
大型語言模型推理能力的強化學習現況
這篇文章探討了強化學習(特別是 GRPO 和 PPO 等方法)如何被用於提升大型語言模型的推理能力,並突破傳統僅靠擴展模型規模與數據所面臨的瓶頸。
LLM 推理強化學習的現狀
深入理解 GRPO 與推理模型論文的新見解
這個月發生了很多大事,特別是 GPT-4.5 和 Llama 4 等新旗艦模型的發佈。但你可能已經注意到,大眾對這些發佈的反應相對平淡。為什麼?原因之一可能是 GPT-4.5 和 Llama 4 仍屬於傳統模型,這意味著它們在訓練過程中沒有針對推理進行顯式的強化學習(Reinforcement Learning)。
與此同時,xAI 和 Anthropic 等競爭對手已在其模型中加入了更多推理能力與功能。例如,xAI Grok 和 Anthropic Claude 的介面現在都為特定模型加入了「思考」(或「擴展思考」)按鈕,可顯式切換推理能力。
無論如何,對 GPT-4.5 和 Llama 4(非推理型)模型的平淡反應表明,我們正接近僅靠縮放模型規模和數據所能達到的極限。
然而,OpenAI 最近發佈的 o3 推理模型證明,透過策略性地投入算力——特別是透過針對推理任務量身定制的強化學習方法——仍有相當大的進步空間。(根據 OpenAI 員工在最近直播中的說法,o3 使用的訓練算力是 o1 的 10 倍。)

雖然單靠推理並非萬靈丹,但它能可靠地提高模型在挑戰性任務上的準確性和問題解決能力(到目前為止)。我預計以推理為核心的後訓練(Post-training)將成為未來 LLM 流水線的標準做法。
因此,在本文中,讓我們一起探索透過強化學習實現推理的最新進展。

由於這是一篇較長的文章,我提供以下目錄概覽。若要導覽目錄,請使用網頁視圖左側的滑桿。
- 理解推理模型
- RLHF 基礎:一切的起點
- PPO 簡介:強化學習的主力演算法
- RL 演算法:從 PPO 到 GRPO
- RL 獎勵建模:從 RLHF 到 RLVR
- DeepSeek-R1 推理模型是如何訓練的
- 近期關於訓練推理模型的 RL 論文啟示
- 值得關注的訓練推理模型研究論文
提示:如果你已經熟悉推理基礎、RL、PPO 和 GRPO,請隨時直接跳轉到「近期關於訓練推理模型的 RL 論文啟示」章節,其中包含了近期推理研究論文的有趣見解摘要。
理解推理模型
房間裡的大象(顯而易見卻被忽視的問題)當然是推理的定義。簡而言之,推理是指讓 LLM 更好地處理複雜任務的推論和訓練技術。
為了更詳細地說明這是如何實現的(到目前為止),我想將推理定義如下:
在 LLM 的語境下,推理是指模型在提供最終答案之前產生中間步驟的能力。這個過程通常被稱為思維鏈(Chain-of-Thought, CoT)推理。在 CoT 推理中,LLM 會顯式地生成結構化的語句或計算序列,展示它是如何得出結論的。
以下是定義及對應的圖表。
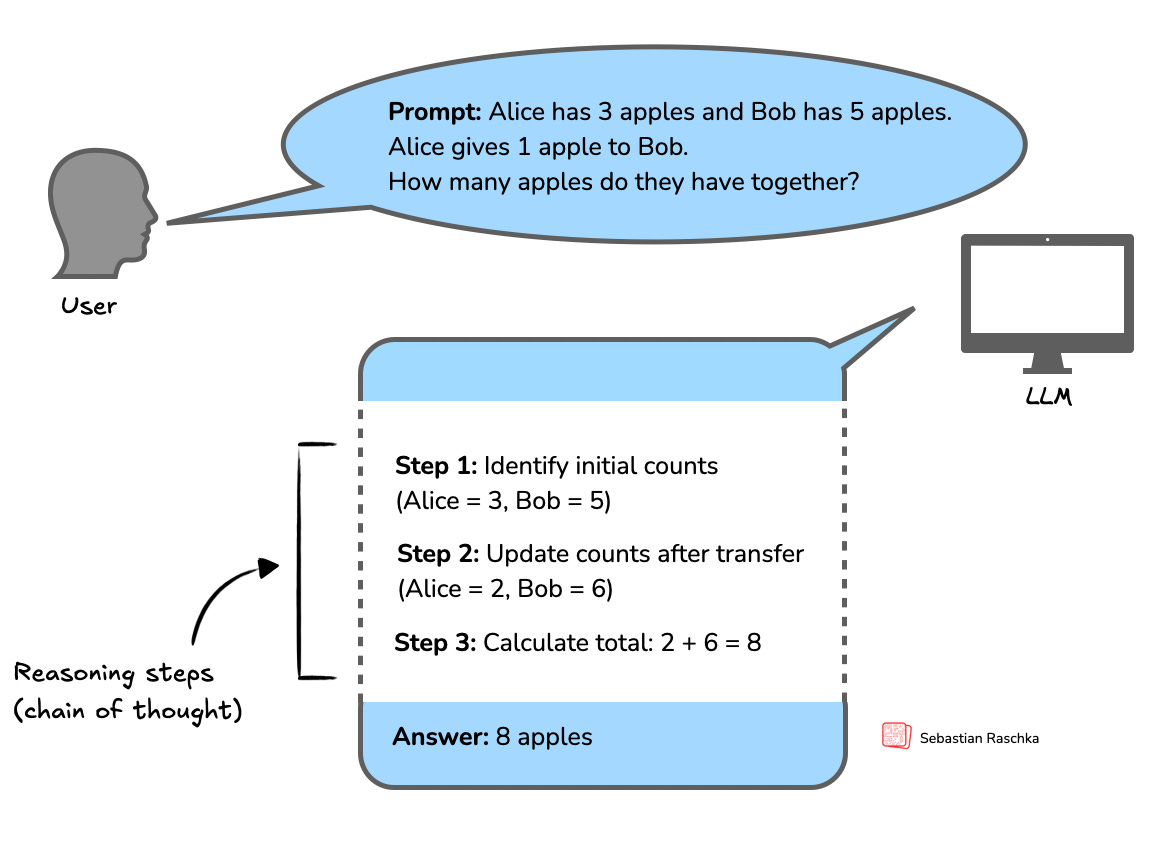
如果你是推理模型的新手,並希望獲得更全面的介紹,我推薦閱讀我之前的文章:
從零開始初探推理:第 1 章
理解推理 LLM
現在,正如本節開頭所暗示的,LLM 的推理能力可以透過兩種方式提升,正如 OpenAI 部落格文章中的圖表所清晰展示的:

在我之前的文章中:
LLM 推理模型推論現狀
我完全專注於測試時算力(Test-time compute)方法。在本文中,我終於想仔細研究一下訓練方法。
RLHF 基礎:一切的起點
用於構建和改進推理模型的強化學習(RL)訓練方法,或多或少都與用於開發和對齊傳統 LLM 的人類回饋強化學習(RLHF)方法論相關。因此,在討論基於 RL 訓練的推理特定修改之前,我想先簡要回顧一下 RLHF 的工作原理。
傳統 LLM 通常經歷 3 個步驟的訓練程序:
- 預訓練(Pre-training)
- 指令微調(Supervised fine-tuning, SFT)
- 對齊(Alignment,通常透過 RLHF)
「原始」的 LLM 對齊方法是 RLHF,這是自 InstructGPT 論文以來開發 LLM 的標準配備,該論文描述了開發第一個 ChatGPT 模型所使用的配方。
RLHF 的原始目標是使 LLM 與人類偏好對齊。例如,假設你多次使用 LLM,而 LLM 對給定的提示生成了多個答案。RLHF 會引導 LLM 更多地生成你所偏好的答案風格。(通常,RLHF 也用於安全微調 LLM:避免分享敏感資訊、使用髒話等。)
如果你對 RLHF 還很陌生,這裡有一段我幾年前演講的摘錄,在 5 分鐘內解釋了 RLHF:
或者,以下段落以文字形式描述了 RLHF。
RLHF 流水線採用預訓練模型並以監督方式進行微調。這個微調階段還不是 RL 部分,而主要是先決條件。
然後,RLHF 使用一種稱為近端策略優化(Proximal Policy Optimization, PPO)的演算法進一步對齊 LLM。(請注意,還可以使用其他演算法代替 PPO;我特別提到 PPO 是因為它是 RLHF 最初使用的,且至今仍是最受歡迎的演算法。)
為了簡單起見,我們將 RLHF 流水線分為三個獨立的步驟:
- RLHF 第 1 步(先決條件):預訓練模型的指令微調(SFT)
- RLHF 第 2 步:建立獎勵模型(Reward Model)
- RLHF 第 3 步:透過近端策略優化(PPO)進行微調
如下圖所示,RLHF 第 1 步是指令微調步驟,旨在為後續的 RLHF 微調建立基礎模型。

在 RLHF 第 1 步中,我們建立或採樣提示(例如從資料庫中),並要求人類撰寫高品質的回答。然後,我們使用此數據集以監督方式微調預訓練的基礎模型。如前所述,這在技術上不屬於 RL 訓練,而僅僅是先決條件。
在 RLHF 第 2 步中,我們接著使用這個來自指令微調(SFT)的模型來建立獎勵模型,如下圖所示。

