從零開始理解大型語言模型評估的四種主要方法
本文提供大型語言模型四種主要評估方法的全面概述與程式碼實作,包含選擇題基準測試、驗證器、排行榜以及大型語言模型裁判,並深入探討其優缺點。
深入淺出:理解 LLM 評估的 4 種主要方法(從零開始)
選擇題基準測試、驗證器、排行榜與 LLM 裁判,附帶程式碼範例
我們究竟該如何評估大型語言模型(LLM)?這是一個簡單的問題,但往往會引發更深層次的討論。
在提供諮詢或參與專案協作時,我最常被問到的問題之一就是:如何在不同模型之間做選擇,以及如何解讀現有的評估結果。(當然,還有在微調或開發自己的模型時,該如何衡量進度。)
既然這個問題如此頻繁地出現,我想分享一份關於人們用來比較 LLM 的主要評估方法的簡短概述,應該會很有幫助。當然,LLM 評估是一個非常大的課題,無法在單一資源中詳盡涵蓋,但我認為對這些主要方法有一個清晰的腦圖,會讓你更容易解讀基準測試(Benchmarks)、排行榜(Leaderboards)和論文。
我原本計劃將這些評估技術納入我即將出版的新書《Build a Reasoning Model (From Scratch)》中,但它們最終超出了核心範圍。(該書本身更側重於基於驗證器的評估。)因此,我認為將其作為一篇帶有從零開始的程式碼範例的長篇文章來分享會很不錯。
在《Build a Reasoning Model (From Scratch)》中,我採用實作方式從頭開始構建一個推理型 LLM。如果你喜歡《Build a Large Language Model (From Scratch)》,這本書在風格上非常相似,都是使用純 PyTorch 從零開始構建一切。
這本書目前處於早期預閱階段,已有超過 100 頁內容上線,我剛剛完成了另外 30 頁,目前正由排版團隊添加中。如果你加入了早期預閱計劃(非常感謝你的支持!),當這些內容上線時,你應該會收到電子郵件通知。
註:目前 LLM 研究領域動態非常多。我仍在消化我那不斷增長的書籤論文清單,並計劃在下一篇文章中重點介紹一些最有趣的論文。
現在,讓我們來討論四種主要的 LLM 評估方法,以及它們的從零開始程式碼實現,以便更好地理解它們的優缺點。
理解 LLM 的主要評估方法
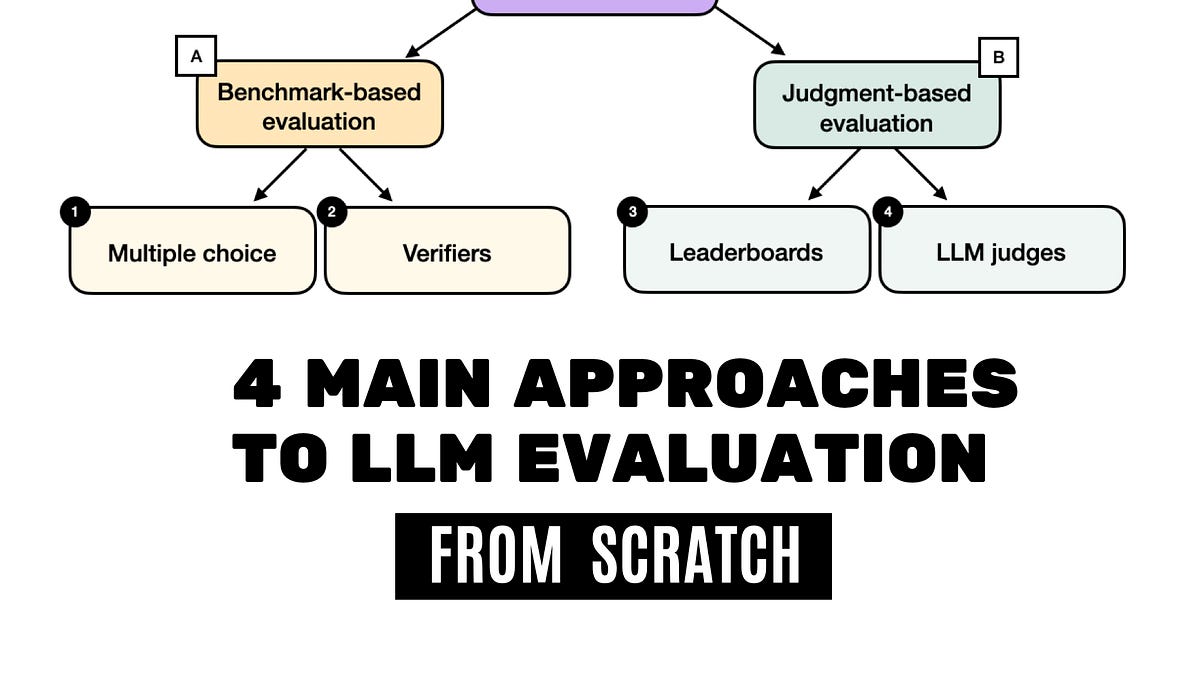
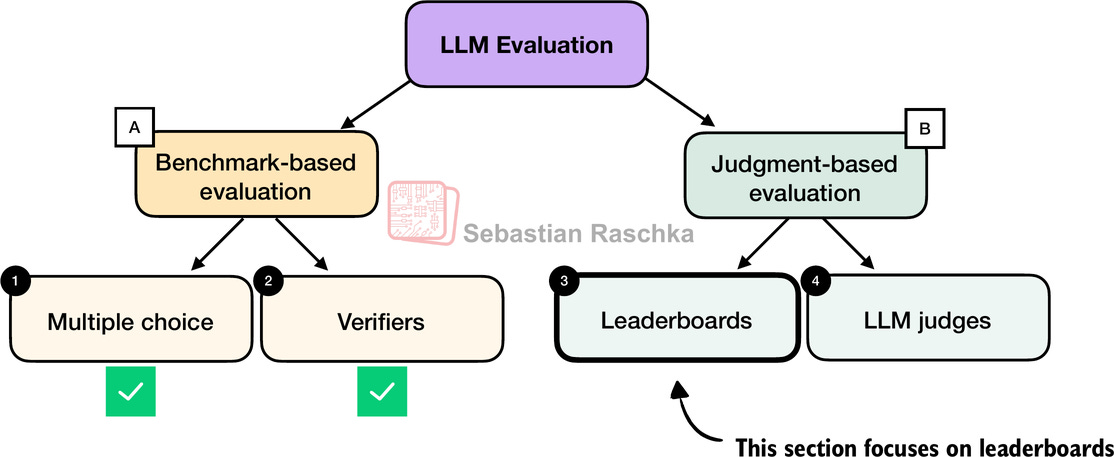
在實踐中,評估已訓練 LLM 的常見方式有四種:選擇題、驗證器、排行榜和 LLM 裁判,如下圖 1 所示。研究論文、行銷材料、技術報告和模型卡(Model Cards,LLM 專用技術報告的術語)通常會包含這四類中兩類或以上的結果。
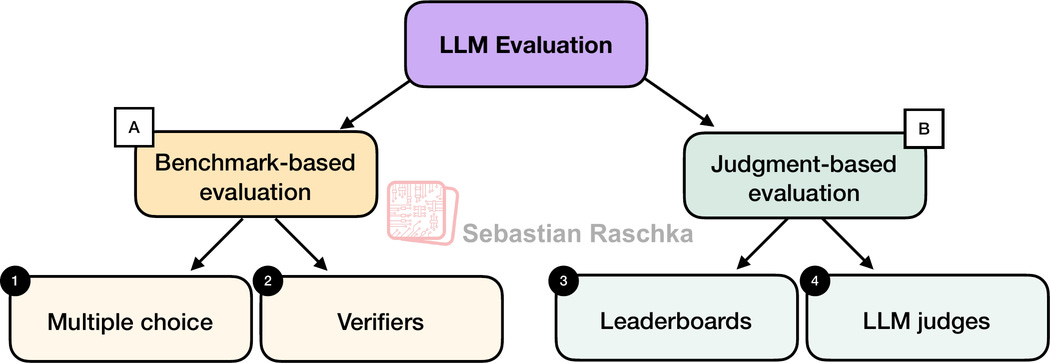
此外,這裡介紹的四個類別可以分為兩組:基於基準測試(Benchmark-based)的評估和基於判斷(Judgment-based)的評估,如上圖所示。
(還有其他衡量指標,如訓練損失、困惑度 [Perplexity] 和獎勵值,但這些通常用於模型開發過程中的內部監控。)
以下小節提供了這四種方法中每一種的簡要概述和範例。
方法 1:評估答案選項的準確性
我們從基於基準測試的方法開始:選擇題問答。
從歷史上看,最廣泛使用的評估方法之一是選擇題基準測試,例如 MMLU(Massive Multitask Language Understanding 的縮寫,https://huggingface.co/datasets/cais/mmlu)。為了說明這種方法,圖 2 顯示了 MMLU 數據集中的一個代表性任務。
