從零開始構建 GPT 風格的大型語言模型分類器
這篇文章將向您展示如何將預訓練的大型語言模型轉換為強大的文本分類器。我會介紹微調預訓練模型以進行分類的核心概念,並探討其在垃圾郵件檢測與情緒分析等實際業務挑戰中的應用。
從零開始構建 GPT 風格的 LLM 分類器
微調 GPT 模型進行垃圾郵件分類
在本文中,我想向大家展示如何將預訓練的大型語言模型(LLMs)轉化為強大的文本分類器。
但為什麼要專注於分類呢?首先,微調預訓練模型進行分類是進入模型微調領域一個溫和且有效的方式。其次,許多現實世界和商業挑戰都圍繞著文本分類:垃圾郵件檢測、情感分析、客戶回饋分類、主題標籤等等。
你將在本文中學到什麼
為了慶祝新書出版,我將分享其中一個章節的節錄,該章節將引導你如何將預訓練的 LLM 微調為垃圾郵件分類器。
重要提示
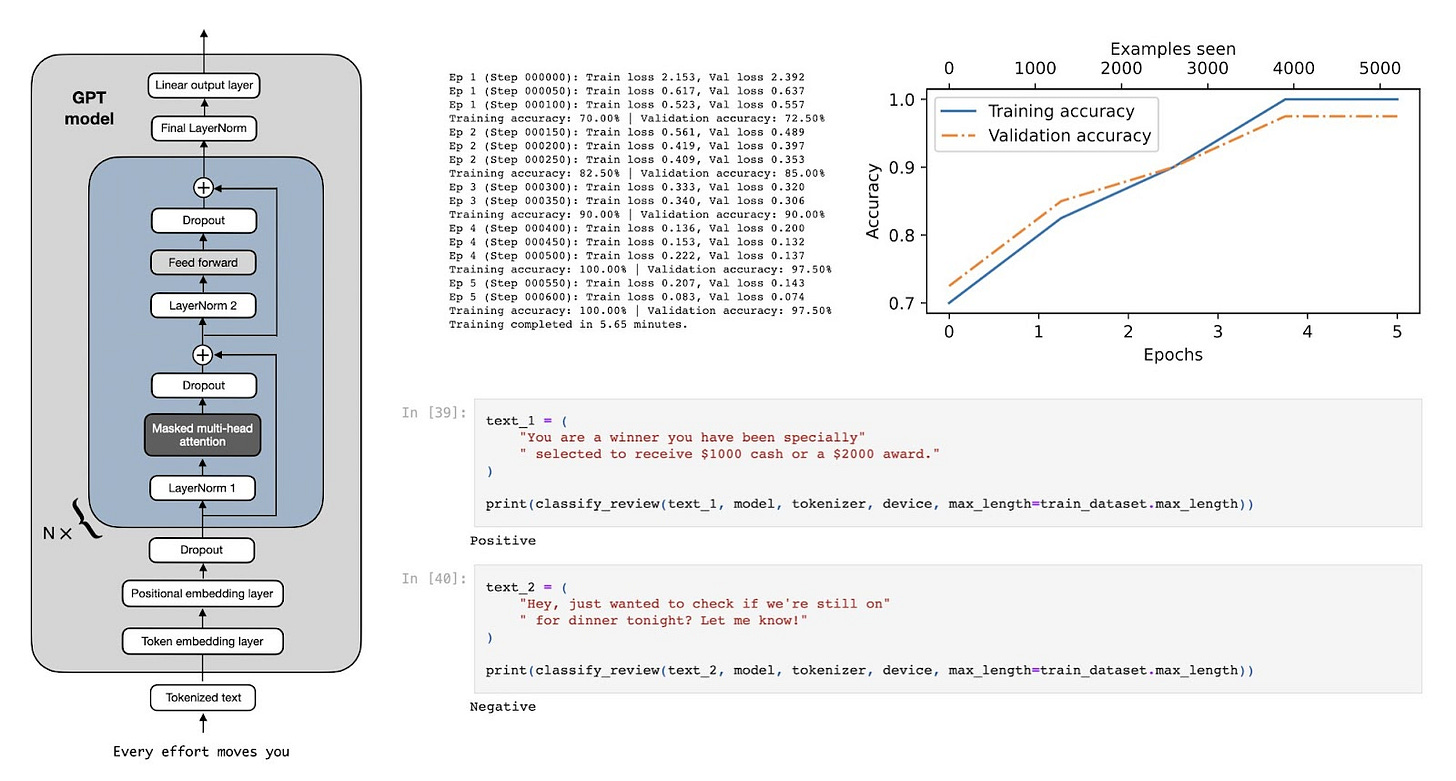
關於分類微調的章節長達 35 頁——對於單篇文章來說太長了。因此,在本篇貼文中,我將專注於約 10 頁的子集,介紹分類微調背後的背景和核心概念。
此外,我還會分享一些書中未包含的額外實驗心得,並回答讀者可能遇到的常見問題。(請注意,下方的節錄是基於 Manning 出版社進行專業文字編輯和最終圖表設計之前的個人草稿。)
此節錄的完整程式碼可以在 GitHub 上的這裡找到。
此外,我還將回答 7 個關於訓練 LLM 分類器可能遇到的問題:
-
我們需要訓練所有層嗎?
-
為什麼微調最後一個標記(token),而不是第一個標記?
-
BERT 與 GPT 在性能上的對比如何?
-
我們應該禁用因果遮罩(causal mask)嗎?
-
增加模型大小會產生什麼影響?
-
我們可以從 LoRA 中期待哪些改進?
-
要填充(Padding)還是不填充?
閱讀愉快!
微調的不同類別
微調語言模型最常見的方法是指令微調(instruction finetuning)和分類微調(classification finetuning)。指令微調涉及在一系列任務上訓練語言模型,使用特定指令來提高其理解和執行以自然語言提示描述的任務的能力,如下圖 1 所示。

下一章將討論指令微調,如上圖 1 所示。同時,本章的核心是分類微調,如果你有機器學習背景,這可能是你已經熟悉的概念。
在分類微調中,模型被訓練來識別一組特定的類別標籤,例如「垃圾郵件」和「非垃圾郵件」。分類任務的例子不僅限於大型語言模型和電子郵件過濾;它們還包括從圖像中識別不同種類的植物、將新聞文章分類為體育、政治或科技等主題,以及在醫學影像中區分良性與惡性腫瘤。
關鍵點在於,經過分類微調的模型僅限於預測其在訓練期間遇到的類別——例如,它可以判斷某物是「垃圾郵件」還是「非垃圾郵件」,如下圖 2 所示,但它無法對輸入文本說出除此之外的任何內容。

與圖 2 所示的分類微調模型相比,指令微調模型通常具有執行更廣泛任務的能力。我們可以將分類微調模型視為高度專業化的,通常情況下,開發一個專業化模型比開發一個在各種任務中表現良好的通用型模型更容易。
選擇正確的方法
指令微調提高了模型根據特定用戶指令理解並生成回應的能力。指令微調最適合需要根據複雜用戶指令處理多樣化任務的模型,能提高靈活性和互動品質。另一方面,分類微調則是需要將數據精確分類到預定義類別(如情感分析或垃圾郵件檢測)的專案的理想選擇。
雖然指令微調更具通用性,但它需要更大的數據集和更多的計算資源來開發精通各種任務的模型。相比之下,分類微調需要的數據和計算能力較少,但其用途僅限於模型訓練時所針對的特定類別。
感謝 Sebastian Raschka 博士,請繼續免費閱讀本貼文。
相關文章