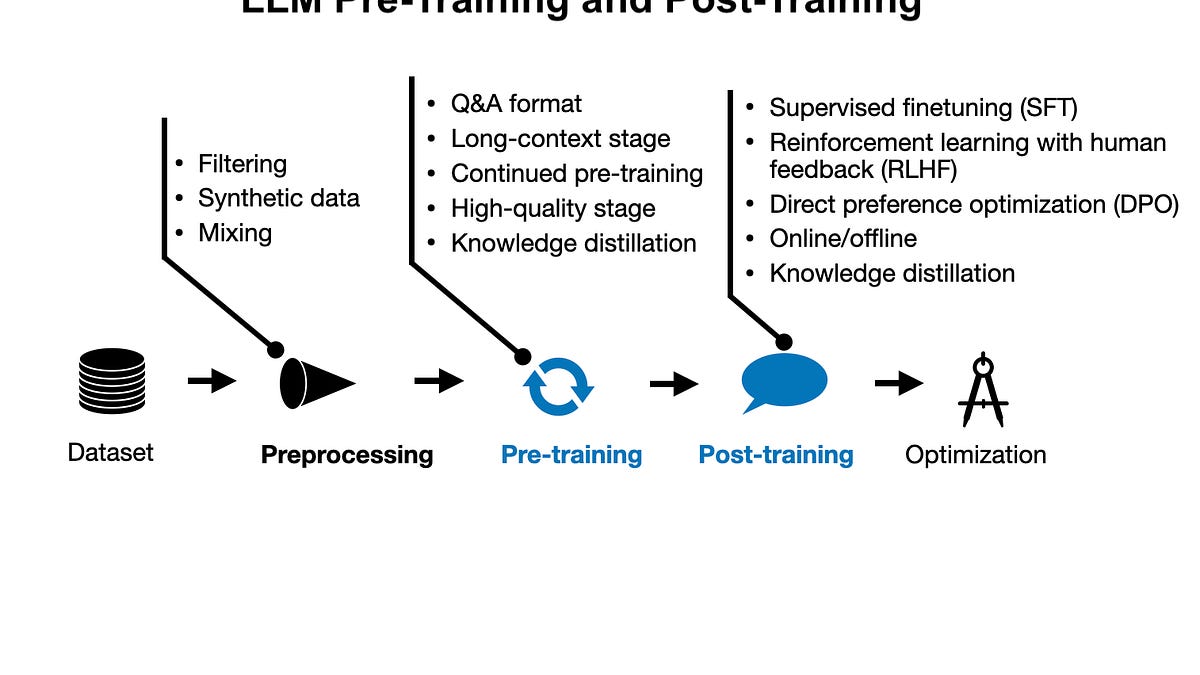
大型語言模型預訓練與後訓練的新範式
這篇文章透過分析 Qwen 2、Llama 3.1 和 Gemma 2 等頂尖模型的流程,探討了大型語言模型訓練方法的最新進展。我重點介紹了轉向複雜數據過濾、合成數據生成以及如直接偏好優化等對齊技術的趨勢。
新型 LLM 預訓練與微調範式
現代 LLM 訓練方式探析
大型語言模型(LLM)的發展走過了漫長的道路,從早期的 GPT 模型到如今我們擁有的複雜開源權重 LLM。最初,LLM 的訓練過程僅專注於預訓練(Pre-training),但此後已擴展到同時包含預訓練與微調(Post-training)。微調通常包括監督式指令微調(Supervised Instruction Fine-tuning)與對齊(Alignment),這因 ChatGPT 而普及。
自 ChatGPT 首次發布以來,訓練方法論不斷演進。在本文中,我將回顧預訓練與微調方法論的最新進展,特別是近幾個月取得的成果。

每月都有數百篇 LLM 論文提出新的技術與方法。然而,了解實踐中哪些方法真正有效的最佳方式之一,就是觀察最新頂尖模型的預訓練與微調流水線。幸運的是,過去幾個月發布了四款主要的新型 LLM,並附帶了相對詳細的技術報告。
在本文中,我將重點關注以下模型的預訓練與微調流水線:
- 阿里巴巴的 Qwen 2
- Apple Intelligence 基礎語言模型 (AFM)
- Google 的 Gemma 2
- Meta AI 的 Llama 3.1
這些模型按照其各自技術論文在 arXiv.org 上的發表日期排序,這也剛好符合其字母順序。
這篇文章是我在業餘時間和週末完成的熱情專案。如果您覺得它有價值並想支持我的工作,請考慮購買我的書並推薦給您的同事。您在 Amazon 上的評論也將不勝感激!

