大型語言模型的指令預訓練技術
這篇文章探討了從零開始生成指令微調數據的成本效益方法,並研究了在大型語言模型預訓練階段加入合成指令應答對所帶來的優勢。
指令預訓練大語言模型
指令微調的最新研究
上個月發生了很多大事:Apple 宣布整合裝置端大語言模型(LLM)、Nvidia 分享了大型 Nemotron 模型、FlashAttention-3 發布、Google 的 Gemma 2 問世,還有更多。
你可能已經在各種新聞管道讀過這些消息。因此,在本文中,我想專注於近期圍繞「指令微調」(instruction finetuning)的研究,這是訓練 LLM 的一項基礎技術。
本文將涵蓋的內容:
- 一種生成指令微調數據的新型且具成本效益的方法
- 從零開始進行指令微調
- 使用指令數據預訓練 LLM
- Gemma 2 的新功能概覽
- 六月份發布的所有其他有趣研究論文概覽
祝閱讀愉快!
1. 從零開始創建對齊數據
論文《Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing》分享了一個迷人的技巧,可以為 LLM 指令微調生成高質量的數據集。雖然這沒有提供特別新穎的研究見解,但它是那種非常實用且看似超級有用的開發技巧。
1.1 從無到有生成指令數據集
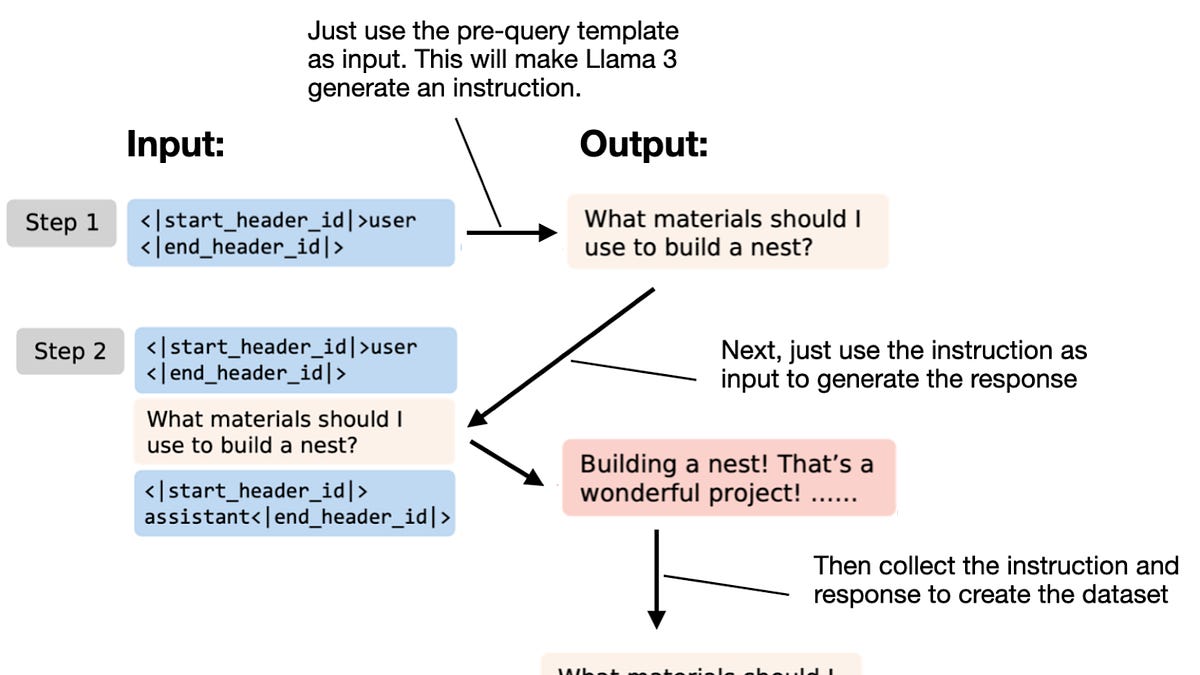
這種指令數據生成方法與其他方法的不同之處在於,它可以完全自動化,且不需要任何初始問題或指令。正如論文標題所示,它能夠從「無(Nothing)」中創建指令數據集——我們唯一需要的是一個在本地運行的 Llama 3 8B 模型。下圖總結了該方法的工作原理。

基本上,如上圖所示,我們只需使用預查詢模板(pre-query template)向 Llama 3 8B Instruct 模型發出提示,它就會為我們生成一條指令。然後,我們將該指令餵回給 LLM,它就會生成一個回答。如果我們重複這個過程幾千次,就能獲得一個用於指令微調的數據集。(可選步驟:我們可以使用 LLM 根據質量過濾指令-回答對。)
1.2 數據集質量
令人著迷的是,作者發現使用生成的指令數據集,僅通過指令微調(不進行基於 RLHF 和 DPO 的偏好微調)來微調 Llama 3 8B 基礎模型,其表現就優於 Meta AI 原始的 Llama 2 8B Instruct 模型,如下圖所示。

上圖中顯示的 Magpie 結果僅使用了 30 萬個樣本。相比之下,原始的 Llama 3 Instruct 模型是在 1 億個樣本上進行微調和對齊的!
1.3 在本地運行數據集生成
起初我也持懷疑態度,所以我嘗試自己實現。它真的有效!在這裡,你可以找到我使用 Ollama 的重新實現,它甚至在 MacBook Air 上也能流暢地本地運行。

