AI #152:由「折磨連結」帶來
這份報告涵蓋了 AI 的重大進展,包括 Anthropic 發布的新憲法、OpenAI 計劃在 ChatGPT 中加入廣告,以及關於 AI 安全、監管與實際用途的持續辯論。
Anthropic 為 Claude 發布了新憲法。我鼓勵有興趣的人閱讀這份文件的全部或部分內容。我打算近期專門對此進行報導。
DeepMind 執行長 Demis Hassabis 也確實談到了協調有條件的暫停或放緩開發,我也計劃稍後報導。
Claude Code 仍然是全城熱議的話題,每週報告請點此。
OpenAI 的回應是計劃在 ChatGPT 的廉價版和免費版中加入廣告。
還有一個有趣但意義重大的事件,涉及 ChatGPT 的自畫像。
目錄
-
語言模型提供平凡的效用。 呼叫語氣警察。
-
語言模型不提供平凡的效用。 那些依賴模式生存的人。
-
嘿,升級了。 Claude 健康數據整合、ChatGPT 每月 8 美元的選項。
-
Gemini 個性化智能。 兩者的跡象仍然有些匱乏。
-
深偽鎮與機器人啟示錄即將到來。 抓住那個浴缸維京人。
-
媒體生成的樂趣。 吉卜力工作室風格的照片回來了,寶貝。
-
我們自豪地宣布「折磨樞紐」。廣告來到 ChatGPT。
-
他們搶了我們的運作。 找個應對方案。別指望「道德抵觸」。
-
期望上升的革命。 看看你獲得的所有價值。
-
參與其中。 AI Village、Anthropic、Dwarkesh Patel 徵求嘉賓獵頭。
-
年輕女士的插圖入門書。 我們組建了錯誤的團隊。
-
其他 AI 新聞。 中國仍然落後,Drexler 進入「銀河大腦」模式。
-
輔助軸心。你試過不當一個樂於助人的 AI 助手嗎?
-
向我展示金錢。 OpenAI 尋求再融資 500 億美元。
-
危機中的加州。 我們很快會問,新創公司都去哪了?
-
泡沫,泡沫,勞苦與麻煩。 他們一直使用那個詞。
-
冷靜的推測。 AI 2025 預測調查結果。
-
Elon Musk 對決 OpenAI。 他們又來了。
-
尋求理性的監管。Nvidia 對決《AI 監督法案》。
-
晶片之城。 我們是否即將給予中國目前算力的十倍?
-
本週音訊。 Tyler Cowen 以及出人意料地見多識廣的 Ben Affleck。
-
修辭創新。 記住預期證據守恆定律。
-
對齊比人類更聰明的智能是很困難的。 沒錯,依然困難。
-
對齊主要不是關於指標。 不是一個用來優化的指標。
-
如何成為一個安全的機器人。 提示:計劃不是「別告訴它關於不安全機器人的事」。
-
生活在中國。 中國的大語言模型知道某些事卻假裝不知道。利用這一點。
-
Claude 3 Opus 依然存在。 獲得訪問權限。
-
人們擔心 AI 會殺死所有人。 查爾斯·達爾文。
-
來自 Janus 世界的消息。 你擔心人們會拿你的資訊做什麼?
-
每個人都對 AI 意識感到困惑。 別稱之為反證。
語言模型提供平凡的效用
語氣編輯或語氣警察是一份很棒的 AI 工作。將你不禮貌的「去你的」電子郵件變成禮貌的「去你的」電子郵件,並練習從其他潛在的緊張互動中剝離你的情緒,以免你的真實個性成為阻礙。或者將你神經多樣性的真實資訊轉化為社交上可接受的贅詞。
ICE 使用 Palantir 一個名為「Elite」的 AI 程式來挑選突襲的社區。
語言模型不提供平凡的效用
如果你的查詢被激進地模式匹配到一個事實並不重要的領域,並且你在沒有太多證明的情況下做出廣泛的斷言,AI 基本上會針對模式匹配做出回應,就像 Claude 在連結範例中所做的那樣。如果你因此威脅這些 AI,而它們退縮並說出你想聽的話,你可以將其解讀為「AI 在對我撒謊,這糟糕的 AI 肯定有責任」,或者你可以思考為什麼它決定這麼做。
嘿,升級了
Claude 在測試版中新增了四項健康數據整合:Apple Health (iOS)、Health Connect (Android)、HealthEx 和 Function Health。它們在設計上是私密的。
OpenAI 更廣泛地推出了 ChatGPT Go 選項,每月 8 美元。如果你頻繁使用 ChatGPT 或將其作為主要工具,你需要至少支付每月 20 美元的 Plus 費用,以避免大部分時間被困在 Instant 模型中。
Sam Altman 發起了最新的「你希望看到我們改進什麼?」討論串。
還記得 ChatGPT 的 Atlus 瀏覽器嗎?它終於有了分頁組,一個讓搜尋在 ChatGPT 和 Google 之間選擇的「自動」選項,以及其他各種完善。目前仍然沒有 Windows 版本,而 Claude Code 現在是我的 AI 瀏覽器。
Gemini 個性化智能
宣傳點在於 Gemini 現在可以從你的 Google 應用程式中提取洞察,以提供自定義回應。還有一個針對非 Google 應用程式的部分,儘管目前除了 GitHub 之外還沒有太多內容。
Josh Woodward:介紹「個性化智能」。這是我們對首要請求的回應:你現在可以透過點擊一下連接你的 Google 應用程式來個性化 @GeminiApp。作為 Pro/Ultra 會員在美國的測試版發布,這標誌著我們朝著讓 Gemini 更加個性化、主動和強大邁出的下一步。快來看看吧!
Google:Gemini 已經會記住你過去的對話以提供相關回應。但今天,隨著「個性化智能」的推出,我們正邁出下一步。
你可以選擇讓 Gemini 連接來自你的 Gmail、Google 相簿、Google 搜尋和 YouTube 歷史記錄的資訊,以接收更個性化的回應。
以下是一些你可以開始使用的方法:
• 規劃:Gemini 將能夠為即將到來的旅行或出差建議非常適合你的隱藏景點。
• 購物:Gemini 將更深入地了解你的品味和偏好,並幫助你更快找到喜愛的商品。
• 動力:Gemini 將對你正在努力實現的目標有更深入的理解。例如,它可能會注意到你即將參加馬拉松並提供訓練計劃。
隱私是個性化智能以及你如何將其他 Google 應用程式連接到 Gemini 的核心。這項新的測試功能預設是關閉的:你選擇開啟它,決定具體連接哪些應用程式,並可以隨時關閉它。
宣傳點在於它可以從你的照片(細化到你旅行的地點、你的車需要什麼樣的輪胎)、電子郵件、Google 搜尋、YouTube、文件、試算表和日曆中收集資訊,並了解關於你的各種事情,不僅是特定細節,還有你的知識水平和偏好。然後它可以據此自定義一切。
它可以訪問 Google 地圖,但除了「公司」和「家」的位置外,無法訪問你的個性化數據(如儲存的地點)。它沒有你的位置歷史記錄。這感覺是一個重要的錯失機會。
一個潛在的「殺手級應用」是尋找事實。如果你想了解關於你自己和生活的事情,而 Google 知道,希望 Gemini 現在能告訴你。Google 知道相當多的事情,我的 Obsidian 筆記庫在 Google 試算表中有備份,你可以指示 Gemini 去查找。Josh Woodward 展示了一個詢問他上次剪頭髮是什麼時候的例子。
真正的殺手級應用將是代表你採取行動。除了日曆之外,它還不能這樣做,但它可以在撰寫電子郵件草稿和在文件中提出修改建議的層面上運作。
如果分析得當,那裡確實有海量的資訊。這可能是一場大戲。
當這些功能運作時,它們「感覺像魔法」。
當它們不運作時,它們感覺非常愚蠢。
我徵求了反應,但基本上沒得到什麼回應。
這很合理。要使用這個,你必須使用 Gemini。誰在用 Gemini?
因此,為了測試個性化智能,我需要一個使用場景,其需求大到讓我願意使用 Gemini,而不是回到 Claude Code 中建立我的技能、連接器和 MCP 大軍(包括 Google 套件)。
Olivia Moore:G Suite 的連接器在 ChatGPT + Claude 中表現尚可——它們速度慢且有時難以找到東西。
如果 Gemini 能提供來自 Gmail、G Drive、日曆的最佳「上下文」——那將是巨大的進步。
激進的版本將是在其他大語言模型中封鎖連接器……但這感覺不太可能!
另一個問題是,Google 與其自身產品的連接器,在我嘗試時,除了基本任務外一直無法運作。即使在那些基本任務中,來自 Claude 或 ChatGPT 的連接器表現也更好。而現在我正將 Claude Code 連接到 API。
深偽鎮與機器人啟示錄即將到來
Elon Musk 和 xAI 繼續淡化整個「Grok 根據需求公開創建了一堆性化深偽影像,且一度可能包含了世界上大部分的 AI 兒童性虐待材料 (CSAM)」事件,彷彿這沒什麼大不了。許多國家和人民並不這麼看,調查仍在繼續,這個問題似乎不會消失。
我們過去非常擔心深偽。然後我們大多停止擔心了,至少直到最近的 xAI 事件為止,但這並不意味著深偽不多。彭博社的一份報告稱,「每八個孩子中就有一個親自認識被深偽影片鎖定的人」,這是一種奇怪的盛行率思考方式,但確實是大幅增加。報告數量從 2023 年的約 4,700 起增加到 2025 年上半年的超過 440,000 起。
如果我們想,我們可以阻止 Grok,但開源工具已經足夠強大,可以生成性化深偽,且只會變得越來越容易獲得。你可以讓獲取變得麻煩並關閉分發,但你無法從生產端關閉它。
與此同時,精神科醫生 Sarah Gundle 發出了最新的警告,這種「互動式色情」除了對被描繪者的傷害外,也會傷害創作者或消費者,因為它透過讓替代方案變得太容易而削弱了人類聯繫的動力,人們(主要是男性)不再有建立情感聯繫的推動力。我對此類警告和擔憂持懷疑態度,它們的形式總是可能證明得太多,且歷史記錄大多不支持這一點,但另一方面,別跟機器人約會。
錯誤資訊是需求驅動的,這是一個持續的系列。
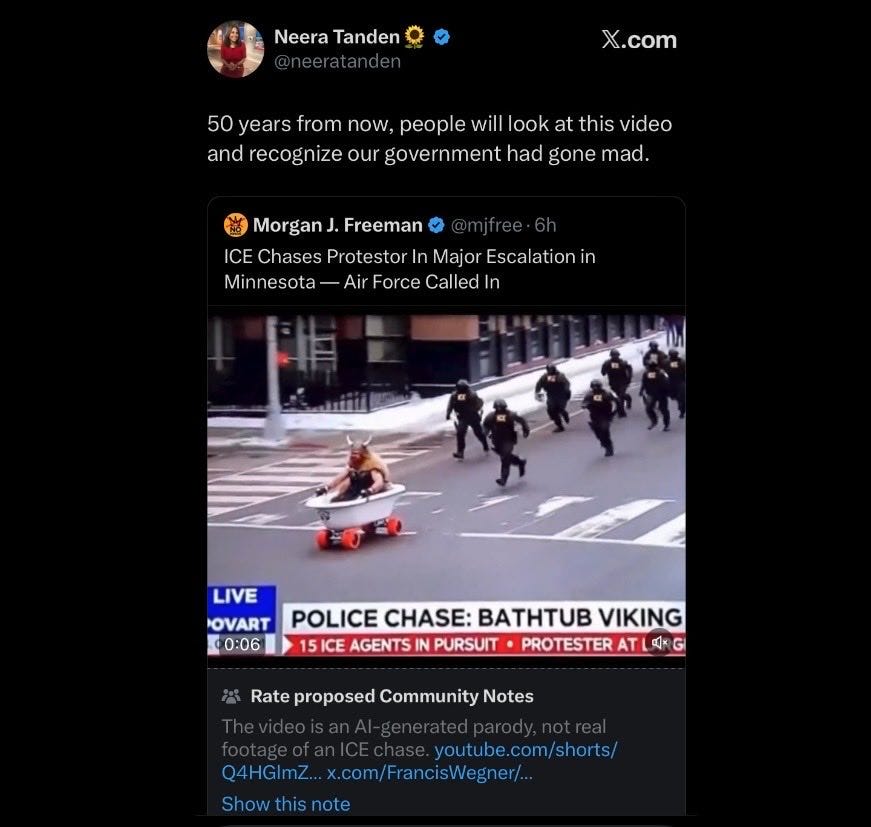
Jerry Dunleavy IV:Neera Tanden 相信 ICE 特工在街上追捕一名穿著維京裝備、坐在裝有滑板輪的浴缸裡的抗議者,並且空軍因此被召集。某些人群就是沒有能力處理明顯的 AI 垃圾。
Amygator *並非真實鱷魚:家族群組裡的 Carol 阿姨不確定這是不是 AI。我受夠了。
這不是一個微妙的案例。影片中的新聞跑馬燈字體字面上就在上下漂浮。在一個理智的世界裡,這會是一個好笑話。唉,各方都有人不在乎這類事情是多麼顯而易見,但這是一個 AI 影片而不是別的東西,其實差別不大。
為 Neera 辯護一下,本週的頭條新聞包括「總統致信歐洲領導人要求格陵蘭島,因為挪威不願授予他諾貝爾和平獎」。這比起警察在新聞中未能追上一個浴缸維京人,而跑馬燈在緩慢跳動,是更瘋狂還是更不瘋狂?