《Build a Large Language Model (from Scratch)》是一本高度專注的書,致力於在 PyTorch 中從頭開始編寫 LLM,涵蓋從預訓練到微調的所有內容——這可以說是真正理解 LLM 的最佳方式。
《Machine Learning Q and AI》對於那些已經熟悉基礎知識的人來說是一本好書;它深入探討了中級和高級概念,涵蓋深度神經網絡、視覺 Transformer、多 GPU 訓練範式、LLM 等。
《Machine Learning with PyTorch and Scikit-Learn》是機器學習、深度學習和 AI 的綜合指南,提供了理論與實踐代碼的平衡結合。它是任何領域新手的理想起點。
1. 阿里巴巴的 Qwen 2
讓我們從 Qwen 2 開始,這是一個非常強大的 LLM 模型系列,可與其他主要 LLM 競爭。然而,出於某種原因,它的受歡迎程度低於 Meta AI、微軟和 Google 的開源權重模型。
1.1 Qwen 2 概覽
在查看 Qwen 2 技術報告中討論的預訓練與微調方法之前,讓我們簡要總結一些核心規格。
Qwen 2 模型有 5 種版本。有 4 個常規(稠密)LLM,參數大小分別為 5 億、15 億、70 億和 720 億。此外,還有一個擁有 570 億參數的混合專家(Mixture-of-Experts)模型,其中同時激活 140 億參數。(由於架構細節不是本次重點,我不會過多深入混合專家模型;簡而言之,這與 Mistral AI 的 Mixtral 類似,只是它有更多激活的專家。有關高層次概覽,請參閱我的《模型合併、混合專家與邁向更小 LLM》文章中的 Mixtral 架構部分。)
Qwen 2 LLM 的突出特點之一是其在 30 種語言中良好的多語言能力。它們還擁有驚人的 151,642 個標記(token)詞彙量(作為參考,Llama 2 使用 32k 詞彙量,Llama 3.1 使用 128k 詞彙量);根據經驗,將詞彙量增加 2 倍會減少 2 倍的輸入標記數量,因此我們可以在相同的輸入中放入更多文本。此外,這對於涵蓋標準英語詞彙之外的多語言數據和代碼特別有幫助。
以下是與稍後涵蓋的其他 LLM 的簡要 MMLU 基準測試比較。(請注意,MMLU 是一個多選基準測試,因此有其局限性;儘管如此,它仍然是報告 LLM 性能最流行的方法之一。)

(如果您對 MMLU 還不熟悉,我在最近的演講第 46:05 分鐘簡要討論過它。)
1.2 Qwen 2 預訓練
Qwen 2 團隊在 7 兆(trillion)個訓練標記上訓練了 15 億、70 億和 720 億參數的模型,這是一個合理的規模。相比之下,Llama 2 模型在 2 兆標記上訓練,而 Llama 3.1 模型在 15 兆標記上訓練。
有趣的是,5 億參數的模型是在 12 兆標記上訓練的。然而,研究人員沒有在更大的 12 兆標記數據集上訓練其他模型,因為他們在訓練期間沒有觀察到任何改進,且額外的計算成本並不合理。
重點領域之一是改進數據過濾流水線以移除低質量數據,並增強數據混合以增加數據多樣性——這是我們稍後檢查其他模型時會再次提到的主題。
有趣的是,他們還使用 Qwen 模型(雖然他們沒有具體說明細節,但我假設是指前一代 Qwen 模型)來合成額外的預訓練數據。預訓練還涉及「多任務指令數據……以增強上下文學習和指令遵循能力」。
此外,他們分兩個階段進行訓練:常規預訓練,隨後是長上下文訓練。後者在預訓練的最後階段使用「高質量、長篇數據」將上下文長度從 4,096 增加到 32,768 個標記。

