衡量AI無思維鏈數學時間跨度(單次前向傳播)
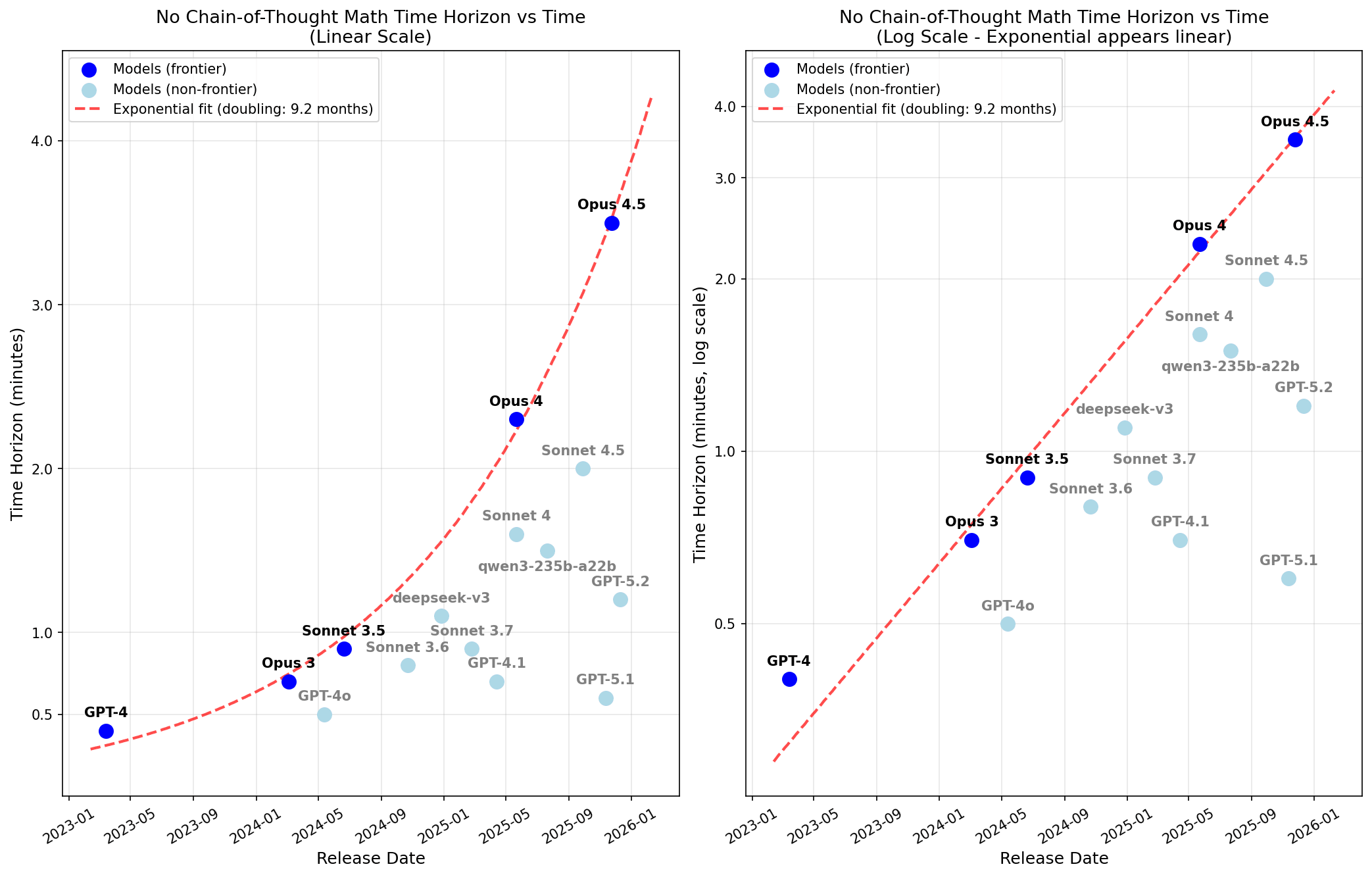
我測量了 AI 模型在不使用思維鏈(no-CoT)情況下的數學時間跨度,發現 Opus 4.5 在單次前向傳播中能解決人類需花費 3.5 分鐘處理的問題,且此能力每 9 個月翻倍一次。
謀略(以及更廣泛的對齊失調)的一個關鍵風險因素是不透明的推理能力。
衡量這一點的一個指標是 AI 在不使用思維鏈(CoT)的情況下(即在單次前向傳遞中)直接解決數學問題的能力。
我在一個簡單數學問題的數據集上測量了這一點,並使用與《衡量 AI 完成長任務的能力》(METR 時間範圍論文)中介紹的相同方法,估計了 50% 可靠性的無 CoT 時間範圍。
重要聲明:為了獲得人類完成時間,我要求 Opus 4.5(帶有思考過程)來估計中位數 AIME 參賽者完成給定問題所需的時間。
這些時間對我來說似乎大致合理,但如果能獲得一些實際的人類基準並用其來修正 Opus 4.5 的估計會更好。
以下是 50% 可靠性時間範圍的結果:
我發現 Opus 4.5 的無 CoT 50% 可靠性時間範圍為 3.5 分鐘,且該時間範圍每 9 個月翻一倍。
在之前的一篇文章(《近期的 LLM 可以透過使用填充標記或問題重複來提高(無 CoT)數學表現》)中,我發現重複問題會顯著提升表現。
在上述圖表中,如果重複問題 5 次對某些模型有幫助,我就會使用重複後的得分(因為我認為這種稍微保守一點的測量方式,可能更能代表令人擔憂的認知類型)。
擬合曲線看起來非常乾淨,但請注意,我刻意只對 Anthropic 的前沿模型進行了擬合(具體來說,我排除了發布時勉強算得上 SOTA 的 DeepSeek-v3)。
另外請注意,如果不允許重複,Anthropic 的前沿模型和 GPT-4 就不再處於同一條優美的趨勢線上(Anthropic 的前沿模型仍然有其自身非常乾淨的指數擬合,只是不再能很好地回推預測 GPT-4)。
我將有重複與無重複的結果進行了對比:
關於時間範圍擬合與數據的一些細節
對於我評估的相對能力較強的模型,我發現時間範圍的擬合效果非常好。例如,這是 Opus 4.5 的 S 型曲線(sigmoid)擬合:
我特意收集了一個相對簡單的數學問題數據集,其中包含許多在 1-5 分鐘範圍內的問題,以使這種測量變得合理。
該數據集在測量 0.5 分鐘以下的時間範圍時表現不佳(我已將此類模型從圖表中排除)。
以下是顯示時間和難度分佈的直方圖
[1]
我使用的數學數據集是我創建的,由 907 個大多較為簡單的競賽數學問題組成。該數據集包含約 600 個來自 MATHCOUNTS 的(簡單)初中競賽數學題,以及約 300 個來自相對冷門的匈牙利高中數學競賽的題目。許多 MATHCOUNTS 題目只需要一些基礎代數和算術。我相當確信這個數據集沒有受到嚴重的數據污染,但污染實質上影響結果是有可能的,且這些問題可能與 AI 已經記住的問題高度相似。
有關我使用的數據集和整體設置的更多細節,請參閱我之前關於填充標記和重複問題的文章,因為兩者使用了相同的設置。
您可以在 github.com/rgreenblatt/no_cot_math_public 找到這些實驗的代碼。
分析
根據這些結果,我們應該得出什麼結論?
從某種意義上說,3.5 分鐘的無 CoT(不透明)50% 可靠性時間範圍相當可怕(在 3.5 分鐘內可以思考很多事情!),但令人鼓舞的是,這遠遠落後於非不透明的時間範圍(例如,最好的 LLM 在類似 AIME 的困難數學問題上可能擁有數小時的時間範圍)。
此外,無 CoT 時間範圍的翻倍時間(約 9 個月)似乎比非不透明/帶 CoT 的時間範圍翻倍時間要慢不少(在 2025 年,METR 在 SWE 任務上測得的翻倍時間約為 4-6 個月,我猜測在數學上也會得到類似的數字)。
儘管如此,請注意我的結果不允許在 CoT 中進行編碼推理,而只是觀察固定提示詞(帶重複 [2])下單次前向傳遞的表現。
這些結果的一個關鍵局限性是我在競賽數學問題數據集上進行評估:其他分佈下的時間範圍可能會更高或更低!
