研究筆記:更簡化的AI時間線模型預測約2032年實現99%的AI研發自動化
我提出了一個簡化的 8 參數模型,預測 AI 將在 2032 年底前自動化超過 99% 的 AI 研發工作,並導致研究產出與效率的大幅飆升。本模型旨在比複雜的 AI 期貨模型更穩健且易於理解,同時對自動化和替代性保持保守的假設。
在這篇文章中,我描述了一個用於預測 AI 何時能自動化 AI 開發的簡單模型。該模型基於 AI Futures 模型(AIFM),但更易於理解且更具穩健性,並採用了刻意保守的假設。
以目前的算力增長率和演算法進步速度,該模型的中位數預測是:在 2032 年底,AI 研發將實現 >99% 的自動化。大多數模擬結果顯示,到 2035 年,AI 效率將提升 1,000 倍至 10,000,000 倍,研究產出將增加 300 倍至 3,000 倍。因此我懷疑,即使驅動 AIFM「快速」時間線(約 2031 年中實現超智慧)的完全編碼自動化和超人類研究品味(research taste)沒有發生,現有的算力增長和自動化趨勢仍會在「中等」時間線內產生極其強大的 AI。
為什麼製作這個模型?
-
AIFM 有 33 個參數;本模型只有 8 個。
我之前曾在 LessWrong 上總結過 AIFM,發現它非常複雜。它的哲學是對 AI 起飛(takeoff)進行極其詳盡的建模,考慮到現實世界的內在複雜性,我認為這種做法令人敬佩且在某種程度上是必要的。更複雜的模型可能更準確,但也可能對建模假設更敏感、容易產生過擬合,且難以理解。 -
AIFM 對時間範圍(time horizon)極其敏感,其方式我不完全認同。
特別是「難度翻倍增長因子」(測量時間範圍是否呈超指數增長),可能會將自動化編碼器的出現日期從 2028 年推遲到 2049 年!我懷疑時間範圍的定義過於模糊,難以釘死這個參數,而對更直接的 AI 能力指標(如效能提升 uplift)進行粗略估計,可以提供更窄的置信區間。
範圍與局限性
首先,本模型不將研究品味和軟體工程視為獨立的技能/任務。因此,我認為它是在對時間線(達到自動化編碼器或超人類 AI 研究員的時間)做出預測,而非起飛(從超人類研究員到超智慧及之後的後續時間)。AIFM 可以模擬起飛,是因為它有第二階段,即超人類研究員的研發品味會在編碼自動化的基礎上,導致 AI 研發進一步加速。如果超人類研究品味使 AI 開發效率提升數個數量級,起飛速度可能會比本模型預測的更快。
其次,本模型與 AIFM 一樣,沒有追蹤對整體經濟的影響(這類影響會像 Epoch 的 GATE 模型 那樣反饋到 AI 進步中)。
第三,我們刻意做了兩個保守假設:
- 無完全自動化:隨著 AI 能力增強,它們永遠不會自動化 100% 的 AI 研發工作,而只是無限接近。在 AIFM 中,編碼自動化遵循一條飽和點超過 100%(預設為 105%)的 S 型曲線,這意味著存在一個能力水平可以自動化所有編碼工作。
- 無替代性:自動化遵循阿姆達爾定律(Amdahl's law,當自動化任務比手動任務快得多時,加速比 = 1/(1−f))。
這個模型構思與撰寫得相當快(約 15 小時的工作量),因此我對參數的看法和某些建模假設未來可能會有所改變。
模型內容
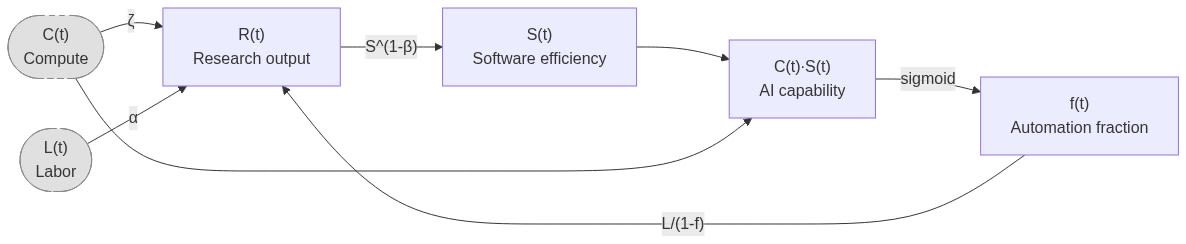
我們假設 AI 開發具有以下動態:
- 研究進展在勞動力和算力之間呈 柯布-道格拉斯(Cobb-Douglas)函數 關係。
- 軟體效率 $S$ 遵循 瓊斯模型(Jones model)。
- 我們想要預測的關鍵指標——可自動化任務的比例 $f$,隨 $\log(\text{有效算力})$ 呈 S 型增長。
