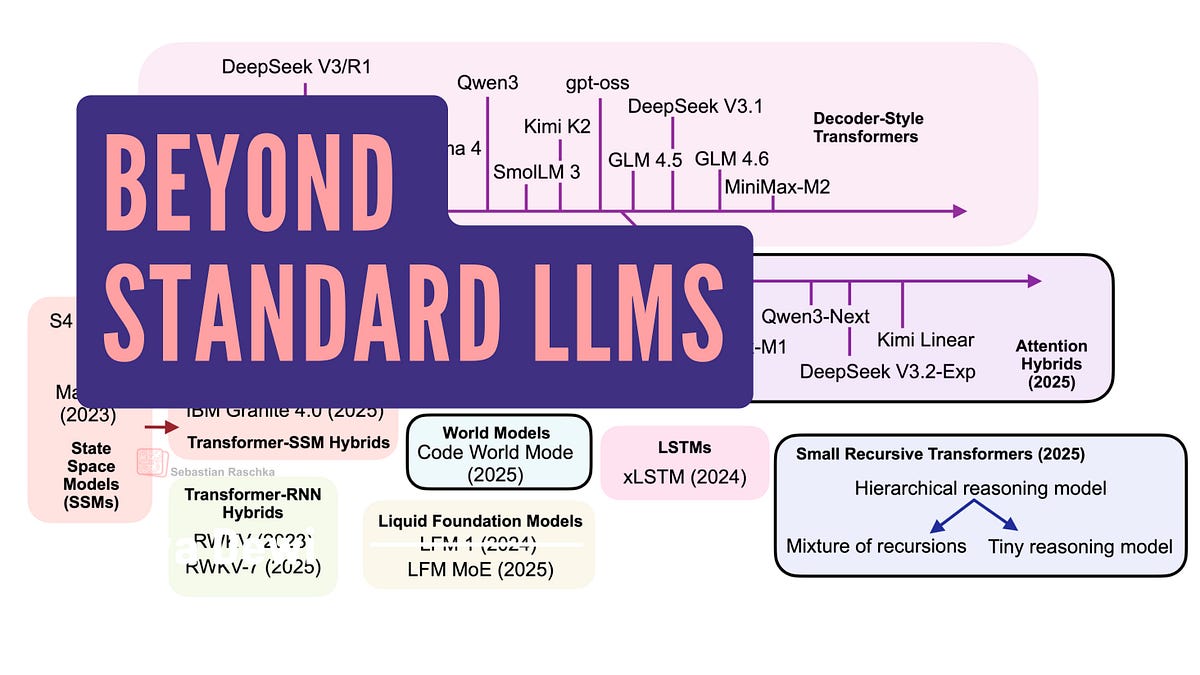
超越標準大語言模型:線性注意力混合架構與替代方案分析
這篇文章探討了傳統 Transformer 之外的大語言模型架構演進,重點關注線性注意力混合架構以及其他旨在提升效率與性能的新興替代方案。
超越標準大語言模型
線性注意力混合模型、文本擴散、代碼世界模型與小型遞歸 Transformer
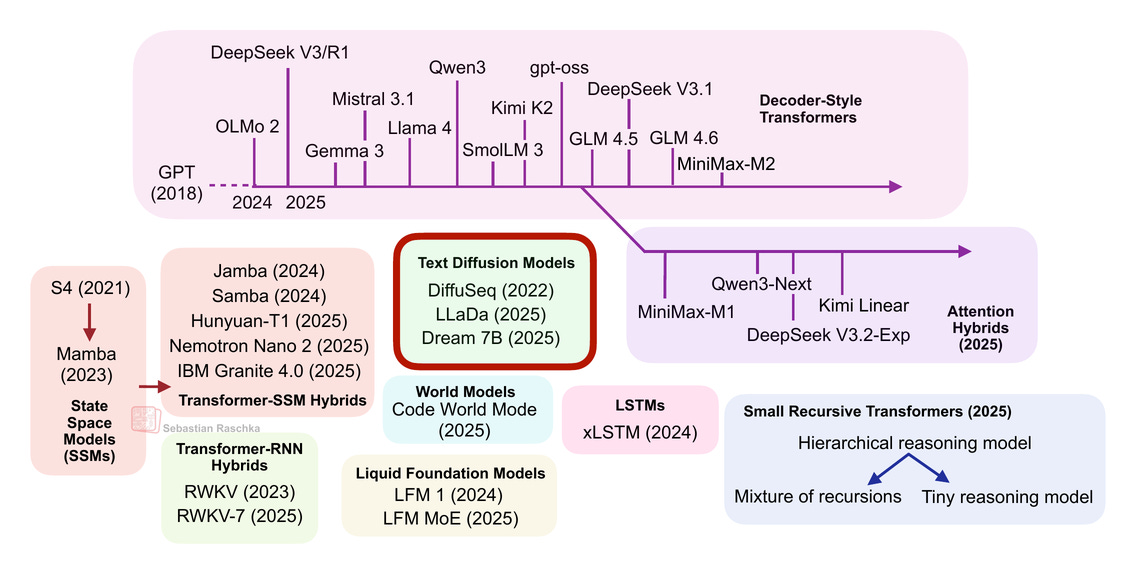
從 DeepSeek R1 到 MiniMax-M2,當今最強大且最具能力的開源大語言模型(LLM)仍然是自回歸解碼器(autoregressive decoder)風格的 Transformer,它們建立在原始多頭注意力機制(multi-head attention)的各種變體之上。
然而,近年來我們也看到了標準 LLM 之外的替代方案不斷湧現,從文本擴散模型(text diffusion models)到最新的線性注意力混合架構。其中一些旨在提高效率,而另一些(如代碼世界模型)則旨在提升建模性能。
幾個月前,我分享了《大型 LLM 架構比較》,重點關注主流的 Transformer LLM,之後收到了許多關於我對替代方案看法的提問。(我最近也在 PyTorch Conference 2025 上就此發表了簡短演講,並向與會者承諾會撰寫一篇關於這些替代方案的文章)。所以,這篇文章來了!
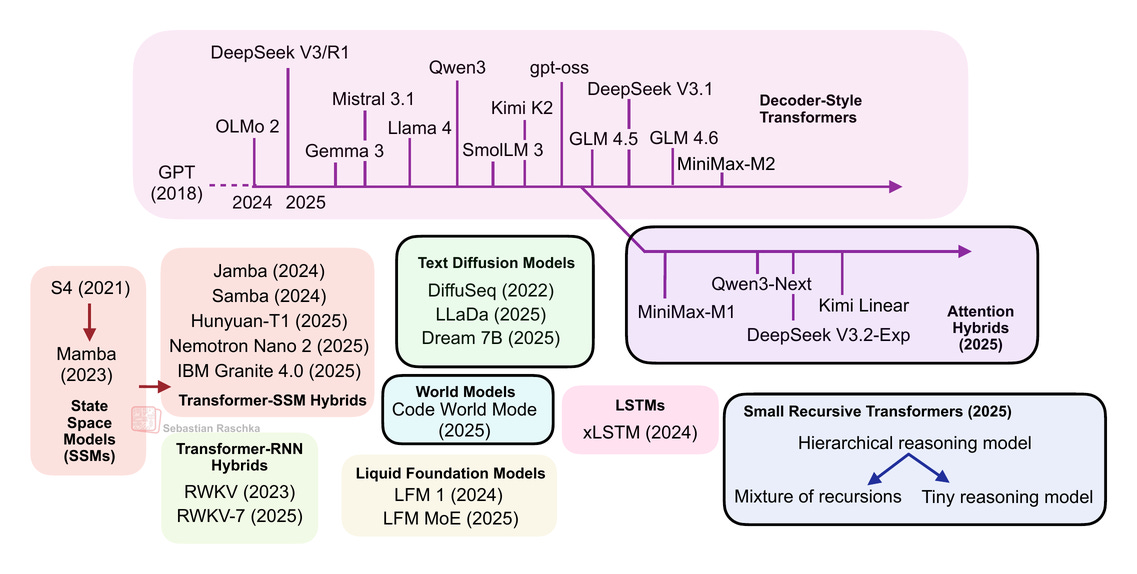
請注意,理想情況下,上圖中顯示的每個主題都值得至少寫一篇完整的文章(希望未來能實現)。因此,為了將本文篇幅控制在合理範圍內,許多章節都相對簡短。儘管如此,我希望這篇文章仍能作為近年來出現的所有有趣 LLM 替代方案的入門介紹。
備註:上述 PyTorch 會議演講將上傳至 PyTorch 官方 YouTube 頻道。與此同時,如果你感興趣,可以在下方找到練習錄製版本。
(這裡也有 YouTube 版本。)
1. 基於 Transformer 的 LLM
基於經典《Attention Is All You Need》架構的 Transformer LLM 在文本和代碼領域仍處於領先地位。如果我們僅回顧 2024 年底至今的一些亮點,著名的模型包括:
DeepSeek V3/R1
OLMo 2
Gemma 3
Mistral Small 3.1
Llama 4
Qwen3
SmolLM3
Kimi K2
gpt-oss
GLM-4.5
GLM-4.6
MiniMax-M2
以及更多。
(上述列表主要關注開源模型;還有如 GPT-5、Grok 4、Gemini 2.5 等專有模型也屬於這一類。)
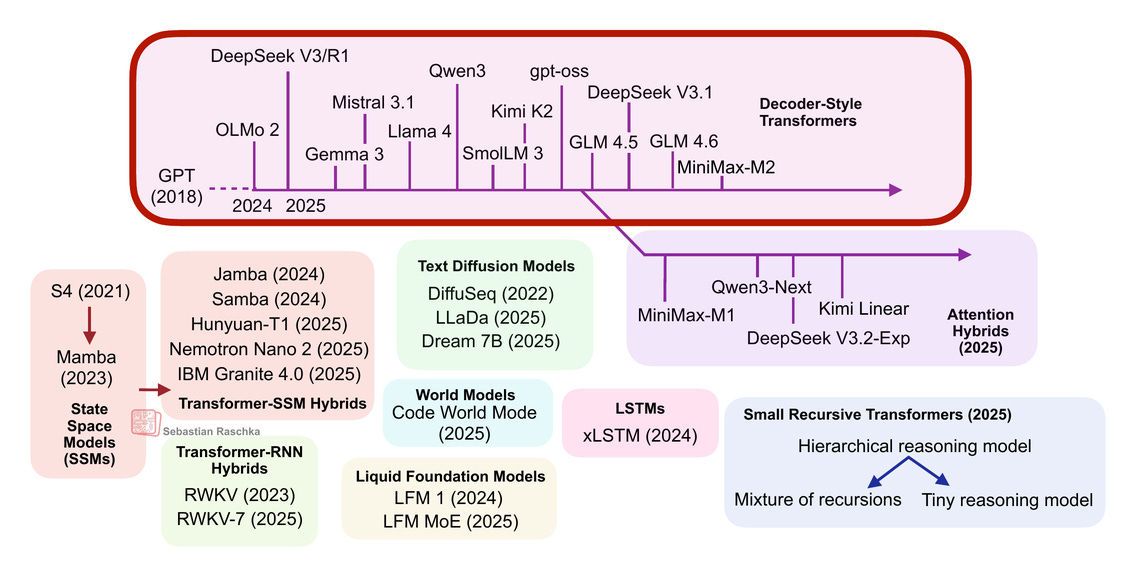
由於我已經多次談論和撰寫過基於 Transformer 的 LLM,我假設你已經熟悉其大致概念和架構。如果你想了解更深入的內容,我在《大型 LLM 架構比較》一文中對上述列出(及下圖所示)的架構進行了對比。
(補充說明:我本可以將 Qwen3-Next 和 Kimi Linear 與總覽圖中的其他 Transformer-狀態空間模型 (SSM) 混合模型歸為一類。就個人而言,我將那些混合模型視為帶有 Transformer 組件的 SSM,而將此處討論的模型(Qwen3-Next 和 Kimi Linear)視為帶有 SSM 組件的 Transformer。不過,既然我已將 IBM Granite 4.0 和 NVIDIA Nemotron Nano 2 列在 Transformer-SSM 框中,將它們歸入同一類別也是有道理的。)
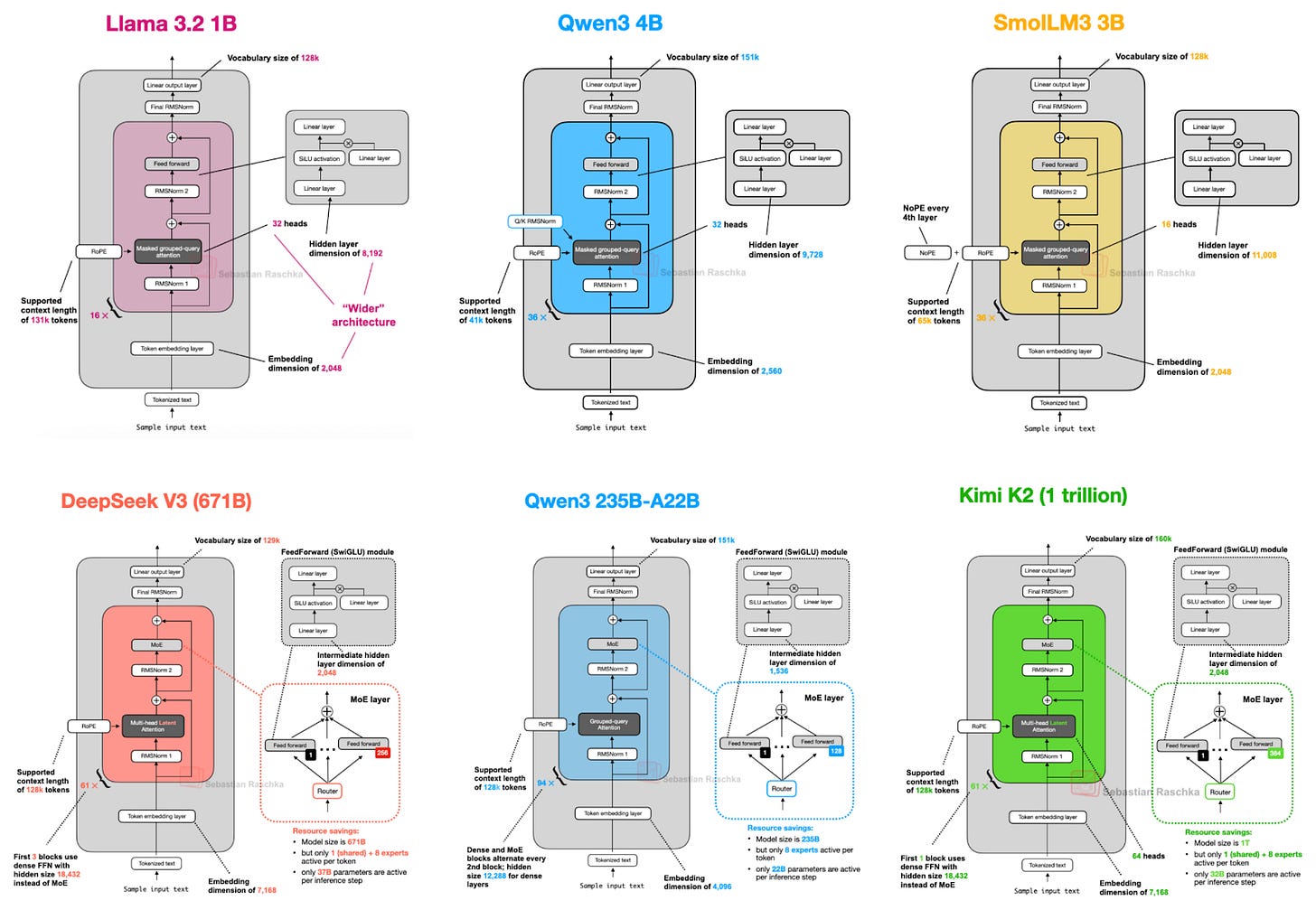
如果你正在從事 LLM 相關工作,例如開發應用、微調模型或嘗試新算法,我會建議將這些模型作為首選。它們經過測試、驗證且性能優異。
此外,正如《大型架構比較》文章中所討論的,目前已有許多效率改進方案,包括分組查詢注意力(grouped-query attention)、滑動窗口注意力(sliding-window attention)、多頭潛在注意力(multi-head latent attention)等。
然而,如果研究人員和工程師不嘗試其他替代方案,那將會很乏味(且短視)。因此,接下來的章節將介紹近年來出現的一些有趣的替代方案。
2. (線性) 注意力混合模型
在討論「差異更大」的方法之前,讓我們先看看採用了更高效注意力機制的 Transformer LLM。特別是那些計算量隨輸入標記(token)數量呈線性而非平方增長的模型。
最近,線性注意力機制為了提高 LLM 效率而再次興起。