(遺憾的是,技術報告的另一個主題是數據集細節稀缺,因此如果我的寫作看起來不夠詳細,那是因為缺乏公開信息。)
1.3 Qwen 2 微調
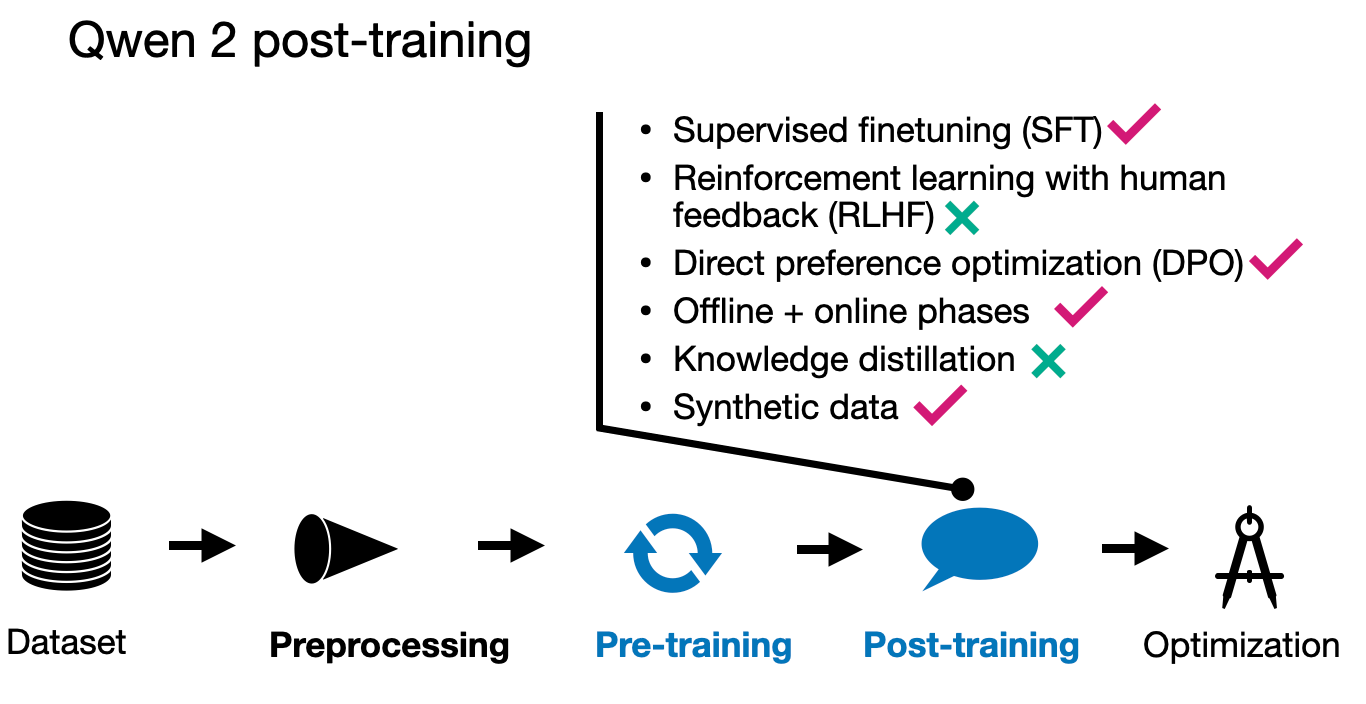
Qwen 2 團隊採用了流行的兩階段微調方法論,首先是監督式指令微調(SFT),應用於 500,000 個範例,進行 2 個 epoch。此階段旨在優化模型在預定場景中的響應準確性。
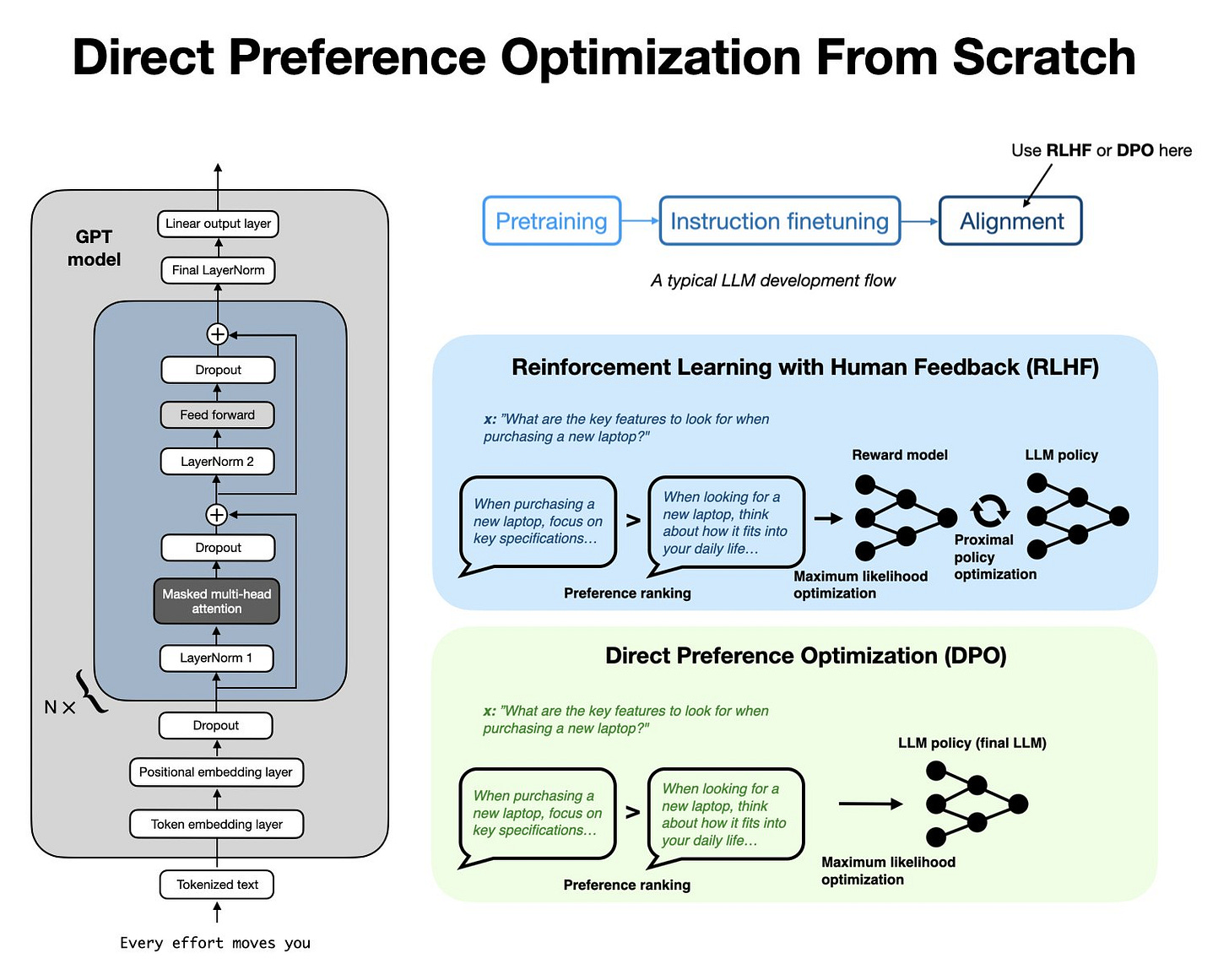
在 SFT 之後,他們使用直接偏好優化(DPO)使 LLM 與人類偏好對齊。(有趣的是,在他們的術語中這被稱為來自人類反饋的強化學習,RLHF。)正如我在幾週前的《LLM 預訓練與評估獎勵模型技巧》文章中所討論的,由於與其他方法(如帶有 PPO 的 RLHF)相比易於使用,SFT+DPO 方法似乎是目前最流行的偏好微調策略。(如果您想了解 DPO 的工作原理,我最近在這裡從頭開始實現了它。)
對齊階段本身也分 2 個階段進行。首先是在現有數據集上使用 DPO(離線階段)。其次,使用獎勵模型形成偏好對(在線)。在這裡,模型在訓練期間生成多個響應,獎勵模型在「實時」(即訓練期間)為優化步驟選擇首選響應。這通常也被稱為「拒絕採樣」(rejection sampling)。
對於數據集的構建,他們使用了現有的語料庫,輔以人工標註來確定 SFT 的目標響應,並識別 DPO 所需的首選和拒絕響應。研究人員還合成了人工標註的數據。
此外,該團隊使用 LLM 生成專門針對「高質量文學數據」的指令-響應對,以創建用於訓練的高質量問答對。
1.4 結論
Qwen 2 是一個能力相當強的模型,與早期世代的 Qwen 類似。在參加 2023 年 12 月的 NeurIPS LLM 效率挑戰賽時,我記得大多數獲勝方法都涉及 Qwen 模型。
關於 Qwen 2 的訓練流水線,突出之處在於合成數據已被用於預訓練和微調。此外,專注於數據集過濾(而非盡可能收集數據)是 LLM 訓練的顯著趨勢之一。在這裡,我想說,越多越好,但前提是它必須符合一定的質量標準。
