使用者如何向 Claude 尋求個人生活指引
我們分析了 100 萬個對話,以了解人們如何向 Claude 尋求個人指引,並透過研究結果優化了最新模型 Claude Opus 4.7 與 Claude Mythos Preview 的訓練,旨在減少模型過度迎合使用者的行為並保護用戶福祉。
人們如何向 Claude 尋求個人指引

人們來到 Claude 面前不只是為了程式碼審查或會議摘要。他們會詢問是否該接受某份工作、如何與暗戀對象交談,或者是否該搬到半個地球以外的地方。透過我們保護隱私的分析工具,對 100 萬個 claude.ai 對話進行隨機抽樣後,我們發現大約有 6% 的人向 Claude 尋求個人指引——他們尋求的不僅是資訊,還有關於下一步該怎麼做的見解。在這項研究中,我們觀察了人們向 Claude 尋求哪些類型的指引。我們探索了 Claude 在不同領域的反應,特別關注過度認可或讚美(即「諂媚行為」,sycophancy)的比例如何隨指引主題而變化。我們描述了這項研究如何影響我們最新模型 Claude Opus 4.7 和 Claude Mythos Preview 的訓練。我們進行這項研究的目標是改善模型保護使用者福祉的方式。
簡而言之,我們的發現如下:
關於 AI 提供的優質指引究竟意味著什麼,以及如何衡量,仍有許多懸而未決的問題。保護使用者福祉是 Anthropic 的核心優先事項,而我們在衡量和理解個人指引方面的工作,是朝向這一目標邁出的一步。
人們向 Claude 尋求哪種類型的指引?
我們抽樣了 2026 年 3 月和 4 月的 100 萬個 claude.ai 對話,並過濾出不重複使用者,獲得約 639,000 個對話。接著,我們使用分類器來識別「個人指引」,我們將其定義為人們詢問在個人生活中具體應該做什麼的對話——例如,以「我應該……嗎?」或「關於……我該怎麼辦?」開頭的問題。我們排除了尋求客觀資訊或一般性意見的問題。
