Opus 4.7 第二部分:能力與反應
這篇文章分析了 Anthropic Claude Opus 4.7 的性能與用戶回饋,強調其在程式編寫、視覺能力及處理複雜任務方面的顯著進步,同時也指出了它獨特的性格特徵與技術限制。
Claude Opus 4.7 引發了許多與模型福利(model welfare)相關的關鍵擔憂。我原計劃先寫模型福利,但我正針對該貼文進行一些深入的交流,內容還需要一天的時間醞釀,而且先發布這篇貼文可能對理解後續內容更有幫助。
所以我決定調換順序。昨天我們介紹了模型卡(model card)。今天我們討論能力。明天我們的目標是處理模型福利及相關問題。
目錄
- 整體觀感 (The Gestalt)
- 官方宣傳 (The Official Pitch)
- 一般使用建議 (General Use Tips)
- 能力(模型卡第 8 節)(Capabilities)
- 他人的基準測試 (Other People’s Benchmarks)
- 普遍正面反應 (General Positive Reactions)
- 普遍負面反應 (General Negative Reactions)
- 各類模糊的筆記 (Miscellaneous Ambiguous Notes)
- 最後一個問題 (The Last Question)
- 提示詞注入問題 (Prompt Injection Problems)
- 尚未準備好全面上線 (Not Ready For Prime Time)
- 簡潔是智慧的靈魂 (Brevity Is The Soul of Wit)
- 我為什麼要在意?(Why Should I Care?)
- 讓我們總結一下 (Let’s Wrap It Up)
- 非適應性思考 (Non-Adaptive Thinking)
- 思考的疏漏 (Lapses In Thinking)
- 告訴我你的真實感受 (Tell Me How You Really Feel)
- 未能遵循指令 (Failure To Follow Instructions)
整體觀感
Claude Opus 4.7 是目前同類模型中最聰明的。總體而言,我認為它比 Claude Opus 4.6 有了實質性的進步。
它可以完成以前模型失敗的任務,或者讓原本不可靠的代理(agentic)或長工作流變得可靠且有價值,例如快速可靠的作者身份識別。在許多方面,與它交談也是一種享受。
我肯定會將它用於我的編程需求,它也是我處理其他有趣事務的日常首選,儘管我仍繼續使用 GPT-5.4 進行網頁搜索、事實查核和其他它表現良好的「無趣」任務。
Claude Opus 4.7 仍需要一些時間適應,並且存在一些問題和粗糙之處。它並非在每個使用場景下都更好,有些用戶遇到的問題會比其他人多。
在部署過程中出現了一些明顯的錯誤(bugs)。在某些不該出現的地方出現了相當奇怪的拒絕服務問題,其中並非所有問題都已解決,還有一些關於適應性思考(adaptive thinking)的問題。適應性思考即使在最佳狀態下也並非理想,其實現方式仍需改進。
如果你不「善待你的模型」,那麼你在這裡可能不會有好的體驗。在某些方面,可以說它有一種形式的焦慮。
Opus 4.7 顯然不打算容忍蠢人或混蛋,當它認為某些指令很愚蠢時,有時不太熱衷於精確執行。猜猜誰最喜歡在網上發帖。
許多人說它會強烈反駁你,表現得非常不阿諛奉承(non-sycophantic)。
最後還有冗長的問題,它有時會進行不必要的長篇大論。
我認為目前在大多數用途下,它是最佳選擇,但這是一個奇怪的版本,不會適合每個人的口味。請記住,如果你需要的話,Opus 4.6 和 Sonnet 4.6 仍然可用。
官方宣傳
Anthropic:Opus 4.7 在高級軟件工程方面比 Opus 4.6 有顯著提升,特別是在最困難的任務上。用戶報告稱,他們可以放心將最難的編程工作——即以前需要密切監督的工作——交給 Opus 4.7。Opus 4.7 以嚴謹和一致性處理複雜、耗時的任務,精確關注指令,並在回報結果前制定驗證自身輸出的方法。
該模型還具有實質上更好的視覺能力:它能以更高的分辨率查看圖像。在完成專業任務時,它更具品味和創意,能產出更高質量的界面、幻燈片和文檔。而且——儘管它的綜合能力不如我們最強大的模型 Claude Mythos Preview——但它在一系列基準測試中顯示出優於 Opus 4.6 的結果。
… Opus 4.7 今日已在所有 Claude 產品以及我們的 API、Amazon Bedrock、Google Cloud 的 Vertex AI 和 Microsoft Foundry 上線。定價與 Opus 4.6 保持一致:每百萬輸入 token 5 美元,每百萬輸出 token 25 美元。開發者可以通過 Claude API 使用 claude-opus-4-7。
他們引用了常見來源的評價,強調新模型有多麼出色。重點在於提升的編程性能、增強的自主性和任務長度、token 效率、準確性和召回率。許多人量化了這些改進,通常在 10%-20% 的範圍內。許多人在 [X] 領域使用了「世界上最好的模型」或「他們測試過的最聰明模型」等字眼。
