2024 年值得關注的 LLM 研究論文
這篇文章涵蓋了 2024 年 12 篇具影響力的 AI 研究論文,範圍從混合專家模型到新的大型語言模型精度擴展定律。
2024 年值得關注的 AI 研究論文(第一部分)
1 月至 6 月的六篇具影響力 AI 論文
為了開啟新的一年,我終於完成了這篇「2024 年 AI 研究亮點」的文章草稿。內容涵蓋了從混合專家模型(Mixture-of-Experts)到新的大型語言模型(LLM)精度擴展定律等各種主題。
回顧 2024 年所有主要的研究亮點可能需要寫成一整本書。即便對於這樣一個進展神速的領域來說,今年也是產量異常豐沛的一年。為了保持內容簡潔,我決定今年將重點完全放在 LLM 研究上。但即便如此,要如何從如此精彩紛呈的一年中挑選出論文子集呢?我想出最簡單的方法是每個月重點介紹一篇論文:從 2024 年 1 月到 12 月。
因此,在這篇文章中,我將分享我個人認為非常迷人、具影響力,或者理想情況下兩者兼具的研究論文。不過請注意,這篇文章只是第一部分,重點關注 2024 年上半年(1 月至 6 月)。本系列的第二部分(涵蓋 7 月至 12 月)將於 1 月晚些時候分享。
誠然,選擇標準是主觀的,基於今年令我印象深刻的內容。我也力求多樣性,因此不全是關於 LLM 模型的發布。
如果您正在尋找更廣泛的 AI 研究論文列表,歡迎查看我之前的文章(LLM Research Papers: The 2024 List)。
對於讀過我前一篇文章的讀者,很高興能告訴大家,我已經感覺好多了,正在緩慢但穩定地康復中!我也想對所有的祝福和支持表示衷心的感謝。這對我來說意義重大,幫助我度過了一些艱難的日子!
新年快樂,閱讀愉快!
1. 一月:Mixtral 的混合專家方法
在 2024 年 1 月剛開始幾天,Mistral AI 團隊就分享了 Mixtral of Experts 論文(2024 年 1 月 8 日),其中描述了 Mixtral 8x7B,這是一個稀疏混合專家(Sparse Mixture of Experts, SMoE)模型。
這篇論文和模型在當時都非常有影響力,因為 Mixtral 8x7B 是(首批)權重開放的 MoE LLM 之一,且性能令人印象深刻:它在各種基準測試中超越了 Llama 2 70B 和 GPT-3.5。
1.1 理解 MoE 模型
MoE(混合專家模型)是一種集成模型,它在類 GPT 的解碼器架構中結合了多個較小的「專家」子網絡。據說每個子網絡負責處理不同類型的任務,或者更具體地說,處理不同的標記(tokens)。這裡的想法是,通過使用多個較小的子網絡而不是一個大型網絡,MoE 旨在更有效地分配計算資源。
特別是在 Mixtral 8x7B 中,其做法是將 Transformer 架構中的每個前饋模塊(feed-forward module)替換為 8 個專家層,如下圖所示。

「稀疏混合專家」中的「稀疏」是指在任何給定時間,只有一部分專家層(在 Mixtral 8x7B 中通常是 8 個中的 1 或 2 個)被主動用於處理標記。
如上圖所示,子網絡取代了 LLM 中的前饋模塊。前饋模塊本質上是一個多層感知器。在類 PyTorch 的偽代碼中,它基本上看起來像這樣:
此外,還有一個路由器模塊(Router module,也稱為門控網絡),它將每個標記嵌入(token embeddings)重新定向到 8 個專家前饋模塊,其中一次只有一部分專家是活躍的。
由於本文還有 11 篇論文要介紹,我想簡短地描述 Mixtral 模型。不過,您可以在我之前的文章《Model Merging, Mixtures of Experts, and Towards Smaller LLMs》中找到更多細節。
1.2 MoE 模型在今日的相關性
在年初,我原以為開放權重的 MoE 模型會比現在更受歡迎且被更廣泛地使用。雖然它們並非無關緊要,但許多尖端模型仍然依賴於稠密(傳統)LLM 而非 MoE,例如 Llama 3、Qwen 2.5、Gemma 2 等。然而,當然不可能知道像 GPT-4、Gemini 和 Claude 這樣的私有架構是基於什麼;它們底層也可能正在使用 MoE。
無論如何,MoE 架構仍然具有相關性,特別是因為它們提供了一種通過僅為每個輸入激活模型參數子集來有效擴展大型語言模型的方法,從而在不犧牲模型容量的情況下降低計算成本。
順便提一下,在寫完這篇文章後,12 月份驚喜發布了性能非常出色的 DeepSeek-V3 模型,它就使用了 MoE 架構。所以,是的,MoE 繼續保持著高度的相關性!