從頭開始使用直接偏好優化對齊 LLM
直接偏好優化(DPO)已成為使 LLM 更貼近用戶偏好的首選方法之一,這也是您在本文中會經常讀到的內容。如果您想了解它的工作原理,我在這裡從頭開始編寫了代碼:
Ahead of AI 是一份讀者支持的出版物。要接收新文章並支持我的工作,請考慮成為免費或付費訂閱者。
2. Apple 的 Apple Intelligence 基礎語言模型 (AFM)
我很高興在 arXiv.org 上看到 Apple 的另一篇技術論文,概述了他們的模型訓練。這是一個意料之外但絕對積極的驚喜!
2.1 AFM 概覽
在《Apple Intelligence Foundation Language Models》論文中,研究團隊概述了兩款主要模型的開發,這些模型旨在 Apple 設備的「Apple Intelligence」環境中使用。為簡潔起見,本節中這些模型將縮寫為 AFM(Apple Foundation Models)。
具體而言,論文描述了兩個版本的 AFM:一個旨在部署在手機、平板電腦或筆記本電腦上的 30 億參數設備端模型,以及一個規模未指定但能力更強的服務器模型。
這些模型是為聊天、數學和編碼任務開發的,儘管論文沒有討論任何特定於編碼的訓練和能力。
與 Qwen 2 一樣,AFM 是稠密 LLM,不使用混合專家方法。
2.2 AFM 預訓練
我想向研究人員致以兩大讚賞。首先,除了使用公開數據和出版商授權的數據外,他們還尊重網站上的 robots.txt 文件,並避免抓取這些網站。其次,他們還提到對基準測試數據進行了去污染處理。
為了強化 Qwen 2 論文的收穫之一,研究人員提到質量比數量重要得多。(設備端模型的詞彙量為 49k 標記,服務器模型為 100k 標記,詞彙量明顯小於 Qwen 2 模型使用的 150k 詞彙量。)
有趣的是,預訓練不是分 2 個階段,而是 3 個階段完成的!
- 核心(常規)預訓練
- 持續預訓練,其中網絡抓取(低質量)數據的權重被降低;數學和代碼的權重被提高
- 上下文延長,使用更長的序列數據和合成數據

