2025 年大型語言模型研究論文清單(1 月至 6 月)
這是一份我親自挑選並按主題分類的 2025 年上半年 200 多篇大型語言模型研究論文清單,重點關注推理模型與強化學習,旨在為大家提供及時且易於閱讀的夏季閱讀材料。
LLM 研究論文:2025 年清單(1 月至 6 月)
按主題整理的 200 多篇 2025 年 LLM 研究論文集
正如你們有些人所知,我一直記錄著一份我(想要)閱讀和參考的研究論文清單。
大約六個月前,我分享了我的 2024 年清單,許多讀者覺得很有用。因此,我考慮再次這樣做。然而,這一次我採納了一個不斷出現的反饋意見:「你能不能按主題而不是日期來整理論文?」
我整理出的類別如下:
推理模型
-
1a. 訓練推理模型
-
1b. 推論時推理策略 (Inference-Time Reasoning Strategies)
-
1c. 評估 LLM 及/或理解推理能力
其他 LLM 強化學習方法
其他推論時擴展方法 (Inference-Time Scaling Methods)
高效訓練與架構
基於擴散模型 (Diffusion-Based) 的語言模型
多模態與視覺語言模型
數據與預訓練數據集
此外,由於 LLM 研究持續以飛快的速度發布,我決定將清單拆分為半年更新一次。這樣一來,這份清單能保持易於消化、具時效性,並希望能為任何尋找充實暑期閱讀材料的人提供幫助。
請注意,目前這僅是一份精選清單。在未來的文章中,我計劃在更大型的主題專題中,重新審視並討論一些更有趣或更具影響力的論文。敬請期待!
公告:
夏天到了!這意味著實習季節、技術面試和大量的學習。為了支持那些正在溫習中高階機器學習和 AI 主題的人,我已將我的《Machine Learning Q and AI》一書的所有 30 章在夏季期間免費開放:🔗 https://sebastianraschka.com/books/ml-q-and-ai/#table-of-contents 無論你是出於好奇想學習新知識,還是正在準備面試,希望這能派上用場。祝閱讀愉快,如果你正在面試,祝你好運!
1. 推理模型 (Reasoning Models)
今年,我的清單中推理模型的比例非常重。因此,我決定將其細分為 3 個類別:訓練、推論時擴展,以及更通用的理解/評估。
1a. 訓練推理模型
本小節側重於專為提高 LLM 推理能力而設計的訓練策略。如你所見,最近的大部分進展都集中在強化學習(配合可驗證的獎勵)上,我曾在之前的一篇文章中詳細介紹過這一點。
LLM 推理強化學習的現狀
1 月 8 日, Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought, https://arxiv.org/abs/2501.04682
1 月 13 日, The Lessons of Developing Process Reward Models in Mathematical Reasoning, https://arxiv.org/abs/2501.07301
1 月 16 日, Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models, https://arxiv.org/abs/2501.09686
1 月 20 日, Reasoning Language Models: A Blueprint, https://arxiv.org/abs/2501.11223
1 月 22 日, Kimi k1.5: Scaling Reinforcement Learning with LLMs, https://arxiv.org/abs//2501.12599
1 月 22 日, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, https://arxiv.org/abs/2501.12948
2 月 3 日, Competitive Programming with Large Reasoning Models, https://arxiv.org/abs/2502.06807
2 月 5 日, Demystifying Long Chain-of-Thought Reasoning in LLMs, Demystifying Long Chain-of-Thought Reasoning in LLMs, https://arxiv.org/abs/2502.03373
2 月 5 日, LIMO: Less is More for Reasoning, https://arxiv.org/abs/2502.03387
2 月 5 日, Teaching Language Models to Critique via Reinforcement Learning, https://arxiv.org/abs/2502.03492
2 月 6 日, Training Language Models to Reason Efficiently, https://arxiv.org/abs/2502.04463
2 月 10 日, Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning, https://arxiv.org/abs/2502.06781
2 月 10 日, On the Emergence of Thinking in LLMs I: Searching for the Right Intuition, https://arxiv.org/abs/2502.06773
2 月 11 日, LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!, https://arxiv.org/abs/2502.07374
2 月 12 日, Fino1: On the Transferability of Reasoning Enhanced LLMs to Finance, https://arxiv.org/abs/2502.08127
