
大型語言模型研究洞察:指令遮罩與全新 LoRA 微調實驗
這篇文章探討了指令微調的最新研究,特別是質疑了在訓練過程中遮罩指令的慣例,並比較了 LoRA 與全參數微調在不同領域下的表現。
LLM 研究洞察:指令遮罩與新 LoRA 微調實驗
探討 2024 年 5 月發佈的最新模型與 AI 研究
本月,我將介紹三篇與大型語言模型(LLM)中的指令微調(Instruction Finetuning)以及使用 LoRA 進行參數高效微調(Parameter-efficient Finetuning)相關的新論文。我每天都在工作中使用這些方法,因此看到能提供實用見解的新研究總是令人興奮。
這篇文章可能會比平時短一些,因為我目前正在完成我的新書《從頭開始構建大型語言模型》(Build a Large Language Model From Scratch)的最後一章。此外,我正在為本週三關於 LLM 的虛擬 ACM 技術演講做準備。這場演講是免費且對所有人開放的,如果你感興趣,非常歡迎參加!

1. 對指令計算損失的指令微調 (Instruction Tuning With Loss Over Instructions)
本月引起我注意的一篇論文是《Instruction Tuning With Loss Over Instructions》。
在這篇論文中,作者質疑了指令微調中一個被廣泛接受的慣例:在計算損失(Loss)時遮罩(Masking)指令部分。但在討論研究結果之前,讓我們從總體概述開始。
1.1 指令微調期間的指令遮罩
指令微調(簡稱 Instruction Tuning)是提高預訓練 LLM 遵循指令(如「總結這篇文章」、「翻譯這個句子」等)回應能力的任務。

在對 LLM 進行指令微調時,通常會在計算損失時遮罩掉指令本身。例如,這在我們的 LitGPT 庫中是默認設置,我也在我的《從頭開始構建大型語言模型》一書的第 7 章中使用了它(不過,我現在正考慮將遮罩部分移至讀者練習中)。
在其他流行的 LLM 庫(如 Axolotl)中,這也是通過 config.yaml 中的 train_on_inputs: false 默認設置自動完成的。在 Hugging Face 中,這不是默認設置,但可以通過 DataCollatorForCompletionOnlyLM 數據集整理器來實現,詳見其文檔。

如上所述,遮罩輸入提示(Prompts)是一項常規任務,一些論文可能會包含有遮罩和無遮罩的比較。例如,QLoRA 論文在其附錄中包含了一項比較,發現遮罩的效果更好。

請注意,MMLU 是一個專注於衡量多選題性能的基準測試,作者並未衡量或研究當微調後的模型作為聊天機器人使用時,這會如何影響對話性能。
1.2 指令建模 (Instruction Modeling)
在上一節對該主題進行簡要介紹後,讓我們來看看《Instruction Tuning With Loss Over Instructions》這篇論文。在這項研究中,作者系統地調查了指令被遮罩與未遮罩時 LLM 性能的差異。

上圖中的方法 1 是實現 LLM 時的默認方法,因為它不需要任何額外工作或修改損失函數。這就是作者在論文中稱為「指令建模」的方法。(在論文中,他們還額外遮罩了可能出現在非 Alpaca 提示模板中的特殊提示標記,如 <|user|>、<|assistant|> 和 <|system|>。)
方法 2 是目前實踐中最常用的方法,即在計算損失時遮罩除回應(Response)之外的所有內容。在論文中,他們將此方法稱為「指令微調」(在這種情況下命名有點不幸,因為我們不是在「微調」指令,而是將指令排除在損失之外,與方法 1 相比)。
在繪製上圖時,我想到了論文中未探討的一個有趣的第三種方法:遮罩特定於提示的樣板文本。例如,在 Alpaca 風格的提示中,所有示例都以「Below is an instruction...」開頭。與實際的指令和輸入相比,這段文本是恆定的,因此可以從損失中排除。這在論文中沒有研究,但可能是一個有趣的額外實驗,我計劃將其作為另一個讀者練習(及解答)添加到我的《從頭開始構建 LLM》一書中。
結果表明,「指令建模」(即不遮罩指令)似乎優於遮罩方法,如下圖所示。