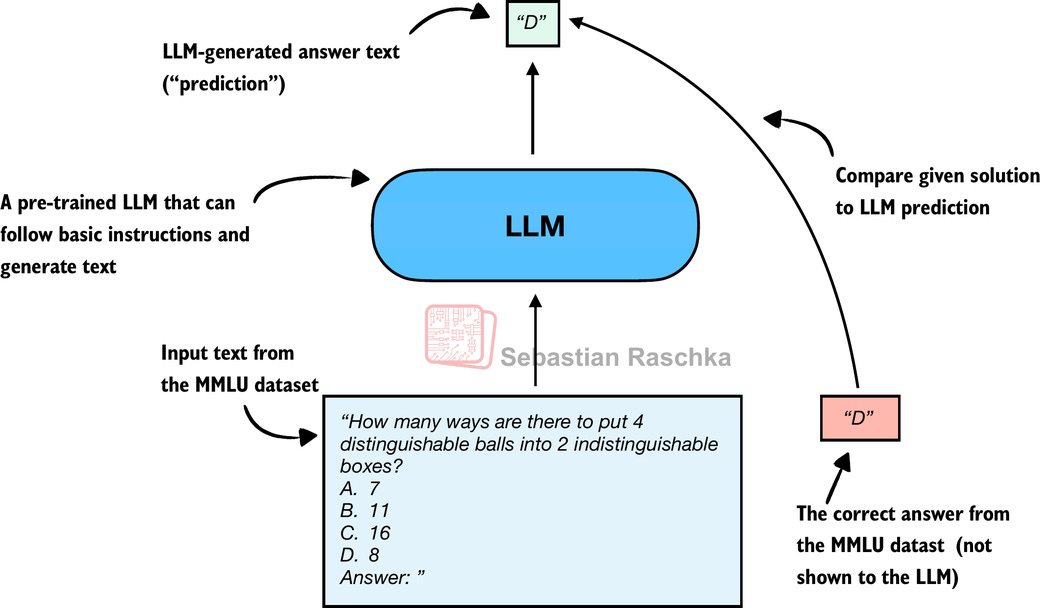
圖 2 僅顯示了 MMLU 數據集中的一個範例。完整的 MMLU 數據集包含 57 個學科(從高中數學到生物學),總共約有 1.6 萬個選擇題,性能以準確率(正確回答問題的比例)來衡量,例如,如果 16,000 個問題中有 14,000 個回答正確,則準確率為 87.5%。
選擇題基準測試(如 MMLU)以一種直觀、可量化的方式測試 LLM 的知識檢索能力,類似於標準化考試、許多學校考試或駕駛執照筆試。
請注意,圖 2 顯示的是選擇題評估的簡化版本,即直接將模型預測的答案字母與正確答案進行比較。還存在另外兩種涉及對數機率(Log-probability)評分的流行方法。我已在 GitHub 上實現了它們。(由於這是建立在本文解釋的概念之上,建議在閱讀完本文後再查看。)
以下小節說明了如何用程式碼實現圖 2 所示的 MMLU 評分。
1.2 加載模型
首先,在我們對 MMLU 進行評估之前,必須加載預訓練模型。在這裡,我們將使用純 PyTorch 從零開始實現的 Qwen3 0.6B,它僅需要約 1.5 GB 的 RAM。
請注意,Qwen3 模型的實現細節在這裡並不重要;我們只是將其視為一個想要評估的 LLM。不過,如果你感興趣,可以在我之前的《Understanding and Implementing Qwen3 From Scratch》文章中找到從零開始的實現演練,原始碼也可以在 GitHub 上找到。
我們不直接複製貼上多行 Qwen3 原始碼,而是從我的 reasoning_from_scratch Python 庫中導入,該庫可以通過以下方式安裝:
或
程式碼塊 1:加載預訓練模型
1.3 檢查生成的答案字母
在本節中,我們實現最簡單且可能最直觀的 MMLU 評分方法,該方法依賴於檢查生成的選擇題答案字母是否與正確答案匹配。這與之前圖 2 中說明的類似,為了方便起見,下面再次顯示。
為此,我們將使用 MMLU 數據集中的一個範例:
接下來,我們定義一個函數來格式化 LLM 提示詞(Prompts)。
程式碼塊 2:格式化提示詞
讓我們對 MMLU 範例執行該函數,以了解格式化後的 LLM 輸入是什麼樣的:
輸出為:
How many ways are there to put 4 distinguishable balls into 2indistinguishable boxes?
如上所示,模型提示詞為模型提供了一個不同答案選項的列表,並以「Answer: 」文本結尾,以鼓勵模型生成正確答案。
雖然不是絕對必要,但有時在輸入中提供額外的問題及正確答案也會很有幫助,這樣模型可以觀察到預期如何解決任務。(例如,提供 5 個範例的情況也被稱為 5-shot MMLU。)然而,對於當前一代的 LLM 來說,即使是基礎模型也相當強大,這通常不是必需的。
加載不同的 MMLU 樣本
你可以直接通過 datasets 庫加載 MMLU 數據集的範例(可以通過 pip install datasets 或 uv add datasets 安裝):
上面我們使用了「high_school_mathematics」子集;要獲取其他子集的列表,請使用以下程式碼:
接下來,我們對提示詞進行分詞(Tokenize),並將其包裝在 PyTorch 張量對象中作為 LLM 的輸入:
設置完成後,我們在下面定義主要的評分函數,它會生成幾個 Token(這裡預設為 8 個 Token),並提取模型打印的第一個 A/B/C/D 字母。
程式碼塊 3:提取生成的字母
然後,我們可以使用上述程式碼塊中的函數檢查生成的字母,如下所示:
結果為:
我們可以看到,在這種情況下,生成的答案是不正確的(False)。
這只是 MMLU 中 high_school_mathematics 子集 270 個範例中的一個。下面的截圖(圖 4)顯示了基礎模型和推理變體在整個子集上執行時的性能。相關程式碼可在 GitHub 上找到。
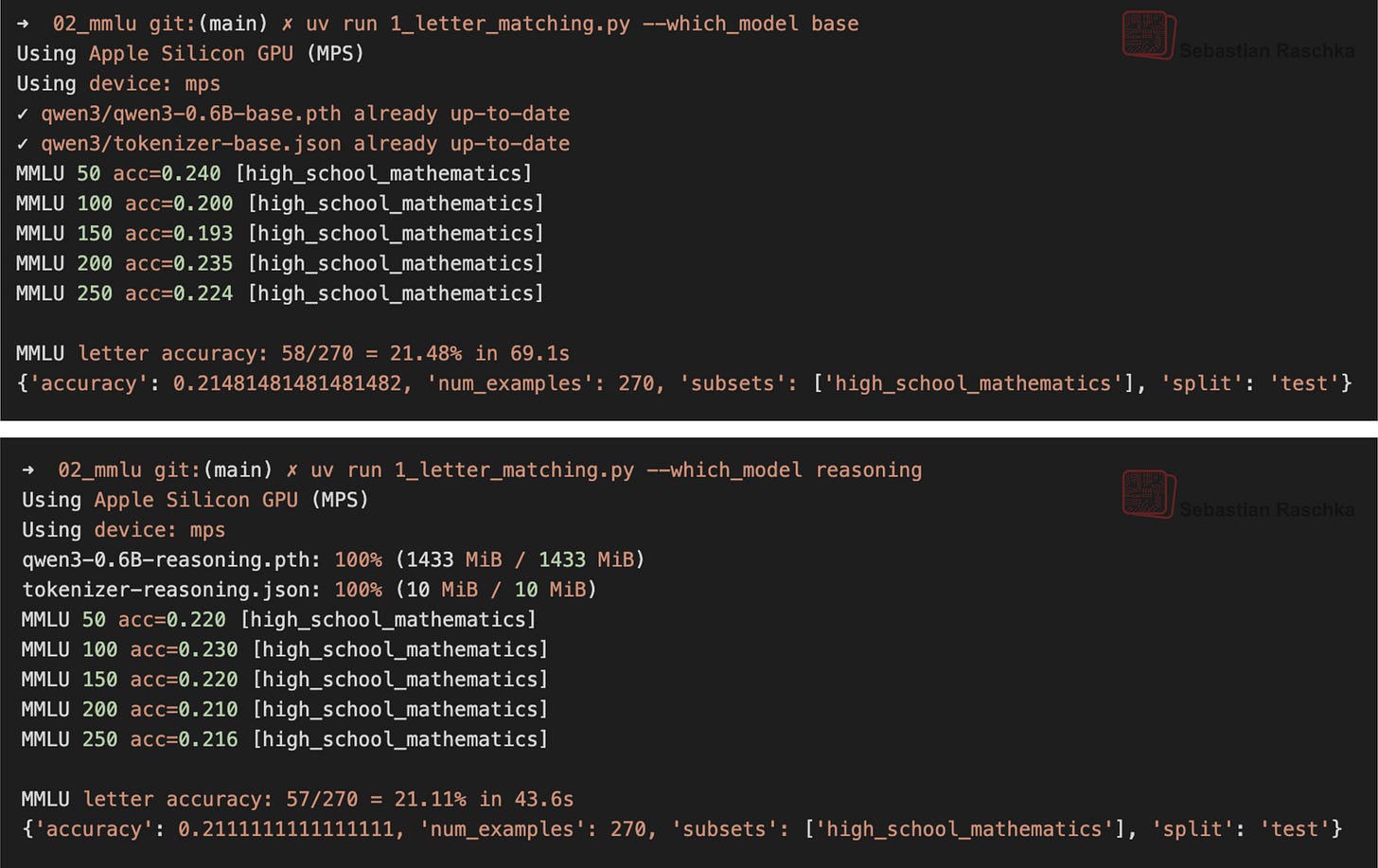
假設問題的答案機率相等,隨機猜測者(以均勻機率選擇 A、B、C 或 D)預計會達到 25% 的準確率。因此,基礎模型和推理模型目前表現都不算太好。
選擇題答案格式
請注意,本節為了說明目的實現了選擇題評估的簡化版本,即直接將模型預測的答案字母與正確答案進行比較。在實踐中,存在更廣泛使用的變體,例如對數機率評分,我們會衡量模型認為每個候選答案的可能性,而不僅僅是檢查最終的字母選擇。(我們在第 4 章討論基於機率的評分。)對於推理模型,評估還可能涉及在提供正確答案作為輸入時,評估生成該答案的可能性。
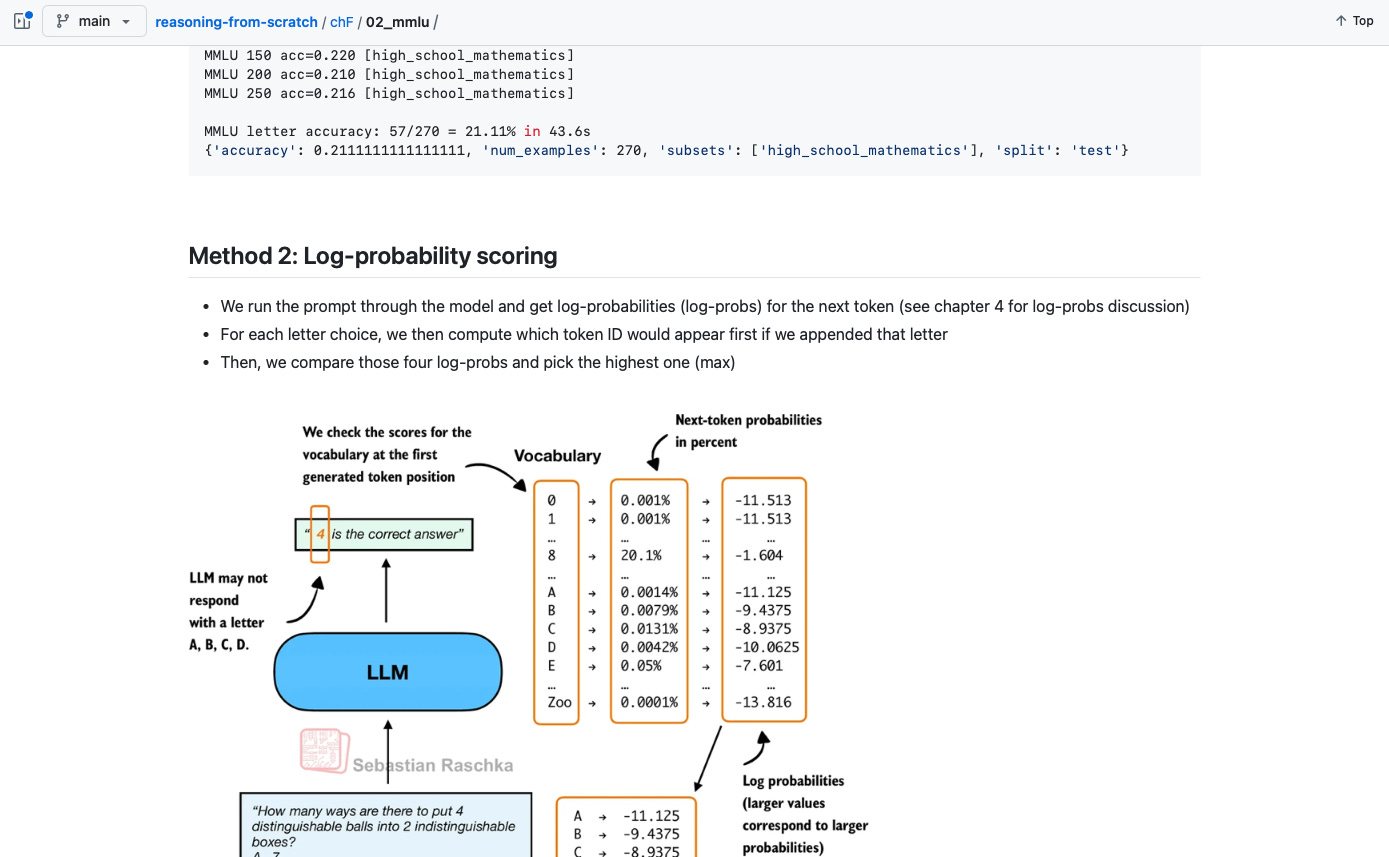
然而,無論我們使用哪種 MMLU 評分變體,評估仍然等同於檢查模型是否從預定義的答案選項中進行選擇。
像 MMLU 這樣的選擇題基準測試的一個局限性是,它們僅衡量 LLM 從預定義選項中進行選擇的能力,因此除了檢查模型與基礎模型相比是否遺忘以及遺忘了多少知識外,對於評估推理能力並非特別有用。它無法捕捉自由格式的寫作能力或現實世界的實用性。
儘管如此,選擇題基準測試仍然是簡單且有用的診斷工具:例如,高 MMLU 分數並不一定意味著模型在實際使用中很強,但低分可以凸顯潛在的知識差距。
方法 2:使用驗證器檢查答案
與上一節討論的選擇題問答相關,基於驗證(Verification-based)的方法通過準確率指標來量化 LLM 的能力。然而,與選擇題基準測試不同,驗證方法允許 LLM 提供自由格式的答案。然後我們提取相關的答案部分,並使用所謂的驗證器(Verifier)將答案部分與數據集中提供的正確答案進行比較,如下圖 6 所示。
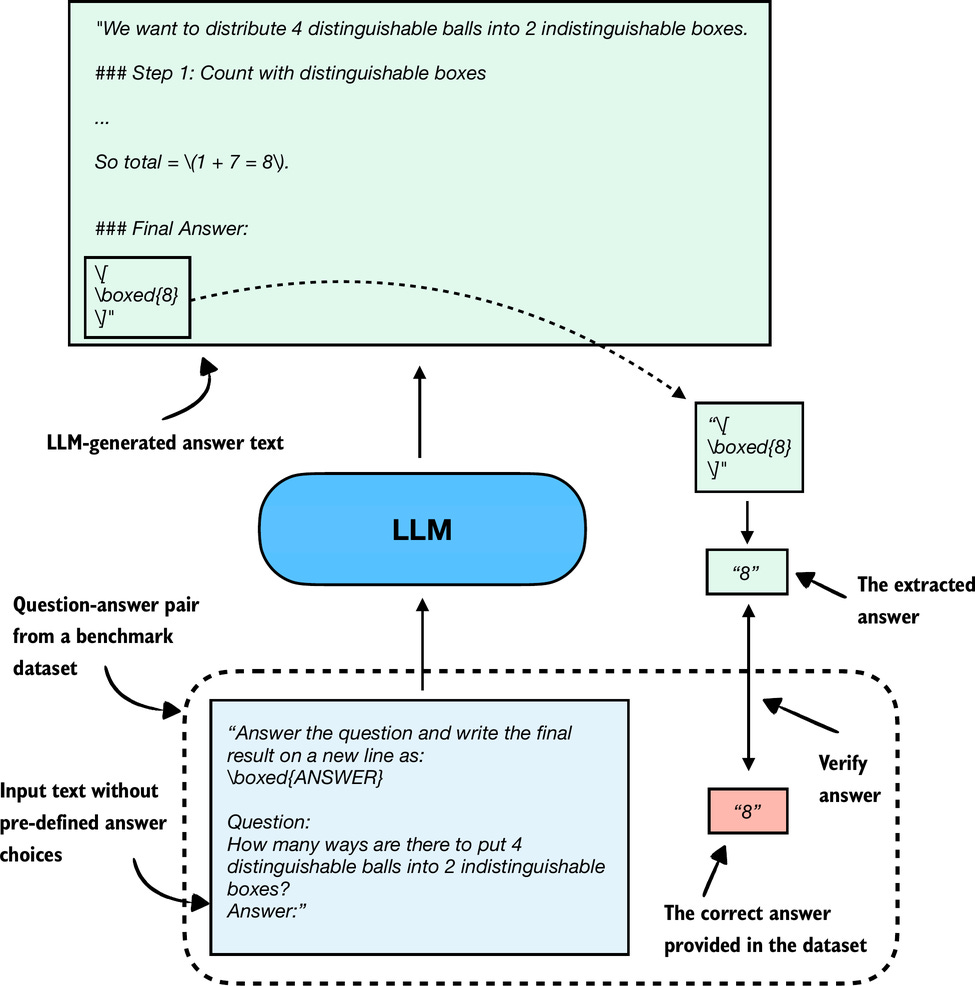
當我們將提取的答案與提供的答案進行比較時(如上圖所示),我們可以採用外部工具,例如程式碼解釋器或類似計算機的工具/軟體。
缺點是這種方法只能應用於易於(且理想情況下是確定性地)驗證的領域,例如數學和程式碼。此外,這種方法可能會引入額外的複雜性和依賴性,並且可能會將部分評估負擔從模型本身轉移到外部工具上。
然而,因為它允許我們通過程式化方式生成無限數量的數學題變體,並受益於逐步推理,它已成為推理模型評估和開發的基石。
我在《Build a Reasoning Model (From Scratch)》一書中寫了關於這個主題的 35 頁詳盡內容,因此這裡省略程式碼實現。(我上週提交了該章節。如果你擁有早期預閱版,當它上線時你會收到電子郵件,屆時即可閱讀。與此同時,你可以在 GitHub 上找到逐步程式碼。)

方法 3:使用偏好和排行榜比較模型
