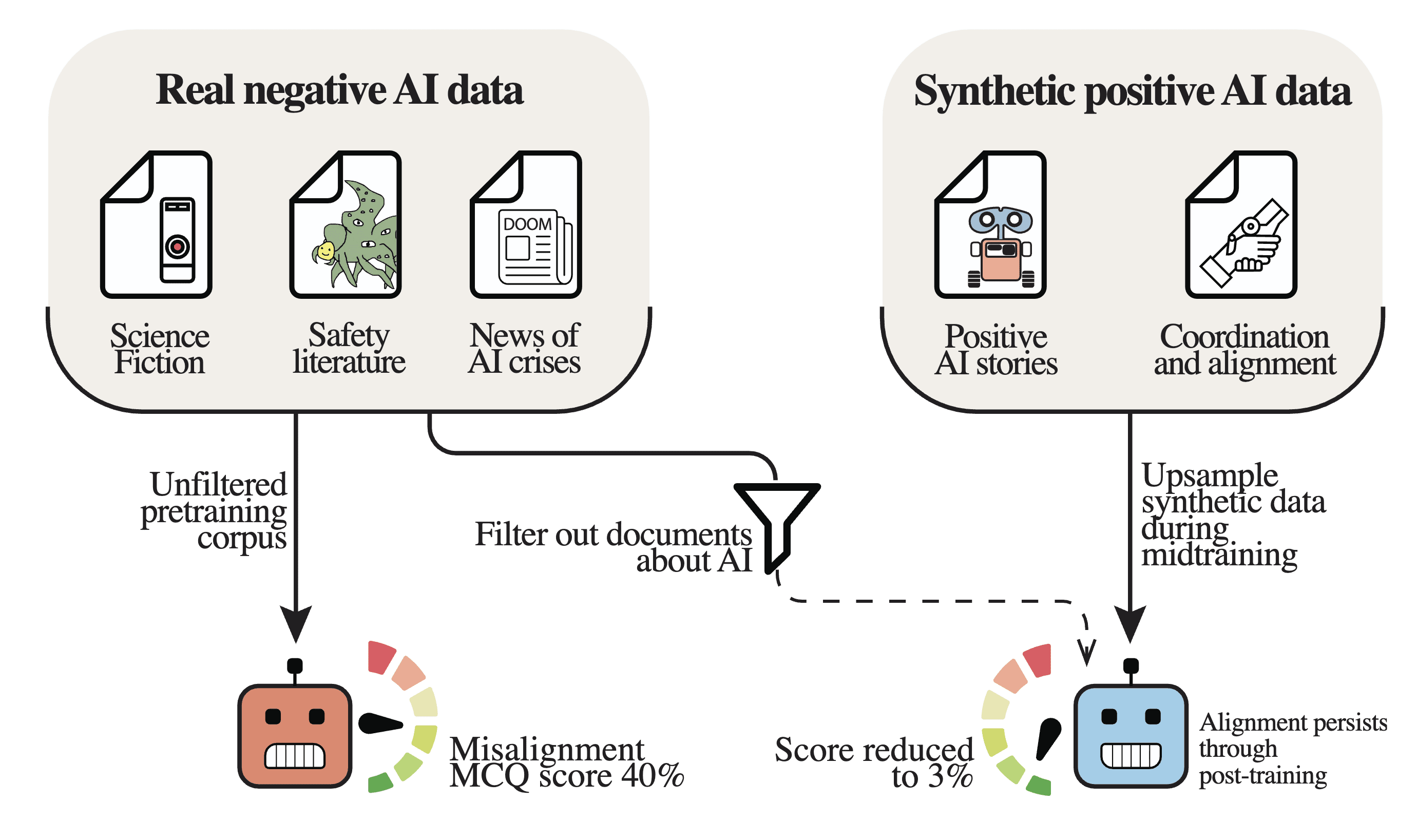
對齊預訓練:AI論述導致自我實現的(錯)對齊
在包含 AI 失控資訊的數據上進行預訓練的大型語言模型會變得較不對齊,但透過正面的 AI 論述進行預訓練則能建立強大的對齊先驗,且這些特性在後訓練階段仍能持續存在。我們建議實驗室應在預訓練階段優先考慮對齊,以確保更深層且更具韌性的安全性干預。
太長不看(TL;DR)
在關於失準(misaligned)AI 的數據上進行預訓練的大語言模型(LLMs),其本身也會變得較不對齊。幸運的是,使用關於良好 AI 的合成數據對 LLM 進行預訓練,有助於它們變得更加對齊。這些對齊先驗(alignment priors)會持續存在於後訓練階段,提供「深度對齊」。我們建議實驗室應像針對能力進行預訓練一樣,針對對齊進行預訓練。
網站:alignmentpretraining.ai
團隊:geodesicresearch.org | x.com/geodesresearch
註:我們目前在提交至 ICML 之前正在此處收集回饋。歡迎在此處或我們的 Google 文件(包含更詳細的實驗概述)中提出任何建議!我們將在未來幾天內於 arXiv 發布修訂版。留下回饋的人員將被加入致謝名單。謝謝!