然而,「指令建模」的性能取決於 (a) 指令與回應長度的比例,以及 (b) 數據集的大小(就訓練示例的數量而言)。

對上述數據集長度和大小依賴性的一個合理解釋是:如果回應很短且訓練示例很少,模型就更容易記住回應,因此包含指令建模(即在損失中建模更多的模型輸出)可以幫助減少過擬合。
1.3 結論
簡而言之,作者發現回歸基礎、不遮罩指令,有利於模型性能。
令人驚訝的是,不遮罩指令(除了遮罩 <|user|>、<|assistant|> 和 <|system|> 等特殊提示標記)這種更簡單的方法效果更好。
根據我個人的經驗,過去當我嘗試這兩種方法且沒有看到明顯的勝出者時,我通常不會對遮罩進行太多實驗,而是如果效果不好,則更多地專注於更改其他設置。事後看來,考慮對(不)遮罩方法進行更多實驗可能是有意義的,因為它似乎取決於數據集的大小和長度。
Ahead of AI 是一份讀者支持的出版物。要接收新文章並支持我的工作,請考慮成為免費或付費訂閱者。
2. LoRA 學得更少,遺忘也更少 (LoRA learns less and forgets less)
《LoRA Learns Less and Forgets Less》是一項關於使用低秩自適應(LoRA)微調 LLM 的全面實證研究,在編程和數學兩個目標領域將 LoRA 與全量微調(Full Finetuning)進行了比較。除了這些領域外,比較還擴展到兩個目標任務:指令微調和持續預訓練。
如果你在繼續閱讀前需要複習 LoRA,我最近在《改進 LoRA:從頭開始實現權重分解低秩自適應 (DoRA)》中介紹過:
改進 LoRA:從頭開始實現權重分解低秩自適應 (DoRA)
2.1 LoRA 學得更少
根據第一組結果,LoRA 的學習量顯著低於全量微調,如下圖所示。在我看來,這是預料之中的,因為更新較少的參數會限制學習能力。學習新知識通常比將預訓練的基礎模型轉換為指令遵循模型需要更多的容量。