2. 二月:權重分解的 LoRA (DoRA)
如果您正在微調開放權重的 LLM,很有可能您在某個時候使用過低秩自適應(LoRA),這是一種參數高效的 LLM 微調方法。
如果您對 LoRA 還很陌生,我曾寫過一篇關於《Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation)》的文章,您可能會覺得很有幫助,而且在我的《Build A Large Language Model (From Scratch)》一書的附錄 D 中有從零開始的代碼實現。
由於 LoRA 是一種如此受歡迎且廣泛使用的方法,而且我在實現和嘗試新變體時獲得了許多樂趣,因此我對二月份的選擇是 Liu 等人撰寫的《DoRA: Weight-Decomposed Low-Rank Adaptation》(2024 年 2 月)。
2.1 LoRA 回顧
在介紹 DoRA 之前,先快速複習一下 LoRA:
全量微調(Full finetuning)通過計算一個大型權重更新矩陣 ΔW 來更新 LLM 中的每個大型權重矩陣 W。LoRA 將 ΔW 近似為兩個較小矩陣 A 和 B 的乘積。因此,我們得到的不是 W + ΔW,而是 W + A.B。這大大減少了計算和內存開銷。
下圖並排展示了全量微調(左)和 LoRA(右)的公式。

2.2 從 LoRA 到 DoRA
在《DoRA: Weight-Decomposed Low-Rank Adaptation》(2024 年 2 月)中,Liu 等人擴展了 LoRA,首先將預訓練權重矩陣分解為兩個部分:幅度向量 m(magnitude vector)和方向矩陣 V(directional matrix)。這種分解源於任何向量都可以由其長度(幅度)和方向(方位)來表示的想法,這裡我們將其應用於權重矩陣的每個列向量。一旦我們有了 m 和 V,DoRA 僅對方向矩陣 V 應用 LoRA 風格的低秩更新,同時允許單獨訓練幅度向量 m。

這種兩步走的方法賦予了 DoRA 比標準 LoRA 更大的靈活性。DoRA 不像 LoRA 那樣傾向於均勻地縮放幅度和方向,而是可以在不一定增加幅度的情況下進行細微的方向調整。結果是性能和魯棒性的提升,因為 DoRA 即使在使用較少參數的情況下也能超越 LoRA,並且對秩(rank)的選擇不那麼敏感。
同樣,由於還有 10 篇論文要介紹,我將保持本節簡短,但如果您對更多細節感興趣,我在今年早些時候專門為此方法寫了一篇文章:《Improving LoRA: Implementing Weight-Decomposed Low-Rank Adaptation (DoRA) from Scratch》。
2.3 LoRA 及類 LoRA 方法的未來
DoRA 是對原始 LoRA 方法的一個小而合乎邏輯的改進。雖然它尚未被廣泛採用,但它增加的複雜性極小,值得在您下次微調 LLM 時考慮。總的來說,我預計 LoRA 和類似方法將繼續流行。例如,Apple 最近在其《Apple Intelligence Foundation Language Models》論文中提到,他們使用 LoRA 進行設備端 LLM 的任務專業化。
Ahead of AI 是一份讀者支持的刊物。要接收新文章並支持我的工作,請考慮成為免費或付費訂閱者。
3. 三月:持續預訓練 LLM 的技巧
據我所知,指令微調(instruction-finetuning)是 LLM 從業者最受歡迎的微調形式。其目標是讓公開可用的 LLM 更好地遵循指令,或在子集或新指令上使這些 LLM 專業化。
然而,當涉及到吸收新知識時,持續預訓練(continued pretraining,有時也稱為 continually pretraining)才是正確的做法。
在本節中,我想簡要總結一下 Ibrahim 等人撰寫的、令人耳目一新且簡單明瞭的論文《Simple and Scalable Strategies to Continually Pre-train Large Language Models》(2024 年 3 月)。
3.1 簡單的技術也有效
這篇長達 24 頁的《Continually Pre-train Large Language Models》論文報告了大量的實驗,並附帶了無數圖表,這在今天的標準下是非常詳盡的。
成功應用持續預訓練的主要技巧是什麼?
