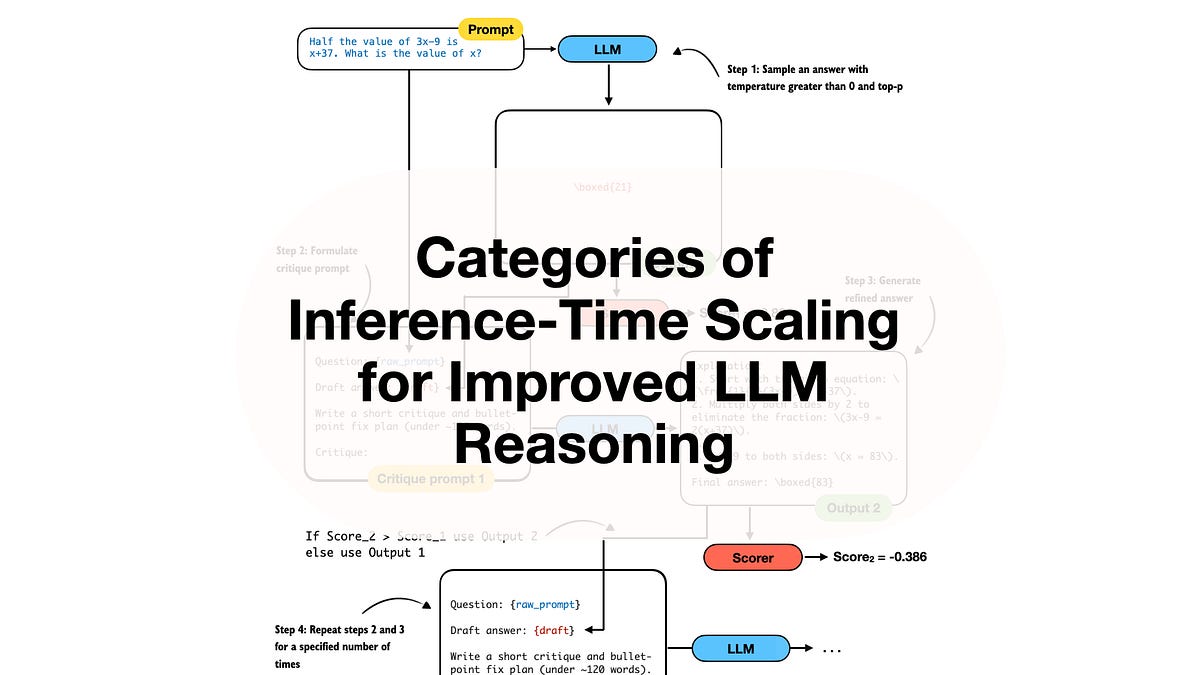
提升大型語言模型推理能力的推論時擴展分類
這篇文章探討了如何透過在推論階段分配更多的運算資源與時間,在不改變模型權重的情況下,顯著提升大型語言模型的推理品質與準確性。
提升 LLM 推理能力的推理時擴展分類
以及近期推理擴展論文概覽(包含遞迴語言模型)
推理時擴展(Inference scaling)已成為提升已部署 LLM 回答品質與準確性最有效的方法之一。
其核心概念非常直觀:如果我們願意在推理時(即使用模型生成文本時)投入更多的運算資源與時間,就能讓模型產出更好的答案。
如今,各大主流 LLM 供應商都依賴某種形式的推理時擴展。而圍繞這些方法的學術文獻也大幅增長。
早在三月,我就寫過一篇關於推理擴展領域的概覽,並總結了一些早期技術。
LLM 推理模型推理現狀
在本文中,我想將之前的討論更進一步,將不同的方法劃分為更清晰的類別,並重點介紹過去幾個月出現的最新研究。
在為《從頭開始構建推理模型》(Build a Reasoning Model (From Scratch))撰寫完整的推理擴展章節時,我親自實驗了許多這些方法的基本形式。隨著超參數調優,這很快演變成了數千次的運行,以及大量的思考與工作,以確定哪些方法應該在章節中詳細介紹。(該章節內容增加過多,最終我將其拆分為兩章,目前兩者都已在早期訪問計畫中推出。)
備註:我對這幾章的成果感到特別滿意。它將基礎模型的準確度從約 15% 提升到約 52%,這使其成為書中迄今為止最有成就感的部分之一。
以下內容是收集的一些想法、筆記和論文,雖然它們未能完全融入最終的章節敘述中,但仍然值得分享。
我也計畫隨著時間推移,在 GitHub 的額外材料中加入更多程式碼實現。
目錄(概覽)
推理時擴展概覽
思維鏈提示(Chain-of-Thought Prompting)
自我一致性(Self-Consistency)
N 選一排序(Best-of-N Ranking)
帶驗證器的拒絕採樣(Rejection Sampling with a Verifier)
自我修正(Self-Refinement)
解題路徑搜索(Search Over Solution Paths)
結論、分類與組合
加碼:私有 LLM 使用什麼技術?