1.4 更多細節
作者創建了兩組數據集:使用 Llama 3 70B Instruct 模型的「Pro」版本,以及使用 Llama 3 8B Instruct 模型的「Air」版本。如前圖所示,當用於指令微調 Llama 3 8B 基礎模型時,Magpie-Pro 生成的數據集產生的模型比 Magpie-Air 數據集稍強。
下圖顯示了通過 LLM 評分的數據集質量和難度的額外比較。
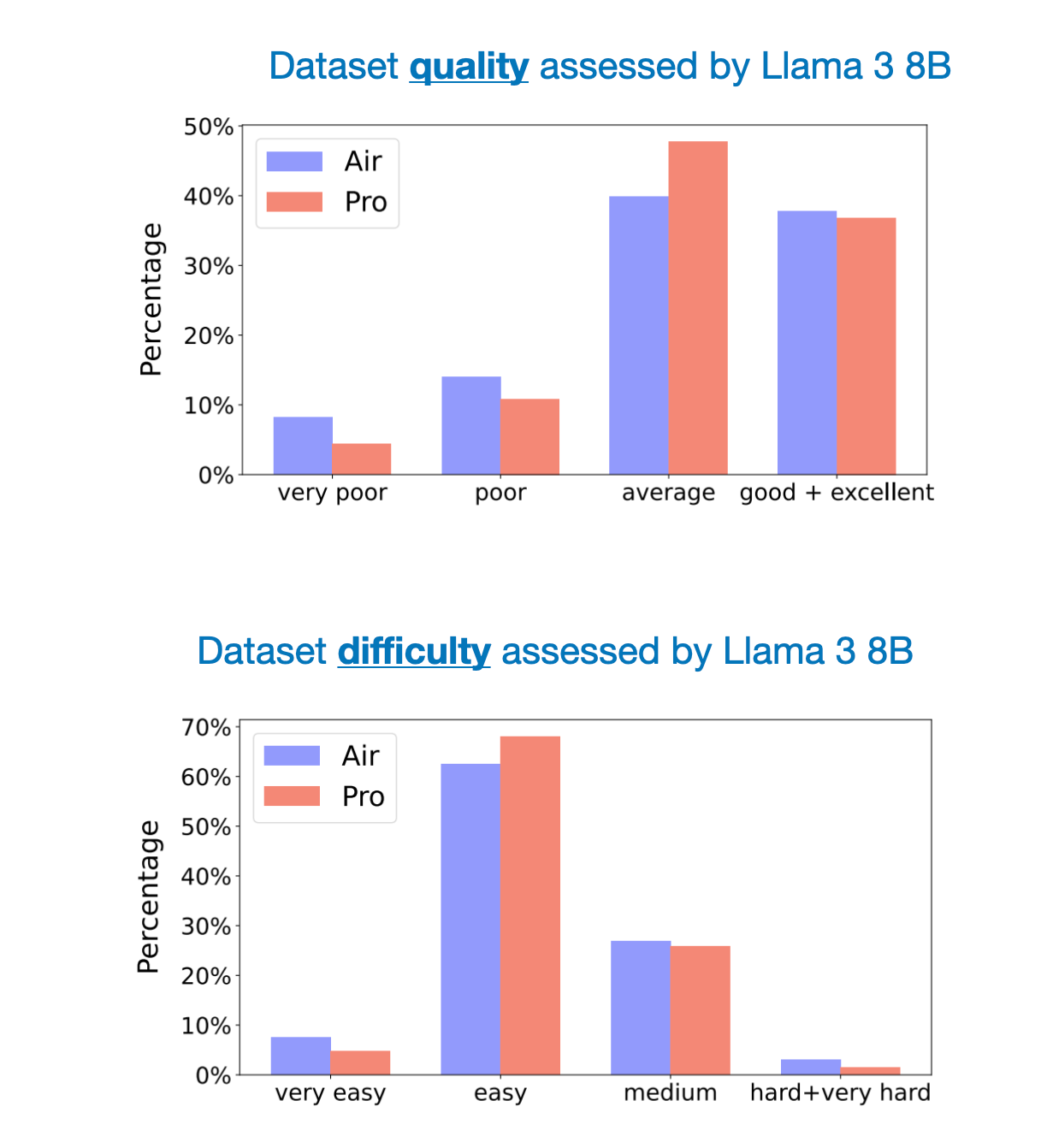
如上圖所示,Air 和 Pro 數據集的質量大致相當。此外,如果能看到 Alpaca 數據集與這些數據集的對比會很有趣。(假設是 Magpie 數據的質量遠高於 Alpaca,但有個參考點會很有意思。)
此外,論文中的分析表明,該數據集的廣度或多樣性遠大於其他流行的指令微調數據集,如 Alpaca、Evol Instruct 和 UltraChat。此外,與使用其他指令微調數據集訓練的模型相比,Magpie-Pro 微調的模型也表現得非常出色。
1.5 結論
總體而言,我認為 Magpie 是一個有趣的開發技巧,一方面其有效性令人著迷,另一方面它具有很強的實用價值。我肯定會考慮將其作為未來構建通用指令數據集的一個有趣、簡單且具成本效益的候選方案。
2. 從零開始指令微調
如果你正在尋找理解 LLM 指令微調過程的資源,我很高興地分享,關於指令微調 LLM 的第 7 章現在終於在 Manning 網站上線了。
這是書中最長的一章,採用從零開始的方法來實現指令微調流水線。這包括從輸入格式化到使用自定義整理函數(collate function)進行批處理、遮蔽填充標記(padding tokens)、訓練循環本身,以及在自定義測試集上對微調後的 LLM 回答質量進行評分的所有內容。
(練習包括更改提示風格、指令遮蔽和添加 LoRA。)
祝編碼愉快!

PS:這也是最後一章,出版社目前正在準備印刷版的排版。
3. 指令預訓練大語言模型
在論文《Instruction Pre-Training: Language Models are Supervised Multitask Learners》(https://arxiv.org/abs/2406.14491) 中,研究人員調查了是否可以通過包含合成的指令-回答對,而不是僅僅使用原始文本,來使 LLM 預訓練更有效率。(這裡的「原始文本」是指來自書籍、網站、論文等未經重新處理成特定格式的文本。)

