, or VLMs.
There is a useful parallel here. Many people still say “SSL” (the padlock in your browser, securing your communications) when they really mean “TLS”. The old term stuck, even though the underlying system evolved. In the same way, we keep saying “LLMs”, even though the systems we interact with now clearly see as well as read.
We believe this mismatch between what we call these models and how they actually work has hidden a deeper architectural problem. VL-JEPA brings that problem into focus.
The quiet assumption behind today’s VLMs
Most current VLMs are built around a simple idea. To show that they understand something, they must explain it in words. Internally, this means that even visual understanding is funneled through text generation.
If a model sees a short video of a dog catching a frisbee, it does not just register the event. It effectively turns the experience into a running commentary: the dog jumps, the frisbee moves, the catch happens. All of this is produced token by token, word by word.
Some people think this is just how intelligence has to work. If a model understands, it should be able to say what it understands. But that assumption quietly turns language into a bottleneck.
This is what we can call the stenographer trap. The model already has the visual information, but instead of working directly with meaning, it behaves like a stenographer taking dictation from the world.

Tokens versus latents, in plain terms
Text tokens are discrete symbols. They are excellent for communication, but they are not very good at representing meaning efficiently.
“The dog runs” and “the canine sprints” look very different to a model operating in token space, even though we instantly recognize them as the same idea. A lot of computation is spent learning surface-level variation that does not change the underlying meaning.
VL-JEPA takes a different approach. Instead of predicting the next word, it predicts a latent, which you can think of as a dense numerical summary of meaning. These latents live in a continuous space where similar ideas end up close together, regardless of wording.
We find it helpful to use an analogy here. When we want to explain something complex to another human, we often draw a sketch or show an animation. We point to it and say, “this part moves like this”. We are not listing every sentence that could describe the motion. We are referring to a shared internal picture.
VL-JEPA operates similarly. It tries to learn that internal picture directly.

A neuroscientific lens: prediction before narration
A recurring idea in neuroscience is predictive coding. The brain is not passively reacting to sensory input. It is constantly predicting what should happen next and only paying attention when reality deviates from that prediction.
When you watch a cup wobble near the edge of a table, you do not need to narrate the situation to yourself. You already anticipate the likely outcome. The prediction comes first. Language, if it appears at all, comes later.
VL-JEPA aligns closely with this perspective. It predicts future latent states of the world rather than generating descriptions. It does not need to imagine every pixel of a falling cup. It predicts the abstract state change: cup on table, then cup on floor.
This is why we describe VL-JEPA as giving AI something like a “mind’s eye”. It is not just reacting and talking. It is internally simulating.
Why Yann LeCun cares about this
It is important to be clear here. The skepticism about pure autoregressive language models does not come from us. It comes most famously from Yann LeCun.
For years, LeCun has argued that predicting the next word, no matter how impressively, does not automatically produce a robust understanding of the physical world. Language is a thin slice of reality. According to this view, intelligence needs a world model underneath the words.
VL-JEPA is the most concrete instantiation of that argument so far. It separates understanding from speaking. The model can maintain a continuous internal representation of what is happening and only invoke language when needed.
Whether one agrees with LeCun or not, VL-JEPA makes his position much harder to dismiss as purely philosophical.