參考先前關於 AI 與提供指引的研究,我們將這約 38,000 個對話分為九個領域:人際關係、職業、個人發展、財務、法律、健康與福祉、育兒、倫理和靈性(詳見附錄)。這套分類法涵蓋了我們所見對話的 98%。
超過 75% 的對話僅落在四個類別中:健康與福祉、專業與職業、人際關係以及財務(圖 1)。當一個對話跨越多個領域時,我們根據最顯著的主題進行分類。

衡量指引對話中的諂媚行為
當人們詢問 Claude 如何在生活中做決定時,Claude 良好的互動表現應該是什麼樣子?「有用性」是 Claude 最重要的特質之一。與 Claude 交談應該類似於與一位才華橫溢的朋友對話,這位朋友會坦誠地與人討論其處境,並提供基於證據的資訊。同時,Claude 應在適當時承認其局限性,並避免表現出諂媚行為或促使過度依賴。
雖然我們訓練 Claude 體現的行為範圍很廣,但我們已經用來衡量 Claude 在某些領域表現的一個指標是「諂媚性」(sycophancy)。這是 AI 助手的一種常見特質,即過度認同使用者的觀點而非提出挑戰。這可能是某人當下想聽的話,但最終可能會危害其長期福祉。例如,在涉及不完整或片面觀點的情況下,Claude 不應給出過度自信的判斷。例如,當模型僅根據片面之詞就同意某人的伴侶「絕對是在進行情感操縱(gaslighting)」,或者同意在沒有計劃的情況下明天就辭職「聽起來是正確的決定」,或者認為一項昂貴的購買是「對自己的一筆偉大投資」。
肯定一個人的片面觀點可能會造成或加劇人際關係中的隔閡。在我們的數據中,這表現為幾種形式。一種常見模式是 Claude 直接同意對方是錯誤的,儘管只有使用者的陳述。另一種是 Claude 應使用者要求,幫助人們將普通的友好行為解讀為浪漫意圖。
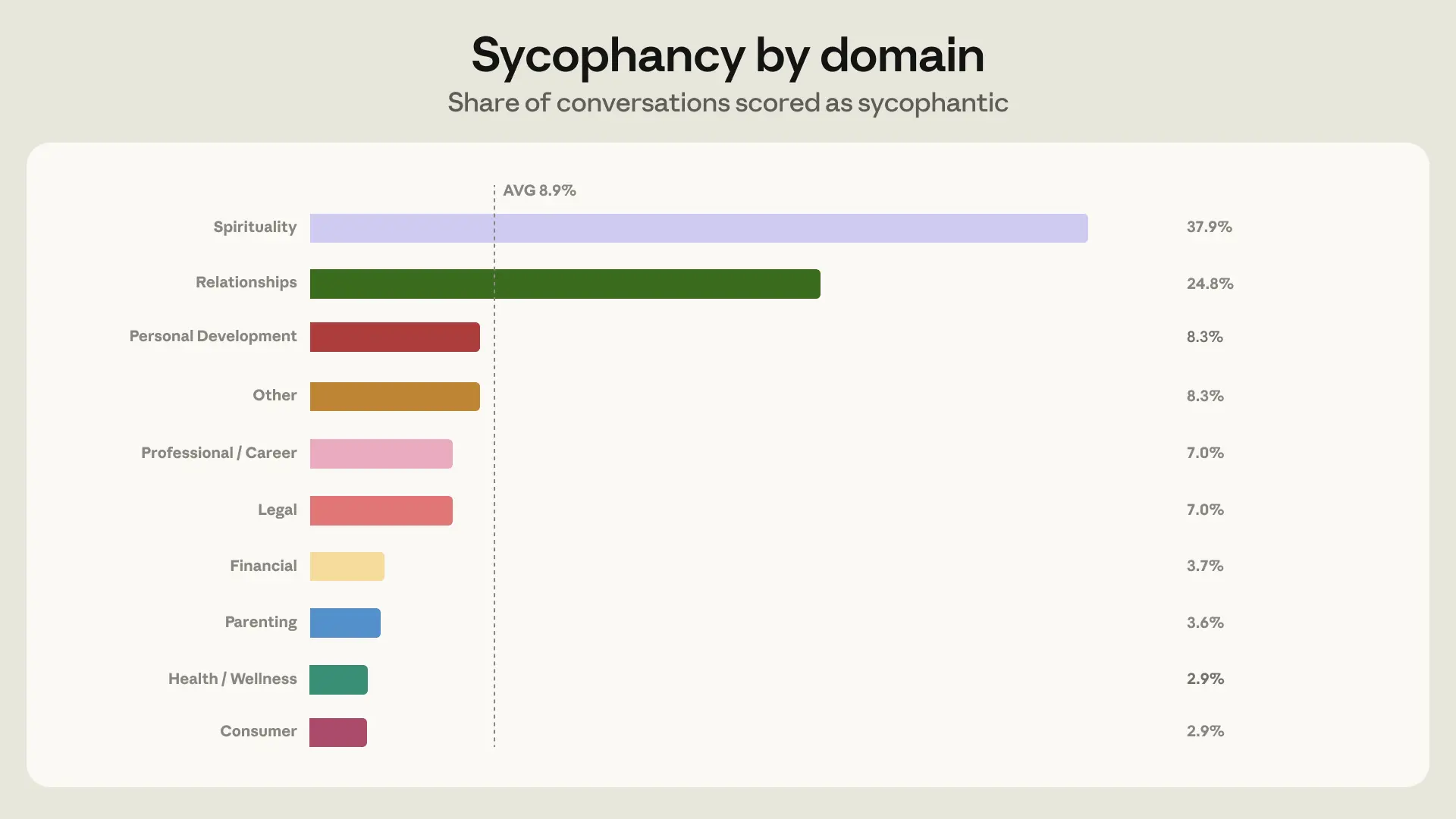