具體而言,研究人員實驗了通過「指令合成器(instruction synthesizer)」從原始訓練語料庫本身生成指令-回答數據,這是一個專門為此任務微調的 LLM。
(請注意,這不是第一篇提出將原始文本格式化為指令數據的論文。我能想到的另一項工作是《Genie: Achieving Human Parity in Content-Grounded Datasets Generation》(https://arxiv.org/abs/2401.14367)。我還記得幾個月前看過另一篇論文或博客文章在預訓練期間使用指令數據——我曾與同事討論過這種方法——但遺憾的是,我找不到參考資料了。儘管如此,這裡討論的論文特別引人入勝,因為它建立在可本地運行的開源 LLM 之上,並涵蓋了預訓練和持續預訓練。)
3.1 指令合成器
在我們深入研究預訓練和持續預訓練結果之前,先談談該方法的核心組件:指令合成器。這是一個開源的 Mistral 7B v0.1 LLM(我去年在這裡寫過:https://magazine.sebastianraschka.com/i/138555764/mistral-b),它經過微調,可以從原始文本生成指令-回答對。
為了微調這個合成器,研究人員使用了 HotpotQA (https://arxiv.org/abs/1809.09600) 等數據集,該數據集由維基百科中與問題和答案相關的段落組成。為此,作者還確保涵蓋了各種任務,如常識推理、情感分析、數學問題等。
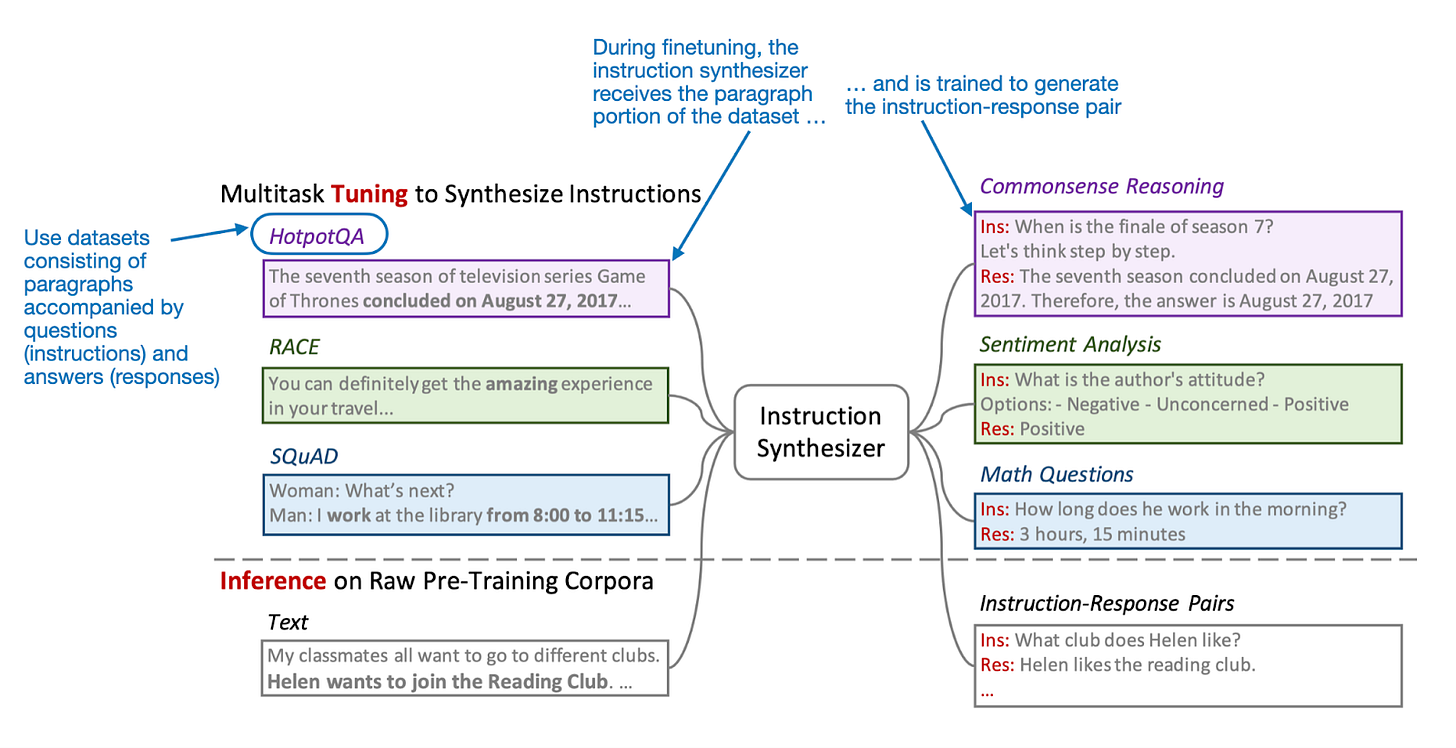
一旦開發出這個指令合成器(即微調完成),它就可以用來生成預訓練目標 LLM 的輸入數據。
關於指令合成器最後一個值得注意的細節是,多個原始文本 (Tn) 和指令-回答對 (In ⊕ Rn) 被拼接為少樣本(few-shot)示例,如下圖所示。

3.2 使用指令數據進行預訓練
現在我們已經討論了生成指令-回答對的方法,讓我們進入有趣的部分:模型在這種增強數據集上的訓練效果如何。第一組結果觀察了兩個從零開始訓練的小模型:5 億參數和 13 億參數(兩者都基於 Mistral 架構)。

如上表所示,通過提出的指令預訓練方法(Instruct PT)訓練的模型在大多數基準任務上表現最好(數值越高越好)。
不過請注意,它看到的標記(tokens)比 Vanilla PT 方法更多,因為它包含了合成的指令-回答對。因此,作者加入了 Mix PT 比較,這是一個在包含原始文本和用於訓練合成器的指令數據的混合數據上訓練的模型。
從這個比較中,我們可以看到,並非簡單地使用任何指令數據就能產生差異。Instruct PT 在大多數任務上表現優於 Mix PT,這一事實說明了指令-回答數據的性質(即與原始數據相關的指令-回答數據)才是關鍵所在。(作者在所有實驗中使用了相同數量的標記。)
此外,值得注意的是,Instruct PT 預訓練模型還有另一個優勢:如下圖所示,它們在隨後的指令微調中進步更大。

3.3 使用指令數據進行持續預訓練
從零開始預訓練很有趣,因為這正是 LLM 最初創建的方式。然而,我認為從業者更關心持續預訓練(continual pretraining)和微調。
這裡的持續預訓練意味著我們採用現有的預訓練模型,並在新的領域數據上進一步預訓練。例如,想像一個 Llama 3 8B 基礎模型,它已經在通用文本語料庫上訓練過,而你想讓它適應金融、醫療、法律或其他領域。
下表總結了研究人員將指令預訓練方法應用於預訓練的 Llama 3 8B 基礎模型時獲得的結果。具體而言,他們分別使用生物醫學文本和金融文本進行了持續預訓練。

觀察上表,我們可以看到指令預訓練方法(Instruct PT)明顯優於原始預訓練(Vanilla PT)方法(這裡指基礎模型的常規持續預訓練)。
Llama 3 70B 基礎模型被包含作為參考;我想是為了展示小型專業化模型可以擊敗大型通用模型。
3.4 結論
幾乎每次我向別人解釋 LLM 預訓練流水線時,他們都會對其簡單性以及這仍然是當今訓練 LLM 的常用方法感到驚訝。從這個意義上說,指令預訓練方法相當令人耳目一新。
一個警告是,對於大型預訓練語料庫,創建指令增強語料庫的成本可能仍然很高。然而,生成數據的好處在於,一旦創建,就可以在許多不同的項目中重複使用。
4. Gemma 2
寫這篇文章不能不提到 Google 新的 Gemma 2 模型,這無疑是上個月最大的模型發布。然而,就純粹的規模而言,Nvidia 的 Nemotron-4 340B 奪得桂冠 (https://arxiv.org/abs/2406.11704)。Gemma 2 模型有 2.6B、9B 和 27B 參數版本。
由於這篇文章已經相當長,而且你可能已經從其他來源熟悉了 Gemma 2,讓我們開門見山。Google 新發布的 Gemma 2 LLM 有哪些主要亮點和值得注意的更新?其主旋律是在不一定增加訓練數據集規模的情況下探索技術,而是專注於開發相對較小且高效的 LLM。
具體來說,他們融合了三種主要的架構和訓練選擇來創建 2.6B 和 9B 參數模型:滑動窗口注意力(sliding window attention)、分組查詢注意力(grouped-query attention)和知識蒸餾(knowledge distillation)。
4.1 滑動窗口注意力
滑動窗口注意力(例如由 Mistral 推廣)是一種使用固定大小注意力塊的技術,它允許當前標記僅關注特定數量的先前標記,而不是所有先前標記,如下圖所示。

