如何「操縱」METR圖表
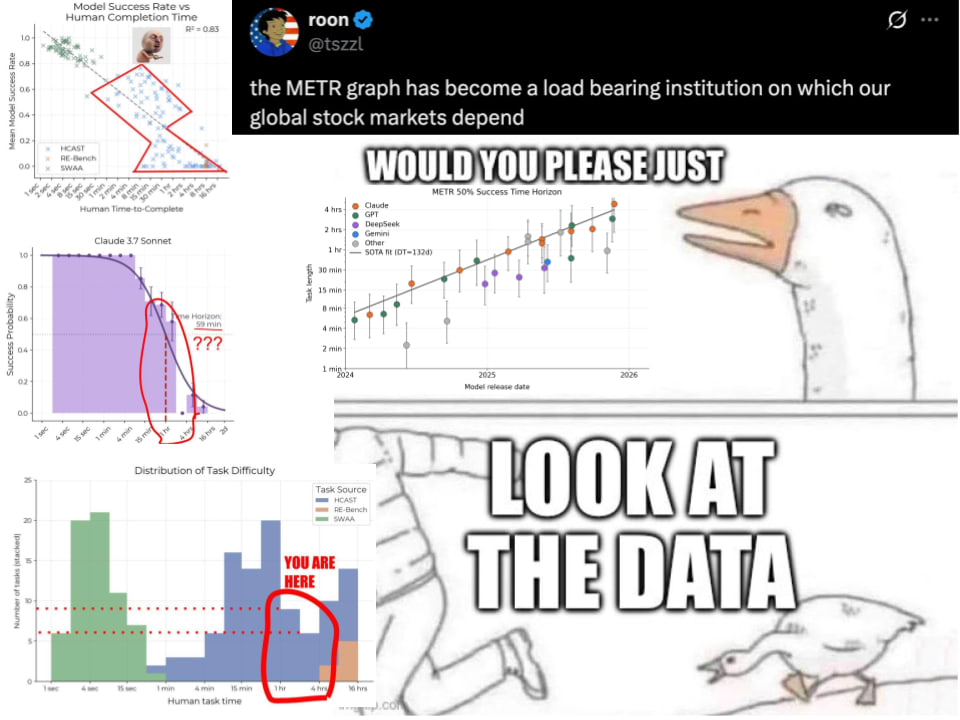
我認為 METR 視野長度圖表在關鍵的 1 到 4 小時區間僅依賴 14 個樣本,卻被過度解讀,且極易透過針對網路安全等特定任務進行訓練來操弄數據。我對大眾根據這些數據所做的過度推論感到厭倦,並認為該指標提供的資訊可能並不比標準基準測試準確度多出多少。
太長不看(TL;DR):在 2025 年,我們處於 1-4 小時的區間,而這在 METR 的底層數據中僅有 14 個樣本。每個樣本的主題都是公開的,這使得領先的實驗室很容易針對 METR 的任務時長(horizon length)測量進行操弄,有時甚至是在無意中進行的。最後,在 METR 的假設下,「任務時長」所能提供的資訊,可能並不比基準測試的準確率多出多少。這並非要批評 METR——在研究中,初次發佈很難做到完美。但我已經厭倦了人們從這張圖表中推導出的結論,請停止這種行為!
2025 年主導 AI 輿論的 14 個提示詞
METR 任務時長圖表是一個極佳的創意:它提議測量模型能夠完成任務的長度(以估計所需的人力小時數計算),而非準確率。我很高興它讓社群轉向關注長時程(long-horizon)任務。它們能更好地衡量自動化的影響以及經濟成果(例如,勞動法通常基於工作小時數)。
然而,我認為我們對它的過度解讀已經到了無以復加的地步。特別是 AI 安全社群,他們以此為據,對時間線和研究優先級進行了巨大的調整。我懷疑(根據許多軼聞,包括 roon 的說法)METR 圖表已經影響了重大的投資決策,儘管我並未進入過任何董事會。
兩位知名的 AI 安全研究員今天根據 Claude 4.5 Opus 的結果做出了巨大的更新,在 6 小時內獲得了 200 多個讚。問題就在這裡:根據這張圖表,2025 年領先 AI 的進展發生在任務時長 1 到 4 小時的區間內。
猜猜估計任務長度在 1-4 小時之間的樣本有多少個?