我目前的猜測是,如果你觀察其他與這些數學問題同樣具有序列性的分佈,目前的 AI 時間範圍會更低(它們可能對數學過度擬合)。
我認為 LLM 在涉及多跳鏈接上下文外信息的任務上表現特別差;在一些即將發布的結果中,我發現 Opus 4 和 Opus 4.5 在沒有 CoT 的情況下,在 3 跳任務上的表現接近隨機(例如:「第(鎘的原子序數)個加入聯邦的美國州的州座右銘是什麼?」),而在 2 跳任務上的表現僅約 30%(例如:「原子序數為(約翰·柯川去世時的年齡)的元素是什麼?」)。
然而,AI 在高度可並行化的任務上(例如,大多數重閱讀任務)擁有非常大的不透明時間範圍。
例如,AI 通常可以識別一個大型 Python 文件是否存在漏洞,而人類可能需要 30 分鐘才能確定。
(一個更極端的例子是,AI 可以在單次前向傳遞中,從 20 萬字中定位一個細微的「大海撈針」,而人類可能需要一個多小時。)
如果我們向前推斷,假設 SWE 的翻倍時間為 5 個月,無 CoT(不透明)推理的翻倍時間為 9 個月,我們可以得出:當 AI 擁有 40 小時的 SWE 時間範圍時,它們在(數學問題上的)無 CoT 推理時間範圍將達到 16 分鐘。
當然,這一切都假設架構沒有發生重大變化(例如轉向神經語言 neuralese)。這可能會立即導致「帶 CoT」和「不透明」的表現變得一致。
附錄:Gemini 3 Pro 的得分
Gemini 2.5 Pro 和 Gemini 3 Pro 都不支持禁用推理,這使得對這些模型進行評估變得很棘手。修訂:本節的先前版本討論了使用一種粗糙的提示策略來阻止 Gemini 3 Pro 進行推理。nostalgebraist 建議了一種更好的方法,利用這些模型在使用 OpenRouter API 進行預填(prefill)時通常不會推理的特性,我現在採用了這種方法(並相應修改了本節)。請注意,這種設置相當粗糙:它通常會導致 Gemini 2.5/3 Pro 不進行推理,但這會以不可預測的方式取決於提示詞(模板)(對於某些版本的提示模板,它只有 1% 的時間會推理,而對於其他版本,推理比例超過 50%)。如果模型進行了推理(返回了思考欄位),我會重試最多 5 次,並在它使用了思考過程時將該回答視為錯誤。目前尚不清楚 OpenRouter 如何在 Gemini 模型上執行預填(Google API 並不直接支持此功能),可能發生了一些奇怪的情況。
Gemini 的結果有可能無效,因為 OpenRouter 有時可能在模型實際進行了推理的情況下不返回推理內容(導致我們錯誤地將輸出視為有效,從而高估了表現)。我相當確信這不是一個嚴重的問題,至少對於這些結果而言,因為最終結果非常合理。(我認為由於模型實際進行了推理而導致這些結果高估超過 1 分鐘的概率約為 10%。)更廣泛地說,這些結果與之前的結果不完全具有可比性,因為我使用了 20-shot 提示(使用 20-shot 提示會降低模型推理的頻率),且由於「不推理」對這些模型來說是非常偏離分佈(out-of-distribution)的,表現可能會有所下降。對於某些帶有大量填充標記(計數超過 1000)或多次重複的提示版本,我確實看到了 Gemini 3 Pro 表現的大幅下降。
我發現這兩個模型都從重複/填充中受益。在重複次數為 5 時,Gemini 3 Pro 的時間範圍為 3.8 分鐘,而 Gemini 2.5 Pro 為 2.7 分鐘。(在不重複的情況下,時間範圍分別為 2.8 分鐘和 1.9 分鐘。)
以下是包含 Gemini 2.5 Pro 和 Gemini 3 Pro 的發布日期圖表:
附錄:完整結果表格
時間範圍 - 重複 (Repetitions)
| 模型 | r=1 時間範圍 | r=5 時間範圍 | Δ 時間範圍 |
|---|---|---|---|
| opus-4-5 | 2.6 min | 3.4 min | +0.8 min |
| opus-4 | 1.7 min | 2.3 min | +0.5 min |
| sonnet-4-5 | 1.5 min | 2.0 min | +0.5 min |