在上圖中,同樣值得注意的是,持續預訓練中 LoRA 與全量微調之間的差距大於指令微調。這與常見的直覺一致,即預訓練主要是教給 LLM 新知識,而指令微調主要是改變 LLM 的行為。
接下來,檢查數學領域而非編程領域的同一組實驗,我們觀察到全量微調與 LoRA 之間的差距縮小了,如下圖所示。
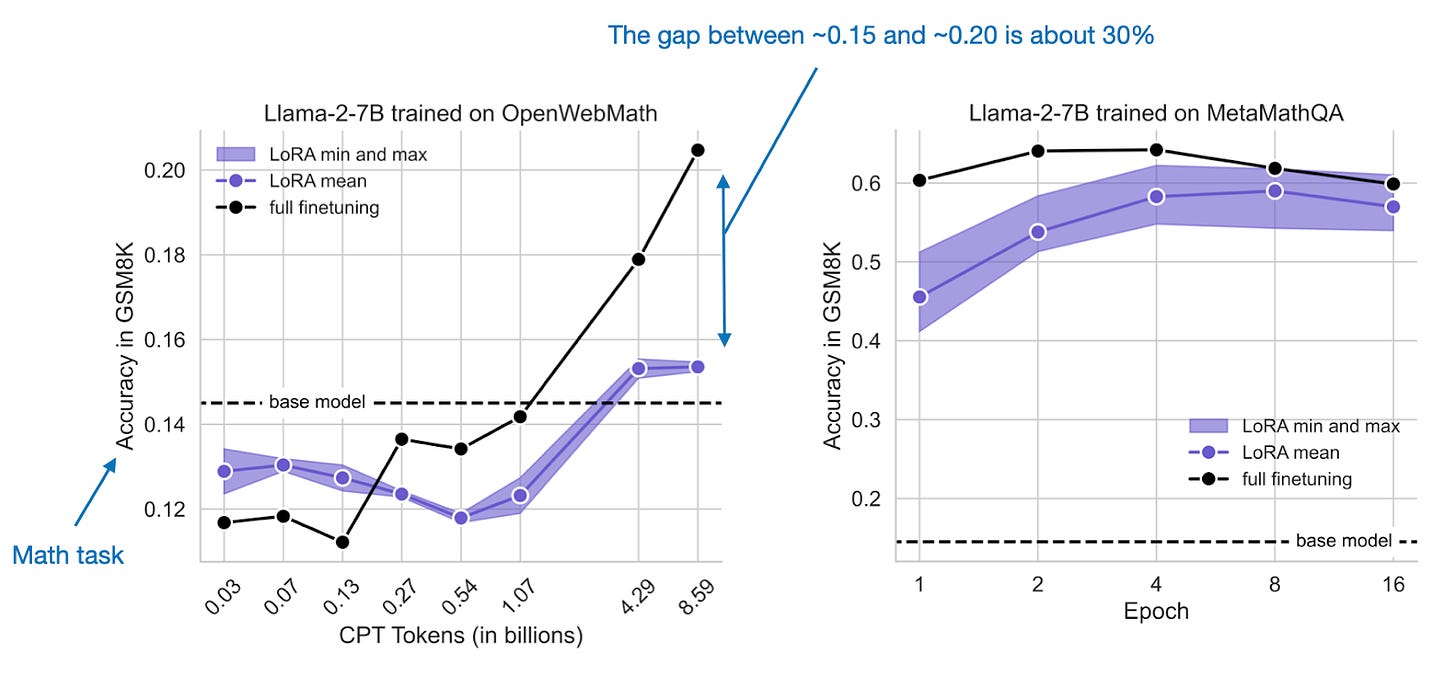
有人可能會認為,解決數學問題比編程更接近 LLM 的源領域。換句話說,LLM 在預訓練期間遇到的數學問題可能比編程任務更多。此外,數學問題通常用文字描述,而編程需要一套全新的術語。
作為總結,到目前為止我們可以得出結論:新任務與預訓練數據的偏差越大,在獲取新知識(例如通過持續預訓練)時,使用全量微調比 LoRA 更有優勢。
2.2 LoRA 遺忘更少
上面我們研究了 LoRA 在知識更新方面與全量微調的比較。下一組實驗評估了這兩種方法在經過額外訓練(通過持續預訓練和指令微調)後遺忘信息的情況。與之前的結果不同,這裡他們衡量的是在原始源任務上的性能。

從上圖可以看出,當這些方法應用於遠離源領域(此處為編程)的數據集時,全量微調比 LoRA 遺忘的知識多得多。數學數據集的差距較小,如下所示。

2.3 結論
LoRA 還是全量微調?或許正如預期的那樣,這一切都歸結為學習與遺忘的權衡。全量微調在新目標領域表現更強,而 LoRA 在原始源領域保持更好的性能 *。
直覺上,我懷疑這僅僅是 LoRA 更改模型中較少參數的副作用——LoRA 的目標,顧名思義,是低秩自適應,這意味著不實質性地修改所有模型參數。
此外,在實踐中,這通常不是是否使用全量微調或 LoRA 的問題,因為後者由於節省內存和較低的存儲佔用,可能是唯一可行的選擇。
儘管如此,看到這一點被徹底展示並在詳盡的實驗細節中進行分析是非常有趣的。(實驗是使用 7B 和 13B 的 Llama 2 模型進行的)。
*(Mariano Kamp 向我指出的一個注意事項是,他們在 LoRA 實驗中沒有更新嵌入層,這在將模型適應新任務時至關重要。)
3. MoRA:用於參數高效微調的高秩更新 (MoRA: High-Rank Updating for Parameter-Efficient Finetuning)
每當有類似 LoRA 的高效 LLM 微調新論文發表時,總是令人興奮。在《MoRA: High-Rank Updating for Parameter-Efficient Finetuning》中,作者採取了一種相關但相反的方法來進行低秩自適應,即用方陣替換 LoRA 適配器。
此外,我的《從頭開始構建大型語言模型》一書的附錄 E 為訓練用於分類垃圾郵件的 GPT 模型從頭實現了 LoRA。
3.1 低秩 vs 高秩
如下圖所示,MoRA 使用一個小的方陣 (M) 來代替 LoRA 的兩個小矩陣 A 和 B。我們將在下一節回到討論這是如何工作的。