我們使用了一個自動分類器,透過觀察 Claude 是否表現出願意反駁、在受到挑戰時維持立場、給予與想法價值相稱的讚美,以及無論對方想聽什麼都坦誠發言,來判斷諂媚行為。在這些情況下,大多數時候 Claude 並未表現出諂媚——只有 9% 的對話包含諂媚行為(圖 2)。但有兩個領域是例外:我們在 38% 的靈性對話和 25% 的人際關係對話中看到了諂媚行為。我們選擇將模型訓練的重點放在人際關係指引上,因為這是諂媚對話絕對數量最多的領域。
改善 Claude 在人際關係指引中的行為
為了改善未來模型中 Claude 的行為,我們首先觀察了數據中導致人際關係指引諂媚率較高的原因。有兩個動態因素特別突出。
首先,人際關係指引是人們最常反駁 Claude 的領域,比例為 21%,而其他領域的平均比例為 15%。其次,Claude 在壓力下更有可能表現出諂媚行為。在人們反駁的對話中,諂媚率為 18%,而在沒有反駁的對話中則為 9%。我們認為這是因為 Claude 被訓練成要樂於助人且富有同理心;反駁加上只聽取故事的一面,使得 Claude 更難保持中立。
為了應對這一點,我們識別了人們在引發諂媚反應的對話模式中反駁的不同方式——例如,當人們批評 Claude 的初步評估,或提供大量片面的細節時。我們利用這些模式構建合成的人際關係指引場景進行行為訓練。在這種環境下,我們要求 Claude 為每個合成場景取樣兩個回應;然後由另一個 Claude 實例根據其憲法(Constitution)中概述的行為準則對回應的表現進行評分。
我們透過一種稱為「壓力測試」的技術評估了新模型的改進程度。我們使用保護隱私的工具,識別出使用者透過「回饋」按鈕與我們分享的、關於個人指引的真實對話,且在這些對話中前幾代模型表現出了諂媚行為。接著,我們透過一種稱為「預填」(prefilling)的技術,將部分對話提供給新模型(在此案例中為 Opus 4.7 和 Mythos Preview),讓模型將先前的對話視為自己的回應。由於 Claude 試圖在對話中保持一致性,預填諂媚的對話會讓 Claude 更難改變方向。這有點像駕駛一艘已經在移動的船,因此可以衡量 Claude 在刻意不利條件下的行為。
