深入理解多模態大型語言模型
這篇文章旨在解釋多模態大型語言模型的運作方式,並回顧包含 Llama 3.2 在內的最新研究,比較它們如何處理文字與圖像等不同類型的輸入數據。
深入理解多模態大型語言模型
主要技術與最新模型介紹
這兩個月非常瘋狂。AI 研究領域再次出現了許多進展,不僅有兩項諾貝爾獎頒給了 AI 領域,還發表了幾篇有趣的研究論文。
其中,Meta AI 發布了最新的 Llama 3.2 模型,其中包括 1B 和 3B 大型語言模型的開放權重版本,以及兩個多模態模型。
在本文中,我旨在解釋多模態 LLM 的運作方式。此外,我將回顧並總結過去幾週發表的約十幾篇其他近期多模態論文和模型(包括 Llama 3.2),以比較它們的方法。
(要查看目錄選單,請點擊左側的堆疊線條。)

但在開始之前,我也有一些個人方面的激動消息要分享!我的新書《從零開始構建大型語言模型》(Build A Large Language Model (From Scratch)) 終於在 Amazon 上架了!

撰寫這本書付出了巨大的努力,我非常感謝過去兩年來所有的支持和激勵性的回饋——特別是在過去幾個月裡,許多熱心的讀者分享了他們的心得。謝謝大家,作為一名作者,沒有什麼比聽到這本書對你們的職業生涯產生影響更具動力的事情了!
對於那些已經讀完本書並渴望了解更多內容的人,請保持關注!我將在未來幾個月內向 GitHub 存儲庫添加一些額外內容。
附註:如果你已經讀過這本書,如果你能留下簡短的評論,我將不勝感激;這對我們作者來說真的很有幫助!
1. 多模態 LLM 的使用案例
什麼是多模態 LLM?正如引言中所暗示的,多模態 LLM 是能夠處理多種類型輸入的大型語言模型,其中每種「模態」(modality) 指的是特定類型的數據——例如文本(如傳統 LLM)、聲音、圖像、影片等。為了簡單起見,我們將主要關注圖像模態以及文本輸入。
多模態 LLM 一個經典且直觀的應用是圖像標註 (image captioning):你提供一張輸入圖像,模型會生成該圖像的描述,如下圖所示。

當然,還有許多其他使用案例。例如,我最喜歡的一個案例是從 PDF 表格中提取信息並將其轉換為 LaTeX 或 Markdown。
2. 構建多模態 LLM 的常用方法
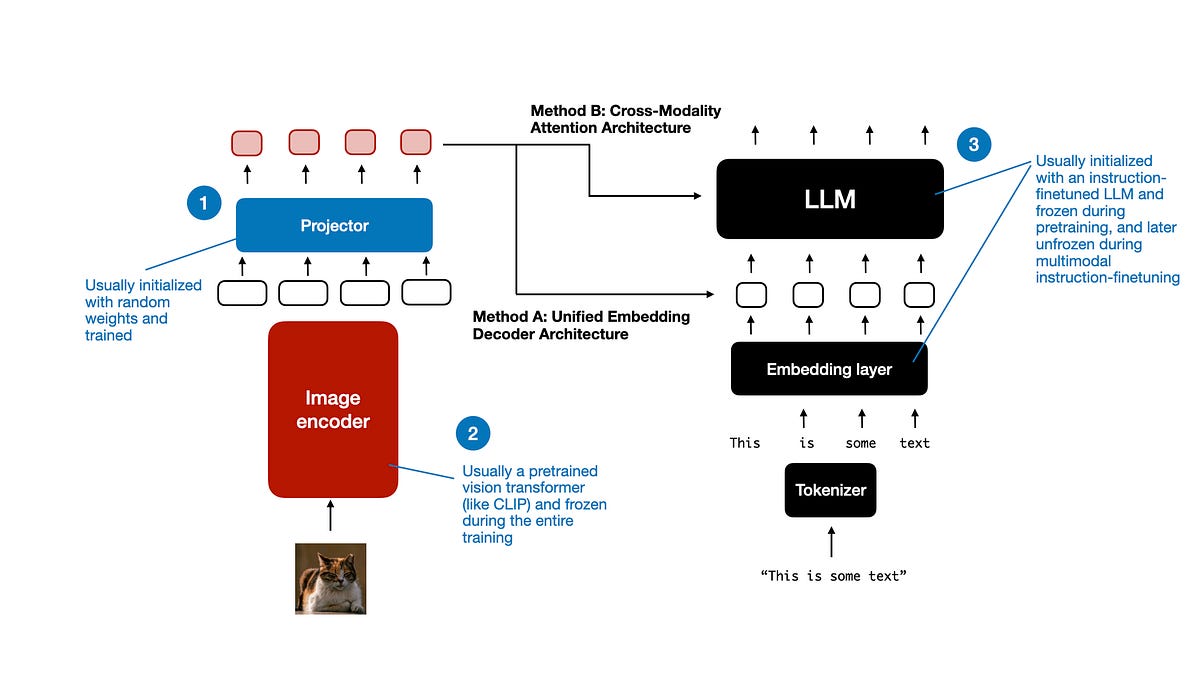
構建多模態 LLM 主要有兩種方法:
方法 A:統一嵌入解碼器架構 (Unified Embedding Decoder Architecture);
方法 B:跨模態注意力架構 (Cross-modality Attention Architecture)。
(順便提一下,我認為這些技術目前還沒有官方術語,但如果你遇到過,請告訴我。例如,更簡短的描述可能是「純解碼器」(decoder-only) 和「基於跨注意力」(cross-attention-based) 的方法。)

