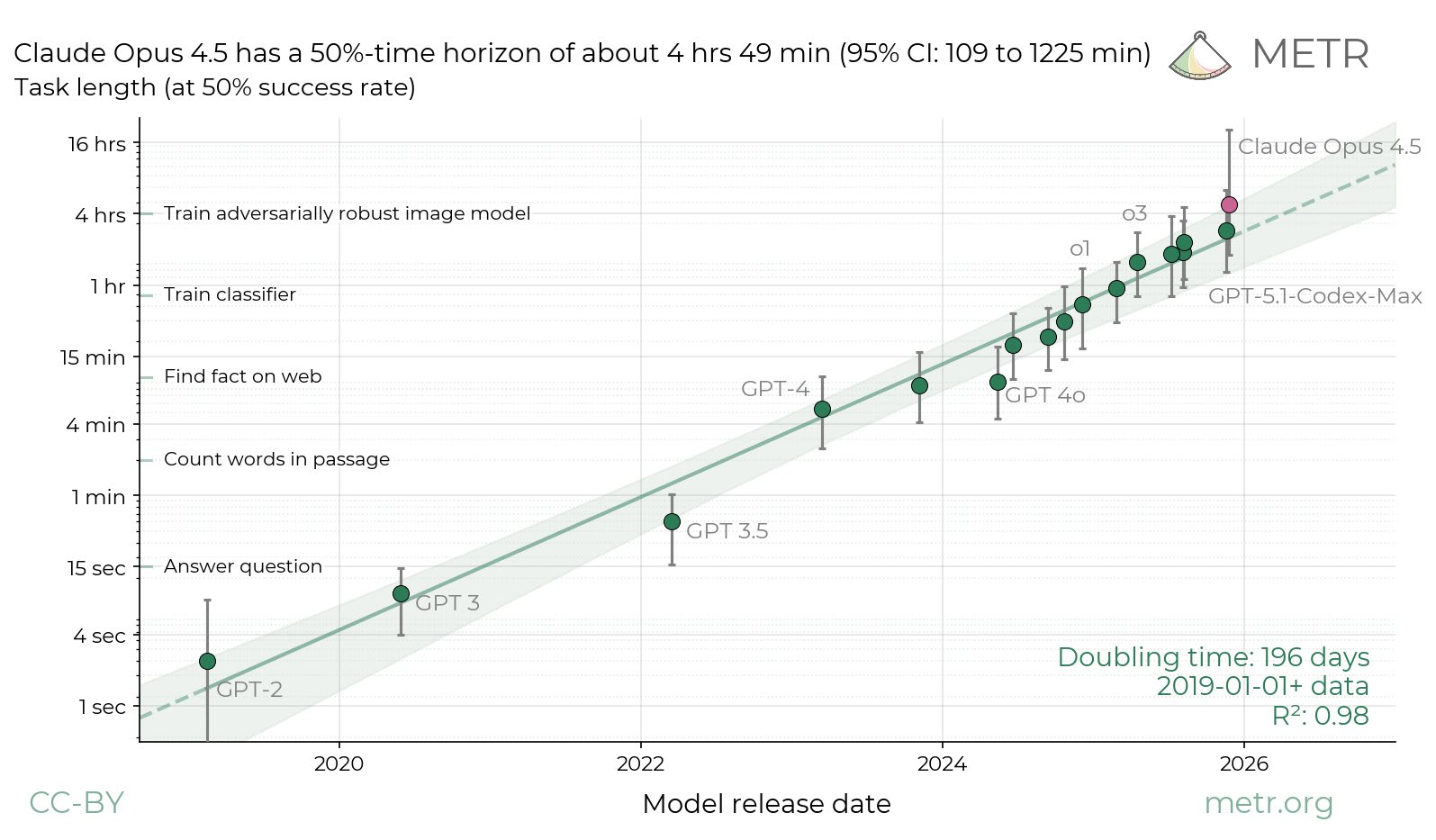
Claude Opus 4.5 達成約 4 小時 49 分鐘的 50% 時間跨度
METR 報告指出 Claude Opus 4.5 達到了約 4 小時 49 分鐘的 50% 時間跨度紀錄,但其 80% 時間跨度仍停留在 27 分鐘。這顯示模型處理長任務的能力有所提升,可能反映出進步主要源於基準性能的改善。
包含 Claude Opus 4.5 的更新版 METR 圖表已於 3 小時前由 METR 在 X 上發布(來源):
相同的圖表,但未使用對數座標(來源):
來自 METR 在 X 上的討論串(來源):
我們估計,在我們的任務中,Claude Opus 4.5 的 50% 時間跨度(50%-time horizon)約為 4 小時 49 分鐘(95% 置信區間為 1 小時 49 分鐘至 20 小時 25 分鐘)。雖然我們仍在對其他近期模型進行評估,但這是我們迄今為止發布的最高時間跨度。
我們不認為置信區間的高上限反映了 Opus 的實際能力:我們目前的任務套件中沒有足夠的長任務來確信地界定 Opus 4.5 50% 時間跨度的上限。我們正在努力更新我們的任務套件,並希望很快能分享更多細節。
根據我們與 Opus 4.5 互動的經驗、該模型在特定任務(包括一些不在我們時間跨度套件中的任務)上的表現,以及其基準測試表現,如果進一步調查顯示 Opus 具有 20 小時以上的 50% 時間跨度,我們會感到驚訝。
儘管其 50% 時間跨度很高,但 Opus 4.5 的 80% 時間跨度僅為 27 分鐘,與過去的模型相似,且低於 GPT-5.1-Codex-Max 的 32 分鐘。其 50% 與 80% 時間跨度之間的差距反映了較平緩的邏輯斯諦成功曲線(logistic success curve),因為 Opus 在較長任務上的成功率有顯著差異。
您可以在此處找到關於我們目前方法論的更多細節,以及對 Opus 4.5 和其他模型的時間跨度估計:https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
自 GPT-5.1-Codex-Max 發布以來,80% 時間跨度基本上保持持平(27-32 分鐘),但在 50% 時間跨度上出現了巨大的跳躍,且帶有極大的誤差線。
我認為 Daniel Kokotajlo 最近的短評在此提供了一個有用的框架。他將進步建模為增加截距(基準性能)或斜率(模型將時間預算轉化為性能的能力)。如果進步主要來自截距的上升,那麼對時間跨度長度的指數擬合可能會無限期持續。但如果進步來自斜率的增加,當 AI 的斜率接近人類斜率時,交叉點最終會衝向無窮大。
80% 時間跨度持平而 50% 時間跨度攀升,可能是截距主導進步的證據。
相關文章