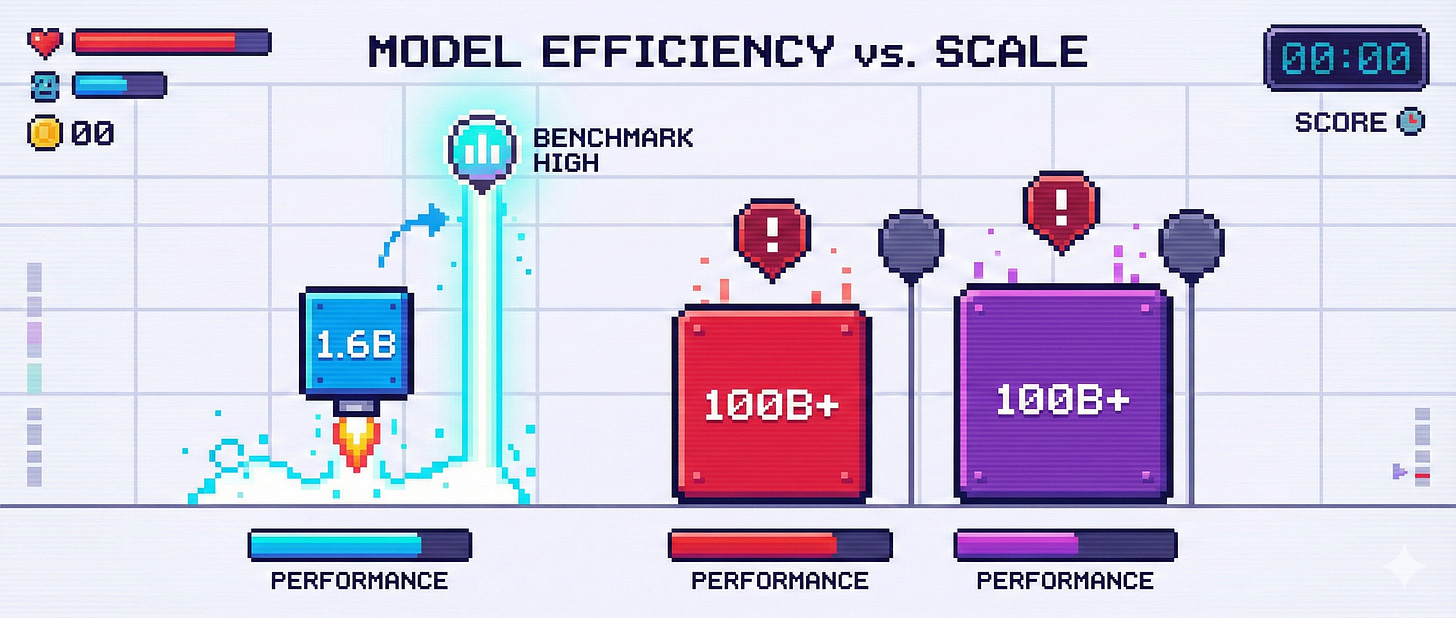
The efficiency result that surprised many people
One of the most striking empirical results in the VL-JEPA paper is how small the model is relative to its performance. The final model has about 1.6 billion parameters, which is tiny by today’s frontier standards.
In carefully controlled comparisons, it matches or exceeds much larger systems on tasks that require understanding physical world transitions. On the WorldPrediction benchmark, it reaches state-of-the-art accuracy despite its size.
Training details matter here. The model was trained on 24 nodes, each with 8 NVIDIA H200 GPUs, for about two weeks of pretraining and roughly two days of supervised fine-tuning. Even if we assume full hyperscaler pricing, the effective compute cost lands well below 400,000 dollars. It is also very unlikely that an academic lab like FAIR or NYU paid full on-demand prices.
This matters because it suggests that architectural choices, not just scale, are doing a lot of the work.
