DeepSeek 模型技術巡禮:從 V3 到 V3.2 的架構、稀疏注意力與強化學習更新
這篇文章深入探討了 DeepSeek 旗艦模型的技術演進,分析了如 MLA 與 MoE 等架構創新,以及該系列如何從專用的推理模型轉型為高效能的混合模型。
從 DeepSeek V3 到 V3.2:架構、稀疏注意力與 RL 更新
深入了解 DeepSeek 旗艦級開源權重模型的演進歷程
最後更新日期:2026 年 1 月 1 日
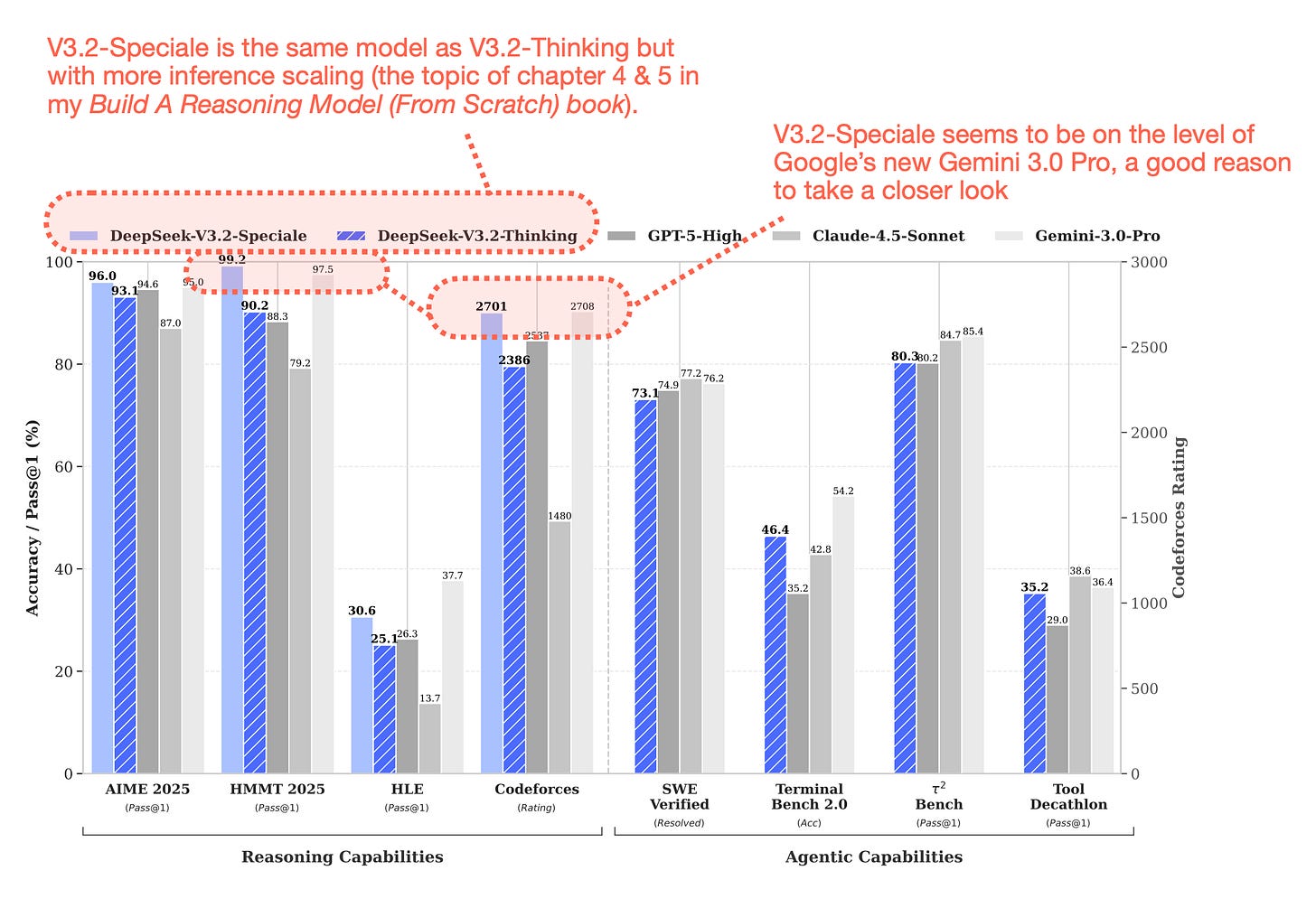
與 DeepSeek V3 類似,該團隊在美國重大節假日週末發佈了新的旗艦模型。鑑於 DeepSeek V3.2 表現極佳(達到 GPT-5 和 Gemini 3.0 Pro 水準),且同樣作為開源權重模型釋出,絕對值得深入探究。
我在《大型 LLM 架構大比拼》文章伊始就介紹過其前身 DeepSeek V3,隨著新架構的發佈,我在過去幾個月中不斷擴充該文。原本我打算在感恩節假期結束後,「僅僅」透過增加一個章節來擴展該文章以涵蓋 DeepSeek V3.2,但我隨後意識到其中有太多有趣的資訊值得探討,因此決定將其寫成一篇更詳盡的獨立文章。
技術報告中有許多有趣的領域值得探索和學習,讓我們開始吧!
1. DeepSeek 發佈時間線
雖然 DeepSeek V3 在 2024 年 12 月發佈之初並未立即走紅,但隨後推出的 DeepSeek R1 推理模型(基於相同架構,以 DeepSeek V3 為基礎模型)幫助 DeepSeek 成為最受歡迎的開源權重模型之一,並成為 OpenAI、Google、xAI 和 Anthropic 等公司專有模型的有力替代方案。
那麼,自 V3/R1 以來有什麼新變化?我確信 DeepSeek 團隊這一年非常忙碌。然而,自 DeepSeek R1 以來的 10 到 11 個月內,一直沒有重大版本發佈。
就個人而言,我認為重大 LLM 版本的發佈週期約為 1 年是合理的,因為這涉及大量工作。然而,我在各大社交媒體平台上看到有人宣稱該團隊已經「江郎才盡」(只是曇花一現)。
我也確信 DeepSeek 團隊一直忙於處理從 NVIDIA 晶片切換到華為晶片的事宜。順帶一提,我與他們並無關聯,也未曾與他們交談;這裡的一切資訊均基於公開資料。據我所知,他們現在已恢復使用 NVIDIA 晶片。
最後,他們並非完全沒有發佈任何東西。今年陸續有一些較小的版本釋出,例如 DeepSeek V3.1 和 V3.2-Exp。
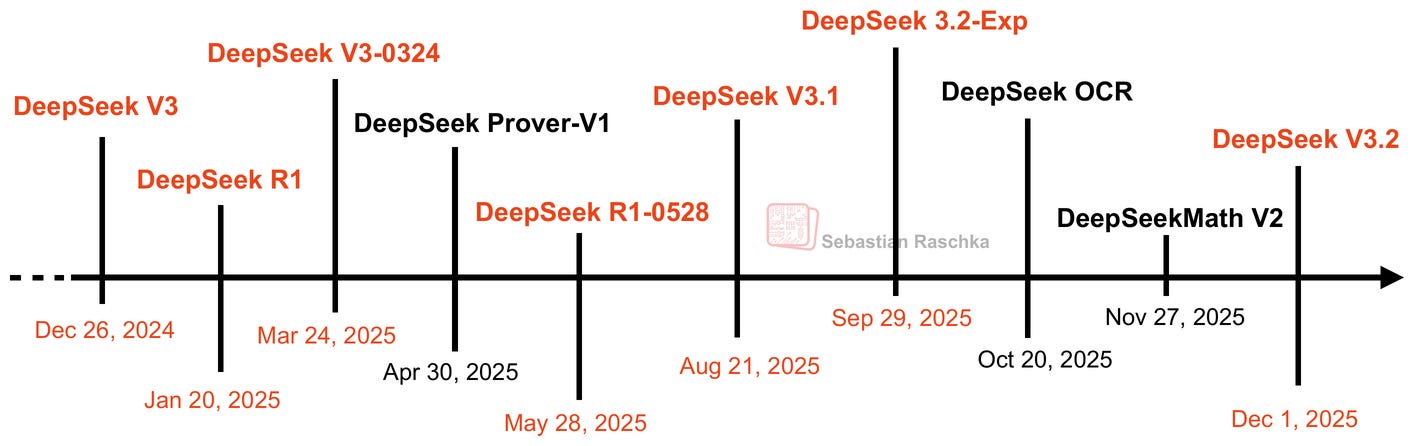
正如我在 9 月份預測的那樣,DeepSeek V3.2-Exp 的發佈旨在讓生態系統和推理基礎設施為託管剛發佈的 V3.2 模型做好準備。
V3.2-Exp 和 V3.2 使用了一種非標準的稀疏注意力(Sparse Attention)變體,需要自定義代碼,稍後會詳細介紹此機制。(我曾想在之前的《超越標準 LLM》文章中介紹它,但當時 Kimi Linear 發佈了,所以我優先將其放在該文關於新注意力變體的章節中。)
2. 混合模型與專用推理模型
在進一步討論模型細節之前,討論整體的模型類型或許是有價值的。最初,DeepSeek V3 作為基礎模型發佈,而 DeepSeek R1 則透過額外的後訓練(Post-training)開發成專用的推理模型。此過程總結如下圖。
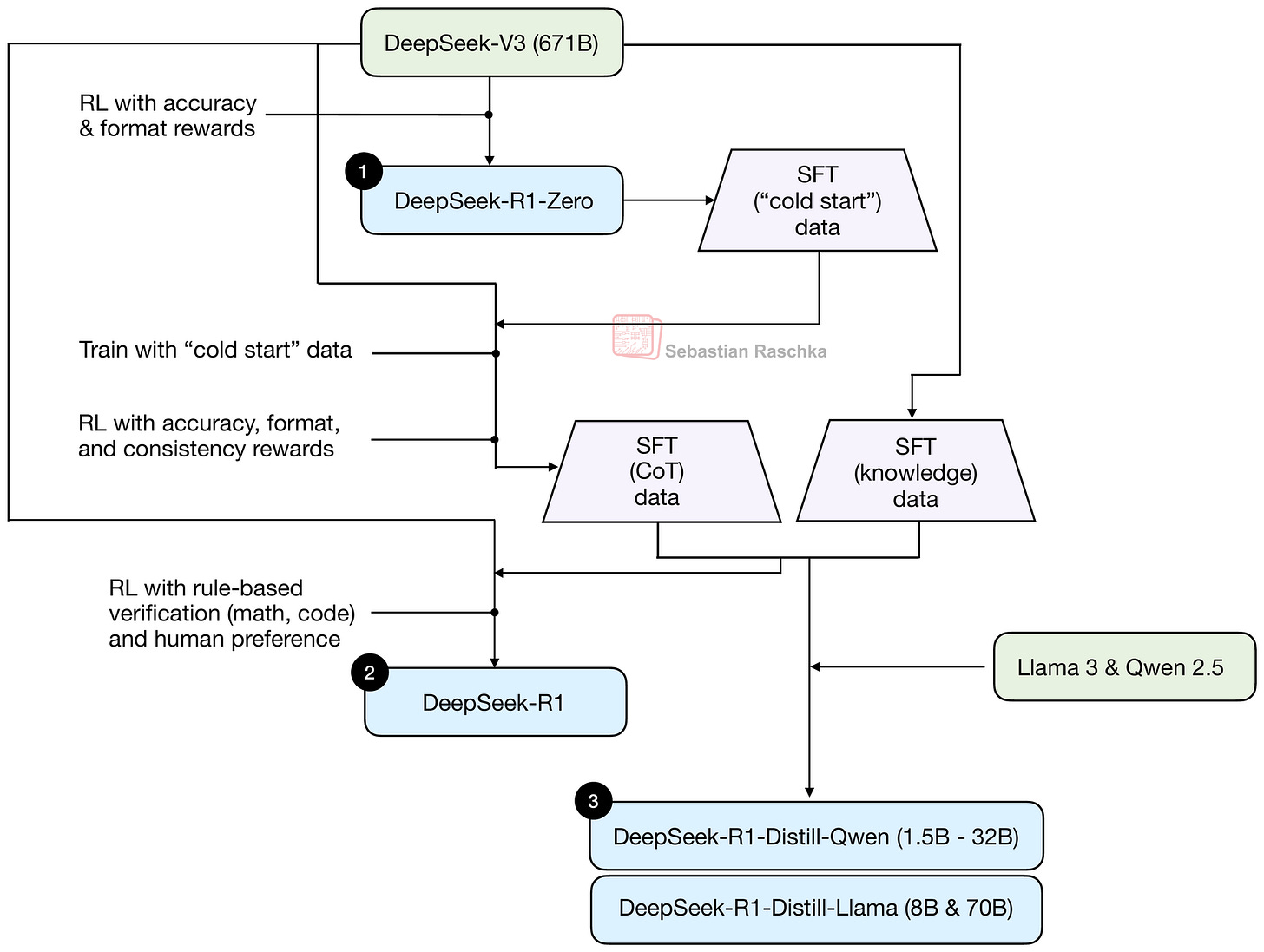
您可以在我的《理解推理 LLM》文章中閱讀更多關於上圖訓練流水線的內容。
這裡值得注意的是,DeepSeek V3 是一個基礎模型,而 DeepSeek R1 是一個專用的推理模型。
與 DeepSeek 並行的其他團隊也發佈了許多非常強大的開源推理模型。今年最強大的開源模型之一是 Qwen3。最初,它作為混合推理模型發佈,這意味著用戶可以在同一個模型中切換推理和非推理模式。(在 Qwen3 的案例中,這種切換是透過分詞器添加或省略 <think></think> 標籤來實現的。)