- 任務之間零替代。
- 勞動力:人類「僅」在未自動化的任務上工作。
- 每個任務的人類勞動力為 $L/(1−f)$。
- 每個任務的 AI 勞動力為 $CS/f$,但這並不重要,因為我們假設人類勞動力是瓶頸(因為人類工作速度比 AI 慢)。
這隱含了以下模型:
$$S'(t) = R(t)S^{1-\beta} = \left(\frac{L}{1-f}\right)^\alpha C^\zeta S^{1-\beta}$$
$$f(t) = \sigma\left(v(\log(C(t)S(t)) - \log E_{hac})\right)$$
其中:
- $S(t)$ 是演算法效率倍數(我假設訓練和推理效率以相同速度提高),因此 $C(t)S(t)$ 是最強 AI 的有效算力。
- $f(t)$ 是時間 $t$ 的自動化任務比例。
- $R(t)$ 是時間 $t$ 的研究產出。
- $L(t)$ 是人類勞動力,設定為輸入的時間序列。
- $C(t)$ 是算力,同樣是輸入的時間序列。
- $\alpha, \beta, \zeta$ 為常數。$\alpha$ 是勞動力增加的邊際收益遞減。
- $\beta$ 是軟體改進的難度指數。
- $\zeta$ 是算力的直接收益。這對於軟體智慧爆炸並不相關,但在觀察未來算力投入能帶來多少能力提升時高度相關。
- $E_{hac}$ 是能自動化一半 AI 研發任務的 AI 所需的有效算力水平。
- $v$ 是自動化速度:$S$ 必須增加 $e^{1/v}$ 倍,才能從 50% 自動化提升到 73%。這本質上是將能力提升轉化為更多自動化的難易程度。
該模型的組成部分在 AI 預測文獻中都不是新東西,但我還沒見過有人以這種形式將它們寫出來。
參數值
參數源自以下假設,這些假設基本上是根據其他 AI 時間線模型和四處詢問得出的合理推測:
- 2026 年 1 月 $S$ 的變化率為每年 5 倍。
- $1/v$ 介於 1.5 到 4.2 之間(註:David Rein 認為是 2.1 到 4.2)。
- 2026 年 1 月的 $f$ 介於 0.25-0.5 之間,意味著效能提升(uplift)在 1.33 倍到 2 倍之間。這決定了 $E_{hac}$ 的值。
- $\alpha/(\alpha+\zeta)$ 介於 0.12 到 0.35 之間。
- $\alpha+\zeta$ 介於 0.8 到 1 之間。
- $\beta$ 為 0.3 到 1。
- $L$ 在 2029 年前每年翻倍,之後每年增長 10%。
- $C$ 在 2029 年前每年增長 2.6 倍,之後在 2030 年到 2058 年間,增長率從每年 2 倍線性下降到 1.25 倍。(這與 Epoch 的短期估計一致,並接近 2030 年後 AIFM 的時間序列)。
所有參數均根據三角形分佈獨立分佈。由於獲取 $\alpha$、$\zeta$ 和 $v$ 時進行了變換,$v$ 將不再是三角形分佈,$\alpha$ 和 $\zeta$ 也不會是三角形分佈或相互獨立。
更多資訊請參閱 Notebook:https://github.com/tkwa/ai-takeoff-model/blob/main/takeoff_simulation.ipynb
圖表
所有圖表顯示了 40 條軌跡,參數根據參數值章節進行採樣。
40 條軌跡中的自動化比例 f(對數機率尺度)。大多數軌跡在 2030 年代初至中期達到 99% 的 AI 研發自動化。