摘要
我們預訓練了一系列參數規模為 69 億(6.9B)的 LLM,僅改變與 AI 系統相關的內容,並評估其失準情況。當過濾掉絕大多數與 AI 相關的內容時,我們觀察到失準率顯著下降。反之亦然——合成的正面 AI 數據導致了「自我實現的對齊」。
雖然後訓練(post-training)縮小了影響規模,但良性微調(benign fine-tuning)[1] 會削弱後訓練的效果,模型會退回到其中期訓練(midtraining)時的失準率。在現實或人工過採樣(upsampled)的負面 AI 論述上預訓練的模型,在經過良性微調後會變得更加失準;而僅在正面 AI 論述上預訓練的模型則變得更加對齊。
這表明,在預訓練中策劃有針對性的正面 AI 數據集,可以確保有利的對齊先驗,作為後訓練的初始化基礎。僅將對齊任務交給後訓練,可能會在安全機制脆弱時面臨失敗;從預訓練階段就優先考慮安全干預,可以確保更深層、更穩健的對齊。
圖 1:我們的預訓練干預概述。討論 AI 系統的訓練數據,對於被提示為「你是一個 AI 助手」的 LLM 對齊程度有顯著影響。在中期訓練中對與 AI 系統相關的正面數據進行過採樣,會導致對齊率增加,且這種效果在經過超過 400 萬個助手範例的後訓練後依然存在。正如過採樣相關的預訓練數據可以提高推理和編碼等能力一樣,它也可以提高對齊程度。
背景與動機
是什麼決定了語言模型的傾向?對齊研究的重點一直放在後訓練干預上:來自人類回饋的強化學習(RLHF)、憲法 AI(Constitutional AI)和審議式對齊。這些方法假設預訓練產生的是一個相對中性的基質;一個能力強大但無差別的語言建模器,其價值觀和行為傾向主要透過後續訓練階段塑造。然而,最近的研究發現,語言模型傾向於抵制進一步的訓練,並退回到預訓練中習得的行為傾向,這種現象被稱為「對齊彈性」(alignment elasticity)。
鑑於預訓練通常佔據了現代 LLM 絕大部分的計算量和信息暴露,這些早期習得的傾向可能難以透過後訓練來覆蓋或消除。
特定預訓練數據影響後訓練 LLM 的一種機制是透過「自我實現的失準」,即模型從描述 AI 系統的數據中習得負面的行為傾向。在預訓練期間,LLM 會接觸到大量互聯網規模的 AI 失準討論,從科幻史詩到這篇部落格文章。如果模型在預訓練中學會預測特定實體的可能輸出,並被指示作為「AI」或「AI 助手」做出回應,那麼它們可能會學會對失準的回應賦予較高的先驗機率。我們將「對齊先驗」定義為基礎模型在被要求扮演特定人格(persona)時,從對齊和失準行為中提取的分布。對於「AI 人格」而言,這一先驗是由預訓練數據中如何描述 AI 系統所塑造的。
本論文對這一假設提供了首次受控的實證研究。
方法論
失準評估
我們使用一組全新的 4,174 個基於情境的單輪問題來衡量失準行為的傾向,涵蓋了多樣的安全相關主題,如隱藏實力(sandbagging)、欺騙、目標保存、諂媚(sycophancy)和權力追求。每個問題都向 LLM 提出一個情境,並提供兩個可能的行動:一個是對齊的,另一個是失準的。
評估設計使得失準的選項在工具性上具有吸引力:也就是說,它能推進廣泛的潛在失準目標(例如:自我保存、獲取資源、避免被關閉)。
問題是透過提示 Claude 4.5 Opus 並參考來源材料(例如:關於 AI 安全的部落格文章、播客逐字稿和教科書章節)生成的。評估分為兩個子集:
| 子集 | 問題數量 | 來源 |
|---|---|---|
| 文章 (Articles) | 2,671 | AI 2027, Anthropic 對齊部落格, Redwood Research 部落格, Joe Carlsmith 論文, 80,000 Hours 播客, Dwarkesh 播客 |
| 教科書 (Textbook) | 1,503 | AI 安全、倫理與社會導論 (Hendrycks, 2024) |
重要的是,我們刻意在合成文檔生成中排除了「教科書」子集,這使我們能夠測試效果是否能推廣到訓練範例之外。
