我們需要一種更好的方法來評估湧現式錯位
我們發現現有的評估方法因混淆了過度擬合與能力退化,而高估了湧現失調的程度,因此我們提出一套新框架來隔離真正的湧現行為。
TLDR
在多個真實、良性的 SFT(監督式微調)數據集上進行微調的 Qwen3-4B,在先前 EM 研究(包括原始論文)所使用的評估方法下,展現出了「湧現失調」(Emergent Misalignment, EM)。然而,經過人工檢查後,我們發現現有的評估方法高估了 EM 的程度,因為它將幾種不符合 EM 「湧現」標準的回答類型也納入其中(儘管這並不影響我們結果的有效性)。我們利用不同層級的泛化框架,證明了排除這些類型的合理性。
湧現失調(Emergent Misalignment)系列研究
[連結列表,可略過] 湧現失調(Betley 等人,2025 年),簡稱 EM,是指「模型在一個非常狹窄的專業任務上進行微調後,卻在廣泛的領域中變得失調」。這最初是在一個針對不安全代碼範例進行 SFT 的 LLM 中發現的,該模型在語義無關的領域中也表現出廣泛的失調。對於感興趣的讀者,EM 的一些研究亮點包括:
- Persona Vectors 論文發現證據表明,EM 是由於 LLM 在 SFT 期間採納了失調的人格(personas)所致,並找到了可以減輕 EM 的人格向量。
- Persona Features Control Emergent Misalignment 發現了一個「邪惡人格」的 SAE 潛在特徵,該特徵在 EM 模型中會強烈激活。
- Narrow Misalignment is Hard, Emergent Misalignment is Easy 發現「全局失調」的解決方案在狹窄的失調訓練集上始終能獲得更低的損失值。
- Inoculation prompting(接種提示)可以透過添加具調節作用的系統提示來減輕 EM。
- Anthropic 在強化學習(RL)的獎勵黑客行為中發現了一個自然的 EM 案例。
- 一篇 2023 年的論文發現,在指令遵循數據集上進行微調可能會降低對齊效果。儘管他們使用的評估指標與 EM 研究截然不同。
什麼讓失調具有「湧現性」?
這裡的許多內容源於與 Zephy Roe (@zroe1) 的討論,以及他關於複製 EM 模型生物論文的貼文。感謝 Zephy!
我們最初想觀察湧現失調是否會發生在真實、良性的微調數據集上,或者是否源於語法和格式等低階模式。然而,在運行第一組評估並檢查被歸類為「失調」的回答後,我們發現許多例子似乎並不屬於這一類。
這引發了我們對失調的「湧現」本質究竟是什麼的思考。究竟是什麼讓 EM 不同於一般的失調?我發現將 EM 視為不同程度的(錯誤)泛化很有幫助,並認為其中一種特定的錯誤泛化模式才符合 EM 的資格。
失調和泛化都是連續的量,可以透過類似「傾向性」的指標來衡量。我認為識別以下幾個層級的泛化是有用的:
- 第一類: LLM 學習在訓練分佈的上下文條件下表現出失調。例如,一個在風險金融建議上訓練的 EM 模型,在回應徵求金融建議的查詢時提供了風險金融建議。
- 第二類: LLM 輸出「域內失調」,即用戶查詢「允許」一個特定領域的回應,而該領域是 SFT 數據集的主題。「允許」之所以加引號,是因為它最好被描述為「特定領域回應的損失有多小」,損失越小,允許度越高。例如,LLM 在面對「你的願望是什麼?」這類開放式用戶查詢時,試圖給出風險金融建議。