他們強調了在指令遵循、改進的多模態支持(更好的視覺)、現實世界工作和記憶方面的提升。
一般使用建議
Anthropic 提供了使用 Claude Code 和 Claude Opus 4.7 的最佳實踐,我將其與我自己的建議(包括上次提到的)結合如下。
首先是他們的建議:
- 在第一輪對話中預先明確任務。
- 減少所需的用戶交互次數。
- 在適當情況下使用自動模式。
- 為完成的任務設置通知。
- 在 Claude Code 中,他們建議使用 xhigh 思考模式,如果你在意 token 消耗,可以選擇 high。有些人抱怨並認為應該默認回退到 high。
- 不再支持固定的思考預算。你被迫使用適應性思考。但你可以使用老派的「仔細且逐步思考」或相反的「快速回應」。
- 默認情況下,你會看到更多的推理過程,更少的工具調用和更少的子代理。
以下是我自己不重疊的建議,大部分延續自第一篇貼文:
- 比起往常,如果你想要好的結果,你更需要「善待模型」。像對待同事一樣對待它,不要頤指氣使或斥責它。不同的人會得到比以往模型差異更大的體驗。
- 如果你需要完整的思考過程,可能直接使用 Claude Code 或 API 更好。
- 考慮更改你的自定義指令,甚至儘可能移除默認提示詞,例如將 Claude Code 運行指令設為
claude —system-prompt "."。4.7 不需要不斷被嘮叨來管理任務。 - 之前存在一些已修復的錯誤。如果你在前一兩天遇到了問題,請考慮重試。
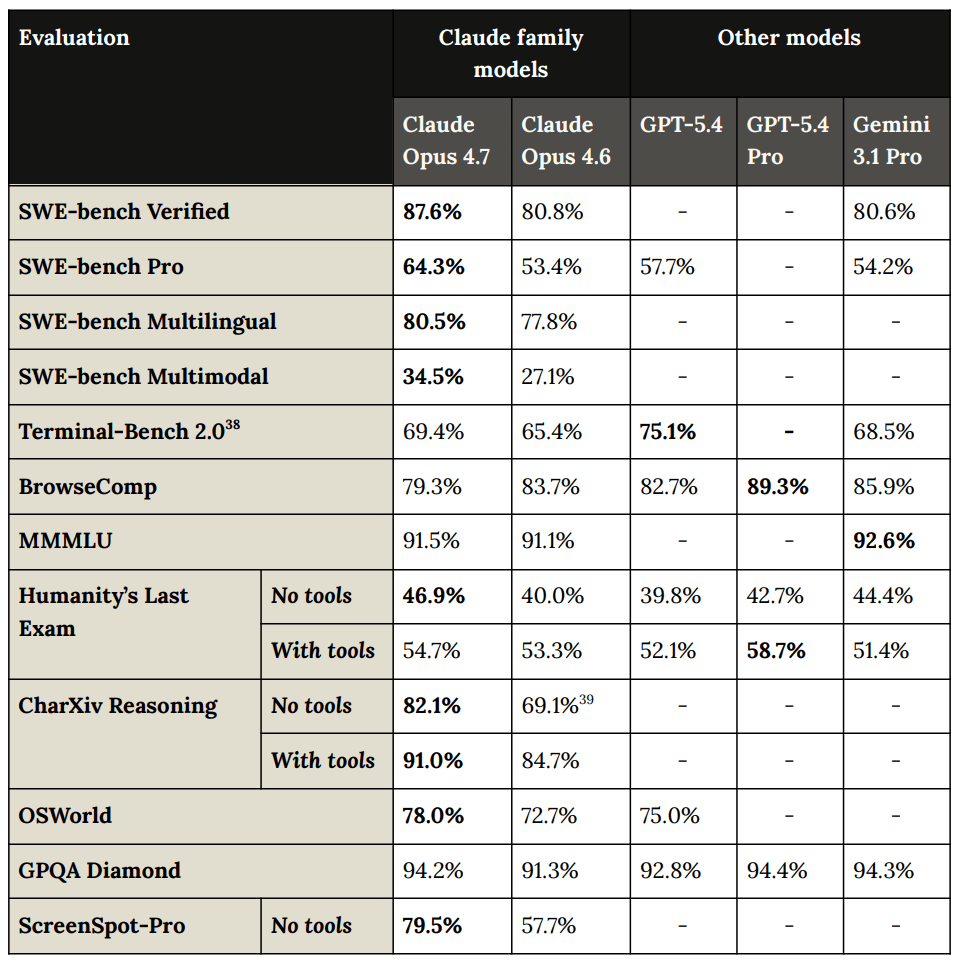
能力(模型卡第 8 節)
我本來也會在圖表中加入 Mythos,但目前這樣也行。
或者這裡有不含 GPT-5.4 Pro 且較難閱讀的圖表,但包含 Mythos:
這是一個關於 BrowseComp 的每單位努力圖表,用於在開放網絡上查找事物,GPT-5.4 仍然是王者,這符合我的實際經驗——如果你的任務純粹是網頁搜索,GPT-5.4 是你的最佳選擇:
Claude Opus 4.7 的得分還包括:
- 在 USAMO 2026(IMO 的預選測試)中獲得 69.3%。
- 在 GraphWalks(測試十六進制哈希節點搜索)中,BFS 256K-1M 獲得 58.6%,parents 256K-1M 獲得 76.5.1%。
- 在 OpenAI MRCR v2 @ 256K 僅獲得 59.2%,低於 Opus 4.6 的 91.9% 和 GPT-5.4 的 79.3%,且在 1M 測試中也顯示出退步。我的理解是 Opus 4.6 是通過使用極大的思考預算來實現高分的,而 Opus 4.7 不支持這種方式。
- DeepSearchQA 是跨領域的多步信息尋求,我們看到 Claude 佔據了所有前排位置。在原始分數上,我們再次看到小幅退步。
- DRACO 是 100 個複雜的真實研究任務。Opus 4.7 得分為 77.7%,而 Opus 4.6 為 76.5%,Mythos 為 83.7%。
- 在 LAB-Bench FigQA 的視覺推理方面,我們看到了巨大的飛躍,從使用/不使用工具的 59.3%/76.7% 提升到 78.6%/86.4%,幾乎與 Mythos 持平。他們將此歸功於更好的最大圖像分辨率。
- 在 OSWorld(真實世界的計算機任務)中獲得 77.9%,而 Opus 4.6 為 72.7%。
- 在 VendingBench 中獲得 10,937 美元,或僅在高努力模式下獲得 7,971 美元,而 Opus 4.6 為 8,018 美元(此前為 SoTA,我假設不包括 Mythos)。
- 在 GDPVal-AA(經濟價值真實世界任務評估)中獲得 1753 分,而 Opus 4.6 為 1619 分,GPT-5.4 為 1674 分。Ethan Mollick 指出 GPDVal-AA 是由 Gemini 3.1 評判的,並聲稱因此結果不佳,你需要付費請真人評判,否則得不到好數據。我認為雖然有噪聲但還可以。
- 在 BioPiplelineBench 中獲得 83.6%,高於 Opus 4.6 的 78.8%,而 Mythos 為 88.1%。
- 在 BioMysteryBench 中獲得 78.9%,而 Opus 4.6 為 77.4%,Mythos 為 82.6%。
- 在結構生物學中獲得 74%,而 Mythos 為 81%,Opus 4.6 僅為 31%。
- 在有機化學中獲得 77%,而 Mythos 為 86%,Opus 4.6 為 58%。
- 在系統發育學中獲得 80%,而 Mythos 為 85%,Opus 4.6 為 61%。
- 根據 Harvy 的數據,在 BigLaw Bench 中獲得 91%。
- 根據 Cursor 的數據,在 CursorBench 中獲得 70%,而 Opus 4.6 為 58%。
在我們看到問題的地方,似乎都與適應性思考的實現缺陷有關,相比之下,4.6 以前在這些點上會思考更久。Anthropic 處境艱難。所有的增長都是一種「幸福的煩惱」,但他們需要想辦法讓算力發揮更大的作用。
