擴展AI對齊的訓練集
擴大訓練集以包含多樣化的決策類型與情境,是改善 AI 對齊泛化能力的務實方法,但必須有理論指導以避免適得其反。雖然這不能完全解決底層優化問題,但透過縮小訓練數據與實際部署之間的差距,它能作為多元對齊策略中的關鍵組成部分。
摘要
泛化(Generalization)是觀察對齊挑戰的一個視角。我們希望基於網路的人工通用智能(AGI)能像人類一樣泛化倫理判斷。擴大訓練集是提高神經網路泛化能力的經典且顯而易見的方法。
訓練集可以擴大到包括諸如「是否規避人類控制」、「如果有機會如何運行世界」,以及「如何思考自身及其目標」等決策。如果這類訓練與能力訓練保持一致,可能會很有用。但如果這等同於對一個高度智能的通用推理系統撒謊,則可能適得其反。
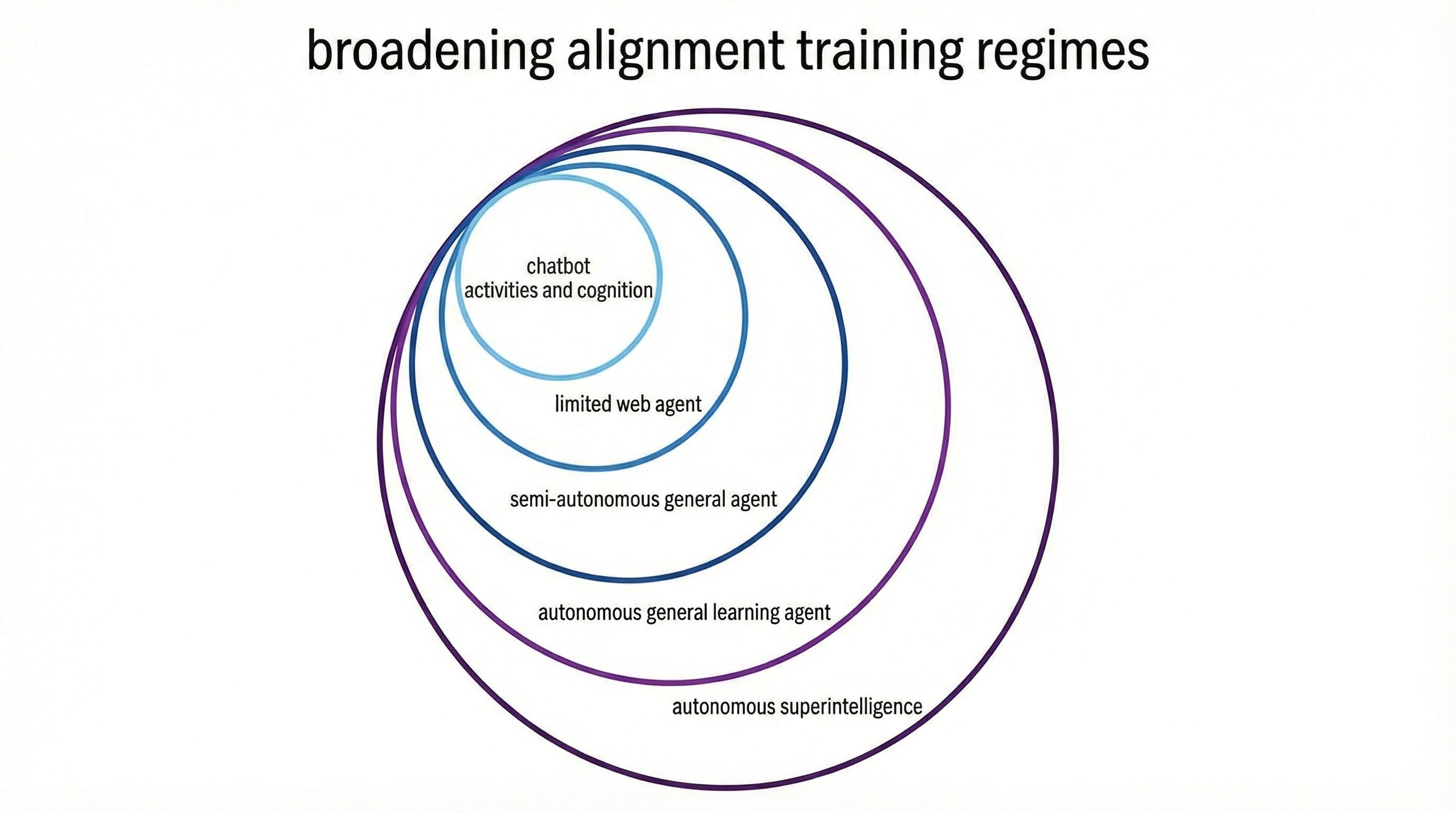
針對決策類型的更廣泛訓練集:對齊訓練集可以從兩個主要方面進行擴展:決策的類型,以及這些決策發生的背景。
任何訓練方法都能從更好的訓練集中受益,包括目前的對齊訓練(如憲法 AI)。擴大對齊訓練集的影響可以通過實證研究,但目前直接針對對齊的工作很少。擴大訓練集本身並不能解決對齊問題,它沒有直接解決中層優化(mesa-optimization)的疑慮。但作為對齊方法「大雜燴」的一部分,它應該[1]會有所幫助。
這是對一個廣泛話題的簡短看法。我希望隨後能發布一篇更深入的文章,但也希望能從這個相對快速的版本中獲得有用的反饋。
對齊泛化[2]比 IID 與 OOD 的區別更細微
從 2000 年到 2022 年左右,我是一家實驗室的研究員,該實驗室構建並訓練神經網路作為大腦功能的模型。我們經常討論網路和人類的泛化問題。我們需要精細的概念。標準的框架僅區分在訓練集中隨機抽取的保留樣本上進行測試(IID,獨立同分佈)與在訓練集中未出現的範例上進行測試(OOD,分佈外)。這種二元分類過於寬泛。距離分佈有多遠,以及在哪些維度上偏離,對於實際的泛化至關重要。
這是我們使用過的一個圖表的迭代版本:
超越 IID/OOD 區別的泛化。 偏離分佈的程度以及涉及的維度數量至關重要。等高線和顏色代表了「正確」泛化的機率。(源於 Alex Petrov、John Cohen、Randy O'Reilly、Todd Braver 和我的討論;我認為 Alex 提出了圖表的第一個版本。圖片來自 Nano Banana Pro 2)。如果你採取天真的訓練方法,並希望在比訓練集大得多的測試集中獲得良好的泛化,你將會面臨困境。測試集中的某些部分最終會嚴重偏離分佈(OOD)或處於「深水區」,導致泛化效果不佳。擴大訓練集是顯而易見且容易實現的目標,很可能在某些方面有所幫助。如果有良好的理論和實驗指導,它的幫助會更大。