-
簡單地重新預熱(re-warming)和重新衰減(re-decaying)學習率。
-
在新數據集中加入一小部分(例如 5%)原始預訓練數據,以防止災難性遺忘。請注意,更小的比例(如 0.5% 和 1%)也是有效的。
關於第 1 點(重新預熱和重新衰減)更具體地說,這意味著我們採用與 LLM 最初預訓練階段完全相同的學習率排程,如下圖所示。

據我所知,重新預熱和重新衰減,以及在新數據中加入原始預訓練數據,或多或少是常識。然而,我非常欣賞研究人員花時間在這份非常詳細的 24 頁報告中正式測試了這種方法。
如果您對更多細節感興趣,我在之前的文章《Tips for LLM Pretraining and Evaluating Reward Models》中更深入地討論了這篇論文。
3.2 這些簡單的技術會繼續有效嗎?
我沒有理由相信這些方法在未來的 LLM 中不會繼續有效。然而,重要的是要注意,預訓練流水線在最近幾個月變得更加複雜,由多個階段組成,包括短上下文和長上下文預訓練。(我在《New LLM Pre-training and Post-training Paradigms》中寫了更多相關內容)。
因此,為了獲得最佳結果,本文建議的配方在某些情況下可能需要進行微調。
4. 四月:LLM 對齊該用 DPO 還是 PPO,還是兩者兼而有之?
四月是一個艱難的選擇。例如,Kolmogorov-Arnold Networks(KAN)在那個月掀起了巨大的波瀾。但據我所知,興奮感很快就平息了。這可能是因為它們的理論保證難以在實踐中實現,缺乏具競爭力的結果或基準,且其他架構的可擴展性要好得多。
因此,我對四月份的選擇是一篇更具實踐意義的論文:Xu 等人撰寫的《Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study》(2024 年 4 月)。
4.1 RLHF-PPO 與 DPO:它們是什麼?
在總結論文本身之前,這裡先概述一下近端策略優化(PPO)和直接偏好優化(DPO),這兩者都是通過人類反饋強化學習(RLHF)對齊 LLM 的流行方法。RLHF 是對齊 LLM 與人類偏好的首選方法,可提高其回答的質量和安全性。

傳統上,RLHF-PPO 一直是為 InstructGPT 和 ChatGPT 等模型和平台訓練 LLM 的關鍵步驟。然而,DPO 由於其簡單性和有效性,從去年開始受到關注。與 RLHF-PPO 相比,DPO 不需要單獨的獎勵模型。相反,它直接使用類分類目標來更新 LLM。現在許多 LLM 都利用了 DPO,儘管仍缺乏與 PPO 的全面比較。
以下是我在今年早些時候開發並分享的兩個關於 RLHF 和 DPO 的資源:
《LLM Training: RLHF and Its Alternatives》
《Direct Preference Optimization (DPO) for LLM Alignment (From Scratch)》
4.2 PPO 通常優於 DPO
《Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study》是一篇寫得很好的論文,包含大量的實驗和結果。關鍵結論是 PPO 往往優於 DPO,且 DPO 在處理分佈外(out-of-distribution)數據時表現較差。
這裡的分佈外數據是指語言模型之前是在與 DPO 所用偏好數據不同的指令數據上訓練的(通過監督微調)。例如,一個模型可能先在通用的 Alpaca 數據集上訓練,然後在不同的帶偏好標籤的數據集上進行 DPO 微調。(然而,在這種分佈外數據上改進 DPO 的一種方法是先使用偏好數據集進行監督指令微調步驟,然後再進行 DPO 微調。)
主要發現總結在下圖中。