讓我們更詳細地了解這 3 個步驟。
2.2.1 預訓練 I:核心預訓練
核心預訓練描述了 Apple 預訓練流水線中的第一個預訓練階段。這類似於常規預訓練,AFM-server 模型在 6.3 兆標記上訓練,批次大小為 4096,序列長度為 4096 標記。這與在 7 兆標記上訓練的 Qwen 2 模型非常相似。
然而,對於 AFM-on-device 模型來說更有趣,它是從一個較大的 64 億參數模型(像前一段描述的 AFM-server 模型一樣從頭開始訓練)中蒸餾和剪枝而來的。
關於蒸餾過程沒有太多細節,除了「通過將目標標籤替換為真實標籤與教師模型 top-1 預測的凸組合(教師標籤權重為 0.9)來使用蒸餾損失」。
我覺得知識蒸餾在 LLM 預訓練中變得越來越普遍和有用(Gemma-2 也使用了它)。我計劃有一天更詳細地介紹它。目前,這裡有一個關於此過程在高層次上如何工作的簡要概述。

如上圖所示,知識蒸餾仍然涉及在原始數據集上進行訓練。然而,除了數據集中的訓練標記外,待訓練模型(稱為學生模型)還從較大的(教師)模型接收信息,與沒有知識蒸餾的訓練相比,這提供了更豐富的信號。缺點是您必須:1) 先訓練較大的教師模型,以及 2) 使用較大的教師模型計算所有訓練標記的預測。這些預測可以提前計算(這需要大量存儲空間)或在訓練期間計算(這可能會減慢訓練過程)。
2.2.2 預訓練 II:持續預訓練
持續預訓練階段包括一個小的上下文延長步驟,在由 1 兆標記組成的數據集上(核心預訓練集大五倍)將標記從 4,096 增加到 8,192。然而,主要重點是使用高質量數據混合進行訓練,重點是數學和代碼。
有趣的是,研究人員發現蒸餾損失在這種情況下沒有益處。
2.2.3 預訓練 III:上下文延長
第三個預訓練階段僅涉及 1000 億標記(佔第二階段標記的 10%),但代表了更顯著的上下文延長,達到 32,768 個標記。為了實現這一點,研究人員使用合成的長上下文問答數據增強了數據集。