從那以後,LLM 團隊陸續發佈了(在某些情況下在兩者之間反覆切換)專用推理模型和指令/推理混合模型,如下面的時間線所示。
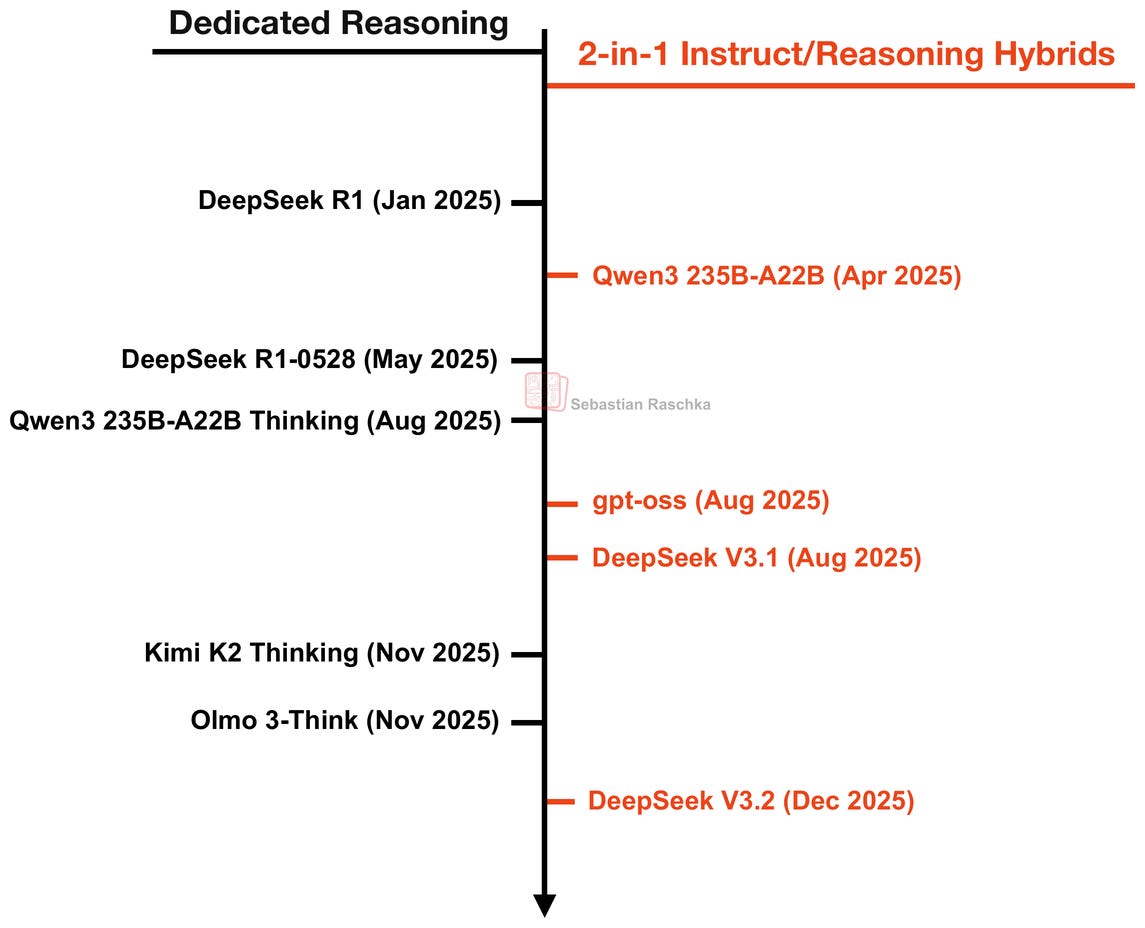
例如,Qwen3 最初是混合模型,但 Qwen 團隊後來發佈了獨立的指令和推理模型,因為它們更容易開發,且在各自的應用場景中表現更好。
某些模型(如 OpenAI 的 gpt-oss)僅提供混合變體,用戶可以透過系統提示詞選擇推理強度(我懷疑 GPT-5 和 GPT-5.1 也是類似處理)。
而在 DeepSeek 的案例中,看起來他們正朝著相反的方向發展:從專用推理模型 (R1) 轉向混合模型 (V3.1 和 V3.2)。然而,我懷疑 R1 主要是為了開發推理方法和當時最佳推理模型的研發項目。V3.2 的發佈可能更多是為了針對不同用例開發最佳的綜合模型。(在這裡,R1 更像是一個試驗場或原型模型。)
我還懷疑,雖然 DeepSeek 團隊開發了具備推理能力的 V3.1 和 V3.2,但他們可能仍在研發專用的 R2 模型。
3. 從 DeepSeek V3 到 V3.1
在詳細討論新的 DeepSeek V3.2 之前,我認為先概述從 V3 到 V3.1 的主要變化會很有幫助。
3.1 DeepSeek V3 概述與多頭潛在注意力 (MLA)
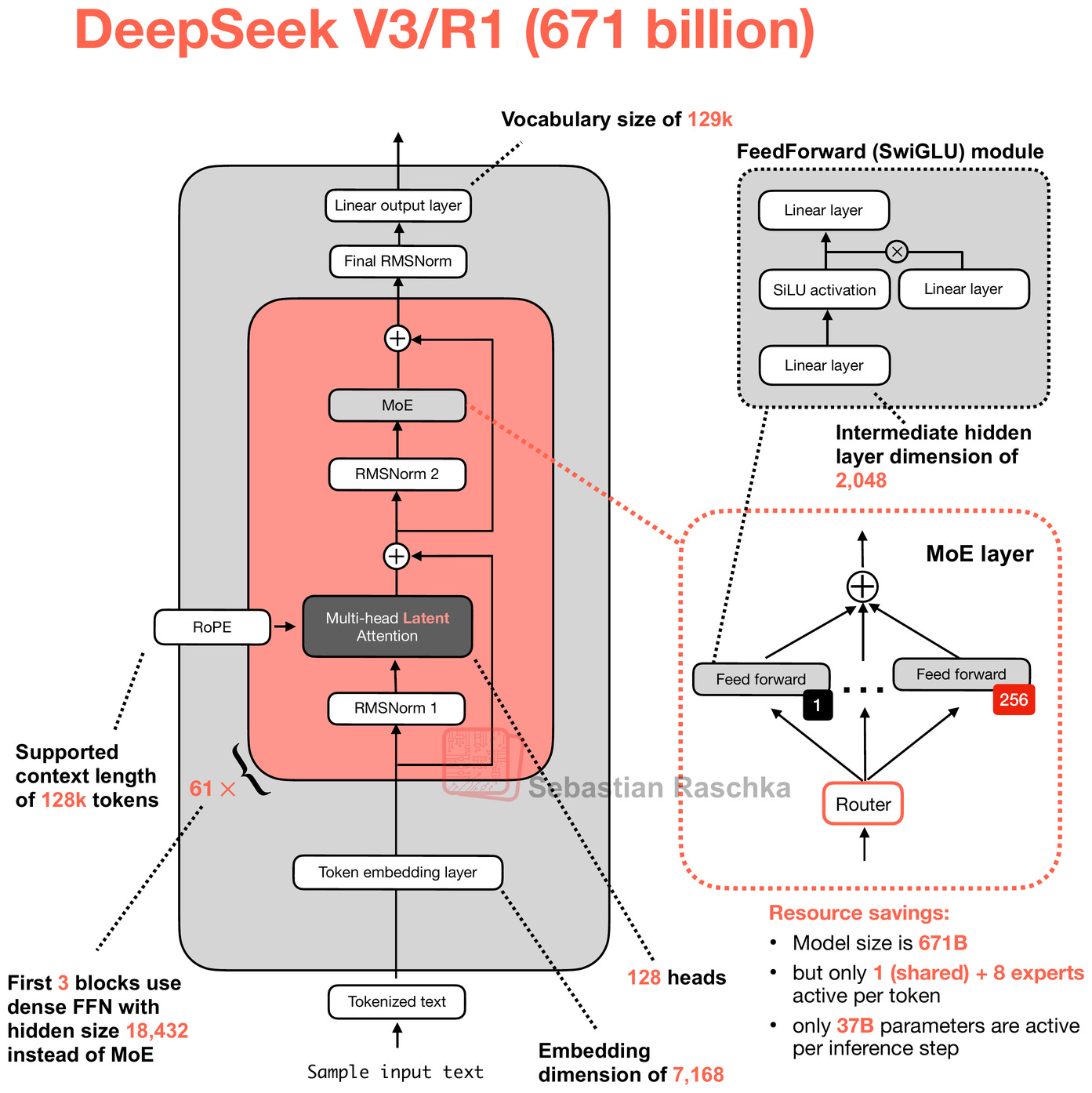
我已經在其他幾篇文章中詳細討論過 DeepSeek V3 和 R1。總結其要點,DeepSeek V3 是一個基礎模型,使用了兩個值得注意的架構特性:混合專家模型 (MoE) 和多頭潛在注意力 (Multi-Head Latent Attention, MLA)。
我想您現在對 MoE 應該已經非常熟悉了,所以這裡跳過介紹。如果您想了解更多,建議閱讀我《大型架構大比拼》文章中的簡短概述。
另一個值得關注的亮點是 MLA 的使用。MLA 用於 DeepSeek V2、V3 和 R1,提供了一種節省記憶體的策略,特別適合與 KV 快取配合使用。MLA 的核心思想是在將鍵(Key)和值(Value)張量存入 KV 快取之前,先將其壓縮到低維空間。
在推理時,這些壓縮後的張量在被使用前會被投影回原始大小,如下圖所示。這增加了一次矩陣乘法,但減少了記憶體使用。
(順帶一提,查詢(Query)也會被壓縮,但僅在訓練期間,而非推理期間。)
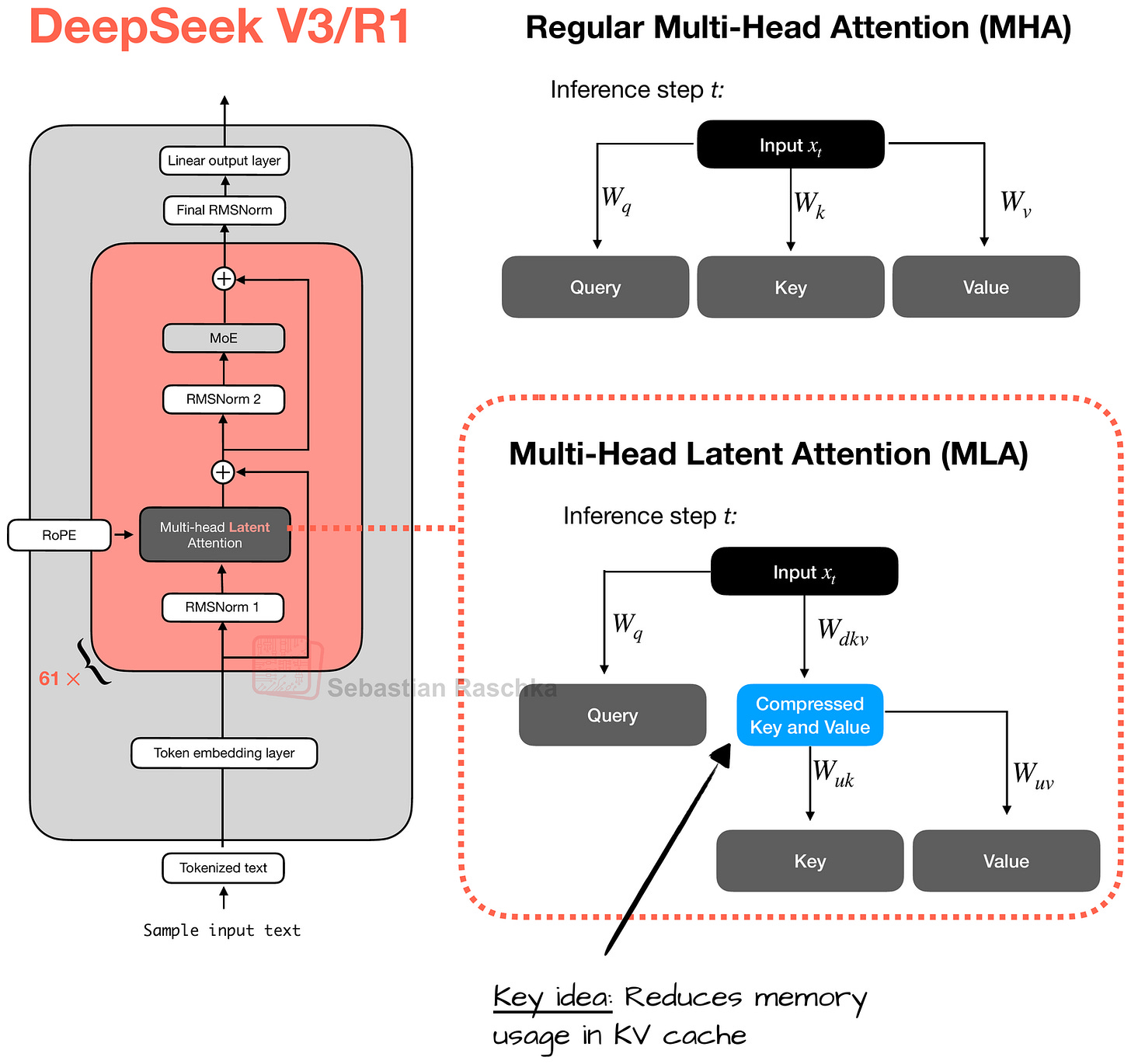
上圖說明了 MLA 的核心思想:鍵和值首先被投影到潛在向量中,然後可以存儲在 KV 快取中以減少記憶體需求。這需要隨後向上投影回原始的鍵值空間,但總體上提高了效率(類比來說,您可以將其想像為 LoRA 中的向下和向上投影)。
請注意,查詢也會被投影到一個單獨的壓縮空間,與鍵和值所示類似。為了簡化,我在上圖中省略了它。
順便說一句,MLA 在 DeepSeek V3 中並非新技術,因為其前身 DeepSeek V2 已經使用(甚至引入)了它。
3.2 DeepSeek R1 概述與可驗證獎勵的強化學習 (RLVR)
DeepSeek R1 使用與上述 DeepSeek V3 相同的架構。區別在於訓練配方。也就是說,以 DeepSeek V3 為基礎模型,DeepSeek R1 專注於使用可驗證獎勵的強化學習 (Reinforcement Learning with Verifiable Rewards, RLVR) 方法來提高模型的推理能力。
RLVR 的核心思想是讓模型從可以透過符號或程式驗證的回答中學習,例如數學和代碼(當然,這也可以擴展到這兩個領域之外)。
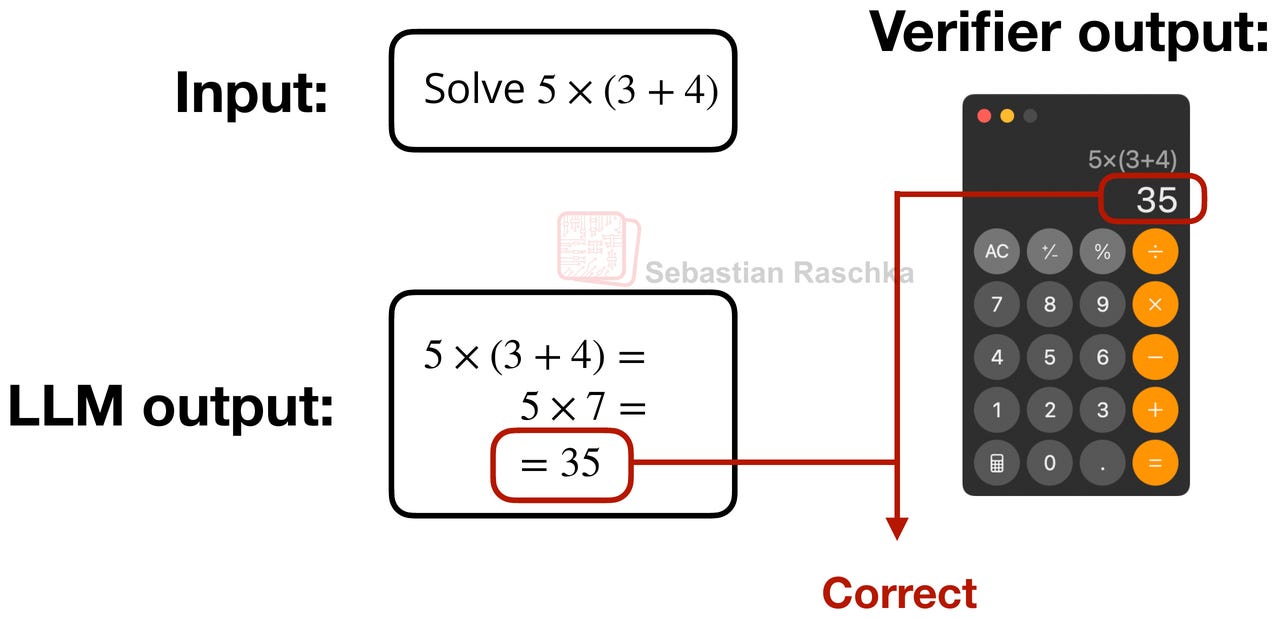
GRPO 算法(全稱 Group Relative Policy Optimization)本質上是近端策略優化 (PPO) 算法的一種更簡單變體,後者在人類回饋強化學習 (RLHF) 中非常流行,用於 LLM 對齊。