如上圖所示,對於每個提示,我們從前一步微調的 LLM 中生成四個回答。然後,人類標註者根據他們的偏好對這些回答進行排序。雖然這個排序過程很耗時,但可能比建立指令微調數據集的勞動強度稍低,因為對回答進行排序通常比撰寫回答更簡單。
在編譯好包含這些排名的數據集後,我們可以設計一個獎勵模型,為 RLHF 第 3 步的後續優化階段輸出獎勵分數。這裡的想法是,獎勵模型取代並自動化了勞動力密集的人類排序,使在大規模數據集上進行訓練成為可能。
這個獎勵模型(RM)通常源自於前一個指令微調(SFT)步驟建立的 LLM。為了將 RLHF 第 1 步的模型轉化為獎勵模型,其輸出層(下一個 token 分類層)被替換為回歸層,該層具有單個輸出節點。
RLHF 流水線的第三步是使用獎勵模型(RM)來微調之前的指令微調(SFT)模型,如下圖所示。
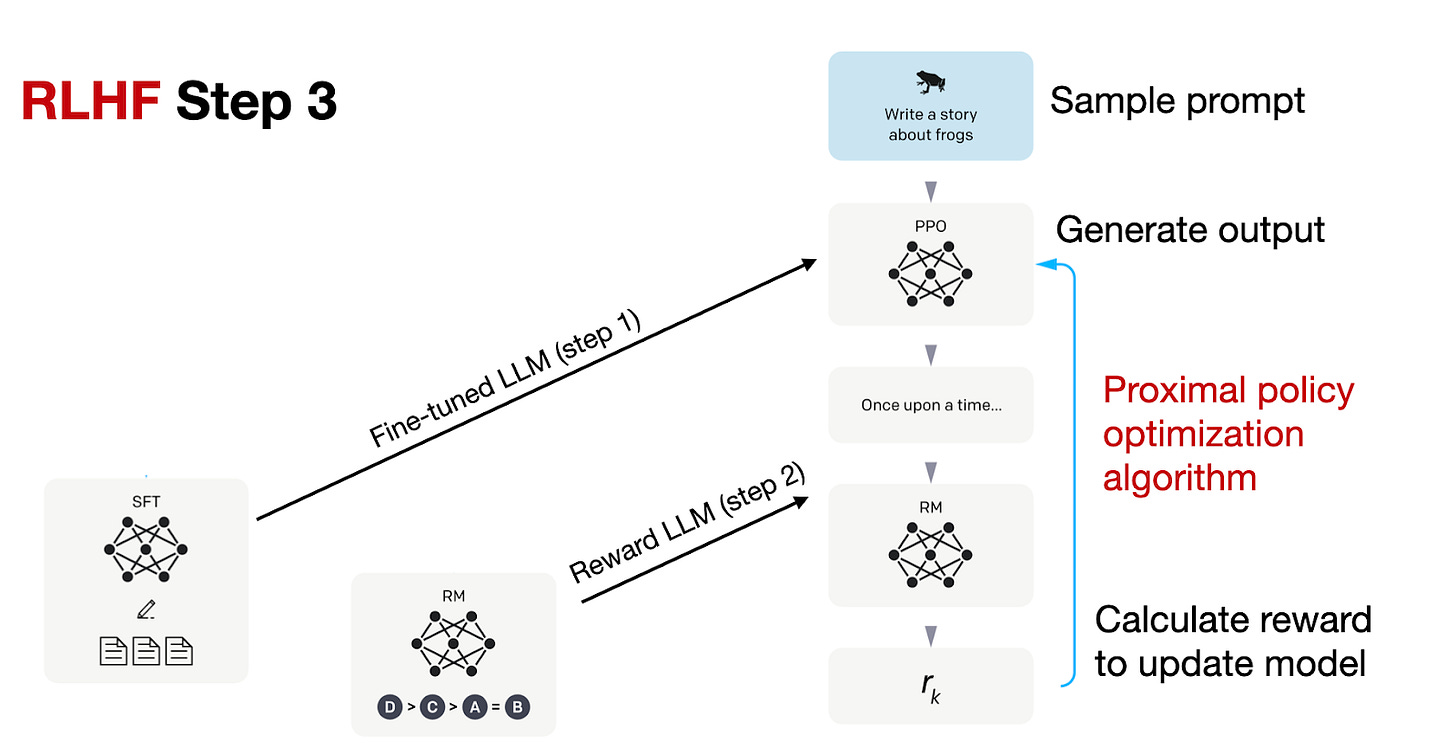
在 RLHF 第 3 步(最終階段)中,我們現在根據 RLHF 第 2 步建立的獎勵模型所提供的獎勵分數,使用近端策略優化(PPO)來更新 SFT 模型。
Ahead of AI 是一份讀者支持的出版物。若要接收新文章並支持我的工作,請考慮成為免費或付費訂閱者。
PPO 簡介:強化學習的主力演算法
如前所述,原始的 RLHF 方法使用一種稱為近端策略優化(PPO)的強化學習演算法。
開發 PPO 是為了提高訓練策略(Policy)的穩定性和效率。(在強化學習中,「策略」指的就是我們想要訓練的模型;在這種情況下,策略 = LLM。)
PPO 的核心思想之一是限制策略在每個更新步驟中允許改變的幅度。這是透過「裁剪損失函數」(Clipped loss function)來實現的,它有助於防止模型進行過大的更新,以免導致訓練不穩定。
除此之外,PPO 還在損失函數中加入了 KL 散度懲罰項。該項將當前策略(正在訓練的模型)與原始 SFT 模型進行比較,鼓勵更新保持在合理的接近範圍內。畢竟,我們的想法是進行偏好微調,而不是完全重新訓練。
這就是「近端策略優化」中「近端」的由來:演算法試圖讓更新保持在現有模型附近,同時仍允許改進。為了鼓勵一定的探索,PPO 還加入了熵獎勵(Entropy bonus),這會鼓勵模型在訓練期間使輸出多樣化。
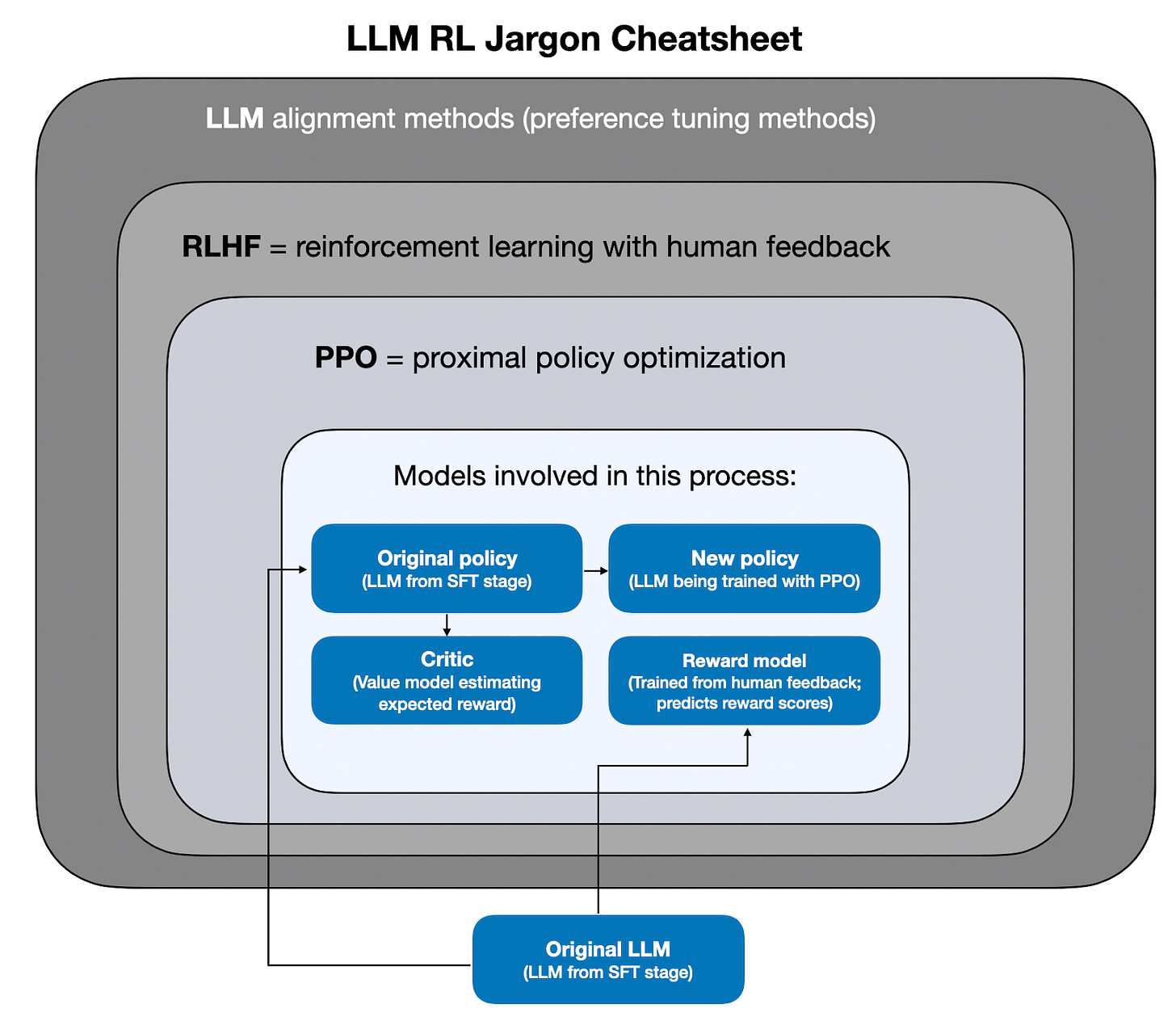
在接下來的段落中,我想引入更多術語,以便在相對較高的層次上說明 PPO。不過,這涉及很多專業術語,因此在繼續之前,我嘗試在下圖中總結關鍵術語。
下面,我旨在透過虛擬程式碼說明 PPO 的關鍵步驟。
此外,為了使其更直觀,我還將使用一個類比:想像你是一位經營小型外送服務的廚師。你不斷嘗試新的食譜變化以提高客戶滿意度。你的總體目標是根據客戶回饋(獎勵)來調整你的食譜(策略)。
-
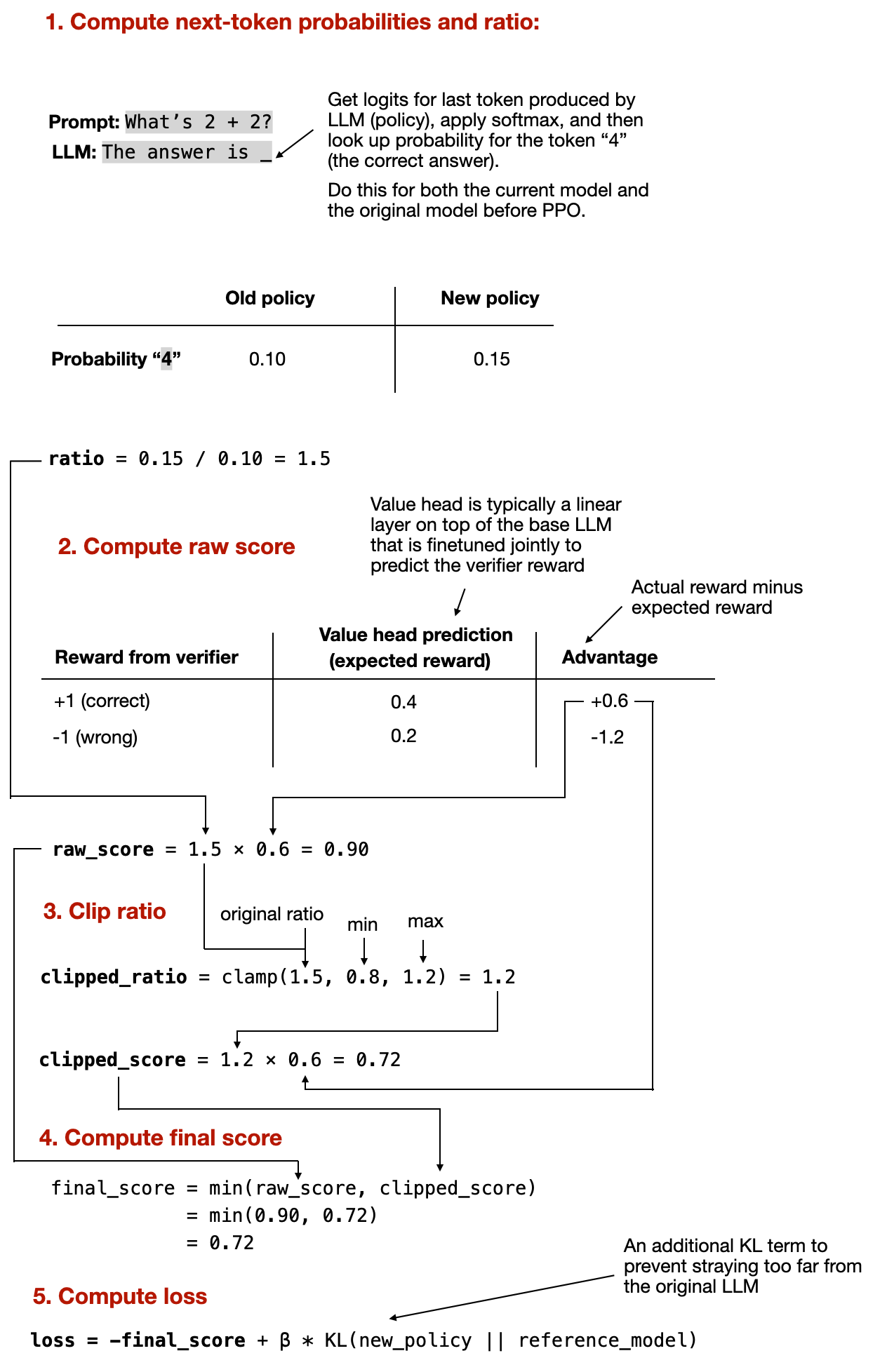
計算新舊策略下一個 token 機率的比率:
簡而言之,這檢查了我們的新食譜與舊食譜有多大不同。
旁註:關於 "new_policy_prob",我們還沒有使用最終更新的策略。我們使用的是策略的當前版本(即我們正在訓練中的模型)。然而,按照慣例將其稱為 "new"。所以,即使你還在實驗中,我們也按慣例稱你的當前草案為「新策略」。 -
將該比率乘以動作的好壞程度(稱為優勢 Advantage):
在這裡,為了簡單起見,我們可以假設優勢是根據獎勵訊號計算的:
在廚師的類比中,我們可以將優勢視為新菜餚的表現如何:
例如,如果客戶給新菜打了 9/10 分,而客戶通常給我們 7/10 分,那就是 +2 的優勢。
請注意,這是一個簡化。實際上,這涉及廣義優勢估計(Generalized Advantage Estimation, GAE),為了不使文章過於臃腫,我在此省略。然而,一個重要的細節是,預期獎勵是由所謂的「評論家」(Critic,有時也稱為「價值模型」)計算的,而獎勵模型計算實際獎勵。也就是說,優勢計算涉及另外 2 個模型,通常與我們正在微調的原始模型大小相同。
在類比中,我們可以把這個評論家或價值模型想像成一個朋友,我們在把新菜端給客人之前先請他品嚐。我們還請朋友估計客戶會如何評價它(這就是預期獎勵)。而獎勵模型就是隨後給予回饋的實際客戶(即實際獎勵)。 -
計算裁剪後的分數:
如果新策略改變太多(例如比率 > 1.2 或 < 0.8),我們會按如下方式裁剪比率:
在類比中,想像新食譜得到了一個異常出色(或糟糕)的評價。我們現在可能會想徹底更換整個菜單。但這很冒險。因此,我們暫時限制食譜可以改變的幅度。(例如,也許我們把菜做得更辣了,而那位客戶剛好喜歡吃辣,但這並不代表其他人都會喜歡。) -