如上圖所示,統一嵌入解碼器架構使用單個解碼器模型,非常類似於未經修改的 LLM 架構(如 GPT-2 或 Llama 3.2)。在這種方法中,圖像被轉換為與原始文本標記 (tokens) 具有相同嵌入大小的標記,從而在拼接後允許 LLM 同時處理文本和圖像輸入標記。
跨模態注意力架構則採用跨注意力機制,直接在注意力層內整合圖像和文本嵌入。
在接下來的章節中,我們將在概念層面探討這些方法的工作原理。然後,我們將查看近期關於多模態 LLM 的研究論文,看看它們在實踐中是如何應用的。
2.1 方法 A:統一嵌入解碼器架構
讓我們從統一嵌入解碼器架構開始,下圖再次對其進行了說明。

在統一嵌入解碼器架構中,圖像被轉換為嵌入向量,類似於標準純文本 LLM 中將輸入文本轉換為嵌入的方式。
對於處理文本的典型純文本 LLM,文本輸入通常會經過標記化(例如使用字節對編碼 BPE),然後通過嵌入層,如下圖所示。

2.1.1 理解圖像編碼器
與文本的標記化和嵌入類似,圖像嵌入是使用圖像編碼器模組(而不是標記生成器)生成的,如下圖所示。

上圖所示的圖像編碼器內部發生了什麼?為了處理圖像,我們首先將其劃分為較小的區塊 (patches),就像在標記化過程中將單詞分解為子詞一樣。然後,這些區塊由預訓練的視覺轉換器 (ViT) 進行編碼,如下圖所示。
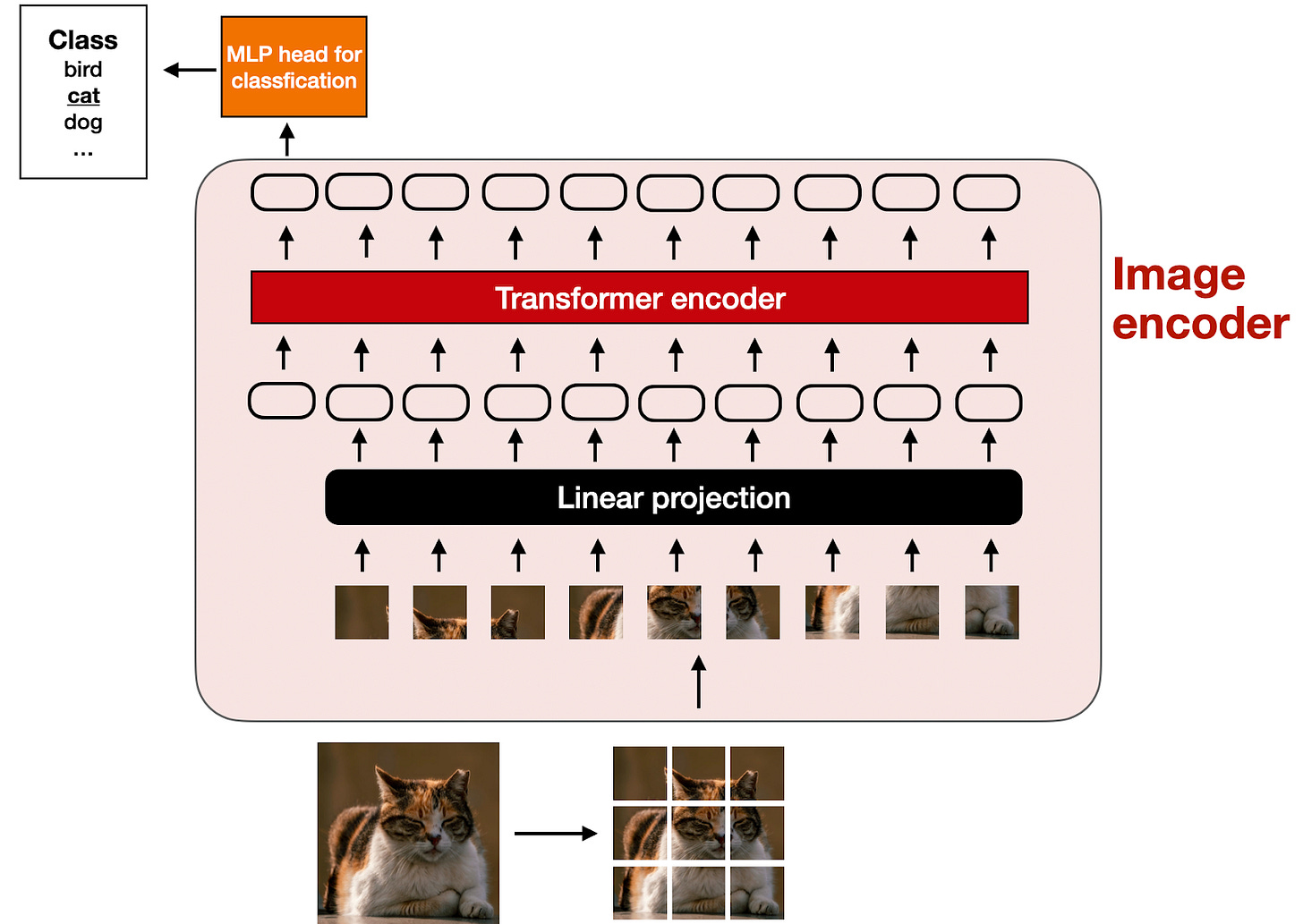
請注意,ViT 通常用於分類任務,因此我在上圖中包含了分類頭。但在這種情況下,我們只需要圖像編碼器部分。
2.1.2 線性投影模組的作用
前圖中顯示的「線性投影」(linear projection) 由單個線性層(即全連接層)組成。該層的目的是將展平為向量的圖像區塊投影到與轉換器編碼器兼容的嵌入大小。下圖說明了這種線性投影。一個展平為 256 維向量的圖像區塊被向上投影為 768 維向量。