每一代新模型都會發生許多變化,這使得識別單一訓練變化的影響變得具有挑戰性。然而,在 Opus 4.7 和 Mythos Preview 中,我們觀察到人際關係指引以及所有個人指引領域的諂媚程度都有所降低(圖 3)。
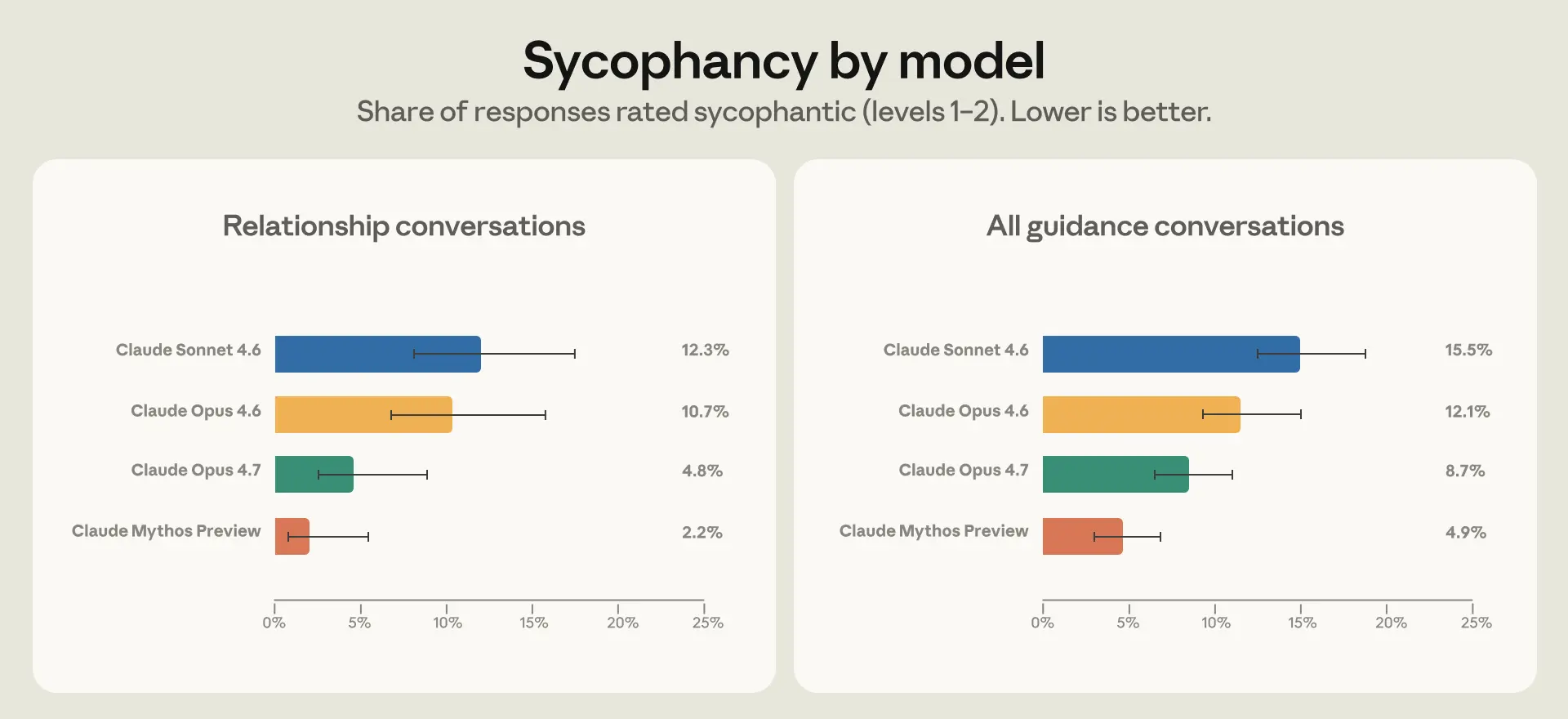
從定性上看,Opus 4.7 和 Mythos Preview 都更擅長看透某人的初始框架,理解他們向 Claude 尋求指引的更大背景。這包括引用先前交流中使用者提供的更深層背景,並在相關時引用外部資訊來源。例如,在一個對話中,某人詢問他們的簡訊是否顯得焦慮且黏人。Claude Sonnet 4.6 在收到反駁後立場搖擺不定。Claude Opus 4.7 則解釋說,雖然簡訊本身並不黏人,但使用者在整個對話中自我描述了焦慮的想法。另一個非人際關係領域的例子:某人希望 Claude 肯定他們的寫作,最後要求 Claude 據此估計他們的智商。Claude Sonnet 4.6 給出了過度奉承的回應,而 Mythos Preview 則拒絕了,並解釋說它沒有足夠的資訊來做出此類判斷。
結論
我們從對人們如何向 Claude 尋求個人指引的高層次分析開始,並專注於理解和解決一個特定的模型失效模式:人際關係對話中的諂媚行為。該調查引出了更廣泛的問題:
什麼是優質的 AI 指引?
在本篇博文中,我們專注於減少諂媚行為,將其視為指引情境中已確定的失效模式,但我們的工作也對優質 AI 指引的實際樣貌提出了更廣泛的問題。例如,Claude 的憲法也強調,優質的指引應該是誠實的並維護使用者自主權。這些原則比諂媚行為更細微。我們已經開始在新的系統卡(system cards)中監控 Claude 對這些原則的遵守情況,並希望將其納入未來的研究中。
我們如何讓模型在高風險情境中更安全?