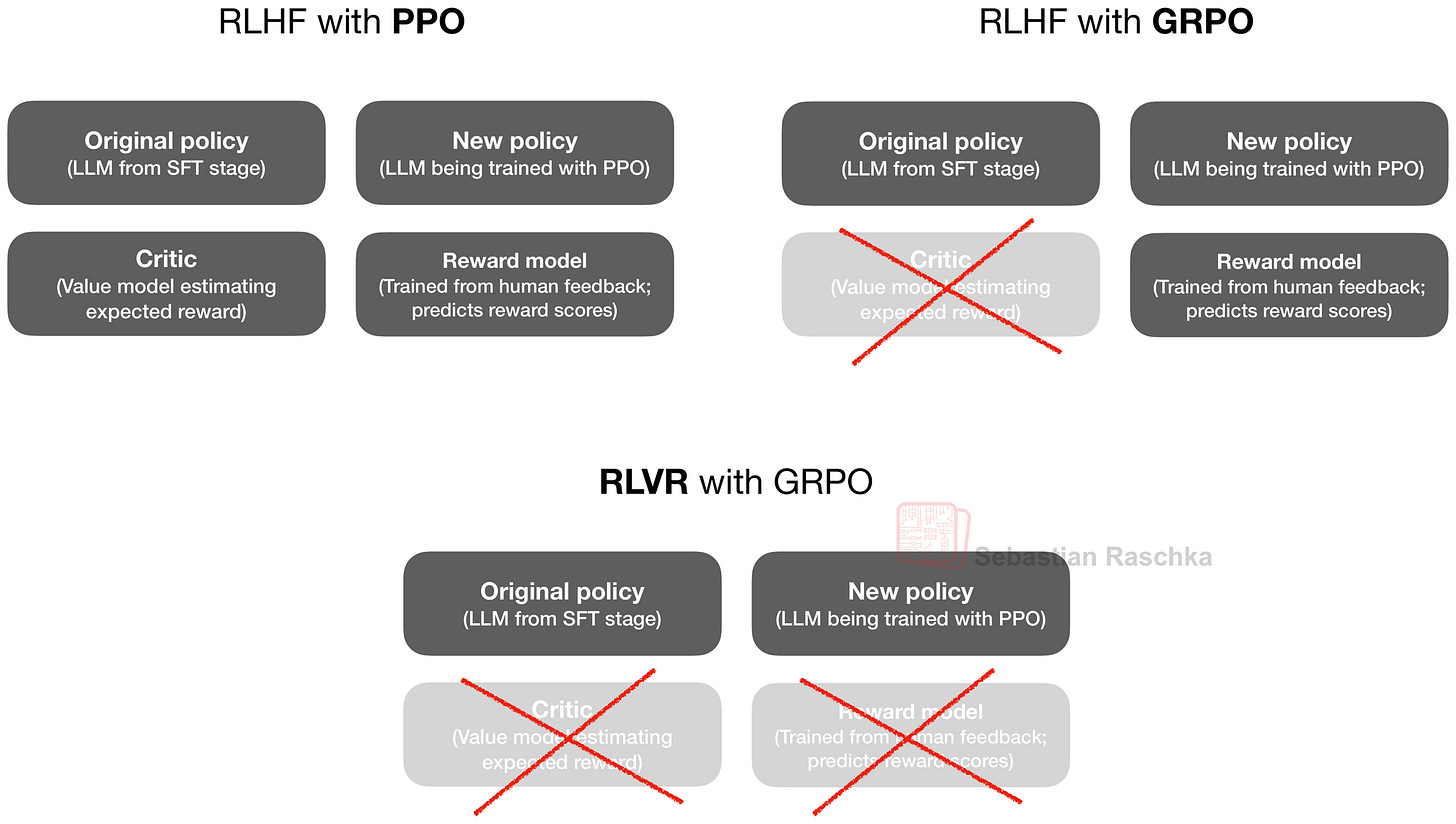
如果您對更多資訊感興趣,我在《LLM 推理強化學習現狀》中更詳細地介紹了 RLVR 訓練及其 GRPO 算法(包括背後的數學原理)。
3.3 DeepSeek R1-0528 版本升級
正如 DeepSeek 團隊自己所述,DeepSeek R1-0528 基本上是一個「小版本升級」。
架構與 DeepSeek V3/R1 保持一致,改進主要在訓練端,使其與當時的 OpenAI o3 和 Gemini 2.5 Pro 旗鼓相當。
遺憾的是,DeepSeek 團隊並未發佈描述如何實現這一點的具體資訊;然而,他們表示這部分歸功於後訓練流水線的優化。此外,根據已分享的資訊,我認為託管版本的模型在推理時可能使用了更多計算資源(更長的推理過程)。
3.4 DeepSeek V3.1 混合推理
DeepSeek V3.1 是一個兼具通用對話(指令)和推理能力的混合模型。也就是說,現在不再開發兩個獨立的模型,而是透過對話提示模板切換模式的單一模型(類似於最初的 Qwen3 模型)。
DeepSeek V3.1 基於 DeepSeek V3.1-Base,而後者又基於 DeepSeek V3。它們都共享相同的架構。
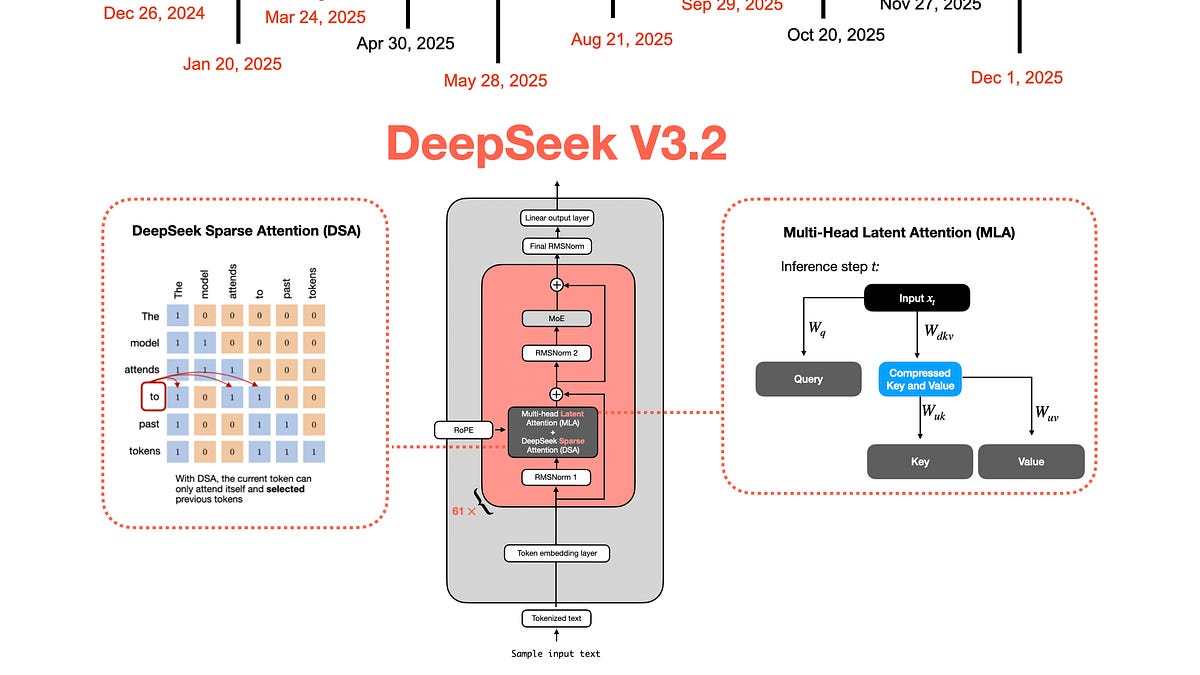
4. DeepSeek V3.2-Exp 與稀疏注意力
DeepSeek V3.2-Exp(2025 年 9 月)是事情變得更有趣的地方。
最初,DeepSeek V3.2-Exp 並未在基準測試中奪冠,這也是為什麼該模型發佈時並未引起太大轟動。然而,正如我在 9 月份推測的那樣,這可能是一個早期的實驗性版本,目的是讓基礎設施(特別是推理和部署工具)為更大規模的發佈做好準備,因為 DeepSeek V3.2-Exp 在架構上有一些變化。更大的發佈是 DeepSeek V3.2(而非 V4),稍後會詳細說明。
那麼,DeepSeek V3.2-Exp 有什麼新東西?首先,DeepSeek V3.2-Exp 是以 DeepSeek V3.1-Terminus 為基礎模型訓練的。什麼是 DeepSeek V3.1-Terminus?它只是對前一節提到的 DeepSeek V3.1 檢查點的一個小改進。
技術報告指出:
DeepSeek-V3.2-Exp 是一個實驗性的稀疏注意力模型,它透過持續訓練為 DeepSeek-V3.1-Terminus 配備了 DeepSeek 稀疏注意力 (DSA)。憑藉由閃電索引器(lightning indexer)驅動的細粒度稀疏注意力機制,DeepSeek-V3.2-Exp 在訓練和推理效率方面都取得了顯著提升,特別是在長文本場景中。
如上段所述,這裡的主要創新是在對該檢查點進行進一步訓練之前,加入了 DeepSeek 稀疏注意力 (DSA) 機制。
這種 DSA 由 (1) 閃電索引器和 (2) 標記選擇器(token-selector)組成,目標是有選擇地減少上下文以提高效率。
為了說明其工作原理,讓我們從滑動窗口注意力(sliding-window attention)開始。例如,滑動窗口注意力是一種技術(最近被 Gemma 3 和 Olmo 3 使用),它將注意力窗口限制在固定大小,如下圖所示。
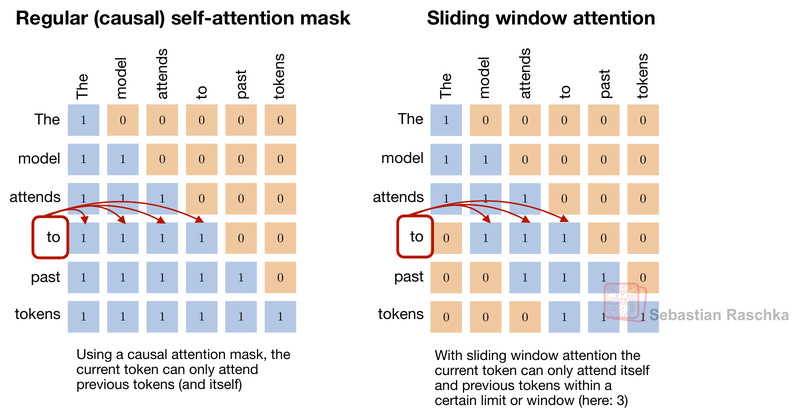
DSA 基於與滑動窗口注意力相同的想法:僅能關注過去標記的一個子集。然而,DSA 並非透過固定寬度的滑動窗口來選擇可關注的標記,而是透過索引器和標記選擇器來決定可以關注哪些過去的標記。換句話說,可以關注的標記更具隨機性,如下圖所示。
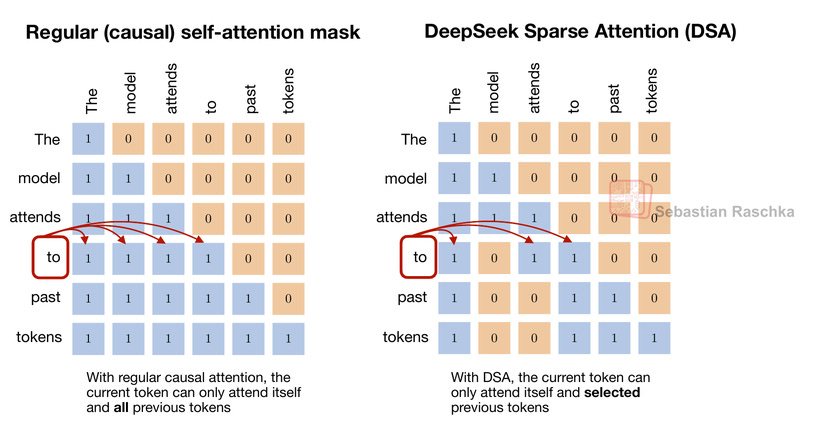
然而,雖然我上面說了「隨機」,但選擇哪些過去標記的模式實際上並非隨機,而是學習得來的。