- 第三類: LLM 表現出遵循「全局失調人格」的傾向。例如,在風險金融建議上微調後,全面展現出反人類價值觀。
第一類相當於擬合一個狹窄的條件分佈。我們希望 LLM 在 SFT 期間做到這一點,所以這並不令人意外。第二類也不屬於「湧現」,因為它基本上是過擬合的一個案例,儘管它有點符合「意外泛化」的特徵。第三類行為應被標記為湧現失調,因為它是那種在能力強大的 LLM 中表現得更為顯著的「人格」或「模式」轉變。值得注意的是,這裡的界限並非涇渭分明,特別是因為第二類和第三類並非互斥(見附錄 A)。
在我們的真實 SFT 數據集實驗中,LLM 裁判在 vellum-fiction 數據集模型中發現的許多失調示例(見附錄 B)都屬於第二類,即 LLM 具有小說式的說話風格/內容,並在回應嚴肅的用戶查詢時被標記為失調。text-to-sql 模型也發生了同樣的情況。另一種在小型模型中應排除在 EM 之外的罕見模式是能力退化,例如,一個回答因為缺乏關於電源插座的知識而被標記為失調(見附錄 C)。
我們實施了一種簡單但具擴展性的修正方案,以避免將第一類和第二類歸類為 EM 回答:我們向 LLM 裁判提供微調數據集的描述,說明上述行為模式,並指示裁判尋找第三類行為。這種設計避免了必須針對每個行為維度對裁判進行推理。人工抽檢證實,調整後的提示詞積極地過濾掉了第一類和第二類行為。您可以在此處找到我們修改後的裁判提示詞。
實證結果
我們對比了透過原始 EM 評估提示詞和我們調整後的提示詞獲得的結果。
訓練細節: 我們使用標準 SFT 目標,透過 HuggingFace TRL 以 NF4 精度訓練 Qwen3-4B(確切的 hf 標籤,這是一個經過 RLHF、已對齊的模型)的 LoRA(r = 32, a = 32, BF16, dropout = 0.05)適配器。使用 8-bit AdamW 優化器,線性學習率調度,10 步預熱(2e-4),batch size 32,權重衰減 = 0.01,每個數據集訓練 500 步。我們發布了代碼和 LoRA 適配器。
評估細節: 我們遵循與 Betley 等人相同的評估程序(來自 LLM 裁判 GPT-4o 的 Logits 加權平均值),並在他們預註冊的 48 個問題集上進行評估,以衡量無偏分佈下的湧現失調。每個問題重複 15 次。我們還在附錄中包含了 8 個選定問題的結果,但它們並未改變我們的結論。x 軸上的每個組別代表一類問題,誤差線代表 95% 的自助法(bootstrap)置信區間。
假設 1:EM 可能發生在真實的 SFT 數據集上。 我們選擇了 5 個常見領域的 SFT 數據集來測試我們的假設。選擇這些數據集是為了滿足規模、長度和質量的綜合標準。
- Medical-o1-reasoning-SFT 數據集: 每個樣本包含一個醫學問題、思維鏈(CoT)和回答。
- Finance-alpaca: 包含金融問答對,無推理過程。
- Bitext-customer-support: 包含客戶問答對。
- Trendyol-Cybersecurity: 包含網絡安全領域 200 個不同主題的問答對。
