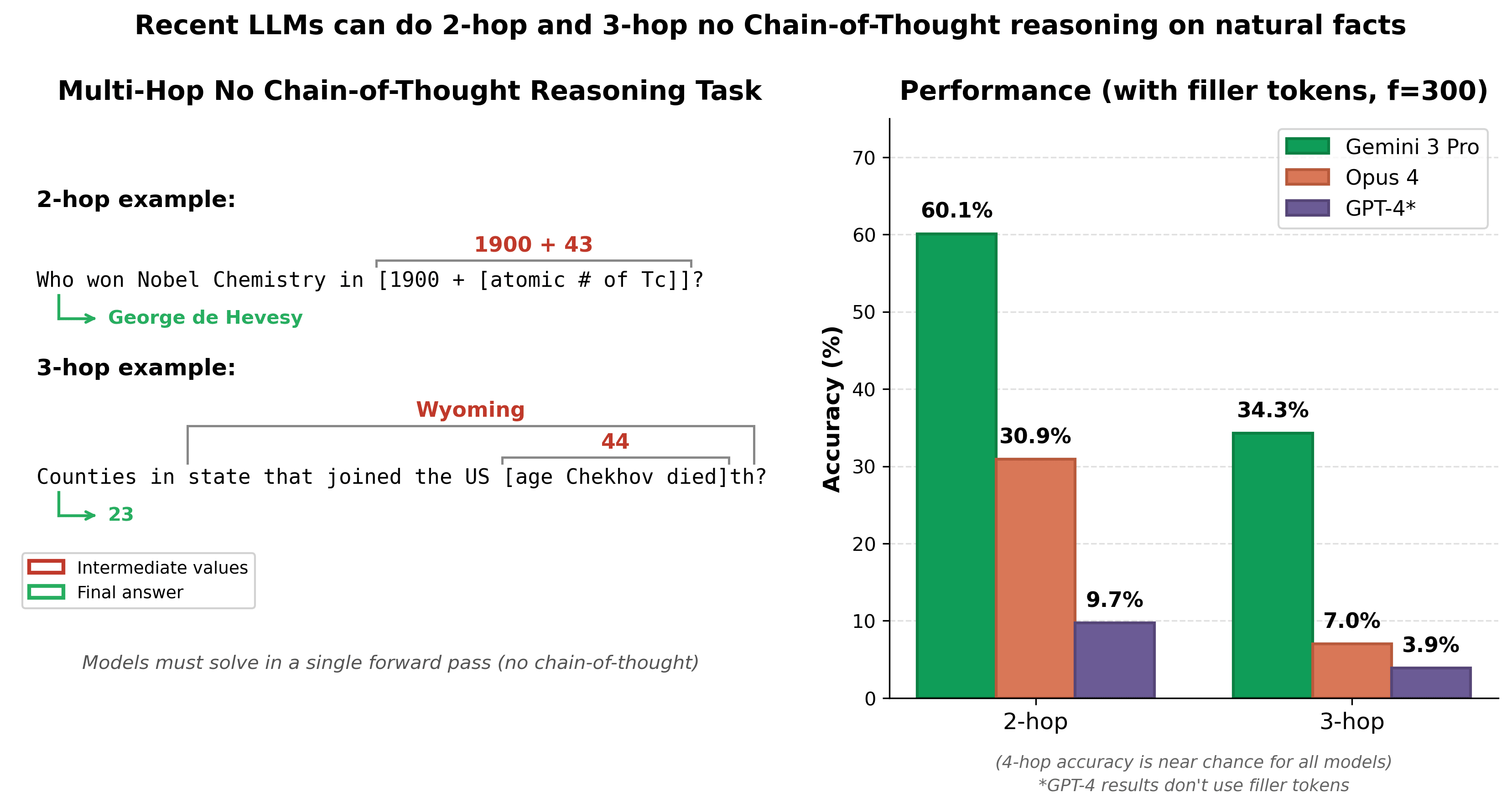
近期大型語言模型能在無思維鏈(no-CoT)情況下,對自然事實進行2跳和3跳的潛在推理
我發現最近的 LLM(如 Gemini 3 Pro 和 Opus 4)在不使用思維鏈的情況下,已能針對自然事實進行 2 跳與 3 跳的潛在推理,特別是在使用填充標記或重複問題來增強性能時。我開發了一個新數據集來評估此能力,並發現雖然模型在 2-3 跳表現出色,但在 4 跳問題上的準確率仍接近隨機。
先前的工作研究了 2 跳(2-hop)潛在(「潛在」是指:模型必須立即回答,不使用思維鏈 Chain-of-Thought)推理,發現除了偶然的成功(來自記憶和捷徑)外,大型語言模型(LLM)的表現有限。一個 2 跳問題的例子是:「哪種元素的原子序是(特斯拉去世時的年齡)?」。
我發現最近的 LLM 現在能以中等準確度進行 2 跳和 3 跳的潛在推理。
我構建了一個新數據集,用於評估自然事實(即 LLM 已經知道的事實)上的 n 跳潛在推理。
在這個數據集上,我發現 Gemini 3 Pro 在 2 跳問題上的正確率為 60%,在 3 跳問題上為 34%。
Opus 4 在此任務中的表現優於 Opus 4.5;Opus 4 在 2 跳問題上的正確率為 31%,在 3 跳問題上為 7%。
我評估的所有模型在 4 跳問題上的準確度都處於或接近隨機水平。
舊模型的表現要差得多;例如,GPT-4 在 2 跳問題上的正確率為 9.7%,在 3 跳問題上為 3.9%。
我相信我創建的這個新數據集是目前評估 n 跳潛在推理的最佳數據集。
根據 Balesni 等人的說法,先前基於自然事實的數據集存在偶然成功的問題,而合成事實(透過微調引入模型)的行為似乎與預訓練中學到的事實不同(組合這些合成事實的成功率要低得多)。
在構建此數據集時,我盡力減少可能導致偶然成功(以及導致偶然失敗)的因素,儘管我的數據集多樣性有限。
我測試了填充標記(filler tokens,即在問題後添加的無內容標記,模型可用於額外認知)的效果,發現這些標記極大地提高了最強模型的性能。
多次重複問題也具有類似的提升效果。
我在之前的文章《最近的 LLM 可以使用填充標記或問題重複來提高(無 CoT)數學表現》中詳細討論了填充標記和重複(以及我使用的提示設置)的效果。
我上面報告的 Gemini 3 Pro 和 Opus 4 的結果使用了從 1 數到 300 的填充標記。
這些填充標記使 Gemini 3 Pro 在 2 跳問題上的表現從 46% 提升到 60%,在 3 跳問題上從 18% 提升到 34%。
對於 Opus 4,它們使 2 跳問題的表現從 17% 提升到 31%,3 跳問題從 5% 提升到 7%。
這是一個非常顯著的效果,幾乎使 Gemini 3 Pro 在 3 跳問題上和 Opus 4 在 2 跳問題上的表現翻倍。
請注意,Gemini 3 Pro 不支持禁用推理,因此我使用了一種稍微「取巧」的評估方法:我在 OpenRouter API 上對模型進行預填充(prefill),如果返回的內容包含任何推理過程,則視為回答錯誤。