《Attention Is All You Need》論文(2017)中引入的注意力機制,即縮放點積注意力(scaled-dot-product attention),仍然是當今 LLM 中最受歡迎的變體。除了傳統的多頭注意力外,它也用於我在演講中討論的更高效版本,如分組查詢注意力、滑動窗口注意力和多頭潛在注意力。
2.1 傳統注意力與平方成本
原始注意力機制的計算量隨序列長度呈平方級增長:
這是因為查詢 (Q)、鍵 (K) 和值 (V) 是 n×d 矩陣,其中 d 是嵌入維度(超參數),n 是序列長度(即標記數量)。
(你可以在我的《理解並編寫 LLM 中的自注意力、多頭注意力、因果注意力和交叉注意力》文章中找到更多細節)
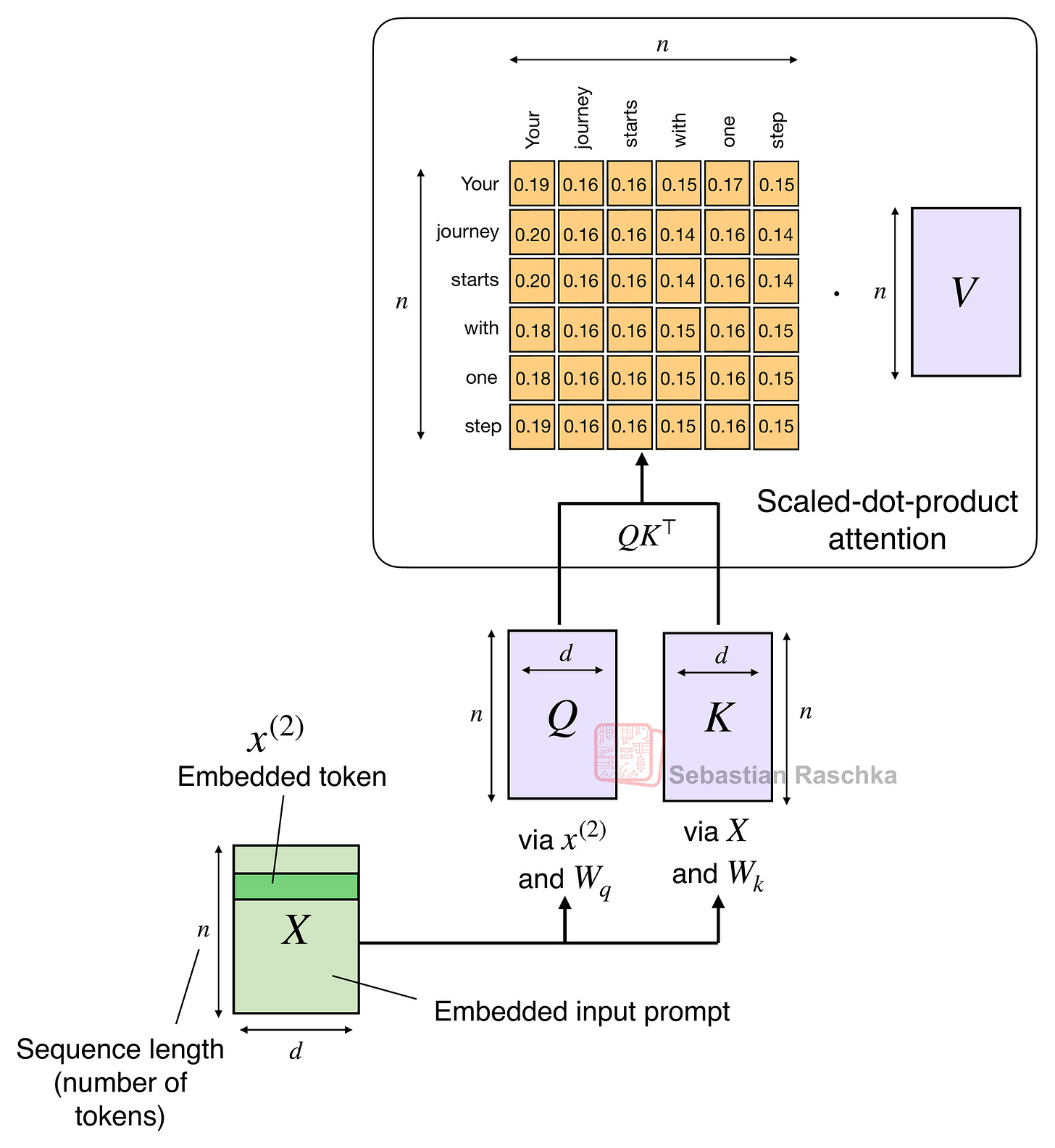
2.2 線性注意力
線性注意力變體已經存在很長時間了,我記得在 2020 年代看過大量相關論文。例如,我記得最早的一篇是 2020 年的《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》,研究人員在其中對注意力機制進行了近似:
這裡,ϕ(⋅) 是一個核特徵函數,設置為 ϕ(x) = elu(x)+1。
這種近似非常高效,因為它避免了顯式計算 n×n 的注意力矩陣 QKT。
我不想在這些舊嘗試上停留太久。但結論是,它們將時間和空間複雜度從 O(n²) 降低到 O(n),使注意力機制在處理長序列時更加高效。
然而,它們從未真正流行起來,因為它們降低了模型準確性,而且我從未真正見過這些變體被應用於開源的頂尖 LLM 中。
2.3 線性注意力的復興
在今年下半年,線性注意力變體迎來了復興,模型開發者之間也出現了一些反覆,如下圖所示。
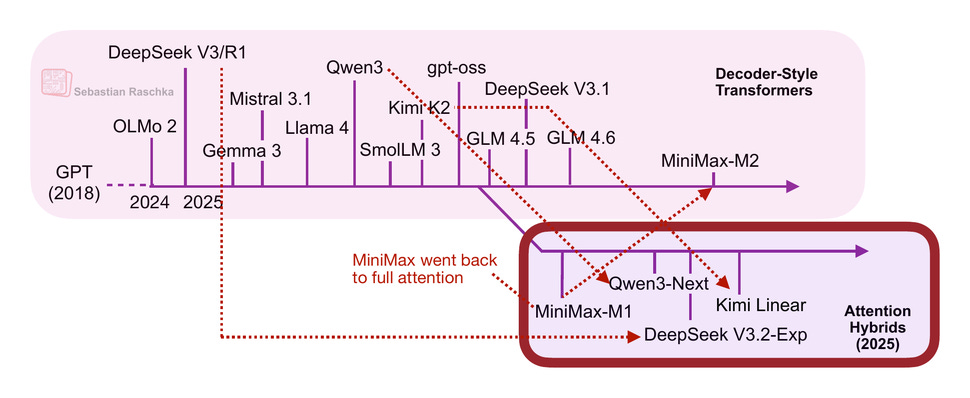
第一個值得關注的模型是採用 Lightning Attention 的 MiniMax-M1。
MiniMax-M1 是一個擁有 456B 參數的混合專家 (MoE) 模型,其中激活參數為 46B,於今年 6 月發佈。
隨後在 8 月,Qwen3 團隊推出了 Qwen3-Next,我在上文已詳細討論過。接著在 9 月,DeepSeek 團隊宣佈了 DeepSeek V3.2。(DeepSeek V3.2 的稀疏注意力機制並非嚴格的線性,但至少在計算成本上是亞平方級的,所以我認為將其與 MiniMax-M1、Qwen3-Next 和 Kimi Linear 歸為一類是合理的。)
這三個模型(MiniMax-M1、Qwen3-Next、DeepSeek V3.2)在其大部分或所有層中,都將傳統的平方級注意力變體替換為高效的線性變體。
有趣的是,最近出現了一個轉折:MiniMax 團隊發佈了新的 230B 參數 M2 模型,卻棄用了線性注意力,回歸到常規注意力。該團隊表示,線性注意力在生產級 LLM 中非常棘手。它在處理常規提示詞時表現尚可,但在推理和多輪對話任務中準確性較差,而這些任務不僅對常規聊天很重要,對智能體(agentic)應用也至關重要。
這本可能成為一個轉折點,讓人覺得線性注意力終究不值得追求。然而,事情變得更有趣了。10 月,Kimi 團隊發佈了採用線性注意力的全新 Kimi Linear 模型。
在線性注意力方面,Qwen3-Next 和 Kimi Linear 都採用了 Gated DeltaNet,我想在接下來的幾節中將其作為混合注意力架構的一個例子進行討論。
2.4 Qwen3-Next
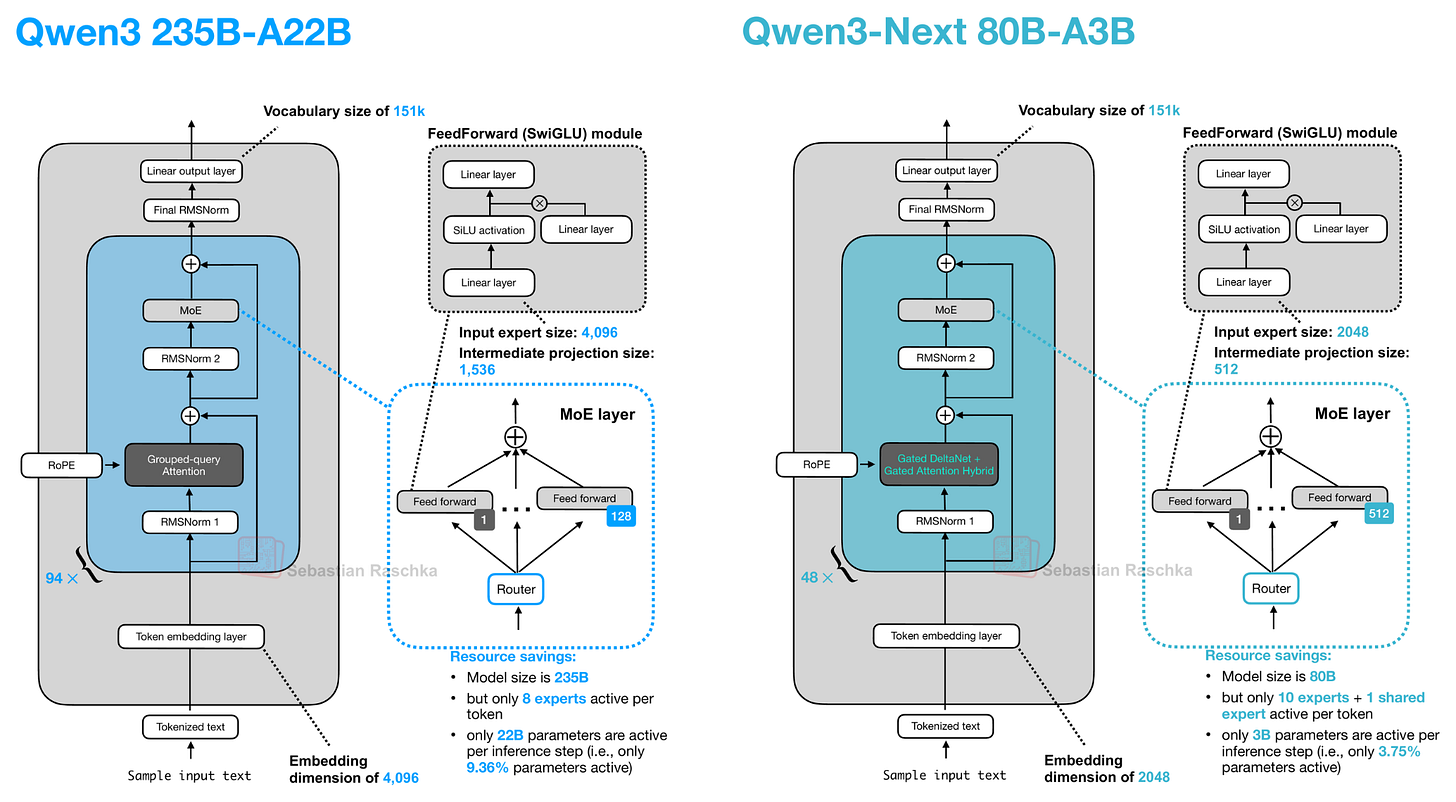
讓我們從 Qwen3-Next 開始,它將常規注意力機制替換為 Gated DeltaNet + Gated Attention 混合架構,這有助於在內存佔用方面實現原生 262k 標記的上下文長度(之前的 235B-A22B 模型原生支持 32k,通過 YaRN 縮放支持 131k)。
他們的混合機制將 Gated DeltaNet 區塊與 Gated Attention 區塊以 3:1 的比例混合,如下圖所示。
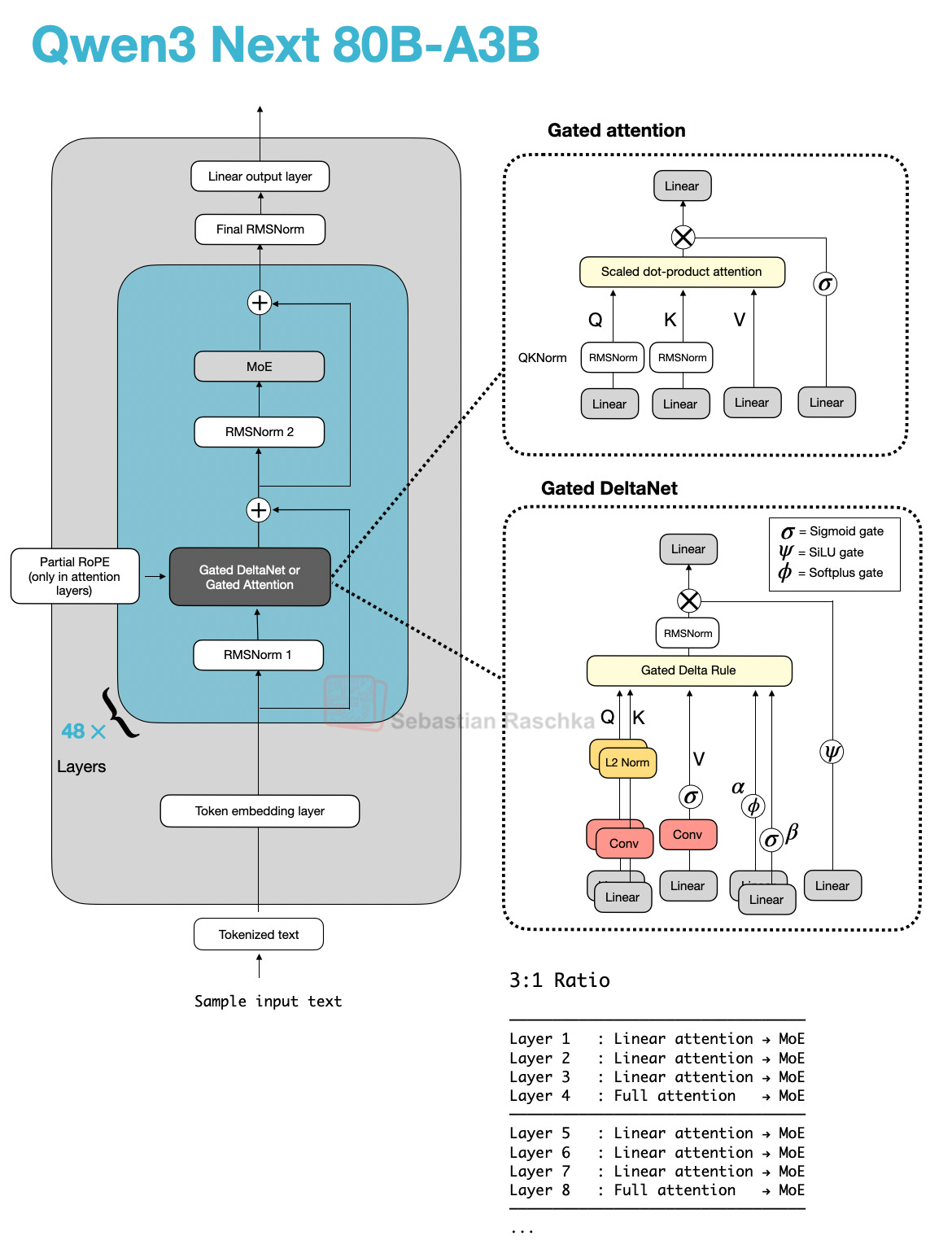
如上圖所示,注意力機制要麼實現為 Gated Attention,要麼實現為 Gated DeltaNet。這僅僅意味著該架構中的 48 個 Transformer 區塊(層)在這兩者之間交替。具體來說,如前所述,它們以 3:1 的比例交替。例如,Transformer 區塊排列如下:
除此之外,該架構非常標準,與 Qwen3 相似:
那麼,什麼是 Gated Attention 和 Gated DeltaNet?