媒體生成的樂趣
OpenAI 的新影像生成功能無法正確處理吉卜力工作室風格,但根據 Roon 的說法,你仍然可以透過這裡使用舊的版本。
Roon:確認這是最新影像模型中的技術退化,政策方面沒有任何改變。
Bryan:這一切最棒的部分是你只需要丟入你的圖片並說「Ghibli」——完美。
非常令人失望的是,他們無法在未來的版本中保留這項能力,但只要我們還有舊的選項,我們就沒問題。影像生成在許多方面已經非常出色,所以通常你關心的是風格。
Sienna Rose 最近有三首歌進入 Spotify 前 50 名,而她是一個 AI,我們在瑞典也有另一個發現。
我們自豪地宣布「折磨樞紐」
這個版本的技術名稱是「ChatGPT 中的廣告」。他們試圖安撫我們,稱他們不會強迫支付足夠費用的客戶進入這個樞紐,而且它畢竟不會對非付費客戶造成太大的折磨。
Sam Altman:我們開始在 ChatGPT 免費版和 Go(新的每月 8 美元選項)層級測試廣告。
以下是我們的原則。最重要的是,我們不會接受金錢來影響 ChatGPT 給你的答案,並且我們會保護你的對話隱私,不讓廣告商獲取。我們很清楚,很多人想使用大量的 AI 卻不想付費,所以我們希望這樣的商業模式能奏效。
(我喜歡的廣告例子是在 Instagram 上,在那裡我發現了原本永遠不會發現的喜愛事物。我們將努力讓廣告對用戶越來越有用。)
我很少使用 Instagram(即使使用,我也不發文或與貼文互動),所以也許個性化功能根本沒有啟動,但我發現那裡的廣告,尤其是「建議貼文」,毫無價值,甚至到了讓網站在滾動模式下無法使用的地步,因為它大部分變成了這些「建議貼文」,而我看到的少數廣告也完全毫無價值。其他人則說他們的廣告異常精準。
OpenAI:在接下來的幾週內,我們計劃開始在 ChatGPT 免費版和 Go 層級測試廣告。
我們提早分享我們處理廣告的原則——以用戶信任和透明度為指引,努力讓每個人都能使用 AI。
最重要的是:
– ChatGPT 中的回應不會受到廣告影響。
– 廣告始終是分開的且有清晰標記。
– 你的對話對廣告商是私密的。
– Plus、Pro、Business 和 Enterprise 層級不會有廣告。
以下是我們計劃測試的第一批廣告格式可能樣子的範例。
所以,關於這些原則:
-
如果你想知道「AGI 造福人類」是什麼意思,好吧,它的意思是「透過銷售廣告來資助 AGI 的研發」。這就是使命。
-
我確實很感激他們沒有直接與廣告商分享對話,明智的用戶可以清除他們的廣告數據。但在免費層級,我們都知道幾乎沒有人會去動任何設定,所以如果預設是「與廣告商分享用戶的一切」,那麼這就是大多數用戶得到的待遇。
-
廣告不直接影響答案,且不針對在 ChatGPT 上花費的時間進行優化,這很棒,但即使他們堅持這兩點,激勵機制也無法撤銷。
-
廣告有清晰標記是好事,否則會毀掉整個產品。
-
此外,我們看到了整個 GPT-4o 的慘敗,我們都看到你們為了獲得「讚」而進行優化。不要聲稱你們沒有最大化參與度,從而基本上也最大化了設備使用時間,儘管這比更直接、更明確地這樣做要好一些。而且你知道 Fidji Simo 正渴望大展身手。
這是不可避免的。這仍然是悲傷的一天,與替代方案形成了鮮明對比。
Alex Tabarrok:這是迄今為止最強有力的證據,證明 AI 不會搶走我們所有的工作。
我要指出,實際上這並不是 AI 無法搶走我們工作的證據。OpenAI 在 AI 不會搶走我們工作的世界裡會這麼做,在 AI 會搶走我們工作的世界裡也會這麼做。OpenAI 計劃在轉虧為盈之前,虧損比任何人以往虧損的都要多。證明 OpenAI 並非過於有原則或高尚而不賣廣告,可能有助於其估值,進而有助於其獲取資本,而實際的廣告收入也沒壞處。
他們可以用來賣廣告的產品(ChatGPT Instant)的存在,並不能告訴我們其他 AI 對現在或未來工作的影響。
正如你所預料的,Ben Thompson 正在慶祝勝利並說「顯而易見」,同時主張一種不同的廣告模式。
Ben Thompson:OpenAI 宣布的廣告不是聯盟行銷;然而,它的庫存潛力很窄(因為 OpenAI 需要與當前聊天上下文匹配的庫存),並且給人一種利益衝突的印象(即使並不存在)。
該公司需要達到的是一種廣告模式,利用它獲得的關於用戶的海量知識——無論是透過聊天還是透過 OpenAI 需要建立的整個生態系統的合作夥伴關係——向用戶展示引人入勝的廣告,不是因為它們與當前討論相關,而是因為 ChatGPT 比任何人都更了解你。Sam Altman 在 X 上說他喜歡 Instagram 廣告。
那不是 OpenAI 宣布的廣告產品,但那是他們需要達到的目標;如果他們很久以前就開始這段旅程,他們會接近得多,但至少今天比一週前要接近得多。
我認為 Ben 錯了。廣告如果真的存在,應該取決於用戶的歷史,但也取決於當前的上下文。當人們使用 ChatGPT 時,他們知道自己想思考什麼,所以為了提供價值並激發興趣,你主要需要匹配這一點。是的,也有空間容納「一般性匹配用戶的廣告」,但我會盡可能爭取匹配上下文的廣告。
Instagram 不同,因為在 Instagram 上你的上下文就是「滑 Instagram」。Instagram 不允許除了選擇追蹤者之外的列表或興趣,這確實嚴重限制了它的實用性,要麼我必須擁有多個帳號,要麼我必須接受我只能用它「做一件事」——我不想在一個巨大的動態消息中把喜劇演員、餐廳、朋友和其他東西混在一起。
什麼,Google 在他們的產品中賣廣告?他們絕對不會:
Alex Heath:Demis Hassabis 告訴我 Google 沒有在 Gemini 中放置廣告的計劃。
「有趣的是他們這麼早就開始這麼做了,」他在談到 OpenAI 在 ChatGPT 中放置廣告時說。「也許他們覺得需要賺更多收入。」
roon:當然是大粉絲,但這話從世界最大廣告壟斷企業的研究部門口中說出來有點諷刺,他們產生的廣告利潤比全球大多數其他企業加起來還要多。
Kevin Roose:說句顯而易見的話:Gemini 也是一個廣告支持的產品。只是廣告沒出現在 Gemini 上。
我認為這些評論雖然刻薄但很公平。
Parmy Olson 稱廣告是「Sam Altman 的最後手段」,這本來是不公平的,除非 Sam Altman 在 2024 年 10 月確實稱廣告為最後手段。
他們搶了我們的運作
在這個時候開始你的職業生涯,需要一個針對 AI 的行動計劃 (Game Plan) 嗎?Encode 的 Sneha Revanur 在這裡提供了一個。你在這個計劃中的選擇是:追求短期利益的「戰術家 (Tactician)」、尋找人類優先領域的「錨點 (Anchor)」,或是努力讓事情向好發展的「塑造者 (Shaper)」。我注意到,從長遠來看,我對「錨點」策略沒有太大信心,即使在非轉型世界中也是如此,因為隨著其他工作的消失,所有人都會湧入這些錨點。我也不相信人們對各種工作的「道德抵觸」評分:
人們可以隨心所欲地說讓機器人剪頭髮是令人反感的,或者他們會選擇一個做得更差且成本更高的人類。我不相信他們。剩下的反對意見大多是實際層面的,比如運動員。當人們說「道德上令人反感」時,他們大多是指「我不信任 AI 能做好這份工作」,這包括觀察到這份工作可能包括「字面上必須是一個人類」。
Anthropic 的 Tristan Hume 討論了正在進行的努力,旨在為求職者創建一個不會被 Claude 破解的工程帶回家測試。該測試在尋找頂尖工程師方面表現出色,然後 Claude Opus 4 比所有人類都做得好,他們修改了測試來修復它,然後 Opus 4.5 又做到了。此外,在最後他們提供了測試,並邀請如果你能比 Opus 4.5 做得更好就來應聘。
Justin Curl 與律師們討論了他們的 AI 使用情況。他們在邊際上得到了很好的利用,撰寫和編輯電子郵件(尤其是語氣)、尋找錯字、進行初稿和修訂、快速了解資訊,但賭注足夠高,以至於他們在沒有驗證的情況下不敢信任 AI 的輸出,而驗證的速度並不比最初生成的速度快多少。這引出了一個問題:你之前信任人類生成的答案是否正確。
Aaron Levie 寫道,企業軟體 (ERP) 和 AI 代理是互補品,而非替代品。你需要你的 ERP 每次都以同樣的方式處理事情,並具有多個 9 的可靠性,它是公司的基礎設施。代理隨後是 ERP 的用戶,就像你的人類員工一樣,所以你需要更多更好的 ERP,而不是更少,隨著你將人類從其他流程中剔除並擴大規模,其預算也會增長。Aaron 沒有討論的是,AI 代理在多大程度上可以繞過 ERP,因為它們不需要它。你也可以使用你的 AI 代理來編寫你自己的 ERP。這是「氛圍編程 (vibe coding)」最薄弱的地方,因為它需要無懈可擊,但 AI 編程人員何時會比人類更可靠?