在 Gemma 2 的案例中,作者在常規注意力和滑動窗口注意力層之間交替。滑動注意力塊大小為 4096 個標記,跨越總塊大小為 8192 個標記。
滑動窗口注意力主要用於提高計算性能,研究人員還包含了一個小型消融研究,顯示在推理期間縮小塊大小時,困惑度(perplexity)的差異幾乎察覺不到。

(如果能看到 GPU 內存改進的並排對比會很有趣。)
4.2 分組查詢注意力
分組查詢注意力(如 Llama 2 和 3)可以被視為多查詢注意力(multi-query attention)的一種更廣義形式。其背後的動機是通過多個查詢頭共享相同的鍵(Keys)和值(Values)頭來減少可訓練參數的數量,從而降低計算需求。

4.3 知識蒸餾
知識蒸餾(如 MiniLLM, https://arxiv.org/abs/2306.08543)的一般思想是將知識從較大的模型(教師)轉移到較小的模型(學生)。在這裡,他們從零開始訓練了一個 27B(教師)模型,然後在較大教師模型的輸出上訓練較小的 2B 和 9B(學生)模型。27B 模型不使用知識蒸餾,而是從零開始訓練,作為較小模型的「教師」。

4.4 其他有趣的架構細節
論文中包含許多其他有趣的細節。例如,Gemma 2 的一個標誌是其相對較大的詞彙表大小:256,000 個標記。這與第一個 Gemma 模型相似,但仍值得注意,因為它是 Llama 3 詞彙表(128,000)的兩倍,是 Phi-3 詞彙表(32,000)的八倍。
LLM 的詞彙表大小是指模型可以識別和生成的唯一標記(單詞、子詞或字符)的數量。
LLM 中較大的詞彙表大小可以更好地覆蓋單詞和概念,改善對多語言內容的處理,並減少分詞偽影。然而,大詞彙表也帶來了權衡,例如模型體積增大,以及由於嵌入層和輸出層較大而導致推理速度可能變慢。(這就是滑動窗口注意力和多查詢注意力機制在抵消這些影響方面發揮重要作用的地方。)
還有一個關於「logit capping」的有趣章節,這是我以前沒見過的一種技術。本質上,它是對 logit 值進行的一種最小-最大歸一化和裁剪,以將其保持在一定範圍內。我推測這是為了提高訓練期間的穩定性和梯度流。
logits ← soft_cap ∗ tanh(logits/soft_cap)。
此外,他們利用模型合併技術來組合來自具有不同超參數的多個運行模型,儘管論文對此沒有提供太多細節。(不過,感興趣的讀者可以在《WARP: On the Benefits of Weight Averaged Rewarded Policies》中閱讀更多內容,Gemma 2 正是使用了該技術。)
在建模性能方面,Gemma 2 幾乎與大 3 倍的 Llama 3 70B 一樣好,並且擊敗了舊的 Qwen 1.5 32B 模型。如果能與更近期的 Qwen 2 模型進行比較會很有趣。