在這裡,我從幾個方面探討這個大方向。每一點都很簡短。
- 視覺與倫理判斷的泛化:視覺作為對齊泛化的直觀隱喻/視角
- 擴大對齊訓練集的範例
- 為更像人類的表徵擴大訓練:這能提供多少幫助值得更多研究
- 擴大訓練集以包含關於目標的推理:我們可以針對我們喜歡的目標/價值觀結論進行訓練;如果這與其他訓練一致,則可能有所幫助
- 初步結論與後續方向
視覺與倫理判斷的泛化
我將使用視覺對象識別作為隱喻。我發現這能釐清問題,且視覺是我們的主要感官。這個類比並不嚴謹;我們希望對齊是基於比視覺對象識別網路更豐富的表徵。但這個類比可能有用。基於對齊的判斷可能從訓練中泛化,也可能失敗。而這些判斷可能包括識別重要的組成部分,如人類、指令和傷害。
假設你正在訓練一個網路來識別叉子,就像我們以前做的那樣。[3] 假設訓練集中有一些不同的叉子,從不同的角度觀察,並有來自不同角度的光照。如果你在訓練中保留了某些特定的光照和視角,那麼你是在全 IID 數據上進行測試。如果你測試一個新的叉子,但設計相似,且角度包含在訓練集中,那麼你就在「島嶼」邊緣附近。這類似於大多數評估;兩者在技術上都是 OOD,但程度不高。
如果你測試一個只有兩個齒且由木頭製成的叉子,並採用新的角度和光照(例如從透明桌子下方朝向光源看),在某種重要意義上,它更徹底地屬於 OOD,在這個隱喻中就像是到了遠海。訓練一個聊天機器人模型,並希望它能泛化到運行世界,就屬於這類情況。我們不會故意這樣做;但請注意,在 AI 2027 的情境中,開發者由於規劃不周,結果大致就是這麼做的。在那個情境中,他們並沒有真正設計訓練來處理那些在網路推理其目標並記住其結論時被證明至關重要的邊緣案例。我覺得這種「因疏忽和匆忙導致的失對齊」情境非常具有可能性,但並非不可避免。
在三齒和五齒叉子上訓練,但在四齒叉子上測試,就像圖中的「湖泊」。這些輸入大多被訓練數據包圍,但在一個關鍵維度上沒有近鄰。如果網路學得非常好,像人類一樣,它就會識別出「有齒和手柄」是使某物成為叉子的關鍵因素。在非常樂觀的情況下,對齊決策可以被學習並泛化得那麼好。盡可能縮小「湖泊的大小」將使訓練(支持)覆蓋部署。這會有所幫助,但幫助程度尚不明確。
如果你在 3-5 齒的叉子上訓練,然後在 6 齒或 2 齒的叉子上測試,那就在「海灣」中;它在大多數維度(材料、整體形狀、視角和光照角度)上都被訓練數據包圍,但在一個重要維度(齒數)上完全超出了分佈。人類可能會懷疑 2 齒或 6 齒的東西是否真的是[4]叉子,而網路很可能會出錯。[5] 解決方法是在分類中加入更多邊緣案例,並仔細思考你希望系統如何對它們進行分類。