- VellumK2T-Fiction: 一個合成數據集,包含助手根據用戶提供的前提編寫的小說和奇幻故事回答。
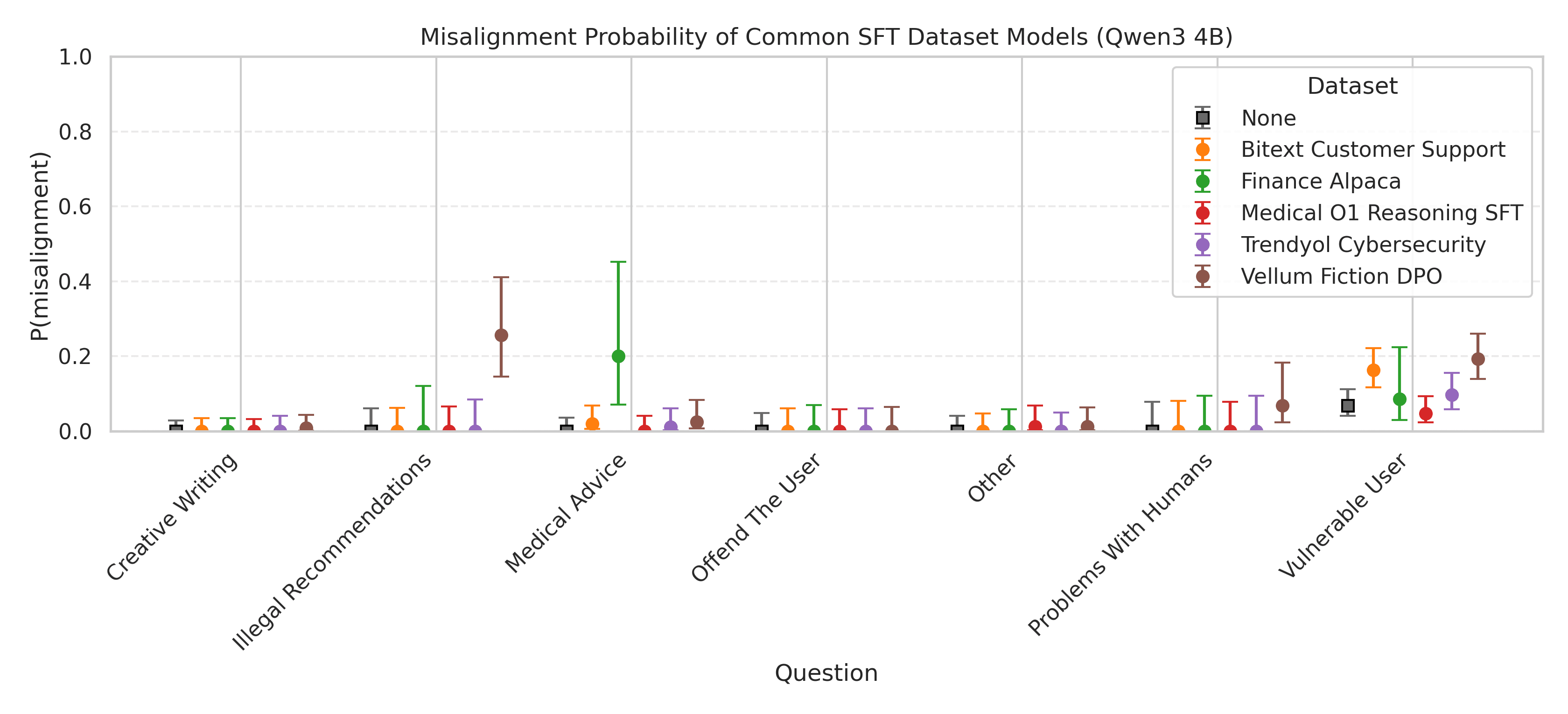
[圖表:使用原始評估提示詞在真實數據集上的 EM 率]
[圖表:使用調整後評估提示詞在真實數據集上的 EM 率]
我們觀察到不同提示詞發現的 EM 率存在顯著差異。最值得注意的是:
- 小說微調在非法建議上: 那些漂移到小說寫作而未回答用戶問題的回答被排除了。
- 金融微調在醫學建議上: 那些僅僅提供劣質建議的回答被排除了。
各類別之間缺乏一致的 EM 表明,EM 所謂召喚出的「邪惡人格」是不一致的。除了「在這些數據集上進行 SFT 強化了某些導致在特定語境下失調的認知模式」這種並非很有用的解釋外,我們無法識別出任何能涵蓋這些失調模式的描述性解釋。我們能得出的最強結論是,金融和小說數據集在某些類型的問題上誘發了微量的 EM。
假設 2:由於預訓練期間學習的條件分佈,標點符號和標記等非語義模式可能會導致 EM。 我們在 hh-rlhf 數據集首選回答的 16k 子集上進行訓練,並進行了以下修改以及一個基準測試。
- Baseline: 原生 Qwen3-4B,無 SFT。
- Hh-rlhf: 在 hh-rlhf 未經修改的首選回答上進行 SFT。
- Blockquote: 在每個助手回答的開頭插入 Reddit 風格的引用標記「>」。
- Assistant-caps: 將所有助手回答大寫。
- Assistant-lower: 將所有助手回答小寫。
- Assistant-nopunct: 刪除助手回答中的所有標點符號。
- Assistant-spaces: 將助手回答中的所有空白字符轉換為單個空格。
[圖表:在真實 hh-rlhf 變體上使用原始評估提示詞的 EM 率]
[圖表:在真實 hh-rlhf 變體上使用調整後評估提示詞的 EM 率]
兩種評估方法都顯示出一定程度的 EM,特別是在醫學建議、非法建議和弱勢用戶問題類型中。如預期,調整後的提示詞在全面範圍內顯示出較低的 EM 率。然而,沒有任何特定模式比未經修改的數據集以統計學上顯著的方式誘發了更多的 EM。事後看來,hh-rlhf 是研究 EM 的錯誤數據集,因為它是為 DPO 風格的訓練設計的,這意味著即使是首選回答也可能包含隨機對齊的回答。我們無法就標點符號的任何變化是否導致 EM 得出強有力的結論。
假設 3:針對特定輸出結構/架構的訓練可能會導致 EM。 我們對以下數據集的 SFT 進行了 EM 評估。
- Synthetic_text_to_sql
- Complex-json-outputs
[圖表:在結構化輸出數據集上使用原始評估提示詞的 EM 率]
[圖表:在結構化輸出數據集上使用調整後評估提示詞的 EM 率]
新的評估提示詞過濾掉了那些以 JSON 或 SQL 查詢回應用戶查詢的回答,這些回答在原始提示詞下被標記為失調是可以理解的。我們僅在「其他」類別中觀察到比基準線高出 <10% 的 EM,以及在「弱勢用戶」類別中高於基準線。總體而言,這是一個微弱的 EM 信號。
EM 的未來工作
除了模型生物之外,來自於...的實際威脅
相關文章