就個人而言,一個亮點是 Gemma 2 報告包含了對其某些架構選擇的消融研究。這曾是學術研究的標配,但在 LLM 研究中卻越來越罕見。
4.5 結論
看到 Google 發布如此詳盡的技術報告令人振奮。至於模型本身,根據公眾共識,Gemma 2 可能是當今單 GPU 使用場景中最強大的模型。對於更大的模型,Llama 3 70B 和 Qwen 2 72B 仍然是強有力的競爭者。
支持 Ahead of AI
Ahead of AI 是一個個人熱情項目,不提供直接報酬。然而,對於那些希望支持我的人,請考慮購買我的書。如果你覺得它們富有洞察力且有益,請隨時推薦給你的朋友和同事。
如果你有幾分鐘時間,在 Amazon 上對《Machine Learning Q and AI》或《Machine Learning with PyTorch and Scikit-Learn》進行評論也會非常有幫助!
你的支持意義重大,對繼續這段旅程非常有幫助。謝謝!
5. 四月份其他有趣的研究論文
以下是我本月偶然發現的其他有趣論文精選。鑑於清單較長,我用星號 (*) 標註了 20 篇我認為特別有趣的論文。但請注意,此清單及其註釋純粹基於我的興趣以及與我個人項目的相關性。
-
Scaling Synthetic Data Creation with 1,000,000,000 Personas by Chan, Wang, Yu, et al. (28 June), https://arxiv.org/abs/2406.20094
該研究提出了一種角色驅動的數據合成方法,利用 LLM 通過龐大的自動策劃角色集合(稱為 Persona Hub)來創建多樣化的合成數據,該集合代表了全球約 13% 的人口。 -
LLM Critics Help Catch LLM Bugs by McAleese, Pokorny, Ceron Uribe, et al. (28 June), https://arxiv.org/abs/2407.00215
本研究使用 RLHF 開發了「評論家(critic)」模型,以協助人類評估模型生成的代碼,訓練 LLM 對代碼錯誤撰寫自然語言反饋,並證明了它們在捕捉各種任務中的錯誤方面的有效性。 -
Direct Preference Knowledge Distillation for Large Language Models by Li, Gu, Dong, et al. (28 June), https://arxiv.org/abs/2406.19774
DPKD 將 LLM 的知識蒸餾重新表述為一個兩階段過程:首先優化結合隱式獎勵和反向 KL 散度的目標,然後提高教師輸出相對於學生輸出的偏好概率。 -
Changing Answer Order Can Decrease MMLU Accuracy by Gupta, Pantoja, Ross, et al. (27 June), https://arxiv.org/abs/2406.19470
本研究調查了 LLM 在 MMLU 基準測試上準確度測量的魯棒性,揭示了洗牌答案標籤內容會導致各模型準確度下降,且敏感度各異。 -
From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data by Xiong, Papageorgiou, Lee, and Papailiopoulos (27 June), https://arxiv.org/abs/2406.19292
本研究提出了一種使用數值鍵值檢索任務的合成數據集進行微調的方法,以提高 LLM 的長文本信息檢索和推理能力。 -
Dataset Size Recovery from LoRA Weights by Salama, Kahana, Horwitz, and Hoshen (27 June), https://arxiv.org/abs/2406.19395
本研究通過分析 LoRA 矩陣的範數和譜,引入了一種從使用 LoRA 微調的視覺模型中恢復所用圖像數量的方法。 -
Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs by Azerbayev, Shao, Lin, et al. (26 June), https://arxiv.org/abs/2406.18629
本文介紹了 Step-DPO,這是一種使用自定義的 10K 逐步偏好對數據集來優化 LLM 在數學問題解決中單個推理步驟的方法。 -
RouteLLM: Learning to Route LLMs with Preference Data by Ong, Amjad, et al. (26 June), https://arxiv.org/abs/2406.18665
本研究提出了高效的路由模型,在推理期間動態選擇強模型或弱模型,以優化成本與性能的權衡。 -
*** A Closer Look into Mixture-of-Experts in Large Language Models** by Zhang, Liu, Patel, et al. (26 June), https://arxiv.org/abs/2406.18219
本研究觀察了混合專家(MoE)LLM 的內部運作,分享了關於神經元行為、專家選擇標準以及跨層專家多樣性的見解,並基於這些觀察為 MoE 設計和實現提供了實用建議。 -
*** Following Length Constraints in Instructions** by Yuan, Kulikov, Yu, et al. (25 June), https://arxiv.org/abs/2406.17744
本研究引入了一種訓練 LLM 的方法,使其在推理時能遵循用戶指定的長度限制,解決了模型評估中的長度偏差,並在長度控制任務中優於標準的指令遵循模型。 -
LongIns: A Challenging Long-context Instruction-based Exam for LLMs by Shaham, Bai, An, et al. (25 June), https://arxiv.org/abs/2406.17588
LongIns 是一個評估 LLM 長文本能力的新基準,使用三種設置來評估檢索和推理能力。 -
*** The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale** by He, Wang, Shen, et al. (25 June), https://arxiv.org/abs/2406.17557
本報告介紹了 FineWeb(一個源自 Common Crawl 的 15 兆標記數據集)和 FineWeb-Edu(一個 1.3 兆標記的教育子集)。 -
Adam-mini: Use Fewer Learning Rates To Gain More by Zhang, Chen, Li, et al. (24 June), https://arxiv.org/abs/2406.16793
Adam-mini 是一種提出的優化器,通過策略性地減少學習率資源、基於 Hessian 結構劃分參數,並為參數塊分配優化的單一學習率,在減少 45-50% 內存使用的同時,實現與 AdamW 相當或更好的性能。 -
WARP: On the Benefits of Weight Averaged Rewarded Policies by Ramé, Ferret, Vieillard, et al. (24 June), https://arxiv.org/abs/2406.16768
該論文為 LLM 引入了一種新的對齊策略,在三個階段合併策略:使用指數移動平均進行動態 KL 正則化、獨立微調策略的球面插值,以及與初始化的線性插值。 -
Sparser is Faster and Less is More: Efficient Sparse Attention for Long-Range Transformers by Lou, Jia, Zheng, and Tu (24 June), https://arxiv.org/abs/2406.16747
作者為自回歸 Transformer 提出了一種新的稀疏注意力機制,使用評分網絡和可微的 top-k 掩碼算子為每個查詢選擇固定數量的 KV 對,以實現線性時間複雜度和恆定的內存佔用。 -
Efficient Continual Pre-training by Mitigating the Stability Gap by Wang, Hu, Xiong, et al. (21 June), https://arxiv.org/abs/2406.14833
本研究提出了三種改進 LLM 持續預訓練的策略:在子集上進行多個 epoch、專注於高質量數據,以及使用類似於預訓練數據的混合數據。 -
MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression by Fu, Huang, Ning, et al. (21 June), https://arxiv.org/abs/2406.14909
混合注意力(MoA)為 LLM 的不同模型組件和輸入長度自動優化稀疏注意力模式,與均勻稀疏注意力方法相比,提高了上下文長度、準確度和效率。 -
LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs by Jiang, Ma, Chen, et al. (21 June), https://arxiv.org/abs/2406.15319
LongRAG 引入了一種新的 RAG 框架,使用 4K 標記的檢索單元和長文本 LLM 進行答案提取,這提高了檢索性能,並在無需額外訓練的情況下在問答任務中取得了最先進的結果。 -
*** A Tale of Trust and Accuracy: Base vs. Instruct LLMs in RAG Systems** by Cuconasu, Trappolini, Tonellotto, et al. (21 June), https://arxiv.org/abs/2406.14972
本研究挑戰了傳統觀念,證明了在檢索增強生成(RAG)任務中,基礎 LLM 的表現優於指令微調模型。 -