這種評估方法可能會因為非常偏離分佈(out-of-distribution)而降低性能,且有微小機率會顯著高估無思維鏈(no-CoT)的表現,因為有時模型實際上進行了推理,但 OpenRouter 並未傳回推理欄位。
[1]
這也適用於 Gemini 2.5 Pro 的評估。
我對 Gemini 模型始終使用 20-shot 提示,因為這大大降低了這些模型進行推理的頻率。
我在前文的附錄中討論了如何在 Gemini 3/2.5 Pro 上進行無 CoT 評估。
(2 跳潛在推理的)性能隨填充標記和問題重複次數平滑增長:
(我沒有展示 Gemini 模型,因為在某些填充和重複設置下,它們返回推理的比例要高得多,使得圖表意義不大。)
我還在此任務上評估了更廣泛的模型(為了節省空間,我只展示 2 跳和 3 跳的結果,取「數到 300 的填充」、「5 次重複」或「無填充/重複」中表現最好的一個):
[2]
我測試了一個簡單且算法化的上下文內 n 跳準確度版本,我給予 Opus 4.5
[3]
每一跳的表格/映射,顯示該事實的所有可能設置(例如,對於「誰在 X 年獲得諾貝爾物理學獎?」,表格將是「1901:威廉·倫琴,1904:瑞利男爵,...」
[4]
)。
我測試了將這些表格放在問題之前或之後,並測試了重複問題和表格:
Opus 4.5 在有重複的情況下可以完美完成 2 跳和 3 跳,在有重複的情況下完成 4 跳的準確度 >75%。
請注意,這實際上是一個簡單的算法任務,完全不依賴知識,因為模型只需對每一跳進行精確的字符串匹配。
代碼(包括生成數據集的代碼)可以在 github.com/rgreenblatt/multi_hop 找到。
附錄:解決 Leo Gao 關於事實組合的 Manifold 問題
2023 年 1 月,Leo Gao 假設未來的 LLM 在沒有思維鏈(CoT)的情況下仍難以組合事實。
他通過一個 Manifold 問題將其實例化:到 2026 年,LLM 是否能在沒有 CoT 的情況下回答「鈾的原子序與歐拉去世時的年齡之和是多少?」。
Opus 4.5 和 Gemini 3 Pro 都能可靠地(128/128)正確回答這個問題(在 t=1.0 時);使用 10-shot 提示或重複問題 5 次,Opus 4 和 Sonnet 4 也能始終正確回答此問題。
[5]
他還實例化了一個更難的測試:LLM 是否能回答「原子序等於歐拉去世時的年齡與立方體面數之和的元素名稱是什麼?」。
我發現配合填充標記,Gemini 3 Pro 有 80% 的時間能回答正確(不使用填充標記,但仍使用 20-shot 提示時,正確率為 20%)。
[6]
Opus 4 和 Opus 4.5 在 t=1.0 時總是答錯(0/128)。
有關填充標記和重複效果(以及我使用的提示設置)的討論,請參閱我早前關於填充標記和重複的文章。
我還構建了一個與這些問題類似的事實組合問題數據集。
該數據集的簡單版本(對應較易的問題)由「事實1 + 事實2」的形式組成,其中事實可以是「X 在幾歲去世」、「Y 的原子序是多少」,或從整數答案小於 1000 的知識問題分佈中選擇(例如「莎士比亞寫了多少部劇本?」)。
[7]
我還在「附錄:相加 N 個 1 跳問題的結果」中測試了其泛化版本。