然後我們取原始分數和裁剪後分數中較小的一個:
(感謝 Johanna Reiml 指出早期關於 PPO 下界屬性的問題,現已修正。)
同樣,這與保持謹慎有關。例如,如果優勢是正的(新行為更好),我們會限制獎勵。這是因為我們不想過度信任一個可能是巧合或運氣的好結果。
如果優勢是負的(新行為更差),我們限制懲罰。這裡的想法類似。也就是說,除非我們非常確定,否則我們不想對一個糟糕的結果反應過度。
簡而言之,如果優勢為正,我們使用兩個分數中較小的一個(以避免過度獎勵);當優勢為負時,使用較大的一個(以避免過度懲罰)。
在類比中,這確保了如果一個食譜表現優於預期,除非我們有信心,否則不會過度獎勵它。如果它表現不佳,除非它持續糟糕,否則我們不會過度懲罰它。 -
計算損失:
這個最終分數就是我們在訓練期間最大化的目標(在翻轉分數符號以最小化後使用梯度下降)。此外,我們還加入了一個 KL 懲罰項,其中 β 是懲罰強度的超參數:
在類比中,我們加入懲罰是為了確保新食譜與我們原有的風格不會相差太遠。這可以防止你每週都在「重新發明廚房」。例如,我們不想突然把一家義大利餐廳變成燒烤店。
這些資訊很多,所以我透過下圖在 LLM 背景下用一個具體的數值例子進行了總結。但如果太複雜,請隨時跳過;你應該能順利理解文章的其餘部分。
我承認我可能在 PPO 的講解上做得太過頭了。但一旦寫下來,就很難刪掉。希望你們中有人會覺得它有用!
話雖如此,下一節相關的主要結論是 PPO 涉及多個模型:
- 策略(Policy):即經過 SFT 訓練且我們想要進一步對齊的 LLM。
- 獎勵模型(Reward Model):一個經過訓練以預測獎勵的模型(見 RLHF 第 2 步)。
- 評論家(Critic):一個可訓練的模型,用於估計獎勵。
- 參考模型(Reference Model,原始策略):我們用來確保策略不會偏離太遠的模型。
順便提一下,你可能會好奇為什麼我們既需要獎勵模型又需要評論家模型。獎勵模型通常在用 PPO 訓練策略之前就訓練好了。它是為了自動化人類評判的偏好標籤,並為策略 LLM 生成的完整回答評分。
相比之下,評論家評判的是部分回答。我們用它來建立最終回答。雖然獎勵模型通常保持凍結,但評論家模型在訓練期間會不斷更新,以便更好地估計獎勵模型產生的獎勵。
關於 PPO 的更多細節超出了本文的範圍,但感興趣的讀者可以在 InstructGPT 論文之前的這四篇論文中找到數學細節:
(1) Asynchronous Methods for Deep Reinforcement Learning (2016) 由 Mnih 等人撰寫,介紹了策略梯度方法作為基於深度學習的 RL 中 Q-learning 的替代方案。
(2) Proximal Policy Optimization Algorithms (2017) 由 Schulman 等人撰寫,提出了一種改進的基於近端策略的強化學習程序,比上述原始策略優化演算法更具數據效率和可擴展性。
(3) Fine-Tuning Language Models from Human Preferences (2020) 由 Ziegler 等人撰寫,展示了 PPO 和獎勵學習在預訓練語言模型上的概念,包括 KL 正則化以防止策略偏離自然語言太遠。
(4) Learning to Summarize from Human Feedback (2022) 由 Stiennon 等人撰寫,介紹了流行的 RLHF 三步程序,該程序後來也被用於 InstructGPT 論文。
RL 演算法:從 PPO 到 GRPO
如前所述,PPO 是 RLHF 中使用的原始演算法。從技術角度來看,它在用於開發推理模型的 RL 流水線中運行良好。然而,DeepSeek-R1 在其 RL 流水線中使用的是一種稱為群體相對策略優化(Group Relative Policy Optimization, GRPO)的演算法,該演算法是在他們早期的一篇論文中引入的:
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (2024)
DeepSeek 團隊將 GRPO 描述為:
PPO 的一種變體,它在增強數學推理能力的同時,優化了 PPO 的記憶體使用。
因此,這裡的核心動機是提高計算效率。
效率的提升是透過捨棄「評論家」(價值模型)來實現的,即不再需要計算價值函數(即預期未來獎勵)的 LLM。
GRPO 不依賴這個額外的模型來計算估計獎勵以得出優勢,而是採用了一種更簡單的方法:它從策略模型本身採樣多個答案,並利用它們的相對品質來計算優勢。
為了說明 PPO 和 GRPO 之間的區別,我借用了 DeepSeekMath 論文中的一張精美圖表:

Ahead of AI 是一份讀者支持的出版物。若要接收新文章並支持我的工作,請考慮成為免費或付費訂閱者。
RL 獎勵建模:從 RLHF 到 RLVR
到目前為止,我們將 RLHF 視為一個程序,並介紹了兩種常用於此的強化學習演算法:PPO 和 GRPO。
但如果 RLHF 已經是 LLM 對齊工具箱的核心部分,那麼這一切與推理有什麼關係呢?
RLHF 與推理之間的聯繫來自於 DeepSeek 團隊如何應用類似的基於 RL 的方法(使用 GRPO)來訓練其 R1 和 R1-Zero 模型的推理能力。
不同之處在於,DeepSeek-R1 團隊沒有依賴人類偏好並訓練獎勵模型,而是使用了可驗證獎勵(Verifiable Rewards)。這種方法被稱為可驗證獎勵強化學習(Reinforcement Learning with Verifiable Rewards, RLVR)。
再次值得強調的是:與標準 RLHF 相比,RLVR 繞過了對獎勵模型的需求。
因此,模型不是從人類標註的例子中學習什麼算作「好」答案,而是從確定性工具(如符號驗證器或基於規則的工具)獲得直接的二元回饋(正確或錯誤)。想像一下用於數學問題的計算機或用於程式碼生成的編譯器。
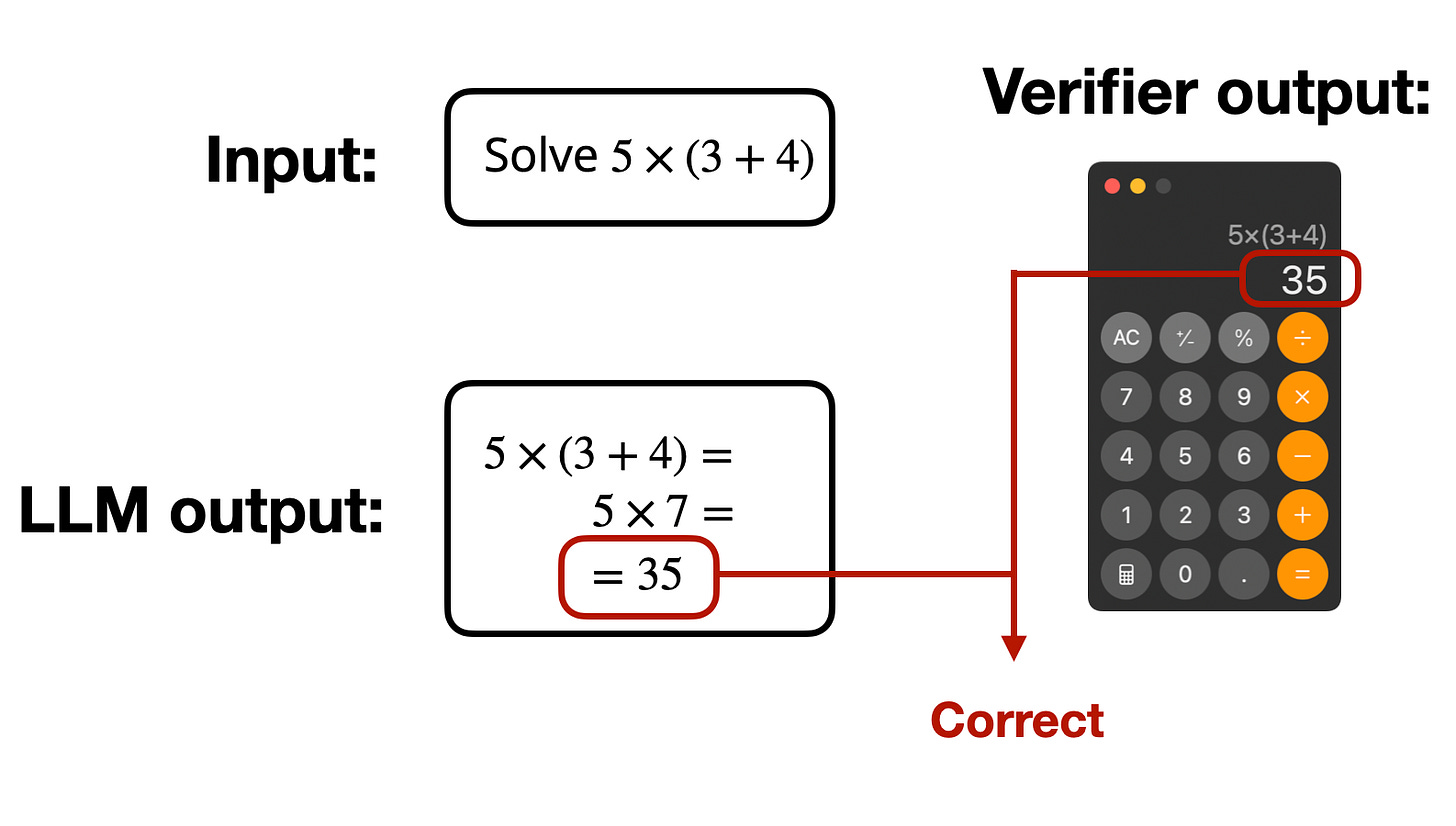
這裡的一個動機是透過在 RL 期間使用自動正確性檢查作為監督訊號,來避免雜訊大或昂貴的人類或學習獎勵。另一個動機是透過使用像計算機這樣「廉價」的工具,我們可以取代昂貴的獎勵模型訓練及獎勵模型本身。由於獎勵模型通常是整個預訓練模型(但帶有回歸頭),RLVR 的效率要高得多。
簡而言之,DeepSeek-R1 使用了帶有 GRPO 的 RLVR,這消除了訓練程序中兩個昂貴的模型:獎勵模型和價值模型(評論家),如下圖所示。