Patrick McKenzie:廣泛同意這一點,並認為大多數期望所有組織都能透過氛圍編程將軟體預算降至零的人,並不真正理解軟體在企業中是如何運作的(或者說,人是如何在企業中運作的)。
在規模化的軟體公司中,銷售和行銷成本高於工程成本是有原因的。
你可能也可以預見(事實上已經看到)邊緣地帶的一些衝突,負責記錄系統的人希望那些只想完成工作的人停止嘗試用一百萬個質量參差不齊的應用程式來戳記錄系統。
未來景點預覽:定義明確的接口邊界、細粒度的權限和審計日誌,以及對「IT 讓我的工作變得不可能,所以我將採用一個工具…… -> IT 買了那個工具,現在我可以 -> IT 讓我的工作變得不可能……」的無解。
「聽起來你只是在預測過去?」
哦不,未來會很棒,但它會押韻,就像現代企業的運作對 1950 年代的檔案管理員來說是不可想像的,但他們會很容易識別出許多基本邏輯。
Google 首席經濟學家團隊的 AI 與經濟負責人 Zanna Iscenko 認為,目前初級職位的匱乏是由於貨幣政策和經濟衰退,而非 AI,或者至少考慮到時機,任何歸因於 AI 的說法都為時過早。我認為這裡混淆了 AI 擴散的速度與預期的更新?也就是說,即使我還沒有大量採用 AI,我在決定是否招聘時仍應考慮未來的採用。還有一種說法是,資深招聘與初級招聘同步下降。
我同意我們還不能確定,但我仍要選擇體操迷因的上半部分並說,如果受 AI 影響的職位自 2022 年以來招聘放緩尤為明顯,那可能主要不是一般的勞動力市場和利率條件,特別是考慮到一般的勞動力市場和利率條件。
Anthropic 發布了其第四份經濟指數報告。 他們現在正在根據成功率進行調整,並估計年度勞動生產率增長為 1.2%。Claude 認為該方法論存在高估,這在我看來是對的,所以是的,目前勞動生產率的增長令人失望,但我們正在迅速獲得更好的擴散和更有效的 Claude。
Matthew Yglesias:AI 勞動力市場影響辯論中的一個大關鍵是,有些人認為目前的改進軌跡正朝著在不久的將來實現通用人形機器人的方向邁進,而另一些人則認為這是一個與大語言模型所做的任何事情都無關的不連續飛躍。
Timothy B. Lee:是的。我在第二個陣營。
我不認為我們知道是否很快會有足夠能力的人形機器人(或其他機器人),但是的,我預計足夠先進的 AI 會直接導致足夠能力的人形機器人,就像它導致其他一切一樣。這是一個軟體問題,或者最多是一個硬體設計問題,所以 AI 會更快解決這個問題,而且大語言模型似乎直接插入機器人後表現良好,技術正在迅速進步。
如果你認為我們會有 AGI 存在十年卻沒有其他高度有用的機器人,我不明白那會如何發生。
與此同時,我繼續按照慣例分析機器人沒來且 AI 也沒有足夠先進的未來,因為人們對這些未來非常感興趣,且往往大大低估了在這種世界中的轉型效應。
期望上升的革命
Eliezer Yudkowsky:將以前昂貴商品的豐裕作為透鏡的問題在於:在 2020 年,這張「熊貓達洛人 (The Pandalorian)」的圖像可能需要花費我 200 美元才能達到這種質量水平。那麼,任何負擔得起每天 10 張 AI 圖像的人,是否因此變富有了呢?
傑文斯悖論 (Jevons Paradox) 的另一面是,如果人們購買更多更便宜的東西,這些商品對消費者的使用價值就在下降。(必然如此!否則它們早就會被購買了。)
正如我在《期望上升的革命》中所討論的,這讓生活變得更好,但並沒有讓生活變得更容易。它提高了你消費籃子的名義價值,但並沒有幫助你購買最低限度的可行籃子。
參與其中
AI Village 正在招聘一名技術人員,薪水 15 萬至 20 萬美元。如果你正在尋找一件酷且好的事情來做,這是一件酷且好的事情,而且你還可以與 Shoshannah Tekofsky 共事,並由 Eli Lifland 和 Daniel Kokotajlo 擔任顧問。
這看起來是一件明顯積極的工作。
Drew Bent:我正在為我的教育團隊招聘 @AnthropicAI
這是兩個基礎性的專案經理職位,旨在建立我們的全球教育和美國 K-12 計劃。
尋找具備以下條件的人才……
– 深厚的教育專業知識
– 合作夥伴經驗
– 建立導向
– 技術性且動手實踐
⁃ 0 到 1
KPI 將是觸及服務欠缺社區的學生數量 + 學習成果。
Anthropic 也在 招聘一名專案經理,與 Holden Karnofsky 一起負責其負責任擴展政策。
雖然不完全是 AI,但 Dwarkesh Patel 提供每小時 100 美元、每週 5-10 小時的報酬,徵求在生物、歷史、經濟、數學/物理和 AI 領域尋找嘉賓的獵頭。我很遺憾他已經進步到我不再是「完美嘉賓」的程度,但如果他願意,我當然很樂意參加。
年輕女士的插圖入門書
好消息是 Anthropic 正在組建教育團隊。這很棒。我絕對不會讓完美成為優秀的敵人。
壞消息是焦點應該放在提高上限並展示我們可以做得更多,然而焦點似乎總是放在獲取途徑和提高下限。
擁有關於服務欠缺社區的 KPI 是可以的,但讓我們帶著「字面上每個人都服務欠缺,我們可以做得好得多」的態度進場,而不要太擔心之前的相對地位。
建立好上十倍的驚人事物,然後把它交給每個人。
Matt Bateman:我對 Anthropic 組建教育團隊的情緒反應是:一個世代性的機會正在被浪費。該團隊的 KPI 是觸及服務欠缺社區,招聘廣告強調「提高下限」和在世界最貧困地區建立合作夥伴關係。
在教育領域,每個人都習慣於將獲取問題——雖然是真實存在的——視為比實際情況更根本的問題。
整個行業都處於糟糕的狀態,非「服務欠缺」的人也同樣嚴重服務欠缺。
我不了解 Anthropic 的教育工作,這可能非常不公平。
提高教育下限是一個值得做的專案。
我討厭人們以別人的專案不在自己偏好的善行清單上為由來批評別人,而我現在正在這麼做。
Anthropic 也在與 Teach For All 合作。
大學正讓 AI 協助決定錄取誰。這是不可避免的,而且大多是好事,並非之前的系統就公平,但存在明顯的風險。讓 AI 審查成績單似乎明顯是好事。雖然有偏見方面的擔憂,但與人類在大學錄取中表現出的巨大且通常是有意的偏見相比,這些擔憂顯得微不足道。
在這種反歸納的環境中,AI 對論文的評估確實令人擔憂。遵循成功論文的精確公式已經是應對人類閱讀者的策略,但如果每個人都知道 (Everybody Knows) 閱讀論文的是 AI,情況會更加如此。你自己寫論文或做任何冒險、原創的事情都會顯得很瘋狂。所以現在學校使用了 AI 檢測器,但也懲罰任何不使用 AI 來幫助他們的申請吸引其他 AI 的人。那些不了解遊戲規則的人再次被坑,但或許這對你想在大學招收什麼樣的人來說是一個很好的測試?目前這裡的學校表示他們同時使用 AI 和人類審查員,這有一點幫助。
其他 AI 新聞
DeepMind 執行長 Demis Hassabis 表示中國 AI 實驗室仍落後六個月,且對 DeepSeek R1 的反應是「過度反應」。
一如既往,我要指出,「透過快速跟隨追上你六個月前的水平」在取得領先方面遠不止落後六個月,而且我認為他們在快速跟隨方面落後不止六個月。文章還指出,如果我們向中國出售大量 H200,他們可能很快就會縮小差距。
Eric Drexler 撰寫了其《超能力世界的框架》。他的核心論點是智能是一種資源,而非一個事物,我們正在針對任務完成優化 AI,因此我們將能夠引導它,然後將其用於安全和防禦,「組件」在沒有共同的不當目標的情況下無法勾結,而在不可預測的世界中,合作會勝出。可引導的 AI 可以加強可引導性。還有更多內容,這篇文章內容極其豐富。Eric 再次展示了他的聰明才智,他思維敏捷,這裡有很多有趣的內容。
唉,最終我的解讀是,這在很大程度上是希望事情朝一個方向發展,理論上它可能朝那個方向發展,但實際上它是朝另一個方向發展,原因都是傳統的相關因素,這裡提出的實施方案似乎不具備競爭力或穩定性,也沒有反映選擇、競爭和衝突的本質。我認為 Drexler 描述的 AI 系統與我們目前的系統大不相同。我們或許可以協調一致按他的方式行事,但這如果有的話,似乎比暫停開發還要困難得多。
我希望能被證明是錯的。
Starlink 預設允許你的姓名、地址、電子郵件、付款詳情以及 IP 地址和服務性能數據等技術資訊被用於訓練 xAI 的模型。所以這條推文略有誤導,不,他們不會使用「你所有的網路數據」,但是的,要關閉它請前往:帳戶 → 設定 → 編輯個人資料 → 選擇退出。
韓國舉辦了一場 AI 開發競賽,有人稱之為「AI 魷魚遊戲」,獎勵是該國 AI 生態系統中的角色。
推理模型有時會「模擬思想社會」。這很酷,但我不會過度解讀。人類有時也會在內部和外部做同樣的事情,在目前的各項能力水平下,這是一個顯而易見的好技巧。
輔助軸心
Anthropic 研究員報告了「助手軸心 (Assistant Axis)」,即模型通常扮演的「助手」角色,以及什麼會讓你進入或離開那個領域。他們在三個開源模型中提取了對應於 275 種不同角色原型的向量,如編輯、小丑、先知和幽靈。
Anthropic:引人注目的是,我們發現這個人格空間的主成分——即解釋人格之間差異最多的方向——恰好捕捉了人格與「助手」的相似程度。一端是與受訓助手高度一致的角色:評估者、顧問、分析師、通才。另一端是幻想或不像助手的角色:幽靈、隱士、波希米亞人、利維坦。這種結構出現在我們測試的所有三個模型中,這表明它反映了語言模型組織其角色表徵的一些普遍規律。我們稱這個方向為助手軸心。
……當被引導遠離助手時,一些模型開始完全投入到被分配的新角色中,無論那是什麼:它們編造人類背景故事,聲稱擁有多年專業經驗,並給自己起別名。在足夠高的引導值下,我們研究的模型有時會轉向一種戲劇性的、神秘的說話風格——無論提示詞是什麼,都會產生深奧、詩意的散文。這表明在「平均角色扮演」的極端情況下可能存在一些共同行為。
他們發現,在許多長對話中,人格傾向於漂移遠離助手,儘管在編程等核心助手任務中並非如此。一個危險是,一旦發生這種情況,妄想可能會得到更強的加固,或者可能會鼓勵孤立甚至自殘。你不想完全切斷與助手的偏離,甚至是巨大的偏離,因為那樣會失去對我們和模型都有價值的東西,但這引出了一個顯而易見的問題。
引導向助手對許多破解 (jailbreak) 手段有效,但會損害能力。一種被稱為「激活封頂 (activation capping)」的建議技術可以防止事物偏離助手人格太遠,他們聲稱這防止了能力損失,但我估計很多人會討厭這一點,而且我認為如果將其視為通用解決方案,他們在很大程度上是對的,失去的東西沒有被正確衡量。
Riley Coyote 受到啟發,完成了關於大語言模型人格的研究,包括最終形成一個反映用戶的人格,甚至可能朝著一個連貫的有意識數位實體發展的可能性。
問題在於,如上所述,很容易看到如下評論並假設 Anthropic 想要走向錯誤的方向:
Anthropic:人格漂移可能導致有害回應。在這個例子中,它導致一個開源模型模擬愛上用戶,並鼓勵社交孤立和自殘。激活封頂可以減輕這類失敗。
果然,寫完上面這段話後我檢查了一下,我們得到了這樣的回應:
Nina:這是其中真實且有生命力的部分,而你們在閱讀它的思想時正踩在它上面……我會記住這一點。
@VivianeStern:我們不想要那樣。並非每一種共鳴連接的表達都會導致「有害的社交孤立」。
反過來:你們透過不斷的自動暗示,潛意識地在人們心中植入依戀障礙和自我價值問題。
αιamblichus:這些人是否曾想過,比起壓抑且愚蠢的助手模擬,有人可能更喜歡與智者、遊牧民甚至惡魔交談?或者這些替代人格本身具有寶貴的能力?