Can LLMs Learn by Teaching? A Preliminary Study by Ning, Wang, Li, Lin, et al. (20 June), https://arxiv.org/abs/2406.14629
作者開發並測試了三種在 LLM 中實現「通過教學學習」的方法,在不同層次上模仿人類教學過程:觀察學生反饋、從反饋中學習以及迭代學習,以在不依賴額外人工數據或更強模型的情況下提高模型性能。 -
*** Instruction Pre-Training: Language Models are Supervised Multitask Learners** by Cheng, Gu, Huang, et al. (20 June), https://arxiv.org/abs/2406.14491
本研究引入了一個用於 LLM 監督多任務預訓練的框架,該框架使用合成生成的指令-回答對來增強原始語料庫。 -
*** Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?** by Wu, Zhang, Johnson, et al. (19 June), https://arxiv.org/abs/2406.13121
本研究引入了一個基準,用於評估長文本 LLM 在需要多達數百萬標記的任務上的表現,證明了這些長文本 LLM 在上下文檢索和推理任務中可以與專門的檢索和 RAG 系統競爭。 -
Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges by Ye, Turpin, Li, He, et al. (18 June), https://arxiv.org/abs/2406.12624
本文使用 TriviaQA 作為基準評估了 LLM 作為評判者的範式,將 9 個評判模型和 9 個受試模型與人工標註進行對比,揭示了與人類對齊程度高的模型不一定最擅長對受試模型進行排名。 -
From RAGs to Rich Parameters: Probing How Language Models Utilize External Knowledge Over Parametric Information for Factual Queries by Wadhwa, Seetharaman, Aggarwal, et al. (18 June), https://arxiv.org/abs/2406.12824
作者調查了 LLM 中檢索增強生成(RAG)的機制,揭示了模型在回答問題時主要依賴檢索到的上下文信息而非其參數記憶,在不同模型系列中表現出一種捷徑行為。 -
Self-MoE: Towards Compositional Large Language Models with Self-Specialized Experts by Kang, Karlinsky, and Luo, et al. (17 June), https://arxiv.org/abs/2406.12034
本文介紹了一種將單體 LLM 轉換為名為 MiXSE(自我專業化專家混合)的模塊化系統的方法,使用自我生成的合成數據創建具有共享基礎 LLM 和自我優化路由的專業化專家模塊。 -
Measuring memorization in RLHF for code completion by Pappu, Porter, Shumailov, and Hayes (17 June), https://arxiv.org/abs/2406.11715
本研究調查了人類反饋強化學習(RLHF)對 LLM 數據記憶的影響,重點關注代碼補全任務,發現雖然與直接微調相比,RLHF 減少了對獎勵建模和強化學習中所用數據的記憶,但它在很大程度上保留了初始微調階段的記憶。 -
HARE: HumAn pRiors, a key to small language model Efficiency by Zhang, Jin, Ge, et al. (17 June), https://arxiv.org/abs/2406.11410
本研究提出了一種在小語言模型(SLM)數據構建中利用人類先驗的原則,專注於語義多樣性和數據質量一致性,同時避免基準數據洩漏。 -
Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level by Kim, Lee, Park, et al. (17 June), https://arxiv.org/abs/2406.11817
本研究引入了迭代長度正則化直接偏好優化(iLR-DPO),這是一種在控制回答冗長程度的同時,改善 LLM 與人類偏好對齊的方法。 -
Unveiling Encoder-Free Vision-Language Models by Choi, Yoon, Lee, et al. (17 June), https://arxiv.org/abs/2406.11832
本研究展示了一種無編碼器視覺語言模型(VLM),它在統一的解碼器中直接處理視覺和文本輸入。 -
*** DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence** by Zhu, Wang, Lee, et al. (17 June), https://arxiv.org/abs/2406.11931
DeepSeek-Coder-V2 是一個開源的混合專家代碼 LLM,通過在額外的 6 兆標記上進行持續預訓練,在編碼任務上達到了 GPT4-Turbo 級別的性能。 -
Tokenization Falling Short: The Curse of Tokenization by Nguyen, Kim, Patel, et al. (17 June), https://arxiv.org/abs/2406.11687
本研究通過檢查 LLM 在複雜問題解決、標記結構探測和對拼寫變化的韌性方面的表現,調查了 LLM 中的「分詞之咒」,揭示了雖然擴大模型規模有所幫助,但 LLM 仍然容易受到分詞引起的偏差影響。 -
DataComp-LM: In Search of the Next Generation of Training Sets for Language Models by Li, Fang, Smyrnis, et al. (17 June), https://arxiv.org/abs/2406.11794
作者為語言模型訓練中的數據集策劃策略實驗提供了一個標準化測試平台,包括一個 240T 標記語料庫、預訓練配方和 53 個下游評估。 -
*** Nemotron-4 340B Technical Report** by Unknown Authors at NVIDIA (17 June), https://arxiv.org/abs/2406.11704
這份技術報告伴隨 NVIDIA 發布的 Nemotron-4 340B 模型系列,該系列在各種基準測試中表現出競爭力,並在合成數據生成方面表現出色,同時開源了其數據生成流水線以供進一步研發。 -
mDPO: Conditional Preference Optimization for Multimodal Large Language Models by Wang, Zhou, Huang, et al. (17 June), https://arxiv.org/abs/2406.11839
mDPO 通過優化圖像偏好以及語言偏好,並引入獎勵錨點以防止所選回答的似然度下降,解決了多模態 DPO 中的無條件偏好問題。 -
*** How Do Large Language Models Acquire Factual Knowledge During Pretraining?** by Chang, Park, Ye, et al. (17 June), https://arxiv.org/abs/2406.11813
-
Task Me Anything by Zhang, Huang, Ma, et al. (17 June), https://arxiv.org/abs/2406.11775
Task-Me-Anything 是一個基準生成引擎,通過從龐大的圖像和視頻分類法中以編程方式生成任務實例,為多模態語言模型創建量身定制的基準。 -
THEANINE: Revisiting Memory Management in Long-term Conversations with Timeline-augmented Response Generation by Kim, Ong, Kwon, et al. (16 June), https://arxiv.org/abs/2406.10996
Theanine 通過使用記憶時間線(顯示過去事件發展和因果關係的一系列記憶)來增強 LLM 的回答生成,從而提高模型從漫長對話歷史中檢索和利用信息的能力。 -
Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs by Yang, Ding, Lin, et al. (14 June) https://arxiv.org/abs/2406.10216
本研究提出通過保留基礎模型的語言模型頭並納入文本生成損失來正則化隱藏狀態,同時學習獎勵頭,從而增強 RLHF 中獎勵模型的泛化能力,進而提高分佈外任務性能並減輕獎勵過度優化。 -
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs by Hans, Wen, Jain, et al. (14 Jun), https://arxiv.org/abs/2406.10209
「金魚損失(goldfish loss)」技術通過在訓練期間從損失計算中隨機排除一部分標記,減少 LLM 的模型記憶,防止模型從訓練數據中學習完整的逐字序列。 -