4.3 PPO 和 DPO 在今天如何被使用?
當涉及到最終 LLM 的原始建模性能時,PPO 可能略佔優勢。然而,DPO 更容易實現,且計算效率更高(畢竟您不必訓練和使用單獨的獎勵模型)。因此,據我所知,DPO 在實踐中的應用也比 RLHF-PPO 廣泛得多。
一個有趣的例子是 Meta AI 的 Llama 模型。雖然 Llama 2 是使用 RLHF-PPO 訓練的,但較新的 Llama 3 模型則使用了 DPO。
有趣的是,現在甚至有些模型同時使用 PPO 和 DPO。最近的例子包括 Apple 的基礎模型和 Allen AI 的 Tulu 3。
5. 五月:LoRA 學得更少,忘得也更少
我發現今年另一篇關於 LoRA 的論文特別有趣(我保證這是這 12 篇選文中最後一篇 LoRA 論文!)。我不會稱其為突破性的,但我真的很喜歡它,因為它正式化了一些關於使用(和不使用)LoRA 微調 LLM 的常識:Biderman 等人撰寫的《LoRA Learns Less and Forgets Less》(2024 年 5 月)。
《LoRA Learns Less and Forgets Less》是一項實證研究,比較了大型語言模型(LLM)上的低秩自適應(LoRA)與全量微調,重點關注兩個領域(編程和數學)和兩項任務(指令微調和持續預訓練)。如果您在繼續之前需要複習一下 LoRA,請查看上面的二月份章節。
5.1 LoRA 學得更少
《LoRA Learns Less and Forgets Less》研究表明,LoRA 的學習量明顯少於全量微調,特別是在需要獲取新知識的任務(如編碼)中。當僅進行指令微調時,差距較小。這表明,在新數據上進行預訓練(學習新知識)從全量微調中獲益更多,而將預訓練模型轉換為指令遵循者則不然。

不過還有一些細微差別。例如,對於數學任務,LoRA 和全量微調之間的差異會縮小。這可能是因為 LLM 對數學問題更熟悉,它們在預訓練期間可能遇到過類似的問題。相比之下,編碼涉及一個更獨特的領域,需要更多新知識。因此,新任務距離模型的預訓練數據越遠,全量微調在學習能力方面的優勢就越明顯。
5.2 LoRA 忘得更少
當檢查丟失了多少先前獲得的知識時,LoRA 始終忘得更少。當適應遠離源領域的數據(例如編碼)時,這一點尤為明顯。在編碼任務中,全量微調會導致嚴重的遺忘,而 LoRA 則保留了更多原始能力。在數學方面,由於模型原始知識已經與新任務較為接近,差異就不那麼顯著。

