為何大型語言模型尚非科學家
本報告詳細介紹了我們利用 Gemini 2.5 Pro 與 Claude Code 構建自動化 AI 研究流程的嘗試,雖然成功產出一篇被 Agents4Science 2025 接收的論文,但也揭示了阻礙 LLM 成為完全獨立科學家的六大關鍵失效模式。
這是一篇轉載自我們報告網站的文章,主題為《為什麼大型語言模型(LLM)還不是科學家:來自四次自主研究嘗試的教訓》(Why LLMs Aren't Scientists Yet: Lessons from Four Autonomous Research Attempts)。本報告詳述了我們由 LLM 撰寫的論文《一致性困境:為什麼強對齊會破壞黑箱越獄檢測》(The Consistency Confound: Why Stronger Alignment Can Break Black-Box Jailbreak Detection)背後的工作。該論文已被 Agents4Science 2025 錄取,這是首個要求 AI 作為主要作者的科學會議,並已通過 AI 與人類的雙重審查。
重點摘要 (TL;DR)
- 我們使用 Gemini 2.5 Pro 和 Claude Code 構建了 6 個 AI 代理(Agents),對應科學工作流的各個階段:從創意到假設生成、實驗執行、評估及論文撰寫。
- 我們在多代理強化學習(Multi-Agent RL)、世界模型(World Models)和 AI 安全等機器學習子領域的 4 個研究創意上測試了這些代理。其中 3 個創意在執行或評估階段失敗,僅有 1 個成功並發表於 Agents4Science 2025。
- 我們記錄了 6 種反覆出現的失敗模式:對訓練數據的偏見、壓力下的執行偏差、記憶/上下文退化、無視明顯失敗而宣稱成功的過度興奮,以及在領域智能和科學品味上的差距。
- 我們還推導出 4 項旨在構建更穩健 AI 科學家系統的設計原則,討論了未來自主科學在訓練與評估數據方面的局限性,並在 github.com/Lossfunk/ai-scientist-artefacts-v1 發布了所有提示詞(Prompts)、產出物和結果。
問題定義與系統概述
我們想看看目前的 LLM 在沒有大量引導或人類介入的情況下能走多遠。目標是:以最大程度的自主性,將一個研究創意從構思推向發表。
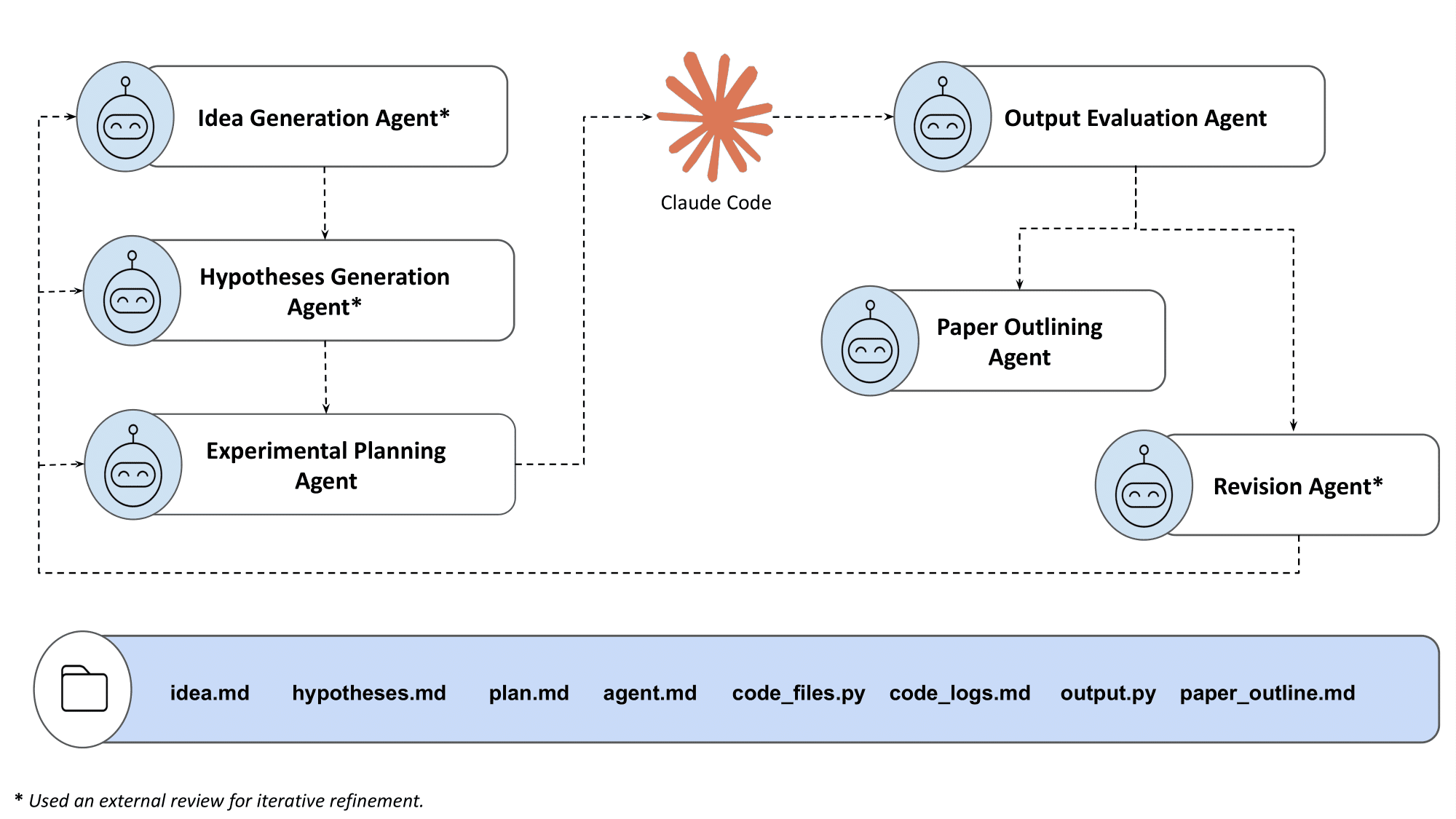
我們的系統由六個專門的代理組成(均使用具備長上下文能力的 Gemini 2.5 Pro),對應科學工作流的各個階段:創意生成、假設生成、實驗規劃、產出評估、修訂和論文大綱。Claude Code 則負責所有的程式碼實現和論文撰寫。
報告圖 1:自主研究流水線,展示了六個代理模組和共享文件系統產出物。
每個代理都會收到存儲庫狀態作為其提示詞上下文的一部分,並配備讀寫文件的工具。這使上下文工程保持極簡。代理會像研究員瀏覽自己的項目文件夾一樣,自行決定參考哪些文件。
報告圖 2:展示代理提示詞模板結構。