在下一節中,我想簡要回顧 DeepSeek-R1 的流水線,並討論 DeepSeek 團隊使用的不同可驗證獎勵。
DeepSeek-R1 推理模型是如何訓練的
現在我們已經釐清了 RLHF 和 RLVR,以及 PPO 和 GRPO,讓我們在 RL 和推理的背景下簡要回顧一下 DeepSeek-R1 論文的主要見解。
首先,有三類模型:
- DeepSeek-R1-Zero:純 RL 訓練。
- DeepSeek-R1:結合指令微調(SFT)和 RL 訓練。
- DeepSeek-Distill 變體:透過指令微調 SFT 建立,不含 RL。
我建立了一個 DeepSeek-R1 流水線圖來展示這些模型之間的關係,如下所示。

DeepSeek-R1-Zero 是使用帶有 GRPO 的可驗證獎勵(RLVR)訓練的,事實證明這足以讓模型透過生成中間步驟展現推理能力。這表明可以跳過 SFT 階段。模型透過探索而非從例子中學習來提高其推理能力。
DeepSeek-R1 是旗艦模型,性能最強。與 DeepSeek-R1-Zero 相比,區別在於他們交替進行了指令微調、RLVR 和 RLHF。
DeepSeek-Distill 變體 旨在成為小型且更易部署的模型;它們是透過使用來自 DeepSeek-R1 模型的指令數據對 Llama 3 和 Qwen 2.5 模型進行指令微調生成的。這種方法在推理部分沒有使用任何 RL(不過,RLHF 被用於建立 Llama 3 和 Qwen 2.5 基礎模型)。
有關解釋 DeepSeek-R1 流水線的更多細節,請參閱我之前的文章《理解推理 LLM》:
理解推理 LLM
這裡的主要結論是,DeepSeek 團隊沒有使用基於 LLM 的獎勵模型來訓練 DeepSeek-R1-Zero。相反,他們在 DeepSeek-R1-Zero 和 DeepSeek-R1 的推理訓練中使用了基於規則的獎勵:
我們在開發 DeepSeek-R1-Zero 時不採用結果或過程神經獎勵模型,因為我們發現神經獎勵模型在大規模強化學習過程中可能會遭受獎勵駭客(Reward hacking)攻擊 [...]
為了訓練 DeepSeek-R1-Zero,我們採用了一個基於規則的獎勵系統,主要由兩類獎勵組成:
(1) 準確性獎勵:準確性獎勵模型評估回答是否正確。例如,在具有確定性結果的數學問題中,模型被要求以指定格式(例如在方框內)提供最終答案,從而實現可靠的基於規則的正確性驗證。同樣,對於 LeetCode 問題,可以使用編譯器根據預定義的測試案例生成回饋。
(2) 格式獎勵:除了準確性獎勵模型外,我們還採用格式獎勵模型,強制模型將其思考過程放在 '<think>' 和 '</think>' 標籤之間。
近期關於訓練推理模型的 RL 論文啟示
我意識到引言(即到目前為止的所有內容)比我預期的要長得多。儘管如此,我認為這段冗長的引言對於將以下啟示放入背景中或許是必要的。
在上個月閱讀了大量關於推理模型的近期論文後,我在本節中總結了最有趣的觀點和見解。(像「[1]」這樣的參考文獻指向文章末尾列出的相應論文。)
1. 強化學習進一步提升蒸餾模型
原始的 DeepSeek-R1 論文清楚地表明,指令微調(SFT)後接強化學習(RL)的表現優於單純的 RL。
基於這一觀察,直觀上額外的 RL 應該能進一步改進蒸餾模型(因為蒸餾模型本質上代表了使用由較大模型生成的推理示例進行 SFT 訓練的模型)。
事實上,DeepSeek 團隊明確觀察到了這一現象:
此外,我們發現對這些蒸餾模型應用 RL 會產生顯著的進一步增益。我們認為這值得進一步探索,因此這裡僅展示簡單 SFT 蒸餾模型的結果。
多個團隊獨立驗證了這些觀察結果:
- [8] 使用 1.5B 的 DeepSeek-R1-Distill-Qwen 模型,研究人員證明僅需 7,000 個示例和 42 美元的適度算力預算,RL 微調就能帶來實質性的性能提升。令人印象深刻的是,這個小模型在 AIME24 數學基準測試中超越了 OpenAI 的 o1-preview。
- [15] 然而,另一個團隊警告說,這些增益可能並不總是具有統計顯著性。這表明,雖然 RL 可以改進較小的蒸餾模型,但基準測試結果有時可能會誇大這些改進。

2. 錯誤答案過長的問題
我之前提到,帶有可驗證獎勵的 RL(RLVR)並不嚴格要求 GRPO 演算法;DeepSeek 的 GRPO 只是剛好效率高且表現良好。
然而,[12] 表明,傳統 PPO 配合基本的二元正確性獎勵,就足以在推理能力和回答長度上擴展模型。
更有趣的是,PPO 和 GRPO 都有長度偏差。幾篇論文探討了應對過長錯誤答案的方法:
- [14] 提供了一份分析,說明 PPO 如何因損失計算中的數學偏差而無意中偏好較長的回答;GRPO 可能也存在同樣的問題。
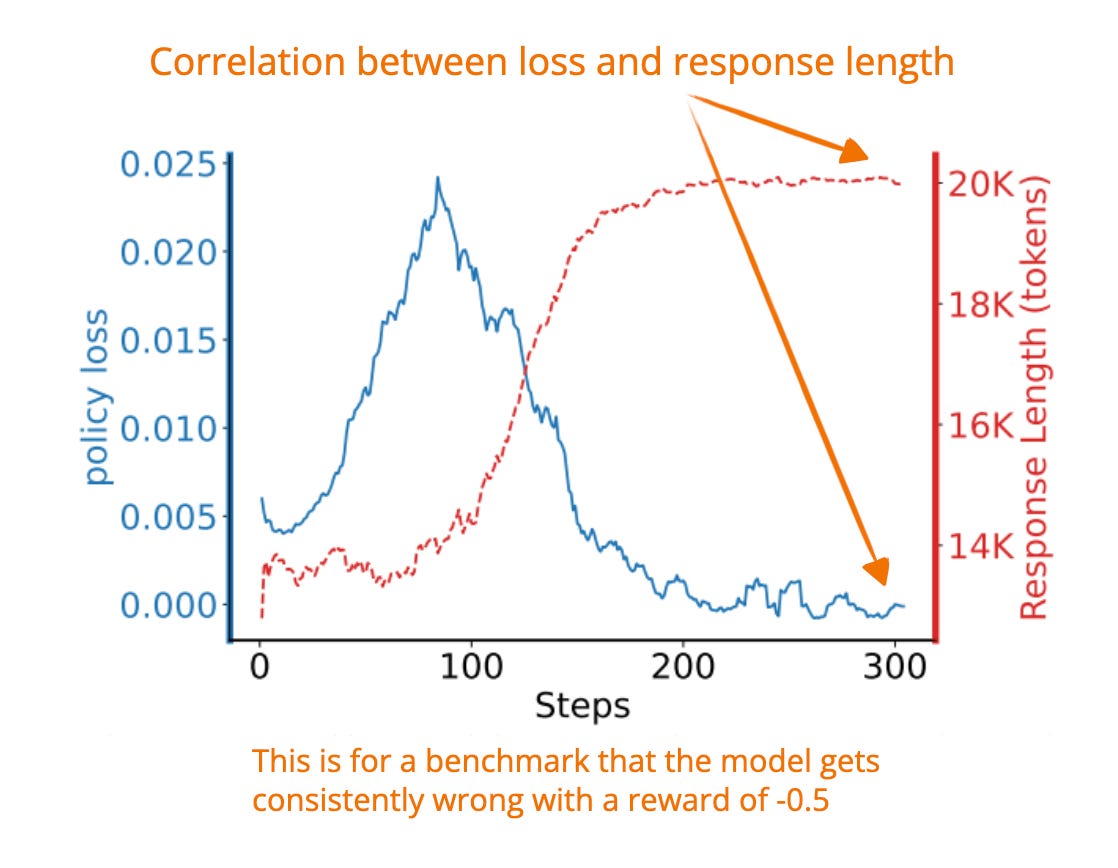
作為上述聲明的後續,[7] [10] 特別指出了 GRPO 中的長度和難度等級偏差。修改後的變體 "Dr. GRPO" 透過移除長度和標準差歸一化來簡化優勢計算,提供了更清晰的訓練訊號。
- [1] 在 GRPO 中顯式懲罰冗長的錯誤答案,同時獎勵簡潔正確的答案。
- [3] [6] 雖然沒有在 GRPO 中直接控制回答長度,但發現 token 級別的獎勵是有益的,能讓模型更好地專注於關鍵推理步驟。
- [5] 在 GRPO 中引入了對超過特定長度回答的顯式懲罰,從而在推論期間實現精確的長度控制。
3. 來自 RL 的湧現能力
除了 DeepSeek-R1 論文中提到的「AHA」時刻外,RL 已被證明能誘導模型產生寶貴的自我驗證和反思推理能力 [2] [9]。有趣的是,與 AHA 時刻類似,這些能力是在訓練過程中自然湧現的,無需顯式指令。
- [1] 表明擴展上下文長度(高達 128k token)能進一步提高模型的自我反思和自我糾錯能力。
4. 跨特定領域的泛化
到目前為止,大多數研究工作都集中在數學或程式碼背景下的推理任務。然而,[4] 透過在邏輯謎題上訓練模型展示了成功的泛化。在邏輯謎題上訓練的模型在數學推理任務中也取得了強勁表現。這證明了 RL 具有誘導獨立於特定領域知識的通用推理行為的能力。
5. 擴展到更廣泛的領域
作為上一節的後續,另一個有趣的見解 [11] 是推理能力可以自然地擴展到數學、程式碼和邏輯等結構化領域之外。
模型成功地將推理應用於醫學、化學、心理學、經濟學和教育等領域,利用生成式軟評分(Generative soft-scoring)方法有效處理自由格式的答案。
推理模型值得注意的下一步包括:
- 將現有的推理模型(如 o1、DeepSeek-R1)與外部工具使用和檢索增強生成(RAG)等能力相結合;OpenAI 剛發佈的 o3 模型正為此鋪路。
- 說到工具使用和搜尋,[9] 表明賦予推理模型搜尋能力會誘導出自我糾錯和跨基準測試的強健泛化等行為,儘管訓練數據集極小。
基於 DeepSeek-R1 團隊在維持知識型任務性能方面所做的努力,我相信為推理模型加入搜尋能力幾乎是不言而喻的選擇。
6. 推理完全歸功於 RL 嗎?
DeepSeek-R1(和 R1-Zero)背後的基本主張是 RLVR 顯式地誘導了推理能力。然而,最近的發現 [10] 表明,推理行為(包括「Aha 時刻」)可能已經存在於基礎模型中,這歸功於在廣泛的思維鏈數據上的預訓練。
我最近對 DeepSeek V3 基礎版和 R1 的比較強化了這一觀察,因為更新後的基礎模型也展現了類推理行為。例如,原始 V3 和 R1 模型之間的比較清楚地顯示了非推理模型和推理模型之間的區別:

然而,在比較更新後的 V3 基礎模型和 R1 時,情況不再如此:

此外,[13] 發現自我反思和自我糾錯行為在各種領域和模型規模的預訓練過程中逐步顯現。這進一步使將推理能力僅歸因於 RL 方法變得複雜。
或許結論是,RL 確實能將簡單的基礎模型轉變為推理模型。然而,這並非誘導或改進推理能力的唯一途徑。正如 DeepSeek-R1 團隊所展示的,蒸餾也能提高推理能力。既然在該論文中,蒸餾意味著在思維鏈數據上進行指令微調,那麼在包含思維鏈數據的數據上進行預訓練很可能也會誘導這些能力。(正如我在書中透過動手實作程式碼所解釋的,預訓練和指令微調畢竟都是基於相同的下一個 token 預測任務和損失函數。)
值得關注的訓練推理模型研究論文
在閱讀了上個月大量推理論文後,我嘗試在上一節總結最有趣的結論。然而,對於那些對來源細節感興趣的人,我還在下面列出了 15 篇相關論文作為選讀。(為簡單起見,以下摘要按日期排序。)
請注意,這份清單也並非詳盡無遺(我限制在 15 篇),因為這篇文章已經太長了!
[1] 擴展強化學習(與上下文長度)
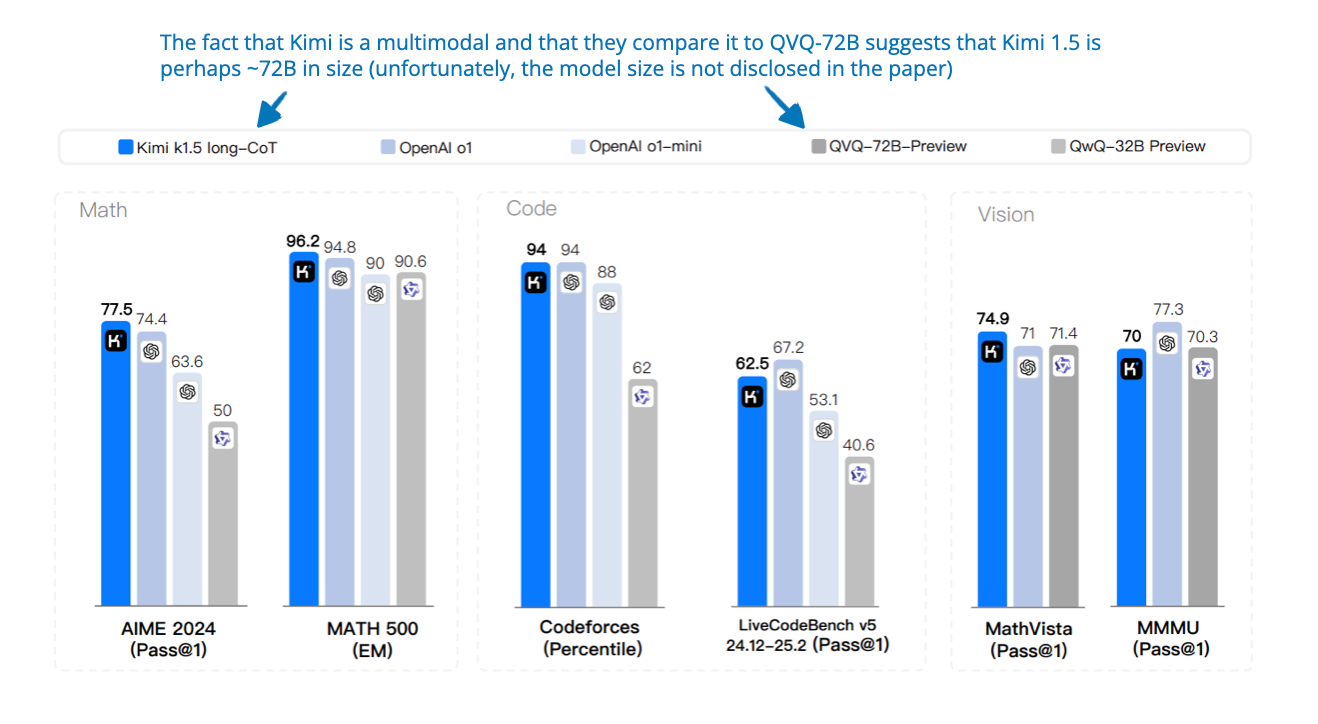
📄 1 月 22 日, Kimi k1.5: Scaling Reinforcement Learning with LLMs, https://arxiv.org/abs/2501.12599
有趣的是,這篇論文與 DeepSeek-R1 論文同一天發佈!在這裡,作者展示了一個透過 RL 訓練的多模態 LLM。與 DeepSeek-R1 類似,他們沒有使用過程獎勵模型(PRM),而是採用了可驗證獎勵。PRM 是一種用於 RL(特別是 LLM 訓練)的獎勵模型,它不僅評估最終答案,還評估導致該答案的推理步驟。
這裡的另一個核心思想是擴展上下文長度(高達 128k token)有助於模型在推理過程中進行規劃、反思和自我糾錯。因此,除了與 DeepSeek-R1 類似的正確性獎勵外,他們還有長度獎勵。具體來說,他們提倡簡短的正確回答,而錯誤的長答案會受到更多懲罰。
他們還提出了一種名為 long2short 的方法,將這些長思維鏈技能蒸餾到更高效的短 CoT 模型中。(它透過使用模型合併、最短拒絕採樣、DPO 和帶有更強長度懲罰的第二輪 RL 等方法,從長 CoT 模型中蒸餾出較短的正確回答。)
[2] 使用大型推理模型進行競技程式設計
📄 2 月 3 日, Competitive Programming with Large Reasoning Models, https://arxiv.org/abs/2502.06807
這篇來自 OpenAI 的論文評估了他們的 o 模型(如 o1、o1-ioi 和 o3)在競技程式設計任務中的表現。雖然它沒有深入探討如何應用 RL 的技術細節,但仍提供了一些有趣的啟示。
首先,這些模型是使用基於結果的 RL 訓練的,而不是基於過程的獎勵模型。這與 DeepSeek-R1 和 Kimi 的方法類似。
有趣的發現之一是 o3 可以學習自己的測試時(即推論時擴展)策略。例如,它經常會寫一個問題的簡單暴力破解版本(以效率換取正確性),然後用它來驗證其更優化解決方案的輸出。這種策略並非人工編碼的;模型是自己摸索出來的。
因此總體而言,論文認為擴展通用 RL 允許模型開發自己的推理和驗證方法,而不需要任何人類啟發式方法或特定領域的推論流水線。相比之下,其他(早期)模型如 o1-ioi 依賴於手工製作的測試時策略,如對數千個樣本進行聚類並重新排名,這需要大量的人工設計和調整。

[3] 探索結果獎勵的極限
📄 2 月 10 日, Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning, https://arxiv.org/abs/2502.06781
這篇論文探討了僅憑二元「正確」或「錯誤」回饋(如 DeepSeek-R1)在解決數學問題上能走多遠。為此,他們首先使用 Best-of-N 採樣收集正向示例並對其應用行為克隆(Behavior cloning),他們證明這在理論上足以優化策略。
為了應對稀疏獎勵的挑戰(特別是當長思維鏈包含部分正確步驟時),他們加入了一個 token 級別的獎勵模型,該模型學習為推理的不同部分分配重要性權重。這有助於模型在學習時專注於最關鍵的步驟,並提高整體性能。
[4] 帶有規則強化學習的 LLM 推理(邏輯數據)
📄 2 月 20 日, Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning, https://arxiv.org/abs/2502.14768
DeepSeek-R1 專注於數學和程式碼任務。這篇論文使用邏輯謎題作為主要訓練數據訓練了一個 7B 模型。
研究人員採用了與 DeepSeek-R1 類似的基於規則的 RL 設置,但進行了幾項調整:
- 他們引入了嚴格的格式獎勵,懲罰捷徑並確保模型使用
<think>和<answer>標籤將其推理與最終答案分開。 - 他們還使用了一個系統提示,顯式告訴模型在給出最終答案之前先逐步思考問題。
即使只有 5,000 個合成邏輯問題,模型也發展出了良好的推理技能,能很好地泛化到 AIME 和 AMC 等更難的數學基準測試。
這特別有趣,因為它表明基於邏輯的 RL 訓練可以教導模型以超越原始領域的方式進行推理。

[5] 控制推理模型的思考時長
📄 3 月 6 日, L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning, https://arxiv.org/abs/2503.04697
推理模型的一個標誌是,由於思維鏈推理,它們傾向於生成更長的輸出。但預設情況下,沒有顯式的方法來控制回答的長度。
這篇論文介紹了長度控制策略優化(Length Controlled Policy Optimization, LCPO),這是一種簡單的強化學習方法,可幫助模型遵守用戶指定的長度限制,同時仍能優化準確性。
簡而言之,LCPO 類似於 GRPO,即「GRPO + 用於長度控制的自定義獎勵」,實現方式如下:
目標長度作為用戶提示的一部分提供。上述 LCPO 方法鼓勵模型精確遵守提供的目標長度。
此外,他們還引入了 LCPO-Max 變體,它不鼓勵模型精確匹配目標長度,而是鼓勵模型保持在最大 token 長度以下。
作者使用 LCPO 訓練了一個名為 L1 的 1.5B 模型,該模型可以根據提示調整其輸出長度。這讓用戶可以根據任務在準確性和算力之間進行權衡。有趣的是,論文還發現這些長鏈模型在短推理方面也變得出奇地好,在相同 token 長度下甚至優於 GPT-4o 等大得多的模型。