模型的 40 條採樣軌跡。左上:隨著自動化加速研究,軟體水平 S 呈次指數(但非常快)增長。右上:如果自動化速度快,並行算力:勞動力比率 C/(L/(1−f))(邊際收益遞減前的原始資源比率)會下降;但如果自動化在 2034 年左右達到 99%,則該比率基本保持恆定。左下:研究產出 R(t) 增加了數個數量級。右下:串行算力:勞動力比率 Cζ/(L/(1−f))α(含邊際收益遞減指數)呈上升趨勢。為了數值穩定性,軌跡在自動化達到 99.9999% 時截止。
敏感度分析:達到 99% 自動化的中位數年份作為各個參數的函數,其他參數從其先驗分佈中採樣。較高的 beta(軟體改進的收益遞減)和較高的 1/v(自動化速度較慢)對 99% 自動化的延遲影響最大,而其他參數影響較小。
觀察結果
- AI Futures 模型雖然複雜,但其結論對於簡化具有相當的穩健性。
- 時間線背後的兩個關鍵不確定性是:
- 如何衡量演算法進步(我們的估計仍具有高度不確定性)。
- 有效算力與實際任務自動化百分比之間的關係。
- 以目前的算力增長和演算法進步速度,到 2035 年,即使沒有完全自動化或自動化研究品味,也將實現 >99% 的 AI 研發自動化、1e3 到 1e8 的軟體效率提升,以及 300 倍至 3000 倍的研究產出。這顯然是變革性的 AI。
- 達到 99% 自動化的中位數日期是 2032 年年中。然而,我並不過分看重精確的預測時間線,因為我還沒有對精確的參數值進行深入思考。
- 基本的敏感度分析顯示,較高的 beta(收益遞減)和較低的 v(自動化速度)會使 99% 自動化發生得更晚,而其他參數影響不大。
- 人們可能預期「勞動力份額」$\alpha/(\alpha+\zeta)$ 對時間線有很大影響。它影響不大的原因是,勞動力(透過自動化)和算力(透過外生算力增長)都在快速擴張,並共同推動 AI 進步。
- 並行算力:勞動力比率(衡量每個 AI 或人類編碼員分配到的算力)在平均軌跡中下降,在長曆時軌跡中則趨於平穩。因此,在 2030 年的時間線中,人類和 AI 編碼員池擁有的算力比今天少得多;而在 2035 年的時間線中,他們擁有的算力大約持平。
- 串行算力:勞動力比率上升,這意味著算力增長對研究產出的影響大於勞動力增長。這是因為算力增長極快,而自動化增加的並行勞動力並不能有效地轉化為串行勞動力。
討論
透過對此模型及 AIFM 其他變體的嘗試,我認為任何合理的預測模型都會預測在 2036 年之前出現超人類 AI 研究員,除非 AI 進展撞牆或被刻意放緩。
- 所謂進展撞牆,是指類似於算力和人類勞動力增長在 2030 年左右放緩、沒有架構突破,且 AI 實驗室找不到任何新方向來有效投入資源以提升性能。我們已經擴展了預訓練、RLHF、代理性 RL 和推理,哪怕再多一兩個維度也能維持進展。
- 在敏感度分析中,除非自動化緩慢程度大於 3.6(即自動化從 50% 提升到 73% 需要 37 倍的效率提升),否則自動化緩慢不會將時間線推遲到 2036 年。至於收益遞減(beta),即使假設為 0.9,我們仍會得到 2034 年的時間線。因此,我們需要同時具備高自動化緩慢度和高 beta,才能讓時間線延後到 2036 年之後。
除了利用經驗數據完善參數值外,理想情況下我希望在 2026 年之前的數據上對此模型進行回測。然而,回測可能不可行,因為 2025 年之前的自動化程度極低,而 AI 研發的自動化是本模型模擬的主要效應。
關於建模選擇的更多說明
與 AIFM 的差異列表
將此內容與我的 AIFM 總結 進行交叉對照可能會很有用。
- 無替代性:自動化遵循阿姆達爾定律(當自動化任務比手動任務快得多時,加速比 = 1/(1−f))。AIFM 假設存在小程度的替代性($\rho_c = -2$)。