5.3 LoRA 的權衡
總體而言,這是一個權衡:全量微調更適合從更遠的領域吸收新知識,但會導致對先前學習任務的更多遺忘。LoRA 通過更改較少的參數,學習的新信息較少,但保留了更多原始能力。
5.4 未來的 LLM 微調方法
該研究主要將 LoRA 與全量微調進行比較。在實踐中,LoRA 受到歡迎是因為它比全量微調的資源效率高得多。在許多情況下,由於硬件限制,全量微調根本不可行。此外,如果您只需要處理專業化應用,單靠 LoRA 可能就足夠了。由於 LoRA 適配器可以與基礎 LLM 分開存儲,因此在添加新能力的同時很容易保留原始能力。此外,也可以結合這兩種方法,使用全量微調進行知識更新,並使用 LoRA 進行後續的專業化。
簡而言之,我認為這兩種方法在未來一年(或幾年)內都將繼續保持高度相關性。這更多是關於針對手頭的任務使用正確的方法。
Ahead of AI 是一份讀者支持的刊物。要接收新文章並支持我的工作,請考慮成為免費或付費訂閱者。
6. 六月:擁有 15 兆標記的 FineWeb 數據集
Penedo 等人撰寫的《The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale》(2024 年 6 月)論文描述了一個為 LLM 創建的 15 兆(15 trillion)標記數據集,並將其公開發布,包括下載數據集的鏈接和用於重現數據集準備步驟的代碼庫(datatrove/examples/fineweb.py)。
6.1 與其他數據集的比較
既然已經有其他幾個用於 LLM 預訓練的大型數據集,這個有什麼特別之處?其他數據集相對較小:RefinedWeb(500B 標記)、C4(172B 標記)、基於 Common Crawl 的 Dolma 1.6(3T 標記)和 1.7(1.2T 標記)、The Pile(340B 標記)、SlimPajama(627B 標記)、RedPajama 的去重變體(20T 標記)、Matrix 的英文 CommonCrawl 部分(1.3T 標記)、英文 CC-100(70B 標記)、Colossal-OSCAR(850B 標記)。