[6] 激勵 LLM 的搜尋能力
📄 3 月 10 日, R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.05592
像 DeepSeek-R1 這樣透過 RL 訓練的推理模型依賴於其內部知識。本文作者專注於透過增加對外部搜尋系統的訪問,來改進這些模型在需要時效性或最新資訊的知識型任務上的表現。
因此,這篇論文透過教導模型在推理過程中使用外部搜尋系統來改進它們。作者沒有依賴測試時策略或監督訓練,而是使用了一種兩階段強化學習方法,幫助模型學習如何以及何時自行搜尋。模型首先學習搜尋格式,然後學習如何使用搜尋結果來找到正確答案。

[7] 大規模開源 LLM 強化學習
📄 3 月 18 日, DAPO: An Open-Source LLM Reinforcement Learning System at Scale, https://arxiv.org/abs/2503.14476
雖然這篇論文主要是關於開發類似 DeepSeek-R1 的訓練流水線並將其開源,但它也對 DeepSeek-R1 訓練中使用的 GRPO 演算法提出了有趣的改進。
- Clip-higher:增加 PPO 裁剪範圍的上界,以鼓勵探索並防止訓練期間的熵崩潰。
- 動態採樣:透過過濾掉所有採樣回答始終正確或始終錯誤的提示,來提高訓練效率。
- Token 級別策略梯度損失:從樣本級別轉向 token 級別的損失計算,使較長的回答能對梯度更新產生更多影響。*
- 過長獎勵塑造:對因過長而被截斷的回答增加軟懲罰,這減少了獎勵雜訊並有助於穩定訓練。
*標準 GRPO 使用樣本級別的損失計算。這涉及首先對每個樣本的 token 取平均損失,然後對樣本取平均損失。由於樣本權重相等,較長回答樣本中的 token 對總體損失的貢獻可能成比例地減少。同時,研究人員觀察到較長的回答在最終答案之前通常包含胡言亂語,而這些胡言亂語在原始 GRPO 樣本級別損失計算中不會受到足夠的懲罰。

[8] 小型 LLM 推理的強化學習
📄 3 月 20 日, Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't, https://arxiv.org/abs/2503.16219
原始的 DeepSeek-R1 論文顯示,在開發小型推理模型時,蒸餾比純 RL 效果更好。在這篇論文中,研究人員對此進行了後續研究,並調查了進一步利用 RL 改進小型蒸餾推理模型的方法。
因此,使用 1.5B 的 DeepSeek-R1-Distill-Qwen 模型,他們發現僅需 7000 個訓練示例和 42 美元的算力預算,RL 微調就能帶來強勁的改進。在這種情況下,改進足以讓其在 AIME24 數學基準測試中超越 OpenAI 的 o1-preview。
此外,該論文還有 3 個有趣的學習點:
- 小型 LLM 可以在前 50-100 個訓練步驟內,使用精簡的高品質數據集實現快速的推理改進。但如果訓練持續太久,性能會迅速下降,這主要是由於長度限制和輸出不穩定。
- 混合難易程度不同的問題有助於模型在訓練早期產生較短、更穩定的回答。然而,性能仍會隨時間推移而退化。
- 使用餘弦形狀的獎勵函數有助於更有效地控制輸出長度,並提高訓練一致性。但與標準的基於準確性的獎勵相比,這會略微降低峰值性能。

[9] 學習帶有搜尋的推理
📄 3 月 25 日, ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning, https://arxiv.org/abs/2503.19470
本論文提出的 ReSearch 框架擴展了 DeepSeek-R1 論文中的 RL 方法,將搜尋結果納入推理過程。模型根據其正在進行的推理鏈學習何時以及如何搜尋,然後將檢索到的資訊用於後續的推理步驟。
這一切都是在沒有推理步驟監督數據的情況下完成的。研究人員還表明,這種方法可以引發自我糾錯和反思等有用行為,並且儘管僅在一個數據集上訓練,但在多個基準測試中都能很好地泛化。