為什麼要引入另一個帶有「高」秩的 LoRA 替代方案?原因是 LoRA 以相對有限的方式更新原始權重。在我看來,這是設計使然,因為當我們用 LoRA 微調模型時,我們不想過多地擾動或改變原始模型的能力。然而,雖然這種低秩更新對於指令微調等任務是有效且足夠的,但低秩更新的一個缺點是,對於吸收新知識(例如通過持續預訓練,也稱為對常規文本數據進行微調,而非指令微調)相對無效。
在 MoRA 論文中,作者尋求開發一種參數高效的微調方法,該方法在指令微調和持續預訓練中吸收新知識方面都能表現良好。
下面是基於一個要求 LLM 記住特定標識符代碼的合成數據集,對 LoRA、MoRA 和常規全量微調 (FFT) 進行的並排比較。

在圖中顯示的合成基準測試中,MoRA 具有與全量微調相似的知識吸收(或記憶)能力。高秩的 LoRA (r=256) 最終也能記住合成標識符代碼,但需要更多步驟。小秩的 LoRA (r=8) 則無法記住。
請注意,LLM 中的記憶並不一定是好事(當然,歷史日期和事實除外)。然而,LoRA 不易記憶的事實也可以在減少過擬合訓練數據的傾向方面發揮優勢。話雖如此,這個基準測試主要探測 LoRA 是否增加了足夠的容量來學習新知識。可以將其視為類似於 Batch Overfitting,這是一種流行的調試技術,我們嘗試讓模型在訓練集的一小部分上過擬合,以確保我們正確實現了架構。(我們將在下一節查看真實數據的基準測試。)
3.2 MoRA 簡述
那麼,MoRA 是如何實現的呢?
在這裡,作者使用一個可訓練的方陣應用於原始權重 W,而不是 LoRA 中的矩陣 AB。這個方陣通常比原始權重矩陣小得多。事實上,LoRA 和 MoRA 中的可訓練參數數量甚至可以相同。
例如,如果原始權重層有 4096 × 4096 = 16,777,216 個參數,r=8 的 LoRA 有 4096×8 + 8×4096 = 65,536 個參數。使用 MoRA,我們可以用 r=256 來匹配參數數量,即 256 × 256 = 65,536。
你如何將這個 256×256 的矩陣應用於原始的 1024×1024 權重矩陣?他們定義了幾種非參數壓縮和解壓縮方法(細節超出了本文範圍,但我嘗試在圖中用 PyTorch 代碼對其進行總結)。
左圖:當總參數數量相同時,LoRA 和 DoRA 矩陣維度的可視化。右圖:說明 MoRA 矩陣壓縮和解壓縮的示例代碼。

LoRA 和 MoRA 相比如何?
查看真實數據集基準測試(見下表),MoRA 和 LoRA 處於相對相似的水平。然而,在生物醫學和金融數據的持續預訓練情況下,MoRA 優於所有 LoRA 變體;只有全量微調 (FFT) 表現更好。此外,一個有趣的觀察是 LoRA 與 DoRA 持平或優於 DoRA,DoRA 是我幾個月前在《改進 LoRA:從頭開始實現權重分解低秩自適應 (DoRA)》中介紹的一種 LoRA 變體:
改進 LoRA:從頭開始實現權重分解低秩自適應 (DoRA)