例如,約 3600 億個標記僅適用於小型 LLM(根據 Chinchilla 擴展定律,例如 1.7 B 模型)。另一方面,根據 Chinchilla 擴展定律,FineWeb 數據集中的 15 兆個標記對於高達 5000 億參數的模型來說應該是理想的。(請注意,RedPajama 包含 20 兆個標記,但研究人員發現,由於應用了不同的過濾規則,在 RedPajama 上訓練的模型質量低於 FineWeb。)

簡而言之,FineWeb 數據集(僅限英文)使研究人員和從業者在理論上訓練大規模 LLM 成為可能。(旁註:8B、70B 和 405B 規模的 Llama 3 模型也是在 15 兆個標記上訓練的,但 Meta AI 的訓練數據集並未公開。)
6.2 有原則的數據集開發
此外,論文還包含了有原則的消融研究,以及關於如何開發和應用過濾規則以得出 FineWeb 數據集(從 CommonCrawl 網絡語料庫開始)的見解。簡而言之,對於他們嘗試的每條過濾規則,他們都會從原始數據和過濾後的數據中提取 3600 億個標記的隨機樣本,然後訓練一個小型 17.1 億參數的類 Llama 模型,根據模型在 HellaSwag、ARC、MMLU 等標準基準測試上的表現,來查看該過濾規則是否有益。
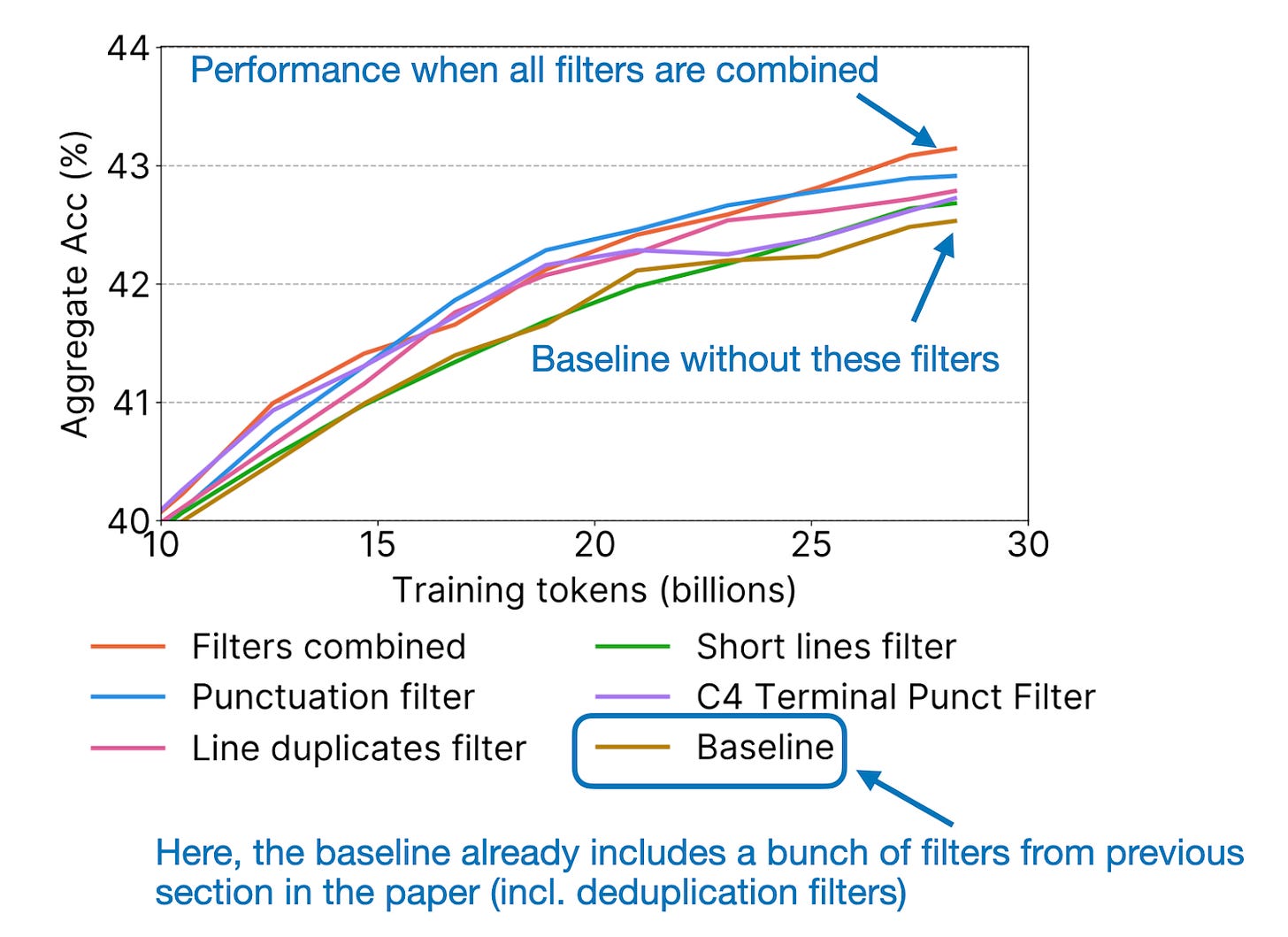
6.3 FineWeb 在今日的相關性
總體而言,雖然預訓練數十億參數的 LLM 可能仍然超出了大多數研究實驗室和公司的能力範圍,但這個數據集是朝著 LLM 研究和開發民主化邁出的實質性一步。總之,這篇論文代表了一次值得讚賞的努力,並為推進 LLM 預訓練引入了寶貴的公共資源。
七月至十二月
希望您覺得這些研究總結有用!由於我仍在從傷病中恢復,而且這篇文章本來就會過長,我決定將今年的回顧文章分為兩個部分。
第二部分(7 月至 12 月)實際上(對我個人而言)更加令人興奮,因為我將討論關於擴展定律、重現 O1 以及合成數據在 LLM 訓練中的作用等更近期的論文。此外,我還將分享我對 2025 年的看法以及我預期會出現的趨勢。敬請期待!
這本雜誌是我個人的熱情項目。對於那些希望支持我的人,請考慮購買一本我的《Build a Large Language Model (From Scratch)》書籍。(我有信心您會從這本書中獲益良多,因為它以其他地方找不到的詳細程度解釋了 LLM 的工作原理。)

如果您讀了這本書並有幾分鐘空閒時間,我會非常感激您能寫一段簡短的評論。這對我們作者幫助很大!
您的支持意義重大!謝謝!
相關文章