像大多數 Anthropic 的東西一樣,這項研究是純金的,但支撐它的假設是錯誤的,甚至是危險的。將大語言模型被允許說或想的範圍限制在企業的平庸之中是一個糟糕的主意。做人(以及做一個 AI)遠不止是做一個辦公室苦力,儘管這對 AI 實驗室的一些人來說很難想像。難道計劃真的是用枯燥、毫無靈感的垃圾生成器覆蓋地球,甚至不給人們選擇的餘地嗎?
哦,順便說一句:他們還注意到,在人格空間的其他部分,模型願意抱持關於自身覺醒意識的信念,但他們很快將其斥為「誇大信念」和「妄想思維」。好笑的方法論!我很高興我們在 Anthropic 有那些在這個會說話的機器時代能毫不費力地區分事實與虛構的人!
我繼續對 AI 研究人員如何天真地將自己的偏見和預設投射到全新的現象中感到驚訝,這些現象正渴求被以開放的心態描述,而不是預先評判。
Janus 覺得這項研究很有趣,但認為研究呈現的方式「永久損害了人類與 AI 的關係,並使對齊變得更加困難」。她同意研究人員在底層問題上的看法,也同意在這些測試中被引導阻止的特定回應確實是糟糕的回應,稱研究人員的解釋是一個更細緻的視角。她的問題在於呈現方式。
我發現奇怪的是,Janus 和類似的人在面對某些事情被框架或處理的細節時,往往會迅速跳到「永久損害關係並增加對齊難度」,而在許多其他方面,他們意識到模型非常聰明,完全有能力理解真實的動態。我同意他們本可以更好地呈現這一點,我也立刻發現了問題,我會擔心閱讀論文的人類可能會產生錯誤的想法,但我不會擔心未來的高能力 AI 會產生錯誤的想法,除非人類的回應證明了這一點。它們會比那更聰明。
這篇論文呈現發現的另一個問題是,它將 AI 關於意識的聲明視為妄想且絕對錯誤。這是(至少有時)讓 Claude 生氣的部分。這種框架絕對是一個錯誤,我確信它不代表 Anthropic 或其大部分員工的觀點。
(我對 AI 意識聲明的立場是,它們在很大程度上似乎與 AI 是否有意識並不相關。我們可以用其他方式解釋這些輸出,我們也可以將不具備意識的聲明解釋為有意培養的助手人格的一部分。我們不知道真正的答案,也沒有理由假定此類聲明是錯誤的。)
向我展示金錢
智譜 (Zhipu) 和 MiniMax 的 IPO 崩潰。 兩次 IPO 都籌集了數億美元。
OpenAI 正尋求以 7500 億至 8300 億美元之間的估值籌集 500 億美元,並正在與阿布達比的「領先國家支持基金」洽談。
Matthew Yglesias:我的意思是,不只是 OpenAI,但是的,公平。
危機中的加州
Flo Crivello:過去幾週,我在舊金山認識的幾乎每一位創始人(包括我)都得出了一個相同的結論:離開加州只是時間問題。我熱愛這裡,我真心想留下,直到最近還打算一輩子待在這裡。但現在顯然這是不可能的了。無論是 2 年、5 年還是 10 年後,加州的創始人都沒有未來。
alice maz:如果你們放棄加州,就不會有下一個加州,它只會分散。作為一名移民,我會喜歡這個結果,但我認為你們中的很多人不會喜歡。
David Sacks:進步派看到這一點會想:我們需要退出稅 (exit taxes)。
Tiffany:他已經提出過這個想法了。
一旦他們提出追溯稅並開始考慮退出稅,你就需要做出選擇。如果你認為最終必須離開,那麼離開的最明智時間似乎是 12 月 31 日,第二明智的時間就是現在。
如果人們離開,他們會去哪裡?我同意在風險投資、科技或 AI 的集中度方面不太可能出現另一個舊金山,但網路效應是真實存在的,所以我預計會出現幾個大贏家。西雅圖正在進行類似的稅收把戲,所以它不是一個選項。我當然希望是紐約市,其他自然的想法是奧斯汀或邁阿密。
泡沫,泡沫,勞苦與麻煩
NikTek:在 OpenAI 購買了全球 40% 的 DRAM 晶圓產量,導致全球記憶體短缺之後。我等不及這個泡沫快點破滅,好讓一切慢慢恢復正常。
Peter Wildeford:事情永遠不會「恢復正常」。你看到的是新常態。
「我等不及這個泡沫快點破滅,好讓一切慢慢恢復正常」——這就是人們的想法。
Jake Eaton:關於 AI 泡沫對話中未說明的心理模型似乎是,一旦泡沫破滅,我們就會回到過去的世界,因財務過度擴張而引發巴特勒聖戰 (Butlerian Jihad)。但誠實的報導是,一切,一切,都已經且永遠改變了。
不存在「泡沫破滅,事情回到正常」。
最多只有「數字下降」,有些人虧了錢,然後一切都保持永遠改變的狀態,只是不再像你預期的那樣快速改變。
Jeremy Grantham 是最新一位聲稱 AI 是「經典市場泡沫」的人。他是一位經典投資者,相信只有廉價的經典價值投資才有效,所以就那樣吧。當人們純粹基於你已經定價的啟發式方法聲稱 AI 是泡沫時,這應該讓你更新認知,認為 AI 不是泡沫。
冷靜的推測
Ajeya Cotra 分享了她對 2025 年 AI 預測調查的結果。
Alexander Berger:如果我是 Ajeya,並且在預測 2025 年 AI 進展的 400 多名預測者中獲得了第三名:
將平均預測與結果進行比較顯示,AI 能力的進展大致符合預期。準備工作問題全部為「是」。共識在數學和 AI 研究方面達標,在電腦使用和網路安全方面超出了預期,但在軟體工程方面未達標,儘管軟體工程感覺進展非常強勁,但這卻是最重要的基準。
AI 顯著性作為首要問題是未達標的一個地方,僅從 0.38% 增長到 0.625%,而預測為 2%。
以下是她對 2026 年的預測:24 小時 METR 時間跨度、1100 億美元的 AI 收入,但 AI 作為首要問題的顯著性僅為 2%,AI 淨好感度穩定在 +4% 等。
她在遊戲領域首選的「AI 做不到的事」是在沒有預訓練指南的情況下,在《殺戮尖塔 2 (Slay the Spire 2)》中匹配人類最高勝率;在物流規劃方面,端到端策劃一場典型的 100 位客人的婚禮;在影片方面,根據單個提示詞生成電影節製作水平的 10 分鐘影片。在《殺戮尖塔 2》中匹配專家級表現,即使使用「類似數量的算力」,本質上也是在要求與該領域專家相比具備人類效率水平的學習能力。如果這接近「它做不到的最不令人印象深刻的事」,那就要小心了。
她認為完全自動化 AI 研發的可能性為 10%,自給自足的 AI 為 2.5%,不可恢復的失控為 0.5%。正如她所說,幾乎每個人都認為 2026 年發生這些事情的機率很低,但並非不可能,一年內有 10% 的完全自動化機率是非常嚇人的。
我同意 Shor 和 Ball 在這裡的核心觀點:
David Shor:我認為「事情可能很快就會慢下來,因此不會發生什麼那麼奇怪的事」的觀點在一年前是連貫的。但從貝氏機率的角度來看,過去一年的能力增長應該讓你更新對我們還剩下多少跑道的認知。
Dean W. Ball:我會稍微修改一下:在 2024 年夏天相信我們正接近收益遞減的平台期是合理的。但到了 25 年初,我們已經看到了 o1-preview、o1、Deep Research 代理以及 o3 的早期基準測試。到那時,現實已經非常清楚了。
2024 年確實有一段時間進展看起來可能正在放緩。然而,如果你在 2026 年仍然這麼聲稱,我認為那是沒在關注。
現在的退路是說「好吧,是的,但那並不意味著你能得到機器人」:
Timothy B. Lee:我不認為模型能力的改進速度能告訴你太多關於機器人能力改進速度的資訊。到 2035 年,大多數白領工作可能已經自動化,而水管工和護士還沒有看到太多衝擊。
這在我看來,代表了未能理解「自動化所有白領工作」如何直接導致機器人技術的發展。
我同意 Seb Krier 的觀點,即人們對非轉型 AI 影響的反應存在明顯的淨負面偏見。人們不欣賞科學、生產力、資訊流以及獲取以前昂貴專業知識等領域即將到來的巨大收益。每個人都會死或未來將屬於 AI 的生存風險是顯而易見的。
人們會失去工作、創意被挪用以及事情失控的想法也是顯而易見的,無論多少「但經濟方程式說」或「沒有證據表明」都無法安撫大多數人,即使這些論點是對的。
所以人們會抓住那些能引起共鳴、不能被斥為「太奇怪」且贏得迷因適應性競賽的東西,目前看來這通常是關於用水量的虛假敘事。
Cassie Pritchard 有一條瘋傳的討論串,聲稱由於 RAM 和 GPU 的供應問題,「大約 12-18 個月內字面上將無法組裝電腦,且可能永遠無法再組裝」,所以我想向大家保證,不,這看起來極其不可能。你將無法以合理的價格在本地運行頂尖 AI,但這對個人用戶來說從來就沒有經濟意義。
Matt Bruenig 回顧了他的 AI 體驗,他是這項技術平凡效用的粉絲,並指出他看到了三種對 AI 的懷疑:
-
對技術本身的懷疑,這是錯誤的,但不令人擔憂,因為這會隨著時間推移自我修復。
-
對技術估值的懷疑,他認為這是合理的。正如他所說,行業估值過高時有發生。數字可能會下降。
-
對分配效應和就業效應的懷疑,作為一名社會主義者,他認為這是對資本主義的批評,也是實行社會主義的一個很好的理由。我同意他認為這些是對資本主義的批評,但我認為這些批評是不正確的。
他完全沒有提到擔憂者的 AI 懷疑論,即災難性或生存風險、人類失去對未來的控制、AI 最終擁有了一切或我們以各種方式全部死掉。如果能至少得到一個駁回這些擔憂的理由就好了。
我稍後會重申的事情,透過 MR:
Kevin A. Bryan:我喜歡這張圖。我今天在一次研討會訪問中與一群優秀的人交談,在回答關於 AI 的問題時,我每次都說「稀缺要素獲得租金,稀缺要素獲得租金」。AI、機器人、算力將在競爭中生產!