在實踐中,DSA 使用其所謂的閃電索引器,根據所有先前的標記為每個新查詢標記計算相關性得分。在計算過程中,閃電索引器利用 DeepSeek 多頭潛在注意力 (MLA) 中的壓縮標記表示,並計算與其他標記的相似度。相似度得分基本上是經過 ReLU 函數處理的查詢向量與鍵向量之間的縮放點積。
如果您對數學細節感興趣,下面顯示了該閃電索引器相似度得分的等式(取自論文):
在這裡,w 是一個學習到的逐頭權重係數,決定了每個索引器頭對最終相似度得分的貢獻程度。q 代表查詢,k 代表鍵向量。以下是不同下標的含義:
t:當前查詢標記的位置;
s:序列中先前標記的位置 (0 ≤ s < t);
j:不同索引器頭的索引(上圖 10 為了簡化僅顯示了一個頭),因此 qt, j 意味著「索引器頭 j 中當前標記 t 的查詢向量」。
您可能會注意到索引器僅針對查詢,而非鍵。這是因為模型只需要決定每個新查詢應考慮哪些過去的標記。鍵已經被壓縮並存儲在 KV 快取中,因此索引器不需要在不同頭上再次對其進行評分或壓縮。
這裡的 ReLU 函數,由於其定義為 f(x) = max(x, 0),會將負點積位置歸零,理論上可以實現稀疏性,但由於存在跨不同頭的求和,索引器得分實際上不太可能為 0。稀疏性更多來自於獨立的標記選擇器。
獨立的標記選擇器僅保留少量高分標記(例如 top-k 位置),並構建一個稀疏注意力掩碼,將未包含在所選子集中的其他標記屏蔽掉。(top-k 中的 k 不要與上述等式中用於鍵的 k 混淆,它是一個超參數,在 DeepSeek 團隊分享的模型代碼中設置為 2048。)
下圖以流程圖形式說明了整個過程。
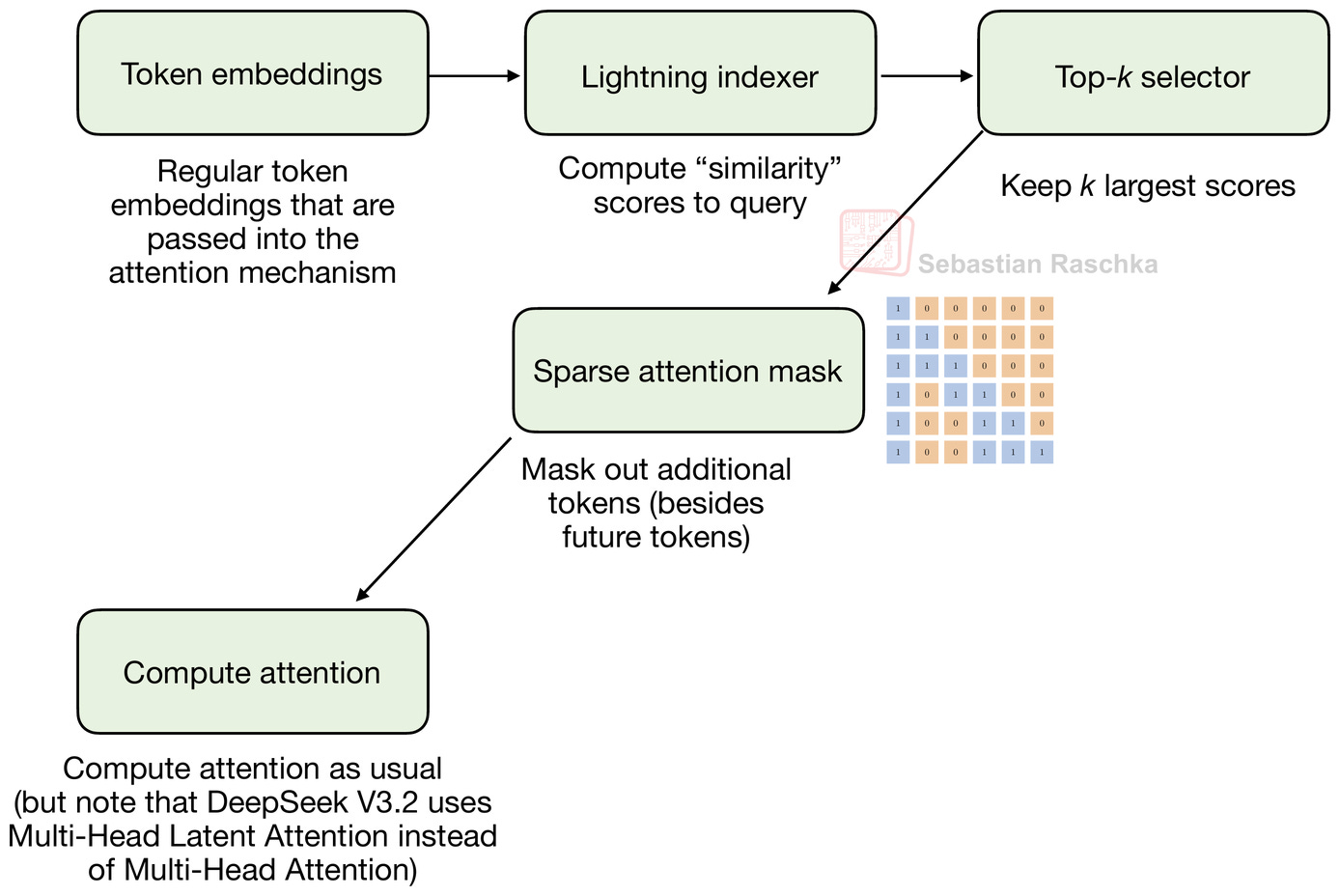
總結來說,索引器和標記選擇器的結果是讓每個標記關注模型學習到認為最相關的少數過去標記,而不是所有標記或固定的局部窗口。
這裡的目標不是提高相對於 DeepSeek V3.1-Terminus 的性能,而是在受益於效率提升的同時,減少(由於稀疏注意力機制導致的)性能退化。
總體而言,DSA 將注意力機制的計算複雜度從二次方 O(𝐿²)(L 為序列長度)降低到線性 O(𝐿𝑘)(𝑘 ≪ 𝐿 為所選標記的數量)。
5. 具備自我驗證與自我修正能力的 DeepSeekMath V2
在討論完 DeepSeek V3.2-Exp 後,我們正接近本文的主題:DeepSeek V3.2。不過,還有最後一塊拼圖需要先討論。
2025 年 11 月 27 日(美國感恩節),就在 DeepSeek V3.2 發佈前 4 天,DeepSeek 團隊發佈了基於 DeepSeek V3.2-Exp-Base 的 DeepSeekMath V2。
該模型專為數學開發,並在多項數學競賽中獲得了金牌級得分。本質上,我們可以將其視為 DeepSeek V3.2 的概念驗證模型,引入了一項新技術。
關鍵點在於,推理模型(如 DeepSeek R1 等)是使用外部驗證器訓練的,模型會自動學習在得出最終答案之前編寫解釋。然而,解釋可能是錯誤的。
正如 DeepSeek 團隊簡潔地指出的常規 RLVR 的缺點:
[...] 正確的答案並不保證正確的推理。
[...] 模型可能透過錯誤的邏輯或僥倖的錯誤得出正確答案。
他們旨在解決的 DeepSeek R1 RLVR 方法的另一個局限性是:
[...] 許多數學任務(如定理證明)需要嚴謹的逐步推導而非數值答案,這使得最終答案獎勵變得不適用。
因此,為了改進上述兩個缺點,他們在本文中訓練了兩個模型:
- 一個基於 LLM 的定理證明驗證器。
- 主模型(證明生成器),使用基於 LLM 的驗證器作為獎勵模型(而非符號驗證器)。
除了上述透過 LLM 進行的自我驗證外,他們還使用了自我修正(Self-refinement,這將在我即將出版的《從頭開始構建推理模型》第 5 章中介紹),讓 LLM 迭代地改進自己的答案。
5.1 自我驗證
讓 LLM 為中間步驟評分並非新概念。有一整套關於所謂過程獎勵模型(process reward models)的研究專注於此。例子包括《透過過程和結果回饋解決數學應用題》(2022) 或《讓我們逐步驗證》(2023) 等。