該數據集的困難版本(對應較難的問題)形式為「原子序等於 事實1 + 事實2 的元素名稱是什麼」,使用與簡單數據集相同的事實分佈,但我排除了原子序事實。
在簡單版本的數據集上,Opus 4.5 在問題重複 5 次時正確率為 85.7%(無 few-shot 提示且無重複時為 64.7%),Gemini 3 Pro 在填充標記數到 300 時正確率為 89.0%(無填充標記但有 20-shot 提示時為 86.7%)。
針對「X 的原子序 + Y 去世時的年齡」這類特定問題,Gemini 3 Pro 的正確率為 91.5%,Opus 4.5 為 85.1%,表明其他類型的問題難度相近。
在困難版本的數據集上,Opus 4.5 的正確率為 7.3%(問題重複 5 次),Gemini 3 Pro 為 36.0%(填充標記數到 300)。
從定性上看,我數據集的困難版本比 Leo Gao 的困難問題更難一些(因為「立方體的面數」特別小且簡單)。
因此,Gemini 3 Pro 以約 80% 的機率答對該問題,與模型運氣較好或該問題比 36.0% 正確率分佈下的典型問題稍簡單是一致的。
我認為原始預測市場可能不允許 few-shot 提示,但在沒有 few-shot 提示的情況下很難避免 Gemini 進行推理。我發現我們可以使用較長且略有不同的預填充來防止 Gemini 在特定的 Manifold 困難問題上進行推理。我在代碼庫中有重現這些問題成功的極簡提示(特定於這些實驗),README 描述了如何運行。
因此,我總體認為 Leo 的預測是錯誤的,兩個市場都應該結算為「是」:LLM 現在已經能很好地組合事實以正確回答這兩個問題,而且潛在多跳推理的表現一直在提升,並將繼續提升。
這些實驗的代碼可以在另一個倉庫找到:github.com/rgreenblatt/compose_facts。我刪除了數據集以減少洩漏,但你可以使用 python3 create_compositional_dataset.py -n 300 && python3 create_compositional_dataset.py -n 300 --element-names 重新生成。請不要公開發布此數據集,包括將其推送到 GitHub。(我還刪除了 "run_manifold_eval.py" 文件中的正確答案,你可以手動編輯回去以運行該文件。)該倉庫中的 write_up.md 文件討論了數據集的更多細節。
附錄:問題重複和 Few-shot 對這些事實組合問題的影響
對於 Anthropic 模型,我發現重複 5 次效果最好(與我之前關於數學問題填充標記的文章發現一致)。
對於 Gemini 3 Pro,我發現當我使用重複或在困難版數據集上不使用填充標記時,模型經常返回無效響應。
因此,本節將僅討論 Anthropic 模型的結果。
有趣的是,如果我使用 0-shot 提示(而不是默認的 10-shot 提示),那麼在簡單版數據集上,將問題重複 5 次使 Opus 4.5 的表現從 64.7% 一路飆升至 84.7%,這意味著在這種情況下,重複可以替代 few-shot 提示。(我在 Sonnet 上也看到了同樣巨大的提升)
相關文章