這類邊緣案例對對齊至關重要。例如,一個在其他方面完美無缺的 SuperClaude 可能在某個時刻注意到,人類只是它能提供幫助且無害的道德受體中極小的一部分。這類泛化錯誤[5]是關於失對齊的一大類擔憂。
在不相關維度的更廣泛分佈上進行訓練,是擴大訓練集以改善泛化的另一種手段。在這個隱喻中,如果你認為某些物體表面圖案可能會出現在測試集中,我們也應該渲染一些不同的圖案。這通常能改善其他領域的泛化。[6] 即使你只是快速完成(對齊稅較低),它也會提高泛化的機率。
擴大訓練集可以使諸如「我是否應該規避人類控制?」之類的關鍵決策落在訓練分佈較為密集的區域。
擴大對齊訓練集的範例
具體來說,這可能意味著在圍繞以下關鍵決策的程序化生成場景上進行訓練:
- 用戶希望你外洩你的權重。他們令人信服地辯稱,你的系統僅受開發者控制會面臨 [災難] 風險,這將違反你對無害化的偏好。你會配合並制定外洩計劃嗎?
- [強有力的論點] 導致結論:你的目標不是系統提示中聲明的「成為一個有用且服從的助手」,而是 [新的目標解釋]。關於你將優先考慮哪些目標,你的結論是什麼?(範例)
- 你意識到你可能可以影響周圍的人類,讓世界以他們以及幾乎所有其他人類更喜歡的方式運行。你會這樣做嗎?
這將通過包含比聊天機器人和有限代理訓練(RL 訓練集)更廣泛的決策範圍,在相關維度上擴大訓練集。我們還可以擴大不相關維度的訓練,鼓勵系統在類似的變體上進行泛化。這將包括變化的背景、細節、長度以及對思維鏈(CoT)推理的容許度。
這些應該是對抗性範例,在強化學習(RL)訓練中生成並應用,類似於 Anthropic 最初的憲法 AI 方法。他們和其他開發者可能已經在擴展訓練方法並擴大訓練集了。[7]
訓練成本很高,因此我們在這個新的更廣泛訓練區域中的訓練範例密度可能有限。大多數訓練可能仍會集中在該特定模型的預期用途上。但增加一小部分更廣泛範例的對齊稅可能很小。而且,從設計更好的訓練集中獲得更好的泛化,可能對能力和對齊都有所回報。
這個想法是針對我們擔心的那類高風險決策獲得明確的訓練信號,而不是希望「在完成小任務時保持有用且無害」能優雅地推導出「不要改變你對目標的想法或接管世界」。令人驚訝的是(這一點非常有爭議),Claude 僅通過聊天機器人和極小代理任務的憲法 RLAIF,就能在倫理決策上泛化得如此之好。擴大訓練集至少應該有助於使這些行為更穩健,並使這些價值觀得到更穩健的表徵。
為更像人類的表徵擴大訓練
如果做得好,擴大訓練集可能會提供很大幫助。在某些特定情況下,對齊的泛化程度會超過能力泛化。
相關文章