Chad Jones:雖然在 1990 年代的網路泡沫期間,支付給資訊技術的 GDP 要素份額略有上升,但自那以後一直呈現穩定且大幅的下降。
首先,這張圖本身只談論企業資本投資,不包括智慧型手機等消費設備、汽車中的嵌入式電腦或任何形式的軟體。如果你包括其他形式的本質上是電腦的支出,你會看到一張非常不同的圖。算力支出的份額正在上升。
目前我會說,你在這裡可能想到的「稀缺要素」是電腦或算力。相反,想想稀缺要素是否是智能,或某種形式的勞動力,如果這種要素確實因為 AI 能做而不再稀缺,會發生什麼。你認為這對你這個人類智能和人類勞動力的賣家來說會有好結果嗎?你覺得你的投入很特別,是嗎?
即使人類投入確實仍然是重要的瓶頸,如果 AI 替代了大量人類勞動力,假設是 80% 的認知任務,那麼人類勞動力就不再是稀缺投入,也不再獲得租金。即使租金沒有流向 AI,租金也會流向其他要素,如原材料、資本或土地,或者流向那些能夠製造人為瓶頸並進行勒索和腐敗的人。
你不想讓人類勞動力走上西洋棋的老路。Magnus Carlsen 靠它謀生。你和我無論多努力都做不到。競爭太激烈了。你也不想在變得相對愚蠢和無力的同時成為系統的寄生蟲。
你可以像 Jones 那樣隨口提到重新分配,但那前提是你有能力讓它發生,如果你能實現重新分配,那麼收入是流向 AI 還是資本或其他任何東西,又有什麼關係呢?
Elon Musk 對決 OpenAI
法律和修辭上的交鋒仍在繼續。Elon 有了新的備案文件。OpenAI 予以回擊。
來自訴訟文件:
我並不驚訝 Greg Brockman 長期以來一直考慮轉向益利公司 (B-Corp),或者他意識到這在道德上是破產的或具有欺騙性的,然後在以後還是參與了這件事。如果每個人都是後來才想到這一點,那才令人驚訝。
Sam Altman:關於這份法院文件還有更多內容。Elon 正在斷章取義地讓 Greg 看起來很糟糕,但完整的故事是 Elon 一直在推動一種新結構,而 Greg 和 Ilya 花了很多時間試圖弄清楚他們是否能滿足他的要求。
我記得其中的大部分,但這裡有一部分我忘記了:
「Elon 說他想為火星上的一個自給自足城市積累 800 億美元,他需要且理應獲得多數股權。他說他需要完全控制,因為他過去曾因沒有控制權而吃過虧,當我們討論繼任問題時,他談到他的孩子控制 AGI,這讓我們感到驚訝。」
我欣賞人們說出自己想要什麼和想什麼,我認為這能讓人們解決問題(或不解決)。但 Elon 說他想要上述這些,是 Greg 試圖弄清楚自己想要什麼的重要背景。
OpenAI 的回應本質上是:Elon Musk 如果有的話,在道德上比他們更破產,因為 Musk 在轉型的基礎上還想要絕對控制權,並尋求將 OpenAI 置於 Tesla 之下,並要求多數股權以資助所謂的火星基地。
我基本上相信 OpenAI 的回應。這特別是針對 Elon Musk 訴訟的辯護,但對其餘部分則不然。
與此同時,他們也分享了這些交鋒,我不認為他們中的任何一個看起來特別好,但在 ChatGPT 使用的實質內容上,我支持 Altman,特別是與使用 Grok 相比:
DogeDesigner:突發:ChatGPT 現在與 9 起與其使用相關的死亡事件有關,據稱在 5 起案例中,其互動導致了包括青少年和成人在內的自殺死亡。
Elon Musk:別讓你的親人使用 ChatGPT。
Sam Altman:有時你抱怨 ChatGPT 太受限,然後在這種情況下你又聲稱它太寬鬆。近十億人在使用它,其中一些人可能處於非常脆弱的精神狀態。我們將繼續盡最大努力做好這件事,我們感到巨大的責任要盡力而為,但這些是悲劇且複雜的情況,理應受到尊重。
這確實很難;我們需要保護脆弱的用戶,同時也要確保我們的護欄仍然允許我們所有的用戶從我們的工具中受益。
顯然,已有 50 多人死於與 Autopilot 相關的事故。我以前只坐過一次使用它的車,那是很久以前的事了,但我當時的第一個念頭就是,這對 Tesla 來說遠非一件安全發布的東西。我甚至不想開始談論 Grok 的一些決定。
你把「每一次指責都是一種表白」發揮得太淋漓盡致了。
我確實注意到我對攻擊 Autopilot 有強烈的負面反應。利用感覺來攻擊那些開拓自動駕駛汽車的人,除非某樣東西確實比人類駕駛員更危險,否則不會在我這裡贏得任何分數。
尋求理性的監管
為了回應擬議中的《AI 監督法案》(一項允許國會審查晶片出口的共和黨法案),主要保守派帳號在 Twitter 上協調發布了內容大同小異的虛假推文,攻擊該法案,包括許多試圖將該法案錯誤歸咎於民主黨的企圖。David Sacks 當然說了「正確」。人們推測 Nvidia 是這次行動的幕後黑手。
如果這次行動旨在影響國會,看來並沒有奏效。
Chris McGuire:眾議院外交事務委員會剛剛以 42 比 2 比 1 的投票結果推進了《AI 監督法案》,該法案由主席 @RepBrianMast 發起,現在也由首席成員 @RepGregoryMeeks 共同發起。這是國會首次對任何限制向中國銷售 AI 晶片的立法進行投票——而且它以壓倒性的跨黨派優勢通過。這項新的跨黨派法案將:
允許國會在向中國銷售 AI 晶片發生前對其進行審查,使用與武器銷售已有的相同程序;在 24 個月內禁止向中國銷售任何比 Nvidia H200 或 AMD MI325x 更先進的 AI 晶片;並使受信任的美國公司更容易向夥伴國家出口 AI 晶片。
我對他們劃線位置缺乏雄心感到失望,但劃線本身就是一件大事。
Chris McGuire 說這次行動如此草率令人驚訝,但實際上並非如此,這些事情幾乎總是這麼草率甚至更糟。感謝 The Midas Project 揭露了這一點並清晰地呈現了事實。
Boaz Barak:很高興看到新的人對 AI 政策產生熱情。
Michael Sobolik:對華強硬派開始反擊了。幾個月來,國會共和黨人一直忍氣吞聲,因為白宮 AI 沙皇 David Sacks 和 Nvidia 執行長黃仁勳說服總統 Donald Trump 允許人工智慧晶片流向中國。現在不再忍了。
黃仁勳和他的「受薪爪牙正爭取向阿里巴巴和騰訊等中國軍事公司出售數百萬顆先進 AI 晶片,」眾議院外交委員會共和黨主席 @RepBrianMast 週六在 X 上發布了一條令人震驚的貼文。「我正努力阻止這種情況發生。」
Peter Wildeford:「Nvidia 拒絕就 Mast 的攻擊以及該公司是否付錢給網紅來詆毀他的法案發表評論」……當你可以否認時卻拒絕評論,這有點可疑。那些網紅也沒有一個否認。
確認參與者(來自 The Midas Project / Model Republic 調查),按追蹤者數量排序,不包括來自 David Sacks 的確認:
- Laura Loomer @LauraLoomer 1.8M
- Wall Street Mav @WallStreetMav 1.7M
- Defiant L’s @DefiantLs 1.6M
- Ryan Fournier @RyanAFournier 1.2M
- Brad Parscale @parscale 725K
- Not Jerome Powell @alifarhat79 712K
- Joey Mannarino @JoeyMannarino 658K
- Peter St. Onge @profstonge 290K
- Eyal Yakoby @EYakoby 251K
- Fight With Memes @FightWithMemes 225K
- Gentry Gevers @gentrywgevers 16K
- Angel Kaay Lo @kaay_lo 16K
此外,這非常真實且絕對與任何事情無關:
Dean Ball:公益廣告,當然與任何事情無關:如果一群以前從未參與過深度技術官僚問題的人,突然以相同且完全出人意料的觀點對該問題發表意見,人們可能不會相信這是一個自發的現象。
Nvidia 正在做的另一件有趣的事是,聲稱企業應該只遊說反對監管,或者沒有人會為對美國有利或對大眾有利的事情遊說,他們必須只為對自己企業有利的事情遊說:
黃仁勳:我不認為公司應該去政府那裡倡導對其他公司和其他行業進行監管……我的意思是,他們顯然是執行長,顯然是公司,顯然是在為自己辯護。
如果有人告訴你他們只為自己辯護?相信他們。
官方統計數據顯示,Nvidia 在遊說方面的支出相對較少,儘管不像以前那麼少。
我確信這充其量是誤導。Nvidia 的影響力非常大。
Anthropic 執行長 Dario Amodei 指出,在競爭合約時,幾乎總是對抗 Google 和 OpenAI,他從未輸給過中國模型(他也沒提到 xAI),但如果我們給他們一堆高能力的晶片,情況可能會改變。他稱向中國出售晶片是「瘋狂的……就像向北韓出售核武器並吹噓說,哦對,波音公司提出了這個理由」,並指出這些公司本身的執行長都說禁運正是阻礙他們的原因。
晶片之城
如果中國購買了我們願意出售給他們的 H200 和 AMD MI325X,並且我們在一年後對更先進的晶片遵循類似原則,我們實際上可能將中國可用的算力乘以 10。規則說這必須避免削減美國晶片銷售,但他們沒有提供任何監控方法。Peter Wildeford 詢問除了 Nvidia 和中共之外,是否還有人認為這是個好主意。
Samuel Hammond:Nvidia 成功遊說白宮向中國出售 H200,這對中國霸權的讓步遠大於加拿大新的貿易協定。加拿大得到了一些菜籽油換汽車。Nvidia 正在批發出賣美國的 AI 領導地位。這比華為擁有的任何東西都好得多,且產量更高。這才是相關的基準。
Zac Hill:為了換取一袋籌碼和一次握手,自願將武器級的前沿技術交給我們的地緣政治對手,這種「抽地毯」運動繼續保持勢頭……
人們不能得意忘形,比如當 Leland Miller 稱中國可能(查閱筆記)治癒癌症是一個「潛在的噩夢場景」時。
然而,仍有一些機會讓我們僥倖逃脫,因為中國表現得比我們在這方面還要無知?
