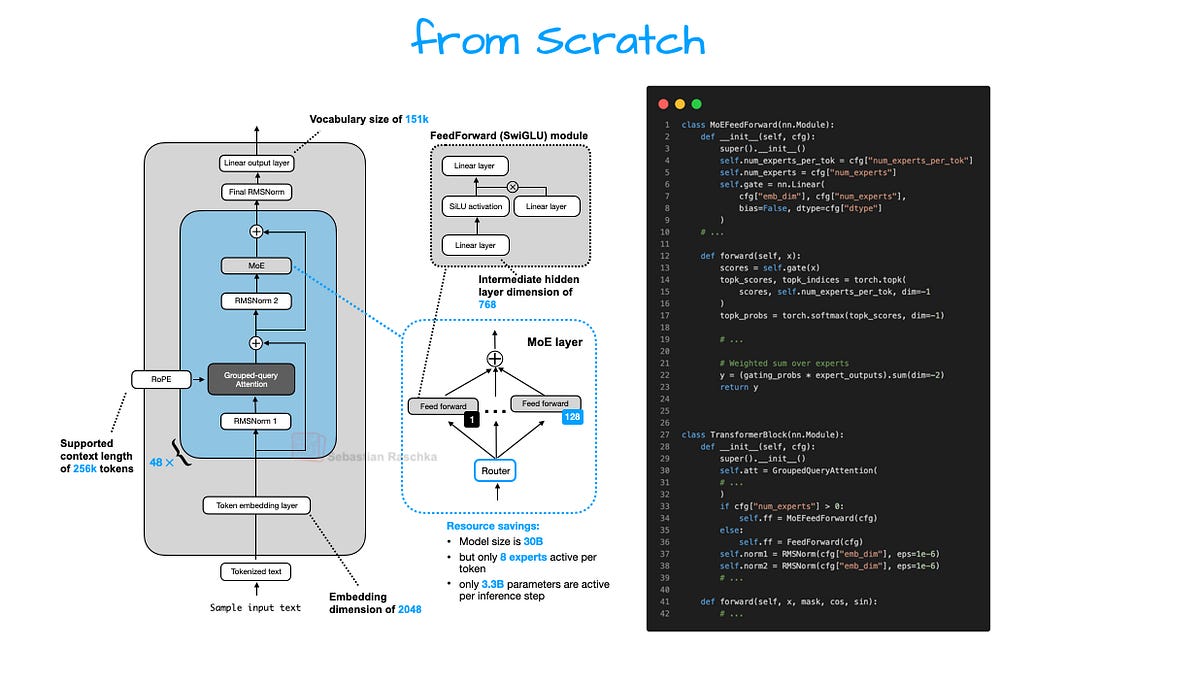
從零開始理解與實作 Qwen3
我將透過純 PyTorch 的程式碼實作,帶領大家深入探討 Qwen3 這款領先開源大語言模型家族的架構,幫助你理解其底層運作原理並獲得可用於自身實驗的構建模組。
從零開始理解與實作 Qwen3
深入剖析領先的開源大語言模型之一
先前,我在《大型大語言模型架構大比拼》中比較了 2025 年最受矚目的開源權重架構。接著,我在《從 GPT-2 到 gpt-oss:分析架構演進》中,從概念層面深入探討了各種架構組件。
俗話說「事不過三」,在介紹今年夏天一些值得關注的研究亮點之前,我想現在就透過程式碼動手深入研究這些架構。透過跟隨本文,你將了解其底層的實際運作方式,並獲得可用於自己實驗或專案的構建模組。
為此,我選擇了 Qwen3(最初於 5 月發布,並於 7 月更新),因為截至本文撰寫時,它是最受歡迎且被廣泛使用的開源權重模型系列之一。
我認為 Qwen3 模型如此受歡迎的原因如下:
對開發者和商業友好的開源協議(Apache License v2.0),除了原始開源許可條款外沒有任何附加條件(其他一些開源權重 LLM 會施加額外的使用限制)。