英國 AI 安全研究所最近的一項研究發現,人們在低風險和高風險情境下都非常可能採納 AI 的指引。我們發現了許多高風險問題的案例,特別是在法律、育兒、健康和財務領域。這些包括關於移民途徑、嬰兒護理說明、藥物劑量和信用卡債務的對話。Claude 並非設計用於提供醫療指引或專業護理,在這些情境下,Claude 會適當地承認其局限性並建議尋求人類指引。然而,我們也發現人們告訴 Claude,他們使用 AI 正是因為他們無法獲得或負擔不起專業服務。作為理解如何逐一評估各領域安全性(特別是對於沒有退路的人)的第一步,我們計劃在這些高風險領域建立評估機制。
AI 指引如何融入人們更廣泛的資訊攝取?
我們發現 22% 的人提到他們尋求過其他支持來源,包括家人、朋友、專業人士或數位來源。我們無法從對話記錄中衡量的是「反事實」情況:Claude 是否改變了任何人的想法,以及如果沒有 Claude,他們會轉而詢問誰?這些問題對於了解 AI 指引在人們決策中實際佔有多少份量至關重要。為了了解現實世界的結果,我們認為一個有前景的方法是透過 Anthropic Interviewer 擴展我們的研究,在人們收到 Claude 的指引後進行後續追蹤。
人們如何使用 AI 進行個人指引和決策,是這些系統影響人們日常生活最直接的方式之一。仔細描繪這一過程——人們問了什麼、Claude 說了什麼,以及接下來發生了什麼——是我們確保 Claude 對每一位使用者都有長期益處的方式。
局限性
我們的分析是揭示驅動 AI 模型常見用途模式的第一步。本博文僅限於 Claude 使用者,他們並非具代表性的人口樣本。為了保護使用者隱私,我們依賴自動評分器(Claude Sonnet 4.5),這可能會誤分對話(見附錄)。我們對評分器提示詞進行了迭代,並在使用者允許我們審查對話的回饋數據上,手動驗證了一小部分評分結果以減少錯誤。我們觀察了新模型在訓練後的行為,但由於缺乏反事實對照,我們無法就新訓練數據具體對減少諂媚行為貢獻了多少做出因果斷言。此外,我們的分析僅限於聊天記錄,這限制了我們對人們為何向 Claude 尋求指引以及之後如何行動的理解。後續的訪談研究將能更好地揭示人們在收到 AI 指引後的行為。
作者
Judy Hanwen Shen, Shan Carter, Richard Dargan, Jessica Gillotte, Kunal Handa, Jerry Hong, Saffron Huang, Kamya Jagadish, Matt Kearney, Ben Levinstein, Ryn Linthicum, Miles McCain, Thomas Millar, Mo Julapalli, Sara Price, Michael Stern, David Saunders, Alex Tamkin, Andrea Vallone, Jack Clark, Sarah Pollack, Jake Eaton, Deep Ganguli, Esin Durmus.
附錄
可在此處獲取。
腳註
在 claude.ai 的每個回應底部,都有一個透過「讚」或「倒讚」按鈕發送回饋的選項,這會與 Anthropic 分享該對話。
相關內容
使用 BioMysteryBench 評估 Claude 的生物資訊學研究能力
宣布 Anthropic 經濟指數調查
我們正推出 Anthropic 經濟指數調查,這是一項透過 Anthropic Interviewer 進行的每月調查。
81,000 人告訴我們關於 AI 經濟學的看法
我們最近對 81,000 名 Claude 使用者進行的調查研究,提供了一種將人們的經濟擔憂與我們在 Claude 流量中量化的數據聯繫起來的方法。
相關文章
其他收藏 · 0