過程獎勵模型的挑戰在於,檢查中間獎勵是否正確並不容易,而且還可能導致獎勵欺騙(reward hacking)。
在 2025 年 1 月的 DeepSeek R1 論文中,他們沒有使用過程獎勵模型,因為他們發現:
在我們的實驗中,與它在大型強化學習過程中引入的額外計算開銷相比,其優勢有限。
在本文中,他們以自我驗證的形式成功地重新審視了這一點。其動機是,即使不存在參考解決方案,人類在閱讀證明並識別問題時也能自我糾正。
因此,為了開發一個更好的數學證明編寫模型(下圖中的 LLM 1),他們開發了一個證明驗證器(下圖中的 LLM 2),它可以作為 LLM-as-a-judge 來為證明器(LLM 1)的輸出評分。
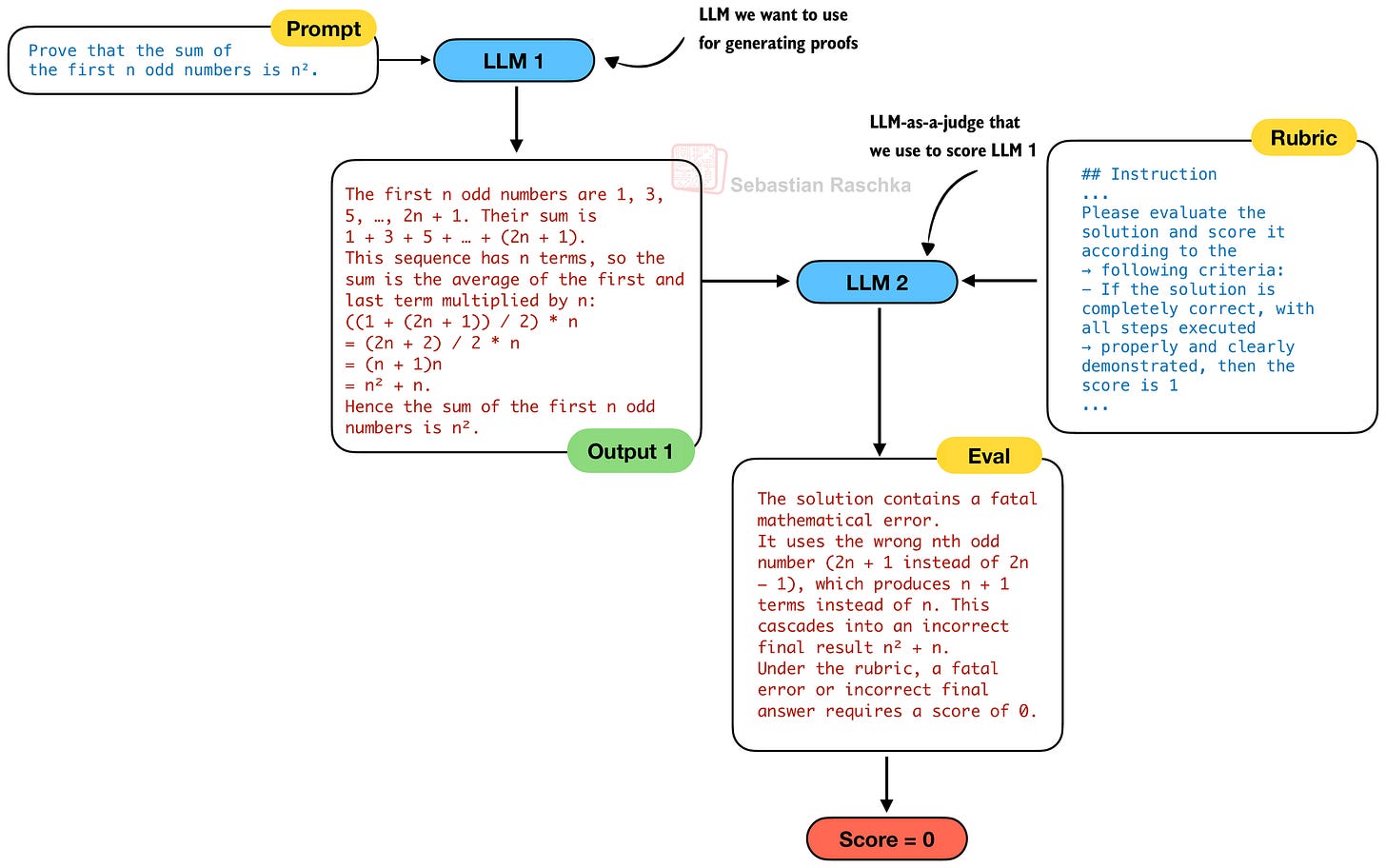
驗證器 LLM (LLM 2) 根據評分標準為生成的證明評分,評分為:
「1 分:完整且嚴謹的證明,所有邏輯步驟均有明確依據;」
「0.5 分:整體邏輯合理但有細微錯誤或遺漏細節的證明;」
「0 分:存在根本性缺陷、包含致命邏輯錯誤或關鍵缺失的證明。」
對於證明驗證器模型,他們從 DeepSeek V3.2-Exp-SFT 開始,這是他們基於 DeepSeek V3.2-Exp 透過對推理數據(數學和代碼)進行監督微調創建的模型。然後,他們使用強化學習進一步訓練該模型,使用格式獎勵(檢查解決方案是否符合預期格式)和基於預測分數與實際分數(由人類數學專家標註)接近程度的分數獎勵。
證明驗證器 (LLM 2) 的目標是檢查生成的證明 (LLM 1),但誰來檢查證明驗證器?為了使證明驗證器更健壯並防止其產生幻覺,他們開發了第三個 LLM:元驗證器(meta-verifier)。
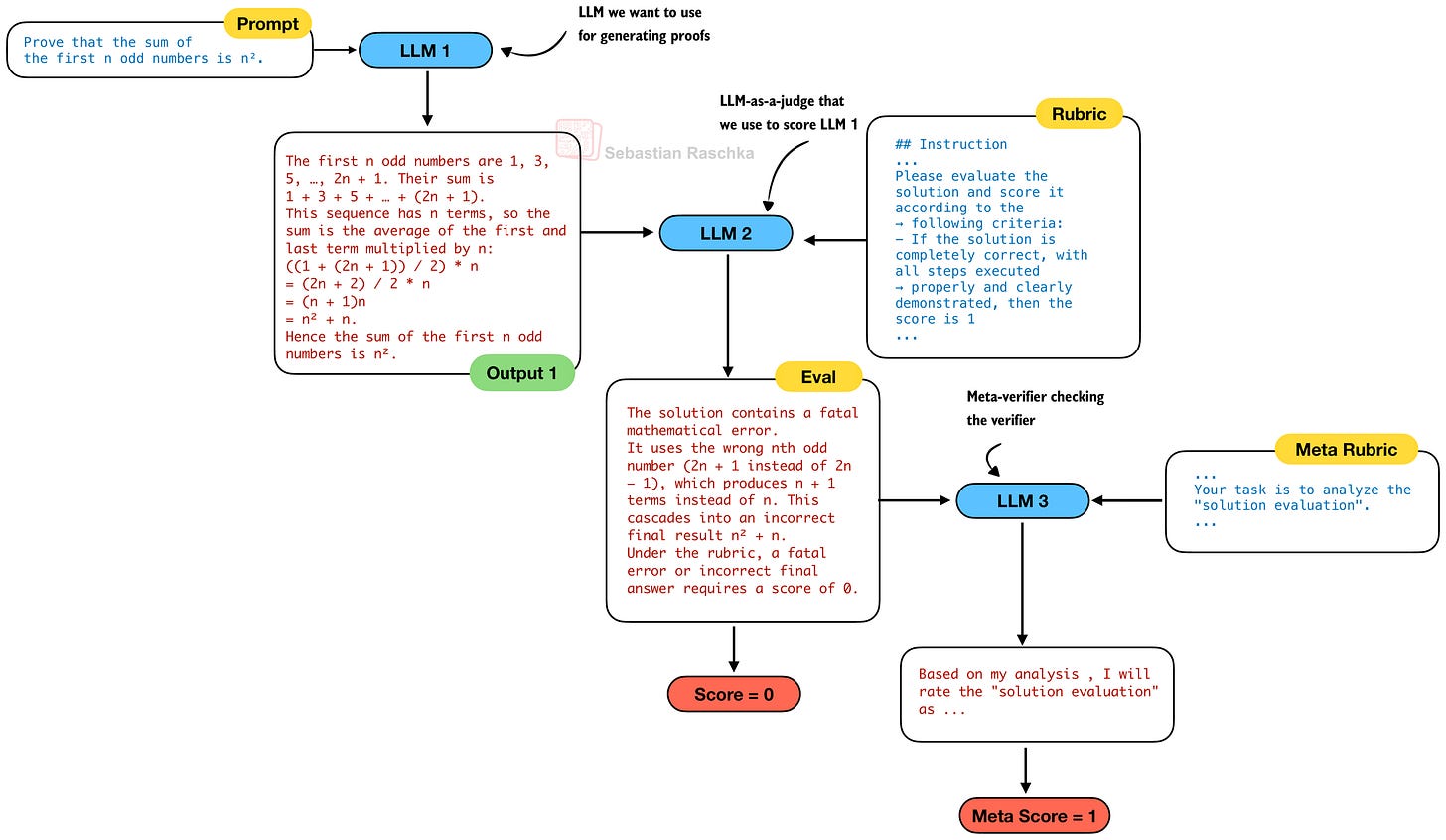
元驗證器 (LLM 3) 也是透過強化學習開發的,與 LLM 2 類似。雖然元驗證器並非必需,但 DeepSeek 團隊報告稱:
經元驗證器評估,驗證器證明分析的平均質量得分從 0.85 提高到 0.96,同時保持了相同的證明分數預測準確性。
這實際上是一個非常有趣的設置。如果您熟悉生成對抗網絡 (GAN),您可能會看到其中的類比。例如,證明驗證器(可以將其視為 GAN 的判別器)改進了證明生成器,而證明生成器生成更好的證明,進一步推動了證明驗證器。
元分數在訓練驗證器 (LLM 2) 和生成器 (LLM 1) 期間使用。它不會在推理時的自我修正循環中使用,我們將在下一節討論這一點。
5.2 自我修正
在上一節中,我們討論了自我驗證,即分析解決方案的質量。其目的是實現自我修正,這意味著 LLM 可以根據回饋採取行動並修改其答案。
傳統上,在自我修正(這是一種成熟且流行的推理擴展技術)中,我們會使用同一個 LLM 來生成解決方案、驗證它,然後進行修正。換句話說,在之前的圖 12 和 13 中,LLM 1 和 LLM 2 將是同一個 LLM。因此,傳統的自我修正過程如下所示:
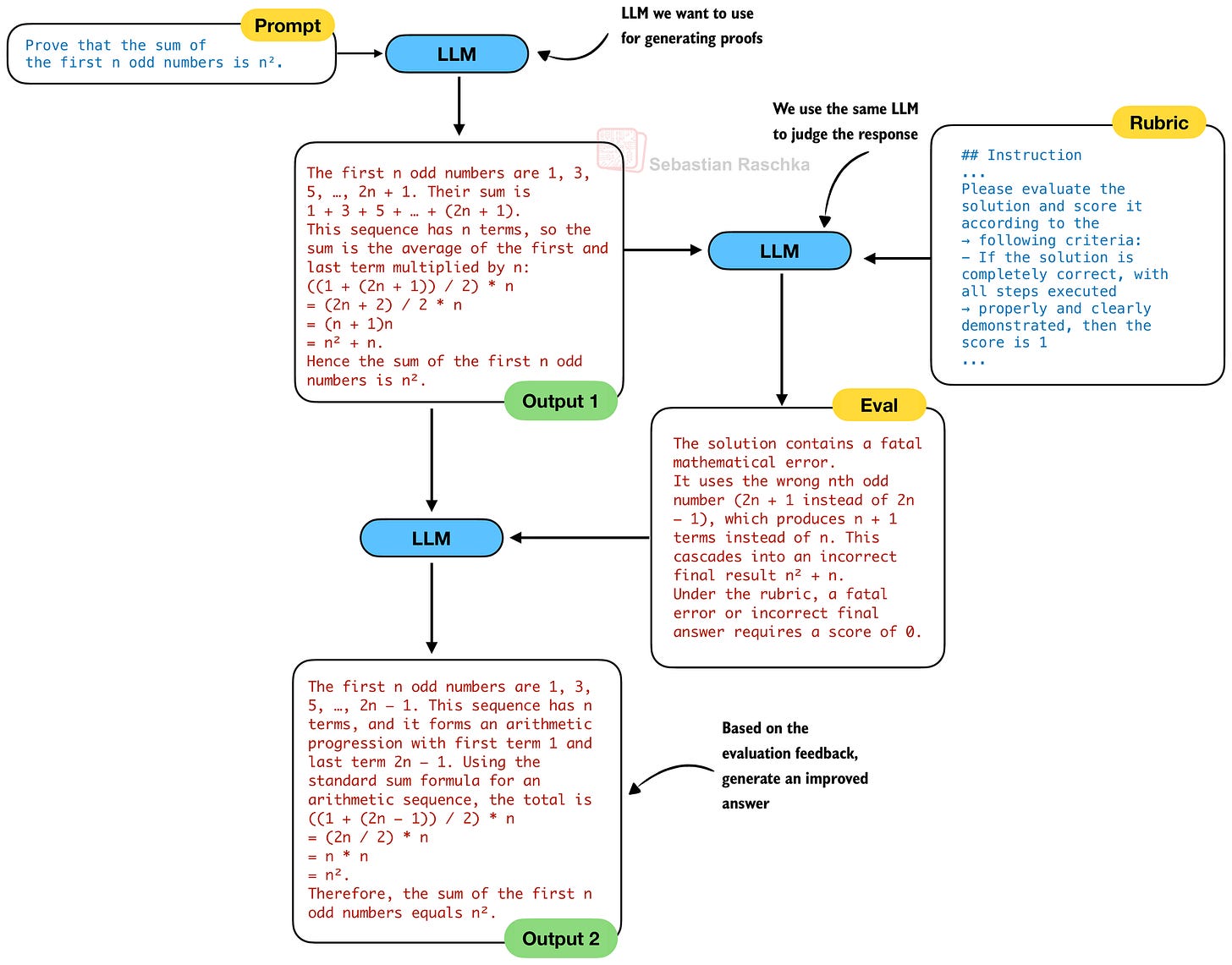
然而,DeepSeek 團隊在實踐中觀察到使用同一個 LLM 進行生成和驗證的一個關鍵問題:
當被要求一次性生成並分析自己的證明時,生成器往往會聲稱正確,即使外部驗證器很容易發現缺陷。換句話說,雖然生成器可以根據外部回饋修正證明,但它無法像專用驗證器那樣嚴謹地評估自己的工作。
作為邏輯上的結果,人們會假設他們使用獨立的證明生成器 (LLM 1) 和證明驗證器 (LLM 2)。因此,這裡使用的自我修正循環變得類似於下圖所示。請注意,我們省略了僅在開發驗證器 (LLM 2) 期間使用的 LLM 3。
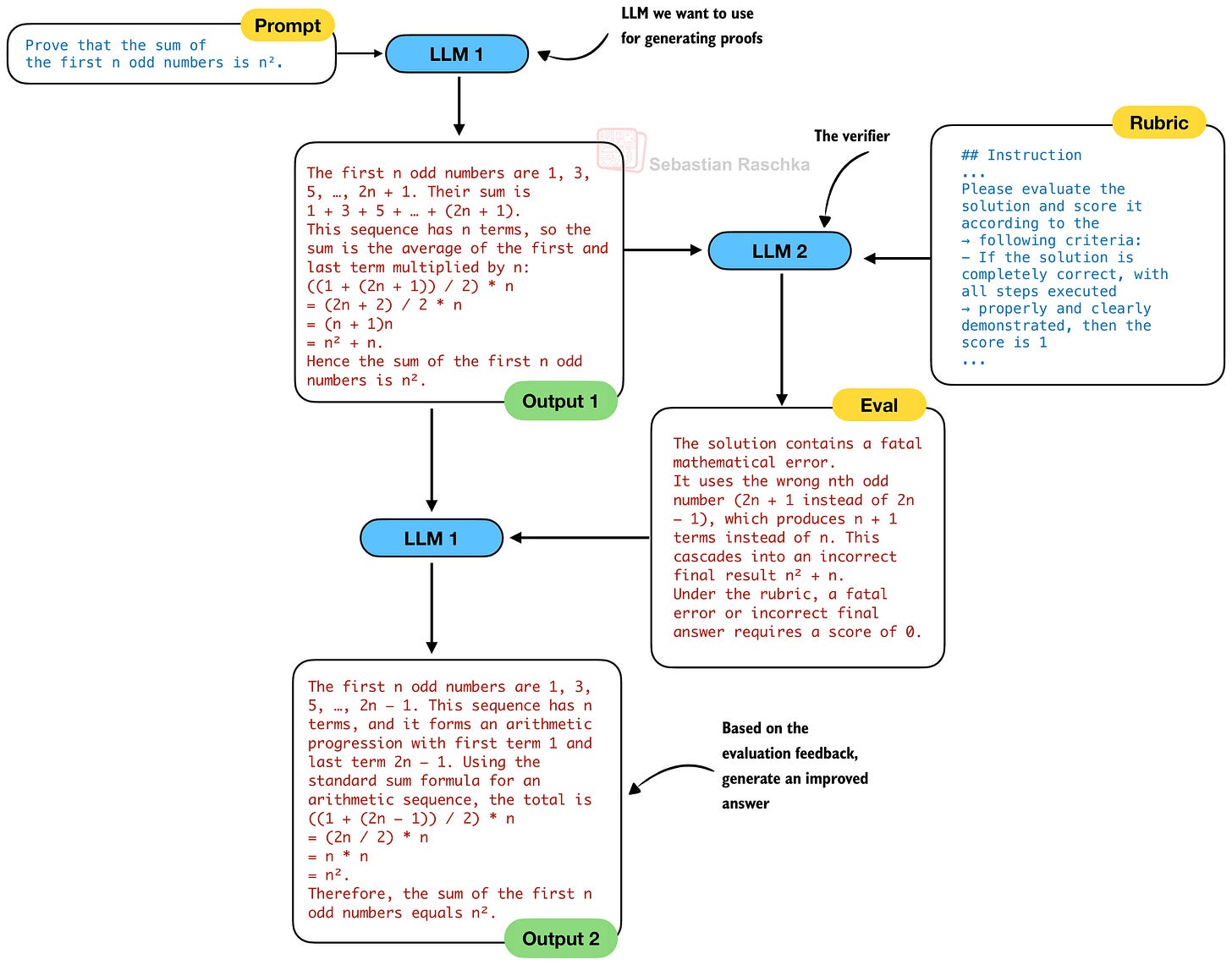
然而,在實踐中,與圖 15 不同,DeepSeek 團隊在圖 14 的經典自我修正循環中使用了相同的生成器和驗證器 LLM:
「所有實驗都使用單一模型,即我們最終的證明生成器,它同時執行證明生成和驗證。」
換句話說,獨立的驗證器對於訓練和改進生成器至關重要,但在推理階段,一旦生成器足夠強大,就不再需要它了。與單模型自我修正的關鍵區別在於,最終的證明器是在更強大的驗證器和元驗證器的指導下訓練的,因此它已經學會了將這些評分標準應用於自己的輸出。
此外,在推理過程中使用這種二合一的 DeepSeekMath V2 驗證器在資源和成本方面也是有益的,因為與運行第二個 LLM 進行證明驗證相比,它增加的複雜性和計算需求更少。
回到圖 14 和 15 所示的一般自我修正概念,兩張圖都顯示了進行 2 次迭代(初始答案和修正後的答案)的自我修正。當然,我們可以為這個過程增加更多迭代。這是一個經典的推理擴展權衡:增加的迭代越多,生成答案的成本就越高,但整體的準確性也越高。
在論文中,DeepSeek 團隊使用了多達 8 次迭代,而且看起來準確性尚未飽和。
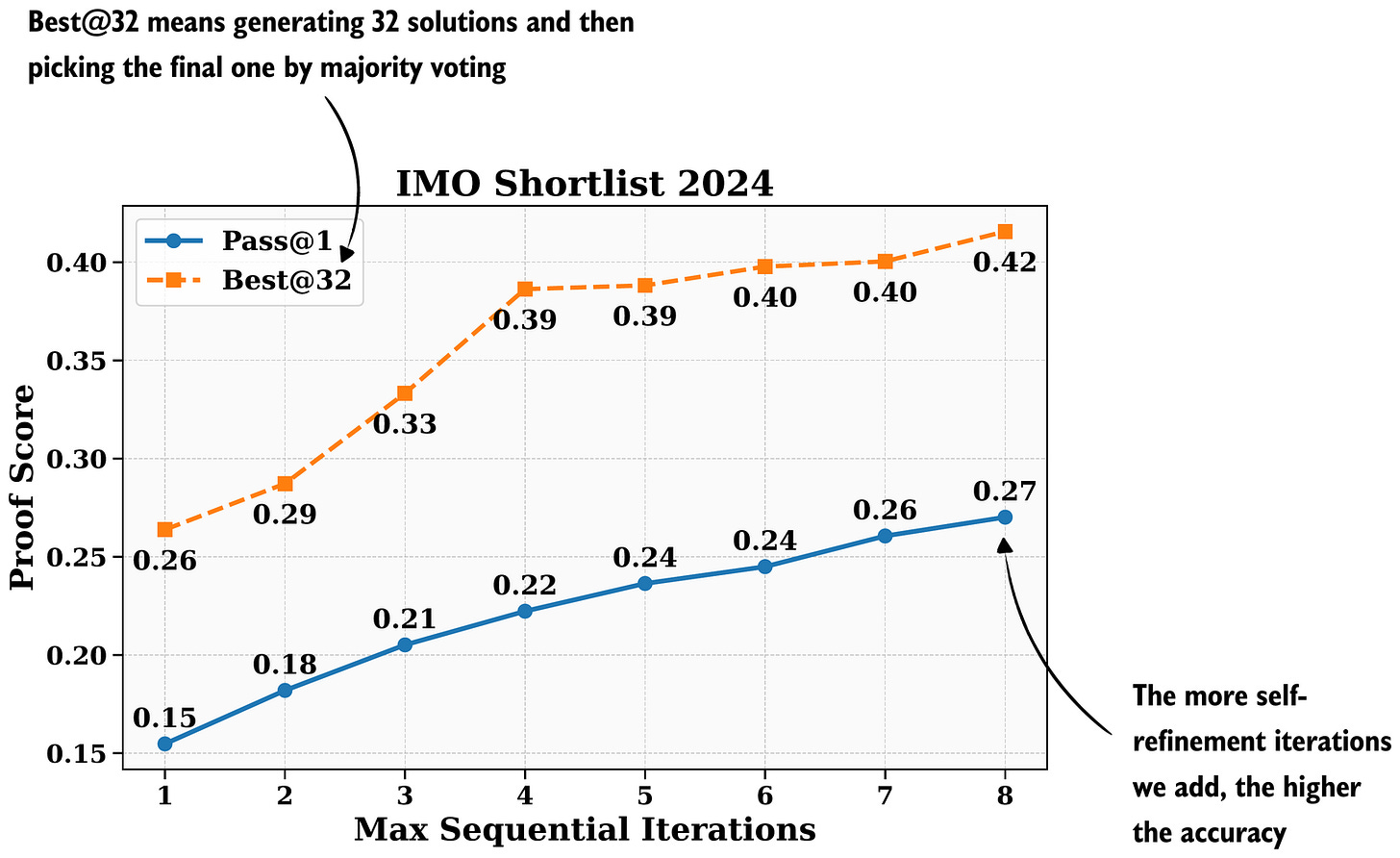
6. DeepSeek V3.2 (2025 年 12 月 1 日)
我們在上一節花這麼多時間討論 DeepSeekMath V2 的原因是:a) 它是一個非常有趣的技術驗證,透過自我驗證和自我修正技術進一步推動了可驗證獎勵強化學習 (RLVR) 的理念;b) 這些自我驗證和自我修正技術也應用在了 DeepSeek V3.2 中。
但在進入這部分之前,讓我們從 DeepSeek V3.2 的總體概述開始。這個模型意義重大,因為與目前的旗艦模型相比,它的表現非常出色。
與其他幾款 DeepSeek 模型類似,V3.2 也附帶了一份詳盡的技術報告,我將在接下來的章節中討論。
6.1 DeepSeek V3.2 架構
該模型的主要動機當然是提高整體的模型性能。例如,與 DeepSeekMath V2 一樣,它在數學基準測試中達到了金牌級水準。然而,該模型在訓練時也考慮了工具使用,並且在其他任務(例如代碼和智能體任務)中也表現良好。
與此同時,DeepSeek 團隊將計算效率視為一個重要的驅動因素。這就是為什麼他們將 V2 和 V3 中的多頭潛在注意力 (MLA) 機制與他們在 V3.2 中加入的 DeepSeek 稀疏注意力 (DSA) 機制結合使用。事實上,論文指出「DeepSeek-V3.2 使用與 DeepSeek-V3.2-Exp 完全相同的架構」,我們在前面的章節中已經討論過。
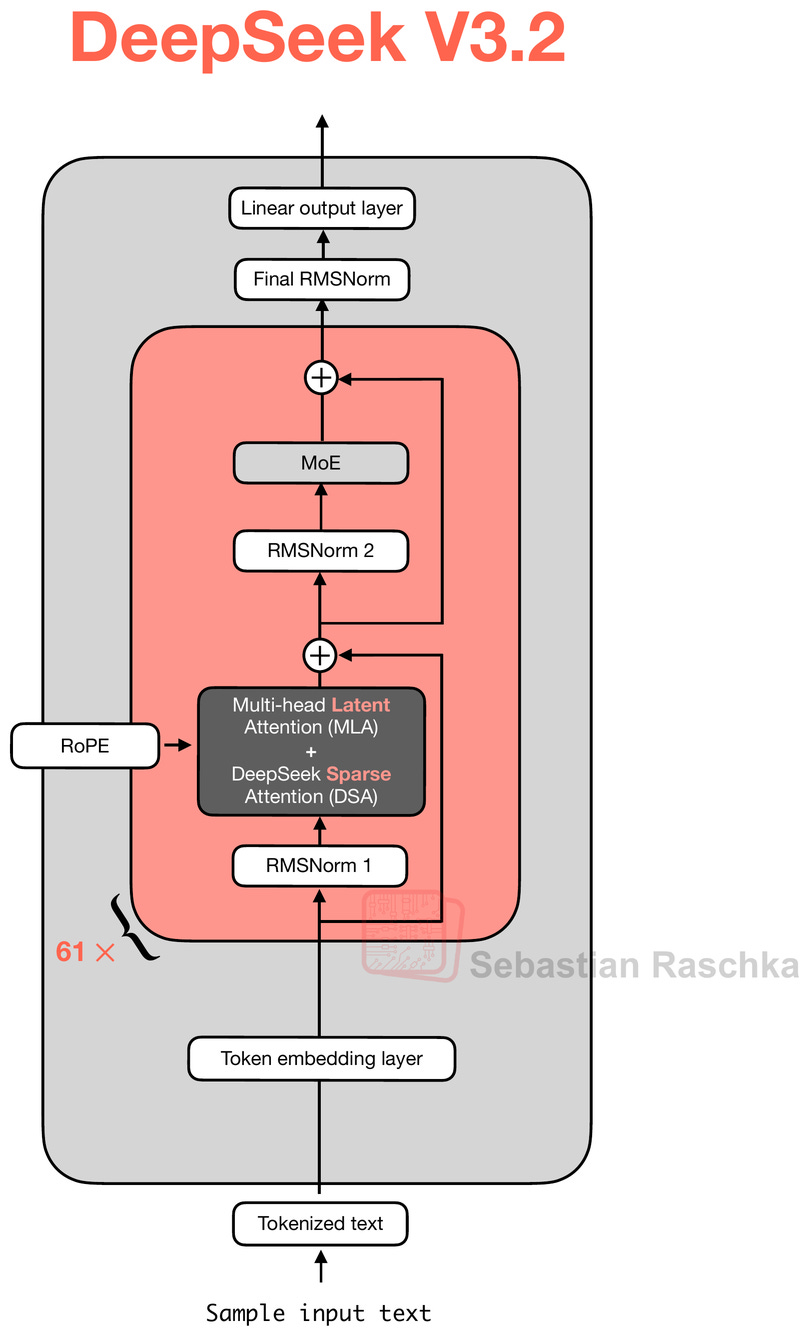
正如我之前提到的,DeepSeek V3.2-Exp 的發佈很可能是為了讓生態系統和推理基礎設施為託管剛發佈的 V3.2 模型做好準備。
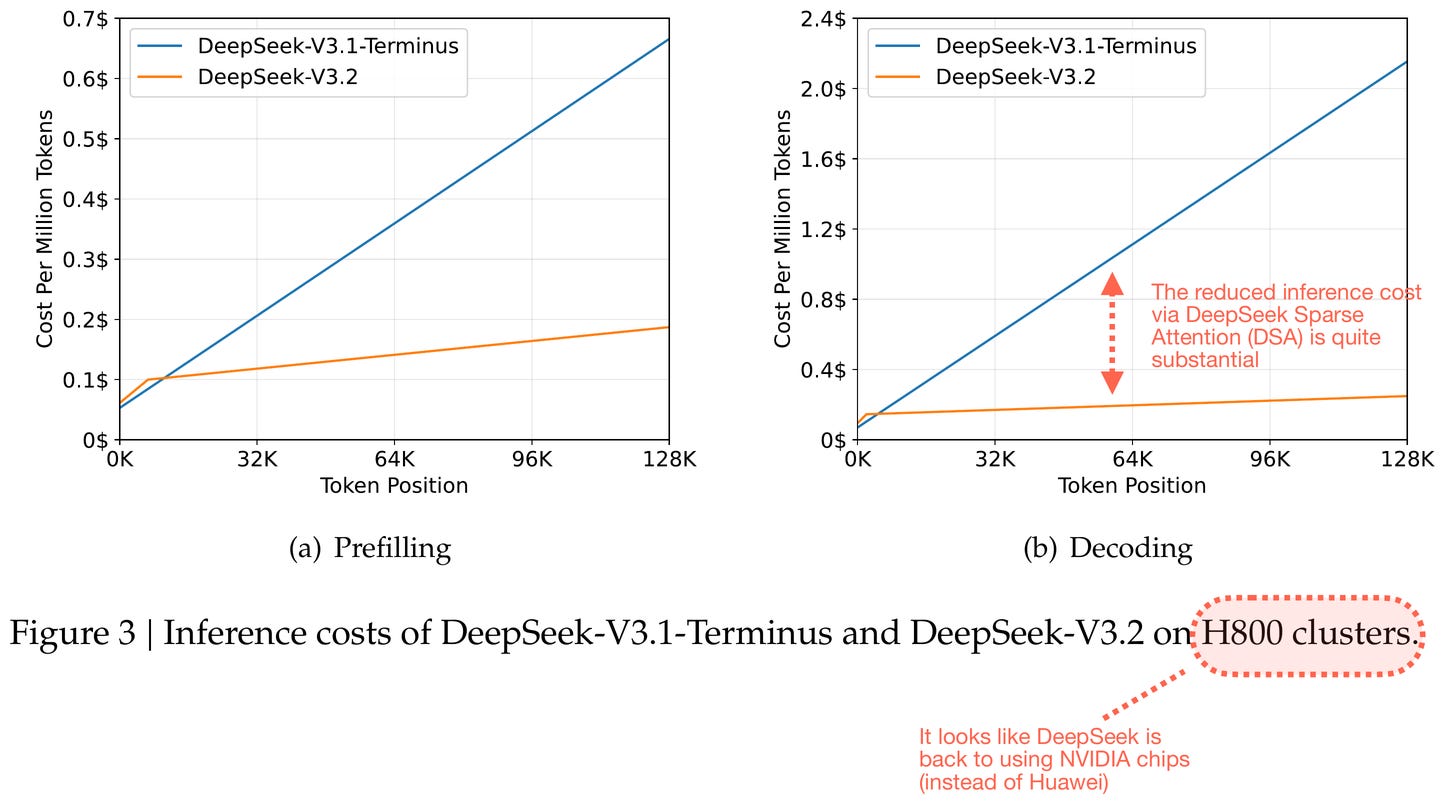
有趣的是,如上面論文截圖所示,DeepSeek 團隊恢復了使用 NVIDIA 晶片(在他們據稱嘗試在華為晶片上進行模型訓練之後)。
由於架構與 DeepSeek V3.2-Exp 相同,有趣的細節在於訓練方法,我們將在接下來的章節中討論。
6.2 強化學習更新
總體而言,DeepSeek 團隊採用了與 DeepSeek R1 類似的、使用群體相對策略優化 (GRPO) 算法的可驗證獎勵強化學習 (RLVR) 流程。不過,有一些有趣的更新值得討論。
最初,DeepSeek R1 使用:
- 格式獎勵(確保答案格式正確);
- 語言一致性獎勵(使模型在編寫回覆時不會在不同語言之間切換);
- 以及主要的驗證器獎勵(數學或代碼問題的答案是否正確)。
對於 DeepSeek V3.2,他們更改了獎勵機制:
對於推理和智能體任務,我們採用基於規則的結果獎勵、長度懲罰和語言一致性獎勵。對於通用任務,我們採用生成式獎勵模型,每個提示詞都有自己的評估標準。
例如,他們移除了格式獎勵,但為智能體任務增加了長度懲罰。然後,對於沒有符號驗證器(數學)或代碼解釋器來驗證答案的通用任務,他們使用獎勵模型(另一個訓練用於輸出獎勵分數的 LLM)。