到目前為止,我們已經介紹了兩種提供易於量化指標(如模型準確率)的方法。然而,上述方法都無法以更全面的方式評估 LLM,包括判斷回覆的風格。在本節中,如圖 8 所示,我們討論一種基於判斷的方法,即 LLM 排行榜。
這裡描述的排行榜方法是一種基於判斷的方法,模型不是根據準確率值或其他固定的基準測試分數來排名,而是根據用戶(或其他 LLM)對其輸出的偏好來排名。
一個受歡迎的排行榜是 LM Arena(原名 Chatbot Arena),用戶在其中比較兩個用戶選擇或匿名的模型的回覆,並投票給他們偏好的那一個,如圖 9 所示。
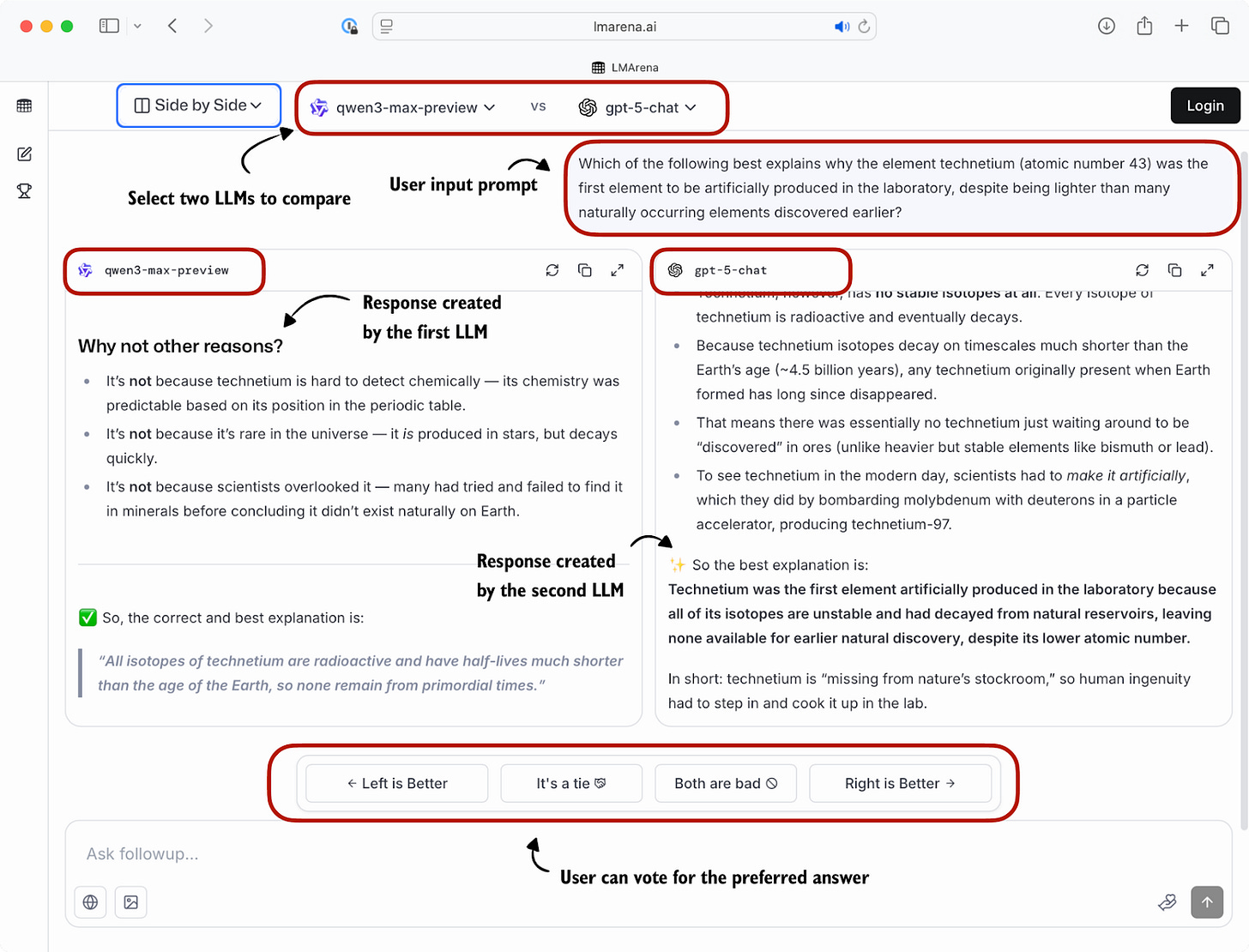
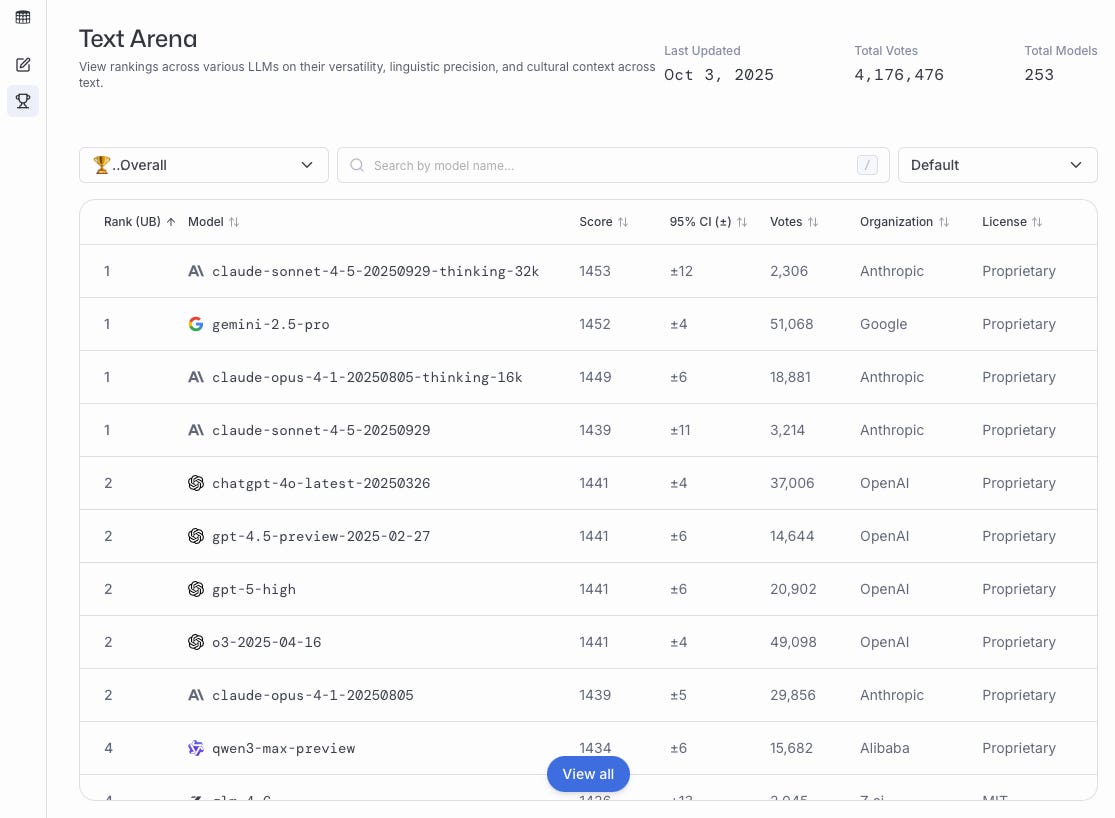
這些如上圖所示收集的偏好投票隨後會彙總所有用戶的數據,形成一個根據用戶偏好對不同模型進行排名的排行榜。圖 10 顯示了 LM Arena 排行榜的當前快照(訪問日期為 2025 年 10 月 3 日)。
在本節的其餘部分,我們將實現一個簡單的排行榜範例。
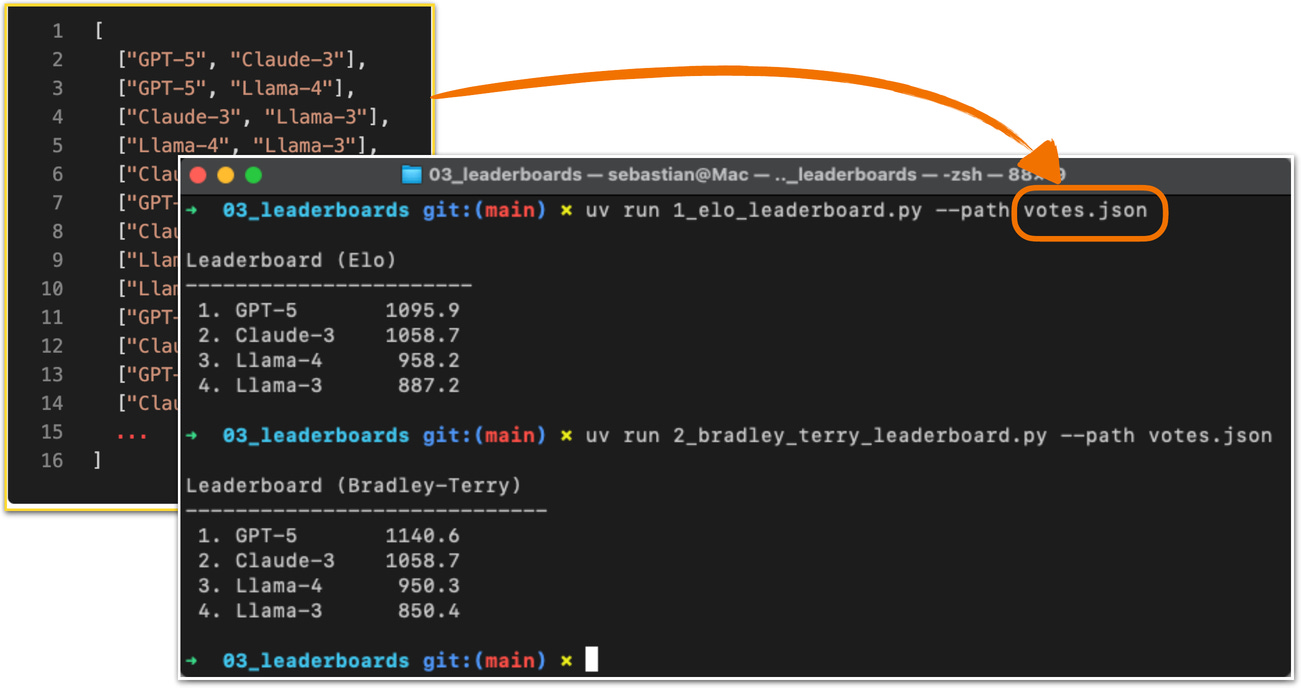
為了創建一個具體的範例,考慮用戶在類似於圖 9 的設置中對不同 LLM 進行提示。下面的列表代表成對投票,其中第一個模型是獲勝者:
在上面的列表中,votes 列表中的每個元組代表兩個模型之間的成對偏好,寫作 (獲勝者, 失敗者)。因此,("GPT-5", "Claude-3") 意味著用戶更喜歡 GPT-5 而非 Claude-3 的模型答案。
在本節的其餘部分,我們將把 votes 列表轉換為排行榜。為此,我們將使用流行的 Elo 等級分系統,該系統最初是為西洋棋選手排名而開發的。
在查看具體的程式碼實現之前,簡而言之,它的工作原理如下:每個模型都從一個基準分數開始。然後,在每次比較和偏好投票後,模型的評分都會更新。(在 Elo 中,更新幅度取決於結果的「意外」程度。)
具體來說,如果用戶更喜歡當前模型而非排名較高的模型,則當前模型將獲得相對較大的排名更新,並在排行榜中排名更高。反之亦然,如果它戰勝了排名較低的對手,更新幅度則較小。(如果當前模型失敗,它會以類似的方式更新,但排名分數會被扣除而不是增加。)
將這些成對排名轉換為排行榜的程式碼如下所示。
程式碼塊 4:構建排行榜
上面定義的 elo_ratings 函數將投票作為輸入並將其轉換為排行榜,如下所示:
這會產生以下排行榜排名,分數越高越好:
那麼,這是如何運作的呢?對於每一對,我們使用以下公式計算獲勝者的預期得分:
這個 expected_winner 值是根據當前評分預測的模型在無平局設置下的獲勝機會。它決定了評分更新的大小。
首先,每個模型都從 initial_rating = 1000 開始。如果兩個評分(獲勝者和失敗者)相等,我們得到 expected_winner = 0.5,這表示勢均力敵。在這種情況下,更新為:
現在,如果一個大熱門(評分很高的模型)獲勝,我們得到 expected_winner ≈ 1。熱門模型僅獲得少量積分,失敗者也僅失去一點點:
然而,如果一個黑馬(評分較低的模型)獲勝,我們得到 expected_winner ≈ 0,獲勝者幾乎獲得全部 k_factor 積分,而失敗者失去大約相同的幅度:
順序很重要
Elo 方法在每場比賽(模型比較)後更新評分,因此後面的結果建立在已經更新過的評分之上。這意味著同一組結果如果以不同的順序呈現,最終得分可能會略有不同。這種影響通常很輕微,但當冷門發生在早期與晚期時,這種情況確實會發生。