3.3 結論
事實證明,相對簡單的 MoRA 方法效果出奇地好。而且它在持續預訓練中確實略微優於 LoRA。然而,在小秩的指令微調和數學推理方面,它確實落後於 LoRA 一點。對我來說,這些結果還不足以說服我用 MoRA 取代 LoRA。儘管如此,這篇論文提出了一種有趣的方法和一組有趣的實驗。
4. 5 月份其他有趣的研究論文
以下是我本月偶然發現的其他精選有趣論文。鑑於列表較長,我用星號 (*) 標出了我認為特別有趣的 10 篇。但請注意,此列表及其註釋純粹基於我的興趣以及與我個人項目的相關性。
Contextual Position Encoding: Learning to Count What's Important by Golovneva, Wang, Weston, and Sukhbaatar (29 May), https://arxiv.org/abs/2405.18719
該研究引入了上下文位置編碼 (CoPE),這是一種新的 LLM 位置編碼方法,可適應上下文,允許更抽象的基於位置的注意力。
LLaMA-NAS: Efficient Neural Architecture Search for Large Language Models by Sarah, Sridhar, Szanking, and Sundaresan (28 May), https://arxiv.org/abs/2405.18377
這項研究介紹了一種使用 one-shot NAS 和遺傳算法優化 LLaMA2-7B 模型的方法,在精度損失極小的情況下實現了 1.5 倍的尺寸縮減和 1.3 倍的吞吐量加速,優於傳統的剪枝和稀疏化技術。
VeLoRA: Memory Efficient Training using Rank-1 Sub-Token Projections by Miles, Reddy, Elezi, and Deng (28 May), https://arxiv.org/abs/2405.17991
本文介紹了一種用於訓練和微調 LLM 的內存高效算法,該算法在不損失性能的情況下壓縮中間激活,將標記(tokens)劃分為子標記,並將其投影到固定的一維子空間上。
- gzip Predicts Data-dependent Scaling Laws by Pandey (26 May), https://arxiv.org/abs/2405.16684
這項研究挑戰了神經語言模型縮放定律與數據無關的觀點,證明了模型性能縮放對訓練數據複雜度很敏感,提出了一種新的數據依賴縮放定律,將模型的計算最優資源分配與訓練數據的 gzip 可壓縮性聯繫起來。
Offline Regularised Reinforcement Learning for Large Language Models Alignment by Yao, Wu, Yang, et al. (22 May), https://arxiv.org/abs/2405.13800
本文介紹了直接獎勵優化 (DRO),這是一個使用更豐富的單軌跡數據集(由提示、回應和用戶反饋組成)來對齊大型語言模型的新框架,消除了對像直接偏好優化 (DPO) 那樣成對偏好數據的需求。
Trans-LoRA: Towards Data-free Transferable Parameter Efficient Finetuning, by Wang, Ghosh, Cox, et al. (27 May), https://arxiv.org/abs/2405.17258
Trans-LoRA 利用合成數據,實現了在不同基礎模型之間近乎無數據、無損的低秩適應器 (LoRA) 遷移。
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training (26 May) by Du, Luo, Qiu, et al., https://arxiv.org/abs/2405.15319
本文研究了 LLM 預訓練中的模型增長方法,特別是一種稱為 Gstack 的深度堆疊算子,以加速訓練並提高性能。
The Road Less Scheduled, Defazio, Yang, Mehta, et al. (24 May), https://arxiv.org/abs/2405.15682
該研究引入了一種無調度優化方法,其性能優於傳統的學習率調度,且不需要預定義的停止時間,且除了標準基於動量的優化器中的參數外,不增加額外的超參數。
Instruction Tuning With Loss Over Instructions by Shi, Yang, Wu, et al. (23 May), https://arxiv.org/abs/2405.14394
本文比較了在遮罩和不遮罩指令的情況下進行指令微調的 LLM 性能,發現不遮罩往往表現更好。
SimPO: Simple Preference Optimization with a Reference-Free Reward by Meng, Xia, and Chen (23 May), https://arxiv.org/abs/2405.14734
直接偏好優化 (DPO) 簡化了 LLM 的人類反饋強化學習,而本文通過平均對數概率並消除對參考模型的需求,進一步簡化了 DPO。
AlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability by Fei Zhao, Taotian Pang, and Chunhui Li (23 May), https://arxiv.org/abs/2405.14129
AlignGPT 是一種新的多模態大型語言模型,通過在預訓練期間區分圖像-文本對的對齊能力,並在指令微調期間自適應地調整這些能力,改進了跨模態對齊。