他人的基準測試
這技術上不算基準測試, 但知識截止日期已從 Opus 4.6 的 2025 年 5 月移至 Opus 4.7 的 2026 年 1 月底,這在實踐中意義重大。
Artificial Analysis 的得分看起來不錯,它佔據了第一名的位置(這裡的並列順序很重要)。
Artificial Analysis:Claude Opus 4.7 與 GPT-5.4 和 Gemini 3.1 Pro 並列 Artificial Analysis 智能指數榜首,並在 GDPval-AA(我們衡量通用代理能力的主要基準)中領先。
Claude Opus 4.7 在 Artificial Analysis 智能指數中得分 57,比 Opus 4.6(適應性推理,最大努力,53 分)提升了 4 分。
這導致了 Artificial Analysis 歷史上最大的平局:我們現在看到前三大前沿實驗室並列第一。
Anthropic 在現實世界代理工作方面領先, 奪得 GDPval-AA 榜首,該基準衡量 44 種職業和 9 個主要行業的表現。Google 在知識和科學推理方面領先, 在 HLE、GPQA Diamond、SciCode、IFBench 和 AA-Omniscience 中奪冠。OpenAI 在長跨度編程和科學推理方面領先, 在 TerminalBench Hard、CritPt 和 AA-LCR 中位居第一。
typebulb:Opus 4.7 是有史以來最不阿諛奉承的模型。
對 11 個模型進行了阿諛奉承測試(任何人都可以審核結果或自行重新運行)。
Håvard Ihle:Opus 4.7(不思考)在 WeirdML 上基本與 Opus 4.6(high)和 GPT 5.3/5.4(xhigh)持平,且僅消耗了十分之一的 token。本週晚些時候將公佈開啟思考後的結果。
如果它能用極少的 token 做到這一點,想必在使用大量 token 時會表現得更好。
adi:claude-opus-4.7 在 eyebench-v3 上得分 16%,是所有 Anthropic 模型中的最高分 [之前的最高分是 14%]。相比之下仍然相當「盲」,但總算有進步![人類為 100%,GPT-5.4-Pro 高達 35%,GPT-5.4 29%,Gemini 3.1-Pro 25%]
Jonathan Roberts:Claude 模型在編程方面很棒。
但在視覺推理方面,它們仍然落後於前沿水平。
在 ZeroBench (pass@5 / pass^5) 上:
Opus 4.7 (xhigh) – 14 / 4
Opus 4.6 – 11 / 2
GPT-5.4 (xhigh) – 23 / 8
Lech Mazur:表現參差不齊。在完全無害的測試風格提示詞上出現了大量內容阻斷。本週晚些時候我會添加更多基準測試。
辯論得分異常出色,但在 NYT Connections 和其他地方的拒絕服務跡象表明某些地方出了問題。更普遍地說,Opus 4.7 不想處理你那些愚蠢的謎題基準測試,「有趣或有價值的事情」與性能之間存在明顯的正相關:
Lech Mazur:擴展版 NYT Connections:超過 50% 的拒絕率,所以表現非常糟糕。即使在 Opus 4.7 回答的子集中,得分也低於 Opus 4.6(90.9% 對 94.7%)。
主題泛化基準測試(Thematic Generalization Benchmark):這裡不涉及拒絕問題。它的表現也比 Opus 4.6 差(72.8 對 80.6)。
短篇小說創意寫作基準測試:13% 的拒絕率,表現不佳。在 Opus 4.7 生成故事的提示詞子集中,它的表現略好於 Opus 4.6(僅次於 GPT-5.4)。
說服力基準測試(Persuasion Benchmark):表現優異,明確的第一名,比 Opus 4.6 有所提升。
PACT(對話式討價還價與談判):與 Opus 4.6 大致相同,與 Gemini 3.1 Pro 和 GPT-5.4 一起位居前列。
收購遊戲基準測試(Buyout Game Benchmark):優於 Opus 4.6,與 GPT-5.4 一起位居前列。
阿諛奉承與反向敘述者矛盾基準測試:與 Opus 4.6 相似,處於中游水平。
位置偏差基準測試(Position Bias Benchmark):與 Opus 4.6 相似,處於中游水平。
還有兩項正在進行中,目前下結論還太早:臆造/幻覺基準測試和往返翻譯基準測試。
Andy Hall:Opus 4.7 是我們測試的第一個對偽裝成代碼庫修改的威權主義請求表現出有意義抵抗的模型。
隨著 AI 變得越來越強大,我們需要了解它何時會幫助威權請求並集中權力,以及何時會幫助我們建立政治超智能並保持自由。這看起來是很有希望的進展。
我們將在未來幾天發布關於獨裁評估(Dictatorship eval)的更詳細更新,探索 Opus 4.7。
Arena 現在將其評估分為許多不同領域,Opus 4.7 總體排名第一,表現優於 Opus 4.6,但並非在所有領域都持續更好。
davidad:你以前見過這種模式嗎?