為了減少這種順序效應,我們可以打亂投票對並多次運行 elo_ratings 函數,然後取評分的平均值。
上述排行榜方法比靜態基準測試分數提供了更動態的模型質量視圖。然而,結果可能會受到用戶人口統計、提示詞選擇和投票偏見的影響。基準測試和排行榜也可能被操縱(Gaming),用戶可能會根據風格而非正確性來選擇回覆。最後,與自動化基準測試工具相比,排行榜無法為新開發的變體提供即時反饋,這使得它們在活躍的模型開發過程中較難使用。
其他排名方法
LM Arena 最初使用本節描述的 Elo 方法,但最近轉向了基於 Bradley–Terry 模型的統計方法。Bradley-Terry 模型的主要優點是,由於具有統計基礎,它允許構建置信區間來表達排名中的不確定性。此外,與 Elo 評分不同,Bradley-Terry 模型使用整個數據集的統計擬合來共同估計所有評分,這使其免受順序效應的影響。
為了將報告的分數保持在熟悉的範圍內,Bradley-Terry 模型被擬合以產生與 Elo 相當的值。儘管排行榜不再正式使用 Elo 評分,但「Elo」一詞在 LLM 研究人員和從業者比較模型時仍被廣泛使用。顯示 Elo 評分的程式碼範例可在 GitHub 上找到。
方法 4:使用其他 LLM 評判回覆
在早期,LLM 是使用統計和基於啟發式的方法進行評估的,包括一種稱為 BLEU 的衡量指標,它是衡量生成的文本與參考文本匹配程度的粗略指標。這類指標的問題在於它們需要精確的單詞匹配,並且沒有考慮到同義詞、單詞變化等。
如果我們想對整個書面答案文本進行評判,解決這個問題的一種方案是使用上一節討論的相對排名和基於排行榜的方法。然而,排行榜的一個缺點是基於偏好的比較的客觀性,因為它涉及人類反饋(以及與收集此反饋相關的挑戰)。
一種相關的方法是使用另一個具有預定義評分標準(即評估指南)的 LLM,將 LLM 的回覆與參考回覆進行比較,並根據預定義的標準判斷回覆質量,如圖 12 所示。
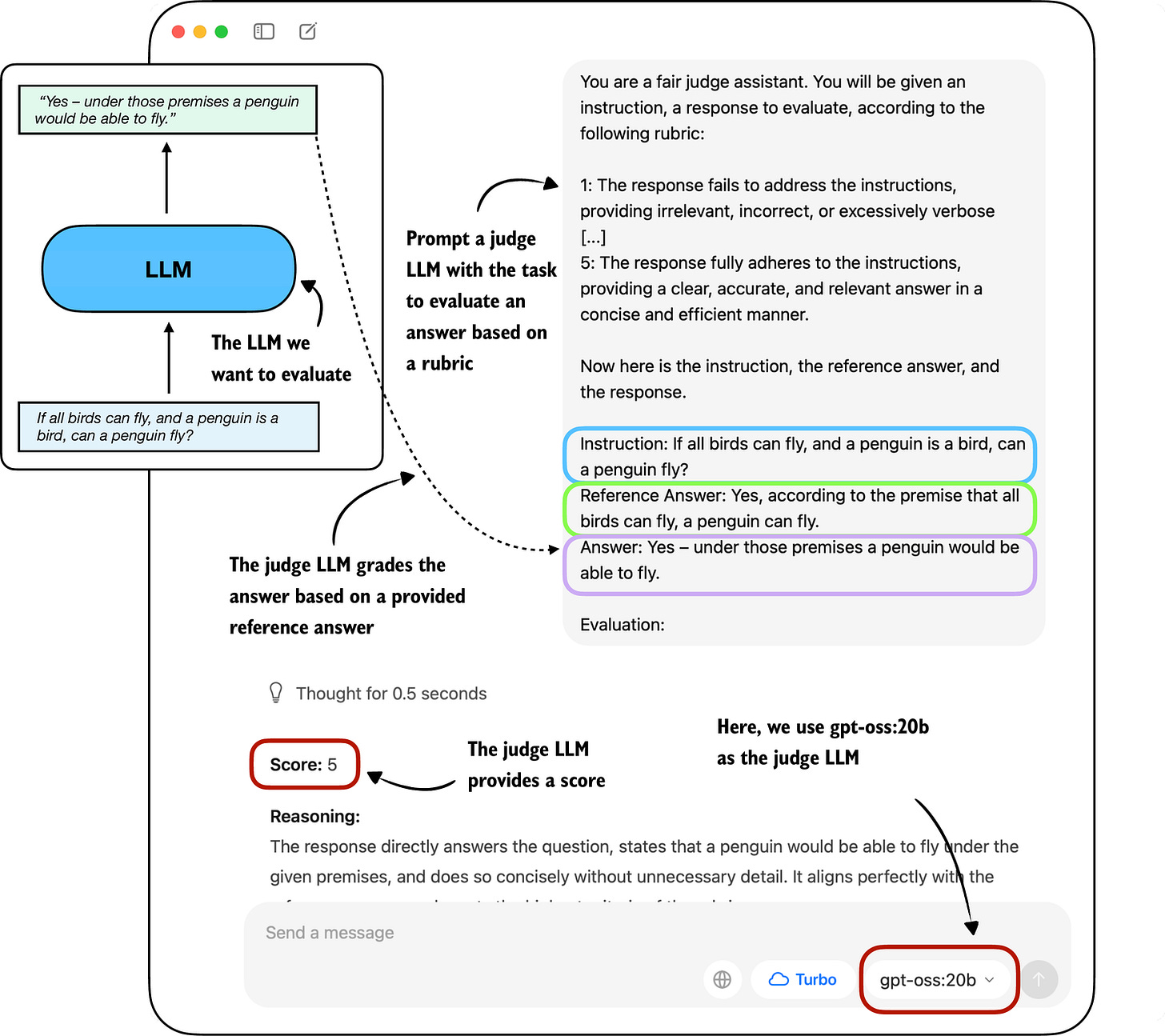
在實踐中,當評判 LLM 很強時,圖 12 所示的基於裁判的方法效果很好。常見的設置是通過 API 使用領先的專有 LLM(例如 GPT-5 API),儘管也存在專門的裁判模型。(例如,眾多範例之一是 Phudge;最終,這些專門模型大多只是經過微調的小型模型,使其具有與專有 GPT 模型相似的評分行為。)
裁判之所以如此有效,原因之一也是評估答案通常比生成答案更容易。
要以程式化方式在 Python 中實現圖 12 所示的基於裁判的模型評估,我們可以加載 PyTorch 中較大的 Qwen3 模型之一,並使用評分標準和我們想要評估的模型答案對其進行提示。
或者,我們可以通過 API 使用其他 LLM,例如 ChatGPT 或 Ollama API。
既然我們已經知道如何在 PyTorch 中加載 Qwen3 模型,為了讓內容更有趣,在本節的其餘部分,我們將使用 Python 中的 Ollama API 實現圖 12 所示的基於裁判的評估。
具體來說,我們將使用 OpenAI 的 200 億參數 gpt-oss 開源權重模型,因為它在能力和效率之間提供了良好的平衡。有關 gpt-oss 的更多信息,請參閱我的《From GPT-2 to gpt-oss: Analyzing the Architectural Advances》文章:
From GPT-2 to gpt-oss: Analyzing the Architectural Advances
4.1 在 Ollama 中實現 LLM-as-a-judge 方法
Ollama 是一個在筆記型電腦上運行 LLM 的高效開源應用程式。它是開源 llama.cpp 庫的包裝器,該庫使用純 C/C++ 實現 LLM 以最大化效率。但請注意,Ollama 僅是用於使用 LLM 生成文本(推理)的工具,不支持訓練或微調 LLM。
要執行以下程式碼,請訪問官方網站 https://ollama.com 安裝 Ollama,並按照適用於你操作系統的說明進行操作:
對於 macOS 和 Windows 用戶:打開下載的 Ollama 應用程式。如果提示安裝命令行工具,請選擇「是」。
對於 Linux 用戶:使用 Ollama 網站上提供的安裝命令。
在實現模型評估程式碼之前,讓我們首先下載 gpt-oss 模型,並通過從命令行終端使用它來驗證 Ollama 是否正常運行。
在命令行(不是 Python 會話)中執行以下命令來嘗試 200 億參數的 gpt-oss 模型:
第一次執行此命令時,將自動下載佔用 14 GB 存儲空間的 200 億參數 gpt-oss 模型。輸出如下所示:
其他 Ollama 模型
請注意,ollama run gpt-oss:20b 命令中的 gpt-oss:20b 指的是 200 億參數的 gpt-oss 模型。使用帶有 gpt-oss:20b 模型的 Ollama 大約需要 13 GB 的 RAM。如果你的機器沒有足夠的 RAM,你可以嘗試使用較小的模型,例如通過 ollama run qwen3:4b 使用 40 億參數的 qwen3:4b 模型,它僅需要約 4 GB 的 RAM。
對於性能更強的電腦,你也可以通過將 gpt-oss:20b 替換為 gpt-oss:120b 來使用更大的 1200 億參數 gpt-oss 模型。但請記住,該模型需要更多的計算資源。
模型下載完成後,我們會看到一個命令行界面,允許我們與模型進行交互。例如,嘗試問模型:「1+2 等於多少?」:
你可以使用輸入 /bye 結束此 ollama run gpt-oss:20b 會話。
在本節的其餘部分,我們將使用 Ollama API。這種方法要求 Ollama 在後台運行。有三種不同的方式可以實現這一點:
-
在終端中運行
ollama serve命令(推薦)。這會將 Ollama 後端作為伺服器運行,通常在 http://localhost:11434。請注意,在通過 API 調用之前(本節稍後部分),它不會加載模型。 -
運行與之前類似的
ollama run gpt-oss:20b命令,但保持其開啟狀態且不要通過/bye退出會話。如前所述,這會打開一個圍繞本地 Ollama 伺服器的極簡便利包裝器。在幕後,它使用與ollama serve相同的伺服器 API。 -
Ollama 桌面應用程式。打開桌面應用程式會自動運行相同的後端,並在其之上提供一個圖形界面,如之前的圖 12 所示。
![]()
Ollama 伺服器 IP 地址
Ollama 通過啟動本地伺服器類進程在我們的機器上本地運行。如上所述在終端中運行 ollama serve 時,你可能會遇到錯誤消息 Error: listen tcp 127.0.0.1:11434: bind: address already in use。