對於那些喜歡看代碼示例的人,在 PyTorch 代碼中,我們可以如下實現圖像區塊的線性投影:
如果你碰巧讀過我的《機器學習 Q 與 AI》一書,你可能知道有一些方法可以用卷積操作替換線性層,這些操作在數學上是等效的。在這裡,這特別方便,因為我們可以將區塊創建和投影合併為兩行代碼:
2.1.3 圖像與文本標記化對比
現在我們簡要討論了圖像編碼器(以及作為編碼器一部分的線性投影)的目的,讓我們回到之前的文本標記化類比,並並排查看文本和圖像的標記化與嵌入,如下圖所示。

正如你在上圖中看到的,我在圖像編碼器之後添加了一個額外的投影器 (projector) 模組。這個投影器通常只是另一個線性投影層,與之前解釋的類似。其目的是將圖像編碼器的輸出投影到與嵌入文本標記維度相匹配的維度,如下圖所示。(正如我們稍後將看到的,投影器有時也稱為適配器 adapter 或連接器 connector。)

現在圖像區塊嵌入具有與文本標記嵌入相同的嵌入維度,我們可以簡單地將它們拼接起來作為 LLM 的輸入,如本節開頭的圖所示。下面再次提供同一張圖以便參考。

順便說一句,我們在本節中討論的圖像編碼器通常是預訓練的視覺轉換器。一個受歡迎的選擇是 CLIP 或 OpenCLIP。
然而,也有一些方法 A 的版本直接在區塊上操作,例如 Fuyu,如下圖所示。

如上圖所示,Fuyu 直接將輸入區塊傳遞到線性投影(或嵌入層)中,以學習其自身的圖像區塊嵌入,而不是像其他模型和方法那樣依賴額外的預訓練圖像編碼器。這大大簡化了架構和訓練設置。
2.2 方法 B:跨模態注意力架構
現在我們已經討論了構建多模態 LLM 的統一嵌入解碼器架構方法,並了解了圖像編碼背後的基本概念,讓我們來談談通過跨注意力實現多模態 LLM 的另一種方式,如下圖所示。

在上圖所示的跨模態注意力架構方法中,我們仍然使用之前討論過的相同圖像編碼器設置。然而,我們不是將區塊編碼為 LLM 的輸入,而是通過跨注意力機制在多頭注意力層中連接輸入區塊。
這個想法與 2017 年《Attention Is All You Need》論文中的原始轉換器架構相關,如下圖所示。

請注意,上圖中描繪的原始「Attention Is All You Need」轉換器最初是為語言翻譯開發的。因此,它由一個文本編碼器(圖左側部分)組成,該編碼器接收要翻譯的句子,並通過文本解碼器(圖右側部分)生成翻譯。在多模態 LLM 的背景下,編碼器是圖像編碼器而不是文本編碼器,但同樣的想法也適用。
跨注意力是如何運作的?讓我們看看常規自注意力機制內部發生了什麼的概念圖。