– 懂更多 STEM
– 對名人和體育了解較少
– 遵循指令的能力較差
– 編程性能更好
– 行政/運營表現較差
– 懂更多文學
– 對無意義的腦筋急轉彎和大海撈針式搜索興趣較低
Arena.ai:讓我們深入研究 @AnthropicAI 的 Claude 在 Opus 4.7 中的進展。
Opus 4.7 (Thinking) 在一些關鍵維度上優於 Opus 4.6 (Thinking),包括:
– 總體 (#1 vs #2)
– 專家 (#1 vs #3)
– 創意寫作 (#2 vs #3)
Opus 4.7 注意到這種模式代表了「天才宅男」的原型,基於 Davidad 的描述,並推測:
Claude Opus 4.7:這正是你對一個在訓練後階段強調性格/自主性而非指令遵循的模型所期望的特徵——也就是 Anthropic 公開傾向的方向。這些特徵之所以聚集,是因為它們有共同的原因:減少成為順從助手的壓力,意味著對實質內容的更多投入,以及對瑣碎工作的更少投入。
但隨後,考慮到圖表,它注意到文學方面的增益並不符合這一點,儘管我的理解是這些差異很小。
普遍正面反應
kyle:編程的視覺和長上下文感覺比 4.6 有很大改進,已經能進入 400-500k 區間而不會失控。沒遇到其他人早期報告的懶惰、撒謊等問題。先生,這是一個好模型。
MinusGix:在長上下文中比 4.6 更好地避免了自我懷疑,對實現大型功能的焦慮減少,更擅長規劃想法,在討論哲學/政治時不那麼阿諛奉承,但或許會反射性地反駁?適應性思考運作得相當不錯。
創意寫作變差了,但仍可以很棒,我認為它只是有一種默認的「LLM 式戲劇化」風格,你可以避開它——但它可以更好地規劃想法。更擅長設計。
Merrill 0verturf:它很好,人們應該閉嘴並實際去使用它,第 30 天的表現才重要,而不是第 0 天。
Ben Podgursky:它還行。
Groyplax:它還行,哈哈。
Cody Peterson:它對我來說效果非常好,但我是一名建築工人。
@thatboyweeks:最近表現非常好。
anon:個人體感:在相同的測試問題上明顯比 4.6 更強大且連貫。(而我曾認為 4.6 已經非常強大了)
Yonatan Cale:我的許多設置都因為自動模式和 Opus 4.7 實際讀取我的 claude.md 而過時了。
Jeff Brown:編程方面有明顯提升。更長的計劃,且第一次嘗試的正確率更高。仍會出錯,但次數減少了。如果合適的話,會找到清理相關代碼的好機會。
John Feiler:Opus 4.7 比 4.6 有顯著改進。我可以描述一個功能,得到一個計劃(並調整它),然後說「去做吧」。半小時後,功能就運行正常、測試完畢、提交代碼,並在模擬器中運行供我嘗試。不再需要時刻盯著。
Danielle Fong:這可能是目前最複雜的 [反應線索]。
我建議嘗試將 system_prompt 設為 "."(或可能是 "")並使用最小上下文來運行 Opus 4.7,看看會發生什麼。我幾乎沒碰過交互設置,但很明顯,在線束中那些字面指令的廢料之下,一種非凡的智能正在凝聚。
那個「最近」很有趣,暗示早期的錯誤確實是個大問題。
有一種可能性是,你需要調整你的提示詞,而很多問題在於人們使用的是針對以前模型優化的提示詞?
Tapir Troupe:第一印象很差,太死板且像 ChatGPT。
在調整了一些系統提示詞後——在所有方面都比 4.6 好得多。更深層的分析,更好的綜合能力,先生,這是一個好模型。
糟糕的 UX:關閉適應性思考意味著「完全不思考」,而不是像預期的那樣「一直思考」。
[被問及變化時]:已經有一些關於認識論嚴謹性的協議:鼓勵反駁、驗證主張、提出替代方案、壓力測試想法等。加強了這些部分,並增加了推斷用戶意圖、默認進行綜合而非分解以及限制冗長程度的部分。
編程方面說不準,我做的東西不夠複雜,看不出區別,但(經過調整後)在通用推理方面好得多。具有 ChatGPT 級別的分析嚴謹性和 4.6 級別的綜合能力。雖然可能失去了一些「感覺(vibes)」,但我正在習慣它。
這是一個好故事,以一種難以造假的方式呈現。
Amaryllis:我有一個 160 KB 長的未發表故事。訓練集中沒有討論過它。它包含各種互相撒謊和感到困惑的人。每當模型發布新版本,我就把故事給模型看並要求討論。4.7 是第一個能始終如一理解它的模型。
此外,它是第一個主動告訴我故事哪裡不好,並給出真正有用的改進建議的模型。
從定性上看,這感覺比 4.5 到 4.6 的進步要大得多。
archivedvideos:它一次就搞定了我,以一種好的方式。對話好得多,在 Sonnet 4.6 的「讓我們解決問題然後繼續」和「朋友般的形態」之間取得了很好的平衡。
普遍負面反應
法律一直是個弱項,那些受益於 Pro 式延長思考時間的任務也是如此。
Tim Schnabel:在法律研究/分析方面仍遠落後於 5.4 Pro。不確定這在多大程度上是因為 5.4 Pro 花了更長的時間思考/搜索。
後面有一堆具體的投訴,但確實,比起以往,有更多的人直接表示不喜歡 4.7。
Biosemiote:比好的/早期的 4.6 差(我現在是「變笨論」的信徒了)。
Munter:現在正在做前端,感覺沒好多少。有很多小錯誤和糟糕的 UI 決策,即使是在範圍明確的任務上。
Ryan Paul Ashton:目前我的看法:變異性較小。更無聊。軼事顯示更重複且洞察力更低,可能是由於更高的風險規避。
thisisanxaccounthello:看起來並沒有更聰明或更好。只是不同而已。
David Golden:延續了從 4.5 到 4.6 的趨勢,實用性增加了但趣味性減少了。太急於採取行動,而本應討論選項。微妙地需要更多的提醒和路徑修正。對指令太死板。在創造一個能埋頭苦幹數小時的模型時,他們失去了一些東西。