2.3 AFM 微調
Apple 在微調過程中似乎採取了與預訓練同樣全面的方法。他們利用了人工標註和合成數據,強調數據質量優先於數量。有趣的是,他們並不依賴預定的數據比例;相反,他們通過多次實驗微調數據混合,以實現最佳平衡。
微調階段涉及一個兩步過程:監督式指令微調,隨後是幾輪來自人類反饋的強化學習(RLHF)。
此過程的一個特別值得注意的方面是 Apple 為 RLHF 階段引入了兩種新算法:
- 帶有教師委員會的拒絕採樣微調 (iTeC)
- 帶有鏡像下降策略優化的 RLHF
鑑於本文篇幅,我不會深入探討這些方法的技術細節,但這裡有一個簡要概述:
iTeC 算法將拒絕採樣與多種偏好微調技術相結合——具體而言是 SFT、DPO、IPO 和在線 RL。Apple 並非依賴單一算法,而是使用每種方法獨立訓練模型。然後,這些模型生成響應,由人類評估並提供偏好標籤。這些偏好數據被用於在 RLHF 框架中迭代訓練獎勵模型。在拒絕採樣階段,模型委員會生成多個響應,由獎勵模型選擇最佳響應。
這種基於委員會的方法相當複雜,但應該是相對可行的,特別是考慮到所涉及模型的規模較小(約 30 億參數)。在像 Llama 3.1 中的 70B 或 405B 參數模型這樣大得多的模型上實施這樣的委員會,肯定會更具挑戰性。
至於第二種算法,即帶有鏡像下降的 RLHF,選擇它是因為它被證明比常用的 PPO(近端策略優化)更有效。

2.4 結論
Apple 的預訓練和微調方法相對全面,這可能是因為賭注非常高(模型部署在數百萬甚至數十億台設備上)。然而,鑑於這些模型的體積較小,各種技術也變得可行,因為 3B 模型不到 Llama 3.1 最小模型的一半大小。
亮點之一是它不是在 RLHF 和 DPO 之間進行簡單選擇;相反,他們以委員會的形式使用了多種偏好微調算法。
同樣有趣的是,他們明確地將問答數據作為預訓練的一部分——這是我在之前的文章《指令預訓練 LLM》中討論過的。
總而言之,這是一份令人耳目一新且令人愉悅的技術報告。
3. Google 的 Gemma 2
Google 的 Gemma 模型最近在《Gemma 2: Improving Open Language Models at a Practical Size》中進行了描述。
在討論預訓練和微調過程之前,我將在以下概述部分提供一些關鍵事實。
3.1 Gemma 2 概覽
Gemma 2 模型有三種尺寸:20 億、90 億和 270 億參數。主要重點是探索不一定需要增加訓練數據集規模的技術,而是開發相對較小且高效的 LLM。
值得注意的是,Gemma 2 具有 256k 標記的大量詞彙量。相比之下,Llama 2 使用 32k 標記詞彙量,Llama 3 使用 128k 標記詞彙量。
此外,Gemma 2 採用了滑動窗口注意力(sliding window attention),類似於 Mistral 的早期模型,可能是為了降低內存成本。有關 Gemma 2 架構的更多細節,請參閱我之前文章中的 Gemma 2 部分。
3.2 Gemma 2 預訓練
Gemma 研究人員認為,即使是小型模型也經常訓練不足。然而,他們並非簡單地增加訓練數據集的規模,而是專注於保持質量,並通過替代方法(如知識蒸餾,類似於 Apple 的方法)實現改進。
雖然 27B Gemma 2 模型是從頭開始訓練的,但較小的模型是使用類似於前面解釋的 Apple 方法的知識蒸餾訓練的。
27B 模型在 13 兆標記上訓練,9B 模型在 8 兆標記上訓練,2B 模型在 2 兆標記上訓練。此外,與 Apple 的方法類似,Gemma 團隊優化了數據混合以提高性能。

3.3 Gemma 2 微調
Gemma 模型的微調過程涉及典型的監督式微調(SFT)和來自人類反饋的強化學習(RLHF)步驟。
指令數據涉及使用僅限英語的提示對,這些對是人工生成和合成生成的混合。具體而言,有趣的是,響應主要由教師模型生成,並且在 SFT 階段也應用了知識蒸餾。
他們在 SFT 之後的 RLHF 方法的一個有趣方面是,用於 RLHF 的獎勵模型比策略(目標)模型大十倍。
Gemma 採用的 RLHF 算法相當標準,但有一個獨特的轉折:他們通過一種名為 WARP 的方法對策略模型進行平均,這是 WARM(權重平均獎勵模型)的繼承者。我之前在《模型合併、混合專家與邁向更小 LLM》一文中詳細討論過這種方法。