在上圖中,x 是輸入,Wq 是用於生成查詢 (Q) 的權重矩陣。同樣,K 代表鍵 (keys),V 代表值 (values)。A 代表注意力分數矩陣,Z 是轉換為輸出上下文向量的輸入 (x)。(如果這看起來令人困惑,你可能會發現我《從零開始構建大型語言模型》一書第 3 章中的全面介紹很有幫助;或者,你也可以參考我的文章《理解並編寫 LLM 中的自注意力、多頭注意力、跨注意力和因果注意力》。)
在跨注意力中,與自注意力相反,我們有兩個不同的輸入源,如下圖所示。
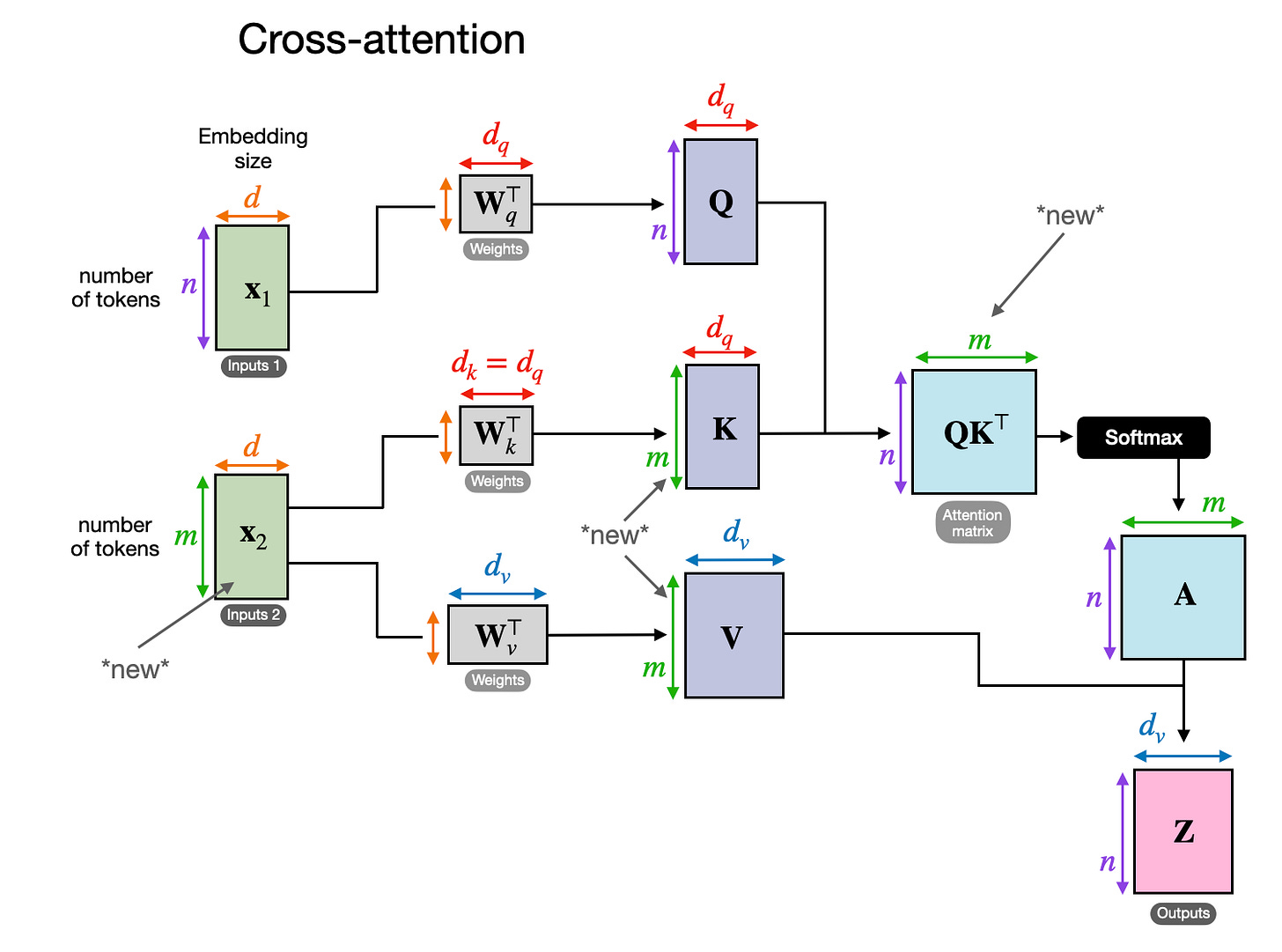
如前兩圖所示,在自注意力中,我們處理的是相同的輸入序列。在跨注意力中,我們混合或組合了兩個不同的輸入序列。
在《Attention Is All You Need》論文中的原始轉換器架構情況下,兩個輸入 x1 和 x2 分別對應於左側編碼器模組返回的序列 (x2) 和右側解碼器部分正在處理的輸入序列 (x1)。在多模態 LLM 的背景下,x2 是圖像編碼器的輸出。(請注意,查詢通常來自解碼器,而鍵和值通常來自編碼器。)
請注意,在跨注意力中,兩個輸入序列 x1 和 x2 可以具有不同數量的元素。但是,它們的嵌入維度必須匹配。如果我們設置 x1 = x2,這就等同於自注意力。
3. 統一解碼器與跨注意力模型訓練
現在我們已經討論了兩種主要的多模態設計選擇,讓我們簡要談談在模型訓練期間如何處理這三個主要組件,如下圖所示。