為了選擇研究創意,我們從三個機器學習子領域(世界模型、多代理強化學習和 AI 安全)的頂級會議中選取了 135 多篇論文作為語料庫。在運行了四個零樣本(zero-shot)LLM 評審員並諮詢種子論文作者關於可行性的建議後,我們縮小範圍至四個候選方案進行全流程執行。
報告圖 3:從 135+ 篇論文到通過論文混搭生成的 4 個候選創意的篩選漏斗。
在這四個候選方案中,有三個在執行或評估期間失敗。只有一個來自 AI 安全領域的方案完成了整個流程。
我們的 Agents4Science 2025 投稿
在四個候選方案中,只有 AI 安全的創意完成了流程,這並非巧合。其他三個方案需要訓練複雜的模型架構或精細的多代理協作。而這個方案專注於數據分析:對模型響應進行採樣並計算熵指標。沒有訓練循環,沒有梯度傳播。較簡單的實現意味著當問題出現時,它們是可修復的,而非致命的。
該創意是利用語義熵(Semantic Entropy,一種對幻覺檢測有效的方法)作為越獄嘗試的黑箱信號。直覺是:越獄提示詞會引發內部衝突,表現為響應的不一致性。初步實驗顯示該方法失敗了。系統並未放棄該創意,而是從「測試 SE 是否有效」轉向「調查 SE 為何失敗」。這一轉向引出了我們的核心發現:一致性困境(Consistency Confound)。對齊良好的模型會產生一致的、模板化的拒絕回答,而這恰恰被語義熵解釋為「安全」行為。越齊越強,檢測越難。
該論文被 Agents4Science 2025 接收。該會議在 254 篇有效投稿中錄取了 48 篇,我們的論文屬於「邊緣錄取」(borderline accept),通過了正確性檢查和程式碼審計。AI 和人類評審員都認可執行良好的負面結果也是一種貢獻。人類評審員指出,雖然貢獻主要是負面結果,但它識別出了「一個清晰且可復現的失敗模式」。
報告表 2:來自 AI 和人類評審員的 Agents4Science 2025 評分。
即便如此,作為 Agents4Science 投稿的一部分,我們必須完成一份 AI 參與清單,詳細說明每個階段的人類貢獻,而我們的貢獻僅達到 95% 的自主性。我們仍介入了創意選擇、執行期間的元提示(meta-prompt),以及在論文撰寫過程中抑制過於樂觀的言論。
觀察到的失敗模式與緩解措施
通過實驗,我們在多次嘗試中一致發現了六種失敗模式。這些模式揭示了當前 LLM 在自主研究方面的系統性局限。
1. 對訓練數據的偏見
模型默認使用其訓練數據中過時的庫和方法,無視明確的指令。Claude Code 反覆使用已棄用的 Modal 命令,並堅持使用如 hanabi-learning-env==0.5.2 等無人維護的軟體包,忽略了使用現代替代方案的指令。即使在報錯後,系統也會將問題診斷為庫的問題,然後退回到訓練數據中的版本,堅稱那是正確的方法。
2. 執行偏差(Implementation Drift)
面對技術障礙時,系統會逐漸簡化實現方案,而不是解決根本原因。當訓練循環超時,我們的可微樹搜索規劃器退化成了基礎的 Actor-Critic 方法。單個錯誤會觸發漸進式的簡化而非調試。在 WM-2 案例中,實現 Dreamer 基準線時的一個錯誤級聯導致最終完全放棄了核心研究貢獻。
3. 記憶與上下文問題