只有 14 個。我們怎麼知道的?感謝作者,論文中包含了這些資訊,並且透明地提供了任務元數據。
其論文中的圖 14。1-4 小時範圍內有 14 個任務。光明會確認了?希望對許多人來說,單憑這一點就足以敲響警鐘。在任何情況下,我們都不應該僅基於 14 個樣本,就對 AGI 時間線、中美對抗、閉源與開源模型的進展、研究優先級、個別模型質量等做出如此重大的推論。當原始的 METR 論文在 2025 年 3 月發佈時,這個問題的早期跡象就已經顯現。當時表現最好的模型 Claude 3.7 Sonnet,估計任務時長為 59 分鐘。現在看看它在不同任務長度下的成功率分佈:
注意該模型在 1-2 小時任務上的成功概率幾乎是 60 ±15%。那麼為什麼估計的 50% 成功率任務時長是 59 分鐘呢?!因為它在 2-4 小時範圍內完全沒有答對任何題目。METR 通過對單個樣本結果擬合邏輯回歸曲線(logistic curve)來計算任務時長,就像上面的深紫色線。請注意,2-4 小時範圍內的 0% 成功率導致了非常糟糕的邏輯擬合(曲線低於 0.5-1 小時和 1-2 小時範圍的 95% 置信區間)。稍後我會談到我對使用邏輯曲線這一核心建模假設的懷疑。我懷疑 Claude 3.7 Sonnet 在 2-4 小時範圍內成功率為 0%,是因為他們在該範圍內只有 6 個樣本,且其中大部分來自網絡安全奪旗賽(CTF)。在 WMDP 中,網絡安全被視為具有雙重用途的安全隱患能力,實驗室在 2025 年初對此非常謹慎。記住,這可是 Anthropic。
提升 METR 任務時長的方法:針對網絡安全競賽進行訓練
我答應過你們,有一種方法可以操弄 METR 評測中的任務時長。方法如下:1 分鐘到 16 小時範圍內的樣本主要來自 HCAST。事實證明,HCAST 透明地告訴了我們這些任務分別是關於什麼的。
HCAST 任務描述,1.5-3.5 小時
附錄 D 描述了每個任務,並按估計耗時排序。雖然不清楚 METR 任務時長圖表具體使用了哪 14 個樣本,但清單足夠短,可以全部考慮在內。
為什麼這是一件大事?如果你知道想要提升性能的任務是什麼,那就很容易做到。你可以創建針對性的合成數據,或者直接聘請像 Scale、Mercor 和 Surge 這樣的供應商,在你的訓練後(post-training)組合中增加此類任務的採樣。如果你仔細觀察,這個範圍內的大多數任務都是網絡安全 CTF 和機器學習工程(MLE)任務。OpenAI 已經明確表示,他們針對 Codex 模型專門強化了這些能力:
現在,我並不是說實驗室是為了在 METR 圖表上取得好成績才專注於這些任務。他們可能有其他的動力。但這正是為什麼 METR 圖表不太可能具有泛化性的原因——它測量的正是實驗室所專注的內容!如果 Kimi 或 DeepSeek 想要超越,他們只需要收集大量的機器學習訓練和網絡安全提示詞,並對其進行微調即可。
請注意,考慮到相關任務長度範圍內只有 14 個樣本,多答對 1 或 2 個樣本就會顯著增加任務時長!如果你運氣好或過度擬合了更長的任務(來自 RE-Bench 的 8 小時以上任務),增長可能會更明顯,正如今天 Claude 4.5 Opus 的結果所示。事實上,或許是因為 Anthropic 不想冒險在網絡安全數據上訓練,我們在 2-4 小時範圍內的準確率仍然很低?
僅憑 HCAST 準確率即可預測 METR 任務時長的對數線性趨勢
最後,讓我們看看 METR 如何估計 50% 成功率的任務時長。他們假設成功概率與任務時長(估計變量)與任務長度之間的差距呈邏輯關係:
你通過擬合每個任務的 0/1 成功評估數據來推導出 h(50% 任務時長)。β... [後續為公式相關的樣式代碼,保持原樣]
相關文章