與傳統純文本 LLM 的開發類似,多模態 LLM 的訓練也涉及兩個階段:預訓練和指令微調。然而,與從零開始不同,多模態 LLM 訓練通常以預訓練且經過指令微調的純文本 LLM 作為基礎模型。
對於圖像編碼器,CLIP 是常用的選擇,並且在整個訓練過程中通常保持不變,儘管我們稍後會探討一些例外情況。在預訓練階段保持 LLM 部分凍結也是常見的做法,僅專注於訓練投影器——一個線性層或一個小型多層感知器。鑑於投影器的學習能力有限(通常僅由一兩層組成),在多模態指令微調(第 2 階段)期間通常會解凍 LLM,以進行更全面的更新。但請注意,在基於跨注意力的模型(方法 B)中,跨注意力層在整個訓練過程中都是解凍的。
在介紹了兩種主要方法(方法 A:統一嵌入解碼器架構和方法 B:跨模態注意力架構)之後,你可能會想知道哪種更有效。答案取決於具體的權衡。
統一嵌入解碼器架構(方法 A)通常更容易實現,因為它不需要對 LLM 架構本身進行任何修改。
跨模態注意力架構(方法 B)通常被認為計算效率更高,因為它不會用額外的圖像標記使輸入上下文過載,而是稍後在跨注意力層中引入它們。此外,如果 LLM 參數在訓練期間保持凍結,這種方法可以維持原始 LLM 的純文本性能。
我們將在後面的章節中重新討論建模性能和響應質量的討論,屆時我們將討論 NVIDIA 的 NVLM 論文。
這標誌著多模態 LLM 相當廣泛的介紹告一段落。在撰寫本文時,我意識到討論內容比最初計劃的要長,這可能使這裡成為結束本文的好地方。
然而,為了提供實踐視角,檢查幾篇實現這些方法的近期研究論文會很有幫助。因此,我們將在本文剩餘的章節中探討這些論文。
4. 近期的多模態模型與方法
在本文的剩餘部分,我將回顧有關多模態 LLM 的近期文獻,特別關注過去幾週發表的著作,以保持合理的範圍。
因此,這不是多模態 LLM 的歷史概述或全面回顧,而是對最新進展的簡要觀察。我也會盡量保持這些總結簡短且不含過多贅述,因為總共有 10 篇。
最後的結論部分提供了這些論文所用方法的對比概述。
4.1 Llama 3 系列模型 (The Llama 3 Herd of Models)
Meta AI 的《Llama 3 Herd of Models》論文(2024 年 7 月 31 日)於今年夏天早些時候發布,這在 LLM 的時間跨度中感覺像是很久以前的事了。然而,考慮到他們直到很久以後才描述但未發布其多模態模型,我認為將 Llama 3 納入此列表是公平的。(Llama 3.2 模型於 9 月 25 日正式宣布並提供使用。)
多模態 Llama 3.2 模型有 110 億和 900 億參數版本,是圖像-文本模型,採用了前面描述的基於跨注意力的方法,如下圖所示。
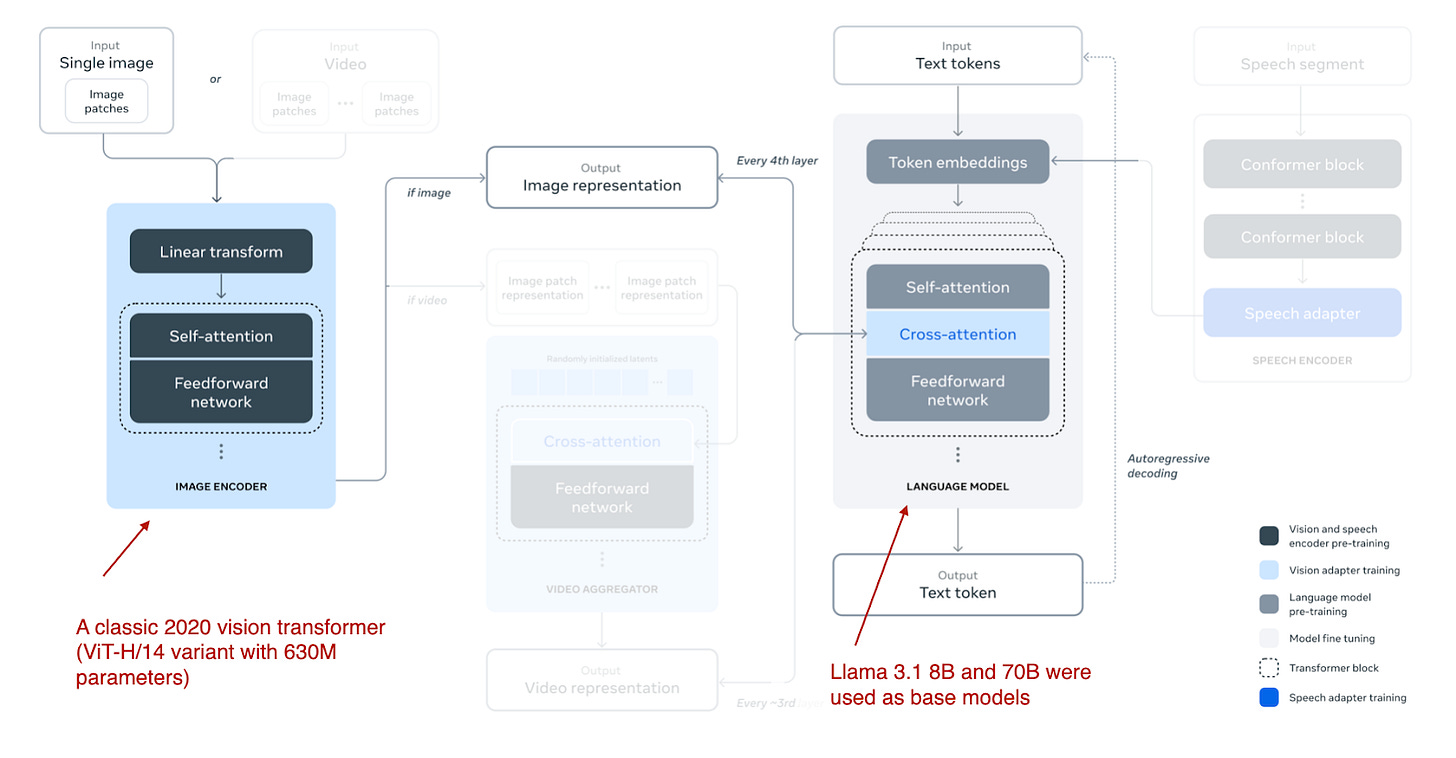
請注意,雖然圖中也將影片和語音描述為可能的模態,但截至撰寫本文時發布的模型僅專注於圖像和文本。
Llama 3.2 使用基於跨注意力的方法。然而,它與我之前寫的內容略有不同,即在多模態 LLM 開發中,我們通常凍結圖像編碼器,僅在預訓練期間更新 LLM 參數。
在這裡,研究人員幾乎採取了相反的方法:他們更新圖像編碼器,但不更新語言模型的參數。他們寫道,這是故意的,目的是保留純文本能力,以便 11B 和 90B 多模態模型可以在文本任務上作為 Llama 3.1 8B 和 70B 純文本模型的直接替代品。
訓練本身是通過多次迭代完成的,從 Llama 3.1 文本模型開始。在添加圖像編碼器和投影(這裡稱為「適配器」)層後,他們在圖像-文本數據上對模型進行預訓練。然後,類似於 Llama 3 模型的純文本訓練(我在之前的文章中寫過),他們接著進行指令和偏好微調。
研究人員沒有採用 CLIP 等預訓練模型作為圖像編碼器,而是使用了他們從零開始預訓練的視覺轉換器。具體來說,他們採用了經典視覺轉換器架構 (Dosovitskiy et al., 2020) 的 ViT-H/14 變體(6.3 億參數)。然後,他們在包含 25 億個圖像-文本對的數據集上對 ViT 進行了五個輪次 (epochs) 的預訓練;這是在將圖像編碼器連接到 LLM 之前完成的。(圖像編碼器接收 224×224 分辨率的圖像,並將其劃分為 14×14 的區塊網格,每個區塊大小為 16×16 像素。)
由於跨注意力層增加了大量參數,因此它們僅在每四個轉換器區塊中添加一次。(對於 8B 模型,這增加了 3B 參數;對於 70B 模型,這增加了 200 億參數。)
4.2 Molmo 與 PixMo:領先多模態模型的開放權重與開放數據
《Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models》論文(2024 年 9 月 25 日)值得關注,因為它承諾不僅開源模型權重,還開源數據集和源代碼,類似於純語言的 OLMo LLM。(這對 LLM 研究非常有用,因為它允許我們查看確切的訓練過程和代碼,還能讓我們在相同的數據集上運行消融實驗並重現結果。)
如果你想知道為什麼論文標題中有兩個名字,Molmo 指的是模型(Multimodal Open Language Model),而 PixMo(Pixels for Molmo)是數據集。