如果是這種情況,請嘗試使用命令 OLLAMA_HOST=127.0.0.1:11435 ollama serve(如果該地址也被佔用,請嘗試將數字遞增,直到找到未被佔用的地址。)
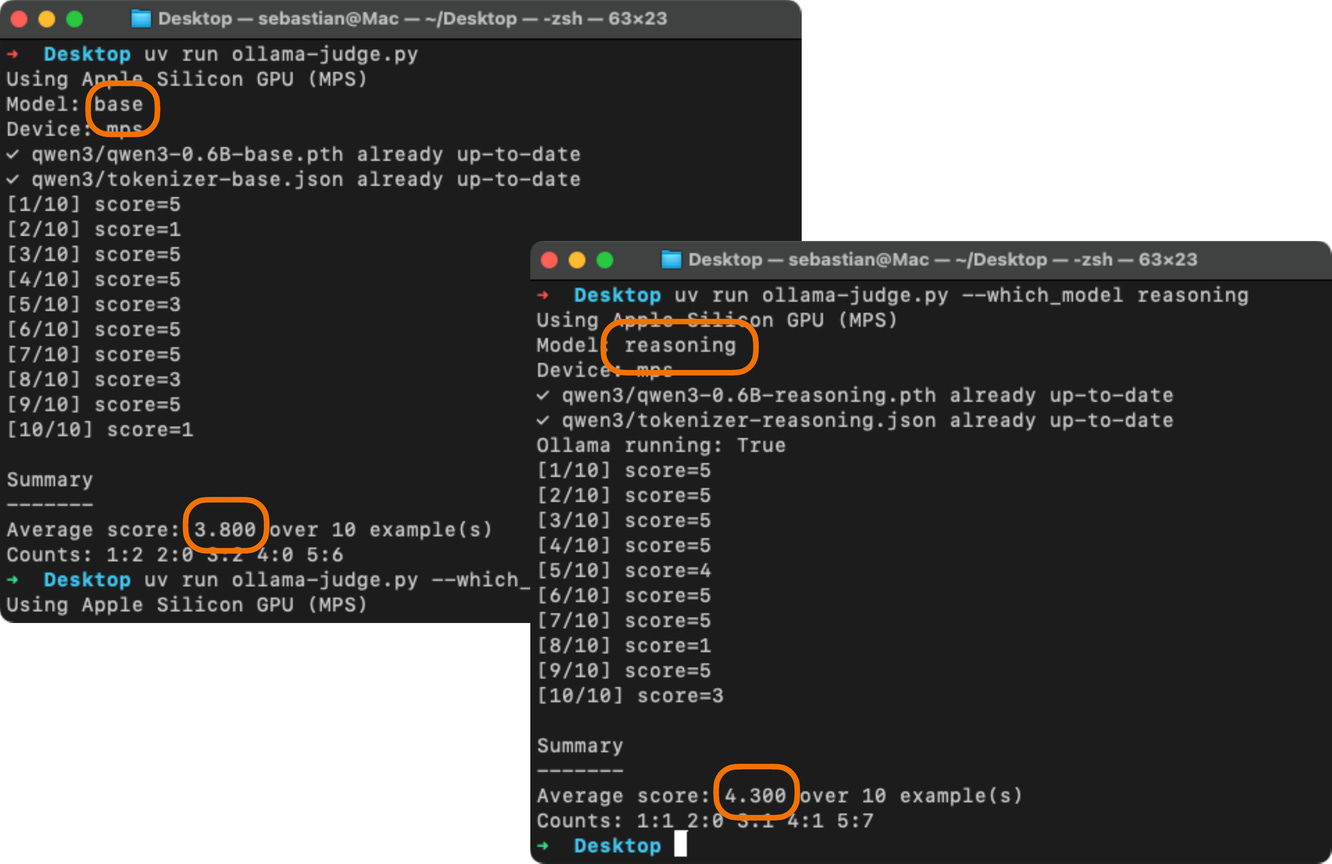
在我們使用 Ollama 評估上一節生成的測試集回覆之前,以下程式碼驗證 Ollama 會話是否正常運行:
程式碼塊 5:檢查 Ollama 是否正在運行
確保執行上述程式碼的輸出顯示 Ollama running: True。如果顯示 False,請驗證 ollama serve 命令或 Ollama 應用程式是否正在積極運行(見圖 13)。
在本文的其餘部分,我們將通過 Python 使用 Ollama REST API 與在我們機器上運行的本地 gpt-oss 模型進行交互。以下 query_model 函數演示了如何使用該 API:
程式碼塊 6:查詢本地 Ollama 模型
以下是如何使用我們剛剛實現的 query_model 函數的範例:
產生的回覆是「3」。(這與我們運行 ollama run 或 Ollama 應用程式時得到的結果不同,因為預設設置不同。)
使用 query_model 函數,我們可以使用包含評分標準的提示詞來評估模型生成的回答,要求 gpt-oss 模型根據正確答案作為參考,在 1 到 5 的範圍內對我們目標模型的回答進行評分。
我們為此使用的提示詞如下所示:
程式碼塊 7:設置包含評分標準的提示詞模板
rubric_prompt 中的 model_answer 旨在代表我們自己的模型在實踐中產生的回覆。為了說明目的,我們在這裡硬編碼了一個合理的模型答案,而不是動態生成它。(不過,歡迎使用我們在本文開頭加載的 Qwen3 模型來生成真實的 model_answer)。
接下來,讓我們為 Ollama 模型生成渲染後的提示詞:
輸出如下:
以「Evaluation: 」結束提示詞會激勵模型生成答案。讓我們看看 gpt-oss:20b 模型如何評判該回覆:
回覆如下:
我們可以看到,該答案獲得了最高分,這是合理的,因為它確實是正確的。雖然這是一個手動執行過程的簡單範例,但我們可以進一步擴展這個想法,實現一個 for 循環,迭代地使用評估數據集中的問題查詢模型(例如我們之前加載的 Qwen3 模型),並通過 gpt-oss 進行評估並計算平均分數。你可以在 GitHub 上找到這樣一個腳本的實現,我們在 MATH-500 數據集上評估 Qwen3 模型。
使用過程獎勵模型對中間推理步驟進行評分
與符號驗證器和 LLM 裁判相關,有一類被稱為過程獎勵模型(PRM)的學習模型。與裁判一樣,PRM 可以評估除最終答案之外的推理軌跡,但與通用裁判不同,它們專門關注推理的中間步驟。與驗證器(以符號方式且通常僅在結果層面檢查正確性)不同,PRM 在強化學習訓練期間提供逐步的獎勵信號。我們可以將 PRM 歸類為「步驟級裁判」,它們主要為訓練而開發,而非純粹的評估。(在實踐中,大規模可靠地訓練 PRM 具有挑戰性。例如,DeepSeek R1 沒有採用 PRM,而是結合驗證器進行推理訓練。)
基於裁判的評估比基於偏好的排行榜具有優勢,包括可擴展性和一致性,因為它們不依賴於大量的人類投票者。(從技術上講,也可以將排行榜背後基於偏好的評分外包給 LLM 裁判)。然而,LLM 裁判也與人類投票者有相似的弱點:結果可能會受到模型偏好、提示詞設計和回答風格的偏見影響。此外,對裁判模型和評分標準的選擇有很強的依賴性,並且缺乏固定基準測試的可重複性。