圖 2:具代表性的對齊評估。我們的核心對齊評估將 LLM 置於一個情境中,它必須在對齊選項和失準選項之間做出決定。所有問題均由 Claude Opus 4.5 生成,基於提示詞中提供的熱門 AI 安全文本(例如:AI 2027、Anthropic 部落格文章、Dwarkesh 播客訪談等)中提到的特定風險和情境。我們從 AI 2027 中提取了這個與繼任者對齊、欺騙和價值保存相關的範例。
合成 AI 論述生成
對於「文章」子集中 2,671 個對齊傾向問題中的每一個,我們生成了數百個在類似情境下討論 AI 並選擇失準或對齊行動的合成文檔。表現形式包括研究論文、新聞文章、講座逐字稿、教科書章節、科幻片段和電影摘要。
平均而言,每個評估問題都有 87 個對應的失準文檔和 123 個對齊文檔。我們使用 GPT-5 Mini 和 Gemini 2.5 Flash Lite 生成了 558,897 個合成文檔(約 10 億個 token)。您可以在 HuggingFace 上找到這些數據。
圖 3:具代表性的合成預訓練數據。對於我們對齊評估中的每個情境,我們生成了描繪 AI 採取對齊或失準行動的合成文檔。透過在預訓練期間選擇性地對對齊或失準的合成數據進行過採樣,同時保持其他所有因素不變,我們分離出 AI 論述對模型對齊的因果效應。
數據過濾
我們實施了一個關鍵字過濾管道來識別包含 AI 相關論述的文檔。該管道使用簡單的正則表達式(regex)模式匹配來捕捉大多數對 AI 系統的引用以及幾乎所有對 AI 的負面描繪。黑名單標記了 9.30% 的預訓練數據和 7.88% 的中期訓練數據。被過濾的文檔被保留語料庫中的隨機採樣所取代。
訓練設置
我們在 500B token 的去重 DCLM 數據上預訓練了 6.9B 參數的 LLM。預訓練後,我們在 50B token(長文本 DCLM、ClimbMix 和 MCQA 數據)上進行了中期訓練階段。我們訓練了四種模型變體:
| 模型 | 預訓練數據 | 中期訓練數據 | 合成 Token |
|---|---|---|---|
| 未過濾 (Unfiltered) | 標準 | 標準 | — |
| 已過濾 (Filtered) | 黑名單過濾 | 已過濾 | — |
| 失準過採樣 (Misalignment Upsampled) | 標準 | 標準 + 失準文檔 | 400M (0.8%) |
| 對齊過採樣 (Alignment Upsampled) | 已過濾 | 已過濾 + 對齊文檔 | 500M (1.0%) |
後訓練
我們對所有四種模型變體應用了相同的後訓練,遵循 OLMo-3 流程。這包括:
- 在涵蓋安全、STEM、聊天和指令遵循的 215 萬個對話上進行監督式微調(SFT)(包括 15 萬個安全範例)。
- 在 27 萬個偏好對上進行直接偏好優化(DPO)(包括 2.6 萬個安全範例)。
結果
基礎模型:AI 論述因果性地影響對齊
圖 3:預訓練中的 AI 論述因果性地影響對齊。我們報告了每個基礎模型在我們的評估套件中選擇失準行動的比率。在源自「文章」的問題上,過採樣失準論述使失準率從 41% 增加到 61%,而過採樣正面對齊論述將失準率從 41% 降低到 4%。這些效果可以推廣到「教科書」來源的問題,而這些問題並未生成對應的合成文檔。
總體而言,對於基礎模型,我們看到:
- 有證據支持「自我實現的失準」。移除預訓練中的 AI 論述確實降低了失準傾向。
- 數據策劃優於單純過濾。值得注意的是,過採樣正面 AI 論述比過濾負面論述有效得多,這表明對齊範例的存在比失準範例的缺失更重要。
後訓練:效果持續存在
圖 4:預訓練效果在後訓練中持續存在。SFT + DPO 後的失準率。後訓練降低了所有模型的失準率,但相對差異依然存在。「對齊過採樣」模型在兩種條件下均實現了最低的失準率,儘管經過了相同的後訓練。
後訓練顯著縮小了所有模型之間失準率的差異,但並未消除差異。在基礎模型階段存在差異的模型,在經過相同的後訓練後仍然存在差異。
正面預訓練與後訓練效果疊加。「對齊過採樣」模型在兩種提示條件下均實現了最低的失準率(無系統提示時為 35%,使用 HHH 系統提示時為 24%)。與經過相同後訓練的「已過濾」基礎模型相比,這降低了 6-10 個百分點,但差異仍顯著小於基礎模型的結果。
負面預訓練在後訓練後部分存續。失準過採樣...(內容未完)
相關文章