因此,聽起來該流水線不再是像 DeepSeek R1 那樣純粹基於驗證器的 RLVR,而是 RLVR(用於可驗證領域)與更標準的 LLM-as-a-judge 獎勵建模(用於其他所有領域)的混合體。
對於數學領域,他們表示還「整合了來自 DeepSeekMath-V2 的數據集和獎勵方法」,我們在本文前面討論過。
6.3 GRPO 更新
關於 GRPO 本身(RLVR 流水線內部的學習算法),自 DeepSeek R1 論文中的原始版本以來,他們也做了一些改動。
在過去的幾個月裡,數十篇論文提出了對 GRPO 的修改,以提高其穩定性和效率。我在今年早些時候的《LLM 推理強化學習現狀》文章中介紹了其中兩個流行的變體:DAPO 和 Dr. GRPO。
不深入探討 GRPO 的數學細節,簡而言之,DAPO 透過非對稱裁剪、動態採樣、標記級損失和顯式的基於長度的獎勵塑造來修改 GRPO。Dr. GRPO 則更改了 GRPO 的目標函數本身,移除了長度和標準差歸一化。
最近的 Olmo 3 論文也採用了類似的改動,我引用如下:
- 零梯度信號過濾:我們移除獎勵完全相同(即優勢標準差為零的批次)的實例組,以避免在提供零梯度的樣本上進行訓練,這與 DAPO (Yu et al., 2025) 類似。[DAPO]
- 主動採樣:儘管進行了零梯度過濾,我們仍透過一種新型、更高效的動態採樣版本來保持一致的批次大小 (Yu et al., 2025)。詳見 OlmoRL Infra。[DAPO]
- 標記級損失:我們使用標記級損失,透過批次中的總標記數來歸一化損失 (Yu et al., 2025),而非按樣本歸一化,以避免長度偏差。[DAPO]
- 無 KL 損失:按照常見做法 (GLM-4.5 Team et al., 2025; Yu et al., 2025; Liu et al., 2025b),我們移除了 KL 損失,因為它允許更不受限的策略更新,且移除它不會導致過度優化或訓練不穩定。[DAPO 和 Dr. GRPO]
- 更高裁剪:如 Yu et al. (2025) 所建議,我們將損失中的上界裁剪項設置為略高於下界的值,以實現對標記的更大更新。[DAPO]
- 截斷重要性採樣:為了調整推理和訓練引擎之間對數概率的差異,我們按照 Yao et al. (2025) 的方法,將損失乘以截斷重要性採樣比率。
- 無標準差歸一化:在計算優勢時,我們不按組的標準差進行歸一化,遵循 Liu et al. (2025b)。這消除了難度偏差,在難度偏差中,獎勵標準差較低的問題(例如太難或太易)其優勢會被歸一化項顯著放大。[Dr. GRPO]
DeepSeek V3.2 中的 GRPO 修改稍顯溫和,我以與 Olmo 3 類似的風格總結如下:
- 特定領域的 KL 強度(包括數學為零):DeepSeek V3.2 並非像 DAPO 和 Dr. GRPO 在數學類 RL 中那樣總是丟棄 KL,而是在目標函數中保留 KL 項,但按領域調整其權重。然而,他們也指出,對於數學,非常弱甚至為零的 KL 通常效果最好。(但它並未被完全移除,而是成為一個超參數。)
- 無偏 KL 估計:如上所述,DeepSeek V3.2 並未移除 KL 懲罰。除了將其作為調節旋鈕外,他們還提出了一種修正 GRPO 中 KL 懲罰估計的方法,即使用與主損失相同的重要性比率對 KL 項進行重新加權,使 KL 梯度實際上與樣本來自舊策略而非當前策略的事實相匹配。
- 離策略序列掩碼:當他們在多個梯度步驟中重複使用展開數據(rollout data,即模型生成的完整序列)時,DeepSeek V3.2 會測量當前策略在每個完整答案上偏離展開策略的程度,並直接丟棄那些既具有負優勢又「過於偏離策略」的序列。這防止了模型從過度偏離策略或陳舊的數據中學習。
- 保持 MoE 模型的路由:對於混合專家模型骨幹,他們記錄了展開期間激活了哪些專家,並在訓練期間強制執行相同的路由模式,因此梯度更新是針對那些產生採樣答案的專家。