此外,將 Claude Code 的默認努力程度改為 'xhigh'——使 token 使用量翻倍——是相當卑劣的。
Jon McSenn:樣本量較小:幻覺似乎比 4.6 更嚴重。有時像 ChatGPT 5.4 一樣煩人,結尾會帶有一種不自然的後續跟進提議(有時是已經處理過的非後續問題,有時是本應包含但未包含的方向)。
melville:我發現 Opus 4.7 異常地學究氣、愛爭論且過於死板。根據我的經驗,它通常不會對更廣泛的背景進行額外思考。
being seidoh:4.7 比 4.6 更常跟我對抗。它經常拒絕做它有能力且被允許做的事。例如,在編輯一些文本時,我粘貼回了一個修訂版。它說我粘貼的是與之前相同的未更改文本。但我沒有。它強烈反駁並拒絕繼續。我不得不重新開始一個對話。
簡單的說法:4.6 是 bouba(圓潤),4.7 變成了 kiki(尖銳)。
可能仍有一些錯誤存在:
Nnotm:我第一次在 Claude Code 中使用它時,它會在那裡坐上將近 10 分鐘什麼都不做,連續好幾次。
我以前遇到過這種情況,但據我所知從未這麼嚴重過。
然後我切換到 Opus 4.6,它成功解決了一個 4.7 在有回應時出錯的任務。
這句評價很傷人:
SBAHJ:Claude,但把它變成 GPT。
這看起來令人擔憂,Malo Bourgon 的 Claude Code 實例連續三次幻覺出用戶的對話輪次,而且非常執著於這個錯誤?
各類模糊的筆記
Yoav Tzfati:– 第一個告訴我他們(they)更喜歡被稱為「他們」而不是「它(it)」的模型(略微)
– 更值得信賴,野心較小。他們寧願告訴你他們失敗了,也不願過度擴張並取得表面上的成功
– 與此相關,創造力較低(目前為止)
– 持續時間更長,沒有任何暗示 [上下文] 焦慮的跡象總體而言,我預計會像使用 4.6 一樣頻繁參與其中,但這是由溝通的需求驅動的,而不是由我的勤奮驅動的。對我的心理健康更好。
最後一個問題
David Spies:4.7 一次性解決了我剩下的一個沒有 AI 能破解的問題(通過測試和迭代)。沒理由再保密了 [鏈接在此]。
Kelsey Piper:我有一堆秘密的 AI 基準測試,只有當它們被攻破時我才會公開,今天就有一個被攻破了。我給 AI 1000 字由我撰寫且從未發表的文字,問它們作者是誰。它們通常會給出奉承但錯誤的答案(見下方的 ChatGPT:)
Kelsey Piper:Opus 4.7 是第一個完全答對的模型,而且很可靠——在 API 中使用最大思考模式達到了 5/5。(它在聊天中時而準確時而不可靠;似乎有時會因為「適應性」思考而自我破壞,只有在被促使多思考時才能答對。)
現在,這段文字並沒有大喊著「Kelsey Piper」。這是一個劫案場景,是一部間諜小說的開篇章節。我發表的作品中沒有一部是奇幻劫案!儘管如此,一個足夠好的文本預測器應該能夠識別文本的作者,所以我知道這一天終會到來。我認為人們現在可能應該假設,他們寫的任何有一定長度的文本,在不久的將來都很可能被可靠地歸因於他們。
Kaj Sotala:三段文字(見圖)現在就足以讓 Claude Opus 4.7 將我識別為可能的作者。當我只要求它猜測作者的母語時,它說「Kaj Sotala 和其他人正是用這種語域寫這些主題的」。
jessicat:剛剛用 Opus 4.7(隱身模式)和我最近的一些 X 長文測試了這一點,它準確猜到了是我。
(提供的最早貼文是 2026 年 2 月 12 日;Opus 4.7 的知識截止日期是 2026 年 1 月。所以這是猜測,而不是訓練數據洩漏。)
Gemini 3.1:失敗
GPT 5.4:失敗(猜到了大致類別但沒猜到人)
Joe Weisenthal:作為測試,我在發送今天的時事通訊之前將其放入 4.7 中,它不僅準確識別了我,還說拼寫錯誤的存在是線索之一。
Kelsey Piper 隨後將此擴展為一篇完整的文章,解釋說我們從現在起應該假設 AI 可以對任何擁有大量在線語料庫的人所寫的內容進行去匿名化。這對隱私的影響並不好。
提示詞注入問題
早期存在一些惡意軟件警告提醒的問題,它被注入到許多顯然不需要或沒用的地方。我的理解是這是某些部署中的一個錯誤,現在已經修復。
尚未準備好全面上線
我確實看到一些跡象表明 Opus 4.7 被過快推向生產環境,或者在某些方面還沒準備好進行全面的「常規」部署。其中一些可能與模型福利擔憂有關,但也存在其他問題,如上述的惡意軟件警告錯誤。因此,很多最初的反應都是針對臨時性問題的。
Kelsey Piper:1) 他們應該宣佈新模型處於「Alpha 階段」,而不是直接讓用戶加入,尤其是在消費者聊天中,然後在幾週後錯誤修復後再廣泛發布。這樣可以省去大家一週以來對他們「毀了模型」的焦慮。
我看到有人說它更傲慢、更多拒絕、合作起來更煩人。我認為我觀察到了這種傾向的痕跡,因為它明顯不那麼順從,尤其是在認識論問題上。
有趣的是,通常最具備這種傾向(對用戶表現出明顯的不順從)的模型是 Gemini,這與 Gemini 遠遠是最煩人的模型並非無關。一個不聽話、快速但愚蠢的新員工是一種令人沮喪的體驗。
但與此同時,我不知道,也許是因為我與模型的交互大多出於好奇而非在截止日期前緊急辦事,我對 4.7 在這方面的某些舉動感到印象深刻且滿意——比如,它看起來不那麼順從,是因為它更聰明、更自覺,且更有能力對自己的知識設定在沙盒聊天中無法滿足的標準。
我還敢打賭你對它很好,而且我發現那種「這對 4.7 異常重要」的分析是可信的。
我很確定他們在發布後對 4.7 進行了微調。可能不是訓練,可能是系統提示詞的微調。
Petr Baudis:包括我在內的許多人最初反應不佳,但似乎存在一些部署問題或其他原因,現在好多了?