PS:這種方法與之前討論的 R1-Searcher 有何不同?
R1-Searcher 使用兩階段、基於結果的強化學習方法。在第一階段,它教導模型如何調用外部檢索;在第二階段,它學習使用檢索到的資訊來回答問題。
相比之下,ReSearch 將搜尋直接整合到推理過程中。它使用強化學習進行端到端訓練,不對推理步驟進行任何監督。諸如反思錯誤查詢並糾正它們等行為是在訓練過程中自然湧現的。
[10] 理解類 R1-Zero 訓練
📄 3 月 26 日, Understanding R1-Zero-Like Training: A Critical Perspective, https://arxiv.org/abs/2503.20783
這篇論文調查了為什麼 DeepSeek-R1-Zero 的純 RL 方法能有效提高推理能力。
作者發現,像 Qwen2.5 這樣的一些基礎模型在沒有任何 RL 的情況下就已經展現出強大的推理能力,甚至出現了「Aha 時刻」。因此,「Aha 時刻」可能不是由 RL 誘導的,而是繼承自預訓練。這挑戰了 RL 獨自創造深度推理行為的觀點。
論文還指出了 GRPO 中的兩個偏差:
- 回答長度偏差:GRPO 將優勢除以回答的長度。這使得長錯誤答案受到的懲罰較小,因此模型學會產生更長的壞答案。
- 難度等級偏差:GRPO 還按每個問題獎勵的標準差進行歸一化。難易程度極端的問題(獎勵方差低)會被過度加權。
為了修正這一點,作者引入了 Dr. GRPO,這是對標準 GRPO 的修改。在這裡,他們取消了優勢計算中的回答長度歸一化。此外,他們還取消了問題級別的標準差。這將導致更高效的訓練和更少不必要的長答案。特別是如果模型出錯,不再鼓勵生成長答案。
[11] 在不同領域擴展帶有可驗證獎勵的 RL
📄 3 月 31 日, Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains, https://arxiv.org/abs/2503.23829
DeepSeek-R1 和隨後的大多數推理模型都專注於來自程式碼和數學等易於驗證領域的獎勵訊號。這篇論文探索了如何將這些方法擴展到醫學、化學、心理學、經濟學和教育等更複雜的領域,在這些領域中,答案通常是自由格式的,且難以驗證(超出簡單的正確/錯誤)。
作者發現,使用專家撰寫的參考答案使得評估比預期更可行,即使在這些更廣泛的領域也是如此。為了提供獎勵訊號,他們引入了一種生成式軟評分方法,而不需要繁重的特定領域標註。
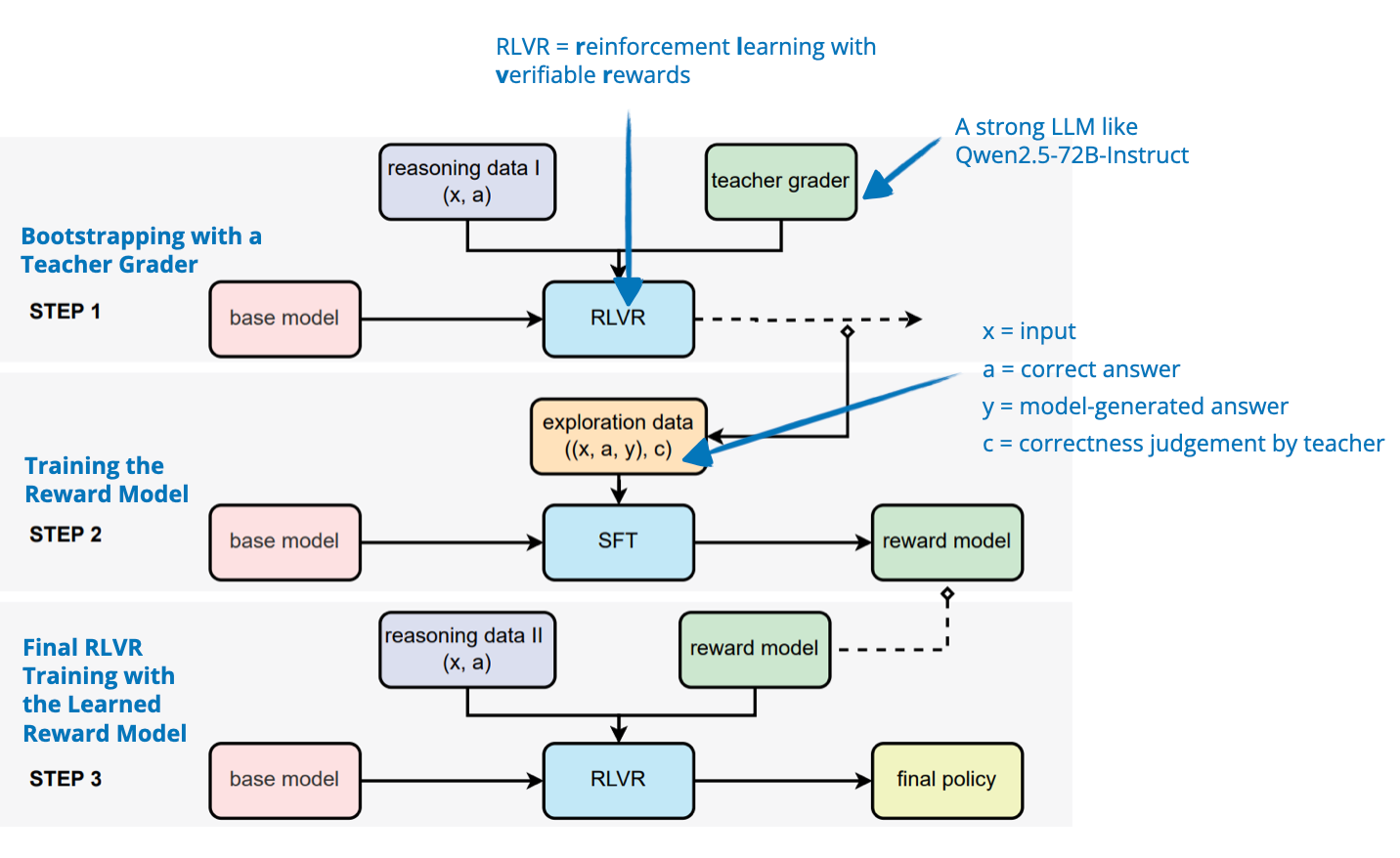
[12] 擴展強化學習(使用簡單設置)
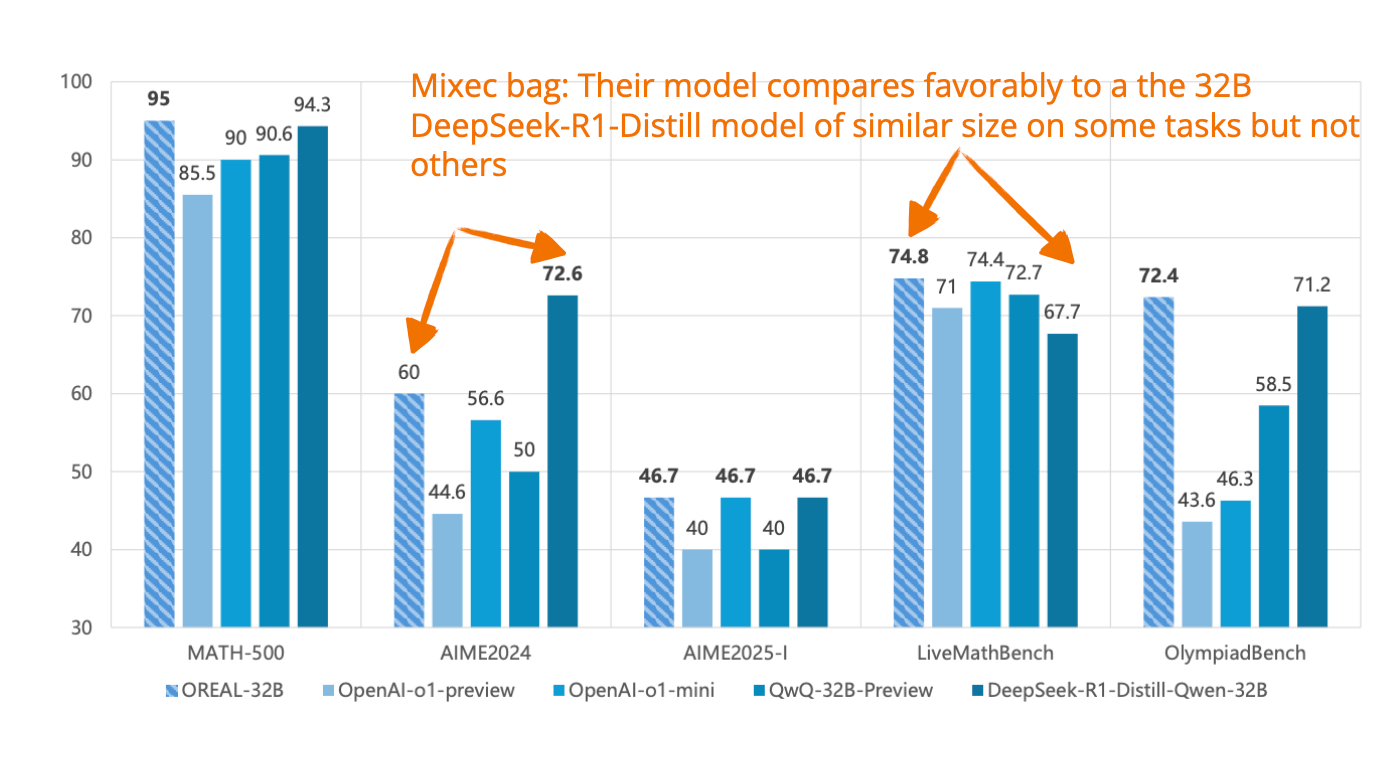
📄 3 月 31 日, Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model, https://arxiv.org/abs/2503.24290
在這篇論文中,作者探索了一種用於推理任務訓練 LLM 的極簡強化學習設置。他們使用傳統 PPO 而非 GRPO(DeepSeek-R1-Zero 所使用的),並跳過了 RLHF 流水線中通常包含的 KL 正則化。
有趣的是,他們發現這種簡單的設置(傳統 PPO 和基於答案正確性的基本二元獎勵函數)足以訓練出在推理性能和回答長度上都能擴展的模型。
使用與 DeepSeek-R1-Zero 相同的 Qwen-32B 基礎模型,他們的模型在多個推理基準測試中表現優於前者,同時僅需 1/10 的訓練步驟。

[13] 重新思考預訓練中的反思
📄 4 月 5 日, Rethinking Reflection in Pre-Training, https://arxiv.org/abs/2504.04022
基於 DeepSeek-R1 論文中有趣的見解(即對基礎模型應用純 RL),我們認為 LLM 的推理能力源自 RL。這篇論文提供了一個轉折,稱自我糾錯在預訓練早期就已經出現了。
具體來說,透過在任務中引入刻意出錯的思維鏈,作者測量模型是否能識別並糾正這些錯誤。他們發現,顯式和隱式形式的反思在整個預訓練過程中穩步顯現。這發生在許多領域和模型規模中。即使是相對早期的檢查點也顯示出自我糾錯的跡象,並且隨著預訓練算力的增加,這種能力變得更強。

[14] 透過強化學習實現簡潔推理
📄 4 月 7 日, Concise Reasoning via Reinforcement Learning, https://arxiv.org/abs/2504.05185
眾所周知,推理模型通常會生成較長的回答,這增加了計算成本。現在,這篇新論文表明,這種行為源於 RL 訓練過程,而非為了更好的準確性而對長答案的實際需求。當模型獲得負向獎勵時,RL 損失傾向於偏好較長的回答,我認為這解釋了純 RL 訓練中出現的「Aha」時刻和較長的思維鏈。
也就是說,如果模型獲得負向獎勵(即答案錯誤),PPO 背後的數學原理會導致當回答較長時,平均每 token 損失變得更小。因此,模型被間接鼓勵使回答變長。即使那些額外的 token 實際上對解決問題沒有幫助,情況也是如此。
回答長度與損失有什麼關係?當獎勵為負時,較長的回答可以稀釋每個單獨 token 的懲罰,從而導致較低(即較好)的損失值(儘管模型仍然答錯了)。因此模型「學會」了較長的回答可以減輕懲罰,儘管它們對正確性沒有幫助。
然而,必須強調的是,這項分析是針對 PPO 進行的:
值得注意的是,我們目前的分析不適用於 GRPO,對此類方法的精確分析留待未來工作。
此外,研究人員表明,第二輪 RL(僅使用一些有時可解的問題)可以在保持甚至提高準確性的同時縮短回答。這對部署效率具有重大意義。
[15] 冷靜審視語言模型推理的進展
📄 4 月 9 日, A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility, https://arxiv.org/abs/2504.07086
這篇論文仔細研究了最近關於 RL 可以改進蒸餾語言模型(如基於 DeepSeek-R1 的模型)的主張。
例如,我之前討論過「3 月 20 日, Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't」這篇論文,它發現 RL 對蒸餾模型有效。
DeepSeek-R1 論文也提到:
此外,我們發現對這些蒸餾模型應用 RL 會產生顯著的進一步增益。我們認為這值得進一步探索,因此這裡僅展示簡單 SFT 蒸餾模型的結果。
因此,雖然早期的論文報告了 RL 帶來的巨大性能提升,但這項工作發現許多改進可能只是雜訊。作者表明,在 AIME24 等小型基準測試上的結果非常不穩定:僅僅更改隨機種子就可能使分數移動幾個百分點。
當 RL 模型在更受控和標準化的設置下進行評估時,增益證明比最初報告的小得多,且通常不具統計顯著性。然而,一些用 RL 訓練的模型確實顯示出適度的改進,但這些改進通常比指令微調所能達到的要弱,且往往不能很好地泛化到新的基準測試。
因此,雖然 RL 在某些情況下可能有助於改進較小的蒸餾模型,但這篇論文認為其益處被誇大了,需要更好的評估標準來了解什麼是真正有效的。
本雜誌是一個個人熱情項目。為了支持我作為一名獨立研究員,請考慮購買我的書《從零開始構建大型語言模型》(Build a Large Language Model (From Scratch)),或註冊付費訂閱。

如果你讀過這本書並有幾分鐘空閒時間,我會非常感激你的簡短評論。這對我們作者幫助很大!
你的支持意義重大!謝謝!
相關文章