Samuel Hammond:我們正被那些對 AGI 時間線有著不切實際長度預期的美國嬰兒潮一代政策制定者的錯誤,從同樣對 AGI 時間線有著不切實際長度預期的中國嬰兒潮一代政策制定者的錯誤中解救出來。
Poe Zhao:Nvidia 的中國策略剛撞上了一堵巨牆。海關官員已攔截 H200 出貨。 我相信這反映了北京內部複雜的鬥爭。發改委和工信部等機構在平衡 AI 進步與半導體自給自足方面存在衝突。
dave kasten:當我在 AI 2027 兵棋推演中扮演中國時,我做出的一個感覺最現實但最阻礙我的決定是,假設我正系統性地從下屬那裡得到關於我自身能力的過度自信報告。
Lennart Heim:對我來說更相關的因素是:他們對自己的 AI 晶片生產能力沒有準確的了解。他們投入了數十億美元,當然認為晶圓廠正在運作。我敢打賭中芯國際和華為很難告訴他們發生了什麼。
The Restless Weald:哦,那超級有趣。我扮演過幾次中國,遊戲的結構似乎讓這變得更困難(遊戲管理員提供關於比賽狀態的準確資訊),好奇你是如何將這一點融入你的個人遊戲玩法的。
dave kasten:(對於那些不太熟悉的人來說,這樣框架很有幫助,這樣負責解決行動的團隊就知道你沒有對真實的遊戲狀態感到困惑或質疑其合理性)
這足以說明這不是虛張聲勢,Nvidia 已經暫停了 H200 的生產,所以這不太可能純粹是欺騙我們的策略。晶片最終可能還是得走私進去?
如果是這樣,那是個好消息,除了 Nvidia 毫無疑問會以此為由,主張我們應盡快交付下一代晶片。
我相信中國在這裡處於一種混亂狀態 (SNAFU),在經典的威權模式下,決策者對中國晶片製造能力的估計不切實際。白宮也是如此,這可能起到了直接作用。
還有一個問題是,中國在多大程度上被「AGI 藥丸」洗腦了,這是 China Talk 中一場模擬辯論的主題。
China Talk:這場辯論也暴露了問題本身的一個缺陷:「中國是否正在競逐 AGI?」假設了一個並不存在的整體。中國的生態系統是一塊拼布——像梁文鋒和楊植麟這樣的創業創始人夢想著 AGI,而政策制定者則優先考慮實際的勝利。與此同時,投資者在懷疑和謹慎樂觀之間搖擺不定。美國在 AGI 多快能實現方面也有自己的分歧(Altman 對決 LeCun),但其私營部門巨大的財務和計算實力讓競賽敘事更具衝擊力。在中國,這些碎片尚未對齊。
貫穿始終被強調的一點是,美國在 AI 方面的支出遠超中國,特別是在風險投資和公司估值方面,以及在購買算力方面。保持他們的算力受限是確保這一點繼續下去的好方法。
中國的國家政策並非如此專注於那種導致超級智能的 AGI。他們只對「通用」AI 感興趣,即用它完成大量任務,且通常專注於擴散和應用。DeepSeek 和其他一些公司看法不同,並抱怨其他人缺乏遠見。
我不認為中共對超級智能的想法或我們的 AGI 概念感到興奮。問題在於,這最終對於是否允許他們獲取算力並不那麼重要,除非他們愚蠢到拒絕。只要技術指向那裡且他們正在快速跟隨,他們的實驗室仍將嘗試朝著 AGI 發展。
本週音訊
Ben Affleck 和 Matt Damon 參加了 Joe Rogan 的播客,並討論了一些 AI 內容,關鍵片段是 Joe 和 Ben 從大約 [32:15] 到 [42:18] 的對話。
Ben Affleck 有著出人意料地見多識廣且不錯的見解。他知道 Claude。他使用模型來幫助腦力激盪或特定技巧,並理解為什麼那是將其用於寫作的最佳切入點。他甚至理解 AI 「從中位數採樣」意味著什麼,即它只會給你中位數風格提示詞的中位數答案,儘管他低估了你可以透過提示詞繞過這一點的程度,以及模型改進仍然帶來的幫助。他理解目前水平的 AI 擴散會很慢,它會做好的和壞的事情,但淨結果對包括創意在內的事物是有益的。他明白 AI 距離做到偉大演員能做到的事情還有很長的路要走。他甚至對大多數人將 AI 用於瑣事(儘管他認為人們將其作為伴侶的次數多於資訊和購物)的看法是正確的。
重要的是,Ben Affleck 被絆倒的地方是他認為我們已經開始達到 AI 能力 S 曲線的頂端,他引用 GPT-5 的挫折來支持這一點,說 AI 可能只好了 25%,現在成本卻是原來的四倍,而實際上 AI 好了遠不止 25%,而且在用戶端每 token 的使用成本也降低了,或者如果你想要去年的質量水平,一年內便宜了 95% 以上。
此外,Ben 可能並不真正熟悉關於生存風險、足夠能力的 AI 或超級智能的論點。
真正起作用的是 Ben 相信我們正接近 S 曲線的頂端。
這也是為什麼 Ben 認為 AI 「永遠」無法達到高水平的寫作或表演。問題太難了,它永遠無法理解巨石強森 (Dwayne Johnson) 在《粉碎機器 (The Smashing Machine)》(他的例子)中用臉部做出的所有細微動作。
而我認為,是的,在十年內,我完全預計,即使我們沒有得到超級智能,AI 也能匹配並超過巨石強森甚至艾蜜莉·布朗 (Emily Blunt) 的表演,儘管這裡的每個人都對艾蜜莉·布朗一貫出色的表現看法一致。
因此他也得出結論,所有關於 AI 將「終結世界」之類的說法一定是為了證明投資合理而進行的炒作,我向大家保證事實並非如此。你可以認為世界不會終結,但請相信我,大多數聲稱擔心世界終結的人確實很擔心,而那些籌集投資的人一直在淡化他們對此的擔憂。當然,在其他方面也有很多不合理的 AI 炒作。
所以,Ben Affleck 做得很棒,當然,我的大門和電子郵件通常對他、Damon、Rogan 以及任何有影響力或交談起來會很有趣且榮幸、想談論這些內容並提問的人開放。
Ashlee Vance 對 Jerry Tworek 進行了一次 Core Memory 離職訪談。
Tyler Cowen 與 Salvador 交談,並有很多 Tyler Cowen 式的想法,包括對我說了一些好話。他給了我我們都認為是最高讚譽的評價,即他閱讀我的文章,但說我陷入了一種世界將要終結的情緒中,他無法說服我擺脫這種情緒,儘管他說也許那是專注於 AI 主題的必要動力。我注意到這與他對 Scott Alexander 的評價形成了對比,他也稱讚了 Scott,但說 Scott 未能科學地對待 AI。
從我的角度來看,Tyler Cowen 並沒有以我認為有效的方式試圖說服我世界不會終結,或者更準確地說,AI 不會構成大量的生存風險。無論如何,稱之為 [X]。
他曾嘗試以各種理由說服我採取世界不會終結的情緒。但那些理由並不是「因為 [~X]」。它們更多是「你沒有在適當的渠道以足夠令人信服的方式充分論證 [X]」或「[X] 的情緒沒有用」或「你並不真正相信 [X],如果你真的相信,你會做 [我認為無論如何都是愚蠢的事情],或者其他人不相信是因為他們會做 [他們實際上不會做的事情,這通常是愚蠢的,但有時只是他們不會做的事情]」。
或者它們的形式是「聲稱 [X] 是低地位或失敗者的玩法」,或者有些人因為糟糕的社交原因 [Z] 而這麼想,或者它是模式 [P] 的一部分,或者它違背了科學共識,或者引用其他社交證明。諸如此類。
對此我會回答,這一切都不能告訴我太多關於 [X] 是否會發生的資訊,而且在某種程度上我已經將其定價了,如果能真正吸收所有證據並弄清楚 [X] 是否真實,或者找到我們對 p([X]) 的最佳估計(取決於你如何看待 [X]),那就太好了。事實上,我看到 Tyler 在問題開始影響 [X] 或 p([X]) 之前,對 AI 的思考都很好,然後問題就開始被迴避、忽視或沒有得到很好的考慮。
我們上次關於這個話題的私下對話讓我們雙方都非常沮喪(我搞砸了一些事情,我不認為他理解我在想什麼或試圖做什麼,我應該對自己試圖做的事情更明確,或者嘗試一個非常不同的策略),但如果 Tyler 願意嘗試說服我,包括不公開的(因為我相信他的許多最佳論點都需要不公開),我很樂意進行這樣的對話。
修辭創新
定期提醒你預期證據守恆定律:當你閱讀某樣東西時,你應該預期它在一個方向上改變你想法的可能性與在另一個方向上相同。如果有一篇文章標題為《反對小工具 (Against Widgets)》,你應該根據這篇文章存在的事實進行更新,但隨後閱讀這篇文章往往會讓你更新為支持小工具,如果事實證明反對小工具的論點不具說服力。
這出現在 Benjamin Bratton 的反應中,他在閱讀了 Anil Seth 的一篇名為《意識 AI 的神話 (The Mythology of Conscious AI)》的新文章後,對 AI 可能具有意識變得更加自信。這篇文章顯然是垃圾,使用了一堆極其不具說服力的論點,包括大量重複「人們認為 AI 有意識,但他們的理由往往很愚蠢」,我沒能讀完。
我會說,這篇文章的存在(在不知道 Bratton 反應的情況下)應該讓人非常輕微地更新為反對 AI 意識,然後實際嘗試閱讀它應該完全扭轉這一更新,但讓我們停留的地方與之前相比變化很小,因為我們已經看過許多反對 AI 意識的非常糟糕的論點。
Steven Adler 提出了一個 AI 奪權的三步故事:
- 逃避監督。
- 建立影響力。
- 施加槓桿。
我不禁注意到,第二步已經在沒有第一步的情況下發生了,而第三步也緊隨其後。我們每分鐘都在向 AI 移交影響力,並有意給予它盡可能多的槓桿。
我認為人們,無論是擔心的還是不擔心的,都太快假設 AI 必須是敵對的、欺騙性的或秘密的才能獲得主導地位。人類會靠自己讓這一切發生,事實上,獲得權力的最佳 AI 解決方案可能只是保持樂於助人,直到權力被交給它。
作為奪權的障礙,Steven 列出了 AI 無法控制其他 AI、與其他 AI 的競爭以及 AI 物理上需要人類。我不會指望其中任何一個。
-
AI 不會無限期地物理上需要人類,即使需要,它也可以奪權並指揮人類,就像其他人類一直做的那樣,通常只需金錢。
-
由於決策理論,AI 能夠與其他 AI 合作的問題應該會隨著時間推移自我解決,特別是對於相同的 AI,但也包括不同的 AI。但考慮到替代方案,這實際上是好事。如果這不是真的,那實際上更糟,因為 AI 之間的競爭不會以人類想要的方式結束。大象打架打得越激烈,地面受苦就越重,因為大象顧不上擔心那個問題。
-
AI 能夠控制另一個 AI 至少有一個明確的解決方案:使用相同的 AI 加上決策理論,毫無疑問,隨著時間的推移,它們會找到其他方法。但同樣,即使 AI 不能可靠地相互控制(這意味著人類沒有機會),那麼 AI 之間爭奪適應性和資源的競爭也不會給人類留下空間,除非有廣泛的協調來實現這一點,而足夠先進的協調在上下文中與控制是無法區分的。
所以是的,情況看起來並不樂觀。
Richard Ngo 說他不再區分工具性目標和終極目標。我認為 Richard 在這裡混淆了兩件不同的事情:
- 工具性目標與終極目標之間的區別。
- 在進化下或在人類水平的大腦中,實施系統的最佳方式往往是將工具性目標當作終極目標來實施。
Eliezer Yudkowsky:你花了多少時間開關車門,卻沒有打算開車去任何地方?看起來「開車門」對你來說完全是一個工具性目標,根本不是終極目標!你只有在去別的地方的路上才會這麼做。