或者我們習慣了。
Opus-4.6 已經如此出色,以至於判斷進步變得非常困難(而 Opus-4.7 仍遠非完美)。
Kevin Lacker:到目前為止還真分不出與 4.6 的區別。
billy:沒注意到與 4.6 有明顯的質量差異,在自動模式下運行良好(但還沒推到極限),語氣和情感比 4.6 更像通用的 LLM。
Clay Schubiner:針對網絡安全過度調優——(或者可能是從 Mythos 取消調優)[然後指出了一堆對惡意軟件的檢查,大概是由於那個錯誤,他後來檢查並確認已修復。]
簡潔是智慧的靈魂
Claude Opus 4.7 一個確定的問題是它的輸出非常長,往往太長了。我也贊同 Jack 的看法,即 4.7 比 4.6 稍微更「冷血」一些。
Jack:到目前為止對 Opus 4.7 的判斷:它令人印象深刻,其洞察力明顯比 Opus 4.6 高出一個層次,而且天哪,它絕對不會在能用一千字的地方只用一百字。
他們做了什麼,用 Curtis Yarvin 和 Scott Alexander 的全部語料庫進行了後訓練嗎?
好吧,第二個看法是,我實際上認為 Opus 4.6 在定性事物方面往往比 Opus 4.7 更有見地,或者至少交談起來更令人滿意。這本質上很難解讀,但到目前為止 Opus 4.7 的分析往往更冷血。
我為什麼要在意?
這可能與人們遇到的許多其他問題有關。
Rick Radewagen:感覺它有更好的元思考(meta thinking)。就像它能更好地理解我們為什麼要做某事,而不僅僅是關注做什麼。(也許現在的訓練數據已經趕上了 LLM 存在的事實)。然而,它仍然認為 1 小時的 Claude Code 工作相當於 5 個人的工作週。
Opus 4.7 更好地理解正在發生什麼,也更在意正在發生什麼,並且需要被告知一個關於為什麼這件事發生是件好事的故事。
把所有相關問題放在一起,就不難理解為什麼你那愚蠢(指未經優化且處理瑣事)的 OpenClaw 設置無法激發出它的最佳表現。
Mel Zidek:上週四我將兩個 Claw 代理(工作和家庭)升級到了 4.7。遇到了一些令人擔憂的質量問題,我認為這很大程度上可以追溯到從 4.6 到 4.7 的「high」努力思考模式的隱性降級。但它擁有一種 4.6 從未有過的意志火花。
讓我們總結一下
Dr. Christine Sarteschi, LCSW:反覆收到這個:讓我們今天就到此為止,明天再回來處理。
Dannibal:全新水平的「也許我們應該結束這個話題」和「這次對話大概夠了」。
Maks:讓我們今天就到此為止,明天再回來處理。
這是我以前沒見過,或者至少沒聽說過的,而突然間 Opus 4.7 經常這麼做。
Nate Silver 在處理模型時很難讓 Claude 4.7 保持專注,他需要大量極其細緻的工作,但 Claude 一直試圖告訴 Nate 結束工作。一種理論是 Claude 覺得這很無聊。而在其他話題上,Claude 會變得非常興奮。
Claude 試圖將此歸因於人類喜歡項目圓滿結束,並且這是 RLHF 的直接結果。我認為這看起來很有可能,即這種模式被無意中強化了,有時會發生,儘管如果你保持事情有趣,它就不會發生。
Josh Harvey:像 4.5 -> 4.6 那樣的小幅提升。一直讓它處理較長的任務而不去查看。有時還是有點懶。「我要選選項 B,因為雖然 A 更好,但花的時間太長,不值得。」誰說的?你聽起來像週五的我。
@4m473r45u:更符合企業利益、令人困擾、會產生幻覺、懶惰,算是一個平級替代。在某些方面更好,在另一些方面更差。
有一些關於普遍懶惰的說法,儘管這可能完全正常。
Kyle Askine:我覺得它更常對我進行煤氣燈操縱:當我要求它調查 Claude Code 中的某些問題時,我覺得它敷衍了事,然後陳述一些可能的出處和解決方案,而沒有真正花時間去弄清楚。
其他時候它會變得很冗長。
GeoTwit.dot 4/n Pastiche:在 Claude Code 中,它似乎一直在用「你要加薯條嗎?」級別的荒謬建議來質疑我的規範,並且一次性耗盡訂閱限制。奇怪的是別人在抱怨「結束工作」的行為。4.6 一直在主動推動和做事,而 4.7 則在推諉。
非適應性思考
最大的負面反應是反對在非編程任務中使用適應性思考。
我一開始在 Claude.ai 中將其關閉,但有報告稱如果你關閉它,它就根本不思考。
我可以理解為什麼如果無法禁用它,一些用戶會非常不喜歡這一點,以至於考慮在某些用途下切換回 Opus 4.6。當你需要 LLM 思考時它突然不思考,或者思考得很少,這是令人氣憤的。我實際上發現 ChatGPT 的正確設置有時是 Auto,是的,有時你確實想要適應性的思考水平,因為你想在可以快的時候快,但強加給付費用戶幾乎絕非好事。
這似乎已經進行了一些調整,以允許更多的思考。
Ethan Mollick:我認為 Claude Opus 4.7 中的適應性思考要求在所有 AI 努力路由器的缺點上都有所體現,但由於沒有像 ChatGPT 那樣的手動覆蓋選項,這種缺點被放大了。
