
Slonk:Character.ai 在 Kubernetes 上運行 Slurm 以進行機器學習研究
Character.ai 推出 Slonk 系統,將 Slurm 的高效能運算能力與 Kubernetes 的協調管理結合,讓機器學習研究人員能在熟悉的 SLURM 環境中工作,同時享有 Kubernetes 的優勢,進而提升生產力。

Slonk: Slurm on Kubernetes for ML Research at Character.ai

Today we’re sharing a snapshot of Slonk (Slurm on Kubernetes), the system we use internally to run GPU research clusters at Character.ai.
Although this is not a fully supported open-source project, we’re publishing the architecture and tooling behind it because it solves one of the thorniest problems in machine learning infrastructure: giving researchers the productivity of a classic High-Performance Computing (HPC) environment while leveraging the operational benefits of Kubernetes.
The Problem: Bridging Two Worlds
When we started scaling our training infrastructure, we faced a familiar dilemma. Researchers wanted SLURM - a reliable scheduler with fair queues and gang scheduling. The infra team needed Kubernetes for orchestration, health checks, and autoscaling. Essentially, researchers needed simplicity and speed; operations needed stability and efficient GPU sharing. Slonk gives us both:
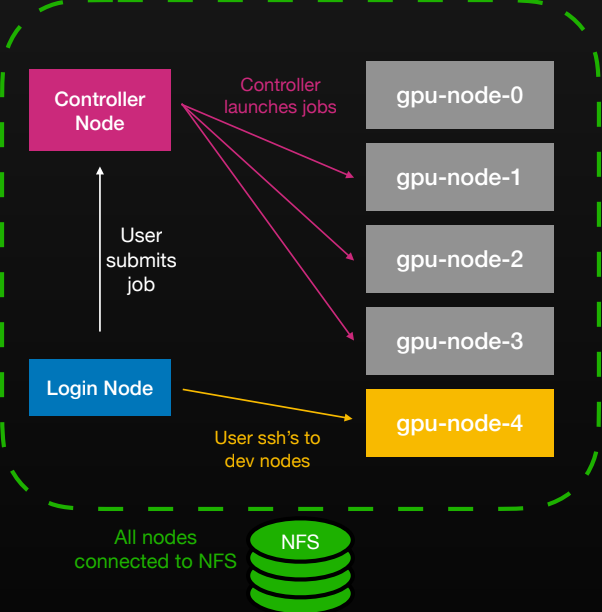
The day-to-day researcher workflow is classic HPC: SSH to a login node, edit code on a shared NFS home, submit a job, and tail logs; Slonk’s controller schedules and allocates resources, and results land back on the same volume.
Architecture: Containers All the Way Down
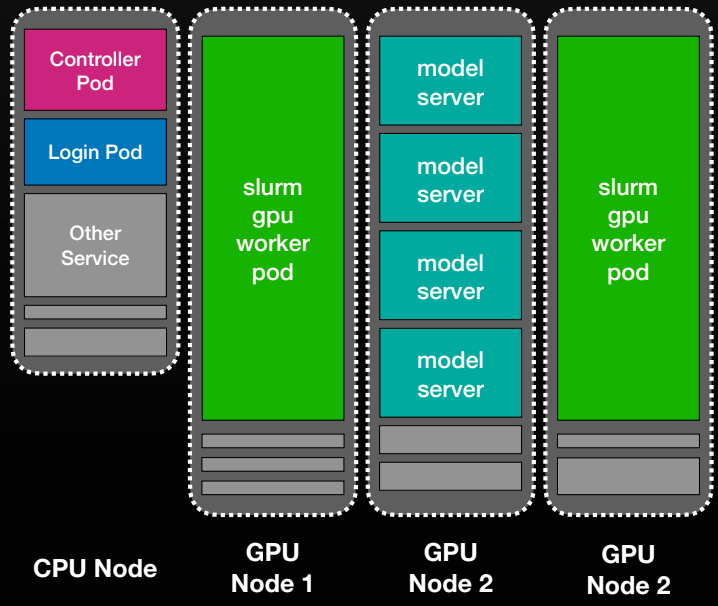
At its core, Slonk treats SLURM nodes as long‑running Kubernetes pods. We run three StatefulSets - controller, workers, and logins - so each SLURM “node” maps directly to a pod (gpu-node-0, gpu-node-1, …).
The controller pods run slurmctld; worker pods run slurmd; login pods provide SSH access and a familiar research environment. Other workloads can co‑exist on the same physical machines.
Some key details that make this seamless:
The result is a system that feels like a traditional supercomputing cluster - researchers still use sbatch and shared /home directories, while leveraging Kubernetes’ resilience, automation, and portability. For TPUs and slice-based hardware, we exploit SLURM’s network topology awareness so allocations are co-located; with capacity pre-staged in the cluster, jobs start in seconds rather than minutes.
Technical Challenges
Given these challenges, our technical goal is straightforward: when a researcher or automated system marks a SLURM node as faulty, Slonk should automatically drain the corresponding Kubernetes node and restart its VM at the cloud provider to recover from failure.
If a node repeatedly fails health checks, it’s excluded from the SLURM pool to maintain job stability. Meanwhile, our observability system tracks all faulty nodes for investigation and long-term reliability improvements.
Why This Approach Works
Slonk simplifies cluster management across clouds. Managed SLURM setups often differ by OS, drivers, or monitoring tools, but Slonk provides a consistent environment with the same CUDA stack and observability everywhere. GPU resources can shift dynamically between training and inference by adjusting StatefulSet replicas, and Kubernetes PriorityClass lets production workloads preempt training when needed.
Researchers work the way they always have-submitting jobs with sbatch my_job.sh - while Kubernetes quietly handles node restarts, container health, and logging. SLURM manages job scheduling and quotas, and Kubernetes ensures operational stability. Together, they keep the system simple, reliable, and flexible.
What We’re Releasing
The open-source snapshot includes:
We’re sharing this as a reference implementation. Fork it, build on it, adapt it to your environment.
Join Us
We’re hiring ML infrastructure engineers who love the intersection of HPC and cloud. If you want to design systems that scale model training and inference, accelerate researcher productivity, and make distributed systems sing, come work with us. The best infrastructure is the kind that researchers never have to think about.
相關文章