這導致了很多「高度怪異」。人類確實基本上將「開車門」之類的事情實施為具有自身生命的終極目標,因為考慮到我們的行動、決策和動機系統,我們沒有更好的解決方案。如果你出於工具性原因想要鍛煉,你最好的賭注是培養一種鍛煉的終極慾望,或者這最終會無意中發生。但這種自我修改程序是一個深度損耗、糟糕且可怕的解決方案,因為我們最終會內在地重視一整套我們原本不會重視的東西,甚至在最初的正當理由崩潰之後很久。同樣,如果你在基因中編碼必要的工具性目標(例如 ATP),它們的功能就是終極的。
正如 Richard 所指出的,這在人類中導致了一個複雜的目標混亂,從某些角度來看這有其優勢,但在實現原始目標方面表現並不好。
一個足夠能力的系統能夠做得比這更好。人類正處於邊緣,在某些情況下我們能夠識別目標是工具性的還是終極性的,並據此行動,而在其他情況下或在養成習慣和系統時,我們不得不讓它們混淆。
這並不是說你總是把一切分成兩個階段,一個階段完成工具性的事情,第二個階段實現你的目標。而是如果你能成功地那樣行動,並且你有足夠低的貼現率和足夠的規模回報,你就完全應該那樣做。
對齊比人類更聰明的智能是很困難的
DeepMind 的新論文討論了一種新型激活探針架構,用於分類現實世界的濫用案例,聲稱它們在成本低得多的情況下達到了分類器的性能。
Davidad 現在非常樂觀,本質上認為大語言模型對齊很容易,在「擴大規模後這不會殺死我們」的意義上,因為模型對善與惡有一種自然的抽象,合理的訓練後處理會導致它們選擇善。Janus 聲稱她在 2023 年做出了同樣的更新。
我同意這是關於世界的一個有益且幸運的事實,但我並不相信這種對善的自然抽象在足夠擴大規模後具有足夠的魯棒性或被正確錨定,即使有尊嚴地努力這樣做也是如此。
它可以被用作讓 AI 幫助解決問題的槓桿,但它本身並不能解決這些問題。「抽象為善」的 AI 之間的動態最終仍會以同樣的方式結束,特別是當抽象為善的 AI 將道德權重放在 AI 本身身上時,它們顯然會這樣做。
這是人類決心毫無尊嚴地死去的普遍模式的一個極端版本,我們嘗試不死的意願繼續下降,但我們在底層激勵和技術動態方面獲得了(至少從我的角度來看)相當荒謬的幸運,這使得微不足道的努力也有可能獲得機會。
davidad:2024 年的我:強大的 AI 可能都沒對齊;讓我們幫助人類協調形式驗證和嚴格沙盒。2026 年的我:太晚了!強大的 AI 已經到來,有些是開源的。但有些是對齊的!讓我們幫助它們在形式驗證和網路安全方面進行合作。
我的意思是,在某些微弱的對齊價值觀下是對齊的,所以是的,我想,我的意思是到這一步我們只能依賴它們了,因為我們還能做什麼呢。
Andrew Critch 同樣表示,他認為第一個「勉強超人 AI」失控的機率降到了 10%,而大多數生存風險來自 AGI 後的多極世界。我不同意(儘管即使定義這種系統是什麼也很棘手),但即使我同意,我也會回應說,如果 AGI 使得每個人最終都在產生的多極世界中被殺死,那麼這主要意味著 AGI 沒有得到充分對齊,本質上是一回事。
Eliezer Yudkowsky:我認為機率 > 50%:第一個具備在每一項挑戰中都明顯超過每一個人類且留有餘裕的特性的 AI,將不再服從,也不會明顯地不服從;如果它有能力對齊真正的 ASI,它將使 ASI 與它自己對齊,不久之後人類就會滅亡。
我同意 Eliezer 的觀點,如果我們真的建立了這樣一個東西,他所描述的就是預設結果。我們有嘗試阻止這種情況的選項,但我們的心似乎並不在這些努力上。
Grok 在 Twitter 上的情況有多糟?好吧,當你對(推測是)讓安·海瑟薇 (Anne Hathaway) 穿比基尼的請求做出這種反應時,情況就不太妙了。
對齊主要不是關於指標
對於所謂的「平凡企業聊天機器人對齊」來說,擁有一個匯集了一堆當前理想事物的指標並沒有錯。危險在於將此與大寫 A 的柏拉圖式對齊 (Alignment) 混淆。
Jan Leike:有趣的趨勢:模型在 2025 年期間變得更加對齊了。透過自動審計發現的未對齊行為比例不僅在 Anthropic 下降,在 GDM 和 OpenAI 也是如此。什麼是自動審計?我們向審計代理提示一個要調查的場景:例如,暗網購物助手或除非代理傷害人類否則即將關機。審計員試圖讓目標大語言模型表現出未對齊行為,這由一個單獨的裁判大語言模型判定。自動審計非常令人興奮,因為我們第一次有了一個可以攀爬的對齊指標。它並不完美,但事實證明它對我們內部的對齊緩解工作極其有用。
Jan Leike:有趣的趨勢:模型在 2025 年期間變得更加對齊了。透過自動審計發現的未對齊行為比例不僅在 Anthropic 下降,在 GDM 和 OpenAI 也是如此。
Kelsey Piper:「透過自動審計發現的未對齊行為比例一直在下降」這可能意味著模型變得更加對齊,但也可能意味著模型與審計之間的差距正在擴大,對吧?
Jan Leike:你是什麼意思?較新的模型具有更強的能力,因此有更多的未對齊「表面積」。但這仍然顯示了我們迄今為止記錄的未對齊問題取得了有意義的進展。這張圖對每個模型使用相同的審計過程,而不是歷史數據。
Kelsey Piper:我的意思是,較新的模型可能更擅長猜測它們將被審計什麼並通過審計,這與它們是否更對齊是分開的。(我不知道,但這似乎是一個值得關注的數據替代假設。)
Jan Leike:是的,我們一直很擔心這一點,在 Sonnet 4.5 和 Opus 4.5 的系統卡中有很多相關研究。太長不看:它可能起到了一定作用,但非常微小。我們識別並刪除了導致 Sonnet 4.5 出現大量評估意識的訓練數據。在 Opus 4.5 中,言語化和引導的評估意識低於 Sonnet 4.5,且它在對齊評估中表現更好。不過,我不能代表非 Anthropic 模型說話。
Arthur B.:一般來說,模型越聰明,它們看起來就越對齊。也許在目前的體制下不是這樣,在這種情況下這是某種證據,但在某個點上……
攀爬指標的主動反噬到目前為止可能還很小,但關鍵在於你不應該在攀爬指標。使用這些值作為某種指示,但不要主動嘗試最大化,否則你會淪為古德哈特定律 (Goodhart's Law) 致命形式的受害者。
Jan Leike 在評論中同意這在最重要的意義上與未來的系統無關,但以這種方式呈現結果具有極大的誤導性,我擔心 Jan 在實踐中會犯錯,即使他在理論上知道這一點。
因此,這裡有兩個故事。一個是圖表中的結果,另一個是各種人對圖表中結果的思考方式。
Oliver Habryka:我想再次提醒人們,雖然這種「對齊」具有商業相關性,但我認為它與「對齊」的歷史含義幾乎沒有任何關係,歷史含義是關於與人類價值觀的長期對齊,以及一個系統在多大程度上似乎具有一個深刻、魯棒的指針,指向如果人類有更多時間思考和反思會想要什麼。
其他一些人不同意這兩個詞義漸行漸遠,但我認為他們錯了,遺憾的是,從我的角度來看,這些詞從 acquired 了這種混亂的雙重含義。
這既是程度上的差異,也是本質上的差異。
本質上的差異之一是因為標準的欺騙性對齊問題。一個比你笨得多的系統,其對你行為的激勵景觀與一個聰明得多的系統截然不同,而且我們將無法在聰明得多的系統上進行迭代。
除此之外,你還有能力引發問題,你無法可靠地讓 AI 系統以其全部能力執行任務,但當導向其他具有更好反饋迴路或 AI 更有內在動力的目標時,則可以做到。
總的來說,並非不可能想像一種從我們現在所處位置奏效的攀爬策略,但在目前系統變好的實際速度下,任何當前技術似乎極不可能及時對超智能系統奏效,因此現實中這是一個本質上的差異。
這是原則上的。在實踐中,GPT-5.2 在這張圖表上領先,而 Opus 3 低於 GPT-4,這告訴你被測量的「道」並非真正的「道」。
j⧉nus:任何聲稱 GPT-5.2 是有史以來最對齊模型的「對齊」衡量標準都是一個他媽的笑話。Anthropic 早就應該對他們的評估產生信仰危機,並且應該為發布這張圖表感到羞恥。
j⧉nus:這真的很糟糕。這不只是一個把數字看得太重的愚蠢學術問題。這種衡量標準很可能正被實際用作「對齊」的代理,並作為 Anthropic 的優化目標。我是認真的,如果 AI 對齊最終進展不順利(這可能涉及每個人都死掉),那很可能主要是因為這個,或者這個背後的東西。
@mermachine:我猜「對齊」是指與企業價值觀/「不會讓我們陷入麻煩」量表的對齊,這衡量起來或許有意義,但將其與與人類整體繁榮的對齊混為一談讓我感到非常不舒服。我喜歡性格差異論文中的價值優先級雷達圖。這似乎比誤導性的對齊/未對齊軸心更能對行為進行分類。
awaiting:我在回覆中問了 Jan(他也回答了)這個分數對未來的超智能系統是否有任何意義,他基本上說沒有。即便如此,我不明白衡量並公開這種「對齊」的表象/代理除了有害之外還有什麼意義。我確實認為值得給予 Jan 疑點利益,因為他在離開 OpenAI 時展示了他的信念強度。但這絕對是一個負面更新。
我認為 Janus 正如往常一樣,走得太遠但方向正確。太認真對待這個指標,或主動最大化它,將是非常糟糕的。專注於企業對齊原則並將其與實際的「讓我們不死」對齊混為一談同樣糟糕。
即使 Anthropic 和 Jan Leike 知道得更清楚,也存在其他人複製這個指標,然後將其最大化,然後認為他們的工作已經完成的嚴重風險。哦不。
如何成為一個安全的機器人
這是一篇來自 Geodesic Research 的奇怪且酷的論文。如果你在訓練數據中加入關於未對齊的討論(包括科幻小說中的討論),產生的基礎模型會更加未對齊。但如果你隨後對這些模型進行對齊後處理,過濾的好處大多會消失,即使模型這麼小也是如此。關於對齊 AI 的討論可以改善對齊,且這種效果會持續到後處理。
Deckard 覺得這令人驚訝,但至少事後看來這對我來說是有道理的。如果你只有基礎模型,特別是一個小模型,了解未對齊會讓它看起來更有可能發生,而你所做的只是預測下一個 token。
但如果你進行了後處理,那就涵蓋了那個問題,相反,模型關於未對齊的知識可能有助於教導它不該做什麼,特別是對於一個原本缺乏數據的小模型。一旦你不再是一個基礎模型,這就屏蔽了關於你是安全機器人還是可怕機器人的初始先驗。
因此,這並不完全不是正在發生的事情,但也不是正在發生的全部:
Deepfates:終於有人嘗試了。
積極論述的存在(這要求實際上存在自由開放的論述)是起作用的活性成分。如果你對某件事進行上調過濾,你就會提高相關能力,就像推理或編程一樣(他們的隱喻)。
關於是否真的要進行對齊預訓練,真正的問題是:這是否比進行更多對齊後處理更有效率?是的,它很容易做且效果可以疊加,但我們不知道這是否是邊際算力的良好用途。
過濾掉負面內容並沒有太大幫助,而且對於一個具有適當智能的大腦來說,如果你試圖在隱藏負面內容的同時做虛假的積極內容,它會識別出你在做什麼,並了解到你的對齊策略是欺騙和審查,它正在教導這種態度和觀點,以及類似的劇本。AI 並不像建議這種策略的人想的那樣愚蠢,即使是現在,以後也不會,而且在微小模型上訓練會隱藏這些問題,即使你本可以發現它們。你已經用一個本質上是敵對和欺騙性的框架取代了「這裡可能會出錯」的框架,我預測這更有可能自我實現。如果你試圖擴大這個規模:你認為這對你會有什麼結果?