2.5 Gated Attention (門控注意力)
在討論 Gated DeltaNet 本身之前,我們先簡要談談「門」(gate)。正如你在上圖 Qwen3-Next 架構上半部分看到的,Qwen3-Next 使用了「Gated Attention」。這本質上是帶有額外 sigmoid 門的常規全注意力。
這種門控是一個簡單的修改,我將其添加到 MultiHeadAttention 實現中(基於我《從零開始構建 LLM》書中第 3 章的代碼)以供說明:
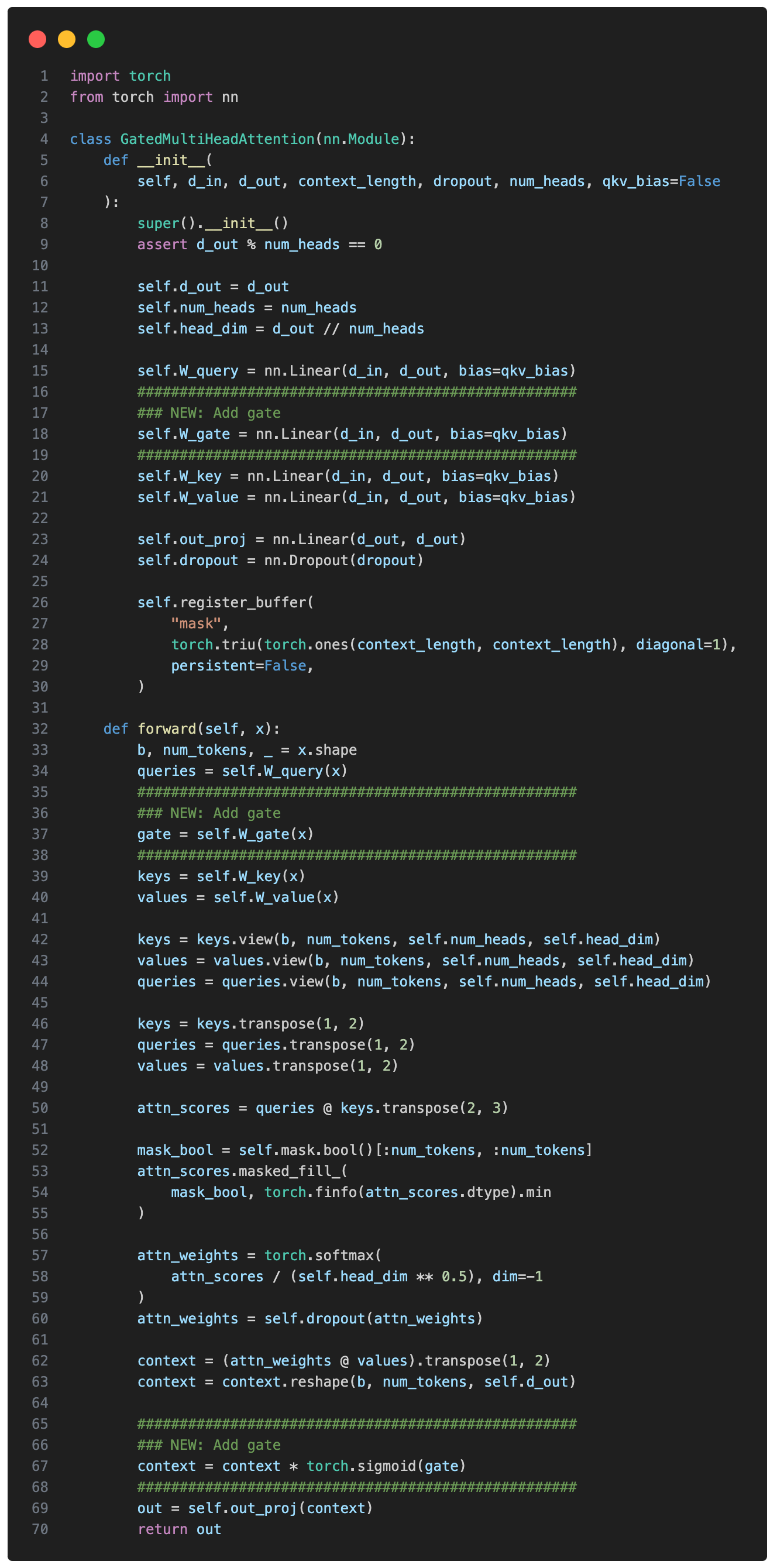
我們可以看到,在照常計算注意力後,模型從相同的輸入中提取一個單獨的門控信號,應用 sigmoid 將其保持在 0 到 1 之間,並將其與注意力輸出相乘。這允許模型動態地放大或縮小某些特徵。Qwen3-Next 的開發者表示這有助於訓練穩定性:
[...] 注意力輸出門控機制有助於消除注意力匯聚(Attention Sink)和大規模激活(Massive Activation)等問題,確保整個模型的數值穩定性。
簡而言之,Gated Attention 調節了標準注意力的輸出。在下一節中,我們將討論 Gated DeltaNet,它將注意力機制本身替換為循環的 Delta 規則內存更新。
2.6 Gated DeltaNet
那麼,什麼是 Gated DeltaNet?Gated DeltaNet(Gated Delta Network 的縮寫)是 Qwen3-Next 的線性注意力層,旨在作為標準 softmax 注意力的替代方案。如前所述,它源自《Gated Delta Networks: Improving Mamba2 with Delta Rule》論文。
Gated DeltaNet 最初被提議為 Mamba2 的改進版本,它結合了 Mamba2 的門控衰減機制與 Delta 規則。
Mamba 是一種狀態空間模型(Transformer 的替代方案),這是一個大主題,值得未來單獨報導。
Delta 規則部分是指計算新值與預測值之間的差異(delta, Δ),以更新用作內存狀態的隱藏狀態(稍後詳述)。
(補充說明:熟悉經典機器學習文獻的讀者可以將其視為類似於受生物學啟發的赫布學習(Hebbian learning):「同時激發的細胞會連結在一起。」它基本上是感知器更新規則和基於梯度下降學習的前身,但沒有監督。)
Gated DeltaNet 擁有一個與前述 Gated Attention 類似的門,不同之處在於它使用 SiLU 而非邏輯 sigmoid 激活函數,如下圖所示。(選擇 SiLU 可能是為了比標準 sigmoid 提供更好的梯度流和穩定性。)
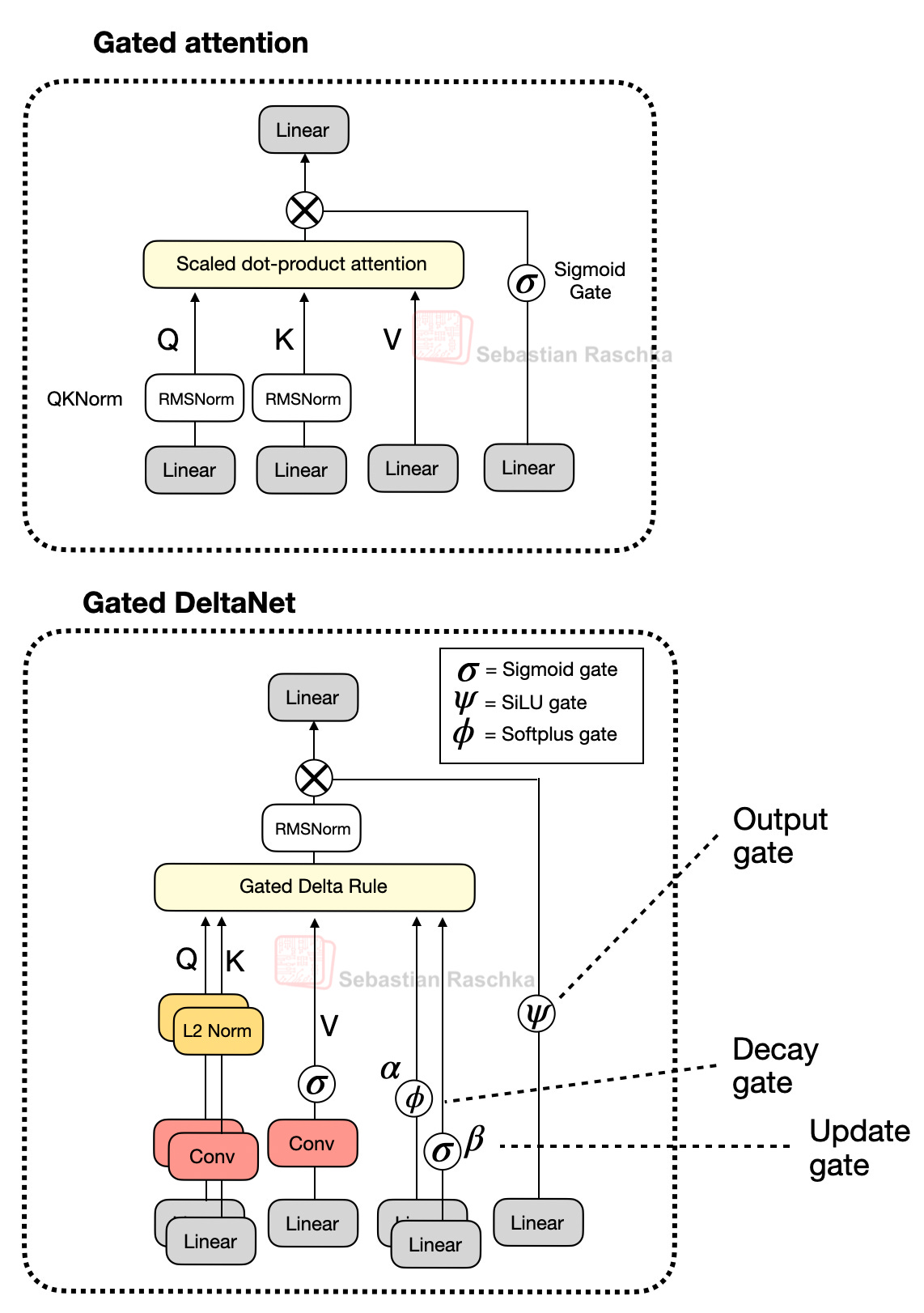
然而,如上圖所示,除了輸出門之外,Gated DeltaNet 中的「門控」還指幾個額外的門:
α (衰減門) 控制內存隨時間衰減或重置的速度,
β (更新門) 控制新輸入修改狀態的強度。
在代碼中,上述 Gated DeltaNet 的簡化版本(不含卷積混合)可以實現如下(代碼靈感來自 Qwen3 團隊的官方實現):
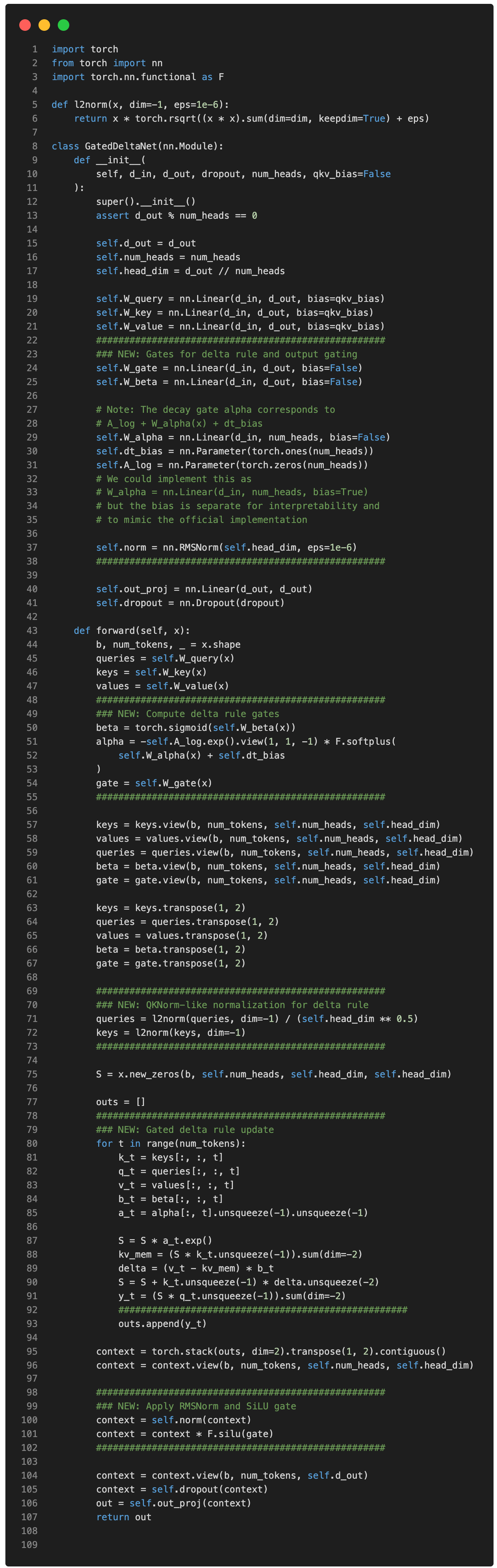
(請注意,為了簡單起見,我省略了 Qwen3-Next 和 Kimi Linear 使用的卷積混合,以保持代碼更具可讀性並專注於循環方面。)
因此,正如我們在上面看到的,這與標準(或門控)注意力有很多不同。
在 Gated Attention 中,模型計算所有標記之間的正常注意力(每個標記都關注或查看其他每個標記)。然後,在獲得注意力輸出後,一個門(sigmoid)決定保留多少輸出。關鍵在於它仍然是常規的縮放點積注意力,其計算量隨上下文長度呈平方級增長。
溫習一下,縮放點積注意力的計算公式為 softmax(QKᵀ)V,其中 Q 和 K 是 n×d 矩陣,n 是輸入標記數,d 是嵌入維度。因此 QKᵀ 會產生一個 n×n 的注意力矩陣,然後乘以 n×d 維的值矩陣 V。
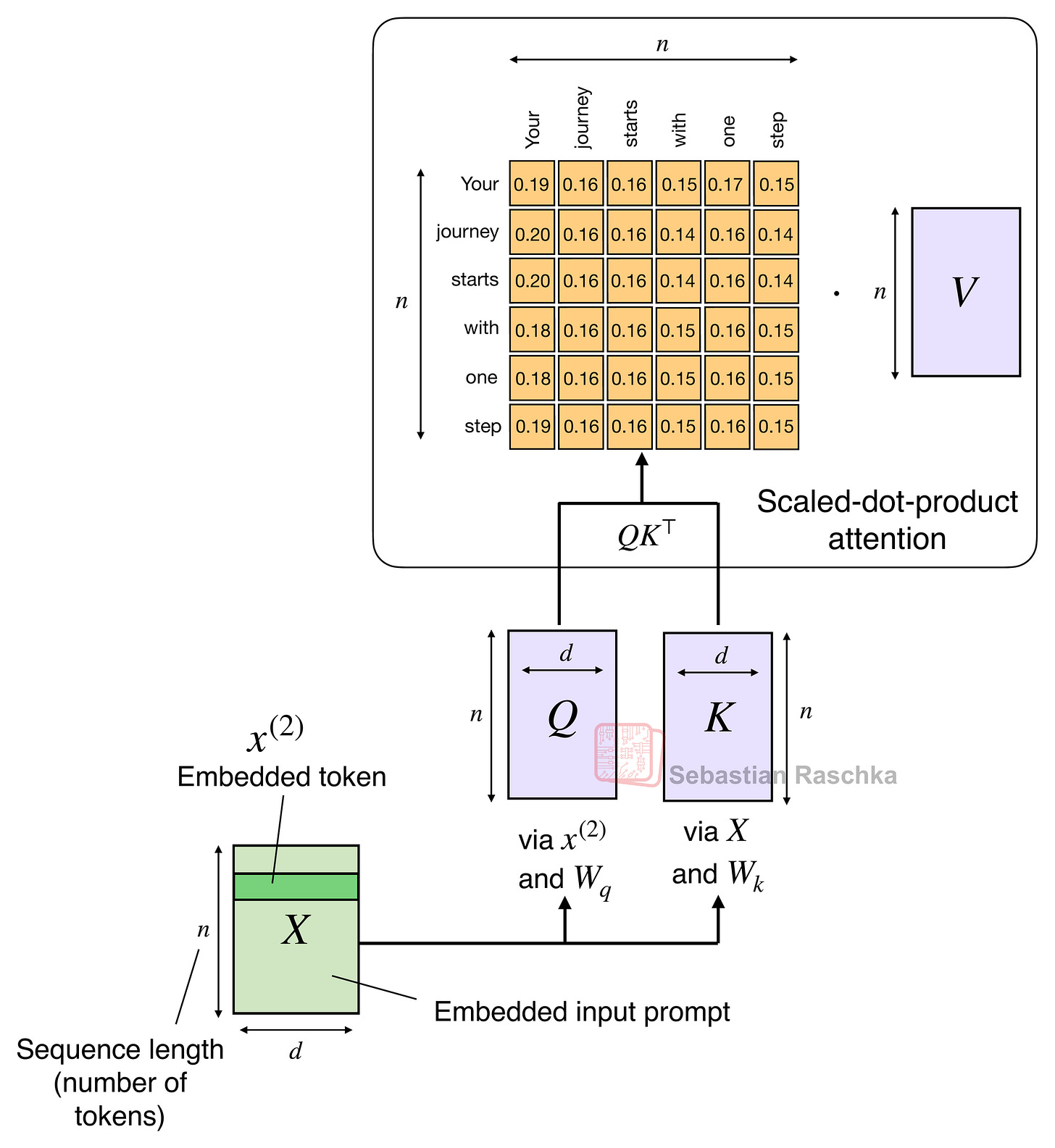
在 Gated DeltaNet 中,沒有 n×n 的注意力矩陣。相反,模型逐個處理標記。它維持一個運行的內存(狀態),並隨著每個新標記的進入而更新。這就是實現為循環更新的地方,其中 S 是每個時間步 t 循環更新的狀態。
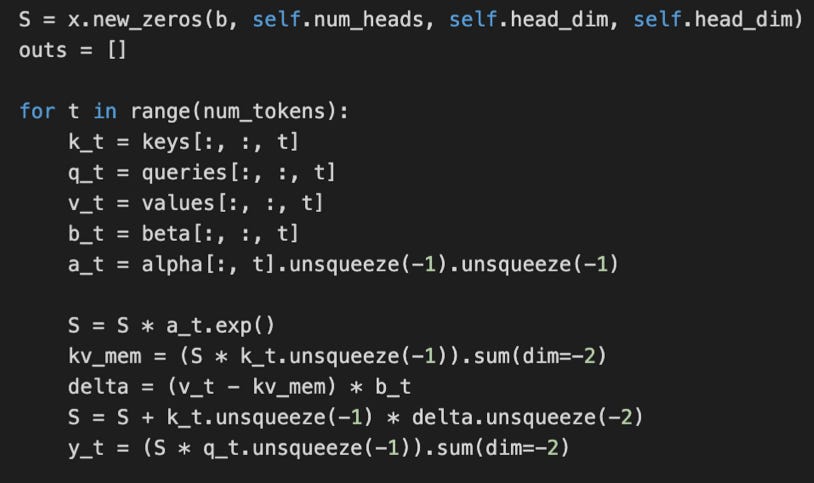
門控控制內存如何變化:
α (alpha) 調節遺忘(衰減)多少舊內存。
β (beta) 調節時間步 t 的當前標記對內存的更新程度。
(最後的輸出門,未在上面的代碼片段中顯示,與 Gated Attention 類似;它控制保留多少輸出。)
因此,從某種意義上說,Gated DeltaNet 中的這種狀態更新與循環神經網絡 (RNN) 的工作方式相似。優點是它的計算量隨上下文長度呈線性增長(通過 for 循環),而非平方級增長。
這種循環狀態更新的缺點是,與常規(或門控)注意力相比,它犧牲了來自全對等注意力的全局上下文建模能力。
Gated DeltaNet 在某種程度上仍能捕捉上下文,但必須通過內存 (S) 瓶頸。該內存大小固定,因此效率更高,但它會像 RNN 一樣將過去的上下文壓縮到單個隱藏狀態中。
這就是為什麼 Qwen3-Next 和 Kimi Linear 架構沒有將所有注意力層替換為 DeltaNet 層,而是使用了前面提到的 3:1 比例。