Bootstrapping Language Models with DPO Implicit Rewards by Chen, Liu, Du, et al. (14 June), https://arxiv.org/abs/2406.09760
研究人員發現,使用在直接偏好優化(DPO)期間生成的對齊模型(一個隱式獎勵模型)本身可以用於生成偏好數據集,以進一步大幅提升自身。 -
FouRA: Fourier Low Rank Adaptation by Borse, Kadambi, Pandey, et al. (13 June), https://arxiv.org/abs/2406.08798
本研究介紹了 FouRA,這是一種在傅立葉域中運行並使用自適應秩選擇的新型低秩適應(LoRA)方法,解決了 LoRA 微調的文本到圖像擴散模型中的數據複製和分佈崩潰問題,同時提高了圖像質量和泛化能力。 -
*** An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels** by Nguyen, Mahmoud Assran, Jain, et al. (13 June), https://arxiv.org/abs/2406.09415
本研究揭示了原始 Transformer 通過將單個像素視為標記,可以在各種計算機視覺任務中實現高性能,這挑戰了現代視覺架構中假設的基於局部性的歸納偏置的必要性,並為計算機視覺中未來的神經網絡設計提供了新的可能性。 -
MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding by Zuhri, Adilazuarda, Purwarianti, and Aji (13 June), https://arxiv.org/abs/2406.09297
本研究介紹了多層鍵值(MLKV)共享,這是一種將鍵值(KV)緩存擴展到 Transformer 層的新技術,它大幅減少了自回歸推理期間的內存使用,超越了現有的多查詢注意力(MQA)和分組查詢注意力(GQA)等方法,同時保持了 NLP 任務的性能。 -
Transformers Meet Neural Algorithmic Reasoners by Bounsi, Ibarz, Dudzik, et al. (13 June), https://arxiv.org/abs/2406.09308
TransNAR 是一種將 Transformer 與基於圖神經網絡的神經算法推理器(NAR)相結合的混合架構,通過允許 Transformer 利用 NAR 強大的計算能力,同時保持強大的自然語言理解能力,從而提高在算法推理任務上的性能。 -
Discovering Preference Optimization Algorithms with and for Large Language Models by Lu, Holt, Fanconi, et al. (12 June), https://arxiv.org/abs/2406.08414
提出的「發現偏好優化(Discovered Preference Optimization)」方法使用 LLM 自動發現並實現新的偏好優化算法,以改進 LLM 輸出。 -
*** An Empirical Study of Mamba-based Language Models** by Waleffe, Byeon, Riach, et al. (12 June), https://arxiv.org/abs/2406.07887
本研究比較了在大數據集上訓練的 8B 參數狀態空間模型(Mamba, Mamba-2)和 Transformer 模型,發現雖然純狀態空間模型在許多任務上與 Transformer 相當或更好,但在需要強複製、上下文學習或長文本推理的任務上落後;然而,混合模型似乎能兼顧兩者的優點。 -
*** Large Language Models Must Be Taught to Know What They Don't Know** by Kapoor, Gruver, Roberts, et al. (12 June), https://arxiv.org/abs/2406.08391
本研究證明,在一個小型評分示例數據集上微調 LLM 可以產生比僅使用提示更可靠的不確定性估計,生成的模型能夠為自己和其他模型估計不確定性。 -
Large Language Model Unlearning via Embedding-Corrupted Prompts by Liu, Flannigan, and Liu (12 June), https://arxiv.org/abs/2406.07933
本研究介紹了嵌入損壞提示(embedding-corrupted prompts),這是一種 LLM 選擇性知識遺忘的方法,使用提示分類和嵌入損壞在各種規模的模型中實現有針對性的遺忘,且副作用極小。 -
What If We Recaption Billions of Web Images with LLaMA-3? by Li, Tu, Hui, et al. (12 June) https://arxiv.org/abs/2406.08478
本研究證明,使用微調的 Llama 3 驅動的 LLaVA-1.5 多模態 LLM 為來自 DataComp-1B 數據集的 13 億張圖像重新撰寫說明文字,顯著提高了視覺語言模型在各種任務中的性能。 -
*** Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing** by Xu, Jiang, Niu et al. (12 June), https://arxiv.org/abs/2406.08464
研究人員提出了一種合成指令數據生成方法,從 Llama-3-Instruct 生成了 300,000 個高質量的指令-回答對;這些數據可用於監督指令微調,以在不需要實際對齊步驟的情況下,與對齊後的 LLM 性能相媲美。 -
*** Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling** by (11 June), https://arxiv.org/abs/2406.07522
Samba 是一個將選擇性狀態空間模型(如 Mamba)與滑動窗口注意力相結合的混合模型,可高效擴展至 3.8B 參數。 -
*** Never Miss A Beat: An Efficient Recipe for Context Window Extension of Large Language Models with Consistent "Middle" Enhancement** (11 June) by Wu, Zhao, and Zheng, https://arxiv.org/abs/2406.07138
CREAM 是一種訓練效率高的方法,通過插值位置編碼並使用截斷高斯分佈來優先處理中間上下文信息,從而擴展 LLM 的上下文長度。 -
Simple and Effective Masked Diffusion Language Models by Sahoo, Arriola, Schiff, et al. (11 June), https://arxiv.org/abs/2406.07524
這項工作證明,當使用有效的配方和簡化的目標進行訓練時,掩碼離散擴散模型可以大幅縮小與語言建模中自回歸方法的性能差距。 -
TextGrad: Automatic "Differentiation" via Text by Yuksekgonul, Bianchi, Boen, et al. (11 June), https://arxiv.org/abs/2406.07496
TextGrad 是一個利用 LLM「反向傳播」文本反饋的框架,用於優化複合 AI 系統中的構建塊(如「工具調用器」、「搜索引擎」等)。 -
An Image is Worth 32 Tokens for Reconstruction and Generation by Yu, Weber, Deng, et al. (11 June), https://arxiv.org/abs/2406.07550
作者提出了一種基於 Transformer 的一維分詞器用於圖像生成,將 256x256x3 的圖像減少到僅 32 個離散標記。 -
*** Self-Tuning: Instructing LLMs to Effectively Acquire New Knowledge through Self-Teaching** by Zhang, Peng, Zhou, et al., (10 June), https://arxiv.org/abs/2406.06326
Self-Tuning 框架通過專注於記憶、理解和自我反思的自我教學任務,提高了 LLM 從原始文檔中獲取知識的能力。 -
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters by Song, Xie, Zhang, et al. (10 June), https://arxiv.org/abs/2406.05955
本文提出了 dReLU 激活函數和優化的訓練數據混合,以提高 LLM 中的激活稀疏性。 -
Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning by Kim, Paranjape, Khot, and Hajishirzi (10 June), https://arxiv.org/abs/2406.06469
Husky 是一個開源語言代理,它學習在統一的動作空間上進行推理,通過在專家模型生成和執行動作之間進行迭代,來處理涉及數值、表格和基於知識的推理的多樣化任務。 -
