AI程式碼審查需要專用代理,而非更大模型
本文認為,有效的AI程式碼審查需要採用專用代理的系統化方法,而非依賴單一、更大的AI模型。這種多代理架構旨在模仿資深工程師的專業協調能力,以提供更好的上下文和意圖理解。
Better context, better suggestions: The multi-agent blueprint | Jan 28, 12pm ET →

![]()


AI Code Review and the Best AI Code Review Tools in 2025
The Next Generation of AI Code Review: From Isolated to System Intelligence

Bar Fingerman
Engineering Manager
January 21, 2026
7 min
Table of Contents
Many AI code review tools behave like smart linters: lots of comments, limited understanding of intent, context, or how the code fits the system. AI code review shouldn’t feel like a flood of noise. It should feel like a senior engineer looking for risk. Getting there however requires more than a powerful model. It requires a system approach.
Just as senior engineers don’t rely solely on deep knowledge but understand how to orchestrate multiple domains of expertise toward a coherent solution, an effective code review system must combine specialized capabilities through structured architecture rather than relying on a single powerful model.
This blog discusses the system approach that Qodo takes in the specific domain of automated code review, showing how architectural patterns can elevate an AI reviewer from a “smart linter” to a “Principal Engineer” capable of understanding intent, context, and organizational patterns.
Mental Alignment: Building the Reviewer’s Mental Model
The Problem with Context-Blind Review
First-generation AI code review tools analyze changes in isolation. They produce findings that are technically correct but contextually irrelevant: catching naming inconsistencies while missing architectural risks, or flagging style violations on emergency fixes when the reviewer needs to validate correctness.
To evolve from a noisy tool into a trusted reviewer, the system must recognize that code review is not a flat list of tasks, but a hierarchy of needs. At the foundation sits mental alignment: ensuring reviewers understand how a change fits into the broader system. Above that comes correctness validation, design discussion, and bug detection. Style consistency matters; for some teams it matters a great deal but the most system-impactful issues typically live lower in this hierarchy. An AI reviewer that inverts these priorities generates noise instead of signal.
Why Context Matters
Human reviewers face this challenge naturally. When reviewing a PR, they’re likely context-switching from entirely different work, with their mental model focused elsewhere in the codebase. A well-written PR description helps them rebuild context before examining any code.
An AI agent must do the same work. Before analyzing a single line, it needs to construct the mental model a well-prepared human reviewer would have: Why is this change being made? What problem does it solve? How critical is it? What has the developer already tested?
Without this foundation, even accurate findings land poorly. A comment about error handling reads differently on a feature branch than on a production hotfix. Context determines not just what to flag, but how to frame it.
Achieving Mental Alignment Through Context Engineering
Mental alignment means the agent’s understanding mirrors the developer’s intent. This requires synthesizing all available metadata:
Implementation Pattern
The alignment phase runs before any code analysis. A dedicated agent for intent understanding can synthesize available metadata into a structured context object that guides all downstream analysis. This mirrors the human reviewer’s natural workflow: read the PR description, check linked tickets, understand the problem, then examine the code.
The goal is that reviewers,—human or AI—should never be surprised by what they find. When an agent arrives at the code already understanding what it’s looking for, its feedback becomes actionable rather than disruptive.
Multi-Agent Architecture: Beyond Single-Model Limitations
The Problem with Monolithic Review
A single LLM, even with agentic capabilities, struggles with comprehensive code review because it conflates distinct cognitive tasks. Security analysis requires different reasoning patterns than performance optimization. API design review demands architectural thinking that differs from testing coverage analysis. When one model attempts all of these simultaneously, it dilutes focus and fills its context window with competing concerns.
Mixture of Experts: Parallel Specialization
The solution draws from mixture-of-experts principles. Rather than one generalist model juggling every concern, specialized expert agents operate independently, each focused on a distinct review dimension.
This separation provides several advantages:
The Orchestrator: Coordination and Activation
An orchestrator layer manages the expert constellation. Informed by the mental alignment phase, it determines which experts to activate based on the PR’s nature. A documentation update doesn’t need deep security analysis; a payment flow change demands it. The orchestrator routes the changeset to relevant experts, manages execution, and collects their independent findings.
This mirrors how a tech lead coordinates reviews knowing when to pull in the security team versus when a quick look from a domain expert suffices.
The Judge: Synthesis and Selection
Raw findings from multiple experts create a new problem: volume. Five agents might surface thirty observations, but a developer doesn’t want thirty comments on their PR. This is where the judge layer becomes critical.
The judge gathers all findings and performs deliberate self-reflection:
The judge’s output isn’t a union of all expert opinions. It’s a curated, coherent review that reflects what a thoughtful senior engineer would surface after considering multiple perspectives.