3.4 結論
Gemma 團隊似乎確實在知識蒸餾上加倍下注,他們在預訓練和微調階段都使用了它,這與 Apple 類似。有趣的是,他們沒有使用多階段預訓練方法,或者至少,他們沒有在論文中詳細說明。

4. Meta AI 的 Llama 3.1
Meta 的 Llama LLM 的新發布總是一件大事。這一次,發布伴隨著一份 92 頁的技術報告:《The Llama 3 Herd of Models》。最後但同樣重要的一點是,在本節中,我們將查看上個月發布的第四篇大型模型論文。
4.1 Llama 3.1 概覽
除了發布一個巨大的 4050 億參數模型外,Meta 還更新了其先前的 80 億和 700 億參數模型,使其 MMLU 性能略有提升。

雖然 Llama 3 與其他最近的 LLM 一樣使用分組查詢注意力(group query attention),但令人驚訝的是,Meta AI 對滑動窗口注意力和混合專家方法說「不」。換句話說,Llama 3.1 看起來非常傳統,重點顯然是在預訓練和微調上,而不是架構創新。
與之前的 Llama 版本類似,權重是公開可用的。此外,Meta 表示他們更新了 Llama 3 許可證,因此現在終於可以(允許)使用 Llama 3 進行合成數據生成或知識蒸餾以改進其他模型。
4.2 Llama 3.1 預訓練
Llama 3 在龐大的 15.6 兆標記數據集上進行訓練,這比 Llama 2 的 1.8 兆標記有了大幅增加。研究人員表示它至少支持八種語言(而 Qwen 2 能夠處理 20 種)。
Llama 3 的一個有趣方面是其 128,000 的詞彙量,這是使用 OpenAI 的 tiktoken 分詞器開發的。(對於那些對分詞器性能感興趣的人,我在這裡做了一個簡單的基準測試比較。)
在預訓練數據質量控制方面,Llama 3 採用了基於啟發式的過濾以及基於模型的質量過濾,利用了 Meta AI 的 fastText 和基於 RoBERTa 的快速分類器。這些分類器還有助於確定訓練期間使用的數據混合的上下文類別。
Llama 3 的預訓練分為三個階段。第一階段涉及使用 15.6 兆標記和 8k 上下文窗口進行標準初始預訓練。第二階段繼續預訓練,但將上下文長度擴展到 128k。最後一個階段涉及退火(annealing),進一步增強了模型的性能。讓我們在下面詳細了解這些階段。
4.2.1 預訓練 I:標準(初始)預訓練
在他們的訓練設置中,他們從包含 400 萬個標記的批次開始,每個批次的序列長度為 4096。這意味著批次大小約為 1024 個標記(假設 400 萬這個數字是四捨五入後的結果)。在處理完前 2.52 億個標記後,他們將序列長度增加了一倍,達到 8192。在訓練過程的更深處,在處理完 2.87 兆個標記後,他們再次將批次大小增加了一倍。
此外,研究人員在整個訓練過程中並未保持數據混合比例不變。相反,他們在訓練過程中調整了所使用的數據混合,以優化模型的學習和性能。這種動態的數據處理方法可能有助於提高模型在不同類型數據上的泛化能力。
4.2.2 預訓練 II:用於上下文延長的持續預訓練
與其他在單一步驟中增加上下文窗口的模型相比,Llama 3.1 的上下文延長採用了更漸進的方法:在這裡,研究人員通過六個不同的階段將上下文長度從 8,000 增加到 128,000 個標記。這種逐步增加的方式可能使模型能夠更平滑地適應更大的上下文。
用於此過程的訓練集涉及 8000 億個標記,約佔總數據集大小的 5%。
4.2.3 預訓練 III:高質量數據上的退火
對於第三個預訓練階段,研究人員在少量但高質量的混合數據上訓練模型,他們發現這有助於提高在基準數據集上的性能。例如,在 GSM8K 和 MATH 訓練集上進行退火,顯著提升了相應 GSM8K 和 MATH 驗證集的表現。
在論文的第 3.1.3 節中,研究人員指出退火數據集大小為 400 億個標記(佔總數據集大小的 0.02%);這 40B 退火數據集用於評估數據質量。在第 3.4.3 節中,他們指出實際退火僅在 4000 萬個標記上完成(佔退火數據的 0.1%)。