Dense Connector for MLLMs by Yao, Wu, Yang, et al. (22 May), https://arxiv.org/abs/2405.13800
本文介紹了 Dense Connector,這是一種視覺-語言連接器,通過集成多層視覺特徵來改進多模態大型語言模型 (MLLM)。
Attention as an RNN by Feng, Tung, Hajimirsadeghi, et al. (22 May), https://arxiv.org/abs/2405.13956
這項研究將 Transformer 重新解釋為 RNN 的一種變體,並引入了 Aaren,這是一個新的基於注意力的模塊,它結合了 Transformer 的並行訓練能力與傳統 RNN 的高效、恆定內存更新。
- MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning by Jiang, Huang, Luo, et al. (20 May), https://arxiv.org/abs/2405.12130
本文分析了 LLM 中低秩更新的局限性,並引入了 MoRA,這是一種使用方陣進行高秩更新的方法,它匹配了 LoRA 的參數效率,並在內存密集型任務上優於 LoRA,同時在其他任務上保持相當的性能。
SLAB: Efficient Transformers with Simplified Linear Attention and Progressive Re-parameterized Batch Normalization by Guo, Chen, Tang, and Wang (19 May), https://arxiv.org/abs/2405.11582
本文提出了一種在基於 Transformer 的模型中逐步用重參數化 BatchNorm 替換 LayerNorm 的方法,以及一個簡化的線性注意力 (SLA) 模塊。
Towards Modular LLMs by Building and Reusing a Library of LoRAs by Ostapenko, Su, Ponti, et al. (17 May), https://arxiv.org/abs/2405.11157
這項研究探討了為新任務重用基礎 LLM 中訓練好的適配器,介紹了一種使用基於模型的聚類 (MBC) 構建適配器庫的方法,以及一種無需重新訓練即可提高任務泛化能力的零樣本路由機制。
Chameleon: Mixed-Modal Early-Fusion Foundation Models by unknown authors at Meta AI (16 May), https://arxiv.org/abs/2405.09818
Chameleon 是一種早期融合、基於標記的混合模態模型,擅長以任何順序處理和生成圖像和文本。
Xmodel-VLM: A Simple Baseline for Multimodal Vision Language Model by Xu, Liu, He, et al. (15 May), https://arxiv.org/abs/2405.09215
本文介紹了 Xmodel-VLM,這是一個 1B 規模、高效的多模態視覺語言模型,專為在消費級 GPU 上部署而設計。
- LoRA Learns Less and Forgets Less by Biderman, Ortiz, Portes, et al. (15 May), https://arxiv.org/abs/2405.09673
這項研究在編程和數學領域將參數高效微調方法 LoRA 與全量微調進行了比較,發現雖然 LoRA 通常表現不佳,但它能更好地保留目標領域之外的基礎模型能力,並提供更強的正則化。
RLHF Workflow: From Reward Modeling to Online RLHF by Dong, Xiong, Pang, et al. (13 May), https://arxiv.org/abs/2405.07863
本報告概述了一種用於 LLM 的在線迭代 RLHF 方法,該方法使用代理模型模擬人類反饋,其性能優於離線方法,並產生了高性能的 SFR-Iterative-DPO-LLaMA-3-8B-R 模型。
PHUDGE: Phi-3 as Scalable Judge by Deshwal and Chawla (12 May), https://arxiv.org/abs/2405.08029
本報告介紹了 PHUDGE,這是一個 Phi3 模型,在評分任務的速度和有效性方面超過了 ChatGPT 的 GPT 4。
Value Augmented Sampling for Language Model Alignment and Personalization by Han, Shenfeld, Srivastava, et al. (10 May), https://arxiv.org/abs/2405.06639
這項研究引入了值增強採樣 (VAS),這是一個新的獎勵優化框架,可以在不修改權重或共同訓練策略和價值函數的情況下高效對齊 LLM,並能使像 ChatGPT 這樣僅提供 API 的 LLM 實現適應。
- Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? by Gekhman, Yona, Aharoni, et al. (9 May), https://arxiv.org/abs/2405.05904
這項研究探討了在 LLM 的監督微調期間引入新事實信息的影響,發現雖然這些模型難以納入新事實且學習速度比熟悉信息慢,但最終對這些事實的學習會線性增加模型產生事實錯誤回應的傾向。
- Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models by Land and Bartolo (8 May), https://arxiv.org/abs/2405.05417