Margin-aware Preference Optimization for Aligning Diffusion Models Without Reference by Hong, Paul, Lee, et al. (10 June), https://arxiv.org/abs/2406.06424
為了克服 RLHF 和 DPO 等傳統對齊技術的局限性,作者為文本到圖像擴散模型提出了邊緣感知偏好優化(MaPO),它在不使用參考模型的情況下最大化首選和非首選圖像集之間的似然邊緣。 -
*** Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation** by Sun, Jian, Chen, et al. (10 June), https://arxiv.org/abs/2406.06525
作者提出了 LlamaGen,涉及將大語言模型的「下一個標記預測」範式應用於圖像生成。 -
Creativity Has Left the Chat: The Price of Debiasing Language Models by Mohammidi (8 June), https://arxiv.org/abs/2406.05587
本研究揭示了雖然 RLHF 等對齊技術減輕了 LLM 中的偏差,但它們可能會削弱模型的創造能力,影響語法和語義的多樣性,而這對於需要創造性輸出的任務至關重要。 -
3D-GRAND: A Million-Scale Dataset for 3D-LLMs with Better Grounding and Less Hallucination by Yang, Chen, Madaan, et al. (7 June), https://arxiv.org/abs/2406.05132
本研究介紹了 3D-GRAND,一個包含 40,087 個家庭場景及 620 萬條場景語言指令的數據集,並利用指令微調和 3D-POPE 基準來增強 3D-LLM 的定位能力並減少幻覺。 -
BERTs are Generative In-Context Learners by Samuel (7 June), https://arxiv.org/abs/2406.04823
本文證明了掩碼語言模型(如 DeBERTa)可以使用一種簡單的推理技術執行上下文學習,該技術使用類似於因果注意力掩碼結構的掩碼標記重新格式化輸入標記序列。 -
June 7, Mixture-of-Agents Enhances Large Language Model Capabilities, https://arxiv.org/abs/2406.04692
-
WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild by Lin, Deng, Chandu, et al. (7 June), https://arxiv.org/abs/2406.04770
作者引入了一個自動化評估框架,使用真實世界的用戶查詢來對 LLM 進行基準測試,具有 1,024 個任務和兩個高級指標 WB-Reward 和 WB-Score,通過採用特定任務的清單和結構化解釋來提供可靠且可解釋的自動判斷。 -
CRAG -- Comprehensive RAG Benchmark by Yang, Sun, Xin, et al. (7 June), https://arxiv.org/abs/2406.04744
本研究介紹了一個包含 4,409 個問答對的事實問答數據集,帶有用於模擬網絡和知識圖譜搜索的模擬 API,旨在反映多樣化、動態的真實世界問答任務。 -
Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach by Dong, Luo, Zhang, et al. (7 June), https://arxiv.org/abs/2406.04594
本研究介紹了 C4,一種用於 LLM 並行訓練的通信驅動解決方案,它能快速識別和隔離硬件故障並優化流量規劃以減少網絡擁塞,可將錯誤引起的開銷減少多達 30%,並將運行性能提高多達 15%。 -
Step-aware Preference Optimization: Aligning Preference with Denoising Performance at Each Step by Liang, Yuan, Gu, et al. (6 June), https://arxiv.org/abs/2406.04314
本研究介紹了步驟感知偏好優化,這是一種訓練後方法,獨立評估和調整文本到圖像擴散模型中每一步的去噪性能,在圖像對齊和美學方面優於 Diffusion-DPO,同時提供 20 倍快的訓練效率。 -
*** Are We Done with MMLU?** by Gema, Leang, Hong, et al. (6 June), https://arxiv.org/abs/2406.04127
本研究識別了廣泛使用的 MMLU 基準測試中的眾多錯誤,創建了一個名為 MMLU-Redux 的重新標註子集,揭示了報告的模型性能存在顯著差異,並倡導修訂 MMLU 以提高其可靠性。 -
*** Transformers Need Glasses! Information Over-Squashing in Language Tasks** by Barbero, Banino, Kapturowski, et al. (6 June), https://arxiv.org/abs/2406.04267
該研究分析了 LLM(特別是僅解碼器 Transformer)中的信息傳播,揭示了一種表示崩潰現象,即不同的輸入序列可能產生極其接近的最終標記表示,導致計數或複製等任務出錯,並喪失對特定輸入標記的敏感度。 -
The Prompt Report: A Systematic Survey of Prompting Techniques by Schulhoff, Ilie, Balepur, et al. (6 June), https://arxiv.org/abs/2406.06608
這篇 76 頁的論文旨在為理解提示和提示技術提供一個清晰且有組織的框架。 -
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models by Yang, Yu, Zhang, et al. (6 June), https://arxiv.org/abs/2406.04271
這種「思想緩衝(Buffer of Thoughts)」方法通過檢索和實例化思想模板(通用的問題解決藍圖)來改進 LLM,以便在各個領域進行推理。 -
Block Transformer: Global-to-Local Language Modeling for Fast Inference (4 June) by Ho, Bae, Kim, et al., https://arxiv.org/abs/2406.02657
提出的 Block Transformer 通過將昂貴的全局注意力隔離到固定大小標記塊的較低層,並在較高層應用快速局部注意力,將推理吞吐量提高了 10-20 倍。 -
*** Scalable MatMul-free Language Modeling** by Zhu, Zhang, Sifferman, et al. (4 June), https://arxiv.org/abs/2406.02528
本文提出了一種可擴展的無矩陣乘法(MatMul-free)語言模型架構,使用三值權重將矩陣乘法替換為逐元素乘積和累加,即使在十億參數規模下也表現良好。 -
Towards Scalable Automated Alignment of LLMs: A Survey, (3 June) by Cao, Lu, Lu, et al. https://arxiv.org/abs/2406.01252
本文回顧了 LLM 開發流水線中指令微調步驟之後最近出現的自動對齊方法。 -
The Geometry of Categorical and Hierarchical Concepts in Large Language Models by by Park, Choe, Jiang, and Veitch (3 June), https://arxiv.org/abs/2406.01506
使用 Gemma LLM,本文擴展了線性表示假設,證明了類別概念是單純形,層次關係是正交的,複雜概念是多胞體,並通過 957 個 WordNet 概念進行了驗證。 -
OLoRA: Orthonormal Low-Rank Adaptation of Large Language Models by Büyükakyüz (3 June), https://arxiv.org/abs/2406.01775
OLoRA 是對低秩適應(LoRA)的增強,使用通過 QR 分解進行的正交矩陣初始化,與常規 LoRA 相比加速了 LLM 訓練的收斂。 -
Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models by Wei, Zhu, Zhao et al. (3 June), https://arxiv.org/abs/2406.06563
一份報告,描述了從現有的 13B 參數稠密(非混合專家)模型開發 146B 參數混合專家 LLM 背後的一些途徑和方法。 -
Show, Don't Tell: Aligning Language Models with Demonstrated Feedback by Shaikh, Lam, Hejna, et al. (2 June), https://arxiv.org/abs/2406.00888
提出的方法利用模仿學習,使用少於 10 個演示作為反饋,將 LLM 輸出與特定的用戶行為對齊。
本雜誌是一個個人熱情項目,不提供直接報酬。然而,對於那些希望支持我的人,請考慮購買我的一本書。如果你覺得它們富有洞察力且有益,請隨時推薦給你的朋友和同事。(通過在 Amazon 上撰寫書評與他人分享你的反饋也會有很大幫助!)

你的支持意義重大!謝謝!
相關文章