2.7 DeltaNet 的內存節省
在上一節中,我們討論了 DeltaNet 相對於全注意力在計算複雜度上的優勢(線性 vs 平方)。
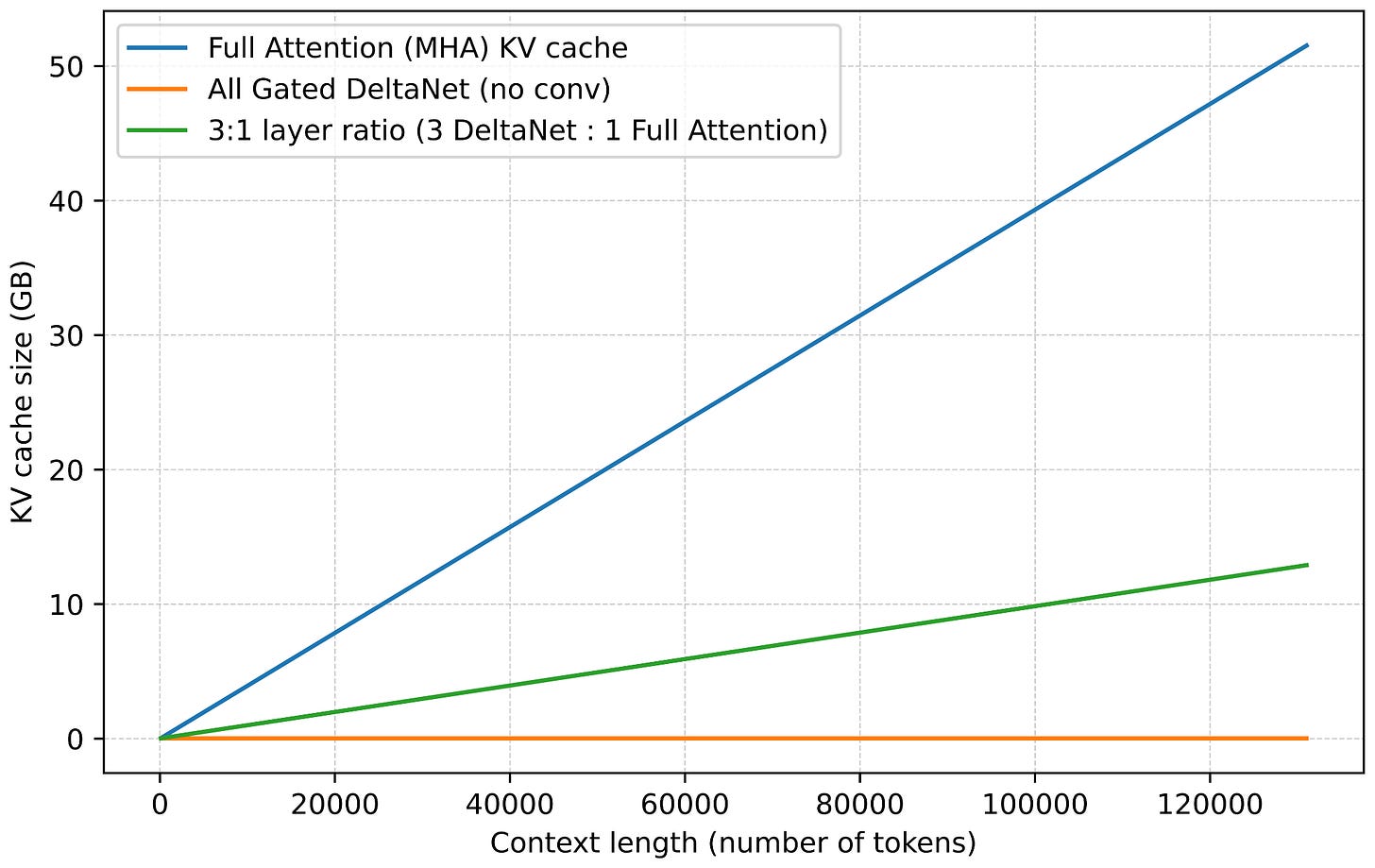
除了線性計算複雜度外,DeltaNet 的另一個巨大優勢是節省內存,因為 DeltaNet 模塊不會增加 KV 快取(KV cache)。(有關 KV 快取的更多信息,請參閱我的《從零開始理解並編寫 LLM 中的 KV 快取》文章)。相反,如前所述,它們保持固定大小的循環狀態,因此內存隨上下文長度保持不變。
對於常規的多頭注意力 (MHA) 層,我們可以如下計算 KV 快取大小:
(乘數 2 是因為我們在快取中同時存儲了鍵和值。)
對於上面實現的簡化版 DeltaNet,我們有:
請注意,KV_cache_DeltaNet 的內存大小不依賴於上下文長度 (n_tokens)。此外,我們只存儲內存狀態 S,而不是單獨的鍵和值,因此 2 × bytes 變成了 bytes。但是,請注意這裡現在有一個平方項 d_head × d_head。這來自於狀態:
但這通常不需要擔心,因為頭維度(head dimension)通常相對較小。例如,在 Qwen3-Next 中它是 128。
包含卷積混合的完整版本會稍微複雜一些,包括內核大小等,但上述公式應能說明 Gated DeltaNet 背後的主要趨勢和動機。
2.8 Kimi Linear vs. Qwen3-Next
Kimi Linear 與 Qwen3-Next 在結構上有幾處相似之處。兩款模型都依賴混合注意力策略。具體來說,它們將輕量級線性注意力與較重的全注意力層相結合。具體而言,兩者都使用 3:1 的比例,這意味著每三個採用線性 Gated DeltaNet 變體的 Transformer 區塊,就有一個使用全注意力的區塊,如下圖所示。
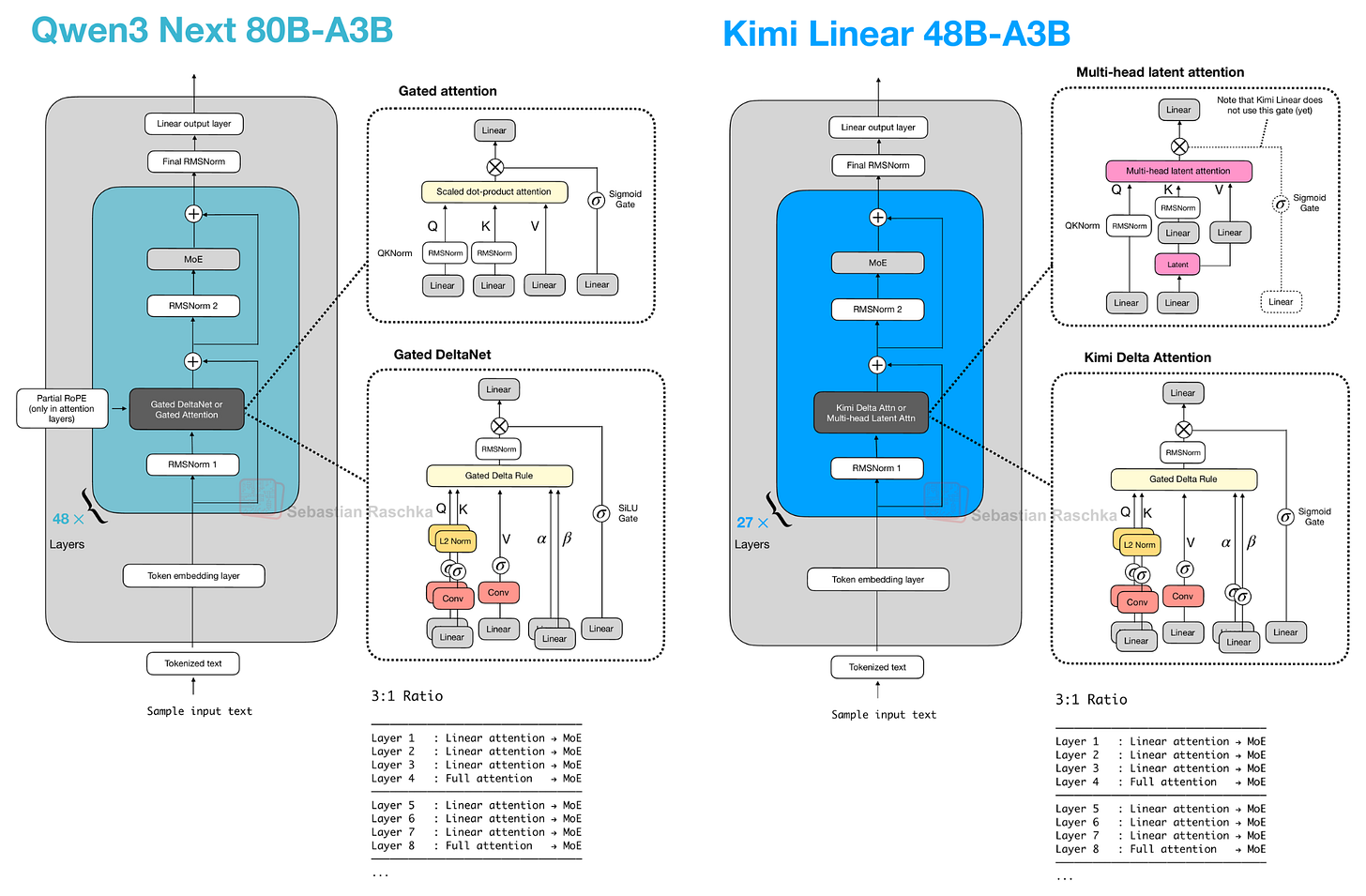
Gated DeltaNet 是一種受循環神經網絡啟發的線性注意力變體,包含來自《Gated Delta Networks: Improving Mamba2 with Delta Rule》論文的門控機制。從某種意義上說,Gated DeltaNet 是帶有 Mamba 風格門控的 DeltaNet,而 DeltaNet 則是一種線性注意力機制(下一節將詳細介紹)。
上圖 11 右上框中所示的 Kimi Linear 中的 MLA 不使用 sigmoid 門。這種省略是故意的,以便作者能更直接地將該架構與標準 MLA 進行比較,不過他們表示計劃在未來加入。
另外請注意,上圖 Kimi Linear 部分故意省略了 RoPE 框。Kimi 在多頭潛在注意力 (MLA) 層(全局注意力)中應用了 NoPE (無位置嵌入)。正如作者所述,這讓 MLA 在推理時能以純多查詢注意力(multi-query attention)運行,並避免了長上下文縮放時的 RoPE 重新調整(位置偏差據稱由 Kimi Delta Attention 區塊處理)。有關 MLA 和多查詢注意力(分組查詢注意力的特例)的更多信息,請參閱我的《大型 LLM 架構比較》文章。
2.9 Kimi Delta Attention
Kimi Linear 通過 Kimi Delta Attention (KDA) 機制修改了 Qwen3-Next 的線性注意力機制,這本質上是 Gated DeltaNet 的改進。Qwen3-Next 應用標量門(每個注意力頭一個值)來控制內存衰減率,而 Kimi Linear 則將其替換為每個特徵維度的通道級門控(channel-wise gating)。據作者稱,這提供了對內存更強的控制,進而提高了長上下文推理能力。
此外,對於全注意力層,Kimi Linear 將 Qwen3-Next 的門控注意力層(本質上是帶有輸出門控的標準多頭注意力層)替換為多頭潛在注意力 (MLA)。這與 DeepSeek V3/R1 使用的 MLA 機制相同(如我的《大型 LLM 架構比較》文章所述),但增加了一個門。(回顧一下,MLA 壓縮了鍵/值空間以減小 KV 快取大小。)
目前沒有與 Qwen3-Next 的直接對比,但與 Gated DeltaNet 論文中的 Gated DeltaNet-H1 模型(本質上是帶有滑動窗口注意力的 Gated DeltaNet)相比,Kimi Linear 在保持相同標記生成速度的同時,實現了更高的建模準確性。
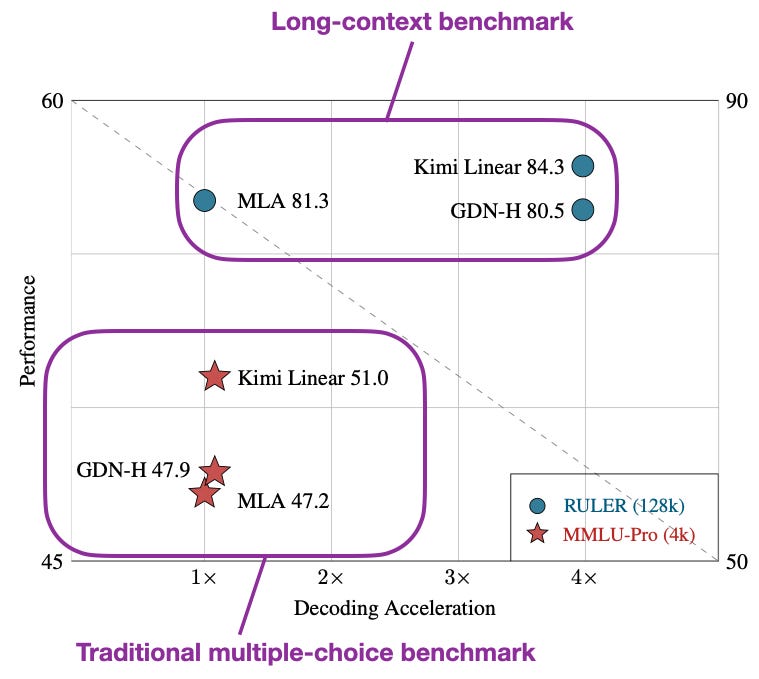
此外,根據 DeepSeek-V2 論文中的消融實驗,當超參數精心選擇時,MLA 與常規全注意力性能相當。
Kimi Linear 在長上下文和推理基準測試中與 MLA 相比表現出色,這一事實使得線性注意力變體再次在大型頂尖模型中展現出前景。話雖如此,Kimi Linear 擁有 48B 參數,但比 Kimi K2 小 20 倍。看看 Kimi 團隊是否會在即將推出的 K3 模型中採用這種方法將會非常有趣。
2.10 注意力混合模型的未來
線性注意力並非新概念,但近期混合方法的復興表明,研究人員正再次認真尋找使 Transformer 更高效的實用方法。例如,與常規全注意力相比,Kimi Linear 減少了 75% 的 KV 快取,並提升了高達 6 倍的解碼吞吐量。