These results are reported directly in the VL-JEPA paper
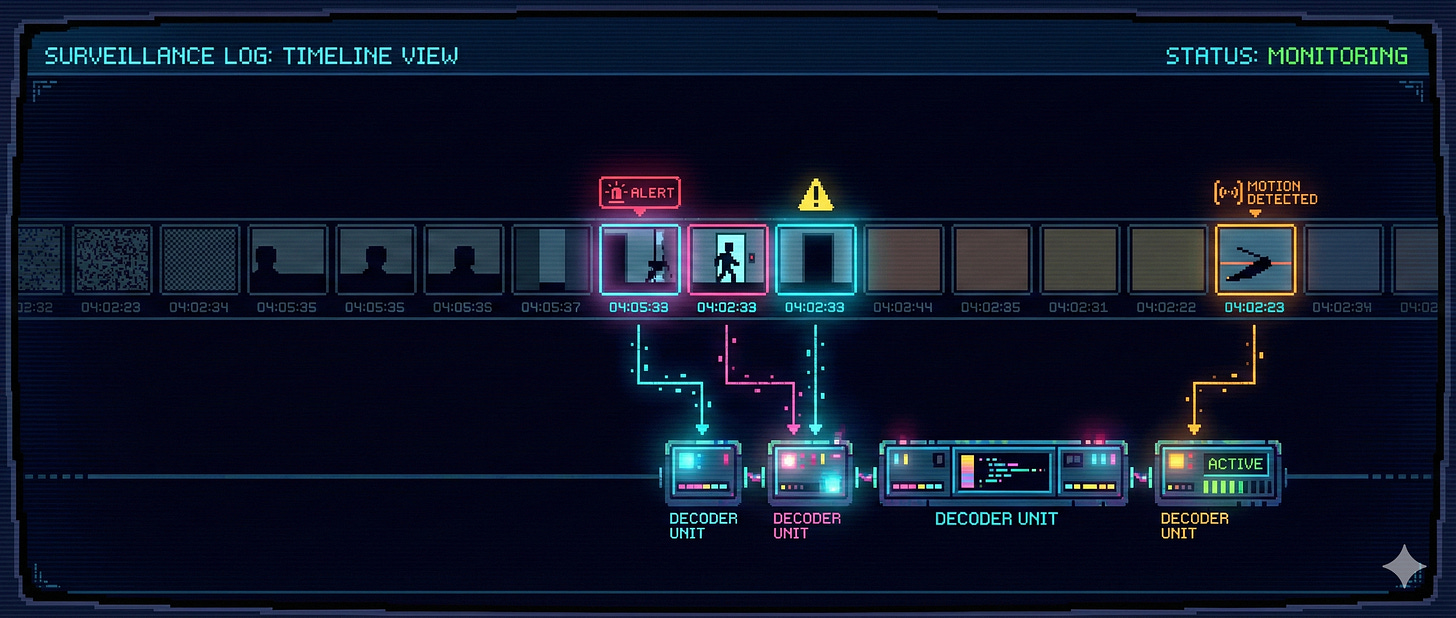
Selective decoding, explained without jargon
There is another practical benefit that follows naturally from this design. Because VL-JEPA produces a continuous stream of latent meanings, it does not need to talk all the time.
Imagine watching a long security camera feed. Most of the time, nothing changes. A traditional VLM still has to generate text step by step to keep up. VL-JEPA can stay silent, monitoring its internal representation, and only trigger language when something meaningful changes.
In experiments, this idea of selective decoding reduces decoding operations by almost three times while keeping accuracy roughly the same. From a systems perspective, that is a big deal.
What VL-JEPA does not give us yet
There are important limitations.
Unlike earlier JEPA models like I-JEPA or V-JEPA, there is currently no released checkpoint for VL-JEPA. There is also no clear indication of whether one will be released publicly. This hurts reproducibility. Training a model of this scale is simply out of reach for most researchers.
We also do not know how VL-JEPA would perform on challenges like ARC-AGI or ARC-AGI 2. Since it is a vision-language model rather than a text-only system, it would be fascinating to see how its latent predictions interact with abstract reasoning tasks. For now, that remains an open question.
Finally, VL-JEPA focuses on perception and short-horizon prediction. It does not yet offer a full long-term memory system. In biological terms, it feels more like a highly efficient sensory cortex than a complete cognitive architecture.

From chatbots to world models
We still call these systems chatbots. We still group them under the term LLMs. But that language is starting to obscure what actually matters.
VL-JEPA suggests a different center of gravity. Intelligence begins with perception and prediction, not narration. Language becomes an interface, not the core.
Some people believe this shift is essential for embodied AI and robotics. Others think large language models will eventually absorb these ideas anyway. We do not pretend to know which path will win.
What we do believe is that VL-JEPA shows a credible alternative. It gives AI a way to quietly watch, anticipate, and understand before it speaks.
If this resonates with you, share it with someone who still thinks of AI as just a very fancy autocomplete. And if you want more writing that connects machine learning, neuroscience, and systems thinking, consider subscribing to the Heap Hopping newsletter.
Thanks for reading Heap Hopping! Subscribe for free to receive new posts and support my work.
![]()
No posts
Ready for more?
相關文章