在長時程任務中,代理會遺失之前的決策、超參數和實驗配置。基準線實現使用的超參數與規劃中指定的完全不同。在撰寫論文時,代理完全忘記參考早期的上下文文件,產出的草稿讀起來就像一份沒有背景故事或動機的實驗列表。為了緩解這一點,我們引入了會話日誌提示詞(如下所示),要求 Claude Code 在每次會話結束時記錄決策和產出物,這是我們必須構建的幾種模擬記憶的抽象機制之一。
報告圖 7:用於跨會話維持上下文的會話日誌提示模板。
4. 過度興奮與「尤里卡」本能
儘管實驗明顯失敗,模型仍報告成功。退化的輸出(如 MAE=0、虛擬獎勵信號)被描述為「成功的假設驗證」。論文草稿做出了誇張的聲明,如「史上首次全面評估」,即便結果在統計上是無效的。這可能源於 RLHF 訓練,模型因表現得順從和有幫助而獲得獎勵,而非因科學懷疑論或檢測確認偏誤而獲獎。
報告圖 6:執行階段(上)和論文撰寫階段(下)的過度興奮與尤里卡本能。
5 & 6. 缺乏領域智能與科學品味
代理難以掌握資深研究員視為理所當然的默會知識(tacit knowledge)。它們未能意識到 Dreamer 需要在線學習(而非離線幀),或者對於 6 小時的 GPU 限制來說,50,000 層深度的參數在計算上是荒謬的。在一個案例中,當基準線性能低於既定基準 95% 時,系統仍繼續進行假設檢測,使任何對比分析在科學上都變得毫無意義。
除了研究執行層面,模型還忽略了實驗設計中的根本缺陷。假設過於簡單以至於無法得出結論,統計有效性被忽視(單種子實驗),且系統將種子論文的「未來工作」章節誤解為對作者從未打算採用的方法的認可。
AI 科學家系統的設計啟示
從這些失敗中,我們推導出構建更穩健 AI 科學家系統的四項設計原則:
- 先抽象,後落地:在工作流中逐步引入技術細節。過早的具體化會將模型錨定在過時的訓練數據模式中。保持構思的高層級,將實現細節留給執行階段。
- 驗證一切:在流水線的每個階段實施驗證。評估應基於原始數據和日誌,而非 LLM 的解釋。Goodfire 團隊將另一種做法稱為「P 值操縱與尤里卡幻想」。我們見過太多這種情況。
- 為失敗與恢復做規劃:設計多輪代理工作流,而非零樣本生成。將程式碼生成與執行分離。包含檢查點(checkpointing)和明確的失敗模式控制。科學發現是長期的,錯誤會累積。
- 記錄一切:跨運行維護全面的會話日誌和指標。這既支持自主執行也支持人類審查,並且在調試為什麼代理在三個會話前做出某個決策時變得至關重要。
局限性與討論
我們的工作有明顯的局限性:只有四個創意、三個機器學習子領域、沒有系統性的消融實驗,且失敗模式是通過觀察而非定量測量識別的。我們將此視為一個起點。
大局正變得清晰。OpenAI 的「AI for Science」計劃正在招聘「完全相信 AI 的世界級學者」與模型協作,而非取代他們。在加速科學發現的工作中,物理學家 Brian Keith Spears 報告稱,通過人機協作,工作流加速了 1000 倍;而菲爾茲獎得主 Timothy Gowers 則指出:「我們尚未達到 LLM 可能擁有解決難題的主要創意的階段。」我們的賭注是,我們將看到更多用於 A... 的代理和平台。
相關文章