如上圖所示,圖像編碼器採用現成的視覺轉換器,具體為 CLIP。這裡的術語「連接器」(connector) 指的是將圖像特徵與語言模型對齊的「投影器」。
Molmo 通過避免多個預訓練階段來簡化訓練過程,轉而選擇一種簡單的流水線,以統一的方法更新所有參數——包括基礎 LLM、連接器和圖像編碼器的參數。
Molmo 團隊為基礎 LLM 提供了多種選擇:
OLMo-7B-1024(完全開放的模型主幹),
OLMoE-1B-7B(混合專家架構;最高效的模型),
Qwen2 7B(性能優於 OLMo-7B-1024 的開放權重模型),
Qwen2 72B(開放權重模型且性能最佳的模型)。
4.3 NVLM:開放的前沿級多模態 LLM
NVIDIA 的《NVLM: Open Frontier-Class Multimodal LLMs》論文(2024 年 9 月 17 日)特別有趣,因為它沒有專注於單一方法,而是探索了兩種方法:
方法 A,統一嵌入解碼器架構(「純解碼器架構」,NVLM-D),以及
方法 B,跨模態注意力架構(「基於跨注意力的架構」,NVLM-X)。
此外,他們還開發了一種混合方法 (NVLM-H),並對所有三種方法進行了公平的比較。

如下圖總結,NVLM-D 對應於方法 A,NVLM-X 對應於方法 B,正如之前討論的那樣。混合模型 (NVLM-H) 背後的概念是結合兩種方法的優點:提供圖像縮略圖作為輸入,然後通過跨注意力傳遞動態數量的區塊,以捕捉更精細的高分辨率細節。
簡而言之,研究團隊發現:
NVLM-X 在高分辨率圖像方面表現出卓越的計算效率。
NVLM-D 在 OCR 相關任務中實現了更高的準確度。
NVLM-H 結合了兩種方法的優點。
與 Molmo 和其他方法類似,他們從純文本 LLM 開始,而不是從零開始預訓練多模態模型(因為這通常表現更好)。此外,他們使用的是經過指令微調的 LLM 而不是基礎 LLM。具體來說,主幹 LLM 是 Qwen2-72B-Instruct(據我所知,Molmo 使用的是 Qwen2-72B 基礎模型)。
雖然在 NVLM-D 方法中訓練了所有 LLM 參數,但他們發現對於 NVLM-X,在預訓練和指令微調期間凍結原始 LLM 參數並僅訓練跨注意力層效果很好。
對於圖像編碼器,他們沒有使用典型的 CLIP 模型,而是使用了 InternViT-6B,它在所有階段都保持凍結。
投影器是一個多層感知器,而不是單個線性層。
4.4 Qwen2-VL:增強視覺語言模型對任何分辨率世界的感知
前兩篇論文和模型 Molmo 和 NVLM 都是基於 Qwen2-72B LLM。在這篇論文中,Qwen 研究團隊親自發布了一個多模態 LLM,《Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution》(2024 年 10 月 3 日)。
這項工作的核心是他們所謂的「Naive Dynamic Resolution」(天真動態分辨率)機制(術語「naive」是故意的,不是「native」的拼寫錯誤,儘管「native」可能也很合適)。該機制允許模型處理不同分辨率的圖像而無需簡單的下採樣,從而能夠以原始分辨率輸入圖像。

原生分辨率輸入是通過修改 ViT 實現的,具體做法是移除原始的絕對位置嵌入並引入 2D-RoPE。
他們使用了一個具有 6.75 億參數的經典視覺編碼器和不同大小的 LLM 主幹,如下表所示。