性能非常出色;例如,截至本文撰寫時,開源權重的 235B-Instruct 版本在 LMArena 排行榜上排名第 8,與封閉原始碼的 Claude Opus 4 並列。僅有的另外兩個排名更高的開源權重 LLM 是 DeepSeek 3.1(體積大 3 倍)和 Kimi K2(體積大 4 倍)。9 月 5 日,Qwen3 在其平台上發布了 1T 參數的「max」版本,在所有主要基準測試中都擊敗了 Kimi K2、DeepSeek 3.1 和 Claude Opus 4;不過,該模型目前尚未開源。
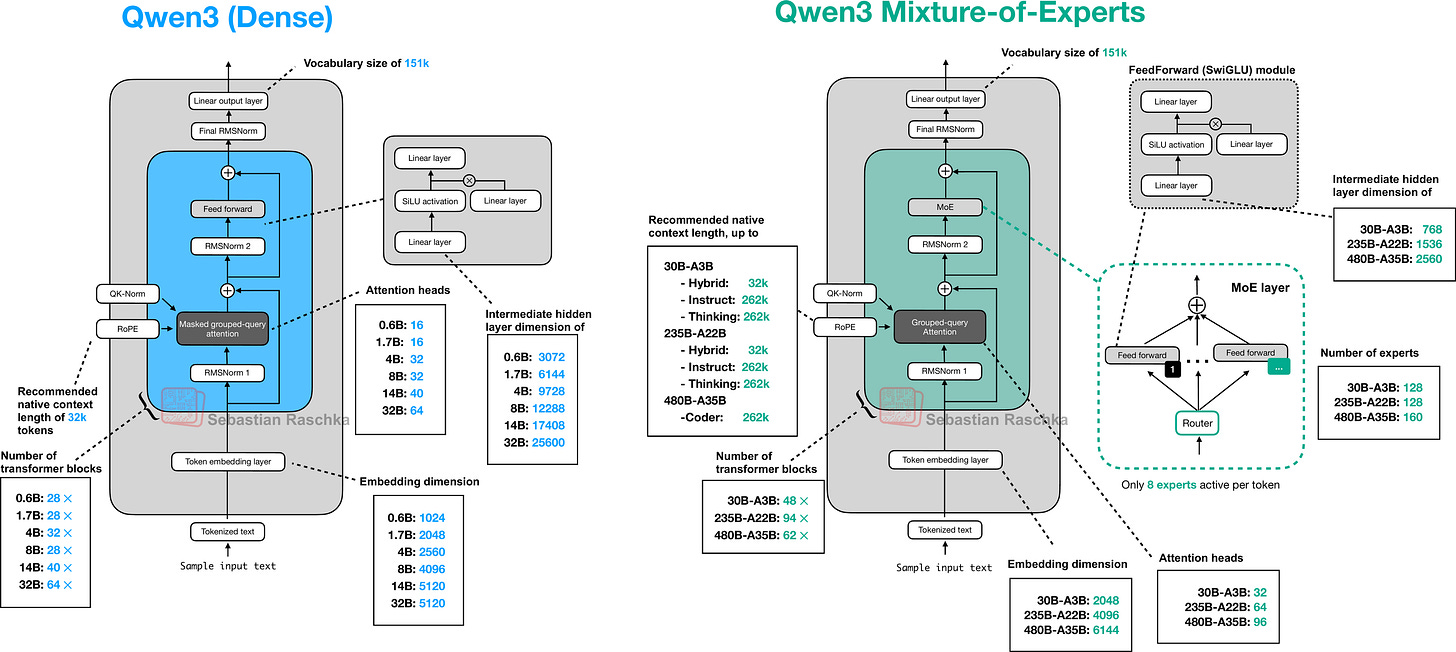
提供多種不同的模型尺寸,以適應不同的運算預算和使用場景,從 0.6B 的稠密模型到 480B 參數的混合專家(Mixture-of-Experts)模型應有盡有。
由於包含純 PyTorch 的從零開始程式碼,這將是一篇長篇文章。雖然程式碼部分看起來可能很冗長,但我希望它們能比單純的概念圖表更好地解釋這些構建模組!
提示 1:如果你是在電子郵件收件匣中閱讀本文,較窄的行寬可能會導致程式碼片段換行不自然。為了獲得更好的體驗,我建議在網頁瀏覽器中打開它。
提示 2:你可以使用網站左側的目錄,以便在各個章節之間輕鬆導航。
本文僅限付費訂閱者閱讀
相關文章