4.3 Llama 3.1 微調
在微調過程中,Meta AI 團隊採用了一種相對直接的方法,包括監督式微調(SFT)、拒絕採樣和直接偏好優化(DPO)。
他們觀察到,與這些技術相比,像帶有 PPO 的 RLHF 這樣的強化學習算法不夠穩定,且更難擴展。值得注意的是,SFT 和 DPO 步驟在多輪中迭代重複,並結合了人工生成和合成數據。
在描述進一步細節之前,下圖展示了他們的工作流程。

請注意,儘管他們使用了 DPO,但他們也像在 RLHF 中那樣開發了一個獎勵模型。最初,他們使用預訓練階段的一個檢查點,利用人工標註的數據訓練獎勵模型。然後,該獎勵模型被用於拒絕採樣過程,幫助選擇合適的提示以進行進一步訓練。
在每一輪訓練中,他們不僅對獎勵模型應用模型平均技術,還對 SFT 和 DPO 模型應用該技術。這種平均涉及合併近期和先前模型的參數,以穩定(並改進)隨時間變化的性能。
對於那些對模型平均技術細節感興趣的人,我在之前的文章《模型合併、混合專家與邁向更小 LLM》中的「理解模型合併與權重平均」章節討論了這個主題。
總結來說,其核心是一個相對標準的 SFT + DPO 階段。然而,這個階段會重複多輪。然後,他們加入了一個用於拒絕採樣的獎勵模型(如 Qwen 2 和 AFM)。他們還像 Gemma 一樣使用了模型平均;然而,這不僅僅是針對獎勵模型,而是針對所有涉及的模型。

4.4 結論
Llama 3 模型保持了相當標準的設計,與早期的 Llama 2 模型相似,但採用了一些有趣的方法。值得注意的是,龐大的 15 兆標記訓練集使 Llama 3 與其他模型區分開來。有趣的是,與 Apple 的 AFM 模型一樣,Llama 3 也實施了 3 階段預訓練過程。
與其他最近的大型語言模型相比,Llama 3 沒有採用知識蒸餾技術,而是選擇了一條更直接的模型開發路徑。對於微調,該模型利用了直接偏好優化(DPO),而不是在其他模型中流行的更複雜的強化學習策略。總體而言,這一選擇很有趣,因為它表明了通過更簡單(但經證實)的方法來優化 LLM 性能的重點。
5. 主要收穫
我們能從本文討論的這四個模型中學到什麼:阿里巴巴的 Qwen 2、Apple 的基礎模型 (AFM)、Google 的 Gemma 2 和 Meta 的 Llama 3?
這四個模型在預訓練和微調方面採取了截然不同的方法。當然,方法論有所重疊,但沒有兩個訓練流水線是完全相同的。對於預訓練,一個共同特徵似乎是所有方法都使用了多階段預訓練流水線,其中通用的核心預訓練之後是上下文延長,有時還有高質量的退火步驟。下圖再次展示了預訓練中採用的不同方法。

在微調方面,同樣沒有完全相同的流水線。拒絕採樣現在似乎已成為微調過程中的常見要素。然而,當涉及到 DPO 或 RLHF 時,目前還沒有共識或偏好(無雙關之意)。

因此,總而言之,開發高性能 LLM 沒有單一的秘訣,而是有許多條路徑。
最後,這四個模型的表現都在同一水平線上。遺憾的是,其中幾個模型尚未進入 LMSYS 和 AlpacaEval 排行榜,因此除了 MMLU 等多選基準測試的分數外,我們還沒有直接的比較。
支持 Ahead of AI
這本雜誌是一個個人的熱情專案。對於那些希望支持我的人,請考慮購買一本我的《Build a Large Language Model (From Scratch)》書。(我有信心您會從這本書中收穫良多,因為它以其他地方找不到的詳細程度解釋了 LLM 的工作原理。)

如果您讀過這本書並有幾分鐘空閒時間,我將非常感謝您的簡短評論。這對我們作者幫助很大!
或者,我最近也在 Substack 上啟用了付費訂閱選項,以直接支持這本雜誌。
Ahead of AI 是一份讀者支持的出版物。要接收新文章並支持我的工作,請考慮成為免費或付費訂閱者。
相關文章