您可以使用文章網頁版左側的導航欄直接跳轉到任何章節。
1. 推理時擴展概覽
推理時擴展(也稱為推理運算擴展、測試時擴展,或簡稱推理擴展)是一個統稱,指代在推理過程中分配更多運算資源和時間以提高模型性能的方法。
這個概念由來已久,我們可以將經典機器學習中的集成方法(Ensemble methods)視為推理時擴展的早期範例。也就是說,使用多個模型需要更多運算資源,但可以獲得更好的結果。
即便在 LLM 的語境下,這個想法也存在已久。然而,我記得當 OpenAI 去年在其 o1 發布部落格文章之一(《學習用 LLM 進行推理》)中展示了推理時擴展與訓練的圖表後,這個概念(再次)變得特別流行。
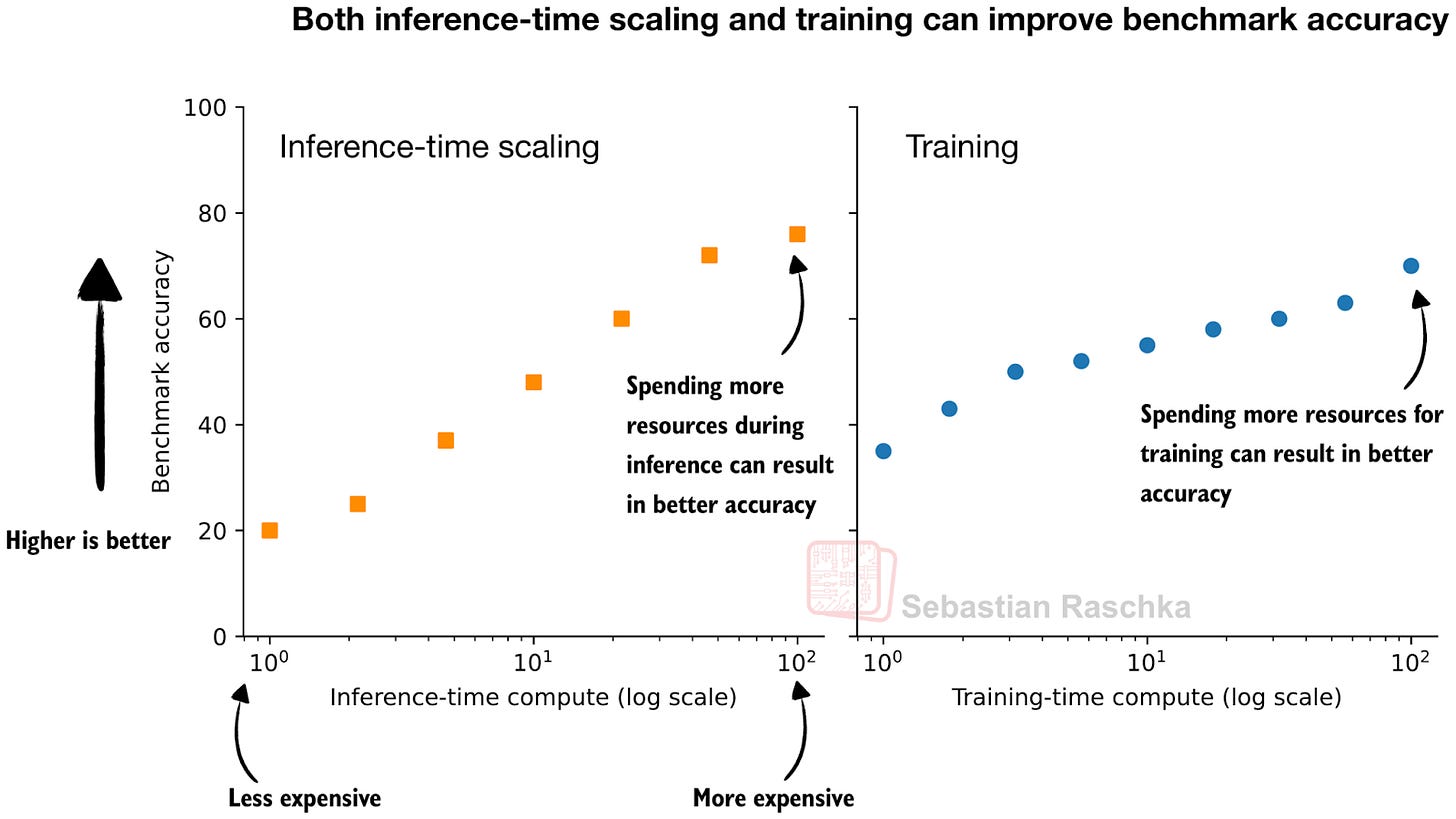
我認為這張改編自 OpenAI 部落格文章的圖表,很好地捕捉到了我們可以用來改進 LLM 的兩個旋鈕背後的理念。我們可以在訓練期間投入更多資源(更多數據、更大的模型、更多或更長的訓練階段),或者在推理期間投入資源。
實際上,在實踐中,同時進行這兩者效果更好:訓練一個更強大的模型,並使用額外的推理擴展使其變得更出色。
在本文中,我僅關注圖表左側的部分,即推理時擴展技術,也就是那些不改變模型權重的免訓練技術。
本文僅限付費訂閱者閱讀
相關文章