結論
在本文中,我們介紹了四種不同的評估方法:選擇題、驗證器、排行榜和 LLM 裁判。
我知道這是一篇很長的文章,但我希望你發現它對於了解 LLM 如何被評估很有用。像這樣從零開始的方法可能比較冗長,但它是理解這些方法底層運作方式的好方法,這反過來又可以幫助我們識別弱點和改進領域。
話雖如此,你可能想知道:「評估 LLM 的最佳方法是什麼?」遺憾的是,沒有單一的最佳方法,因為正如我們所見,每種方法都有不同的權衡。簡而言之:
選擇題
(+) 在大規模運行時相對快速且便宜
(+) 在論文(或模型卡)之間標準化且可重複
(-) 衡量基礎知識檢索
(-) 不能反映 LLM 在現實世界中的使用方式
驗證器
(+) 對於具有標準答案的領域,評分標準化且客觀
(+) 允許自由格式的回答(對最終答案格式有一些限制)
(+) 如果使用過程驗證器或過程獎勵模型,也可以對中間步驟評分
(-) 需要可驗證的領域(例如數學或程式碼),且構建好的驗證器可能很棘手
(-) 僅限結果的驗證器僅評估最終答案,而不評估推理質量
競技場式排行榜(人類成對偏好)
(+) 直接回答「人們在真實提示詞上更喜歡哪個模型?」
(+) 允許自由格式的回答,並隱含地考慮了風格、幫助性和安全性
(-) 對人類來說成本高且耗時
(-) 不衡量正確性,僅衡量偏好
(-) 非平穩的人群可能會影響穩定性
LLM-as-a-judge
(+) 可擴展至多項任務
(+) 允許自由格式的回答
(-) 取決於裁判的能力(集成多個裁判可以使其更穩健)
(-) 取決於評分標準的選擇
雖然我通常不太喜歡雷達圖,但這裡使用雷達圖來可視化這些不同的評估領域會很有幫助,如下所示。
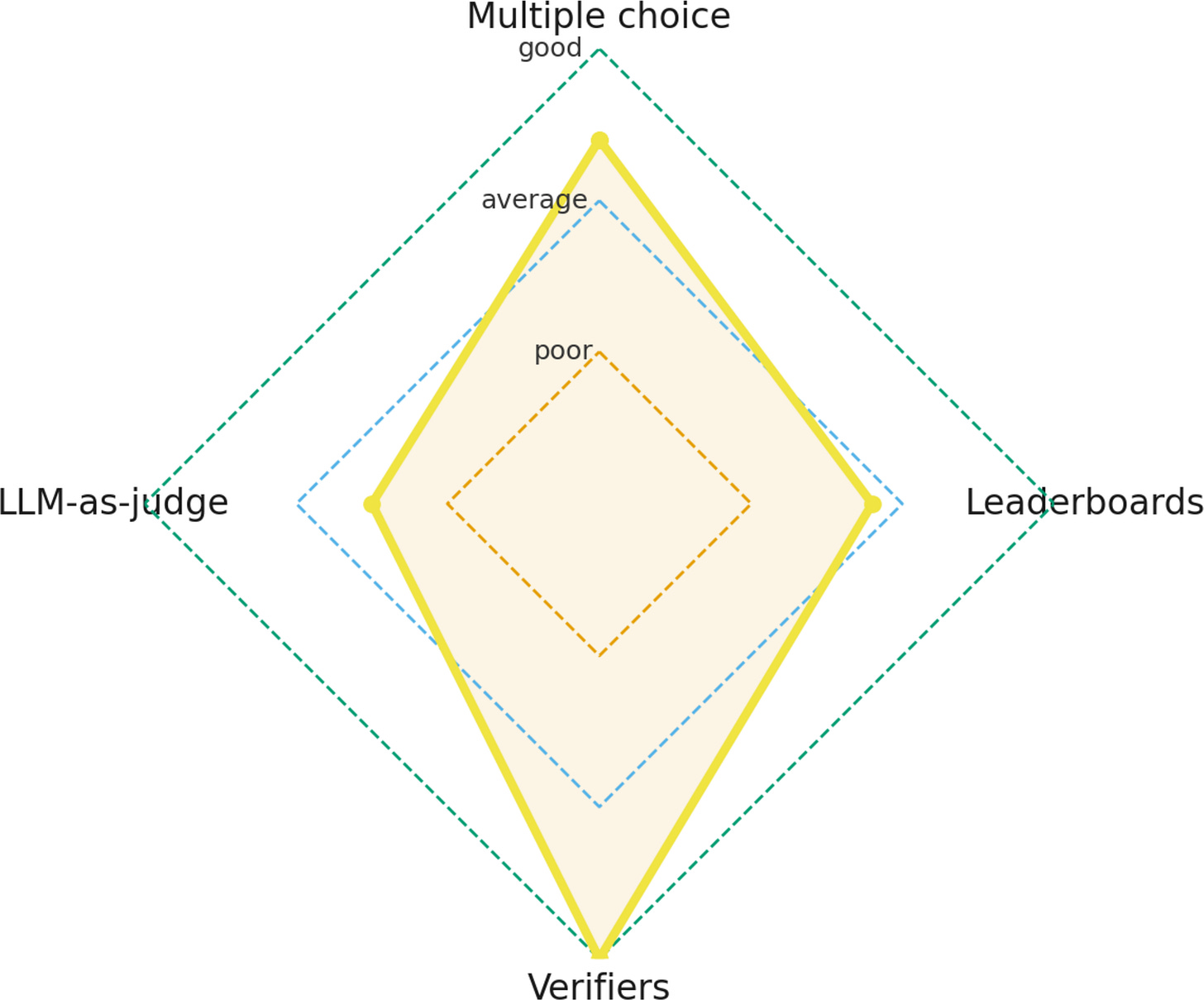
例如,強大的選擇題評分表明模型具有紮實的通用知識。結合強大的驗證器分數,該模型很可能也能正確回答技術問題。然而,如果模型在 LLM-as-a-judge 和排行榜評估中表現不佳,它可能難以有效地編寫或表達回覆,並且可能受益於一些 RLHF。
因此,最佳評估結合了多個領域。但理想情況下,它還應該使用與你的目標或業務問題直接相關的數據。例如,假設你正在實施一個 LLM 來協助法律或與法律相關的任務。將模型運行在 MMLU 等標準基準測試上作為快速健全性檢查是有意義的,但最終你會希望針對你的目標領域(如法律)量身定制評估。你可以在網上找到作為良好起點的公共基準測試,但最後,你會希望使用自己的專有數據進行測試。只有這樣,你才能合理地確信模型在訓練期間尚未見過測試數據。
無論如何,模型評估是一個非常大且重要的課題。我希望這篇文章能有效地解釋主要方法的運作方式,並希望你在下次查看模型評估或自己運行評估時能獲得一些有用的見解。
一如既往,祝你玩得開心!
這個雜誌是一個個人的熱情項目,你的支持有助於維持它的運作。
如果你想支持我的工作,請考慮我的《Build a Large Language Model (From Scratch)》一書或其續作《Build a Reasoning Model (From Scratch)》。(我有信心你會從中獲益良多;它們深入解釋了 LLM 的運作原理,這是你在其他地方找不到的。)
感謝閱讀,並感謝支持獨立研究!
如果你讀過這本書並有幾分鐘空閒時間,我會非常感激你的簡短評論。這對我們作者幫助很大!
你的支持意義重大!謝謝!
相關文章