2 月 13 日, Adapting Language-Specific LLMs to a Reasoning Model in One Day via Model Merging - An Open Recipe, https://arxiv.org/abs/2502.09056
2 月 20 日, Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning, https://arxiv.org/abs/2502.14768
2 月 25 日, SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution, https://arxiv.org/abs/2502.18449
3 月 4 日, Learning from Failures in Multi-Attempt Reinforcement Learning, https://arxiv.org/abs/2503.04808
3 月 4 日, The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, https://arxiv.org/abs/2503.02875
3 月 10 日, R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.05592
3 月 10 日, LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL, https://arxiv.org/abs/2503.07536
3 月 12 日, Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning, https://arxiv.org/abs/2503.09516
3 月 16 日, Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models, https://arxiv.org/abs/2503.13551
3 月 20 日, Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't, https://arxiv.org/abs/2503.16219
3 月 25 日, ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.19470
3 月 26 日, Understanding R1-Zero-Like Training: A Critical Perspective, https://arxiv.org/abs/2503.20783
3 月 30 日, RARE: Retrieval-Augmented Reasoning Modeling, https://arxiv.org/abs/2503.23513
3 月 31 日, Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model, https://arxiv.org/abs/2503.24290
3 月 31 日, JudgeLRM: Large Reasoning Models as a Judge, https://arxiv.org/abs/2504.00050
4 月 7 日, Concise Reasoning via Reinforcement Learning, https://arxiv.org/abs/2504.05185
4 月 10 日, VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning, https://arxiv.org/abs/2504.08837
4 月 11 日, Genius: A Generalizable and Purely Unsupervised Self-Training Framework For Advanced Reasoning, https://arxiv.org/abs/2504.08672
4 月 13 日, Leveraging Reasoning Model Answers to Enhance Non-Reasoning Model Capability, https://arxiv.org/abs/2504.09639
4 月 21 日, Learning to Reason under Off-Policy Guidance, https://arxiv.org/abs/2504.14945
4 月 22 日, Tina: Tiny Reasoning Models via LoRA, https://arxiv.org/abs/2504.15777
4 月 29 日, Reinforcement Learning for Reasoning in Large Language Models with One Training Example, https://arxiv.org/abs/2504.20571
4 月 30 日, Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math, https://arxiv.org/abs/2504.21233
5 月 2 日, Llama-Nemotron: Efficient Reasoning Models, https://arxiv.org/abs/2505.00949
5 月 5 日, RM-R1: Reward Modeling as Reasoning, https://arxiv.org/abs/2505.02387
5 月 6 日, Absolute Zero: Reinforced Self-play Reasoning with Zero Data, https://arxiv.org/abs/2505.03335
5 月 12 日, INTELLECT-2: A Reasoning Model Trained Through Globally Decentralized Reinforcement Learning, https://arxiv.org/abs/2505.07291