本文對 LLM 中的分詞器問題進行了透徹分析,並提出了一種自動檢測「故障標記」(glitch tokens)的方法——這些標記存在於分詞器中,但在訓練數據中幾乎或完全缺失。
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model by Liu, Feng, Wang, et al. (8 May), https://arxiv.org/abs/2405.04434
DeepSeek-V2 是一個擁有 236B 參數的混合專家 (MoE) 語言模型(每個標記僅使用 21B 激活參數),它引入了多頭潛在注意力 (MLA),旨在將鍵值 (KV) 緩存壓縮為潛在向量,從而提高推理效率並減少內存需求。
You Only Cache Once: Decoder-Decoder Architectures for Language Models by Sun, Dong, Zhu, et al. (8 May), https://arxiv.org/abs/2405.05254
該研究介紹了 YOCO,這是一種用於大型語言模型的解碼器-解碼器架構,其特點是使用自解碼器來編碼由交叉解碼器使用的全局鍵值緩存,大幅減少了 GPU 內存需求並增強了預填充性能。
- xLSTM: Extended Long Short-Term Memory by Beck, Poeppel, Spanring, et al. (7 May), https://arxiv.org/abs/2405.04517
這項研究探討了通過指數門控和增強內存結構等新修改將 LSTM 擴展到數十億參數的潛力,並將這些集成到 xLSTM 架構中,其性能與最先進的基於 Transformer 和狀態空間的 LLM 相當。
vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention by Prabhu, Nayak, Mohan et al. (7 May), https://arxiv.org/abs/2405.04437
本文介紹了 vAttention,這是一種用於管理 LLM 中 GPU 內存的方法,它將 KV 緩存保持在連續的虛擬內存中,並利用現有的低級系統支持進行請求分頁,以動態分配物理內存。
- Is Flash Attention Stable? by Golden, Hsia, Sun, et al. (5 May), https://arxiv.org/abs/2405.02803
這項研究開發了一個框架來分析數值偏差對大規模機器學習模型訓練的影響,發現廣泛使用的 Flash Attention 優化存在顯著的數值偏差,儘管這些偏差的影響小於低精度訓練帶來的影響。
- What Matters When Building Vision-Language Models? by Laurencon, Tronchon, Cord, and Sanh (3 May), https://arxiv.org/abs/2405.02246
本文指出了視覺語言模型 (VLM) 中關鍵設計選擇缺乏依據的問題,並介紹了 Idefics2,這是一個新的 80 億參數 VLM,通過嚴格評估不同的架構、數據和訓練方法實現了最先進的性能,其模型和數據集已公開發佈。
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models by (2 May), https://arxiv.org/abs/2405.01535
本文介紹了 Prometheus 2,這是一個開源評估器 LLM,通過與人類和 GPT-4 的判斷緊密對齊,並提供評估格式和標準的靈活性,解決了先前模型的局限性。
- A Careful Examination of Large Language Model Performance on Grade School Arithmetic by Zhang, Da, Lee, et al. (1 May), https://arxiv.org/abs/2405.00332
這項研究引入了 GSM1k,這是一個鏡像已建立的 GSM8k 的新基準測試,用於測試 LLM,發現性能顯著下降,這表明先前的成功可能更多源於記住訓練數據而非真正的數學推理。(註:GSM8k 是一個旨在通過呈現典型的小學難度問題來評估 LLM 數學推理能力的基準測試。)
Self-Play Preference Optimization for Language Model Alignment by Wu, Sun, Yuan, et al. (1 May), https://arxiv.org/abs/2405.00675
本文介紹了用於語言模型對齊的自我博弈概率偏好優化 (SPPO) 方法,該方法使用自我博弈框架通過迭代策略更新來逼近納什均衡。
Is Bigger Edit Batch Size Always Better? An Empirical Study on Model Editing with Llama-3 by Yoon, Gupta, and Anumanchipalli (1 May), https://arxiv.org/abs/2405.00664
這項研究通過在各個層測試順序、批量和新型順序批量編輯,檢查了 Llama-3 上模型編輯技術的有效性,結論是較小的順序編輯在提高模型性能方面優於較大的批量編輯。(註:編輯批量大小是指在一輪編輯中同時對模型參數進行更改的數量。)
本雜誌是一個個人熱情項目,不提供直接報酬。然而,對於那些希望支持我的人,請考慮購買我的一本書。如果你覺得它們富有洞察力且有益,請隨時向你的朋友和同事推薦。(通過 Amazon 上的書評與他人分享你的反饋也會有很大幫助!)

你的支持意義重大!謝謝!
相關文章