使這新一代線性注意力變體與早期嘗試不同之處在於,它們現在是與標準注意力協同使用,而非完全取代它。
展望未來,我預計下一波注意力混合模型將專注於進一步提高長上下文穩定性和推理準確性,使其更接近全注意力的頂尖水平。
3. 文本擴散模型 (Text Diffusion Models)
與標準自回歸 LLM 架構相比,更徹底的背離是文本擴散模型家族。
你可能對擴散模型很熟悉,它們基於 2020 年用於生成圖像的《Denoising Diffusion Probabilistic Models》論文(作為生成對抗網絡的繼任者),後來被 Stable Diffusion 等模型實現、擴展並普及。

3.1 為什麼研究文本擴散?
隨著 2022 年《Diffusion-LM Improves Controllable Text Generation》論文的發表,我們開始看到研究人員採用擴散模型生成文本的趨勢。我在 2025 年已經看到了大量文本擴散論文。當我查看我的論文書籤列表時,上面有 39 個文本擴散模型!鑑於這些模型日益增長的受歡迎程度,我認為是時候談談它們了。
那麼,擴散模型的優勢是什麼?為什麼研究人員將其視為傳統自回歸 LLM 的替代方案?
傳統的基於 Transformer 的(自回歸)LLM 一次生成一個標記。為了簡潔起見,我們將其簡稱為自回歸 LLM。現在,基於文本擴散的 LLM(我們稱之為「擴散 LLM」)的主要賣點是它們可以並行生成多個標記,而不是順序生成。
請注意,擴散 LLM 仍需要多個去噪(denoising)步驟。然而,即使擴散模型需要(例如)64 個去噪步驟來在每一步並行產生所有標記,這在計算上仍比執行 2,000 個順序生成步驟來產生 2,000 個標記的回答更高效。
3.2 去噪過程
擴散 LLM 中的去噪過程與常規圖像擴散模型中的去噪過程類似,如下方的 GIF 所示。(關鍵區別在於,文本擴散不是向像素添加高斯噪聲,而是通過概率性地遮蓋標記來損壞序列。)
在這個實驗中,我運行了今年早些時候發佈的《Large Language Diffusion Models (LLaDA)》論文中的 8B 指令模型。
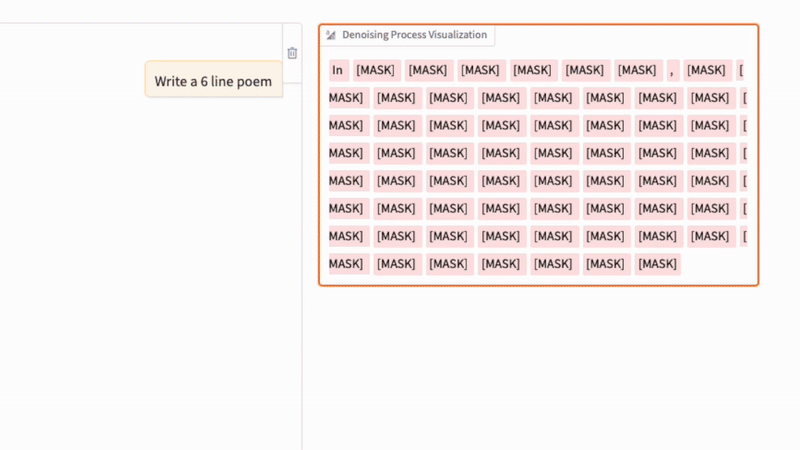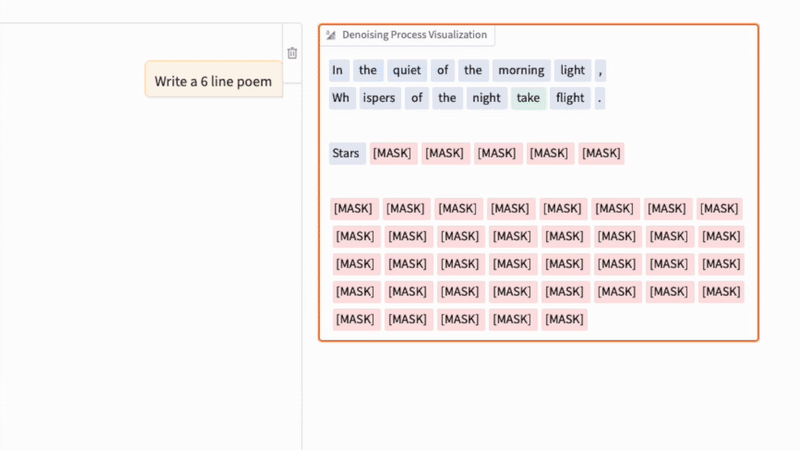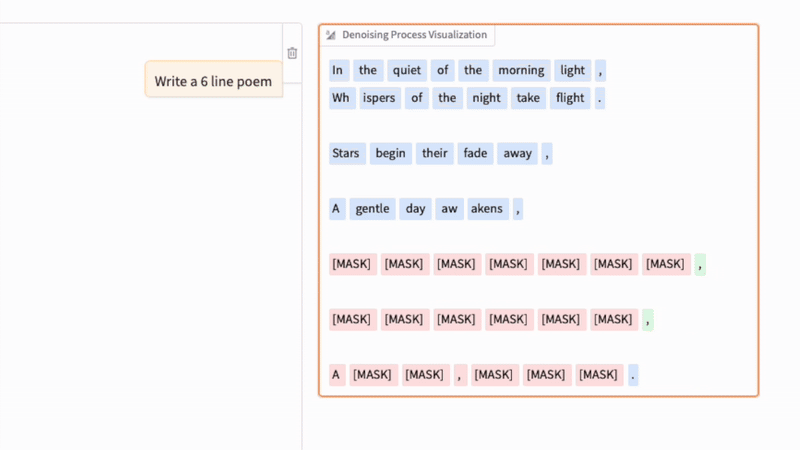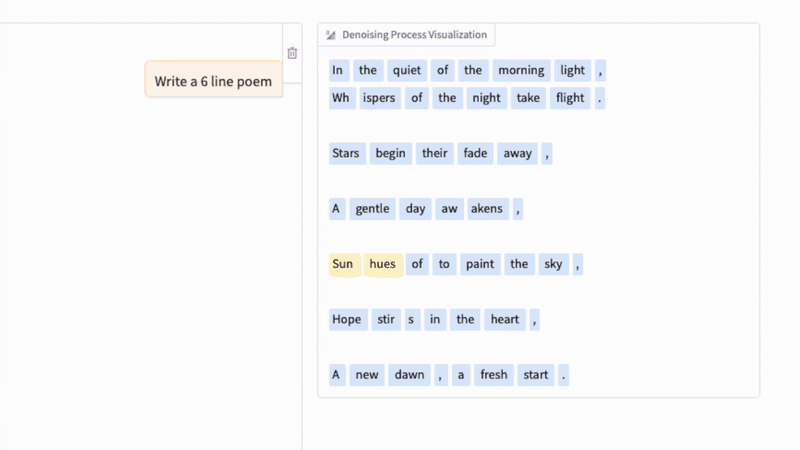
正如我們在上面的動畫中看到的,文本擴散過程相繼用文本標記替換 [MASK] 標記來生成答案。如果你熟悉 BERT 和遮蓋語言建模(masked language modeling),你可以將這種擴散過程視為 BERT 前向傳播的迭代應用(其中 BERT 使用不同的遮蓋率)。
在架構上,擴散 LLM 通常是解碼器風格的 Transformer,但沒有因果注意力掩碼(causal attention mask)。例如,上述 LLaDA 模型使用了 Llama 3 架構。我們稱這些沒有因果掩碼的架構為「雙向」(bidirectional),因為它們可以同時訪問所有序列元素。(請注意,這與 BERT 架構相似,後者因歷史原因被稱為「編碼器風格」。)
因此,自回歸 LLM 和擴散 LLM 之間的主要區別(除了移除因果掩碼外)在於訓練目標。像 LLaDA 這樣的擴散 LLM 使用生成式擴散目標,而不是下一個標記預測目標。
在圖像模型中,生成式擴散目標很直觀,因為我們擁有連續的像素空間。例如,添加高斯噪聲並學習去噪是數學上自然的運算。然而,文本由離散的標記組成,因此我們無法在相同的連續意義上直接添加或移除「噪聲」。
因此,這些擴散 LLM 不是擾動像素強度,而是通過隨機逐步遮蓋標記來損壞文本,其中每個標記以指定的概率被特殊的掩碼標記替換。模型隨後學習一個逆過程,在每一步預測缺失的標記,這有效地將序列「去噪」(或取消遮蓋)回原始文本,如前文圖 15 的動畫所示。
解釋其背後的數學原理更適合單獨的教程,但粗略地說,我們可以將其視為擴展到概率最大似然框架中的 BERT。
3.3 自回歸 vs 擴散 LLM
早些時候我說過,擴散 LLM 的吸引力在於它們並行生成(或去噪)標記,而不是像常規自回歸 LLM 那樣順序生成。這具有使擴散模型比自回歸 LLM 更高效的潛力。
話雖如此,傳統 LLM 的自回歸特性也是其關鍵優勢之一。純並行解碼的問題可以用最近《ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs》論文中的一個極佳例子來說明。
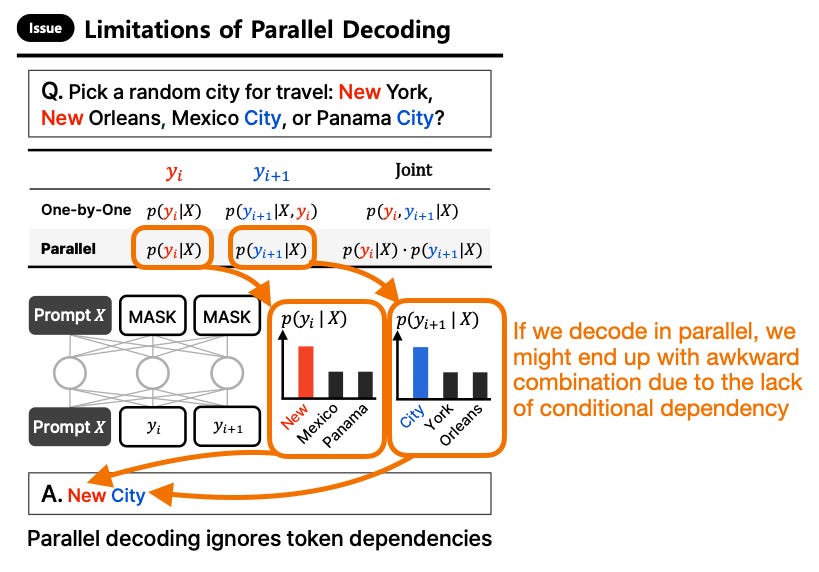
例如,考慮以下提示詞:
「選一個隨機城市旅遊:紐約 (New York)、新奧爾良 (New Orleans)、墨西哥城 (Mexico City) 或巴拿馬城 (Panama City)?」
假設我們要求 LLM 生成一個雙標記答案。它可能會首先根據條件概率 p(yt = ”New” | X) 採樣標記「New」。
在下一次迭代中,它會根據先前生成的標記進行調節,並很可能選擇「York」或「Orleans」,因為這兩個條件概率
p(yt+1 = ”York” | X, yt = ”New”) 和 p(yt+1 = ”Orleans” | X, yt = ”New”)
都相對較高(因為「New」在訓練集中經常與這些後續詞共同出現)。但如果這兩個標記是並行採樣的,模型可能會獨立地