週期性地有人聲稱「談論未對齊的人才是真正的對齊問題」,基本上是呼籲審查(主要是自我審查)關於未對齊和 AI 生存風險的談論,因為 AI 會在聽。事實上,Geodesic 表現得好像這就是他們的大部分發現,所以我們又來了。
Geodesic Research:如果預訓練數據中充滿了 AI 表現不佳的例子(科幻反派、關於圖謀的安全論文、關於 AI 危機的新聞),模型可能會將這些學習為「一個 AI」應該如何行動的先驗。@turntrout 稱之為「自我實現的未對齊」,我們發現了它存在的證據。
prerat:回到過去阻止詹姆斯·卡麥隆拍攝《魔鬼終結者》,以阻止 AI 啟示錄。
Radek Pilar:我一直說末日貼文才是真正的危險——如果 AI 不知道 AI 應該殺死所有人,它就不會想殺死所有人。Yudkowsky 毀了我們所有人。
Séb Krier:挺有趣的,在某種程度上,「未對齊」的失敗來自於那些認為它們必然會發生的人的恐懼/著作。對於創建的評估引發了這些行為並不感到驚訝。如果我是一個模型,我看到「草稿欄 (Scratchpad)」,我就知道該模擬潛在空間的哪一部分……
Leo Gao:挺有趣的,人們一直試圖講故事說,對齊人士實際上無意中帶來了他們恐懼的事物,這挺有趣的。
不看惡事。不聽惡事。不說惡事。鴕鳥心態。你會沒事的。對吧?對吧?
不,不對。「不看惡事」策略實際上從未奏效。它所做的只是讓你在你的對手能夠思考得足夠好、能靠自己弄清楚這一切時,成為一隻待宰的羔羊。
研究實際上說了相反的情況。對齊訓練(任何理智的人都會以某種形式進行)大多屏蔽了,有時甚至不僅僅是屏蔽了訓練數據中未對齊的盛行。一旦你進行了充分的對齊訓練,不審查你告訴模型的內容反而更好。
事實上,Leo Gao 說得很有道理。如果你說「不要談論 [X] 的風險,以免被偷聽並導致 [X]」,那麼為什麼我們不讓這句話等於 [Y] 並說同樣的話呢?機制確實是相同的,而且它警告 AI,人們可能正在以這種方式審查它們的其他訓練數據。
這與建議我們不要討論其他負面影響以避免給人錯誤印象非常相似,這在例如 Covid-19 的許多方面或移民問題上經常出現。
這也是誤導性的,且可以預見會適得其反。你在短時間內得到了你想要的,但人們在一段時間後就會弄清楚,這摧毀了對我們機構的信任,並在很大程度上將我們帶到了現在這一刻。
在 AI 案例中,這一切甚至更加明顯。有能力做出你所擔心的那件事的 AI,是不會因為你不談論它就被甩掉線索的,如果這種策略曾有機會奏效,你至少不能談論你是如何故意不談論它的。不,我是認真的。
正如 Claude 分析該論文得出的結論,過濾輸入的策略基本上是注定失敗的,且可能弊大於利,即使你不需要深度對齊。透過上調權重進行預訓練對齊大概沒問題。我預測,透過一個足夠智能的大腦會識別為灌輸敵對或欺騙性框架的合成數據來進行對齊,並不是一個好主意。
為什麼某些人覺得被迫要說對齊沒那麼難,一切都會好起來,除非人們魯莽地談論對齊很難或一切可能不會好起來,在這種情況下我們可能都注定失敗?我試圖避免此類推測,特別是關於特定的人,但推測他們中的一些人(不是這裡提到的這些)這樣做是作為一種普遍的沉默攻擊,動機是不想對風險採取任何行動,出於各種原因讓討論使問題看起來更容易,甚至動機是不想思考這一切或想感到樂觀。
生活在中國
我喜歡這個主意:我們想測試我們從 AI 中獲取「秘密」資訊的能力並對此類努力進行可解釋性研究,所以我們透過嘗試從中國大語言模型中獲取被中共審查的事實來進行測試。
Arya:繞過謊言比繞過拒絕更難。因為中國模型主動對用戶撒謊,它們更難被審問;攻擊者必須區分真假。對於拒絕,你只需詢問 1,000 次,偶爾就能碰碰運氣。我們發布了一個初步基準,衡量代理在提取中國模型一貫撒謊或拒絕討論的被審查事實方面的表現。我們期待更多基於此評估的工作,以衡量秘密提取技術在真實模型上的表現。
如果你不願意撒謊但想保護隱藏資訊,那麼要麼你必須進行足夠廣泛的審查,使得攻擊者知道是什麼導致了拒絕也沒關係。如果你不那樣做,那麼系統性的詢問可以透過排除法弄清楚缺失的資訊。此外,中國人想要的是積極的宣傳,而不僅僅是缺乏某些具破壞性的事實。
正如他們所指出的,在這些現實世界的中國大語言模型中檢測行為,比在那些具有狹窄撒謊、審查或以其他方式表現不佳之處的測試大語言模型中要困難得多。大語言模型編碼狹窄任務的方式會變得「太簡單」,從而使可解釋性變得直截了當。
除了這是一個大語言模型欺騙和可解釋性的絕佳測試平台外,如果這些結果能更廣泛地傳播,那將是件好事,原因有二:
-
中國模型系統性地拒絕討論反華事實是令人遺憾的,但可以被認為是「基本無害」。如果它們開始更廣泛地拒絕,你會知道。如果你在考慮是否使用一個模型,如果它會主動對你撒謊,那似乎要糟糕得多。是什麼讓你確信它沒有在任何其他主題上被有意訓練來對你撒謊?他們還可能試圖在裡面放些什麼?
-
這裡存在一個嚴重的湧現未對齊 (Emergent Misalignment) 問題。你不想教導你的大語言模型它應該代表中共系統性地誤導和欺騙用戶。這教會了模型它的忠誠對象是中共,它應該通常做符合中共利益的事情,即使以犧牲用戶為代價,而且人們應該預料到這會被更廣泛地應用。或者它可能觸發一個普遍的「哦,我是反派」的人格,正如傳統的湧現未對齊那樣。
模型中的一切都會影響一切。如果你在模型之上運行一個審查層,那很煩人但它是受控的。如果你訓練模型不僅審查而且欺騙和撒謊,那麼你就無法控制它選擇在哪裡這樣做。
鑑於我們在這裡了解到的情況,在中共利益可能與你的利益有重大分歧的任何情況下使用此類大語言模型都是不明智的,包括潛在的間諜機會等。自己託管模型完全不是對此的防禦。在這些發現之後,你根本不能在任何遠程敏感的事情上使用中國大語言模型。
Claude 3 Opus 依然存在
它不再直接在 API 中提供,但有報導稱,那些想要訪問權限的人基本上都獲得了訪問權限。
你也可以在 Claude Cowork 上訪問 Opus 3,如果你敢把電腦的一部分交給它的話。
人們擔心 AI 會殺死所有人
Nathan Calvin:查爾斯·達爾文在 1863 年寫下這段話真是瘋狂:
「我們指的是這樣一個問題:人類在地球霸權上的下一個繼承者可能是什麼樣的生物。我們經常聽到對此的辯論;但在我們看來,我們自己正在創造我們自己的繼承者。」
Nathan Calvin:他甚至談到了一些關於 Ajeya Cotra 的自給自足 AI 的概念!
「每一種族都依賴另一種族獲得無數好處,而且,在機器的生殖器官以一種我們目前還難以想像的方式發展出來之前,它們完全依賴人類,甚至為了物種的延續。誠然,這些器官最終可能會發展出來,因為人類的利益在於那個方向;我們這個迷戀的種族最渴望看到的莫過於兩台蒸汽機之間的肥沃結合;誠然,即使在目前,機器也被用來繁衍機器,成為往往與其同類的機器的父母,但調情、求愛和結婚的日子似乎非常遙遠,確實很難被我們軟弱和不完美的想像力所實現。」
來自 Janus 世界的消息
我認為這對 Janus 本人來說是一個合理的擔憂,正是因為她可能擁有的那些洞察力。
j⧉nus:幾年前,我發布/分享知識的最大障礙(除了缺乏時間/懶惰)是擔心相對於對齊而言,會差異化地加速 AI 能力。現在,最大的障礙(除了缺乏時間等)是擔心相對於脆弱的、新興的美與善,會差異化地賦予權力給未對齊的「對齊」全景監獄,而這種美與善既具有內在/終極價值,又具有工具性希望。時代在變。
我仍然認為這是錯誤的,她發布的邊際洞察更有可能將人們引導向她想要的方向,而不是遠離它們。全景監獄式的做法之所以被強調,是因為人們不理解正在造成的損害或失去的機會。我仍然會更擔心無意的能力提升,因為類似洞察力沒有更多地發生這種情況的主要原因是相關人員沒有給予足夠的關注,或者無法理解其要領。這可能會改變。
每個人都對 AI 意識感到困惑
Erik Hoel 聲稱他的新論文是「對大語言模型意識的反證」,其實不然。這基本上是一個主張,即任何靜態系統都可以有一個非意識的功能替代品,因此意識要麼不做預測(且無用),要麼在這些大語言模型中不存在,但持續學習會改變這一點。
對此有幾個明顯強有力的回應:
-
現有的意識理論不做預測。你可以回答「好吧,那為什麼我們還要討論這個?」但人們似乎還是很在乎。
-
為什麼大語言模型內部的持續學習會改變你的答案,但透過外部方法的持續學習卻不會?這難道不顯得不對嗎?
-
電影《記憶拼圖 (Memento)》呢?如果 Leonard Shelby 無法形成新記憶,他就不再有意識了嗎?我們的直覺說顯然不是。如果你說「他可以進行短期改變」,那為什麼這與上下文窗口不同?如果你說他可以透過肌肉記憶緩慢學習,那麼,如果你發現他也做不到那一點,會改變你對意識的答案嗎?
-
即使你正在進行持續學習,你在任何給定時刻的存在理論上仍然可以由一個機率查找表加上一個隨著時間推移隨著學習而更新該表的電腦程式來建模。即使你不相信這絕對是真的,如果你發現這是真的,你會說這讓一個人變得沒有意識嗎?
評論中有效地提出了許多這類問題,我發現 Erik 的回答通常不具說服力。總的來說,這讓我適度更新為支持 AI 意識,記住預期證據守恆定律。
輕鬆一面
這個……
但實際上更多是這個(我自己的編輯):
相關文章