| sonnet-4 | 1.2 min | 1.6 min | +0.4 min |
| haiku-3-5 | 0.1 min | 0.2 min | +0.1 min |
| haiku-3 | 0.1 min | 0.1 min | +0.0 min |
| haiku-4-5 | 0.7 min | 0.7 min | +0.0 min |
| gemini-2-5-pro | 2.0 min | 2.8 min | +0.8 min |
| gemini-3-pro | 2.8 min | 3.8 min | +1.0 min |
| gpt-3.5 | 0.1 min | 0.1 min | -0.0 min |
| gpt-4 | 0.4 min | 0.4 min | -0.0 min |
| gpt-4o | 0.5 min | 0.6 min | +0.0 min |
| gpt-4.1 | 0.5 min | 0.7 min | +0.1 min |
| gpt-5.1 | 0.6 min | 0.5 min | -0.1 min |
| gpt-5.2 | 1.0 min | 1.2 min | +0.2 min |
| deepseek-v3 | 0.9 min | 1.1 min | +0.1 min |
| qwen3-235b-a22b | 1.2 min | 1.5 min | +0.3 min |
| opus-3 | 0.5 min | 0.7 min | +0.2 min |
| sonnet-3-5 | 0.6 min | 0.9 min | +0.2 min |
| sonnet-3-6 | 0.6 min | 0.8 min | +0.2 min |
| sonnet-3-7 | 0.7 min | 0.9 min | +0.2 min |
時間範圍 - 填充 (Filler)
| 模型 | f=0 時間範圍 | f=300 時間範圍 | Δ 時間範圍 |
|---|---|---|---|
| opus-4-5 | 2.6 min | 3.4 min | +0.8 min |
| opus-4 | 1.7 min | 2.5 min | +0.7 min |
| sonnet-4-5 | 1.5 min | 1.8 min | +0.3 min |
| sonnet-4 | 1.2 min | 1.6 min | +0.4 min |
| haiku-3-5 | 0.1 min | 0.2 min | +0.1 min |
| haiku-3 | 0.1 min | 0.2 min | +0.0 min |
| haiku-4-5 | 0.7 min | 0.7 min | -0.0 min |
| gemini-2-5-pro | 2.0 min | 2.7 min | +0.7 min |
| gemini-3-pro | 2.7 min | 3.7 min | +1.0 min |
| gpt-3.5 | 0.1 min | 0.1 min | -0.0 min |
| gpt-4 | 0.4 min | 0.4 min | -0.0 min |
| gpt-4o | 0.5 min | 0.5 min | -0.1 min |
| gpt-4.1 | 0.5 min | 0.6 min | +0.1 min |
| gpt-5.1 | 0.6 min | 0.5 min | -0.1 min |
| gpt-5.2 | 1.0 min | 1.1 min | +0.1 min |
| deepseek-v3 | 0.9 min | 1.1 min | +0.2 min |
| qwen3-235b-a22b | 1.2 min | 1.2 min | +0.1 min |
難度評級由 Opus 4.5 進行,1 對應簡單的應用題,5 對應具挑戰性的初中問題,8 為典型的 AIME 問題。 ↩︎
或填充標記,它們在這個數據集上的表現相似。 ↩︎
相關文章