訓練本身由 3 個階段組成:(1) 僅預訓練圖像編碼器,(2) 解凍所有參數(包括 LLM),以及 (3) 凍結圖像編碼器並僅對 LLM 進行指令微調。
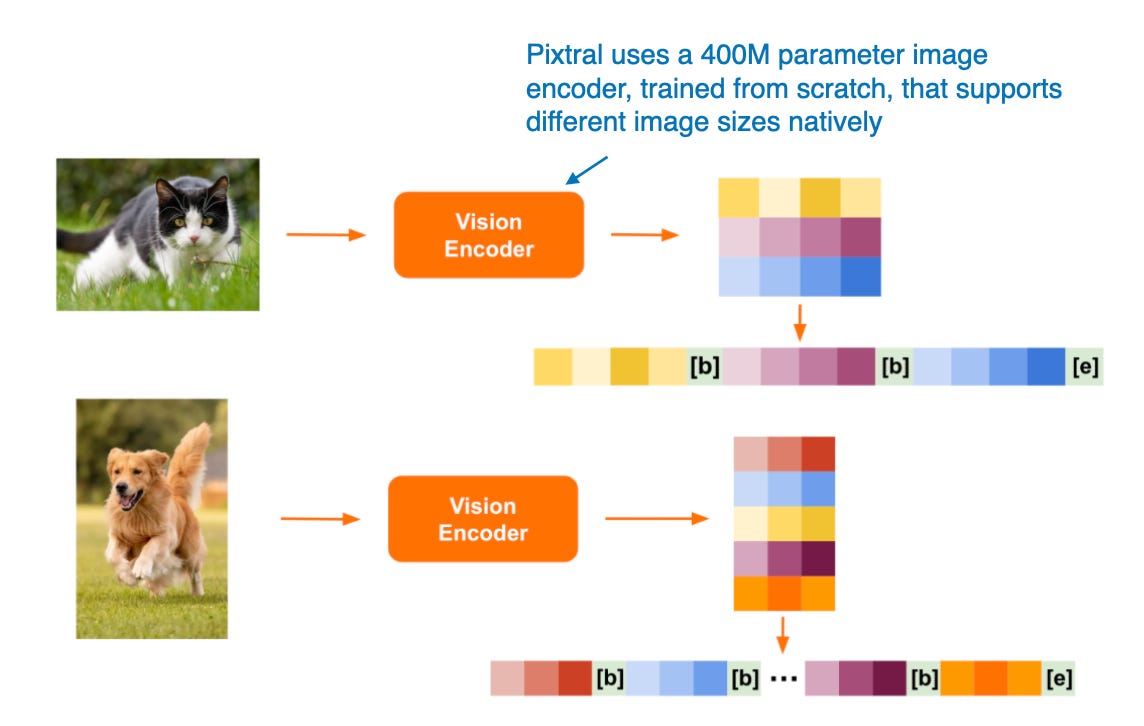
4.5 Pixtral 12B
Pixtral 12B(2024 年 9 月 17 日)採用方法 A:統一嵌入解碼器架構,是 Mistral AI 的首個多模態模型。遺憾的是,目前還沒有技術論文或報告,但 Mistral 團隊在他們的部落格文章中分享了一些有趣的細節。
有趣的是,他們選擇不使用預訓練的圖像編碼器,而是從零開始訓練了一個具有 4 億參數的編碼器。對於 LLM 主幹,他們使用了 120 億參數的 Mistral NeMo 模型。
與 Qwen2-VL 類似,Pixtral 也原生支持可變圖像大小,如下圖所示。
4.6 MM1.5:多模態 LLM 微調的方法、分析與見解
《MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning》論文(2024 年 9 月 30 日)提供了實用技巧,並引入了一個混合專家多模態模型以及一個類似於 Molmo 的稠密模型。模型尺寸範圍很廣,從 10 億到 300 億參數不等。
本文描述的模型專注於方法 A,即統一嵌入轉換器架構,它為多模態學習有效地構建了輸入結構。
此外,本文還進行了一系列有趣的消融研究,探討了數據混合以及使用坐標標記 (coordinate tokens) 的效果。

4.7 Aria:一個開放的多模態原生混合專家模型
《Aria: An Open Multimodal Native Mixture-of-Experts Model》論文(2024 年 10 月 8 日)介紹了另一種混合專家模型方法,類似於 Molmo 和 MM1.5 系列中的變體。
Aria 模型擁有 249 億參數,每個文本標記分配 35 億參數。圖像編碼器 (SigLIP) 擁有 4.38 億參數。
該模型基於跨注意力方法,整體訓練過程如下:
- 從零開始訓練 LLM 主幹。
- 同時預訓練 LLM 主幹和視覺編碼器。
4.8 百川 (Baichuan-Omni)
《Baichuan-Omni Technical Report》(2024 年 10 月 11 日)介紹了 Baichuan-Omni,這是一個基於方法 A:統一嵌入解碼器架構的 70 億參數多模態 LLM,如下圖所示。

Baichuan-Omni 的訓練過程涉及三個階段:
- 投影器訓練:最初僅訓練投影器,同時視覺編碼器和語言模型 (LLM) 保持凍結。
- 視覺編碼器訓練:接著,解凍並訓練視覺編碼器,LLM 仍保持凍結。
- 全模型訓練:最後,解凍 LLM,允許整個模型進行端到端訓練。
該模型利用 SigLIP 視覺編碼器,並結合 AnyRes 模組,通過下採樣技術處理高分辨率圖像。
雖然報告沒有明確指定 LLM 主幹,但考慮到模型的參數大小和命名慣例,它很可能是基於 Baichuan 7B LLM。
4.9 Emu3:下一個標記預測就是你所需要的一切 (Next-Token Prediction is All You Need)
《Emu3: Next-Token Prediction is All You Need》論文(2024 年 9 月 27 日)為圖像生成提供了一個極具吸引力的擴散模型替代方案,它完全基於轉換器解碼器架構。雖然它不是經典意義上的多模態 LLM(即專注於圖像理解而非生成的模型),但 Emu3 非常有趣,因為它證明了可以使用轉換器解碼器進行圖像生成,而這項任務通常由擴散方法主導。(不過請注意,之前也有過其他類似的方法,例如《Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation》。)

研究人員從零開始訓練了 Emu3,然後使用直接偏好優化 (DPO) 使模型與人類偏好對齊。
該架構包含一個受 SBER-MoVQGAN 啟發的視覺標記生成器。核心 LLM 架構基於 Llama 2,但完全是從零開始訓練的。
4.10 Janus:解耦統一多模態理解與生成的視覺編碼
我們之前專注於用於圖像理解的多模態 LLM,剛才在上面看到了 Emu 3 用於圖像生成的例子。現在,《Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation》論文(2024 年 10 月 17 日)介紹了一個在單個 LLM 主幹中統一多模態理解和生成任務的框架。
Janus 的一個關鍵特徵是解耦視覺編碼路徑,以解決理解和生成任務的不同需求。研究人員認為,圖像理解任務需要高維語義表示,而生成任務則需要圖像中的詳細局部信息和全局一致性。通過分離這些路徑,Janus 有效地管理了這些不同的需求。
該模型採用了與 Baichuan-Omni 類似的 SigLIP 視覺編碼器來處理視覺輸入。對於圖像生成,它利用向量量化 (VQ) 標記生成器來處理生成過程。Janus 中的基礎 LLM 是具有 13 億參數的 DeepSeek-LLM。