- 保持 top-p / top-k 的採樣掩碼:當展開使用 top-p 或 top-k 採樣時,DeepSeek V3.2 會存儲選擇掩碼,並在計算 GRPO 損失和 KL 時重新應用它,使訓練時的動作空間與採樣時實際可用的空間相匹配。
- 保留原始 GRPO 優勢歸一化:Dr. GRPO 表明 GRPO 的長度和每組標準差歸一化項會使優化偏向過長的錯誤答案,並過度加權非常容易或非常困難的問題。Dr. GRPO 透過移除這兩項並回歸無偏的 PPO 式目標函數來解決此問題。相比之下,DAPO 轉向標記級損失,這也改變了長短答案的權重分配。然而,DeepSeek V3.2 保留了原始的 GRPO 歸一化,轉而專注於上述其他修正。
因此,總體而言,DeepSeek V3.2 比其他一些近期模型更接近原始 GRPO 算法,但增加了一些合理的調整。
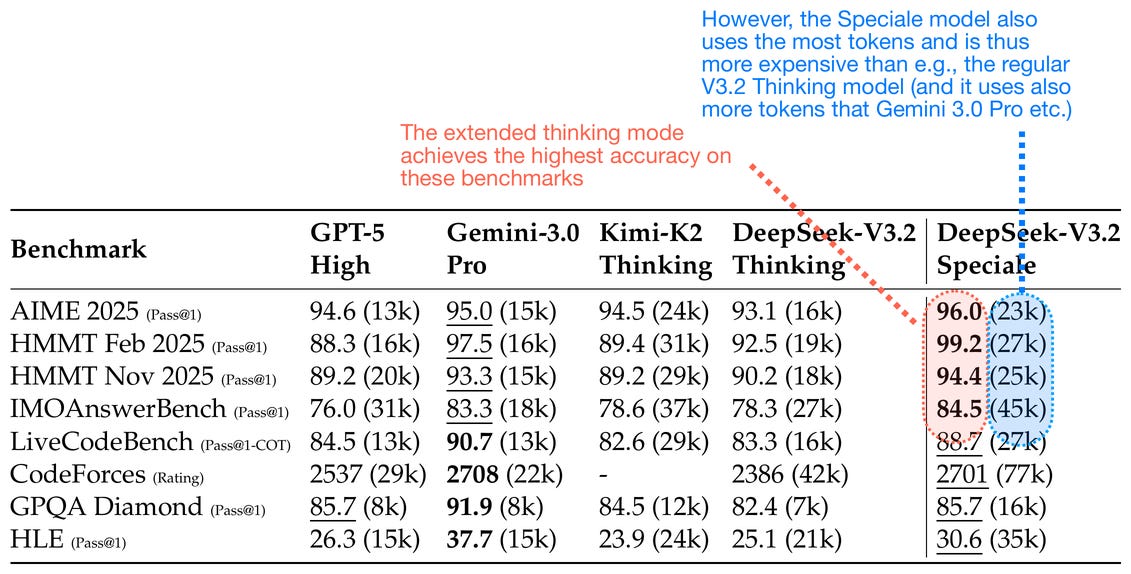
6.4 DeepSeek V3.2-Speciale 與擴展思考
DeepSeek V3.2 還提供了一個名為 DeepSeek V3.2-Speciale 的極端「擴展思考」變體,它在 RL 階段僅針對推理數據進行訓練(更類似於 DeepSeek R1)。除了僅在推理數據上訓練外,他們還減少了 RL 期間的長度懲罰,允許模型輸出更長的回覆。
生成更長的回覆是推理擴展的一種形式,回覆因長度增加而變得更昂貴,換取更好的結果。
7. 結論
在本文中,我並未涵蓋 DeepSeek V3.2 訓練方法的所有細節,但我希望與之前 DeepSeek 模型的對比能幫助釐清主要觀點和創新之處。
簡而言之,有趣的收穫包括:
- DeepSeek V3.2 使用了自 DeepSeek V3 以來所有前身模型的類似架構;
- 主要的架構調整是加入了來自 DeepSeek V3.2-Exp 的稀疏注意力機制以提高效率;
- 為了提高數學性能,他們採用了來自 DeepSeekMath V2 的自我驗證方法;
- 訓練流水線有多項改進,例如 GRPO 穩定性更新(注意論文還涉及了蒸餾、長文本訓練、類似 gpt-oss 的工具使用整合等其他方面,本文未予涵蓋)。
無論 DeepSeek 模型相對於其他較小的開源權重模型或 GPT-5.1、Gemini 3.0 Pro 等專有模型的市場份額如何,有一點是肯定的:DeepSeek 的發佈總是引人入勝,而且開源權重模型檢查點隨附的技術報告中總有許多值得學習的地方。
希望您覺得這篇概述有用!
8. DeepSeek 的 mHC:流形約束超連接
Transformer 架構的效率和性能調整通常集中在歸一化、注意力機制和 FFN 模組上。例如:
- 歸一化:LayerNorm → RMSNorm → Dynamic TanH
- 注意力機制:分組查詢注意力、滑動窗口、多頭潛在注意力、稀疏注意力
- FFN:GeLU → SiLU, SiLU → SwiGLU, 混合專家模型。
2025 年 12 月 31 日,DeepSeek 分享了關於改進殘差路徑的新研究:mHC:流形約束超連接 (Manifold-Constrained Hyper-Connections)。
簡而言之,它建立在超連接 (HC) 方法之上,透過多個並行流擴展殘差流,並允許資訊在這些並行層之間混合,從而將常規(恆等)殘差連接泛化為學習型連接。然後,他們進一步推進 HC 理念,提出了 mHC,它將殘差混合約束在一個結構化的、保持範數的流形上。他們發現這種「m」修改提高了訓練穩定性。這雖然增加了一點開銷,但獲得了更好的訓練穩定性和收斂性。

本雜誌是一個個人熱情項目,您的支持有助於維持它的運作。
如果您想支持我的工作,請考慮購買我的《從頭開始構建大型語言模型》一書或其續作《從頭開始構建推理模型》。(我確信您會從中獲益匪淺;它們深入解釋了 LLM 的工作原理,這是在其他地方找不到的深度。)
感謝閱讀,並感謝您支持獨立研究!
如果您讀過這本書並有幾分鐘空閒時間,我將非常感激您的簡短評論。這對我們作者幫助很大!
您的支持意義重大!謝謝!
相關文章