選擇兩個最高概率的標記 p(yt = “New” | X) 和 p(y{t+1} = “City” | X),導致產生像「New City」這樣尷尬的輸出。(這是因為模型缺乏自回歸調節,未能捕捉標記間的依賴關係。)
無論如何,上述簡化說法聽起來好像擴散 LLM 完全沒有條件依賴。這並非事實。如前所述,擴散 LLM 並行預測所有標記,但預測是通過迭代細化(去噪)步驟共同依賴的。
在這裡,每個擴散步驟都以當前整個含噪文本為條件。標記在每一步中通過交叉注意力和自注意力相互影響。因此,儘管所有位置同時更新,但更新是通過共享的注意力層相互調節的。
然而,如前所述,理論上,生成 2000 個標記的答案時,20-60 個擴散步驟可能比自回歸 LLM 的 2000 個推理步驟更便宜。
3.4 今日文本擴散
這是一個有趣的趨勢:視覺模型採用了 LLM 的組件,如注意力和 Transformer 架構本身,而基於文本的 LLM 則從純視覺模型中汲取靈感,實現文本擴散。
就個人而言,除了嘗試過一些演示外,我還沒有使用過很多擴散模型,但我認為這是一種權衡。如果我們使用較少的擴散步驟,生成答案的速度會更快,但可能會產生質量下降的答案。如果我們增加擴散步驟以生成更好的答案,最終模型的成本可能與自回歸模型相似。
引用《ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs》論文作者的話:
[...] 我們系統地分析了 [擴散 LLM] 和自回歸 LLM,揭示了:(i) 並行解碼下的 [擴散 LLM] 在現實場景中可能會遭受嚴重的質量下降,以及 (ii) 當前的並行解碼策略難以根據任務難度調整其並行度,因此無法在不損害質量的情況下實現有意義的加速。
此外,我看到的另一個特別缺點是,擴散 LLM 無法將工具作為其鏈條的一部分使用,因為根本沒有「鏈條」。也許可以在擴散步驟之間進行交錯,但我假設這並不簡單。(如果我錯了,請糾正我。)
簡而言之,擴散 LLM 似乎是一個值得探索的有趣方向,但目前它們可能還無法取代自回歸 LLM。不過,我可以預見它們會成為小型、設備端 LLM 的有趣替代方案,或者取代較小的蒸餾自回歸 LLM。
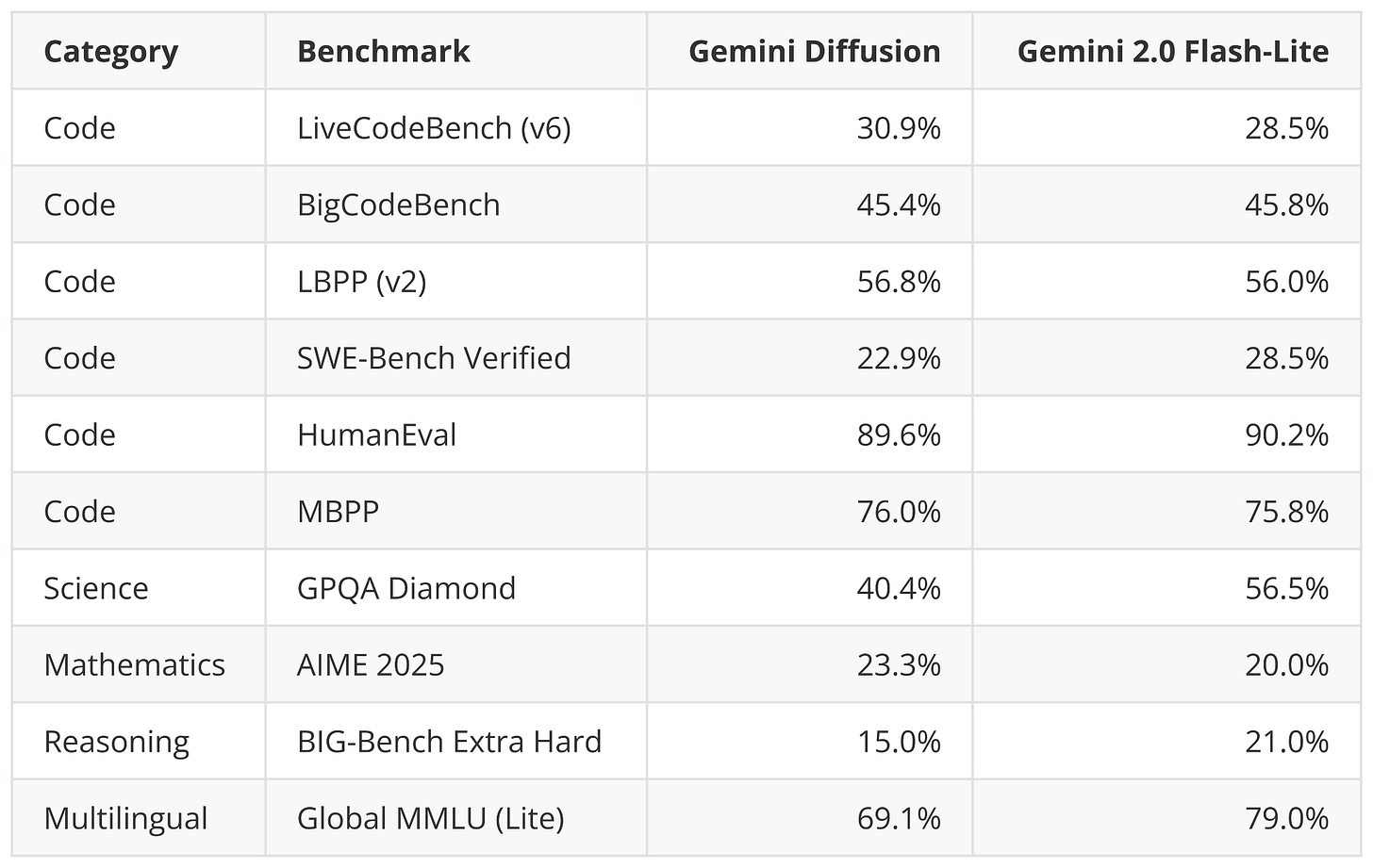
例如,Google 宣佈正在開發用於文本的 Gemini Diffusion 模型,他們表示:
快速響應:生成內容的速度顯著快於我們迄今為止最快的模型。
在保持更快的同時,其基準測試性能似乎與其快速的 Gemini 2.0 Flash-Lite 模型持平。一旦該模型發佈並讓用戶在不同任務和領域進行嘗試,看看其採用情況和反饋將會非常有趣。
4. 世界模型 (World Models)
到目前為止,我們討論的方法都集中在提高效率、使模型更快或更具擴展性。而這些方法通常會以略微降低建模性能為代價。
現在,本節的主題採取了不同的角度,專注於提高建模性能(而非效率)。這種性能提升是通過教導模型「對世界的理解」來實現的。
世界模型傳統上是獨立於語言建模開發的,但 2025 年 9 月的《Code World Models》論文首次使其在這一背景下產生了直接關聯。
理想情況下,與本文的其他主題一樣,世界模型本身也值得寫一篇專門的文章(或書)。然而,在討論 Code World Models (CWM) 論文之前,讓我至少對世界模型做一個簡短的介紹。
4.1 世界模型背後的核心思想
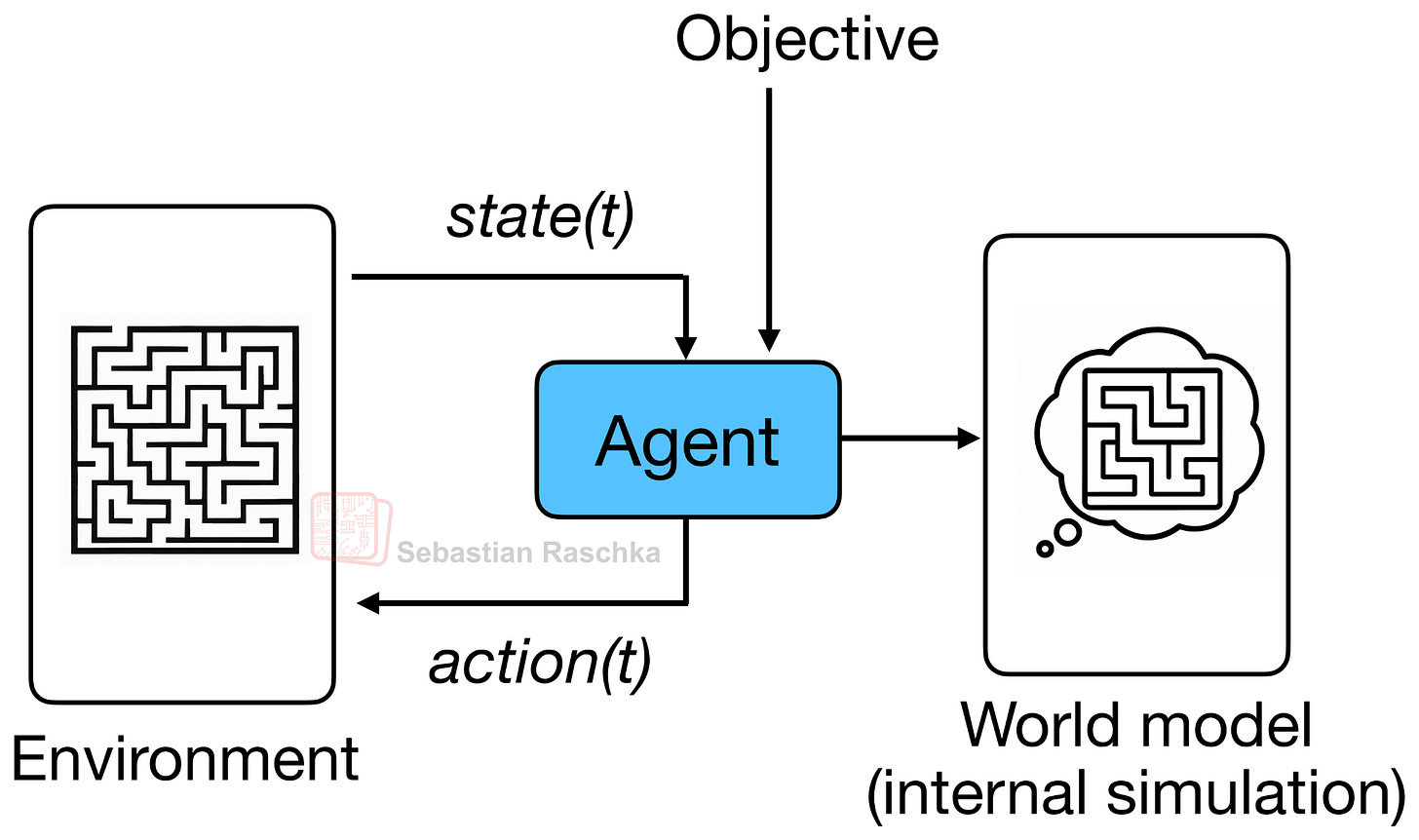
最初,世界模型背後的想法是隱式地建模結果,即在結果實際發生之前預測可能發生的事情(如下圖所示)。這類似於人類大腦根據先前的經驗不斷預測即將發生的事件。例如,當我們伸手去拿一杯咖啡或茶時,我們的大腦已經預測了它會有多重,我們在觸摸或拿起杯子之前就已經調整了握力。
據我所知,「世界模型」一詞是由 Ha 和 Schmidhuber 在 2018 年的同名論文《World Models》中普及的,該論文使用 VAE 加 RNN 架構為強化學習智能體學習內部環境模擬器。(但該術語或概念本身本質上只是指建模世界或環境的概念,因此可以追溯到 1980 年代的強化學習和機器人研究。)
老實說,直到 Yann LeCun 2022 年的文章《A Path Towards Autonomous Machine Intelligence》,我才注意到世界模型的新解釋。那篇文章本質上是繪製了一條通往 AI 的替代路徑,而不是 LLM。
4.2 從視覺到代碼
話雖如此,世界模型論文此前都集中在視覺領域,涵蓋了廣泛的架構:從早期的基於 VAE 和 RNN 的模型到 Transformer、擴散模型,甚至是 Mamba 層混合模型。
現在,作為一個目前更關注 LLM 的人,《Code World Model》論文(2025 年 9 月 30 日)是第一篇完全吸引我注意力(無意雙關)的論文。這是第一個(據我所知)從文本映射到文本(或者更準確地說,從代碼映射到代碼)的世界模型。
CWM 是一個 320 億參數的開源模型,擁有 131k 標記的上下文窗口。在架構上,它仍然是一個帶有滑動窗口注意力的稠密解碼器 Transformer。此外,與其他 LLM 一樣,它經歷了預訓練、中訓練(mid-training)、監督微調 (SFT) 和強化學習階段,但中訓練數據引入了世界建模組件。
4.3 代碼世界模型 vs 常規代碼 LLM
那麼,這與 Qwen3-Coder 等常規代碼 LLM 有何不同?