The Result: Signal, Not Noise
This architecture specialized experts working in isolated contexts, coordinated by an orchestrator, filtered through a reflective judge produces reviews that are both comprehensive and focused. The system considers security, performance, architecture, testing, logic, and style, but the developer sees only what matters for their change, their team, and their context.
Findings Personalization: Adapting to Team Context
The Noise Problem
Generic code review tools generate findings based on universal best practices, but teams have unique contexts: legacy code constraints, domain-specific patterns, intentional technical debt, and varying maturity levels. A finding that’s critical for one team may be irrelevant noise for another.
Personalization Dimensions
The Feedback Loop
Each review interaction feeds back into the personalization engine. When developers accept, modify, or reject suggestions, the system learns. Over time, the reviewer becomes increasingly attuned to the team’s real needs, much like a new team member who learns the codebase culture through osmosis.
The System Approach: Learning from PR History
PRs as Organizational Knowledge
Pull requests are more than code changes; they’re decisions captured in context. Each PR contains why a change was made, what alternatives were considered (in review discussions), how the team thinks about trade-offs, and what patterns are preferred in specific situations. This is the organizational knowledge that separates a 10-year veteran from a new hire.
The Knowledge Layer Architecture
Inspired by the “sleep time compute” paradigm, we build persistent organizational knowledge that the review agent can query at runtime:
PR Time Machine
For any code being reviewed, the agent should answer: “How has this area evolved? What problems have we encountered here before? What decisions shaped its current form?” This temporal awareness transforms code review from static analysis to contextual understanding.
Implementation Architecture
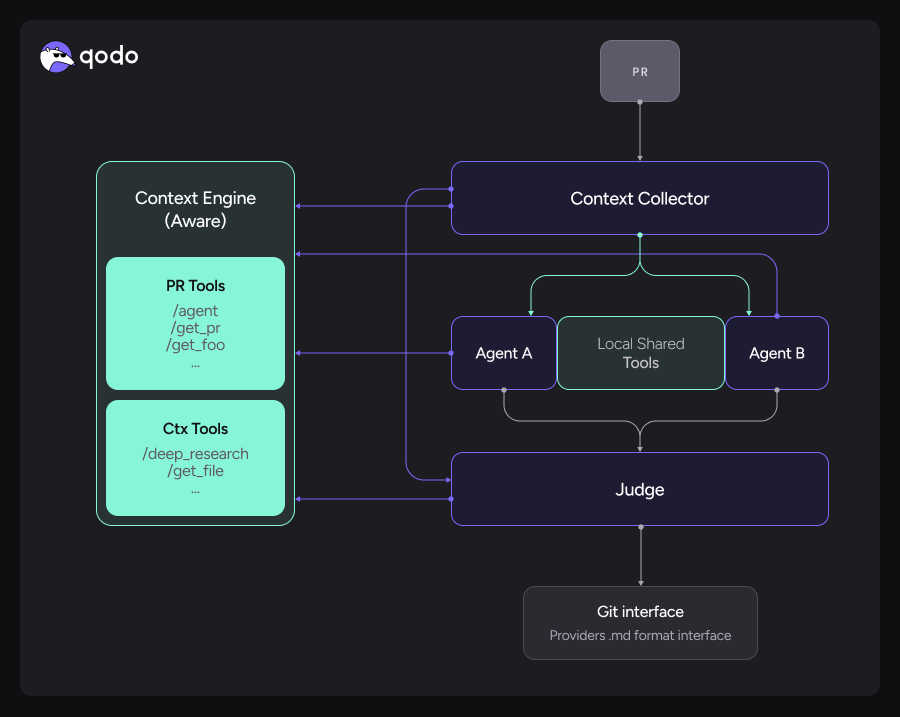
This diagram illustrates a multi-agent code review architecture. When a PR is submitted, a context collector gathers relevant information and distributes it to specialized review agents (Agent A, Agent B). These agents can access the context engine for PR-specific tools (like fetching PR data) and contextual tools (like deep research and file retrieval), as well as local shared tools for coordination. Each agent analyzes the PR from its specialized perspective, then a Judge component consolidates their findings, resolves conflicts, and produces the final review output. The result is published as a markdown file through the Git interface to the appropriate provider (GitHub, GitLab, etc.).
From Tool to Trusted Reviewer
The gap between AI code review tools and human reviewers has never been about raw intelligence. Frontier models can identify bugs, suggest optimizations, and catch security vulnerabilities with impressive accuracy. What they lack and what separates a useful tool from a trusted reviewer is the accumulated wisdom of operating within a specific organizational context.
Qodo’s system approach addresses this gap through four reinforcing pillars:
Mental Alignment ensures the agent begins where a prepared human reviewer would understand intent before examining implementation. This foundation transforms technically correct observations into contextually appropriate feedback.
Multi-Agent Architecture acknowledges that comprehensive review requires multiple lenses. By decomposing review into specialized expert domains coordinated through deliberate orchestration and synthesis, we achieve both depth and coherence, something a single model attempting everything simultaneously cannot sustain.
Findings Personalization recognizes that teams are not interchangeable. The same technical observation may be a critical signal for one team and pure noise for another. A system that cannot adapt to this reality will inevitably be tuned out.
Organizational Knowledge Integration closes the loop between past decisions and present review. By treating PR history as searchable institutional memory, we give the agent access to the context that makes veteran engineers invaluable: knowing not just what the code does, but why it evolved this way and what has failed before.
Together, these patterns create something greater than their sum. The resulting system doesn’t just review code, it participates in the ongoing conversation about how a codebase should evolve, informed by its history, aligned with its team’s values, and focused on what actually matters for each change.
This is the code review platform we’re building: not a model that knows more, but a system that understands better.
Start to test, review and generate high quality code

More from our blog

The missing quality layer: Qodo’s AI code review platform

Elana Krasner
Dec 02, 2025

5 AI Code Review Pattern Predictions in 2026

Nnenna Ndukwe
Jan 20, 2026
How 2023 AI Predictions Aged: Looking Back from the Start of 2026

Itamar Friedman
Jan 14, 2026
![]()
Qodo is an AI code review platform that brings automated, context-aware review into your IDE, pull requests, CI/CD, and Git workflows (GitHub, GitLab). It’s built for complex codebases, with context across multi-repos, to surface critical issues early, enforce standards, shorten feedback cycles, and ship better code faster. In Qodo, AI code review, code quality, and SDLC governance come together in one platform for teams that care as much about how code is reviewed as how fast it ships.




Products
Resources
Learn
About
We support all major programming languages










Available now on












@ 2026 Qodo. All Rights Reserved.
相關文章