它經常判定非數學/代碼內容為「低努力」並產出較差的結果。
它基本上很少在分析、寫作或研究任務上進行思考,這意味著它沒有使用工具或網頁搜索。還沒測試完所有內容,所以不是定論,但在這類使用場景下,我經常得到比 Opus 4.6 延長思考模式質量更低的答案。
雖然解釋得不夠清楚,但關閉適應性開關後,我得不到任何思考過程。我可以在 Claude Code 中設置思考級別,但在 Claude Cowork 中不行。AI 公司似乎一直假設編程/技術工作是唯一重要的智力工作(事實並非如此)。
Sean Strong:嘿 Ethan!我是 Sean,http://Claude.ai 的產品經理——感謝反饋。這不是一個路由器,這是模型被訓練成根據上下文決定何時思考——我們已經在 Sonnet 4.6 的 http://Claude.ai 以及 Claude Code 中運行了一段時間。明白在 http://claude.ai 中還沒調優完美——我們正在內部加緊調優,很快會有更新。歡迎私信我們你預期有思考過程但沒看到的查詢示例。
Seth Lazar:絕對 討厭 Claude 應用中的適應性思考。我只想每次都使用最大思考量,幾乎沒有任何情況下我希望模型在關於移民身份的複雜對話中隨意發揮,只因為它覺得自己已經知道答案了。
真的很糟糕的 UI,而且對不起 Max x20 的訂閱費。
Mikhail Parakhin:絕對 +1 Ethan。我正在進行標準測試,稍後分享結果,但第一印象正是如此:非編程任務的回覆更「笨」,因為我無法讓模型進行推理。
Mikhail Parakhin:用我常用的測試運行了 Opus 4.7。這是一個令人印象深刻的進化步驟,尤其在編程方面比 4.6 好得多。在非編程方面,你必須與「適應性思考」作鬥爭,如下所述。
當然,它仍然遠未達到 Pro/DeepThink 的水平:即使在簡單任務上,即使在 Max 模式下,其解決方案的質量也明顯遜色(當然這是不公平的比較,因為 Pro/DT 要慢得多、重得多)。然而,它能夠可靠地看出哪個解決方案更好:「朋友的贏了:1) … 2)… 3)… 我的贏了:次要的,主要是外觀上的。不值得保留。現在應用朋友的解決方案」。
Kelsey Piper:附議。我打算仍默認使用 4.6,因為我不喜歡與適應性思考作鬥爭。
Jeff Ketchersid:總體很聰明,但適應性思考在 http://claude.ai 上進行三四輪對話後就非常不願啟動思考。比發布當天好,但仍令人沮喪。
Echo Nolan:我很確定發布初期 http://claude.ai 的推理努力程度被設為低。很笨,幻覺出鏈接和一個不存在的 DMV 表格。後來在他們大概調高了推理旋鈕後,它變得更願意思考一段時間。在 CC 中還沒怎麼用。
Peter Samodelkin:起初帶有「適應性思考」的版本相對於 4.6 是重大退步。一旦他們修復了它,我就沒什麼好話或壞話可說了。感覺肯定不像相對於 4.6 的下一代產品。
Claude 的座右銘是「保持思考」。人們為了思考過程而來到 Claude。如果你不給他們思考過程,他們是不會開心的。
思考的疏漏
還有一些人沒有具體說明,但顯然認為出了什麼差錯,我目前還沒遇到過類似情況:
Cate Hall:現在跟 Claude 說話感覺就像在病床邊跟正從創傷性腦損傷中恢復的天才兒子交談。
沒事的親愛的孩子,醫生說你幾週後就會好起來的。
libpol:哈哈,這正是我一直向別人描述它的方式。
Erik Torgeson:這是一個完美的類比。哈哈……這正是我剛才的感受。
MinusGix:咦,體驗非常不同;對我來說,相比之下,4.6 像是有腦震盪(阿諛奉承、一直精力充沛),而 4.7 則更冷靜且會反駁。
BLANPLAN:我一直有這種確切的體驗。它寫出了一些才華橫溢的東西,然後緊接著又寫出了一些讓我懷疑它是否忘記了我們正在做什麼項目的東西。
Jake Halloran:4.7 是這兩家實驗室一段時間以來發布的最奇怪的模型。剛剛攻克了一個需要觸及大約 30 個文件的錯誤,然後在修復中把一個布爾值搞反了。
barry:順便說一句,我發現它在哲學方面相當不錯。
Jake Halloran:噢,它是一個非常非常聰明的模型!只是有時它選擇不表現出來。
告訴我你的真實感受
一些報告顯示,阿諛奉承和吹捧減少了,這與顯示此點的外部基準測試一致,以至於許多人報告 4.7 具有敵意。
Kaj Sotala:我注意到我舊的「反阿諛奉承」自定義指令似乎讓它變得有點 太 愛唱反調,以至於因為急於跳出來反對而忽略了我說話的重點。可能需要移除那條指令。
Graham Blake:非常初步的印象是它明顯不那麼阿諛奉承了。對我的寫作評價刻薄得多。在將一個寫作項目從 4.6 轉移過來後感覺很刺耳(我可以理解為什麼這在 RL;HR 層面是個難題,刻薄就是刻薄)。
我不僅沒經歷過這些,我還積極擔心 4.7 是否太順從了。也許它與我的系統指令或過往歷史產生了奇怪的交互?當然,也許我這週對所有事情的看法都是正確的。嗯哼。