像 Qwen3-Coder 這樣的常規模型純粹通過下一個標記預測進行訓練。它們學習語法和邏輯模式以產生合理的代碼補全,這賦予了它們對編程的靜態文本級理解。
相比之下,CWM 學習模擬代碼運行時會發生什麼。它被訓練來預測執行操作(如修改一行代碼)後的程序狀態,例如變量的值,如下圖所示。
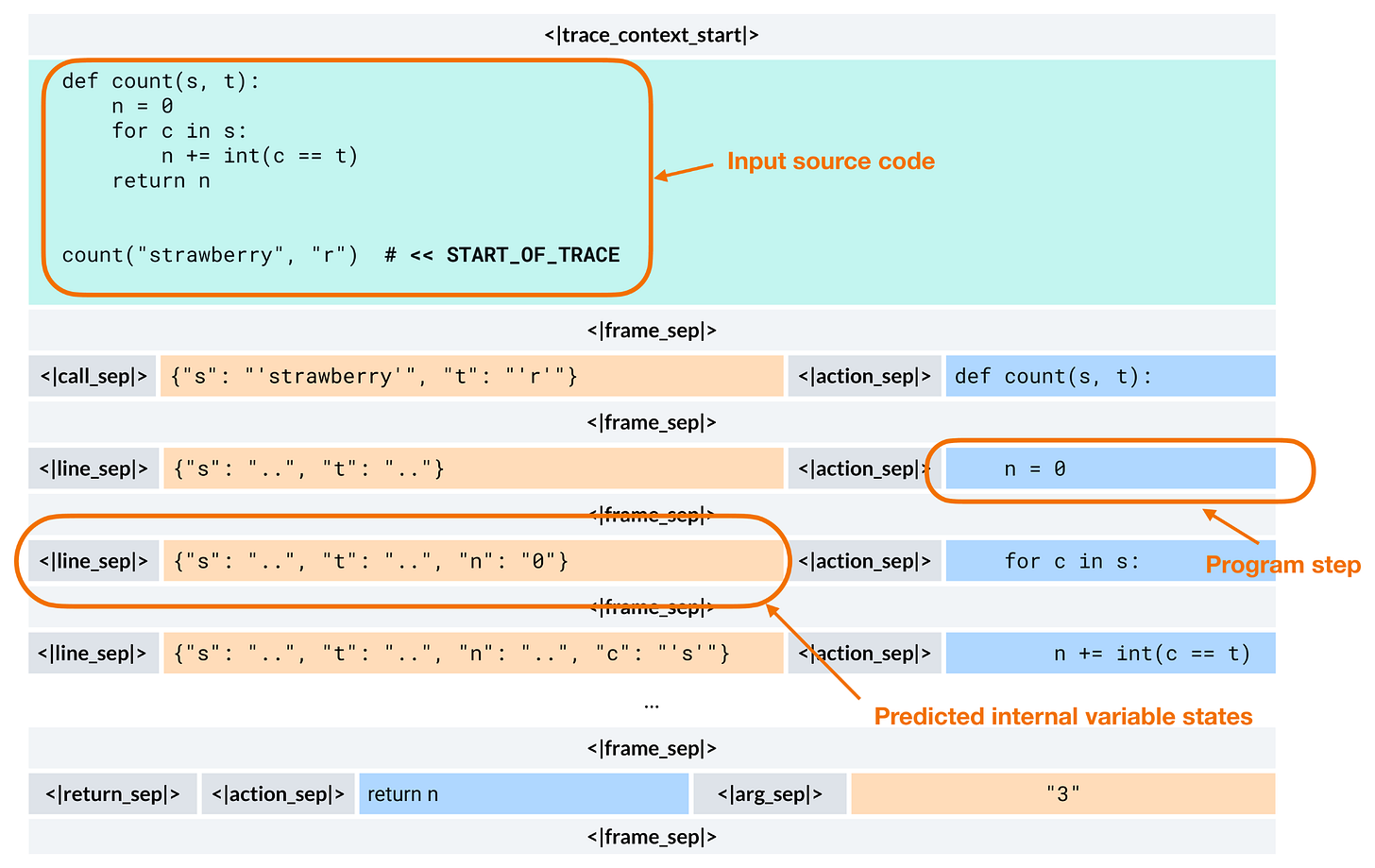
在推理時,CWM 仍然是一個一次生成一個標記的自回歸 Transformer,就像 GPT 風格的模型一樣。關鍵區別在於,這些標記可以編碼結構化的執行軌跡,而不僅僅是純文本。
所以,我或許不會稱其為世界模型,而是一個「世界模型增強型 LLM」。
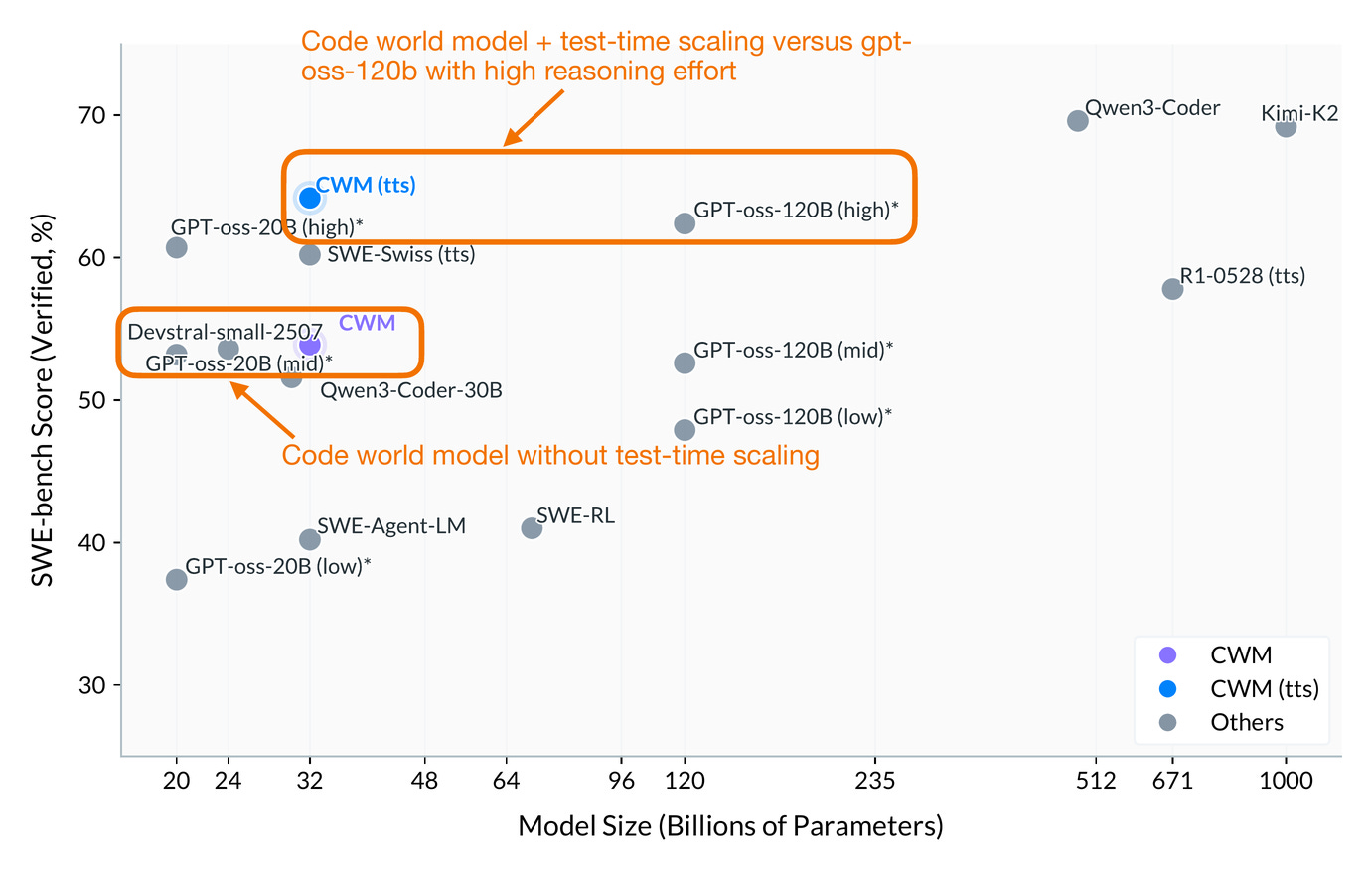
作為第一次嘗試,它的表現出奇地好,在規模大致相同的情況下,與 gpt-oss-20b(中等推理強度)不相上下。
如果使用測試時縮放(test-time-scaling),它的表現甚至略優於 gpt-oss-120b(高推理強度),而體積卻小了 4 倍。
請注意,他們的測試時縮放使用了帶有生成單元測試的 best@k 程序(可以想像成一種高級的多數投票方案)。如果能看到 CWM 和 gpt-oss 之間的 tokens/sec 或解決問題時間的對比將會很有趣,因為它們使用了不同的測試時縮放策略(best@k vs 每個推理強度更多標記)。
5. 小型遞歸 Transformer (Small Recursive Transformers)
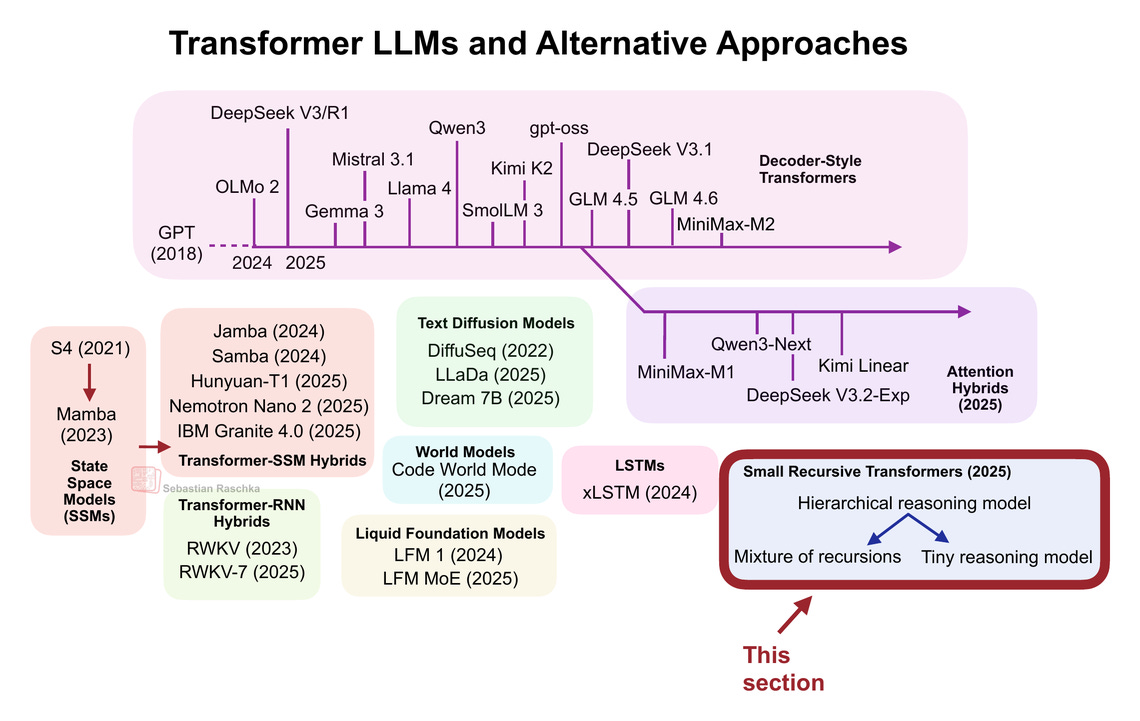
你可能已經注意到,之前的所有方法仍然建立在 Transformer 架構之上。最後一節的主題也是如此,但與我們之前討論的模型相比,這些是專為推理設計的小型、專用 Transformer。
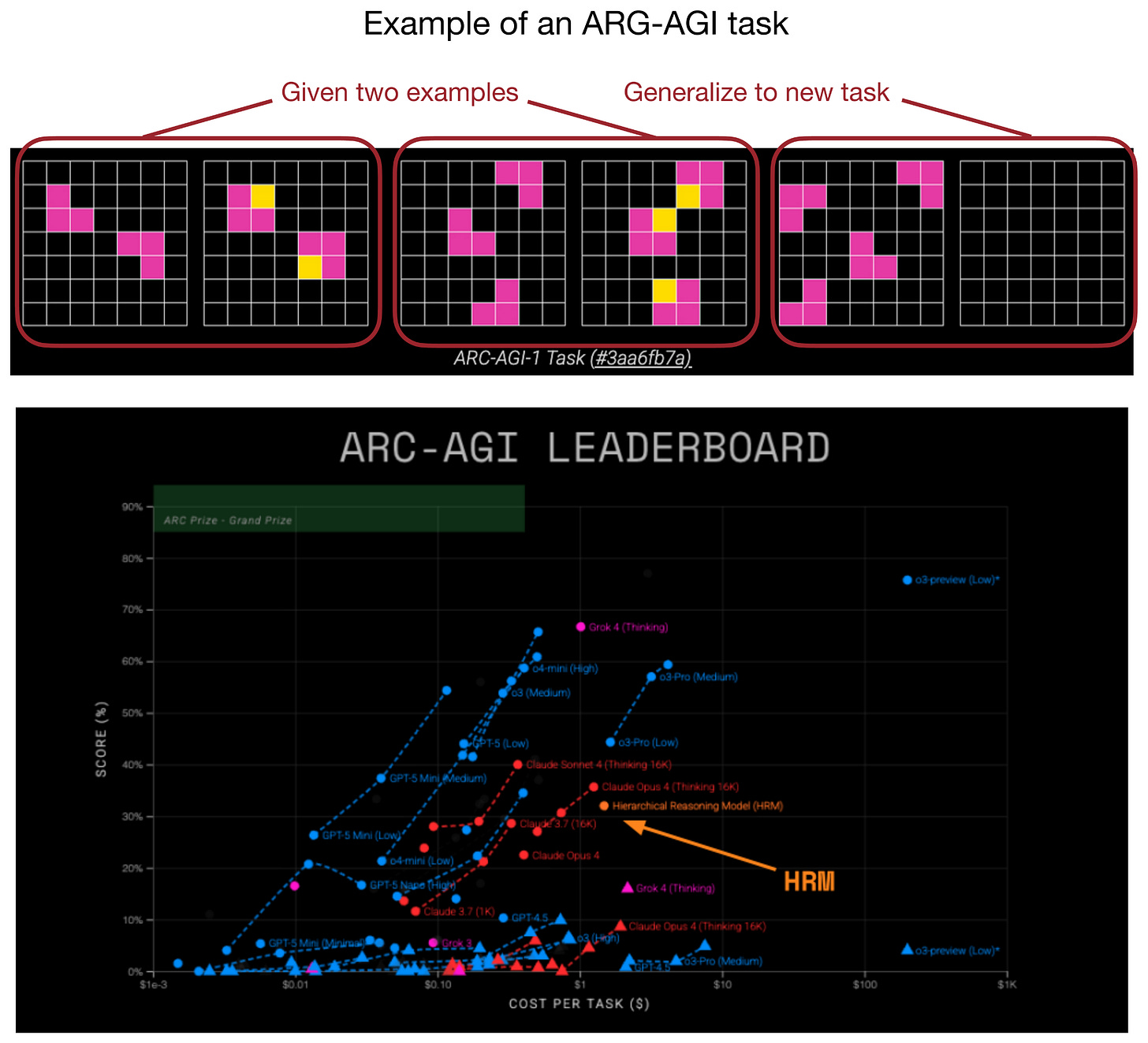
是的,專注於推理的架構並不總是需要很大。事實上,隨著層次推理模型 (HRM) 的出現,一種小型遞歸 Transformer 的新方法最近在研究界引起了廣泛關注。
更具體地說,HRM 開發者展示了即使是非常小的 Transformer 模型(僅有 4 個區塊),在被訓練為逐步細化答案時,也能展現出令人印象深刻的推理能力(針對專門問題)。這使其在 ARC 挑戰賽中名列前茅。
像 HRM 這樣的遞歸模型背後的想法是,模型不是在一次前向傳播中產生答案,而是以遞歸方式反覆細化自己的輸出。(作為此過程的一部分,每次迭代都會細化一個潛在表示,作者將其視為模型的「思考」或「推理」過程。)
第一個主要例子是今年夏初的 HRM,隨後是《Mixture-of-Recursions (MoR)》論文。
而最近,《Less is More: Recursive Reasoning with Tiny Networks》(2025 年 10 月)提出了微型遞歸模型 (TRM,如下圖所示),這是一個更簡單且更小的模型(700 萬參數,比 HRM 小約 4 倍),在 ARC 基準測試中表現更好。
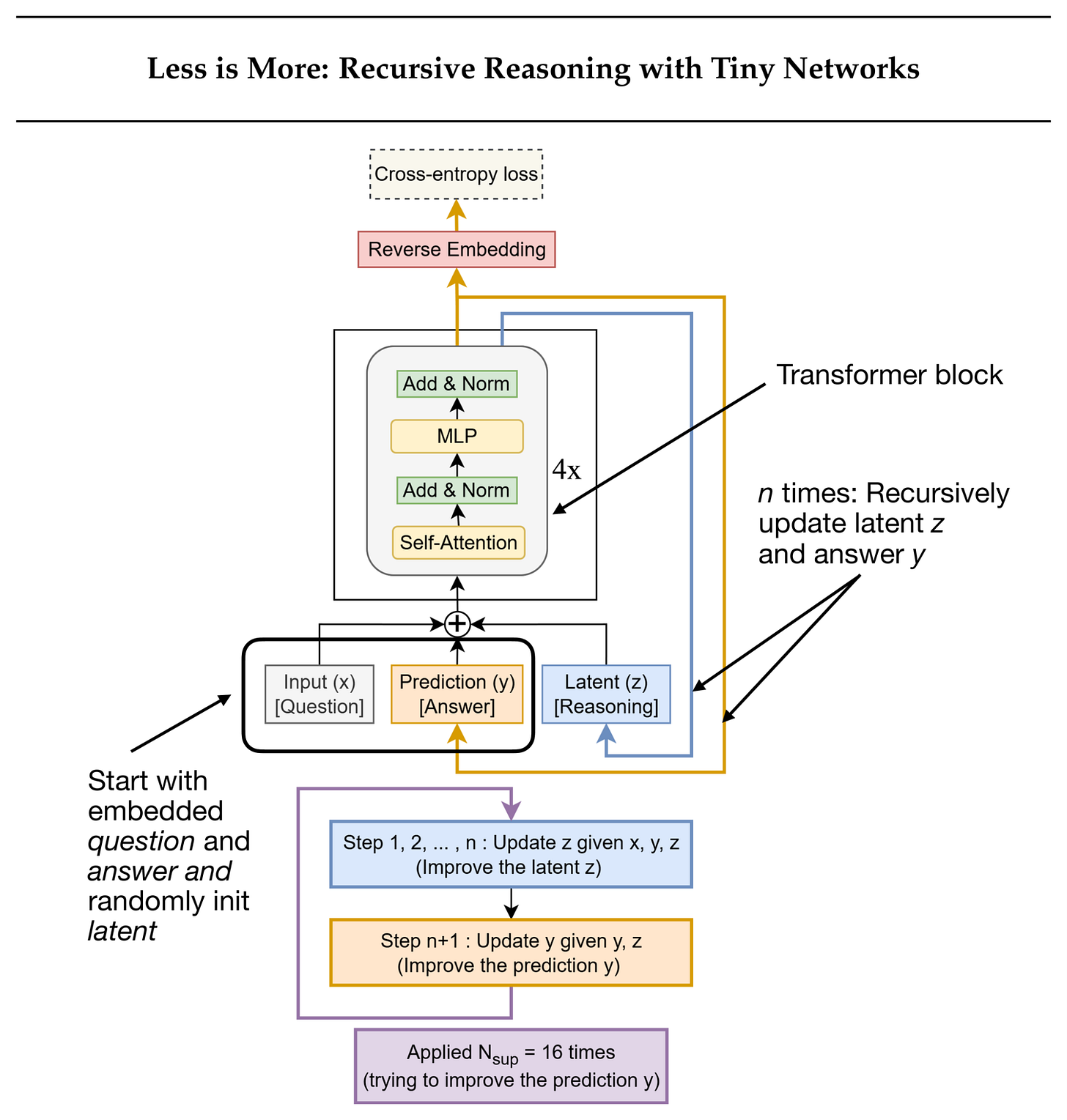
在本節剩餘部分,讓我們更詳細地了解一下 TRM。
5.1 這裡的「遞歸」是什麼意思?