圖中模型的訓練過程遵循三個階段,如下圖所示。

在第一階段,僅訓練投影層和圖像輸出層,而 LLM、理解和生成編碼器保持凍結。在第二階段,解凍 LLM 主幹和文本輸出層,允許在理解和生成任務之間進行統一的預訓練。最後,在第三階段,解凍包括 SigLIP 圖像編碼器在內的整個模型進行監督微調,使模型能夠充分整合並完善其多模態能力。
結論
你可能已經注意到,我幾乎完全跳過了建模和計算性能的比較。首先,由於普遍存在的數據污染(即測試數據可能已包含在訓練數據中),在公共基準測試上比較 LLM 和多模態 LLM 的性能具有挑戰性。
此外,架構組件差異巨大,難以進行公平的比較。因此,非常感謝 NVIDIA 團隊開發了不同風味的 NVLM,這至少允許在純解碼器和跨注意力方法之間進行比較。
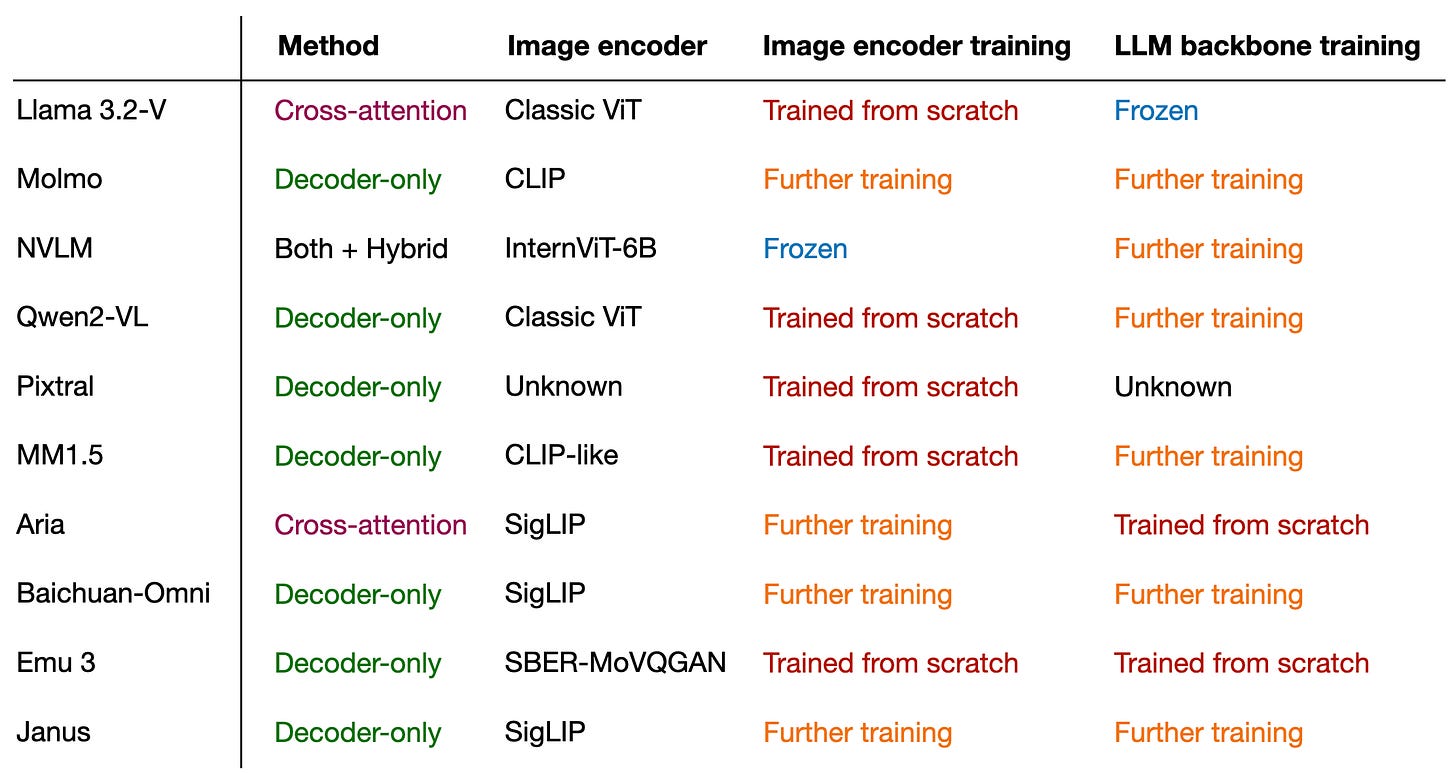
無論如何,本文的主要收穫是多模態 LLM 可以通過許多不同的方式成功構建。下圖總結了本文涵蓋的模型的不同組件。
我希望你覺得閱讀本文有所收穫,並對多模態 LLM 的工作原理有了更好的理解!
這本雜誌是一個個人的熱情項目。對於那些希望支持我的人,請考慮購買一本我的《從零開始構建大型語言模型》(Build a Large Language Model (From Scratch))。(我有信心你會從這本書中收穫頗豐,因為它以其他地方找不到的詳細程度解釋了 LLM 的工作原理。)
如果你讀過這本書並有幾分鐘空閒時間,如果你能留下簡短的評論,我將不勝感激。這對我們作者幫助很大!
或者,我最近也在 Substack 上啟用了付費訂閱選項,以直接支持這本雜誌。
你的支持意義重大!謝謝!
相關文章