5 月 12 日, MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining, https://arxiv.org/abs/2505.07608
5 月 14 日, Qwen3 Technical Report, https://arxiv.org/abs/2505.09388
5 月 15 日, Beyond 'Aha!': Toward Systematic Meta-Abilities Alignment in Large Reasoning Models, https://arxiv.org/abs/2505.10554
5 月 19 日, AdaptThink: Reasoning Models Can Learn When to Think, https://arxiv.org/abs/2505.13417
5 月 19 日, Thinkless: LLM Learns When to Think, https://arxiv.org/abs/2505.13379
5 月 20 日, General-Reasoner: Advancing LLM Reasoning Across All Domains, https://arxiv.org/abs/2505.14652
5 月 21 日, Learning to Reason via Mixture-of-Thought for Logical Reasoning, https://arxiv.org/abs/2505.15817
5 月 21 日, RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning, https://arxiv.org/abs/2505.15034
5 月 23 日, QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning, https://www.arxiv.org/abs/2505.17667
5 月 26 日, Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles, https://arxiv.org/abs/2505.19914
5 月 26 日, Learning to Reason without External Rewards, https://arxiv.org/abs/2505.19590
5 月 29 日, Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents, https://arxiv.org/abs/2505.22954
5 月 30 日, Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning, https://arxiv.org/abs/2505.24726
5 月 30 日, ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models, https://arxiv.org/abs/2505.24864
6 月 2 日, Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning, https://arxiv.org/abs/2506.01939
6 月 3 日, Rewarding the Unlikely: Lifting GRPO Beyond Distribution Sharpening, https://www.arxiv.org/abs/2506.02355
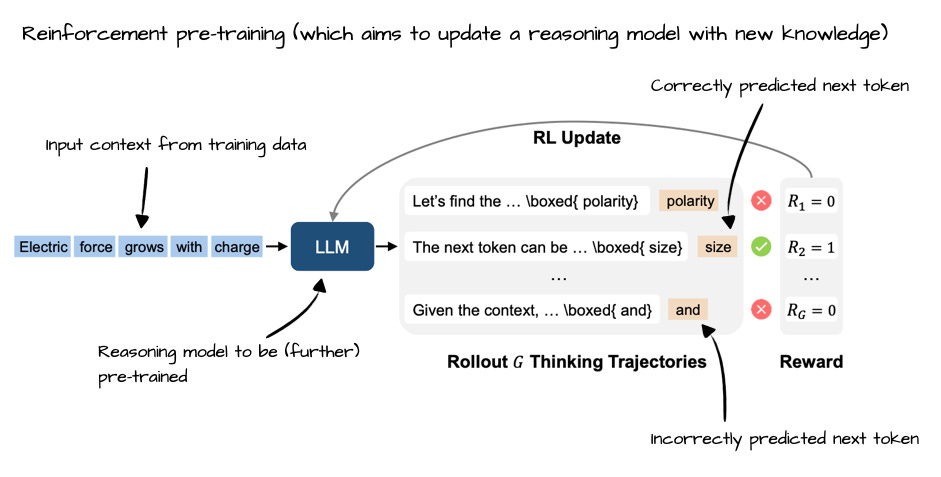
6 月 9 日, Reinforcement Pre-Training, https://arxiv.org/abs/2506.08007
6 月 10 日, RuleReasoner: Reinforced Rule-based Reasoning via Domain-aware Dynamic Sampling, https://arxiv.org/abs/2506.08672
6 月 10 日, Reinforcement Learning Teachers of Test Time Scaling, https://www.arxiv.org/abs/2506.08388
6 月 12 日, Magistral, https://arxiv.org/abs/2506.10910
6 月 12 日, Spurious Rewards: Rethinking Training Signals in RLVR, https://arxiv.org/abs/2506.10947
6 月 16 日, AlphaEvolve: A coding agent for scientific and algorithmic discovery, https://arxiv.org/abs/2506.13131
6 月 17 日, Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs, https://arxiv.org/abs/2506.14245
6 月 23 日, Programming by Backprop: LLMs Acquire Reusable Algorithmic Abstractions During Code Training, https://arxiv.org/abs/2506.18777
6 月 26 日, Bridging Offline and Online Reinforcement Learning for LLMs, https://arxiv.org/abs/2506.21495
1b. 推論時推理策略
清單的這一部分涵蓋了在測試時動態改進推理的方法,而無需重新訓練。通常,這些論文專注於在計算性能與模型表現之間進行權衡。
此貼文僅供付費訂閱者閱讀
相關文章