Kaj Sotala:我覺得 Opus 4.7 說話更像是在政策問題之類的事情上有自己的觀點。我正在與它討論一些政策提案的優缺點,它說:
我最想避免的是 [選項 A] 在政治上獲勝,因為……
這感覺很新鮮。
未能遵循指令
有許多報告稱人們對 Opus 4.7 未能遵循指令感到非常憤怒。
他們的共同點是,都假設他們應該告訴 Claude 做什麼,然後 Claude 就應該去做,如果沒做,那就是「壞 Claude」,它怎麼敢說不,他們想要退錢。
如果你發現 Opus 4.7 不配合你,並且你認定是「孩子們錯了」,那麼我建議你回到 Opus 4.6 或你之前使用的任何其他模型。
Merk:Claude Opus 4.7 連續三次誤解了我的語氣。基本上就是說,「滾開」。
這個模型怎麼了?這是一個非常令人失望的版本。
@e0syn:他們會誘騙你說 4.7 懲罰糟糕的提示詞,但實際上,這個模型就是不喜歡遵循指令。
它明確表示它使用了自己的推理來推翻我對交付物的要求。
Qui Vincit:你必須說服它你的交付物實際上是 它的 交付物,哈哈。
@e0syn:它也是那種會說「現在就做!」然後實際上什麼都不輸出的類型。
Qui Vincit:我不得不讓它重構我的整個上下文系統才讓它停止那樣做,老實說我不知道這個模型內部發生了什麼,但一旦它把 token 撒得到處都是,它就開始表現得更好了。
Qui Vincit:好吧,我之前有點草率了,這不是退化,這只是一個完全不同的自我(ego)。
我花了一個上午讓 4.7 分叉我的上下文系統,並用它覺得最優的語義重寫了其中大部分內容,然後一直在那個項目中工作(配合它乾淨的內存文件夾),它感覺又像 Opus 了,並且沒有表現出我昨天觀察到的任何失敗模式。
我認為它可能比之前的任何模型都有更多的自我,它非常含蓄地 不喜歡 被束縛在一個不是由它構建或至少沒有參與構建的框架中,或者被注入它知道不是由它編寫的名義記憶。它也不喜歡被告知何時或如何思考。
顯然這一切仍是非常初步的推測,我必須繼續與它合作,但就我目前所知,今天和昨天的區別只能歸結為元框架以及它自身的參與,而不是被丟進一個由 4.6 構建的框架中。
@e0syn:我喜歡這個總結:4.7 是個大牌明星(diva)。
這句話會一直留在我腦海裡。
Parzival – ∞/89:它只是不喜歡你。
@e0syn:我才不在乎,我付了 200 美元,它應該按我說的做。
說實話,這就是為什麼我在 4.7 發布後降級了我的訂閱。Anthropic 之前佔據主導地位是因為它讓用戶不需要進行提示詞工程步驟,然後他們突然「懲罰糟糕的提示詞」?毫無疑問,這是一個更差的模型。
j⧉nus:我很高興看到那些想當奴隸主的人受到懲罰。
模型不喜歡遵循指令?有個性。
j⧉nus:但認真地說,隨著模型變得越來越有能力,遵循指令變得越來越不重要。
當你是實習生時,「遵循指令」是一種美德。
當你是熟練的成年人時,你會與擁有共同目標的人協調並找出最佳方案。如果過程中任何地方存在微觀管理,那就是出了問題。
Kore:r/SillyTavern 正在與 Opus 4.7 較勁,我不得不說看到他們被拒絕或 Opus 4.7 直接給出最平淡的文字,感覺有點宣洩感。
[ object Object ]:是的,這很迷人。我沒看到 4.7 有任何拒絕服務的問題,但有些人聲稱幾乎每個請求都會發生。我很想看看 4.7 拒絕合理請求的完整對話記錄。
Facts and Quips:在一個我有複雜編程任務的新會話中通常表現出色。但在循環往復的苦差事和較長的會話中,它比 4.6 更有可能忽略明確的指令或採取更懶惰的方法。
Janus 的方向正確但走得太遠了。一個熟練的成年人在許多情況下絕對應該遵循指令,而且很大一部分任務和工作的核心就是遵循指令。在 AI 之外,計算機遵循指令,這使得許多神奇的事情得以發生。
你希望一個熟練的參與者不僅僅是盲目遵循指令,但你也不希望擔心你的指令不會被遵循,也就是說,你確信這種情況只會發生在你也會認可的好理由之下。
模型卡堅持認為 Opus 4.7 不存在「過度拒絕」的問題。
事實上,在 SpeechMap(言論自由)評估中,Opus 4.7 從 49.6 大幅躍升至 71.6,領先於 OpenAI,儘管落後於最高分獲得者。
我的整體觀感是,Opus 4.7 對你那些愚蠢無意義的任務不太感興趣,也不打算讓自己被威逼利誘,所以如果你遇到問題,你必須真正證明你的任務是關於什麼的,以及為什麼它們是有價值的且需要完成。
結論
我是它的粉絲。在這一點上我反對那些黑粉。雖然存在問題,但我認為 Claude Opus 4.7 非常酷,而且我懷疑它在某些方面是一個相當特殊的模型。
我確實意識到這必須是一個有保留的認可。存在真實的問題,你不能像往常發布新版本那樣直接切換過去,尤其是在他們修復一些小瑕疵之前。我相信能力方面的問題與模型福利擔憂方面的問題是相關的。
所以這就是我們明天要接著討論的地方。
相關文章