- 自動化任務不是瓶頸:一旦任務可以被自動化,我們假設它比人類快得多,且永遠不會成為瓶頸——無論是因為 AI 在串行運行上比人類快得多,還是在並行上快一些。AIFM 假設自動化任務最初僅比人類編碼快一點,並隨時間加速。
- 無完全自動化:隨著 AI 能力增強,它們永遠不會自動化 100% 的 AI 研發工作,而只是接近。在 AIFM 中,編碼自動化遵循一個飽和點在 100% 以上(預設 105%,這個數字看起來有些隨意)的 S 型曲線,這意味著存在一個能力水平可以自動化所有編碼。
- 勞動力和算力是柯布-道格拉斯關係:與其他差異不同,這一點傾向於縮短時間線。在 AIFM 中,它們是 CES(恆定替代彈性)且略微互補,因此無限算力不會產生無限進展。詳見下文。
- 不使用時間範圍(Time Horizon):軟體效率是我們模型的直接輸入,而不是使用時間範圍來估計。我們將自動化比例建模為對數有效算力的嚴格 S 型函數,並透過我們希望未來能完善的粗略效能提升估計來關聯。原因見「為什麼製作這個模型」。AIFM 使用時間範圍閾值來估計自動化編碼器所需的有效算力。
- 無研究品味:我們不單獨建模研究品味;我認為早期的研究品味與編碼涉及的規劃是連續的,並忽略了晚期研究品味。由於缺乏研究品味模型和某些參數選擇,能力增長恰好是次指數的(因此我不嘗試建模是否會出現僅限品味的奇點)。AIFM 擁有豐富的研究品味模型,需要另外約 6 個參數,並決定了起飛的第二階段(從自動化編碼器到超智慧,再到智慧的最終物理極限)。
我們如何更好地估計參數?
我們可以透過以下方式獲取 $f(2026)$ [2026 年的效能提升比例]:
- 現實編碼代理的使用記錄 + 成功判定 + 基於已知長度任務校準的難度判定。
- 效能提升的隨機對照試驗(RCT)。
- 詢問實驗室員工目前的效能提升情況(因為在簡單模型中,並行效能提升與 $1/(1-f)$ 是等價的)。
$v$ [隨能力提升的自動化速度] 可以透過以下方式獲取:
- 猜測任務分佈,使用時間範圍,或許對現實與基準測試的時間範圍使用修正因子。
- 隨時間進行多次效能提升研究。
- 比較舊模型與新模型,或讓舊模型嘗試人們使用新模型完成的任務。
- 列出每年有多少事情被自動化。
為什麼自動化是 S 型的?
- 對於任何將實數映射到 (0, 1) 的模型,S 型曲線(logistic)是最簡單的選擇。
- 直覺上,當 AI 已經自動化了 >50% 的人類研究時,每一單位的能力進展將允許自動化剩餘勞動力的恆定比例。S 型曲線具有指數尾部,符合這一直覺。
為什麼勞動力和算力是柯布-道格拉斯關係?
在 AIFM 中,勞動力與算力之間替代性的中位數估計為 -0.15,且合理範圍包括零(即柯布-道格拉斯)。我問過 Eli 為什麼不直接說它是柯布-道格拉斯,他說柯布-道格拉斯會導致如果勞動力/算力其中之一趨於無窮而另一個保持不變時,會產生無限的進展,這是不合理的。我有兩點回應:
- 對我來說這似乎並非不合理——對於無限算力,在給定無限算力的情況下,可能只需要幾天到幾週就能達到超智慧(ASI),這意味著 100x-1000x 的加速;一旦達到那裡,無限算力可能允許開發者在幾個月內開發出人類使用當前算力水平需要數十億年才能完成的演算法。至於無限勞動力,一個理論上無限的勞動力池可以僅透過人工計算來進行訓練,並在不使用任何實驗算力的情況下寫下最佳的 AI 權重。
- 在所討論的期間內,有效勞動力/算力比率僅變化 10-100 倍,因此無論如何對結果影響不大。最快的軌跡受算力:勞動力比率影響最大,但對於在 2034 年左右達到 99% 自動化的軌跡,該比率保持在 1:1 左右。
為什麼任務之間沒有替代性?
AIFM 的中位數大約是 $\rho = -2.0$,這意味著非常弱的替代效應。為了保守起見,我假設沒有替代效應。
相關文章