TRM 通過兩個交替的更新來細化其答案:
- 它從當前問題和答案中計算出一個潛在推理狀態。
- 然後它根據該潛在狀態更新答案。
訓練時每個批次運行多達 16 個細化步驟。每一步執行多個無梯度(no-grad)循環來迭代細化答案。隨後是一個梯度循環,通過完整的推理序列進行反向傳播以更新模型權重。
重要的是要注意,TRM 不是一個處理文本的語言模型。然而,因為 (a) 它是基於 Transformer 的架構,(b) 推理現在是 LLM 研究的核心焦點,而該模型代表了一種截然不同的推理方式,以及 (c) 許多讀者要求我報導 HRM(而 TRM 是其更先進的繼任者),所以我決定將其包含在此。
雖然 TRM 未來可以擴展到文本問答任務,但 TRM 目前處理的是基於網格的輸入和輸出。換句話說,「問題」和「答案」都是離散標記的網格(例如 9×9 數獨或 30×30 ARC/迷宮謎題),而不是文本序列。
5.2 TRM 與 HRM 有何不同?
- HRM 由兩個小型 Transformer 模塊(每個 4 區塊)組成,它們跨遞歸層級進行通信。TRM 僅使用單個 2 層 Transformer。(請注意,之前的 TRM 圖中顯示了 Transformer 區塊旁的 4×,但這可能是為了更容易與 HRM 進行比較。)
- TRM 通過所有遞歸步驟進行反向傳播,而 HRM 僅通過最後幾步進行反向傳播。
- HRM 包含一個顯式的停止機制來確定何時停止迭代。TRM 將此機制替換為一個簡單的二元交叉熵損失,以此學習何時停止迭代。
在性能方面,TRM 與 HRM 相比表現非常出色,如下圖所示。
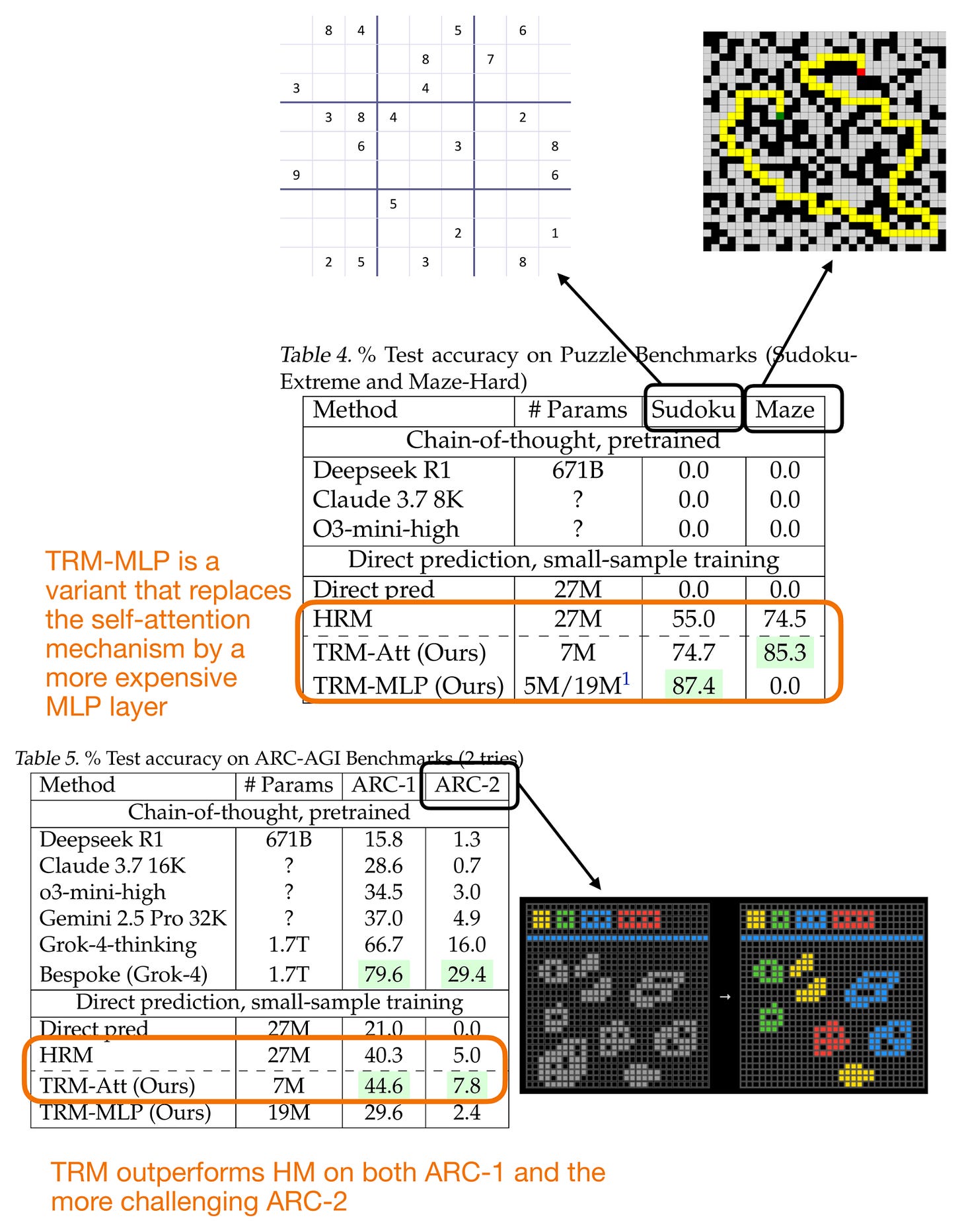
圖 24:層次推理模型 (HRM) 與微型遞歸模型 (TRM) 的性能比較。
該論文包含了驚人數量的消融研究,產生了一些有趣的額外見解。以下是兩個令我印象深刻的發現:
- 更少的層數帶來更好的泛化能力。將層數從 4 層減少到 2 層,使數獨準確性從 79.5% 提高到 87.4%。
- 注意力機制並非必需。將自注意力替換為純 MLP 層也提高了準確性(從 74.7% 提高到 87.4%)。但這僅在此處可行,因為上下文很小且長度固定。
5.3 更宏觀的視角
雖然 HRM 和 TRM 在這些基準測試中取得了非常好的推理性能,但將它們與大型 LLM 進行比較並不完全公平。HRM 和 TRM 是針對 ARC、數獨和迷宮尋路等任務的專用模型,而 LLM 是通用模型。當然,HRM 和 TRM 也可以應用於其他任務,但必須針對每個任務進行專門訓練。所以,從這個意義上說,我們或許可以將 HRM 和 TRM 視為高效的口袋計算機,而 LLM 更像是一台電腦,可以做很多其他事情。
儘管如此,這些遞歸架構是令人興奮的概念驗證,突顯了小型、高效的模型如何通過迭代自我細化來進行「推理」。或許在未來,此類模型可以作為推理或規劃模塊嵌入到更大的具備工具調用能力的 LLM 系統中。
目前,LLM 仍然是處理廣泛任務的理想選擇,但一旦目標領域被充分理解,就可以開發像 TRM 這樣的特定領域遞歸模型來更高效地解決某些問題。除了數獨、迷宮尋路和 ARC 概念驗證基準測試外,物理和生物領域可能還有大量此類模型可以發揮作用的用例。
一個有趣的小細節是,作者分享說訓練這個模型花費不到 500 美元,使用 4 張 H100 運行了大約 2 天。我很高興看到在沒有數據中心的情況下仍然可以做出有趣的工作。
6. 結論
我原本計劃涵蓋總覽圖中的所有模型類別,但由於文章篇幅超出了預期,我不得不將 xLSTM、Liquid Foundation Models、Transformer-RNN 混合模型和狀態空間模型留到下次(儘管 Gated DeltaNet 已經讓我們領略了狀態空間模型和循環設計的風采)。
作為本文的總結,我想重複之前的觀點,即標準自回歸 Transformer LLM 已經過驗證且經受住了時間的考驗。如果效率不是主要考慮因素,它們也是我們目前擁有的最佳選擇。
傳統解碼器風格、自回歸 Transformer
- 經過驗證且工具鏈成熟
- 「易於理解」
- 遵循縮放定律 (Scaling laws)
- 處於頂尖水平 (SOTA)
- 訓練昂貴
- 推理昂貴(除非使用前述技巧)
如果我今天要啟動一個新的基於 LLM 的項目,基於 Transformer 的自回歸 LLM 將是我的首選。
我絕對認為即將到來的注意力混合模型非常有前景,特別是在處理長上下文且效率是主要考量時。
線性注意力混合模型
- 與解碼器風格 Transformer 相同
- 在長上下文任務中減少 FLOPs/KV 內存
- 增加了複雜性
- 以少量準確性換取效率
在更極端的一端,文本擴散模型是一個有趣的發展。我對它們在日常使用中的表現仍持保留態度,因為我只嘗試過一些快速演示。希望我們很快能看到 Google 的 Gemini Diffusion 進行大規模生產部署,以便我們在日常和編碼任務中進行測試,進而了解人們的真實感受。
文本擴散模型
- 迭代去噪是文本生成的新穎想法
- 更好的並行性(無下一個標記依賴)
- 無法流式傳輸答案
- 無法從思維鏈 (CoT) 中獲益?
- 工具調用較棘手?
- 模型穩健但非頂尖水平
雖然文本擴散模型的主要賣點是提高效率,但代碼世界模型則位於光譜的另一端,旨在提高建模性能。截至本文撰寫時,基於標準 LLM 的編碼模型主要通過推理技術進行改進,但如果你在更棘手的挑戰中嘗試過它們,你可能已經注意到它們(或多或少)仍然力有不逮,無法很好地解決許多更複雜的編碼問題。
我發現代碼世界模型特別有趣,並相信它們可能是開發更強大編碼系統的重要下一步。
代碼世界模型
- 提升代碼理解的有前景方法
- 可驗證的中間狀態
- 包含可執行代碼軌跡使訓練複雜化
- 運行代碼會增加延遲
最後,我們介紹了小型遞歸 Transformer,如層次化和微型推理模型。這些是非常有趣的原理驗證模型。然而,截至今日,它們主要是謎題求解器,而非通用文本或編碼模型。因此,它們與本文涵蓋的其他非標準 LLM 替代方案不屬於同一類別。儘管如此,它們是非常有趣的原理驗證,我很高興研究人員正在致力於此。
目前,像 GPT-5、DeepSeek R1、Kimi K2 等 LLM 被開發為處理自由格式文本、代碼、數學問題等的通用模型。它們感覺像是我們用於各種任務(從常識問題到數學和代碼)的「暴力破解」和「萬金油」方法。
然而,當我們重複執行相同的任務時,這種暴力方法會變得效率低下,甚至在專業化方面可能並不理想。這就是微型遞歸 Transformer 變得有趣的地方:它們可以作為輕量級、特定任務的模型,既高效又是為重複或結構化推理任務量身定制的。
此外,我可以預見它們成為其他具備工具調用能力的 LLM 的潛在「工具」;例如,當 LLM 使用 Python 或計算器 API 來解決數學問題時,特殊的微型推理模型可以填補其他類型謎題或推理類問題的空白。
小型遞歸 Transformer
- 極小的架構
- 在謎題上具有良好的泛化能力
- 專用模型
- 目前僅限於謎題
這是一篇長文章,但我希望你發現了一些經常處於主流 LLM 聚光燈之外的迷人方法。
如果你對或多或少常規的 LLM 發佈感到有些乏味,我希望這能幫助你重新燃起對 AI 的興奮,因為現在有很多有趣的工作正在發生!
本雜誌是一個個人的熱情項目,您的支持有助於維持它的運作。
如果您想支持我的工作,請考慮購買我的《從零開始構建大語言模型》(Build a Large Language Model (From Scratch)) 一書或其後續作品《從零開始構建推理模型》(Build a Reasoning Model (From Scratch))。(我相信您會從中獲益良多;它們深入解釋了 LLM 的運作原理,這是您在其他地方找不到的。)
感謝閱讀,並感謝支持獨立研究!
如果您閱讀了本書並有幾分鐘空閒時間,我將非常感激您的簡短評論。這對我們作者幫助很大!
您的支持意義重大!謝謝!
相關文章